

相关连接请点击
程晓宏
李翔
github
具体分工如下:
- 晓宏:爬取论文信息,爬虫实现的代码,程序测试环节,附加功能
- 李翔:命令行自定义参数,加权统计,词组统计,词频统计的功能代码
PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 15 |
| · Estimate | · 估计这个任务需要多少时间 | 720 | 800 |
| Development | 开发 | 500 | 720 |
| · Analysis | · 需求分析 (包括学习新技术) | 150 | 90 |
| · Design Spec | · 生成设计文档 | 30 | 45 |
| · Design Review | · 设计复审 | 30 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 15 |
| · Design | · 具体设计 | 50 | 60 |
| · Coding | · 具体编码 | 300 | 450 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 60 | 30 |
| · Test Repor | · 测试报告 | 30 | 15 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 15 |
| | 合计 |1310 |1170
解题思路描述和设计实现说明
爬虫使用
- 最开始使用的爬虫工具是八爪鱼,简单上手快。但是爬的好慢,而且结果是导入到Excel文件中。还要对Excel文件进行处理,最终经过漫长的手动排版(吐血),完成了论文爬取。
- 八爪鱼爬取论文截图
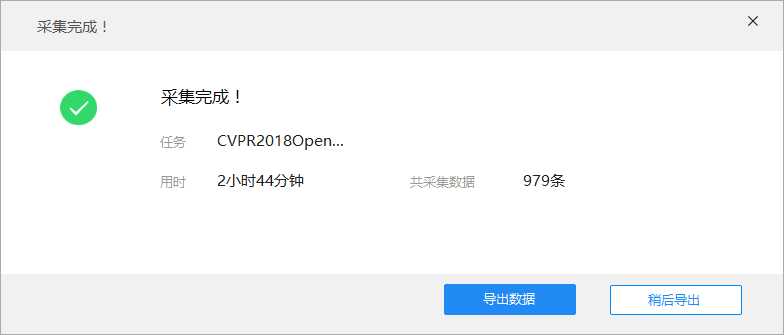
- 到学校之后,经过舍友的点拨,在他们推荐下了解使用Java用jsoup包进行爬取,在学习jsoup以及HTML知识之后,参考网络上的爬虫代码,编写了Java爬取论文代码:
- Java爬虫代码
package cpvrpaper;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class CpvrPaper {
public static void getContent(String URL)
{
try
{
File file = new File("C:\\Users\\Administrator\\Desktop\\课程\\软件工程\\result1.txt");
BufferedWriter bi = new BufferedWriter(new FileWriter(file));
Document document1 = Jsoup.connect(URL)
.maxBodySize(0)
.timeout(600000)
.get();
