spark学习四
spark core学习2
1 Action算子
| Action function | 解释 |
| reduce((T,T)=>U) | 对整个结果集规约, 最终生成一条数据, 是整个数据集的汇总 |
| count() | 返回元素个数 |
| collect() | 以数组形式返回数据集中所有元素 |
| first() | 返回第一个元素 |
| take(N) | 返回前N个元素 |
| countByKey() | Key对应Key出现的次数 |
| foreach(T=>...) | 遍历 |
| saveAsTextFile(path) | 保存文件 |
| takeSample(withReplacement,num) | 类似于sample |
1.1 RDD 对数字型数据的额外支持
| 算子 | 含义 |
|---|---|
|
|
个数 |
|
|
均值 |
|
|
求和 |
|
|
最大值 |
|
|
最小值 |
|
|
方差 |
|
|
从采样中计算方差 |
|
|
标准差 |
|
|
采样的标准差 |
2 RDD 的 Shuffle 和分区
2.1 分区的作用
RDD 使用分区来分布式并行处理数据, 并且要做到尽量少的在不同的 Executor 之间使用网络交换数据, 所以当使用 RDD 读取数据的时候, 会尽量的在物理上靠近数据源, 比如说在读取 Cassandra 或者 HDFS 中数据的时候, 会尽量的保持 RDD 的分区和数据源的分区数, 分区模式等一一对应
2.2 分区和 Shuffle 的关系
分区的主要作用是用来实现并行计算, 本质上和 Shuffle 没什么关系, 但是往往在进行数据处理的时候, 例如 reduceByKey,groupByKey等聚合操作, 需要把 Key 相同的 Value 拉取到一起进行计算, 这个时候因为这些 Key 相同的 Value 可能会坐落于不同的分区, 于是理解分区才能理解 Shuffle 的根本原理
