zSim_缓存结构理解
本文是对Understanding Cache System Simulation in zSim的翻译,这篇文章详细的介绍了Zsim的Cache模拟是如何进行的,中英文对照,纯粹机翻,用作记录。
- zSim is a fast processor simulator used for modeling the bahavior of memory subsystems. zSim is based on PIN, a binary instrumention tool that allows programmers to instrument instructions at run time and insert customized function calls. The simulated application is executed on native hardware, with zSim imposing limited control only at certain points during the execution (e.g. special instructions, basic block boundaries, etc.). In this article, we will not provide detailed description on how zSim works on the instrumentation level. Instead, we isolate the implementation of zSim cache subsystems from the other parts of the simulator, and elaborate on how the simulated cache is architected and how timing is computed. For more information about zSim, please refer to the original paper which gives a rather detailed description of the simulator’s big picture. And also, it is always best practice to read the official source code when things are unclear. In the following sections, we will use the official source code github repo given above as the reference when source code is discussed.
zSim是一个快速的处理器模拟器,用于模拟内存子系统的行为。zSim基于PIN,这是一个二进制工具,允许程序员在运行时检测指令并插入自定义的函数调用。模拟的应用程序在本地硬件上执行,zSim只在执行过程中的某些点(如特殊指令、基本块边界等)施加有限的控制。在这篇文章中,我们将不提供关于zSim如何在工具层面上工作的详细描述。相反,我们将zSim缓存子系统的实现与模拟器的其他部分隔离开来,并详细说明模拟缓存是如何架构的,以及如何计算时间。关于zSim的更多信息,请参考原始论文,其中对模拟器的全貌有相当详细的描述。还有,当事情不清楚的时候,阅读官方源代码总是最好的做法。在下面的章节中,我们将使用上面给出的官方源代码github repo作为讨论源代码时的参考。
- Below is a table of source code files under the /src/ directory of the project that we will be talking about. For each file we also list its important classes and declarations for reader’s convenience. One thing that worth noting is that a file is not always named using the name of the class defined within that file. If you are unsure where a class is defined, simply doing a grep -r "class ClsName" or grep -r "struct ClsName" will suffice for most of the time.
下面是我们将要讨论的项目的/src/目录下的源代码文件的表格。对于每个文件,我们也列出了其重要的类和声明,以方便读者。值得注意的一点是,一个文件并不总是用该文件中定义的类的名称来命名。如果你不确定一个类是在哪里定义的,只需做grep -r "class ClsName "或grep -r "struct ClsName",在大多数情况下就足够了。

- Note that zSim actually provides several implementations of caches, which can be selected by editing the configuration file. The most basic cache implementation is in cache.h, and it defines the basic timing and operation of a working cache, and no more. A more detailed implementation, called TimingCache, is also available, which adds a weave phase timing model to simulate cache tag contention (zSim simulates shared resource contention in a separate phase after running the simulated program for a short interval, assuming that path-altering interferences are rare). In this article, we focus on the functionality and architecture of the cache subsystem, rather than detailed timing model and discrete event simulation. To this end, we only discuss the basic cache model, and leave the discussion of timing cache to future works.
请注意,zSim实际上提供了几种缓存的实现方式,可以通过编辑配置文件来选择。最基本的缓存实现在cache.h中,它定义了一个工作缓存的基本时序和操作,仅此而已。还有一个更详细的实现,叫做TimingCache,它增加了一个编织阶段的时序模型来模拟缓存标签的争夺(zSim在运行模拟程序很短的间隔后,在一个单独的阶段模拟共享资源的争夺,假设改变路径的干扰很少)。在这篇文章中,我们专注于高速缓存子系统的功能和架构,而不是详细的时序模型和离散事件仿真。为此,我们只讨论了基本的高速缓存模型,而把关于定时高速缓存的讨论留给未来的工作。
- In this section we discuss cache subsystem interfaces. In zSim, all memory objects, including cache and memory, must inherit from the virtual base class, MemObject, which features only one neat interface, access(). The access() call takes one MemReq object as argument, which contains all arguments for the memory request. The return value of the base cache access() call is the finish time of the operation, assuming no contention (if contention is not simulated, then it is the actual completion time of the operation, as in our case).
在本节中,我们讨论缓存子系统的接口。在zSim中,所有的内存对象,包括缓存和内存,都必须继承自虚拟基类MemObject,它只有一个整洁的接口,access()。access()调用需要一个MemReq对象作为参数,它包含了内存请求的所有参数。基础缓存access()调用的返回值是操作的完成时间,假设没有竞争(如果没有模拟竞争,那么它就是操作的实际完成时间,就像我们的例子一样)。
- Cache objects also inherit from the base class, BaseCache, which itself inherits from MemObject, and defines another interface call, invalidate(). This function call does not take MemReq as argument, but instead, it takes the address of the line, the invalidation type, and a boolean flag pointer to indicate to the caller whether the invalidated line is dirty (and hence a write back to lower level cache is required). Note that in zSim, the invalidate() call only invalidiates the block in the current cache object, and indicates to the caller via the boolean flag whether a write back is induced by the invalidation. It is therefore the caller’s responsibility to write back the dirty block to the lower level using a PUTX transaction, as we will see below. The return value of invalidate() is also the response time of the operation.
缓存对象也继承于基类BaseCache,BaseCache本身也继承于MemObject,并定义了另一个接口调用,invalidate()。这个函数调用不以MemReq为参数,而是以行的地址、无效类型和一个布尔标志指针为参数,向调用者表明无效的行是否是脏的(因此需要写回下层缓存)。请注意,在zSim中,invalidate()调用只对当前缓存对象中的块进行无效化处理,并通过布尔标志向调用者指出无效化处理是否会引起回写。因此,调用者有责任使用PUTX事务将脏块回写到下层,我们将在下面看到。invalidate()的返回值也是该操作的响应时间。
- Overall, the cache object interface in zSim is rather simple: access() implements how the cache handles reads and writes from upper levels. invalidate() implements how the cache handles invalidations from the processor or lower levels (depending on the position of the cache object in the hierarchy). Both methods are blocking: A begin time (absolute cycle number) is taken as part of the argument, and a finish time is returned as the cycle the operation completes.
