
适用于大数据的开源OLAP系统的比较:ClickHouse,Druid和Pinot
在这篇文章中,我想比较ClickHouse,Druid和Pinot,这三个开源数据存储区,他们通过交互延迟对大量数据运行分析查询。
警告:这篇文章很大,您可能只想阅读最后的“摘要”部分。
信息来源
我从核心开发人员之一Alexey Zatelepin那里了解了ClickHouse的实现细节。用英语提供的最好的材料是本文档页面的最后四个部分,但是非常稀缺。
我是Druid的提交者,但是我对这个系统没有既得利益(实际上,我可能很快就会停止参与它的开发),因此读者可以期望我对Druid相当客观。
我在这篇关于Pinot的文章中写的所有内容都是基于Pinot Wiki中的Architecture页面以及“ Design Docs”部分中的其他Wiki页面,这些页面的最新更新于2017年6月,已经有半年多了。
这篇文章被很多人审阅,包括Alexey Zatelepin和Vitaliy Lyudvichenko(ClickHouse的开发人员),Gian Merlino(PMC成员和Druid的最活跃开发人员),Kishore Gopalakrishna(黑皮诺的建筑师)和Jean-FrançoisIm(黑皮诺的开发人员)。感谢审稿人。
系统之间的相似性
耦合数据和计算
从根本上讲,ClickHouse,Druid和Pinot都是相似的,因为它们在同一节点上存储数据并进行查询处理,这与去耦BigQuery体系结构不同。最近,我以Druid为例描述了一些固有的问题与耦合结构1,2)。目前没有与BigQuery等效的开源软件(也许是Drill吗?),我已经在本博文中探讨了构建此类开源系统的方法。
与大数据SQL系统的区别:索引和静态数据分发
特有系统的查询运行速度比Hadoop-SQL系列Hive,Impala,Presto和Spark中的大数据处理系统要快,即使后者访问以列格式存储的数据(例如Parquet或Kudu)。这是因为ClickHouse,Druid和Pinot:
- 具有自己的格式来存储带索引的数据,并与查询处理引擎紧密集成。Hadoop上的SQL系统通常与数据格式无关,因此在大数据后端的“侵入性”较小。
- 在节点之间相对“静态”地分配数据,并且分布式查询执行利用了这一知识。另一方面,ClickHouse,Druid和Pinot不支持要求在节点之间移动大量数据的查询,例如,两个大型表之间的联接。
没有点更新和删除
从数据库的另一端来看,与诸如Kudu,InfluxDB和Vertica(?)之类的列式系统相反,ClickHouse,Druid和Pinot不支持点更新和删除。这使ClickHouse,Druid和Pinot能够进行更有效的列压缩和更积极的索引,这意味着更高的资源效率和更快的查询。
Yandex的ClickHouse开发人员的目标是将来支持更新和删除,但是我不确定这是否是真正的点查询或数据范围的更新和删除。
大数据样式提取
所有ClickHouse,Druid和Pinot都支持从Kafka接收流数据。Druid和Pinot支持Lambda样式的流传输和同一数据的批量提取。ClickHouse直接支持批处理插入,因此不需要像Druid和Pinot那样的单独的批处理摄取系统。这篇文章下面将对此进行更详细的讨论。
大规模验证
这三个系统都得到了大规模验证:在Yandex.Metrica上有一个ClickHouse集群,大约有上万个CPU内核。Metamarkets运行着一个类似规模的Druid集群。LinkedIn上的一个Pinot 集群拥有“ 数千台机器 ”。
不成熟
按照企业数据库标准,所有特有系统都非常不成熟。(但是,可能不比一般的开源大数据系统还不成熟,但这是另一回事。)ClickHouse,Druid和Pinot到处都缺乏明显的优化和功能,并且到处都是bug(这里我不能百分百确定)关于ClickHouse和Pinot,但没有理由认为它们比Druid更好。
这将我们带入下一个重要部分
性能比较与系统选择
我经常在网上看到人们如何比较和选择大数据系统-他们获取数据样本,以某种方式将其摄入到评估的系统中,然后立即尝试衡量效率-它占用了多少内存或磁盘空间,在不了解所评估系统内部的情况下,查询完成的速度如何。然后,只用这样的性能信息,有时也考虑系统功能列表,他们需要和目前拥有的系统进行比较,他们做出选择,或者更糟糕,决定从头写自己的“更好”的系统。
