
第二次作业-个人项目
对代码的改进地址:https://www.cnblogs.com/031602401chl/p/9665968.html
Github项目地址:(https://github.com/AsianLazyMan/personal-project/tree/master/Cplusplus)
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 80 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 50 |
| Development | 开发 | 300 | 450 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 120 |
| · Design Spec | · 生成设计文档 | 20 | 45 |
| · Design Review | · 设计复审 | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| · Design | · 具体设计 | 60 | 35 |
| · Coding | · 具体编码 | 180 | 240 |
| · Code Review | · 代码复审 | 60 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 300 |
| Reporting | 报告 | 60 | 45 |
| · Test Repor | · 测试报告 | 60 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 30 |
| | 合计 |1050 |1560
***需求分析***
===========
程序所要求的功能有以下几点:
-
统计文件的字符数(不需要考虑汉字需要考虑空格制表符换行符)。
-
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
-
统计文件的有效行数:任何包含非空白字符的行,都需要统计。
-
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
-
按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
-
输出的格式为
characters: number
words: number
lines: number
<word1>: number
<word2>: number
...
***思路***
===========
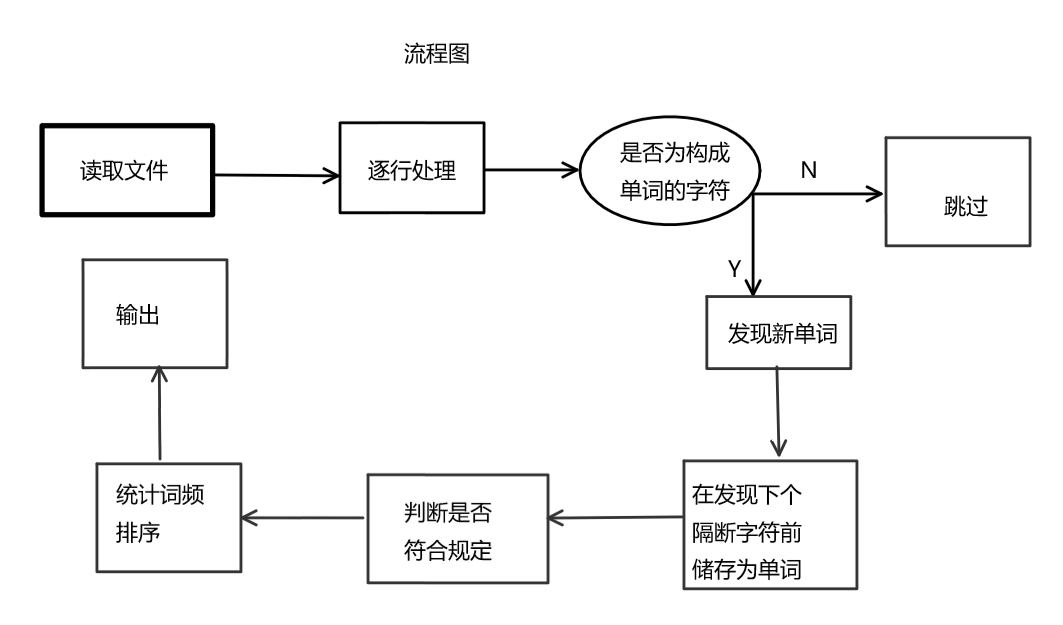
看到题目后第一想到的就是怎么在程序中读取文件。因为没学过,就去网上找了资料。使用fstream读取txt文件。然后使用getline()函数来读取文件中的每一行。并在函数中对每一行的字符进行操作。然后使用lower()函数把全部字母都变小写。首先先得到每一行的字数,使用temp.size()+1来表示每行的字数.加一是因为行末还有一个回车字符。行数即为每次使用getline时对linenum加1.对行中每一个字符进行遍历。当遇到非单词中的字符时continue。当遇到英文字母或者数字时即为发现新单词。进入对新单词的判断,当所遇到的字符不是空格、句号、逗号等符号时,将字符储存起来,当遇到空格、句号、逗号等符号时,停止储存,并将最后一个字符的后一个字符设为‘\0’.如a[k++]=‘\0’。将单词分割出来后,使用judge()函数判断是否为符合要求的单词。如是拷贝进word2[]中。在储存完所有单词后,检测各个单词的频率。最后进行排序。
- lower()函数
void lower(string& str) {//大写转化成小写
for (int j = 0; j < str.size(); j++)
{
if (str[j] <= 'Z'&&str[j] >= 'A') {
str[j] = str[j] + 32;
}
}
}
- 将单词按要求分开
for (int y = 0; y < temp.size(); ) {
if (p[y] == ' ' || p[y] == '.' || p[y] == '?' || p[y] == '!' || p[y] == ',' || p[y] == '"')
{
y++;
continue;
}
else {//发现一个单词
char *danci = (char*)malloc(sizeof(char)*10);
memset(danci, 0, sizeof(char) * 10);
int k = 0;
while ((p[y] >= 'a'&&p[y] <= 'z') || (p[y] >= '0'&&p[y] <= '9')) {
danci[k] = p[y];
k++; y++;
}
danci[k] = '\0';//终止符号 很重要
//cout << danci << "*"<<endl;
if (Judge(danci)) {
word2[m].s = danci;
word2[m].num = 0;
/*if (word2[m].s) {
cout << word2[m].s << endl;
}*/
m++;
}
}
输入输出
输入:
aaaa SSSSSS AAAA,SHENZHEN.