总的来说,zSim中的缓存对象接口相当简单:access()实现了缓存如何处理来自上层的读写;invalidate()实现了缓存如何处理来自处理器或下层的无效操作(取决于缓存对象在层次结构中的位置)。两个方法都是阻塞的。开始时间(绝对周期数)作为参数的一部分,结束时间作为操作完成的周期被返回。
- The MemReq object is used in two scenarios. First, an external component (e.g. the simulated processor) may issue a memory request to the hierarchy by creating a MemReq object before it calls the access() method (in zSim, we have an extra level of FilterCache, in which case the FilterCache object issues the request). The caller of access() function needs to pass the address to be accessed (lineAddr field) and the begin cycle (cycle field) of the cache access. The type of the access in terms of coherence is also specified by initializing the type field. In this scenario, no coherence state in involved, and the access type can only be GETS or GETX. In the second scenario, an upper level cache may issue request to lower level caches to fulfill a request processed on the upper level. For example, when an upper level cache evicts a dirty block to the lower level, it must initiate a cache write transaction by creating a MemReq object and making it a PUTX request. In addition, when a request misses the upper level cache, a MemReq object must be created to fetch the block from lower level caches or degrade coherence states in other caches. The process can be conducted recursively until the request reaches a cache that holds this block or has full ownership, potentially reaching beyond the LLC and reading from the DRAM.
MemReq对象在两种情况下使用。首先,一个外部组件(例如模拟的处理器)可以在调用access()方法之前通过创建MemReq对象向层次结构发出内存请求(在zSim中,我们有一个额外的FilterCache层次,在这种情况下,FilterCache对象发出请求)。access()函数的调用者需要传递要访问的地址(lineAddr字段)和缓存访问的开始周期(cycle字段)。在相干性方面,访问的类型也是通过初始化类型字段来指定的。在这种情况下,不涉及相干性状态,访问类型只能是GETS或GETX。在第二种情况下,上层缓存可以向下层缓存发出请求,以满足在上层处理的请求。例如,当上层缓存将一个脏块驱逐到下层时,它必须通过创建一个MemReq对象并使其成为一个PUTX请求来启动一个缓存写事务。此外,当一个请求错过了上层缓存时,必须创建一个MemReq对象,以便从下层缓存中获取该区块或降低其他缓存的一致性状态。这个过程可以递归进行,直到请求到达持有这个区块的缓存或拥有全部所有权,有可能达到LLC之外,并从DRAM中读取。
- An interesting design decision in zSim is that when upper level cache issues a request to the lower level cache, the coherence state of the block in the upper level cache is determined by the lower level cache controller. This design decision is made to simplify the creation of “E” state, which requires information held by the lower level cache (i.e. the shared vector). As a result, when upper level caches issue the request, it must also pass a pointer to lower level caches such that the latter can assign the coherence state of the block when the request is handled. This pointer is stored in the state field of the MemReq object.
zSim中一个有趣的设计决定是,当上层缓存向下层缓存发出请求时,上层缓存中的块的一致性状态由下层缓存控制器决定。这个设计决定是为了简化 "E "状态的创建,这需要下层缓存持有的信息(即共享向量)。因此,当上层缓存发出请求时,它也必须向下层缓存传递一个指针,以便后者在处理请求时可以分配块的一致性状态。这个指针被存储在MemReq对象的状态字段中。
- Another invariant is that MemReq object is only used for upper-to-lower requests, such as cache line write back, line fetch, or coherence invalidation. For lower-to-upper requests, such as block invalidation, we never use MemReq objects. Instead, lower level caches directly call into upper level cache’s invalidate method, potentially broadcasting the invalidation request to several upper levels recursively.
另一个不变的原则是MemReq对象只用于从上到下的请求,如缓存行回写、行取、或一致性失效。对于从下到上的请求,比如块失效,我们从不使用MemReq对象。相反,下层缓存直接调用上层缓存的invalidate方法,可能会递归地将无效请求广播给几个上层缓存。
- We summarize the fields and their descriptions in the following table.
我们在下表中总结了这些字段和它们的描述。
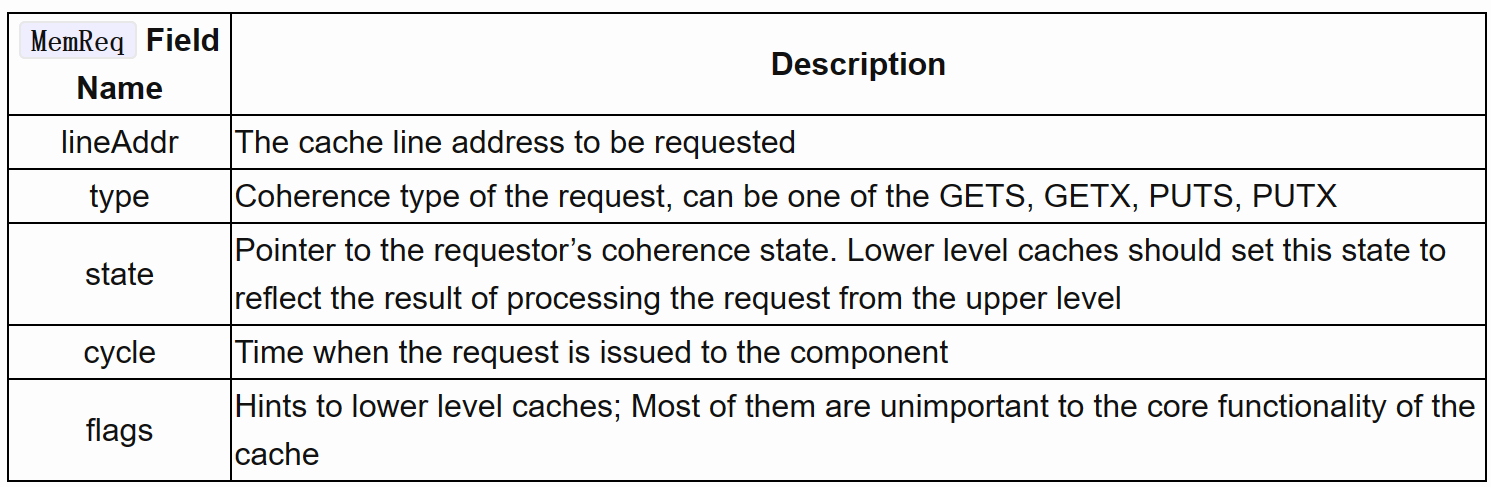
- Note that this is not a complete list of all MemReq fields. Some fields are dedicated to concurrency control and race detection, which will not be covered in this article. To make things simple, we always assume that only a single thread will access the cache hierarchy, and hence all states are stable. In practice, multiple threads may access the same cache object from different directions (upper-to-lower for line fetch, and lower-to-upper for invalidation). zSim has an ad-hoc locking protocol to ensure that concurrent cache accesses can always be serialized.