Elements element3 = document1.select("[class=ptitle]");
Elements hrefs = element3.select("a[href]");
long count = 0;
for(Element element6:hrefs)
{
String url = element6.absUrl("href");
Document document2 = Jsoup.connect(url)
.maxBodySize(0)
.timeout(600000)
.get();
Elements elements1 = document2.select("[id=papertitle]");
String title = elements1.text();
bi.write(count+"\r\n");
bi.write("Title: "+title+"\r\n");
Elements elements2 = document2.select("[id=abstract]");
String abstract1 = elements2.text();
bi.write("Abstract: "+abstract1+"\r\n"+"\r\n"+"\r\n");
count++;
}
bi.close();
}catch(Exception e)
{
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException
{
String url = "http://openaccess.thecvf.com/CVPR2018.py";
getContent(url);
}
}
代码组织和内部实现设计
类设计和程序框架如图

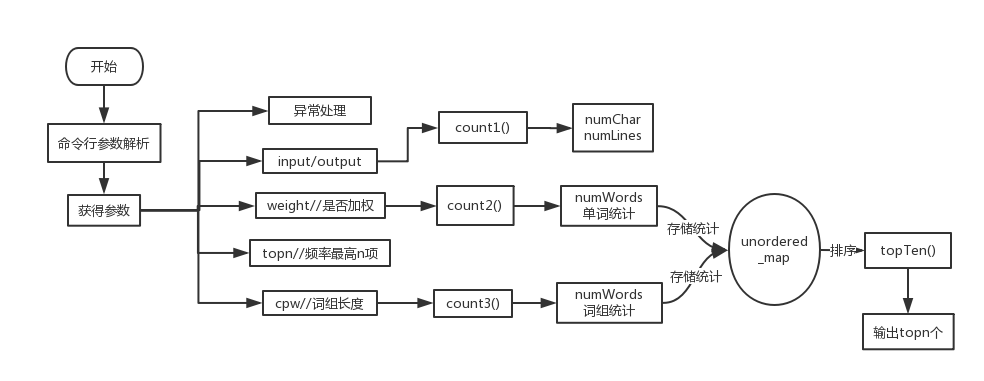
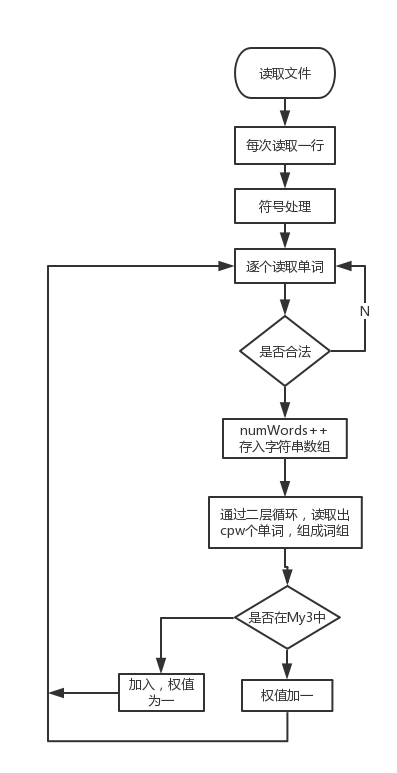
算法关键及流程图
最主要的三个函数
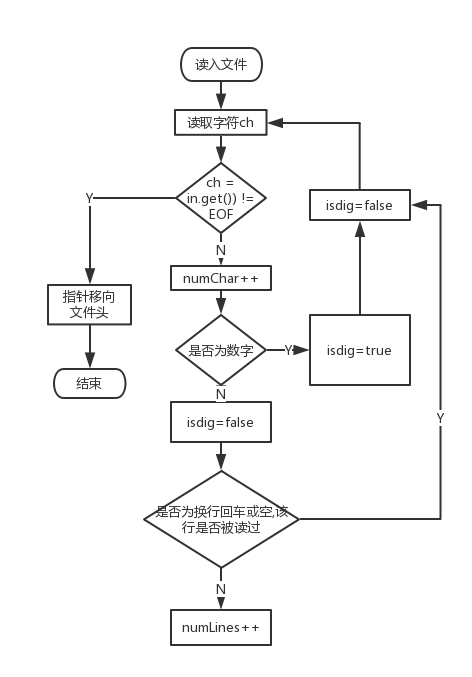
- count1()——字符数和行数统计
大致思路和作业一相同,略微做一些调整
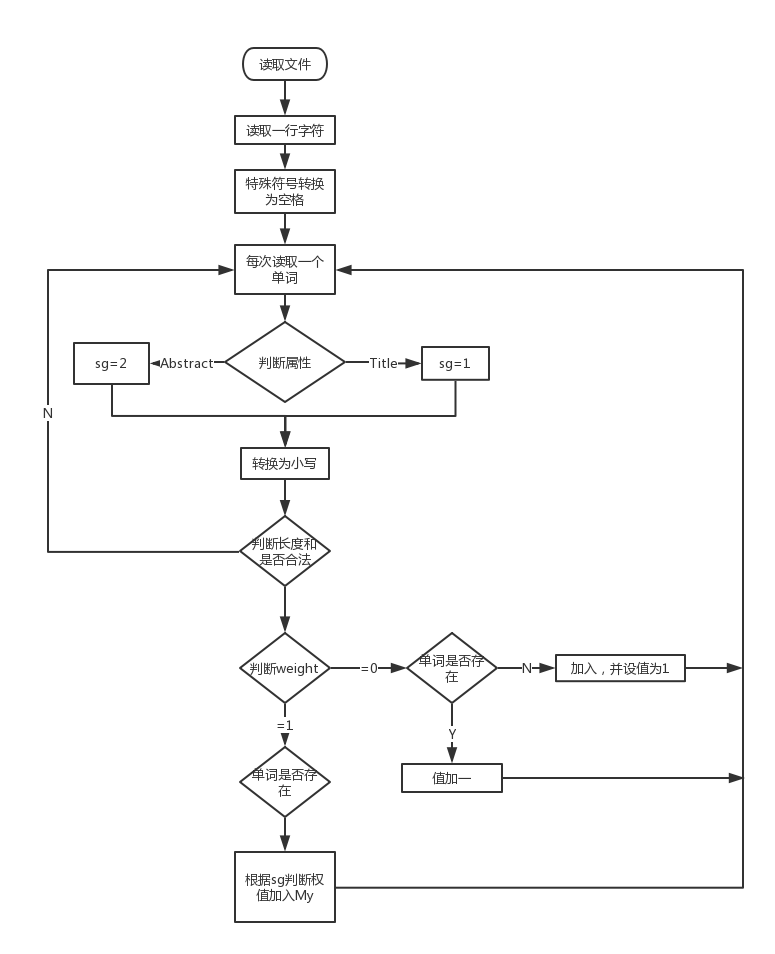
- count2()——带权值的词频统计
增加了权值判断部分,标记sg用来标记当前单词所属哪一度分
- count3()——词组频率统计
思路:逐行读取,将每个单词分开存储到字符串数组中,然后按照所需长度将其取出,合并成词组,再进行统计。
附加题设计与展示
- 在改进了Java代码之后,增加了对作者和PDF下载链接的爬取,结果展示如下,详见GitHub result2.txt

- 为了直观的看到CVPR论文热点词汇,利用Python生成了热点词汇词云,结果展示如下


- 代码如下:
import wordcloud
from scipy.misc import imread