KKKKK KK AAAA aaaa?SHENZHEN.
XXXX XXXX XXXX XXXX XXXX!SHENZHEN,SHENZHEN.
"sdsdas" gaomima
输出:
characters:117
words:17
lines:4
word1:xxxx times:5
word2:aaaa times:4
word3:shenzhen times:4
word4:ssssss times:1
word5:kkkkk times:1
word6:sdsdas times:1
word7:gaomima times:1
计算模块接口的设计与实现过程
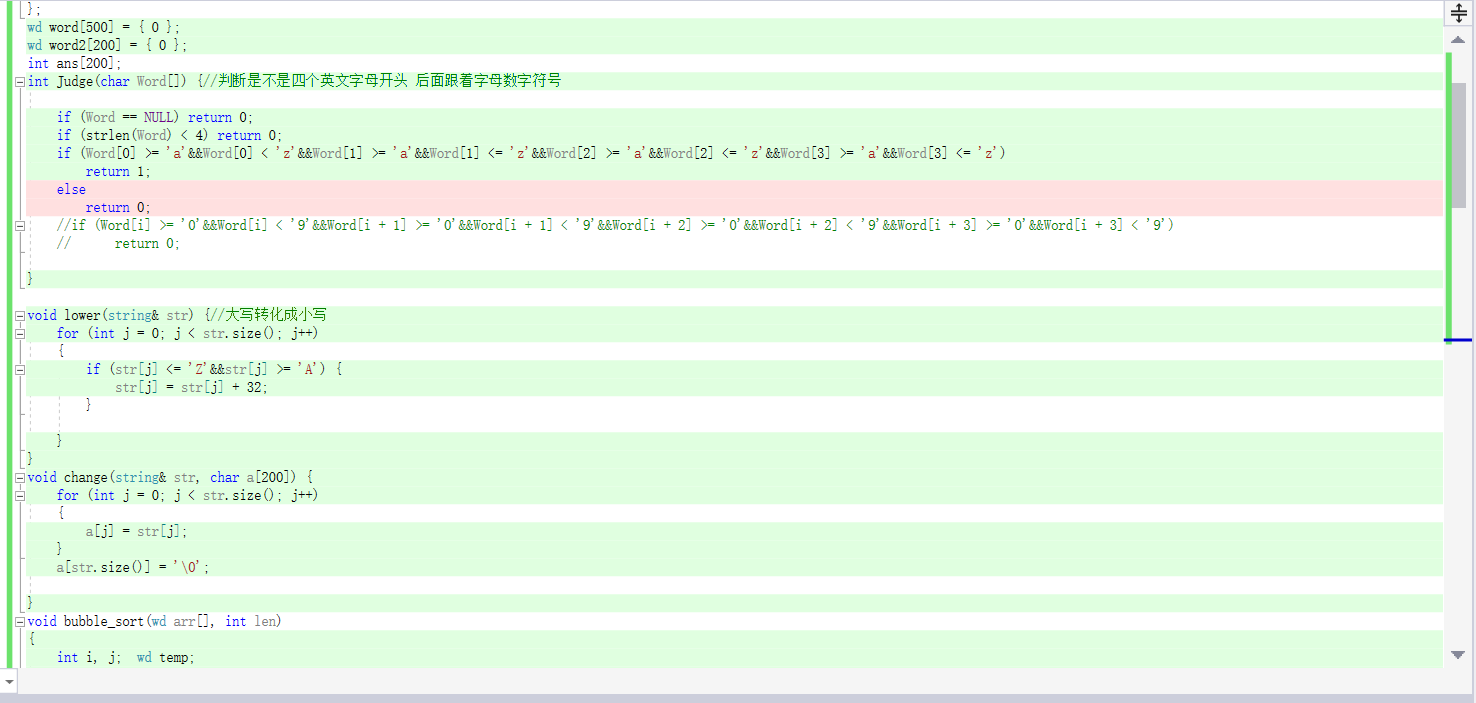