2.3 Spark 中的 Shuffle 操作的特点
- 只有 Key-Value`型的 RDD 才会有 Shuffle 操作, 特例: repartition 算子可以对任何数据类型 Shuffle
- 早期版本 Spark 的 Shuffle 算法是 Hash base shuffle, 后来改为 Sort base shuffle, 更适合大吞吐量的场景
2.4 RDD 的分区操作
- 查看分区数:rdd.partitions.size
- 创建分区:创建 RDD 时指定分区数、
coalesce算子指定、repartition算子指定
2.5 RDD 的 Shuffle 是什么
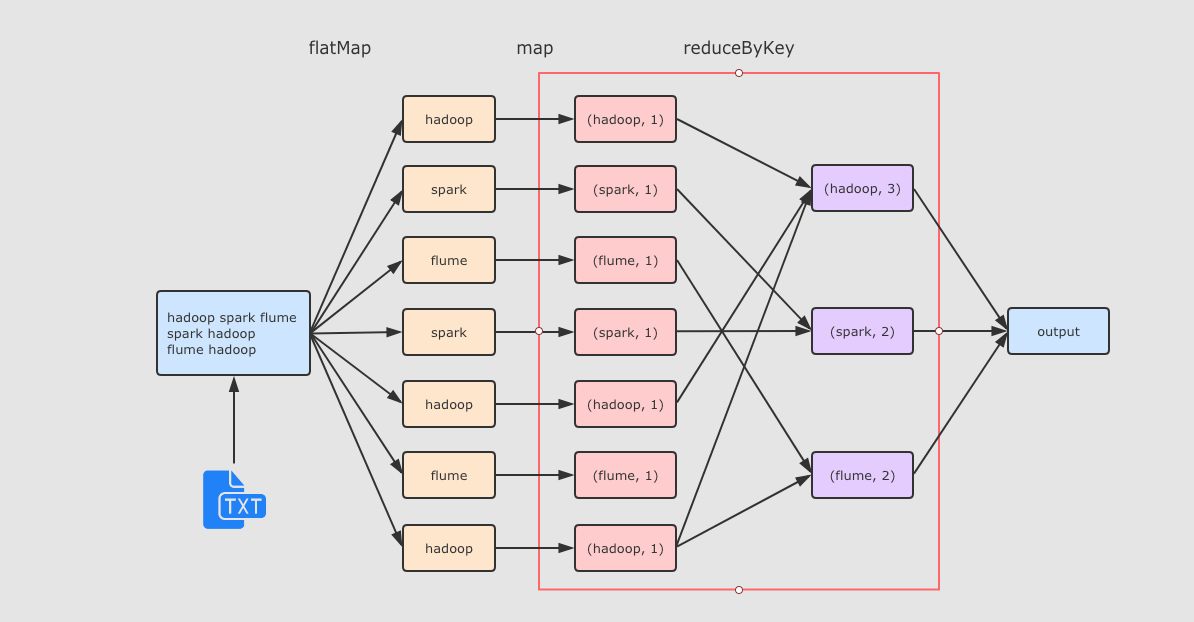
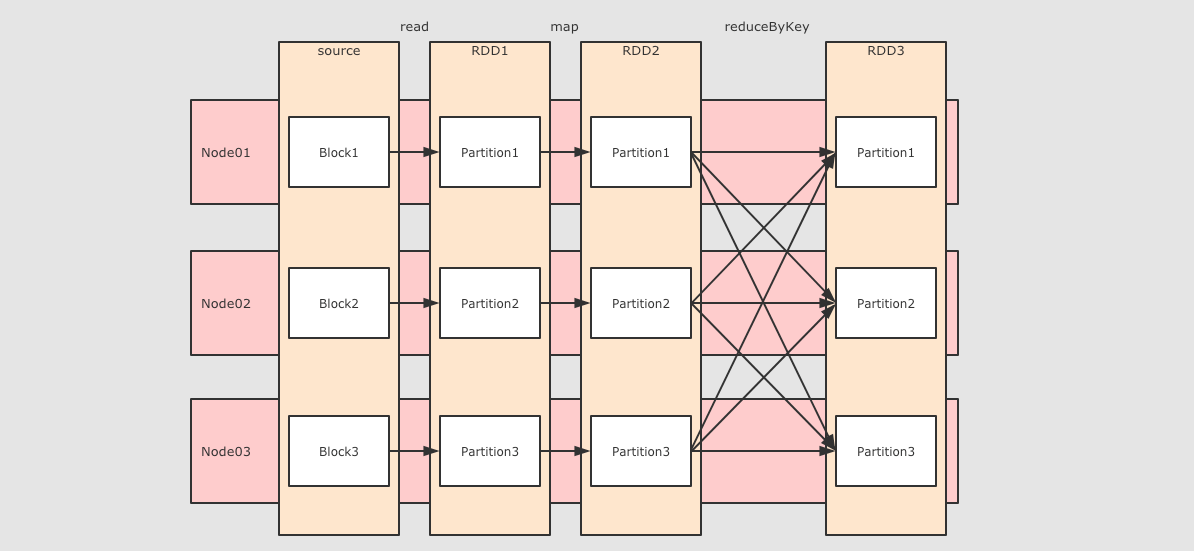
reduceByKey 这个算子本质上就是先按照 Key 分组, 后对每一组数据进行 reduce, 所面临的挑战就是 Key 相同的所有数据可能分布在不同的 Partition 分区中, 甚至可能在不同的节点中, 但是它们必须被共同计算.
为了让来自相同 Key 的所有数据都在 reduceByKey 的同一个 reduce 中处理, 需要执行一个 all-to-all 的操作, 需要在不同的节点(不同的分区)之间拷贝数据, 必须跨分区聚集相同 Key 的所有数据, 这个过程叫做 Shuffle
2.6 RDD 的 Shuffle 原理
Hash base shuffle
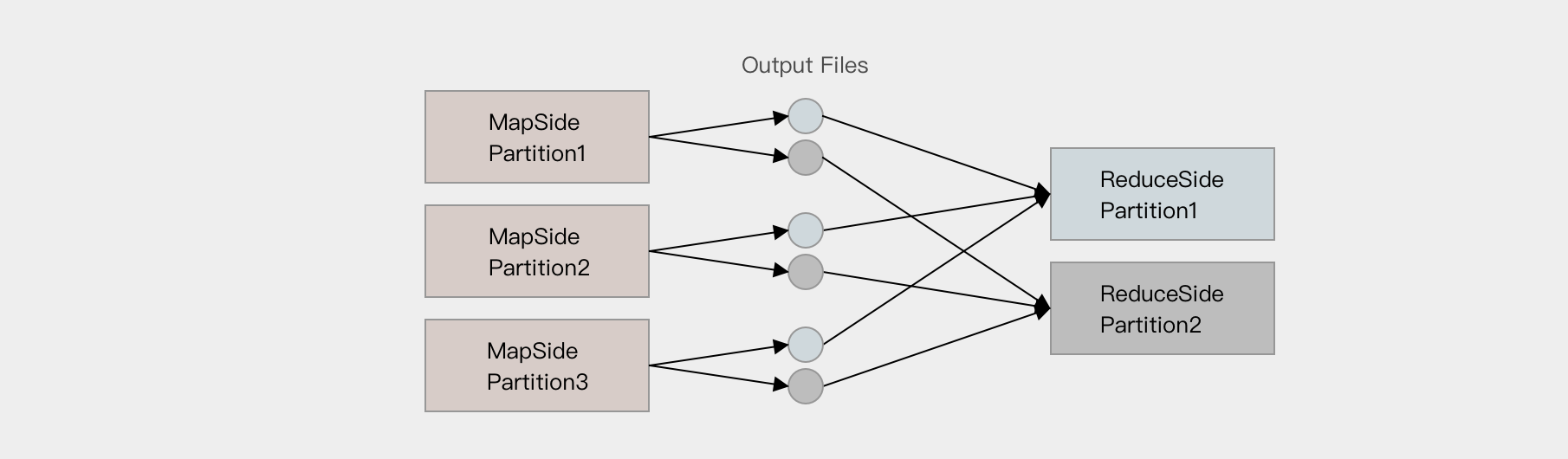
大致的原理是分桶, 假设 Reducer 的个数为 R, 那么每个 Mapper 有 R 个桶, 按照 Key 的 Hash 将数据映射到不同的桶中, Reduce 找到每一个 Mapper 中对应自己的桶拉取数据.