f = open("test.txt","r",encoding="utf-8")
mask = imread("D:\PCcode\羊.jpg")
t = f.read()
f.close()
w = wordcloud.WordCloud(width = 1000, height = 700 , background_color= "white",stopwords={"based","human","using","well","given","ale",\
"work","loss","the","for","in","of","with","by","in","and","to","on","are","from","as","is","which","we","that","this","two","it","one","can",\
"both","an","these","be","all","or","over","make" ,"such","while","use","also" },mask= mask)
w.generate(t)
w.to_file("cvprwordcloud5.png")
关键代码解释
- 自定义参数部分代码:通过赋值,形成类似开关的功能,将参数传入函数,调用需要的功能。
for (i = 0; i < nt; i++)
{
if ((**(argv + i)) == '-')
{
switch (*(*(argv + i) + 1))
{
case 'i':
in.open(argv[i + 1]);
break;
case 'o':
out.open(argv[i + 1]);
break;
case 'w':
if (argv[i + 1] == "1")
weight = 1;
else
weight = 0;
break;
case 'n':
sscanf_s(argv[i + 1], "%d", &topn);
break;
case 'm':
sscanf_s(argv[i + 1], "%d", &cpw);
break;
}
}
}
- 权重判断部分:设置sg,当读到Title时为1,说明这时读到的单词都是属于Title中的,当读到Abstract时为2,说明这以后读到的单词都是摘要里的。
if (stemp == "Title")
{
sg = 1;
}
if (stemp == "Abstract")
{
sg = 2;
}
// 只展示出部分代码
if (sg == 1)
{
My.insert(unordered_map<string, int>::value_type(stemp, 10));
}
if (sg == 2)
{
My.insert(unordered_map<string, int>::value_type(stemp, 1));
}