我认为这种方法是错误的,至少在开源大数据OLAP系统中是如此。设计通用的大数据OLAP系统,使其能够在大多数用例和功能(及其组合的强大功能!)中有效地工作,这个问题确实非常巨大-我估计这至少需要100个人年去建立这样的系统。
ClickHouse,Druid和Pinot当前仅针对开发人员关心的特定用例进行了优化,并且几乎仅具有开发人员所需的功能。如果您要部署其中一个系统的大型集群并关心效率,那么我保证您的用例将遇到其独特的瓶颈,特定OLAP系统的开发人员以前从未遇到过或没有遇到过不在乎。更不用说上述方法“将数据投入您所不了解的系统并衡量效率”很有可能会遇到一些主要瓶颈,而这些瓶颈可以通过更改某些配置或数据模式或以其他方式进行查询来解决。
CloudFlare: ClickHouse与Druid
一个说明上述问题的示例是MarekVavruša的帖子,内容涉及Cloudflare在ClickHouse和Druid之间的选择。他们需要4个ClickHouse服务器(超过了9个),并估计类似的Druid部署将需要“数百个节点”。尽管Marek承认这是不公平的比较,但由于Druid缺乏“主键排序”,他可能没有意识到仅通过在“摄取规范”中设置正确的维度顺序和简单的数据准备就可以在Druid中获得几乎相同的效果:截断Druid的__time如果某些查询需要更精细的时间范围,则将列值设置为一些粗粒度(例如一个小时),并可选地添加另一个长型列“ precise_time”。这是一个hack,但是允许Druid之前实际上按某种维度对数据进行排序__time也将很容易实现。
我不质疑他们选择ClickHouse的最终决定,因为在大约10个节点的规模上,并且对于他们的用例,我还认为ClickHouse比Druid更好的选择(我将在本文下面进行解释)。但是他们得出的结论是,ClickHouse的效率(在基础设施成本方面)至少比Druid高出一个数量级,这完全是谬论。实际上,在这里讨论的三个系统中,Druid提供了最多的功能来实现真正方便的安装,请参阅下面的“在Druid中分层查询处理节点”。
在选择大数据OLAP系统时,请勿比较它们当前对于您的用例的最佳程度。目前,它们都非常次优。比较您的组织可以使这些系统朝着使您的用例更优化的方向移动的速度。
由于其基本的架构相似性,ClickHouse,Druid和Pinot在效率和性能优化上具有大约相同的“极限”。没有“魔术药”可以使这些系统中的任何一个都比其他系统快得多。在当前状态下,这些系统在某些基准测试中的性能有很大不同,这一事实并不会让您感到困惑。例如 当前,Druid与ClickHouse不同(参见上文),它不很好地支持“主键排序”,而ClickHouse与Druid不同,它不支持反向索引,这使这些系统在特定工作负载方面处于优势。如果您有意愿和能力,则可以在选定的系统中实施缺少的优化,而无需花费很多精力。
- 您的组织中的任何一个工程师都应该具有能够阅读,理解和修改所选系统的源代码。请注意,ClickHouse用C ++,Druid和Pinot用Java编写。
- 或者,您的组织应与提供所选系统支持的公司签订合同。有Altinity为ClickHouse,Imply和Hortonworks为Druid,目前没有针对Pinot的此类公司。
其他开发注意事项:
- Yandex的ClickHouse开发人员表示,他们将50%的时间用于构建公司内部所需的功能,而50%的时间用于“社区投票”次数最多的功能。但是,要从中受益,您在ClickHouse中所需的功能应与社区中大多数其他人所需的功能匹配。
- Imply的Druid开发人员具有建立广泛适用的功能的动机,以最大程度地发展他们的未来业务。
- Druid的开发过程与Apache模型非常相似,多年来,它是由多家公司开发的,这些公司的优先级大相径庭,并且在任何一家公司中都不占主导地位。ClickHouse和Pinot目前距离这种状态还很遥远,它们分别是分别由Yandex和LinkedIn开发的。对Druid的贡献以后被拒绝或撤销的可能性最小,因为它们与主要开发者的目标不一致。Druid没有“主要”开发商公司。
- Druid承诺支持“开发人员API”,该API允许提供自定义列类型,聚合算法,“深度存储”选项等,并使它们与核心Druid的代码库分开。Druid开发人员记录了此API,并跟踪其与先前版本的兼容性。但是,该API尚未成熟,并且在每个Druid版本中都几乎被破坏了。据我所知,ClickHouse和Pinot没有维护类似的API。