请注意,这并不是所有MemReq字段的完整列表。有些字段是专门用于并发控制和竞赛检测的,这在本文中不会涉及。为了简单起见,我们总是假设只有一个线程会访问缓存层次,因此所有状态都是稳定的。在实践中,多个线程可能会从不同的方向访问同一个缓存对象(从上到下的取行,从下到上的失效)。zSim有一个临时的锁定协议,以确保并发的缓存访问总是能够被序列化。
- In this section we discuss the abstract model of zSim’s cache system. The cache system is organized as a tree structure, with a single root representing the last-level cache (LLC), and intermediate nodes representing intermediate level caches (e.g. L2). At the leaf level, we have the processor and the attached private L1d and L1i cache. Note that zSim does not “visualize” the cache hierarchy in the usual way, in which processors are at the top, and the LLC is placed at the bottom. This may cause some naming problems since we used to call those that are closer to the leaf level “upper level caches”, and those that are close to the root level “lower level caches”. To avoid such confusion, in the discussion that follows, we use the term “child cache” to refer to caches that are closer to the leaf level which usually have smaller capacity and operate faster. We use the term “parent cache” to refer to caches that are closer to the root level which are larger but slower.
在这一节中,我们讨论zSim的缓存系统的抽象模型。缓存系统被组织成一个树状结构,一个根代表最后一级缓存(LLC),中间节点代表中间一级缓存(如L2)。在叶层,我们有处理器和附加的私有L1d和L1i高速缓存。请注意,zSim并没有以通常的方式 "可视化 "缓存层次,即处理器在顶部,而LLC在底部。这可能会引起一些命名上的问题,因为我们习惯于把那些接近叶层的称为 "上层缓存",而把那些接近根层的称为 "下层缓存"。为了避免这种混淆,在下面的讨论中,我们用 "子缓存 "来指代那些更接近叶层的缓存,它们的容量通常更小,运行速度更快。我们用 "父级缓存 "来指代更接近根级的缓存,它们的容量更大但速度更慢。
- A cache object can be partitioned into multiple banks, each having different network latency from its child caches. Although this seems to break the tree abstraction of the cache hierarchy, the partitioned cache can still be regarded as a logical cache object without losing generality. The partitioned parent cache models the so called Non-Uniform Cache Access (NUCA), which is typically applied to the LLC to increase parallelism and to avoid having a non-scalable monolithic storage. Accesses from child caches are first mapped to one of the banks using a hash function, and then dispatched to the parent partition (see MESIBottomCC::getParentId). In zSim, each partition is treated as a separate cache object, which can be accessed using the regular access() interface. Latencies from the children to the parent partitions are stored in a network latency configuration file, which is loaded at zSim initialization time. When a child cache accesses a partition of the parent, the corresponding child-to-parent latency value is added to the total access latency in order to model NUCA (see parentRTTs in class MESIBottomCC).
一个缓存对象可以被划分为多个库,每个库与它的子缓存有不同的网络延时。虽然这似乎打破了缓存层次结构的树状抽象,但分区的缓存仍然可以被视为一个逻辑的缓存对象而不失去通用性。分区的父缓存是所谓的非统一缓存访问(NUCA)的模型,它通常被应用于LLC,以增加并行性并避免拥有不可扩展的单体存储。来自子缓存的访问首先使用哈希函数映射到其中一个库,然后派发到父分区(见MESIBottomCC::getParentId)。在zSim中,每个分区被视为一个单独的缓存对象,可以使用常规的access()接口进行访问。从子分区到父分区的延迟被存储在网络延迟配置文件中,该文件在zSim初始化时被加载。当一个子缓存访问父缓存的一个分区时,相应的子缓存到父缓存的延迟值被添加到总的访问延迟中,以模拟NUCA(见MESIBottomCC类中的parentRTTs)。
- Although zSim supports both inclusive and non-inclusive caches (see nonInclusiveHack flag in MESI controllers), in the following discussion, we assume that caches are always inclusive. The implication of inclusive caches is that when a block is invalidated or evicted in the parent level, all children caches that hold a copy of the same block must also invalidate or write back (in case of a dirty line) the block to maintain inclusiveness. In addition, when a block is loaded into a child cache by a request, the same block must also be loaded into all parent level caches as the requested is passed down recursively. The author of zSim also suggested in a code comment that the non-inclusive path is not fully tested, which may incur unexpected behavior.
尽管zSim同时支持包容性和非包容性的缓存(参见MESI控制器中的nonInclusiveHack标志),在下面的讨论中,我们假设缓存总是包容性的。包容性缓存的含义是,当一个区块在父级中失效或被驱逐时,所有持有同一区块副本的子缓存也必须失效或回写(在脏行的情况下)该区块以保持包容性。此外,当一个区块被请求加载到子缓存中时,同样的区块也必须被加载到所有的父级缓存中,因为请求是递归传递的。zSim的作者也在代码注释中提出,非包容性的路径没有被完全测试,这可能会招致意外的行为。
- Three types of events can occur at a cache object. The first type is access, which is issued by the processor or by a child cache to fetch a line, write back a dirty line, or perform state degradation. Accesses are always issued to lower level caches wrapped by the MemReq object. The second type is invalidation, which in the current implementation is always sent from a parent cache to inform child caches that certain addresses can no longer be cached due to a conflicting access or an eviction. Note that invalidations do not use MemReq objects, and instead they call the child caches’ invalidate() method with the type of the invalidation (INV means full invalidation; INVX means downgrade to shared state). The third type is eviction, which naturally happens when a new block is brought into the cache, but the current set is full. An existing block is evicted to make space for the new block, which also incurs invalidation message sent to child caches if the evicted block is also cached by at least one child caches.
