
Flink table&Sql中使用Calcite
Apache Calcite是什么东东
Apache Calcite面向Hadoop新的sql引擎,它提供了标准的SQL语言、多种查询优化和连接各种数据源的能力。除此之外,Calcite还提供了OLAP和流处理的查询引擎。它2013年成为了Apache孵化项目以来,在Hadoop中越来越引人注目,并被众多项目集成。比如Flink/Storm/Drill/Phoenix都依赖它做sql解析和优化。
Flink 结合 Calcite
Flink Table API&SQL 为流式数据和静态数据的关系查询保留统一的接口,而且利用了Calcite的查询优化框架和SQL parser。该设计是基于Flink已构建好的API构建的,DataStream API 提供低延时高吞吐的流处理能力而且就有exactly-once语义而且可以基于event-time进行处理。而且DataSet拥有稳定高效的内存算子和流水线式的数据交换。Flink的core API和引擎的所有改进都会自动应用到Table API和SQL上。
一条stream sql从提交到calcite解析、优化最后到flink引擎执行,一般分为以下几个阶段:
1 1. Sql Parser: 将sql语句通过java cc解析成AST(语法树),在calcite中用SqlNode表示AST; 2 2. Sql Validator: 结合数字字典(catalog)去验证sql语法; 3 3. 生成Logical Plan: 将sqlNode表示的AST转换成LogicalPlan, 用relNode表示; 4 4. 生成 optimized LogicalPlan: 先基于calcite rules 去优化logical Plan, 5 再基于flink定制的一些优化rules去优化logical Plan; 6 5. 生成Flink PhysicalPlan: 这里也是基于flink里头的rules将,将optimized LogicalPlan转成成Flink的物理执行计划; 7 6. 将物理执行计划转成Flink ExecutionPlan: 就是调用相应的tanslateToPlan方法转换和利用CodeGen元编程成Flink的各种算子。
而如果是通过table api来提交任务的话,也会经过calcite优化等阶段,基本流程和直接运行sql类似:
1. table api parser: flink会把table api表达的计算逻辑也表示成一颗树,用treeNode去表式; 在这棵树上的每个节点的计算逻辑用Expression来表示。 2. Validate: 会结合数字字典(catalog)将树的每个节点的Unresolved Expression进行绑定,生成Resolved Expression; 3. 生成Logical Plan: 依次遍历数的每个节点,调用construct方法将原先用treeNode表达的节点转成成用calcite 内部的数据结构relNode 来表达。即生成了LogicalPlan, 用relNode表示; 4. 生成 optimized LogicalPlan: 先基于calcite rules 去优化logical Plan, 再基于flink定制的一些优化rules去优化logical Plan; 5. 生成Flink PhysicalPlan: 这里也是基于flink里头的rules将,将optimized LogicalPlan转成成Flink的物理执行计划; 6. 将物理执行计划转成Flink ExecutionPlan: 就是调用相应的tanslateToPlan方法转换和利用CodeGen元编程成Flink的各种算子。
所以在flink提供两种API进行关系型查询,Table API 和 SQL。这两种API的查询都会用包含注册过的Table的catalog进行验证,除了在开始阶段从计算逻辑转成logical plan有点差别以外,之后都差不多。同时在stream和batch的查询看起来也是完全一样。只不过flink会根据数据源的性质(流式和静态)使用不同的规则进行优化, 最终优化后的plan转传成常规的Flink DataSet 或 DataStream 程序。所以我们下面统一用table api来举例讲解flink是如何用calcite做解析优化,再转换成回DataStream。
Table api任务的解析执行过程
Table Example