- 自定义词组长度统计:这一部分因为没有想到更好的办法了就只能暴力了。思路是逐行读取文本,将每个单词分开存储到字符串数组中,然后按照自定义词组长度将其取出,合并成词组,再进行统计。
while (ss >> stemp)
{
strarr[strnum] = stemp;//将每一行的单词逐个存入字符串数组中
strnum++;
}
for (int i = 0; i < strnum - cpw + 1; i++) //遍历strarr,每cpw个单词合并
{
cpwtp = "";
for (int j = 0; j < cpw; j++)
{
cpwtp += strarr[i + j];
if (j != cpw - 1)
cpwtp += ' ';
}
unordered_map<string, int>::iterator it = My3.find(cpwtp);
if (it == My3.end())
{
My3.insert(unordered_map<string, int>::value_type(cpwtp, 1));
}
else
{
My3[cpwtp]++;
}
for (int z = 0; z < 10000; z++)
strarr[z].clear();//清空
}
性能分析和改进
改进思路
- 在整个文本处理过程,最消费时间的就是单词或数组的存入和查询了。对于这一点,采用unordered_map容器进行存储。虽然空间复杂度大,但是时间复杂度低,当对大文本进行处理时,能节省更多的时间
- 对于词组统计方面,因为才用了二重循环,如果一次读入的单词量太多的话也会消耗大量的时间。这一点就有待改进了。
展示性能分析图和程序中消耗最大的函数
有权重统计时,排序功能函数占了最主要的性能

在进行词组统计时,毫无疑问词组的划分和统计占用了绝对的资源

单元测试
- 在单元测试时,没有在代码编程时就介入编写单元测试用例,导致了函数与单元测试的分离,单元测试编写时有一定困难。
- 编写了十个用例,分别测试了- w参数权重测试,- n 参数 自定义输出测试,- m 词组测试,字数测试,词数测试,行数测试,空白文档测试
- 部分代码:
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(LineCounttest1)
{
char f[] = "C://Users//Administrator//source//repos//wordcount//Debug//input.txt";
ifstream in;
in.open(f);
WordCount wfc;
wfc.count1(in);
Assert::IsTrue(wfc.numLines == 12);
}
TEST_METHOD(CharCounttest1)
{
char f[] = "C://Users//Administrator//source//repos//wordcount//Debug//input.txt";
ifstream in;
