06 Spark SQL 及其DataFrame的基本操作
Spark SQL DataFrame的基本操作
文件路径:
file='url'
文本:

json:

创建:
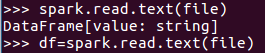
spark.read.text(file)
spark.read.json(file)

打印数据
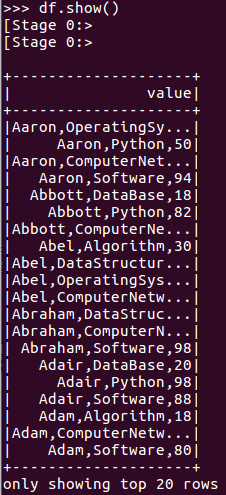
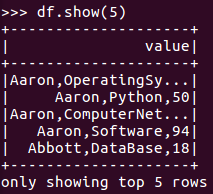
df.show()默认打印前20条数据,df.show(n)
文本:
json:

打印概要
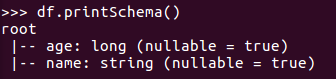
df.printSchema()
文本:

json:
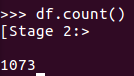
查询总行数
df.count()
df.head(3) #list类型,list中每个元素是Row类
文本:

json:

输出全部行
df.collect() #list类型,list中每个元素是Row类(文本与json数据差异与上df.head()同)

查询概况
df.describe().show()
文本:
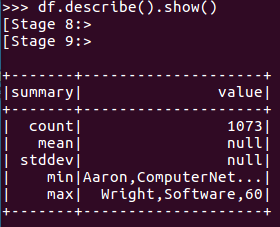
json:
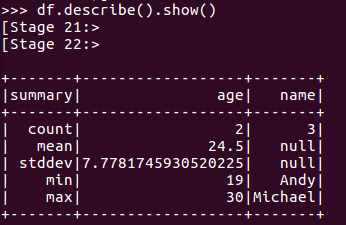
取列(仅json文件可使用以下命令)
df['name']
df.name

df.select()


df.filter()


df.groupBy()

df.sort()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号