一共有四个函数分别是大写转化成小写的函数lower(),判断单词是否符合标准的函数judge(),将string转化成char的函数change(),冒泡排序的函数bubble_sort()。
这其中两个函数需要说明。
一是judge()函数。首先判断单词长度是否大于四,而后判断是否是至少四个英文字母开头。
而是转换函数change(),在进行转换后一定要将最后一个字符的后一个字符设定问‘\0’。否则会出现后面计算无法识别单词的情况。
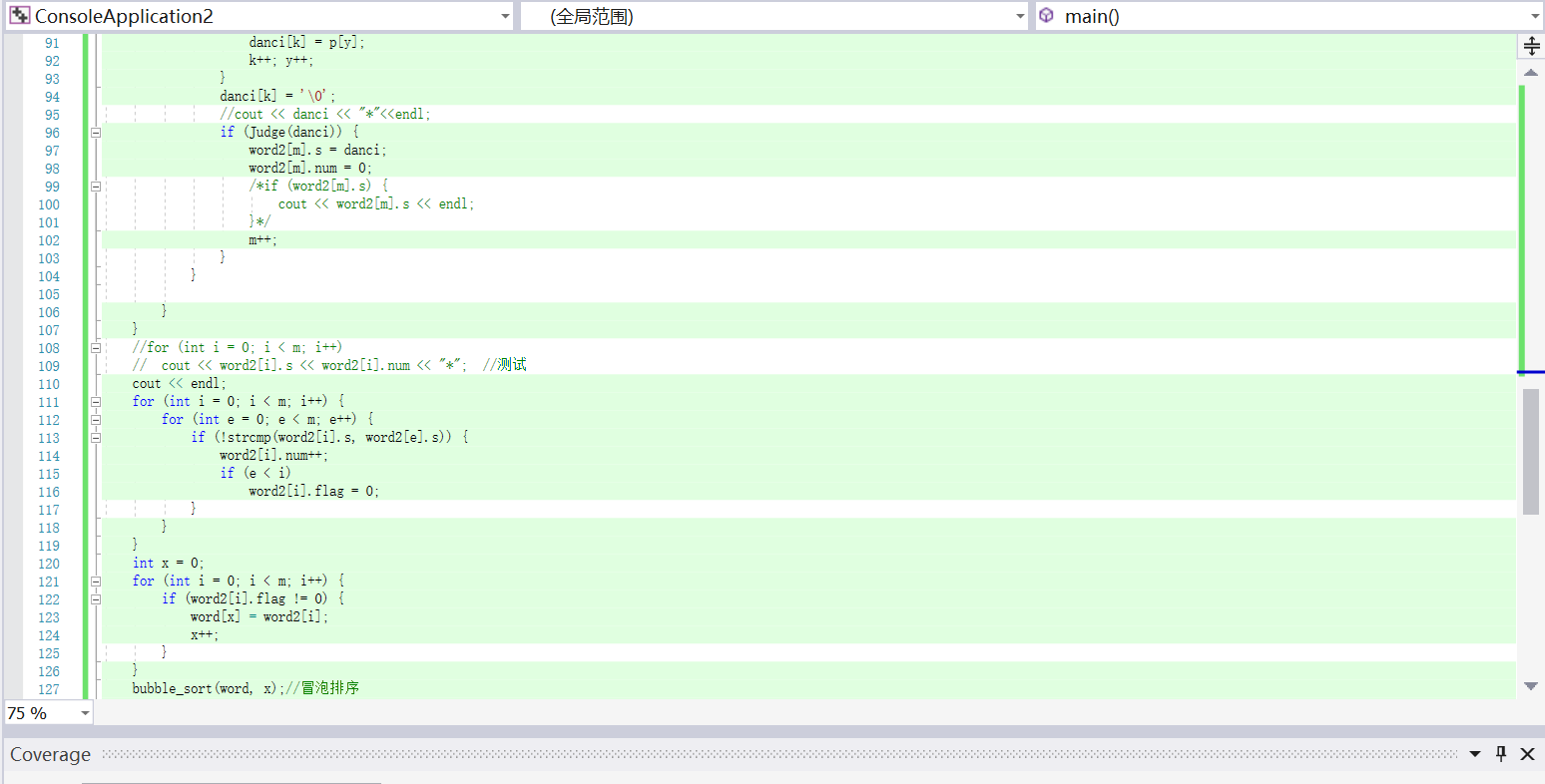
程序的关键是对单词的分割。
当遇到字母或数字是才确定为是一个单词(后面会再用judge()函数判断是否符合标准)。然后继续往后遍历,遇到规定的分隔字符后停止,并将所得到的单词存入word2中,进行后续操作。这样做比较具有可靠性。
