
mongodb的文本搜索
1、当mongodb进程文本搜索的时候,
一个collection,只有一个文本查询的索引、
2、全文索引的定义,搜索的是有意义的词,不是字母
一开始是简单的用中文姓名的姓,如:张,来查询,但是无效,或者简单用一个英文字符来测试,如:o ,但是两次都无效。。。。
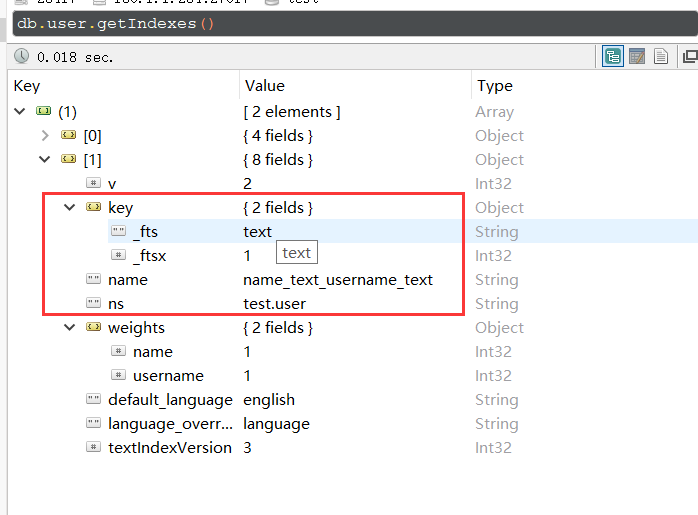
3、中文词与词之间没有空格,所以没法有效地分词。缺乏有效的分词器就是为什么不支持中文的原因。
在中文里面要进行有效的文本查询,需要有效的分词器
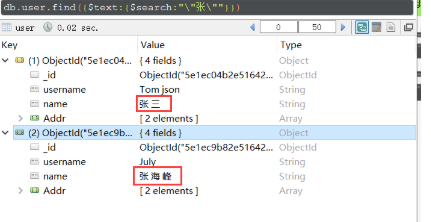
这种说法也不对,应该是必须分词,不用空格,用-试过,也是ok的。
4、文本搜索查询
1 | db.user.find({$text:{$search:'张 海 峰'}},{score:{$meta:"textScore"}}).sort( { score: { $meta: "textScore" } } ) |
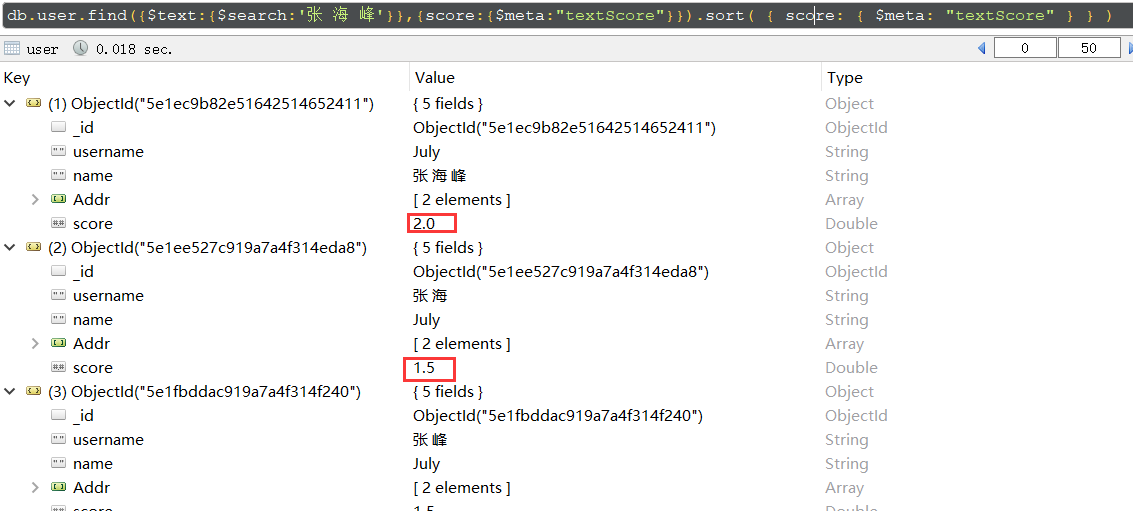
5、权重。。,即当文本搜索所占比重的成分
上面说到一个collection只有一个文本搜索,但是能够包含多个 字段,还存在4中的分数,而这几个字段在能够看所占的权重。。。。
首先是在新建索引的的设置好。。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | db.blog.createIndex( { Addr: "text", name: "text", username: "text", data: "text" }, { weights: { name: 10, usernaem: 5, data: 5 }, name: "TextIndex" } ) |
