
2018软工—团队现场编程实战(抽奖系统)
组员职责分工
林燊
- 分工
- 协调组内成员编码
- 完成原始数据的格式化处理,分类别抽取出数据特征
- 审查最终各成员代码
- 协助优化各模块代码
董钧昊
- 分工
- 完成基于字典形式的数据库建立
- 实现抽奖标准算法——开局选取基于名字中的英文字符个数以及极低的随机权重选取部分 “欧洲人”(运气较好的人),同时基于朴素贝叶斯分类器以及较低的发言权重再附加上极低的随机权重完成中奖者的选取
- 完成数据处理端与后端接口以及前后端接口的实现
- 完成博客的编写工作
卢恺翔
- 分工
- 完成普通过滤算法和深度过滤算法的实现,以及参与了数据预处理部分。
- 普通过滤算法能够根据用户发言的时间进行判断,过滤掉只在抽奖当天发言或者已经有两周不发言的人;而深度过滤算法过滤掉只在抽奖当天发言或者在3天内不发言的人。
- 将格式化化文件按照要求,转换成固定格式的txt文件。
杨喜源
- 分工
- 附加功能实现中的中奖海报生成——提供了抽奖次数、颁奖时间、中奖名单等一系列信息,实现了数据到海报的可视化。
- 附加功能中的自动分享功能
朱志豪
- 分工
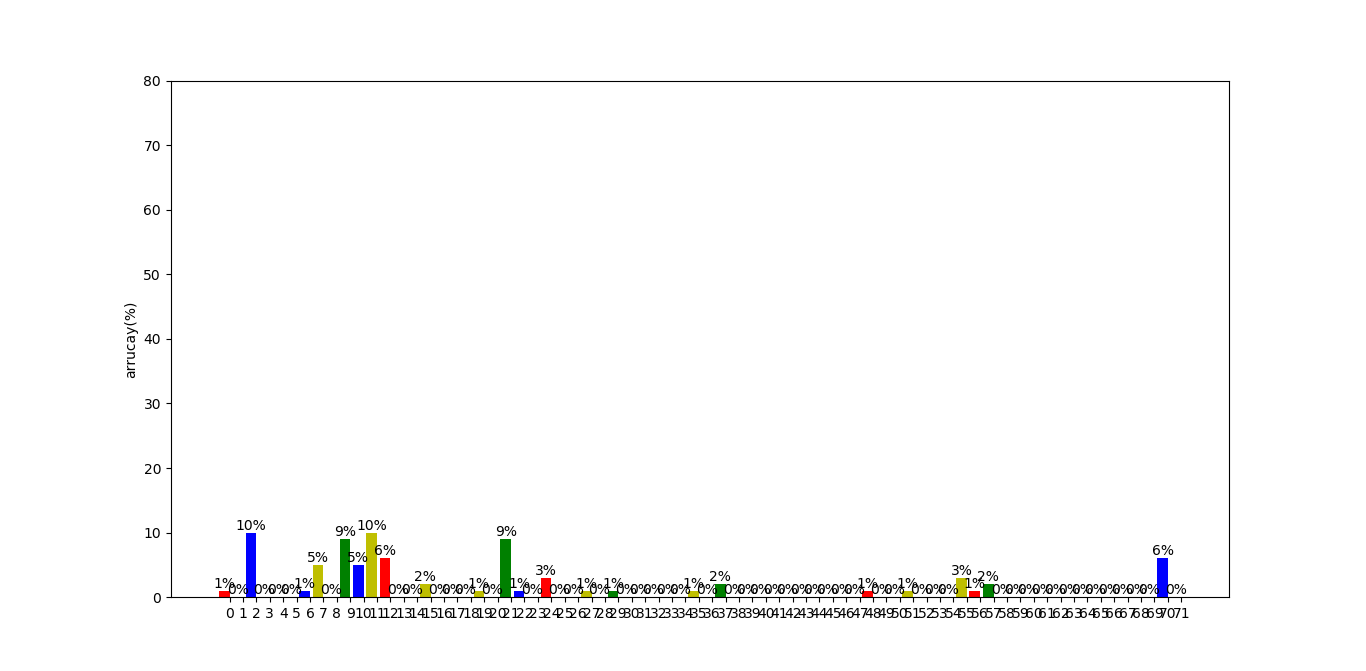
- 附加功能实现中的数据可视化,即为将同学之间提到对方的次数呈现为可视化的图,得到结论:聊天室的中心是柯老师。
- 同时提供了条形图数据,将每个人被提次数呈现为条形图,结论:排名前三的是柯老师,助教雨勤学姐和佩佩
- 抽奖文案的设计
陈柏涛
- 分工
- 前段界面实现
- 协助前后端接口实现
蔡宇航
- 分工
- qqbot的学习(附加功能中实现爬取指定群聊指定时刻聊天记录)
- qqbot爬取用户所有聊天记录并写入文件
- 编写定时结束qqbot并退出账号的函数
- 代码整合
刘宏岩
- 分工
- 编写启动qqbot登录指定账号的函数
- 编写指定群聊聊天记录指定格式写入文件写入文件的函数
- 接口封装
陈俞辛
- 分工
- 对爬取的聊天记录预处理,结果提供给抽奖算法
- 测试程序功能以及算法是否公平公正
- 收集成员材料,以供钧昊写博客
- readme部分撰写
github的提交日志截图
程序运行截图
实现视频
- 我们通过设置抽奖名称、奖品名称等多个抽奖关键字来完成抽奖的进行,同时隐式返回信息至后端,完成海报的智能生成。
- 再通过选择关键词以及过滤规则 (不过滤、浅度过滤、深度过滤) 来完成抽奖信息的匹配。
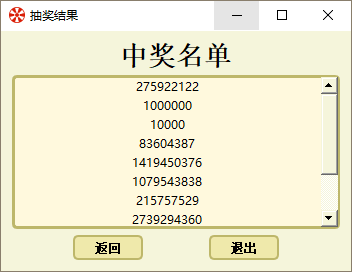
- 最后实现抽奖返回中奖名单以及公示海报,如下图所示。