计算模块接口部分的性能
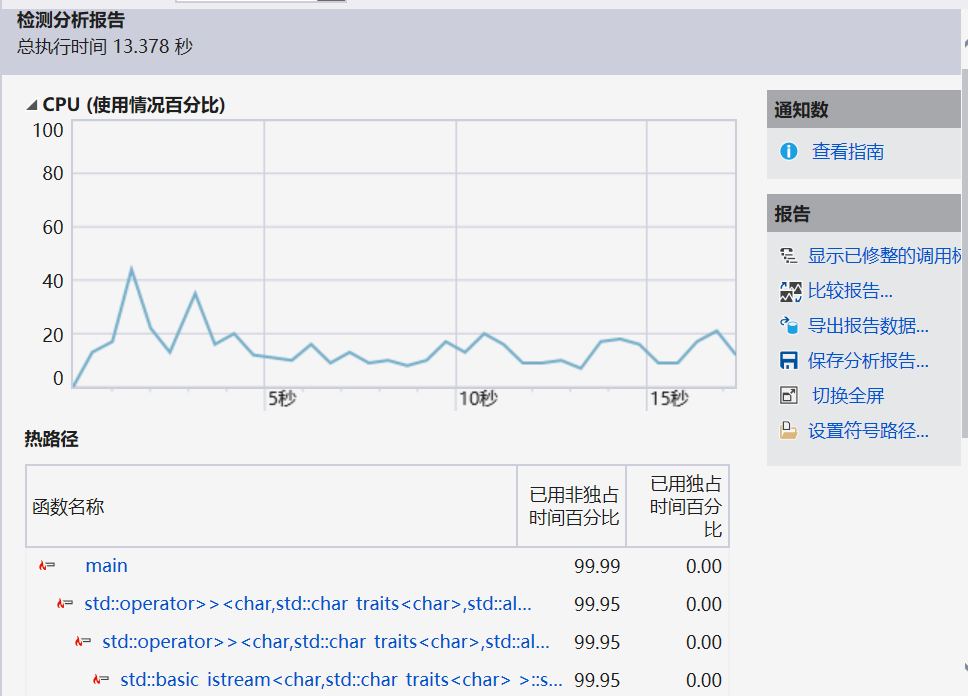
计算模块部分单元测试展示

异常处理
if (argv[1] == NULL) {
cout << "No input";
}
fstream file(argv[1]);
if (!file) {
printf("Unable to open");
}
总结与感想
处理字符是我平常比较不熟悉的部分,所以这次完成程序花了比较多的时间。比如忘记在字符后加上‘\0’终止符。这花了我非常多时间去找错误。但是也是有了这些错误,才让我对字符方面的编码更加熟悉。收获无疑是很大的。解决错误会给自己带来很多收获。
这次除了学习读取文件的功能有去查找资料外,其他都是自己一点点试出来,感觉比一不懂就去找资料充实得多。