假设 Mapper 的个数为 M, 整个集群的文件数量是 M * R, 如果有 1,000 个 Mapper 和 Reducer, 则会生成 1,000,000 个文件, 这个量非常大了.
Sort base shuffle
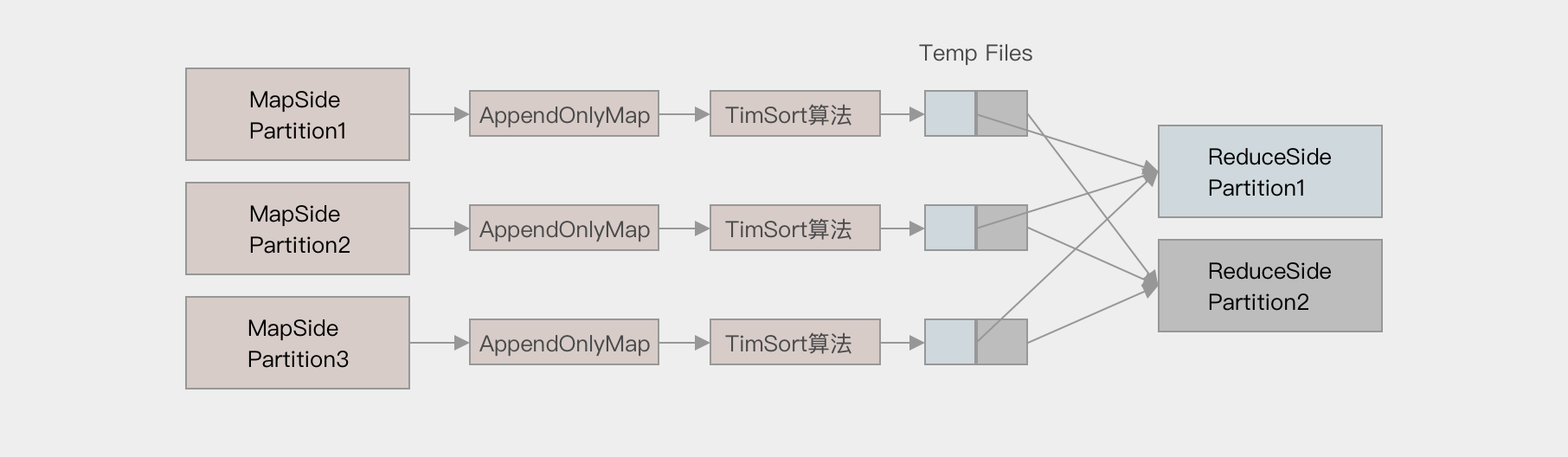
对于 Sort base shuffle 来说, 每个 Map 侧的分区只有一个输出文件, Reduce 侧的 Task 来拉取, 大致流程如下
-
Map 侧将数据全部放入一个叫做 AppendOnlyMap 的组件中, 同时可以在这个特殊的数据结构中做聚合操作
-
然后通过一个类似于 MergeSort 的排序算法 TimSort 对 AppendOnlyMap 底层的 Array 排序
-
先按照 Partition ID 排序, 后按照 Key 的 HashCode 排序
-
-
最终每个 Map Task 生成一个 输出文件, Reduce Task 来拉取自己对应的数据
3 缓存
3.1 使用缓存的意义?
3.2 缓存相关API
| 缓存级别 | userDisk 是否使用磁盘 | useMemory 是否使用内存 | useOffHeap 是否使用堆外内存 | deserialized 是否以反序列化形式存储 | replication 副本数 |
|---|---|---|---|---|---|
|
|
false |
false |
false |
false |
1 |
|
|
true |
false |
false |
false |
1 |
|
|
true |
false |
false |
false |
2 |
|
|
false |
true |
false |
true |
1 |
|
|
false |
true |
false |
true |
2 |
|
|
false |
true |
false |
false |
1 |
|
|
false |
true |
false |
false |
2 |
|
|
true |
true |
false |
true |
1 |
|
|
true |
true |
false |
true |
2 |
|
|
true |
true |
false |
false |
1 |
|
|
true |
true |
false |
false |
2 |
|
|
true |
true |
true |
false |
1 |
.unpersist():清除缓存
4 Checkpoint
4.1 作用
Checkpoint 的主要作用是斩断 RDD 的依赖链, 并且将数据存储在可靠的存储引擎中, 例如支持分布式存储和副本机制的 HDFS.
4.2 Checkpoint和Cache的区别
所以他们的区别主要在以下两点
-
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上, Persist 和 Cache 只能保存在本地的磁盘和内存中
-
Checkpoint 可以斩断 RDD 的依赖链, 而 Persist 和 Cache 不行
-
因为 CheckpointRDD 没有向上的依赖链, 所以程序结束后依然存在, 不会被删除. 而 Cache 和 Persist 会在程序结束后立刻被清除.
4.3 使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号