1 // set up execution environment 2 val env = StreamExecutionEnvironment.getExecutionEnvironment 3 val tEnv = TableEnvironment.getTableEnvironment(env) 4 //定义数据源 5 val dataStream = env.fromCollection(Seq( Order(1L, "beer", 3), Order(1L, "diaper", 4), Order(3L, "rubber", 2))) 6 //将DataStream 转换成 table,就是将数据源在TableEnvironment中注册成表 7 val orderA = dataStream.toTable(tEnv) 8 //用table api执行业务逻辑, 生成tab里头包含了flink 自己的logicalPlan,用LogicalNode表示 9 val tab = orderA.groupBy('user).select('user, 'amount.sum) 10 .filter('user < 2L) 11 //将table转成成DataStream, 这里头就是涉及到我们calcite逻辑计划生成 12 // 优化、转成可可执行的flink 算子等过程 13 val result = tab.toDataStream[Order]
将数据源注册成表
将DataStream 转换成table的过程,其实就是将DataStream在TableEnvironment中注册成表的过程中,主要是通过调用tableEnv.fromDataStream方法完成。
1 // 生成一个唯一性表名 val name = createUniqueTableName() 2 //生成表的 scheme val (fieldNames, fieldIndexes) = getFieldInfo[T](dataStream.getType) 3 //传入dataStream, 创建calcite可以识别的表 4 val dataStreamTable = new DataStreamTable[T]( 5 dataStream, 6 fieldIndexes, 7 fieldNames, None, None ) 8 //在数字字典里头注册该表 registerTableInternal(name, dataStreamTable)
上面函数实现的最后会调用scan,这里头会创建一个CatalogNode对象,里头携带了可以查找到数据源的表路径。其实它是Flink 逻辑树上的一个叶节点。
生成Flink 自身的逻辑计划
1 val tab = orderA.groupBy('user).select('user, 'amount.sum) 2 .filter('user < 2L)
上面每次调用table api,就会生成Flink 逻辑计划的节点。比如grouBy和select的调用会生成节点Project、Aggregate、Project,而filter的调用会生成节点Filter。这些节点的逻辑关系,就会组成下图的一个Flink 自身数据结构表达的一颗逻辑树:
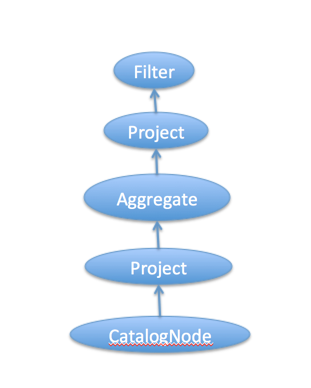
因为这个例子很简单,节点都没有两个子节点。这里的实现可能有的人会奇怪,filter函数的形参类型是Expression,而我们传进去的是"'user<2L",是不是不对呀? 其实这是scala比较牛逼的特性:隐式转换,这些传递的表达式会先自动转换成Expression。这些隐式转换的定义基本都在接口类ImplicitExpressionOperations里头。其中user前面定义的'符号,则scala会将user字符串转化成Symbol类型。通过隐式转换"'user<2L"表示式会生成一个LessThan对象,它会有两个孩子Expression,分别是UnresolvedFieldReference("user")和Liter("2")。这个LessThan对象会作为Filter对象的condition。
Flink 自身的逻辑计划 转换成calcite可识别的逻辑计划
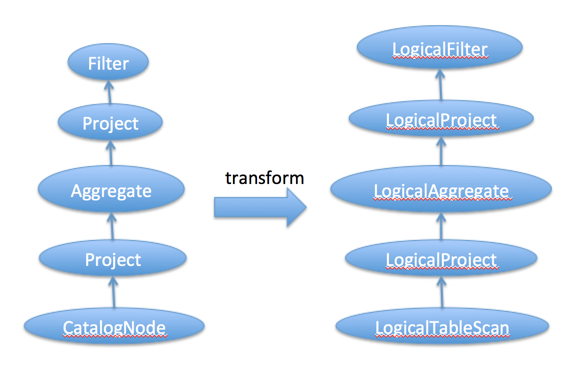
根据上面分析我们只是生成了Flink的 logical Plan,我们必须将它转换成calcite的logical Plan,这样我们才能用到calcite强大的优化规则。在Flink里头会由上往下一次调用各个节点的construct方法,将Flink节点转换成calcite的RelNode节点。
1 //-----Filter的construct创建Calcite 的 LogicalFilter节点---- 2 //先遍历子节点 3 child.construct(relBuilder) 4 //创建LogicalFilter 5 relBuilder.filter(condition.toRexNode(relBuilder)) 6 7 //-----Project的construct创建Calcite的LogicalProject节点---- 8 //先遍历子节点 9 child.construct(relBuilder) 10 //创建LogicalProject 11 relBuilder.project( 12 projectList.map(_.toRexNode(relBuilder)).asJava, 13 projectList.map(_.name).asJava, 14 true) 15 16 //-----Aggregate的construct创建Calcite的LogicalAggregate节点---- 17 child.construct(relBuilder) 18 relBuilder.aggregate( 19 relBuilder.groupKey(groupingExpressions.map(_.toRexNode(relBuilder)).asJava), 20 aggregateExpressions.map { 21 case Alias(agg: Aggregation, name, _) => agg.toAggCall(name)(relBuilder) 22 case _ => throw new RuntimeException("This should never happen.") 23 }.asJava) 24 25 //-----CatalogNode的construct创建Calcite的LogicalTableScan节点---- 26 relBuilder.scan(tablePath.asJava)
通过以上转换后,就生成了Calcite逻辑计划:
优化逻辑计划并转换成Flink的物理计划
这部分实现Flink统一封装在optimize方法里头,这个方法具体的实现如下:
1 // 去除关联子查询 2 val decorPlan = RelDecorrelator.decorrelateQuery(relNode) 3 // 转换time的标识符,比如存在rowtime标识的话,我们将会引入TimeMaterializationSqlFunction operator, 4 //这个operator我们会在codeGen中会用到 5 val convPlan = RelTimeIndicatorConverter.convert(decorPlan, getRelBuilder.getRexBuilder) 6 // 规范化logica计划,比如一个Filter它的过滤条件都是true的话,那么我们可以直接将这个filter去掉 7 val normRuleSet = getNormRuleSet 8 val normalizedPlan = if (normRuleSet.iterator().hasNext) { 9 runHepPlanner(HepMatchOrder.BOTTOM_UP, normRuleSet, convPlan, convPlan.getTraitSet) 10 } else { 11 convPlan 12 } 13 // 优化逻辑计划,调整节点间的上下游到达优化计算逻辑的效果,同时将 14 //节点转换成派生于FlinkLogicalRel的节点 15 val logicalOptRuleSet = getLogicalOptRuleSet 16 //用FlinkConventions.LOGICAL替换traitSet,表示转换后的树节点要求派生与接口 17 // FlinkLogicalRel 18 val logicalOutputProps = relNode.getTraitSet.replace(FlinkConventions.LOGICAL).simplify() 19 val logicalPlan = if (logicalOptRuleSet.iterator().hasNext) { 20 runVolcanoPlanner(logicalOptRuleSet, normalizedPlan, logicalOutputProps) 21 } else { 22 normalizedPlan 23 } 24 // 将优化后的逻辑计划转换成Flink的物理计划,同时将 25 //节点转换成派生于DataStreamRel的节点 26 val physicalOptRuleSet = getPhysicalOptRuleSet 27 val physicalOutputProps = relNode.getTraitSet.replace(FlinkConventions.DATASTREAM).simplify() 28 val physicalPlan = if (physicalOptRuleSet.iterator().hasNext) { 29 runVolcanoPlanner(physicalOptRuleSet, logicalPlan, physicalOutputProps) 30 } else { 31 logicalPlan 32 }
这段涉及到多个阶段,每个阶段无非都是用Rule对逻辑计划进行优化和改进。每个Rule的逻辑大家自己去看,如果我想自己自定义一个Rule该如何做呢?首先声明定义于派生RelOptRule的一个类,然后再构造函数中要求传入RelOptRuleOperand对象,该对象需要传入你这个Rule将要匹配的节点类型。如果你的自定义的Rule只用于LogicalTableScan节点,那么你这个operand对象应该是operand(LogicalTableScan.class, any())。就像这样一样