有三种类型的事件可以发生在一个缓冲区对象上。第一种类型是访问,由处理器或子缓冲区发出,以获取一行,写回一个脏行,或执行状态退化。访问总是被发布到由MemReq对象包裹的较低级别的缓冲区。第二种类型是失效,在当前的实现中,它总是从父缓存中发出,通知子缓存,由于冲突的访问或驱逐,某些地址不能再被缓存了。请注意,无效化并不使用MemReq对象,而是调用子缓存的invalidate()方法,并说明无效化的类型(INV意味着完全无效化;INVX意味着降级到共享状态)。第三种类型是驱逐,当一个新的区块被带入缓冲区,但当前的区块集已经满了,这自然会发生。一个现有的区块被驱逐,以便为新的区块腾出空间,如果被驱逐的区块也被至少一个子缓存所缓存,这也会引起无效消息被发送到子缓存。
- Each simulated cache object consists a tag array for storing address tags and eviction information, a replacement policy object that is purely logical, a coherence controller object which maintains the coherence states and shared vectors of each block, and access latencies for reading the tag array (accLat) and invalidating a block (invLat) respectively. The following table lists all data members of class Cache and a short description. In the following sections we will discuss these cache components individually.
每个模拟缓存对象包括一个用于存储地址标签和驱逐信息的标签阵列,一个纯逻辑的替换策略对象,一个维护每个块的一致性状态和共享向量的一致性控制器对象,以及分别用于读取标签阵列(accLat)和无效块(invLat)的访问延迟。下表列出了Cache类的所有数据成员以及简短的描述。在下面的章节中,我们将单独讨论这些缓存组件。

- The tag array object is defined in file cache_array.h. Tag arrays are one-dimensional array of address tags that can be accessed using a single index. Although some cache organization may divide the array into associative sets, the 1-D array abstraction is still used for identifying a cache block. All tag arrays must inherit from the base class, CacheArray, which provides three methods: lookup(), preinsert(), and postinsert(). The lookup method returns the index of the block if its address is found in the tag array, or -1 if not found. Optionally, the lookup method will also change the replacement metadata of the cache line, which is indicated by the updateReplacement flag in the argument list. The preinsert() method is called before inserting a new address tag into the tag array. This method will search the tag array for an empty slot to store inserted tag. If an empty slot cannot be found, as should be the majority of the cases, an existing slot will be made empty first by writing back the current block data, and then returning its index. The address to be written back is returned to the caller via the last argument, wbLineAddr, and the index of the selected slot is the returned value. postinsert() will actually store the new address tag into the target slot given both the address and the index of the slot.
标签阵列对象在文件cache_array.h中定义。标签阵列是由地址标签组成的一维阵列,可以用一个索引来访问。尽管一些缓存组织可能会将数组划分为关联集,但一维数组的抽象仍然用于识别一个缓存块。所有的标签阵列必须继承自基类CacheArray,它提供了三个方法:lookup(), preinsert(), and postinsert()。lookup方法如果在标签数组中找到了该块的地址,则返回该块的索引,如果没有找到则返回-1。可选择的是,查找方法也将改变缓存行的替换元数据,这由参数列表中的updateReplacement标志来表示。preinsert()方法在将一个新的地址标签插入标签阵列之前被调用。这个方法将在标签数组中搜索一个空槽来存储插入的标签。如果找不到空槽,大多数情况下,将通过回写当前块数据使现有槽变空,然后返回其索引。要回写的地址通过最后一个参数wbLineAddr返回给调用者,所选槽的索引是返回值。 postinsert()将实际把新的地址标签存储到给定地址和槽的索引的目标槽。
- Note that zSim only guarantees that preinsert() and postinsert() will not be nested, i.e. the pending insertion must complete before the next one could be performed. It is, however, possible that lookup() be called between the two methods as a result of write backs from child caches. One example is when a middle-level cache evicts a block that has been written drity in child caches. After preinsert() returns, the cache controller processes the eviction of the block, which requires sending invalidations to child caches. On receiving the invalidation, the child cache holding a dirty copy of the block will initiate a write back which directly sends the dirty block to the current cache, before the latter initiates a PUTX transaction to its parent cache. lookup() will be called to find the slot for writing back the dirty block during the process of the PUTX request in the parent cache.
请注意,zSim只保证preinsert()和postinsert()不会被嵌套,也就是说,在执行下一次插入之前,必须完成待定的插入。然而,由于来自子缓存的回写,在这两个方法之间调用lookup()是可能的。一个例子是当一个中级缓存驱逐了一个在子缓存中被写入的块。在preinsert()返回后,缓存控制器处理该块的驱逐,这需要向子缓存发送无效信息。在收到无效信息后,持有该区块脏副本的子缓存将启动回写,直接将脏区块发送到当前缓存,然后再由后者向其父缓存启动PUTX事务。在父缓存的PUTX请求过程中,将调用lookup()来找到回写脏区块的槽。
- We next take a closer look at these three method functions. For simplicity, we assume set-associative tag storage, which is implemented by class SetAssocArray. On initialization, the number of blocks and sets are passed as construction argument. The set size is computed by dividing the number of lines with the number of sets. The number of sets must be a power of two to simplify tag address mapping. The set mask is also computed to map any integer from the hash function to the range from zero to set size minus one.
接下来我们仔细看看这三个方法函数。为了简单起见,我们假设是集合关联的标签存储,由SetAssocArray类实现。在初始化时,块和集的数量被作为构造参数传递。集的大小是通过将行的数量除以集的数量来计算的。集的数量必须是2的幂,以简化标签地址映射。集数掩码也被计算出来,以将哈希函数中的任何整数映射到从零到集数减一的范围内。
- A hash function is associated with the tag array to compute the index of the set given a block address. The hash function is relatively unimportant for set-associative caches, since we just perform an identity mapping (i.e. do not change the address) and let the set mask map the block address into the set number. For other types of tag arrays, such as Z array, the hash function must be an non-trivial one, and can be assigned by specifyingarray.hash in the configurtation file.
一个哈希函数与标签阵列相关联,用于计算给定块地址的集合索引。哈希函数对于集合关联缓存来说相对不重要,因为我们只是进行身份映射(即不改变地址),让集合掩码将块地址映射为集合编号。对于其他类型的标签阵列,比如Z阵列,哈希函数必须是一个非简单的函数,可以通过在配置文件中指定array.hash来分配。
- A replacement policy object is responsible for deciding which block should be evicted, if any, when a new block is brought into the set. As discussed in the previous section, the replacement policy object stores its own metadata, which can be optionally updated on every tag array access.