- 在附加模块上,我们完成了获取指定群聊的所有聊天记录、公示海报的智能生成以及聊天记录的分析与挖掘,具体如下图所示。

程序运行环境
- 算法、后端部分
- python==3.6
- matlab
- 前端
- Qt==5
- 具体运行操作参见readme.md
GUI界面
- 信息填写部分用于选取QQ群名,进而获取指定群消息记录。
基础功能实现
基础功能
- 部分基于朴素贝叶斯分类器的抽奖,具体分为以下几个步骤:
- 抽奖前,针对用户的ID选取部分幸运者,置这些人较高的权重
- 在选取过程中,会参考用户的发言次数以及发言长度,同时筛选重复发言,以浅度过滤水军发言
- 最后再附加上极小的随机性,得出中奖几率
- 流程图如下所示:

- 时间过滤,则分为以下三类:
- 不过滤:默认对全聊天记录进行分析
- 浅度过滤:对30天内的聊天记录进行分析
- 深度过滤:对7天内的聊天记录分析
附加功能实现
附加功能(需要安装qqbot库):
- 在给定时间内获取指定群聊的所有聊天记录,具体如下:
- 设定用于获取记录的qq帐号
- 利用网页端qq(smart qq)实现指定账号扫码登录;
- 基于qqbot库实时爬取当前账户的所有聊天记录;
- 将爬取的聊天记录进行分类,并写入到如下两个文件:
- input.txt:爬取并记录下用户登录后所有聊天记录
- output.txt:爬取并以指定格式记录用户指定群聊指定时刻内的聊天记录
- 超过用户给定时间后自动退出当前账户,保证账户安全;
- 由于腾讯关闭获取qq号端口,无法获取qq号(属于个人隐私)
- 效果展示:
- 请求用户输入群名和倒计时长:

- 弹出登录二维码:

- 登录成功开始计时:

- 提示计时完毕

- 命令行中显示爬取结果:
- input.txt内容:

- output.txt内容:
- 自动生成海报
获奖了怎么公布?发文字?太low了。一键自动生成获奖海报才能体现逼格。
本次利用python的PIL库,实现读取抽奖结果的txt文件,自动生成美观海报
例:#我要红包#结果如下:

-
聊天记录的分析与挖掘
-
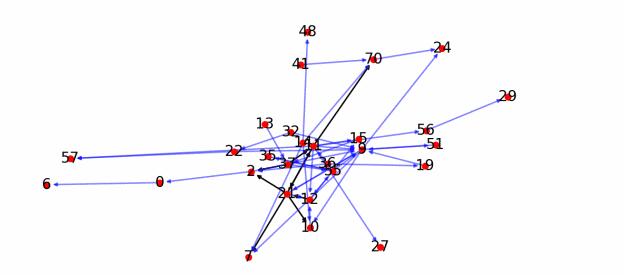
1. 将同学之间提到对方的次数呈现为可视化图(如下所示)
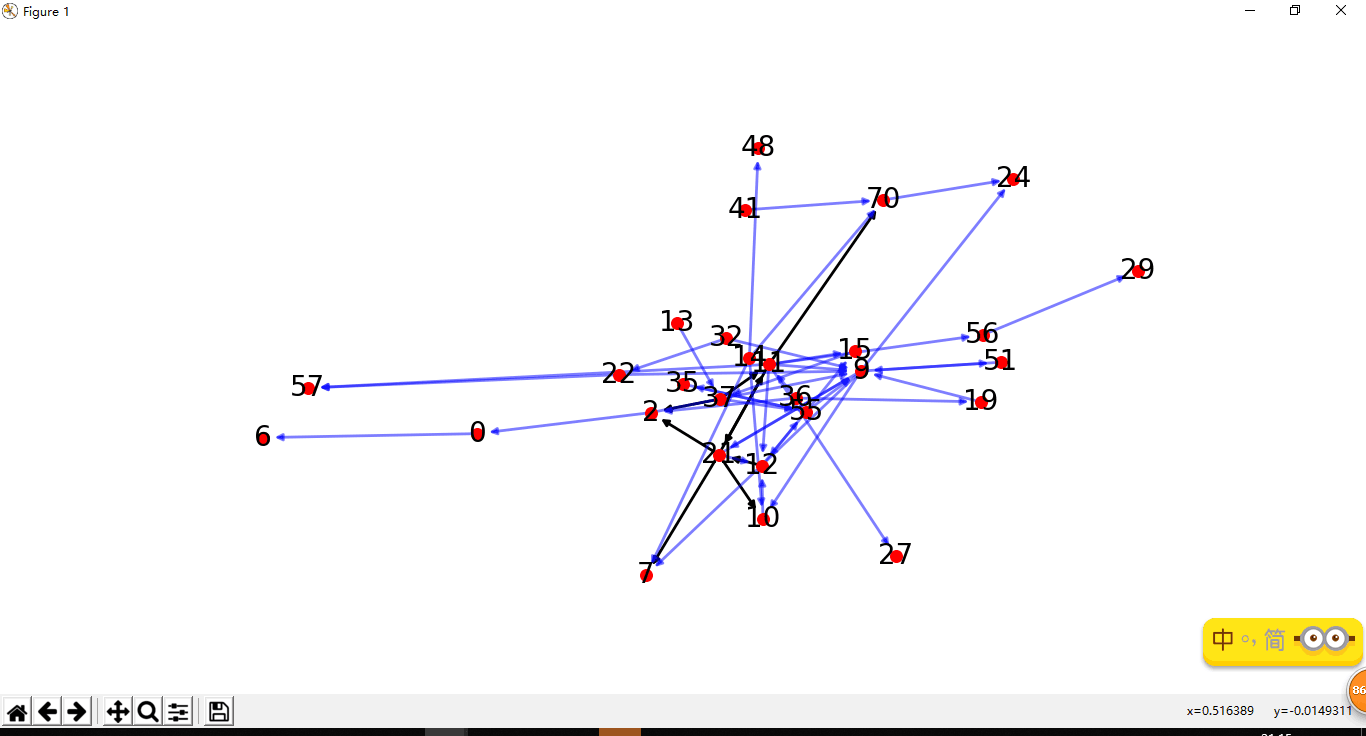
实现方法:遍历数据,将同学名和他们所发的消息保存成词典,然后依次遍历消息,寻找提到别人的次数,记到列表中。
仔细观察图,发现2号和9号被提起的次数很多,查看前面记录的数据(号数加用户名)