- 根据Github的说法,Pinot 从事这项工作的人最多,去年似乎至少有10个人年在Pinot 上进行类似工作。对于ClickHouse来说,这个数字可能是6;对于Druid,这个数字大约是7。这意味着从理论上讲,Pinot在主题系统中的进步最快。
Druid和Pinot的体系结构几乎完全相同,而ClickHouse则与它们略有不同。我将首先将ClickHouse的架构与“通用” Druid / Pinot架构进行比较,然后讨论Druid与Pinot之间的较小差异。
ClickHouse和Druid / Pinot之间的区别
数据管理:Druid 和Pinot
在Druid和Pinot中,每个“表”中的所有数据(无论这些系统用什么术语称呼)都被划分为指定数量的部分。按照时间维度,通常还会将数据除以指定的时间间隔。然后,将这些数据的各个部分分别“密封”到称为“段”的自包含实体中。每个段包括表元数据,压缩的列数据和索引。
段保留在“深度存储”(例如HDFS)中,可以加载到查询处理节点上,但是后者不负责段的持久性,因此可以相对自由地替换查询处理节点。段并非严格地附加到某些节点,它们可以或多或少地加载到任何节点上。一个特殊的专用服务器(在Druid中称为“协调器”,在Pinot中称为“控制器”,但在下面我将其统称为“主服务器”)负责将分段分配给节点,并在节点之间移动分段, 如果需要的话。(这与我在本文中上面指出的观点并不矛盾,因为包括Druid和Pinot在内的所有三个特有系统在节点之间都具有“静态”数据分布,这是因为Druid(Pinot一样),因为Druid(Pinot一样)中的段加载和移动是昂贵的操作,并且对于每个特定查询都没有完成,并且通常仅每隔几分钟,几小时或几天发生一次。
有关段的元数据在Druid中直接保存在zookeeper,在Pinot中的通过Helix框架保存在ZooKeeper 中。在Druid中,元数据也保留在SQL数据库中,在本文下面的“ Druid与Pinot之间的区别”部分中对此进行了详细说明。
数据管理:ClickHouse
ClickHouse没有“段”的概念,其中包含严格属于特定时间范围的数据。没有数据的“深度存储”,ClickHouse群集中的节点还负责查询处理以及存储在其上的数据的持久性。因此,不需要HDFS设置,也不需要像Amazon S3这样的或云数据存储。
ClickHouse具有分区表,由特定的节点集组成。没有“中央权限”或元数据服务器。在其中对某个表进行分区的所有节点都具有表元数据的完全相同的副本,包括存储该表分区的所有其他节点的地址。
分区表的元数据包括用于分发新写入的数据的节点的“权重”,例如40%的数据应流向节点A,30%的数据流向节点B,30%的数据流向节点C。通常应在节点之间的相等分布。如上例所示,只有在将新节点添加到分区表中时才需要“倾斜”,以便用某些数据更快地填充新节点。这些“权重”的更新应由ClickHouse群集管理员手动完成,或者应在ClickHouse之上构建一个自动化系统。
数据管理:比较
在ClickHouse中,数据管理方法比在Druid和Pinot中更简单:不需要“深度存储”,只需一种类型的节点,就不需要用于数据管理的专用服务器。但是,当任何数据表变得如此之大以至于需要在数十个或更多节点之间进行分区时,ClickHouse的方法就变得有些问题了:查询放大因子变得与分区因子一样大,即使对于查询而言,其覆盖数据范围很小:
Data distribution tradeoff in ClickHouse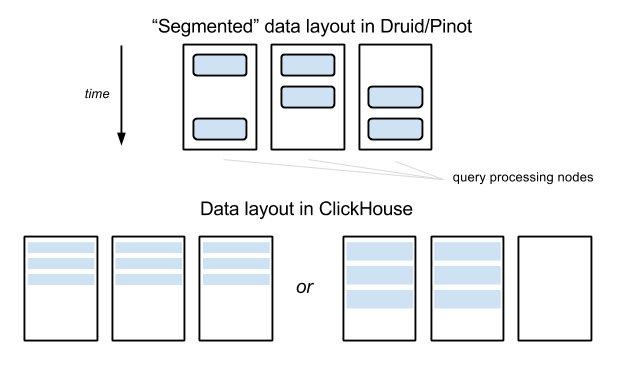
在上图中给出的示例中,表数据分布在Druid或Pinot中的三个节点之间,但是查询少量数据间隔通常只会命中两个节点(除非该间隔跨越了段间隔边界)。在ClickHouse中,如果表在三个节点之间进行分区,则任何查询都需要命中三个节点。在此示例中,这似乎并没有太大的区别,但是可以想象节点数为100,而在Druid或Pinot中,分配因子仍可以是10。