替换策略对象负责决定当一个新区块被带入集合时,哪个区块应该被驱逐(如果有的话)。正如上一节所讨论的,替换策略对象存储了它自己的元数据,它可以在每次标签阵列访问时选择性地更新。
- The tag array is declared as a one-dimensional pointer named array. In order to access set X, the begin index is computed as (ways * X), and the end index is (ways * (X + 1)). To perform an array lookup given a block address, we first compute the set number by AND’ing the address with the set mask. Note that all block addresses have been right shifted to remove lower bit zeros. Then for each address tag in the set, we compare whether it equals the given address. If true, a hit is indicated and the index of the tag array entry is returned. Otherwise we return -1. If indicated by the caller, we also inform the replacement policy that the address has been accessed on a hit. The replacement policy object may then promote the hit block according to its own policy (e.g. moving to the end of the LRU stack).
标签阵列被声明为一个名为array的一维指针。为了访问集合X,开始索引被计算为(方式*X),结束索引为(方式*(X+1))。为了执行给定块地址的数组查询,我们首先通过将地址与集合掩码相乘来计算集合的编号。请注意,所有的块地址都被右移以去除低位的零。然后对于集合中的每个地址标签,我们比较它是否等于给定的地址。如果为真,表示命中,并返回标签数组条目的索引。否则我们返回-1。如果调用者指示,我们也会通知替换策略,该地址已经被访问过了。然后,替换策略对象可以根据它自己的策略来提升命中块(例如,移动到LRU堆栈的末端)。
- In preinsert(), the tag array either finds an empty slot, or more likely, finds a slot to be evicted. This is exactly where the replacement policy comes into play. The preinsert() method first initializes a SetAssocCands object, which is just a pair of indices indicating the begin and end index of the set in which replacement happens, and then passes this object to the replacement policy’s rankCands() method. The rankCands() method returns the index of the selected block, which is then returned together with the address tag. Note that preinsert() has no idea whether a block is invalid or dirty when it makes decision on eviction. The coherence controller, on the other hand, knows the exact state of the selected block, and will enforce correct behavior. As a result, the replacement policy will query the state of the block when it evaluates the block for eviction to avoid evicting invalid blocks.
在preinsert()中,标签阵列要么找到一个空槽,要么更有可能找到一个要被驱逐的槽。这正是替换策略发挥作用的地方。preinsert()方法首先初始化一个SetAssocCands对象,它只是一对索引,表示发生替换的集合的开始和结束索引,然后将这个对象传递给替换策略的rankCands()方法。rankCands()方法返回所选块的索引,然后与地址标签一起返回。请注意,preinsert()在做出驱逐决定时不知道一个块是无效的还是脏的。另一方面,一致性控制器知道所选块的确切状态,并将执行正确的行为。因此,替换策略在评估块的驱逐时将查询块的状态,以避免驱逐无效的块。
- The logic of postinsert() is simple. The replacement policy is notified that the selected block has been invalidated, and that a new block is inserted. The metadata for the block will be updated to reflect the replacement. The new address is also written into the array.
postinsert()的逻辑很简单。替换策略被通知所选择的块已经失效,并且有一个新的块被插入。该区块的元数据将被更新以反映替换。新的地址也会被写入数组中。
- The replacement policy is implemented as a ranking function. The policy can be specified using the repl.type key in the configuration file. In this section we only discuss LRU, which is implemented by class LRUReplPolicy. zSim implements LRU using timestamps. A single global timestamp is incremented for every access to the tag array. Each block also has a local timestamp which stores the value of the global timestamp when it is accessed. A larger local timestamp means the block is closer to the MRU position.
替换策略是作为一个排序函数实现的。该策略可以通过配置文件中的rep.type键来指定。在本节中,我们只讨论LRU,它是由LRUReplPolicy类实现的。每次对标签阵列的访问都会增加一个全局时间戳。每个区块也有一个本地时间戳,当它被访问时,它存储了全局时间戳的值。一个较大的本地时间戳意味着该块更接近MRU的位置。
- The ranking function, rankCands() (also rank()), iterates over the SetAssocCands object, and for each block in the set, it computes a score based on the LRU counter. If the LRU policy is sharer-aware, the score will be affected by: (1) the validity of the block; (2) the number of sharers; and (3) the local timestamp value. The higher the score is, the less favorable it is to evict the block. The replacement policy selects the block with the smallest score as the candidate for LRU eviction.
排名函数,rankCands()(也是rank()),迭代SetAssocCands对象,对于集合中的每个块,它根据LRU计数器计算出一个分数。如果LRU策略是共享感知的,那么分数将受到以下因素的影响。(1)区块的有效性;(2)分享者的数量;(3)本地时间戳值。分数越高,越不利于驱逐该区块。替换策略选择得分最小的区块作为LRU驱逐的候选人。
- zSim simulates MESI coherence protocol using an implementation of directory-based MESI state machine across the memory hierarchy. zSim does not model the full set features of the protocol, since only stable states are simulated. zSim also does not model the on-chip network traffic incurred by coherence activities. Latencies of the network is assigned statically, and they will not change based on network utilization.
zSim 使用基于目录的 MESI 状态机的实现来模拟 MESI 连贯性协议,跨内存层次。zSim 没有模拟该协议的全部功能,因为只模拟了稳定状态。网络的延迟是静态分配的,它们不会根据网络利用率而改变。
- Each cache object has a coherence controller, which maintains the coherence states of all blocks currently residing in the cache. Since zSim caches are inclusive, the coherence directory is implemented as in-cache sharer lists, one for each cached block. The number of bits in the sharer list per block equals the number of children caches. A “1” bit in the list indicates that the corresponding child cache may have a cached copy on the same address, dirty or clean. The sharer list is queried when invalidations are sent to the children caches, and is updated when a new block is fetched by a child cache.
每个缓存对象都有一个一致性控制器,它维护当前驻留在缓存中的所有块的一致性状态。 由于 zSim 缓存是包容性的,因此一致性目录被实现为缓存内共享器列表,每个缓存块一个。 每个块共享器列表中的位数等于子缓存的数量。 列表中的“1”位表示相应的子缓存可能在同一地址上有缓存副本,脏的或干净的。 当向子缓存发送无效时查询共享者列表,并在子缓存获取新块时更新共享列表。
- The coherence controller is further divided into two logical parts: A “top controller” maintains the directory and sends invalidation to children caches, and a “bottom controller” maintains the state for cached blocks and handles requests from child caches. These two logical parts are largely independent from each other, and are implemented as separate modules. The following table lists the coherence controller module name and the responsibility of the module.