发现是柯老师和雨勤学姐(显而易见)
- 2. 将每个同学被q的次数呈现为条形图
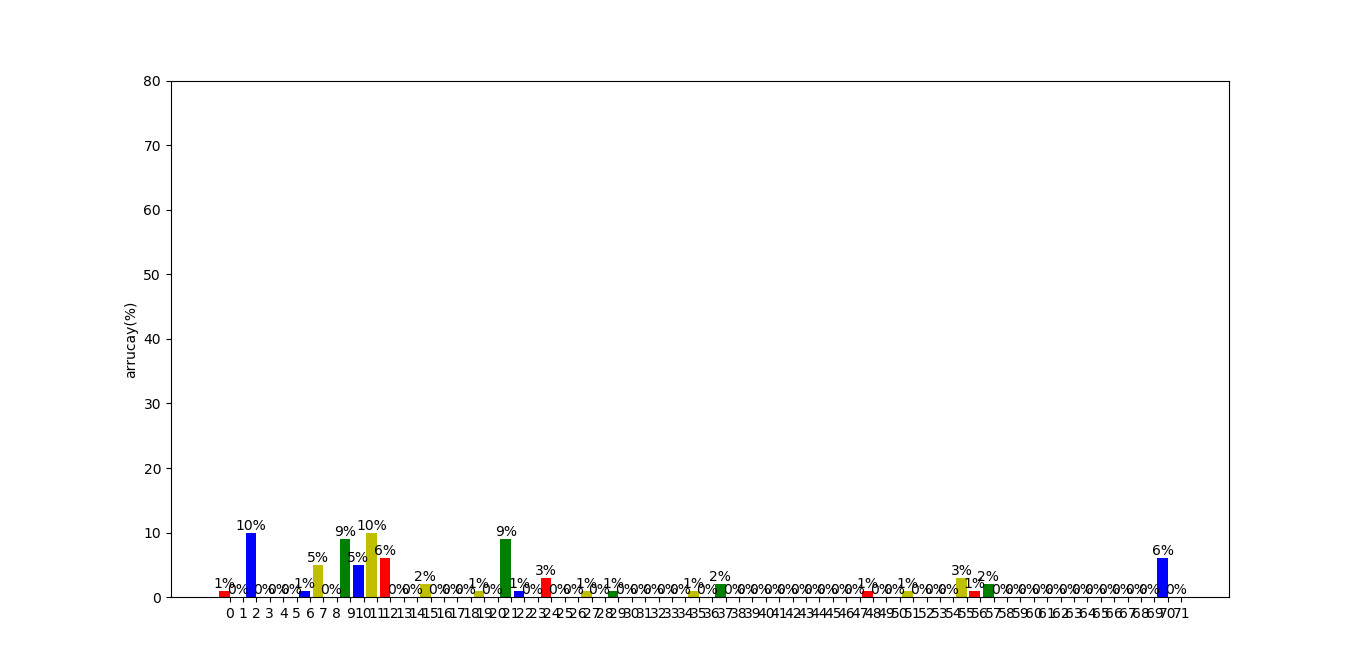
可以看到,被que最多的是2号(柯老师),9号(雨勤学姐)和21号(佩佩),和我们预想的一样
这个功能也有一些问题,比如有礼貌的我可能并不会提到老师的全名,这样的que是不被计入次数的,又或者各个同学有一些奇怪的爱称,这个也是我们不能识别的
鼓励有想法且有用的功能
- 或许你想根据聊天记录分析获取发言者的情感波动,而文本量较大且无法人工进行,这时我们该怎么办呢?
- 对此我们可基于此结合情感分析的手段实现文本处理,遗憾工程量过大,无法在时间限定内实现,大致结果图如下图所示:

遇到的困难及解决方法
- 董钧昊
- 困难一:很久没有编码,查找资料以及Debug上花费时间过长
- 解决方法一:定时的编码练习还是需要多注意的
- 困难二:在实现朴素贝叶斯分类器时,最开始思路不清晰,导致中期代码重构以及接口不对称问题
- 解决方法二:提前协调规范化接口定义,绘制出总体流程图后,再予以解决方案。
- 卢恺翔
- 困难一:数据格式没有按照预期的想法实现
- 解决方法一:对预处理过的数据进行再处理
- 困难二:过滤算法时间界定判断复杂
- 解决方法二:再次对数据进行格式化,调用python库进行时间筛选。
- 朱志豪
- 困难一:不会用python绘图
- 解决方法一:现场学习,百度python如何绘图,平时多学习python的有用的库
- 困难二:对自己的定位不是很清楚
- 解决方法二:静下来冷静思考,合理分析自己的能力和不足 打开文件,发现有的发言居然不止一行...然后就只好调整处理文件的逻辑重新编码
- 困难三:代码能力偏弱
- 解决方法三:平时多打代码,也可以做一些不需要特别强代码能力的事
- 困难四:很难构思出很有创意的附加功能
- 解决方法四:从生活找素材,冷静观察,大胆思考
- 杨喜源
- 困难一:负责写附加功能中的海报和自动分享,但是以前没有做过类似的东西,再加上时间比较紧迫,网上没有找到类似的发送图片
- 解决方法一:在设计海报方面找到了python的PIL能够自动生成海报,同时也了解到可以发送qq信息的qqbot,但是qqbot不支持发送图片,这方面还是没能解决
- 陈俞辛
- 困难一:作业中给出的示例聊天记录编码格式和我的VS上默认的编码格式不一样,导致我在处理文件的时候一直乱码
- 解决方法一:用了队友的 MAC 进行编程(MAC真好用)
- 困难二:还是示例聊天记录的问题,现场编码的时候看到用户的每次发言都只有一行,于是就按这样的格式去处理文件了,然而频繁出错
- 解决方法二:在队友的建议下,使用 Notepad++ 打开文件,发现有的发言居然不止一行...然后就只好调整处理文件的逻辑重新编码
马后炮
- 董钧昊
- 如果时间利用更高效的话,整合对接功能就不会那么仓促了。
- 朱志豪
- 如果平时能够多打点代码,那么那天早上我就能完成附加功能了。
- 杨喜源
- 如果时间能再多一点,这学期的课少一点,那么就多做做软工实践了
- 陈俞辛
- 如果我早点发现编码和格式的问题,那么就不用浪费那么多时间做无用功了
贡献度
| 名 | 贡献度 |
|---|---|
| 燊 | 11% |
| 俞辛 | 8% |
| 柏涛 | 13% |
| 志豪 | 12% |
| 钧昊 | 14% |
| 恺翔 | 12% |
| 喜源 | 10% |
| 宇航 | 12% |
| 宏岩 | 8% |
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 60 | 40 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 80 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 15 | 20 |
| · Coding | · 具体编码 | 30 | 40 |
| · Code Review | · 代码复审 | 30 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 15 | 20 |
| Reporting | 报告 | 10 | 10 |
| · Test Report | · 测试报告 | 10 | 5 |
| · Size Measurement | · 计算工作量 | 15 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 15 |
| 合计 | 385 | 400 |
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 300 | 300 | 18 | 18 | 原型设计,爬虫关于python的urllib库及request库学习 |
| 2 | 0 | 300 | 8 | 26 | 钢铁直男们的审美进步“一点点” |
| 3 | 500 | 800 | 12 | 38 | Java爬虫、Tkinter界面 |
| 4 | 0 | 800 | 6 | 44 | 学习了需求分析报告的撰写 |
| 5 | 0 | 800 | 8 | 52 | 学习了PPT制作以及视频剪辑 |
| 6 | 200 | 1000 | 7 | 59 | 学习了labelImg标注数据集 |
| 6 | 300 | 1300 | 10 | 69 | 进一步学习python网络爬虫 |
| 6 | 100 | 1400 | 8 | 77 | 学习了Linux下搭建MySQL数据库 |
| 6 | 350 | 1750 | 12 | 89 | 学习python爬虫中的beautifulsoup库并实战 |
| 7 | 150 | 1900 | 6 | 95 | 熟悉Linux下MySQL数据库的操作以及数据导入 |
| 7 | 0 | 1900 | 15 | 105 | 熟悉Linux下的进程通信机制,为远程连接任务储备知识 |
| 7 | 100 | 2000 | 5 | 110 | 学会编写简单的数据库脚本 |
| 7 | 300 | 2300 | 15 | 125 | 学会简单的安卓开发,在朱志豪同学的帮助下学会配置Androidstudio |
| 7 | 500 | 2800 | 10 | 135 | 熟悉hellohttp库,实现简单的demo,可以实现移动端和服务器端通信 |
| 8 | 300 | 3100 | 10 | 145 | 简单实用hellohttp库,实现移动端和服务器端通信 |
| 8 | 200 | 3300 | 3 | 148 | 使用python的qqbot库,实时获取聊天记录信息。并学会爬取命令行信息通过正则表达式输出到文件 |