为了缓解此问题,实际上,Yandex上最大的ClickHouse群集(数百个节点)被分成许多“子群集”,每个群集包含几十个节点。该ClickHouse集群用于支持网站分析,并且每个数据点都有“网站ID”维度。每个网站ID都严格分配给特定的子集群,该网站ID的所有数据都存放在该子集群中。该ClickHouse群集之上有一些业务逻辑层,可在数据提取和查询方面管理此类数据分离。值得庆幸的是,在用例中,很少有查询可以跨多个网站ID来访问数据,而且此类查询并非来自服务客户,因此它们没有严格的实时SLA。
ClickHouse方法的另一个缺点是,当群集快速增长时,如果没有人工手动更改分区表中的“节点权重”,数据就不会自动重新平衡。
Druid中的查询处理节点分层
具有段的数据管理“很容易推理”。段可以相对容易地在节点之间移动。这两个因素帮助Druid实现了查询处理节点的“分层”:将旧数据自动移动到磁盘相对较大但内存和CPU较少的服务器上,从而可以显着降低运行大型Druid集群的成本,减慢对旧数据的查询。
与“扁平”集群相比,该功能可使Metamarkets每月节省数十万美元的Druid基础设施支出。
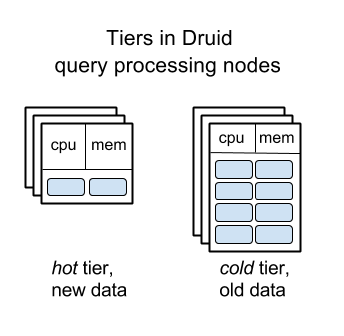
Tiering of query processing nodes in Druid
据我所知,ClickHouse和Pinot还没有类似的功能,它们群集中的所有节点都应该是相同的。
由于Pinot的体系结构与Druid的体系非常相似,因此我认为在Pinot中引入类似的功能并不难。在ClickHouse中执行此操作可能会比较困难,因为段的概念对于实现此类功能确实很有帮助,但是仍然可以实现。
数据复制:Druid和Pinot
Druid和Pinot的复制单位是单个段。段在“深层存储”层(例如,HDFS中的三个副本,或者在云blob存储(例如Amazon S3)中透明完成)和查询处理层中复制:通常在Druid和Pinot中,每个段在两个不同的节点上加载。如果复制因子低于指定的级别(例如,如果某个节点变得无响应),则“主”服务器将监视每个段的复制级别并在某个服务器上加载一个段。
数据复制: ClickHouse
ClickHouse中的复制单元是服务器上的表分区,即某个表中的所有数据都存储在服务器上。与分区类似,ClickHouse中的复制是“静态的和特定的”,而不是“云样式”,即,几台服务器知道它们是彼此的副本(对于某些特定表;对于不同的表,复制配置可能不同)。复制可提供持久性和查询可用性。当某个节点上的磁盘损坏时,数据也不会丢失,因为它也存储在其他节点上。当某个节点暂时关闭时,查询可以路由到副本。
在Yandex上最大的ClickHouse集群中,不同数据中心中有两组相等的节点,并且它们是成对的。在每对节点中,节点是彼此的副本(即,使用两个复制因子),并且位于不同的数据中心中。
ClickHouse依赖ZooKeeper进行复制管理,但是不需要ZooKeeper。这意味着单节点ClickHouse部署不需要ZooKeeper。
数据提取: Druid and Pinot
在Druid和Pinot中,查询处理节点专门用于加载段并向段中的数据提供查询,但不累积新数据并产生新段。
当可以延迟一小时或更长时间来更新表时,将使用批处理引擎(例如Hadoop或Spark)创建分段。Druid和Pinot都对Hadoop提供了“一流”的现成支持。Spark中有一个用于Druid索引的第三方插件,但目前尚不支持。据我所知,Pinot甚至没有对Spark的这种支持,即您应该自己做出贡献:了解Pinot接口和代码,编写一些Java或Scala代码。但这并不难。(更新:Slack的Ananth PackkilDurai 现在正在为Pinot的Spark 提供支持。)
当应该实时更新表时,Druid和Pinot都引入了“实时节点”的概念,该概念可做三件事:接受来自Kafka的新数据(Druid也支持其他来源),为最近的数据提供查询,以及在后台创建细分,然后将其推送到“深度存储”。
数据提取: ClickHouse
ClickHouse无需准备严格包含所有数据(属于特定时间间隔)的“段”,这一事实使得数据摄取架构更为简单。ClickHouse不需要像Hadoop这样的批处理引擎,也不需要“实时”节点。常规ClickHouse节点(用于存储数据并为其提供查询)与之相同,它们直接接受批处理数据写入。
如果表已分区,则接受批量写入的节点(例如1万行)将根据分区表本身中所有节点的“权重”来分配数据(请参见上方的“数据管理:ClickHouse”部分)。