一致性控制器进一步分为两个逻辑部分:“顶部控制器”维护目录并向子缓存发送失效,“底部控制器”维护缓存块的状态并处理来自子缓存的请求。 这两个逻辑部分在很大程度上相互独立,并作为单独的模块实现。 下表列出了一致性控制器模块名称和模块的职责。

- We also list the members of class MESIBottomCC and class MESITopCC to aid our discussion of coherence actions in the following sections.
我们还列出了类 MESIBottomCC 和类 MESITopCC 的成员,以帮助我们在以下部分中讨论一致性操作。


- One unfortunate fact with zSim source code is that methods of class MESICC and class MESITerminalCC have the same name as methods of class MESIBottomCC and class MESITopCC, which adds significant difficulties navigating the source files. The rule of thumb is that class MESICC and class MESITerminalCC methods are all defined in coherence_ctrls.h, while most of the class MESIBottomCC and class MESITopCC methods are defined in the cpp file.
zSim 源代码的一个不幸事实是类 MESICC 和类 MESITerminalCC 的方法与类 MESIBottomCC 和类 MESITopCC 的方法同名,这给浏览源文件增加了很大的困难。 根据经验,类 MESICC 和类 MESITerminalCC 方法都在 coherence_ctrls.h 中定义,而类 MESIBottomCC 和类 MESITopCC 方法的大部分定义在 cpp 文件中。
- We next describe coherence actions one by one.
接下来我们一一描述一致性动作。
- Invalidation can be initiated at any level of the cache by calling the invalidate() method. In fact, even the coherence protocol calls this method to invalidate blocks in child caches. The semantics of invalidate() method guarantees that the block to be invalidated will not be cached on the level it is called as well as all children levels. In this section we show how invalidate() interacts with cache coherence.
可以通过调用 invalidate() 方法在缓存的任何级别启动失效。 事实上,即使是一致性协议也会调用此方法来使子缓存中的块无效。 invalidate() 方法的语义保证了要失效的块不会被缓存在它被调用的级别以及所有子级别上。 在本节中,我们将展示 invalidate() 如何与缓存一致性交互。
- The invalidate() method first performs a cache lookup using the lookup() method of the tag array (not updating LRU states). If the block is found in the tag array, the address and the index of the block is passed to the coherence controller’s method processInv. Note that invalidate() handles both downgrades (INVX) and true invalidations (INV). The type of invalidation is specified using the type parameter. When downgrade is requested, the current level on which invalidate() is called and levels below are assumed to hold a block in M or E state.
invalidate() 方法首先使用标记数组的 lookup() 方法执行缓存查找(不更新 LRU 状态)。 如果在标签数组中找到该块,则将块的地址和索引传递给一致性控制器的方法 processInv。 请注意,invalidate() 处理降级 (INVX) 和真正的失效 (INV)。 使用类型参数指定失效类型。 当请求降级时,调用 invalidate() 的当前级别和下面的级别被假定为持有 M 或 E 状态的块。
- In a non-terminal coherence controller, processInv() simply calls processInval() on tcc and then calls the method of the same name on bcc. The completion cycle, however, is the cycle when tcc finishes broadcasting. This reflects an important assumption made by zSim: broadcasting is on the critical path, while transfer of dirty data and local state changes are not.
在非终端一致性控制器中,processInv() 简单地调用 tcc 上的 processInval(),然后调用 bcc 上的同名方法。 然而,完成周期是 tcc 结束广播的周期。 这反映了 zSim 做出的一个重要假设:广播在关键路径上,而脏数据的传输和本地状态更改则不是。
- In tcc’s processInval(), sendInvalidates() is called to broadcast the invalidation request to child caches that have a “1” bit in the sharer list. To elaborate: This function walks the sharer list of the block, and for each potential sharer, it calls the cache object’s invalidate() method recursively (recall that we are now in the initial invalidate()’s call chain). The type of invalidation and the boolean flag indicating dirty write back are passed unmodified. zSim assumes that all invalidations are signaled to child caches at the same time. The completion cycle of a single invalidation is computed as the response cycle from the child cache plus the network latency. Since all requests are signaled in parallel, the final completion cycle is the maximum of all child cache invalidations. After all children caches have responded, the controller changes the directory entry of the current block based on the invalidation type. For full invalidation, the directory entry is cleared, since the block no longer exists in the cache. For downgrades, the directory entry’s exclusive flag is cleared, but we keep sharer list bit vector intact.
在 tcc 的 processInval() 中,调用 sendInvalidates() 以将无效请求广播到共享列表中具有“1”位的子缓存。 详细说明:此函数遍历块的共享者列表,并且对于每个潜在的共享者,它递归地调用缓存对象的 invalidate() 方法(回想一下我们现在处于初始 invalidate() 的调用链中)。 无效类型和指示脏写回的布尔标志未修改地传递。 zSim 假定所有失效都同时向子缓存发出信号。 单个失效的完成周期计算为来自子缓存的响应周期加上网络延迟。 由于所有请求都是并行发出信号的,因此最终完成周期是所有子缓存失效的最大值。 在所有子缓存都响应后,控制器根据失效类型更改当前块的目录条目。 对于完全失效,目录条目被清除,因为该块不再存在于缓存中。 对于降级,目录条目的独占标志被清除,但我们保持共享者列表位向量不变。
- After tcc’s processInval() method returns, bcc’s processInval() method is invoked to handle local state changes. For full invalidations, we always set the coherence state to I, and set write back flag if the state is currently M to signal a dirty write back to the caller. Note that since at most one cache in the entire hierarchy can have a dirty copy, the dirty write back flag will be set exactly once during the invalidation process. For downgrades, we simply change the current M or E states (other states are illegal) to S, and set the write back flag if the current state is M. No actual write back takes place during invalidation. The caller of cache object’s invalidate() method should handle dirty write back by starting a PUTX transaction on parent caches or to other memory objects (e.g. DRAM, NVM).