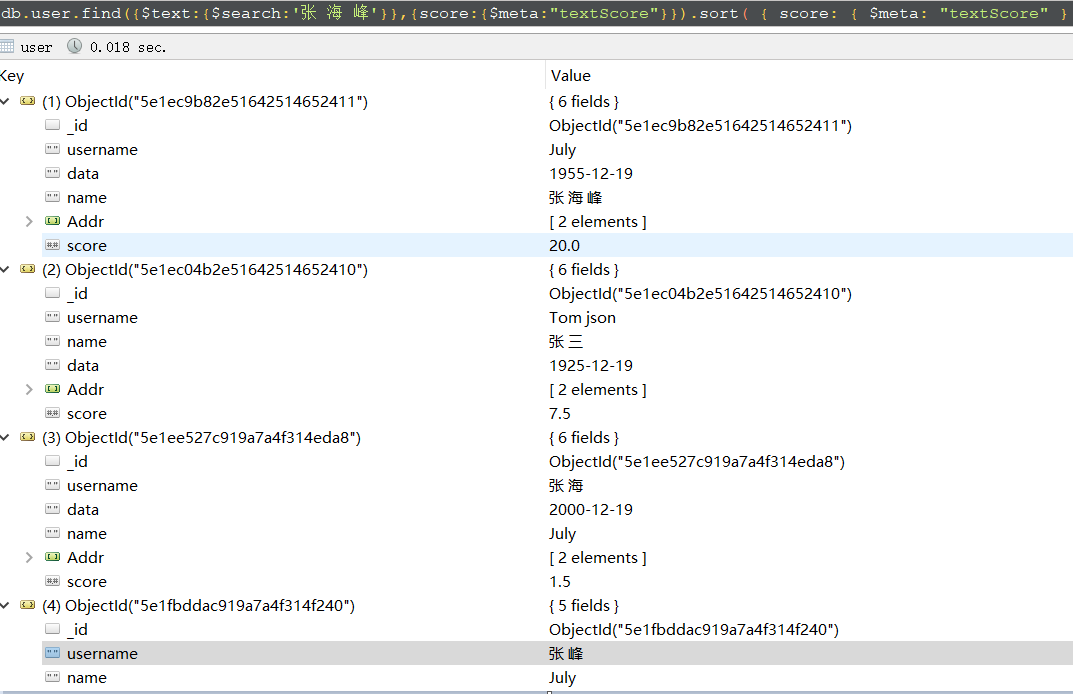
由name所占比例较大,即优先级不同。。。。故先选了name这份字段。。。再是username,,,
6、数据库内的Array[String]的不同的表现形式。。。
(1)、

1 2 3 4 5 6 7 8 9 10 11 | case class TU ( Addr:List[String] ) extends ModelBase[Document] { override def to: Document = { var doc= Document("Addr" -> this.Addr) doc } }//查询出来的List(Document((_id,BsonObjectId{value=5e2023b1e640cf7a0b589da8}), (Addr,BsonArray{values=[BsonString{value='珠海市居民房12号'}, BsonString{value='台湾市居民房12号'}]}))) |
(2)、



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core内存结构体系(Windows环境)底层原理浅谈
· C# 深度学习:对抗生成网络(GAN)训练头像生成模型
· .NET 适配 HarmonyOS 进展
· .NET 进程 stackoverflow异常后,还可以接收 TCP 连接请求吗?
· SQL Server统计信息更新会被阻塞或引起会话阻塞吗?
· 传国玉玺易主,ai.com竟然跳转到国产AI
· 本地部署 DeepSeek:小白也能轻松搞定!
· 自己如何在本地电脑从零搭建DeepSeek!手把手教学,快来看看! (建议收藏)
· 我们是如何解决abp身上的几个痛点
· 普通人也能轻松掌握的20个DeepSeek高频提示词(2025版)