作业2
一、了解对比Hadoop不同版本的特性,可以用图表的形式呈现。
答:Apache Hadoop版本分为两代,第一代Hadoop称为Hadoop1.0,第二代Hadoop称为Hadoop2.0。第一代Hadoop包含0.20.x、0.21.x、0.22.x三大版本,其中,0.20.x最后演化成1.0.x,变成了稳定版。而0.21.x和0.22.x则增加了HDFS HA等重要的新特性。第二代Hadoop包含0.23.x和2.x两大版本。他们完全不同于Hadoop1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统。
Hadoop 2.4.0版本于2014年4月7日发布,相比于hadoop 2.3.0,有了很多重大改进,主要包括:
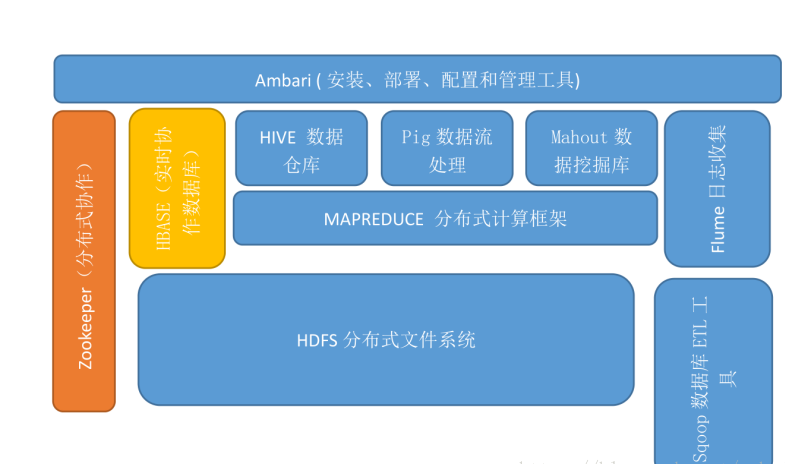
二、Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
答:Hadoop的核心组件是HDFS、MapReduce。随着处理任务不同,各种组件相继出现,丰富Hadoop生态圈,目前生态圈结构大致如图所示:
三、官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
答:
下载Hadoop安装包————www.hadoop.org
解压Hadoop安装包
首先先要配置好java环境变量 Java_HOME要确认好jdk的路径。
配置好Java环境变量后开始配置hadoop核心配置文件
1.打开 hadoop-2.7.3/etc/hadoop/core-site.xml,添加一下内容到末尾。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2.打开 hadoop-2.7.3/etc/hadoop/mapred-site.xml,添加一下内容到末尾。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.打开 hadoop-2.7.3/etc/hadoop/hdfs-site.xml,添加一下内容到末尾。
先创建两个文件夹
E:/hadoop-2.7.3/namenode
E:/hadoop-2.7.3/datanode
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/E:/hadoop-2.7.3/namenode</value>//路径为你的存放路径
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/E:/hadoop-2.7.3/datanode</value>//路径为你的存放路径
</property>
</configuration>
4.打开 hadoop-2.7.3/etc/hadoop/yarn-site.xml,添加一下内容到末尾。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
最后WIN+R 输入cmd 到Hadoop-2.7.3\bin下,输入hdfs namenode -format执行到格式化之后,namenode文件里会自动生成一个current文件,则格式化成功。
然后转到Hadoop-2.7.3\sbin下,输入start-all.cmd,启动hadoop服务,等待他启动完成。
完成之后,输入jps可以查看运行的所有服务 (前提是java路径设置正确)
这样hadoop(windows环境下)就启动完成了
四、评估华为hadoop发行版本的特点与可用性。
华为hadoop发行版:华为的hadoop版本基于自研的Hadoop HA平台,构建NameNode、JobTracker、HiveServer的HA功能,进程故障后系统自动Failover,无需人工干预,这个也是对hadoop的小修补,远不如mapR解决的彻底。

答:华为的hadoop版本基于自研的Hadoop HA平台,构建NameNode、JobTracker、HiveServer的HA功能,进程故障后系统自动Failover,无需人工干预,这个也是对hadoop的小修补,远不如mapR解决的彻底。
华为fusionInsight有以下特点:
安全
- 架构安全
FusionInsight HD基于开源组件实现功能增强,保持100%的开放性,不使用私有架构和组件。
- 认证安全
- 基于用户和角色的认证统一体系,遵从帐户/角色RBAC(Role-Based Access Control)模型,实现通过角色进行权限管理,对用户进行批量授权管理。
- 支持安全协议Kerberos,FusionInsight HD使用LDAP作为帐户管理系统,并通过Kerberos对帐户信息进行安全认证。
- 提供单点登录,统一了Manager系统用户和组件用户的管理及认证。
- 对登录FusionInsight Manager的用户进行审计。
- 文件系统层加密
Hive、HBase可以对表、字段加密,集群内部用户信息禁止明文存储。
- 加密灵活:加密算法插件化,可进行扩充,亦可自行开发。非敏感数据可不加密,不影响性能(加密约有5%性能开销)。
- 业务透明:上层业务只需指定敏感数据(Hive表级、HBase列族级加密),加解密过程业务完全不感知。
可靠
- 所有管理节点组件均实现HA(High Availability)
业界第一个实现所有组件HA的产品,确保数据的可靠性、一致性。NameNode、Hive Server、HMaster、Resources Manager等管理节点均实现HA。
- 集群异地灾备
业界第一个支持超过1000公里异地容灾的大数据平台,为日志详单类存储提供了迄今为止可靠性最佳实践。
- 数据备份恢复
表级别全量备份、增量备份,数据恢复(对本地存储的业务数据进行完整性校验,在发现数据遭破坏或丢失时进行自恢复)。
易用
- 统一运维管理
Manager作为FusionInsight HD的运维管理系统,提供界面化的统一安装、告警、监控和集群管理。
- 易集成
提供北向接口,实现与企业现有网管系统集成;当前支持Syslog接口,接口消息可通过配置适配现有系统;整个集群采用统一的集中管理,未来北向接口可根据需求灵活扩展。
- 易开发
提供自动化的二次开发助手和开发样例,帮助软件开发人员快速上手。
对于新手学习还是可以快速上手的一个hadoop平台。