单批写入的行形成一个小的“集合”。集合立即转换为列格式。每个ClickHouse节点上都有一个后台进程,该进程将行集合并为较大的行集。ClickHouse的文档在很大程度上将这一原理称为“ MergeTree”,并强调了它与日志结构的合并树的相似性,尽管IMO有点令人困惑,因为数据不是以树的形式组织的,而是采用扁平列格式。
数据提取: 比较
Druid和Pinot的数据摄取是“繁重的”:它由几种不同的服务组成,并且管理是一个负担。
尽管有一个警告,但ClickHouse中的数据提取要简单得多(以更复杂的历史数据管理为代价(请参见上文)):您应该能够在ClickHouse本身之前“分批”数据。开箱即用的功能是自动获取和批处理来自Kafka的数据,但是,如果您有不同的实时数据源,包括从替代Kafka的排队基础结构和流处理引擎到简单的HTTP端点,则需要创建中间批处理服务,或直接向ClickHouse提供代码。
查询执行
Druid和Pinot具有称为“代理”的专用节点层,它们接受对系统的所有查询。它们基于从段到加载段的节点的映射,确定应向哪些“历史”查询处理节点发出子查询。代理将此映射信息保留在内存中。代理节点将下游子查询发送到查询处理节点,当这些子查询的结果返回时,代理将它们合并,并将最终的合并结果返回给用户。
我只能推测为什么在设计Druid和Pinot时决定构造另一种类型的节点。但是现在看来,这是必不可少的,因为随着群集中的段总数超过一千万,段到节点的映射信息需要GB的内存。在所有查询处理节点上分配这么多的内存太浪费了。因此,这是Druid和Pinot的“分段”数据管理体系结构带来的另一个缺点。
在ClickHouse中,通常不需要为“查询代理”指定单独的节点集。ClickHouse中有一种特殊的临时“分布式”表类型,可以在任何节点上进行设置,并且对该表的查询可以完成在Druid和Pinot中负责“代理”节点的工作。通常,此类临时表是在参与分区表的每个节点上设置的,因此,实际上,每个节点都可以作为对ClickHouse集群进行查询的“入口点”。该节点将向其他分区发出必要的子查询,处理该查询本身的一部分,并将其与其他分区的部分结果合并。
当一个节点(ClickHouse中的一个处理节点,或Druid和Pinot中的“代理”节点)向其他节点发出子查询,并且单个或几个子查询由于某种原因而失败时,ClickHouse和Pinot会正确处理此情况:合并所有成功子查询的结果,并且仍将部分结果返回给用户。目前,Druid非常缺乏此功能:如果任何子查询失败,则整个查询也会失败。
ClickHouse vs. Druid or Pinot: 结论
Druid和Pinot中数据管理的“分段”方法与ClickHouse中较简单的数据管理方法定义了系统的许多其他方面。但是,重要的是,这种差异对潜在的压缩效率(尽管目前这三个系统中的压缩情况目前都是令人沮丧的)或查询处理速度几乎没有影响。
ClickHouse与传统的RDMBS类似,例如PostgreSQL。特别是,ClickHouse可以仅部署在单个服务器上。如果部署的预计规模很小,例如,不超过用于查询处理的100个CPU内核和1 TB数据的数量级,那么我想说ClickHouse相对于Druid和Pinot具有显着优势,因为它非常简单并且不需要其他类型的节点,例如“主节点”,“实时提取节点”,“经纪人”。在此领域,ClickHouse与InfluxDB竞争而不是与Druid或Pinot竞争。
Druid和Pinot类似于大数据系统,例如HBase。不取决于它们的性能特征,而是取决于对ZooKeeper的依赖性,对持久性复制存储(例如HDFS)的依赖性,对单个节点故障的恢复能力的关注以及不需要常规人员关注的自主工作和数据管理。
对于广泛的应用程序,ClickHouse或Druid或Pinot都不是明显的赢家。首先,我建议考虑您能够理解的系统源代码,修复错误,添加功能等。“性能比较和系统选择”部分将对此进行更多讨论。
其次,您可以查看下表。该表中的每个单元格都描述了某个应用程序的属性,这使ClickHouse或Druid / Pinot可能是更好的选择。行没有按其重要性排序。每行的相对重要性对于不同的应用程序是不同的,但是如果您的应用程序由表中一列的许多属性描述,而由另一列的无或几个属性描述,则很可能应该从列标题中选择相应的系统。