tcc 的 processInval() 方法返回后,调用 bcc 的 processInval() 方法来处理本地状态变化。 对于完全失效,我们始终将一致性状态设置为 I,如果当前状态为 M,则设置写回标志以向调用者发出脏写回信号。 请注意,由于整个层次结构中最多有一个缓存可以有一个脏副本,因此脏回写标志将在无效过程中设置一次。 对于降级,我们只需将当前的 M 或 E 状态(其他状态是非法的)更改为 S,如果当前状态为 M,则设置回写标志。在无效期间不会发生实际的回写。 缓存对象的 invalidate() 方法的调用者应该通过在父缓存或其他内存对象(例如 DRAM、NVM)上启动 PUTX 事务来处理脏写回。
- Cache line eviction is triggered naturally as new blocks are loaded into the cache when the set is full. No external interface is available for the cache object to initiate an eviction. Instead, the cache controller calls processEviction() on the coherence controller when the tag array’s preinsert() returns a valid block number, indicating that a block should be evicted. Coherence controller’s processEviction() calls the method of the same name (unfortunate coincidence) on tcc and bcc respectively, in this order, and returns the bcc completion time as the eviction completion time. Note that by returning bcc’s completion time, zSim assumes that tcc’s broadcasting and bcc’s write back are serialized, such that the latter can only proceed after the former returns. This design decision is reasonable, as dirty write back needs to see the dirty line first, which is transferred in a side channel from one of the child caches to the coherence controller.
当集合已满时,当新块加载到缓存中时,自然会触发缓存行驱逐。 没有外部接口可用于缓存对象启动逐出。 相反,当标记数组的 preinsert() 返回一个有效的块号时,缓存控制器调用一致性控制器上的 processEviction() ,表明应该驱逐一个块。 Coherence controller的processEviction()依次调用了tcc和bcc上的同名方法(不幸巧合),返回bcc完成时间作为驱逐完成时间。 请注意,通过返回 bcc 的完成时间,zSim 假设 tcc 的广播和 bcc 的回写是序列化的,这样后者只能在前者返回后才能继续。 这个设计决定是合理的,因为脏写回需要首先看到脏行,它在侧通道中从一个子缓存传输到一致性控制器。
- The processEviction() method of tcc simply wraps sendInvalidates() method, which signals children caches of the cache line invalidation operation. The invalidation type is set to INV, indicating that blocks must be fully invalidated. The dirty write back flag is passed to a local variable of coherence controller’s processEviction(), which is then passed to bcc’s processEviction() to actually perform the write back.
tcc 的 processEviction() 方法简单地包装了 sendInvalidates() 方法,它向子缓存发出缓存行失效操作的信号。 失效类型设置为 INV,表示块必须完全失效。 脏回写标志被传递给一致性控制器的 processEviction() 的局部变量,然后传递给 bcc 的 processEviction() 以实际执行回写。
- After sending the invalidation, bcc’s processEviction() method changes the local state and conducts the write back. It first checks the dirty write back flag which is set by tcc’s invalidation process. If the flag is set, meaning a child cache has a dirty block on the invalidated address, the bcc first changes the local state from E or M to M (other from states are illegal). Note that local E state implies that the child cache first reads the line using GETS, acquiring the line in E state, and then does a silent transition from E to M. Local M state implies that the child cache originally acquired the line using GETX, which sets all caches holding the block to M state along the way the block is passed to it. Also note that zSim assumes that children caches will pass the dirty block to the current controller using a side channel, which is not on the critical path of broadcasting, instead of using regular MemReq. This assumption is justified by the fact that writing data back level-by-level is unnecessary, since these written back copies between the bottommost dirty block owner and the current cache object will be invalidated anyway.
发送无效后,bcc 的 processEviction() 方法更改本地状态并进行回写。 它首先检查由 tcc 的无效过程设置的脏回写标志。 如果设置了标志,意味着子缓存在无效地址上有脏块,bcc 首先将本地状态从 E 或 M 更改为 M(其他状态是非法的)。 请注意,本地 E 状态意味着子缓存首先使用 GETS 读取行,获取 E 状态的行,然后从 E 到 M 进行静默转换。本地 M 状态意味着子缓存最初使用 GETX 获取行, 在将块传递给它的过程中,它将所有保存该块的缓存设置为 M 状态。 另请注意,zSim 假定子缓存将使用不在广播关键路径上的侧通道将脏块传递给当前控制器,而不是使用常规 MemReq。 这个假设是合理的,因为逐级写回数据是不必要的,因为最底层的脏块所有者和当前缓存对象之间的这些写回副本无论如何都会失效。
- The type of the write back depends on the state of the block after handling dirty write backs from children caches. If the block state is E or S, meaning no dirty data needs to be written, the coherence controller creates a PUTS MemReq object, and calls parent cache access() method to handle the write back synchronously. If, on the other hand, the block state is M, a PUTX MemReq object is created and fed to the parent cache’s access() method. I state blocks will be simply ignored, since they neither have any sharer nor require any form of write back. In all cases, the completion cycle of the parent access() method will be returned to the caller as the completion cycle of the eviction operation. As discussed in early sections, the current block state will be set by the parent cache when the request is handled by access() method. After parent cache access() returns, the block state should be I, indicating the block is no longer cached in any part of the hierarchy down below the current level.
回写的类型取决于处理来自子缓存的脏写回后块的状态。 如果块状态为E或S,意味着不需要写脏数据,一致性控制器创建一个PUTS MemReq对象,并调用父缓存的access()方法同步处理回写。 另一方面,如果块状态为 M,则会创建一个 PUTX MemReq 对象并将其提供给父缓存的 access() 方法。 I 状态块将被简单地忽略,因为它们既没有任何共享者也不需要任何形式的回写。 在所有情况下,父 access() 方法的完成周期将作为驱逐操作的完成周期返回给调用者。 正如前面部分所讨论的,当请求由 access() 方法处理时,当前块状态将由父缓存设置。 父缓存 access() 返回后,块状态应为 I,表示该块不再缓存在当前级别以下的层次结构的任何部分。
- One design decision is whether to send PUTS requests to parent caches when the block is clean. In general, sending clean write backs help parent cache to manage their sharer lists by removing the sharer eagerly and making the list precise. Imprecise sharer lists do not affect correctness, but will incur extra coherence messages to caches that do not actually hold the block. zSim decouples the creation and processing of PUTS requests. PUTS requests are always sent whenever possible, but parent caches may just ignore them. Since zSim does not model network utilization, and assumes that all invalidations are sent in parallel, not cleaning the sharer list eagerly will not affect simulation result (despite that, zSim still clears the sharer list on clean write backs).