in.open(f);
WordCount wfc;
wfc.count1(in);
Assert::IsTrue(wfc.numChar == 2977);
}
TEST_METHOD(WordCounttest1)
{
char f[] = "C://Users//Administrator//source//repos//wordcount//Debug//input.txt";
ifstream in;
int w = 0;
in.open(f);
WordCount wfc;
wfc.count1(in);
Assert::IsTrue(wfc.numWords == 281);
}
- 截图
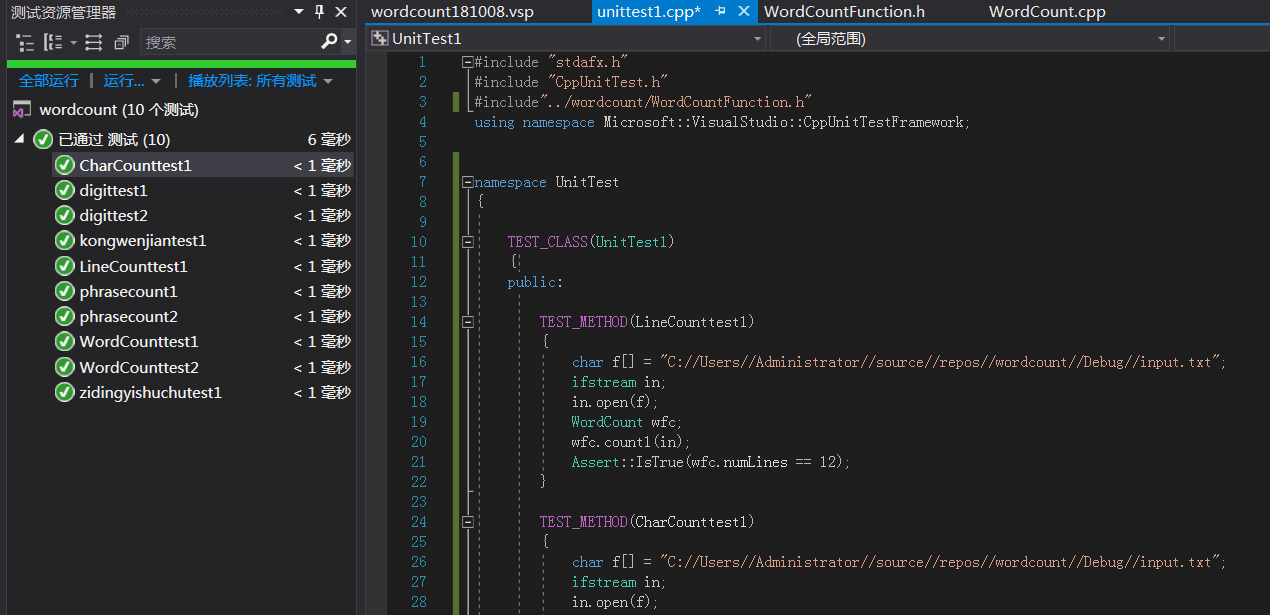
GitHub的代签入记录

遇到的代码模块异常或结对困难及解决办法
问题描述
因为我是主要负责打所有的功能代码的,对于代码上的bug只能慢慢排查。因为思路比较明确,所以没有碰到那种一卡就没法解决的问题。且使用的函数基本上之前都有用过,所以没出现什么大问题。但是要重新写函数和类的接口,因为之前写的不满足要求,所以做了个大调整。但是在性能分析测试上,因为采用命令行测试,每次测试就出现异常处理的“argv=1”,最后是把功能模块拎出来测试解决的。结对配合上可以说是非常愉快了!互相按时按量完成任务,真的是贼靠谱了。
尝试和结果
尝试方面我这里本来想对词组划分统计进行优化的,结果也没找到好的方法。词频排序还是采用unordered_map容器,时间复杂度低。尝试的话晓宏那边爬虫需要学习的蛮多的。
收获
因为我是主要负责编所有的功能代码,并负责改产生的bug的,所以压力还是有一丢丢的的。权重和自定义参数还比较容易实现,但是词组统计真的费劲脑汁,查了很多资料也没找到有相似问题的解决方法,最后只能硬着头皮,采用最直接但是有效的办法,最后运行成功。程序的功能越多,越需要清晰的思路,越发觉得思维导图的必要。
评价队友
晓宏真的是很靠谱了,默默完成了工作,做事很认真,遇到问题会及时反馈不拖延进度。我们的分工分为两部分,尽量不让之间有重合的部分。我把写好的代码经过简单测试后交给晓宏,由他进行接下来的测试和分析。我觉得我们的配合还是很友好的,没有人偷懒,都尽力把这个项目做好。需改进的地方尚未发现。
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 200 | 200 | 5 | 5 | 巩固C++,了解单元测试和异常分析 |
| 2 | 100 | 300 | 5 | 10 | 学习主函数参数,文件流读取 |
| 3 | 0 | 300 | 3 | 13 | 学习《构建之法》和原型设计,process on制图 |
| 4 | 0 | 300 | 3 | 16 | 深入学习命令行测试,学习数据结构 |
| 5 | 350 | 650 | 10 | 26 | 改bug技能up,深入了解C++和调试技术 |