| ClickHouse | Druid or Pinot |
|---|---|
| The organization has expertise in C++ | The organization has expertise in Java |
| Small cluster | Large cluster |
| A few tables | Many tables |
| Single data set | Multiple unrelated data sets (multitenancy) |
| Tables and data sets reside the cluster permanently | Tables and data sets periodically emerge and retire from the cluster |
| Table sizes (and query intensity to them) are stable in time | Tables significantly grow and shrink in time |
| Homogeneity of queries (their type, size, distribution by time of the day, etc.) | Heterogeneity |
| There is a dimension in the data, by which it could be partitioned and almost no queries that touch data across the partitions are done (i. e. shared-nothing partitioning) |
There is no such dimension, queries often touch data across the whole cluster. Edit 2019: Pinot now supports partitioning by dimension. |
| Cloud is not used, cluster is deployed on specific physical servers | Cluster is deployed in the cloud |
| No existing clusters of Hadoop or Spark | Clusters of either Hadoop or Spark already exist and could be used |
Differences between Druid and Pinot
正如我在上面多次提到的,Druid和Pinot具有非常相似的体系结构。在一个系统中存在着几个相当大的功能,而在另一个系统中则没有,还有一些区域,其中一个系统比另一个系统的进步要远得多。但是我要提到的所有这些内容都可以通过合理的努力在另一个系统中复制。
Druid与Pinot之间只有一个区别,那就是太大了,无法在可预见的将来消除-这是“主”节点中段管理的实现。而且,这两种系统的开发人员可能都不想这样做,因为两者的方法各有利弊,并不是说一个人总比另一个人好。
Segment Management in Druid
Druid(以及Pinot中的两个节点)中的“主”节点不负责集群中数据段的元数据的持久性以及段与加载这些段的查询处理节点之间的当前映射,此信息保留在ZooKeeper中。但是,Druid 还将这些信息保存在SQL数据库中,应该提供该信息以设置Druid集群。我不能说为什么最初做出这个决定,但是目前它提供了以下好处:
- 较少的数据存储在ZooKeeper中。ZooKeeper中仅保留有关从段ID到加载该段的查询处理节点列表的映射的最少信息。其余的扩展元数据(例如段的大小,其数据中的维度和指标列表等)仅存储在SQL数据库中。
- 如果由于数据段太旧而将其从集群中逐出(这是时间序列数据库的常见功能,所有ClickHouse,Druid和Pinot都具有),则将它们从查询处理节点上卸载,并从ZooKeeper中删除有关它们的元数据,但不是来自“深度存储”和SQL数据库。只要不从这些地方手动删除它们,就可以快速“恢复”真正的旧数据,以防某些报告或调查需要该数据。
