
海量数据与布隆过滤
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
方案1:可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999)中。这样每个小文件的大约为300M。
遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,...,b999)。这样处理后,所有可能相同的url都在对应的小文件(a0vsb0,a1vsb1,...,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2:如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
Bloom Filter是一种空间效率很高的随机数据结构,它的原理是,当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个位阵列(Bit array)中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检索元素一定不在;如果都是1,则被检索元素很可能在。这就是布隆过滤器的基本思想。
但Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

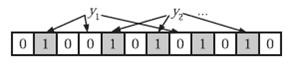
为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位,即第二个“1“处)。

在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素(因为y1有一处指向了“0”位)。y2或者属于这个集合,或者刚好是一个false positive。
基本原理及要点
扩展
问题实例
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考参考文献1。该文献证明了对于给定的m、n,当 k = ln(2)* m/n 时出错的概率是最小的。
同时该文献还给出特定的k,m,n的出错概率。例如:根据参考文献1,哈希函数个数k取10,位数组大小m设为字符串个数n的20倍时,false positive发生的概率是0.0000889 ,这个概率基本能满足网络爬虫的需求了。
[1]Pei Cao. Bloom Filters - the math.
http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html
import java.util.BitSet; public class BloomFilter { private static final int DEFAULT_SIZE = 2 << 24;//布隆过滤器的比特长度 private static final int[] seeds = {3,5,7, 11, 13, 31, 37, 61};//这里要选取质数,能很好的降低错误率 private static BitSet bits = new BitSet(DEFAULT_SIZE); private static SimpleHash[] func = new SimpleHash[seeds.length]; public static void addValue(String value) { for(SimpleHash f : func)//将字符串value哈希为8个或多个整数,然后在这些整数的bit上变为1 bits.set(f.hash(value),true); } public static void add(String value) { if(value != null) addValue(value); } public static boolean contains(String value) { if(value == null) return false; boolean ret = true; for(SimpleHash f : func)//这里其实没必要全部跑完,只要一次ret==false那么就不包含这个字符串 ret = ret && bits.get(f.hash(value)); return ret; } public static void main(String[] args) { String value = "xkeyideal@gmail.com"; for (int i = 0; i < seeds.length; i++) { func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]); } add(value); System.out.println(contains(value)); } } class SimpleHash { private int cap; private int seed; public SimpleHash(int cap, int seed) { this.cap = cap; this.seed = seed; } public int hash(String value) {//字符串哈希,选取好的哈希函数很重要 int result = 0; int len = value.length(); for (int i = 0; i < len; i++) { result = seed * result + value.charAt(i); } return (cap - 1) & result; } }