1 public class TableScanRule extends RelOptRule { 2 //~ Static fields/initializers --------------------------------------------- 3 public static final TableScanRule INSTANCE = new TableScanRule(); 4 //~ Constructors ----------------------------------------------------------- 5 private TableScanRule() { 6 super(operand(LogicalTableScan.class, any())); 7 } 8 //默认返回True, 可以继承matches,里面实现逻辑是判断是否进行转换调用onMatch 9 @Override 10 public boolean matches(RelOptRuleCall call) { 11 return super.matches(call); 12 } 13 //~ Methods ---------------------------------------------------------------- 14 //对当前节点进行转换 15 public void onMatch(RelOptRuleCall call) { 16 final LogicalTableScan oldRel = call.rel(0); 17 RelNode newRel = 18 oldRel.getTable().toRel( 19 RelOptUtil.getContext(oldRel.getCluster())); 20 call.transformTo(newRel); 21 } 22 }
通过以上代码对逻辑计划进行了优化和转换,最后会将逻辑计划的每个节点转换成Flink Node,既可物理计划。整个转换过程最后的结果如下:
1 == Optimized pyhical Plan == DataStreamGroupAggregate(groupBy=[user], select=[user, SUM(amount) AS TMP_0]) 2 3 DataStreamCalc(select=[user, amount], where=[<(user, 2)]) 4 5 DataStreamScan(table=[[_DataStreamTable_0]])
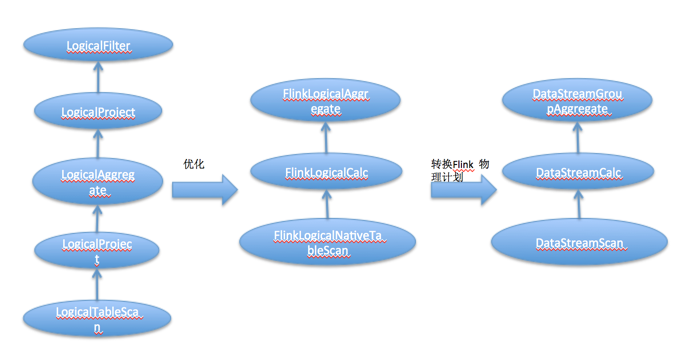
我们发现Filter节点在树结构中下移了,这样对数据进行操作时现在过滤再做聚合,可以减少计算量。
生成Flink 可以执行的计划
这一块只要是递归调用各个节点DataStreamRel的translateToPlan方法,这个方法转换和利用CodeGen元编程成Flink的各种算子。现在就相当于我们直接利用Flink的DataSet或DataStream API开发的程序。整个流程的转换大体就像这样:
1 == Physical Execution Plan == 2 Stage 1 : Data Source 3 content : collect elements with CollectionInputFormat 4 Stage 2 : Operator content : from: (user, product, amount) 5 ship_strategy : REBALANCE 6 Stage 3 : Operator content : where: (<(user, 2)), select: (user, amount) 7 ship_strategy : FORWARD 8 Stage 4 : Operator content : groupBy: (user), select: (user, SUM(amount) AS TMP_0) 9 ship_strategy : HASH
总结
不过这个样例中忽略了流处理中最有趣的部分:window aggregate 和 join。这些操作如何用SQL表达呢?Apache Calcite社区提出了一个proposal来讨论SQL on streams的语法和语义。社区将Calcite的stream SQL描述为标准SQL的扩展而不是另外的 SQL-like语言。这有很多好处,首先,熟悉SQL标准的人能够在不学习新语法的情况下分析流数据。静态表和流表的查询几乎相同,可以轻松地移植。此外,可以同时在静态表和流表上进行查询,这和flink的愿景是一样的,将批处理看做特殊的流处理(批看作是有限的流)。最后,使用标准SQL进行流处理意味着有很多成熟的工具支持
此文转载自http://blog.chinaunix.net/uid-29038263-id-5765791.html,感谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号