- 最初这不太可能是一个意图,但是现在Druid中有计划使对ZooKeeper的依赖成为可选。目前,ZooKeeper用于三种不同的事物:段管理,服务发现和属性存储,例如用于实时数据摄取管理。服务发现和属性存储功能可以由Consul提供。段管理可以通过HTTP公告和命令来实现,而ZooKeeper的持久性功能已由SQL数据库“备份”,则部分启用了该功能。
将SQL数据库作为依赖项的弊端是更大的操作负担,尤其是在组织中尚未建立某些SQL数据库的情况下。Druid支持MySQL和PostgreSQL,Microsoft SQL Server有一个社区扩展。同样,当Druid部署在云中时,可以使用方便的托管RDBMS服务,例如Amazon RDS。
Segment Management in Pinot
与Druid本身实现所有分段管理逻辑并且仅依靠Curator与ZooKeeper进行通信不同,Pinot将大部分分段和集群管理逻辑委托给Helix框架。一方面,我可以想象它为Pinot开发人员提供了一种专注于其系统其他部分的杠杆。与在Druid中实现的逻辑相比,Helix的bug可能更少,这是因为在不同的条件下对它进行了测试,并且可能将更多的时间投入到Helix开发中。
另一方面,Helix的“框架界限”可能会限制Pinot。Helix,进而是Pinot,可能永远永远依赖ZooKeeper。
现在,我将列举Druid与Pinot之间更浅的区别。这里的“浅”是指如果有人愿意的话,有一条清晰的途径可以在缺少这些功能的系统中复制这些功能。
“Predicate pushdown” in Pinot
如果在摄取期间通过某些维键在Kafka中对数据进行了分区,则Pinot会生成包含有关该分区的信息的段,然后在执行带有该维谓词的查询时,代理节点会预先过滤段,这样有时段会少得多因此,查询处理节点需要命中。
此功能对于某些应用程序的性能很重要。
当前Druid支持基于密钥的分区,如果在Hadoop中创建了段,但在实时摄取期间创建段时尚不支持。Druid 目前不对broker实施“谓词下推”。
“Pluggable” Druid and Opinionated Pinot
由于Druid由许多组织使用和开发,因此随着时间的流逝,它几乎为每个专用部件或“服务”获得了几个可交换选项的支持:
- HDFS或Cassandra或Amazon S3或Google Cloud Storage或Azure Blob存储等作为“深度存储”;
- Kafka或RabbitMQ,Samza或Flink或Spark,Storm等(通过宁静)作为实时数据提取源;
- Druid本身,或Graphite,Ambari或StatsD或Kafka,作为Druid群集(度量标准)遥测的接收器。
由于Pinot几乎都是在LinkedIn上专门开发的,并且要满足LinkedIn的需求,因此,它通常不能为用户提供太多选择:HDFS或Amazon S3必须用作深度存储,而只有Kafka才能进行实时数据提取。但是,如果有人需要,我可以想象,为Pinot中的任何服务引入对多个可插拔选项的支持并不难。自Uber和Slack开始使用Pinot以来,这种情况可能很快就会改变。
Data Format and Query Execution Engine are Optimized Better in Pinot
即,Druid目前缺少以下的Pinot的段格式功能:
- 在Druid中以位粒度和字节粒度压缩索引列。
- 倒排索引对于每列都是可选的,在Druid中这是强制性的,有时不需要,并且占用大量空间。Uber观察到的 Druid和Pinot之间在空间消耗上的差异可能是由于这一点。
- 每段记录数值列中的最小值和最大值。
- 开箱即用的数据排序支持。如上文“ CloudFlare:ClickHouse与Druid”部分中所述,在Druid中只能通过手动方式和破解方式实现。数据排序意味着更好的压缩,因此Pinot的这一功能是Uber观察到的Druid和Pinot之间的空间消耗(和查询性能!)差异的另一个可能原因。
- 与Druid相比,用于多值列的某种更优化的格式。
所有这些事情都可以在Druid中实现。而且,尽管Pinot的格式优化上比Druid要好得多,但距离真正的优化还差得很远。例如,Pinot(以及Druid)仅使用通用压缩(例如Zstd),而尚未实现Gorilla论文中的任何压缩思想。
关于查询执行,Uber主要用于count (*)查询与Druid(以比较Pinot的表现1,2),因为它只是一个愚蠢的线性扫描在Druid的那一刻,虽然它很容易用适当的替换为o(1 )实施。这是“黑匣子”比较毫无意义的例证,本文上面的“关于性能比较和系统选择”部分对此进行了介绍。
我认为,GROUP BYUber观察到的查询性能差异应归因于Druid细分市场中缺乏数据排序,如本节上文所述。
Druid Has a Smarter Segment Assignment (Balancing) Algorithm
Pinot的算法是将段分配给当前加载的总段数最少的查询处理节点。Druid的算法复杂得多,它考虑了每个段的表和时间,并应用了一个复杂的公式来计算最终分数,通过该公式对查询处理节点进行排名,以选择最佳的节点来分配新的段。该算法使Metamarkets的生产查询速度提高了30–40%。然而,在Metamarkets我们仍然不满意这个算法,请参阅“历史节点的性能差异巨大” 这篇文章。
我不知道LinkedIn在Pinot中使用如此简单的分段平衡算法的效果如何,但是如果他们需要时间来改进其算法,那么可能巨大的收获正在等待着他们。
Pinot is More Fault Tolerant on the Query Execution Path
正如我在上面的“查询执行”部分中提到的那样,当“代理”节点向其他节点进行子查询,并且某些子查询失败时,Pinot会合并所有成功的子查询的结果,并且仍将部分结果返回给用户。
Druid目前没有实现此功能。
Tiering of Query Processing Nodes in Druid
请参阅本文上方的同名部分。Druid允许为较旧和较新的数据提取查询处理节点的“层”,而较旧数据的节点具有较低的“ CPU,RAM资源/已加载段数”比率,从而可以在访问时以较小的基础架构开销换取较低的查询性能旧数据。
据我所知,Pinot目前没有类似的功能。
Summary
ClickHouse,Druid和Pinot具有基本相似的体系结构,它们在通用大数据处理框架(例如Impala,Presto,Spark和列式数据库)之间具有独特的优势,并适当支持唯一的主键,点更新和删除(例如InfluxDB)。
由于它们的架构相似,ClickHouse,Druid和Pinot具有近似相同的“优化限制”。但是到目前为止,这三个系统都还不成熟,距离该限制还很遥远。仅需花费几个月的工程师工作,就可以对其中任何一个系统(当应用于特定用例时)大幅度提高效率。我不建议您完全比较主题系统的性能,不要选择您可以理解和修改的源代码,或者您想要投资的源代码。
在这三个系统中,ClickHouse与Druid和Pinot略有不同,而后两个几乎相同,但它们几乎是完全独立于同一系统的两个独立开发的实现。
ClickHouse更类似于PostgreSQL之类的“传统”数据库。ClickHouse的单节点安装是可能的。规模较小(少于1 TB的内存,少于100个CPU内核)如果您仍想与它们比较,则ClickHouse比Druid或Pinot更有趣,因为ClickHouse更简单并且移动部件和服务更少。我要说的是,它在这种规模上与InfluxDB或Prometheus竞争,而不是与Druid或Pinot竞争。
Druid和Pinot更类似于Hadoop生态系统中的其他大数据系统。它们即使在非常大的规模(超过500个节点)中仍保留“自动驾驶”属性,而ClickHouse需要专业SRE的大量关注。此外,与ClickHouse相比,Druid和Pinot更适合优化大型集群的基础架构成本,并且更适合云环境。
Druid和Pinot之间唯一的可持续区别是Pinot依赖于Helix框架,并将继续依赖ZooZeeper,而Druid可以摆脱对ZooKeeper的依赖。另一方面,Druid的安装将继续取决于某些SQL数据库的存在。
目前,Pinot比Druid的优化效果更好。(但请在上面再次阅读-“我不建议完全比较主题系统的性能”,以及帖子中的相应部分。)
原文帖子:https://medium.com/@leventov/comparison-of-the-open-source-olap-systems-for-big-data-clickhouse-druid-and-pinot-8e042a5ed1c7

 浙公网安备 33010602011771号
浙公网安备 33010602011771号