一个设计决定是当块干净时是否向父缓存发送 PUTS 请求。 一般来说,发送干净的回写有助于父缓存通过急切地删除共享者并使列表精确来管理他们的共享者列表。 不精确的共享者列表不会影响正确性,但会向实际上不包含块的缓存产生额外的一致性消息。 zSim 分离了 PUTS 请求的创建和处理。 PUTS 请求总是在可能的情况下发送,但父缓存可能会忽略它们。 由于 zSim 不对网络利用率进行建模,并假设所有无效都是并行发送的,因此不急切地清理共享者列表不会影响模拟结果(尽管如此,zSim 仍然会在干净的回写时清除共享者列表)。
- We discuss access() method in two sections. In this section, we present how GETS and GETX are handled. In the next section, we present PUTS and PUTX.
我们分两节讨论 access() 方法。 在本节中,我们介绍如何处理 GETS 和 GETX。 在下一节中,我们将介绍 PUTS 和 PUTX。
- The cache object’s access() method begins by performing a lookup in the tag array. If the address is not cached, and the request is a GETS or GETX, then we need to first evict an existing block (preinsert() and processEviction), and then load the intended block from parent level caches by calling coherence controller’s processAccess(). If the parent level cache does not contain the block, this process may be recursively repeated until reaching a parent level cache that holds the block with sufficient permission, or finally hit the DRAM (or other types of main memory). If the address is cached, we still need to call processAccess() to update its coherence state, since a cache hit may also change the coherence state of the block (e.g. if a GETX request hits a E state line, the state will transfer to M silently). The invariant is that no matter a block is evicted or hit, processAccess() always sees a valid cache line number, which is the slot for loading the new block or changing existing coherence states (recall that after a block is evicted, its coherence state in the former holder will be I).
缓存对象的 access() 方法首先在标记数组中执行查找。 如果地址未被缓存,并且请求是 GETS 或 GETX,那么我们需要首先驱逐现有块(preinsert() 和 processEviction),然后通过调用一致性控制器的 processAccess() 从父级缓存加载预期的块 . 如果父级缓存不包含该块,则可以递归地重复此过程,直到到达拥有足够权限的块的父级缓存,或者最终命中 DRAM(或其他类型的主存储器)。 如果地址被缓存,我们仍然需要调用 processAccess() 来更新它的一致性状态,因为缓存命中也可能改变块的一致性状态(例如,如果 GETX 请求命中 E 状态线,状态将转移到 M 默默地)。 不变的是,无论一个块被逐出还是命中,processAccess() 总是看到一个有效的缓存行号,这是用于加载新块或更改现有一致性状态的槽(回想一下,在一个块被逐出后,它在前持有者中的一致性状态将是I)。
- In the terminal level coherence controller, processAccess() only calls bcc’s method of the same name. For GETS requests, we check the current coherence state. If it is E, S or M, then the controller already has sufficient permission for accessing the block, and no coherence action will take place. If the block is in I state, the block needs to be brought into the cache from a parent level cache. To this end, the controller creates a GETS MemReq object, and calls parent cache access() method recursively. The coherence state of the current block will be set by the parent level access() method after it returns, which should be either S (already peer caches holding the block) or E (when it is the only holder of the block in parent’s sharer list, and the parent itself also has E or M permission).
在终端级一致性控制器中,processAccess() 只调用 bcc 的同名方法。 对于 GETS 请求,我们检查当前的一致性状态。 如果是E、S或M,那么controller已经有足够的权限访问block,不会发生一致性动作。 如果块处于I状态,则需要将块从父级缓存带入缓存。 为此,控制器创建一个GETS MemReq对象,并递归调用父缓存的access()方法。 当前块的一致性状态将在返回后由父级别的 access() 方法设置,它应该是 S(已经持有该块的对等缓存)或 E(当它是父共享者中块的唯一持有者时) 列表,父级本身也有 E 或 M 权限)。
- For a GETX request, if the current block state is E, then the block silently transfers to M state without notifying the parent cache. The fact that a dirty block is held by the current cache will be available to the parent when an invalidation forces the M state block to be written back. If, however, the current state is I or S, then just like the case for GETS, the controller creates a GETX MemReq object, and feeds it to parent cache’s access() method in order to invalidate all shared copies held by its peer caches (and peers of its parent, etc.). The final state of the block will be set by the parent instance of access(), which should be M.
对于 GETX 请求,如果当前块状态为 E,则块在不通知父缓存的情况下静默转移到 M 状态。 当无效强制 M 状态块被写回时,当前缓存持有脏块的事实将对父级可用。 但是,如果当前状态是 I 或 S,那么就像 GETS 的情况一样,控制器创建一个 GETX MemReq 对象,并将其提供给父缓存的 access() 方法,以便使其对等缓存持有的所有共享副本无效 (及其父母的同龄人等)。 块的最终状态将由 access() 的父实例设置,它应该是 M。
- The handling of GETS and GETX are more complicated on non-terminal caches. There are two invariants in non-terminal coherence controllers. The first invariant is that a controller can grant permission to its children caches only if it holds the same or higher permission. For example, a controller holding an S state line should not grant M permission to the child without acquiring M permission with its parent first. The second invariant is that non-terminal cache controllers always send data it has fetched to children caches (except for prefetching, which we do not discuss).
GETS 和 GETX 的处理在非终端缓存上更加复杂。 非终端一致性控制器中有两个不变量。 第一个不变量是控制器只有在拥有相同或更高权限的情况下才能向其子缓存授予权限。 例如,持有 S 状态线的控制器不应在未先向其父级获取 M 权限的情况下将 M 权限授予子级。 第二个不变量是非终端缓存控制器总是将它获取的数据发送到子缓存(预取除外,我们不讨论)。
- On receiving a request from a child cache, a non-terminal coherence controller first attempts to acquire equal or higher permission requested by the child cache if it does not hold the block in that permission. This translates to calling bcc’s processAccess(), which has exactly the same effect as in a terminal controller. After processAccess() returns, the current cache should have sufficient permission to grant the child cache’s request, which is performed by calling tcc’s processAccess(). This function takes a boolean flag indicating whether the current state of the block is exclusive (i.e. M or E) as one of the arguments (recall that tcc has no access to the current state of the block, but only the state of the child block). The function also takes argument on whether a dirty write back is incurred as a result of permission downgrade in one of its children caches.
在收到来自子缓存的请求时,非终端一致性控制器首先尝试获取子缓存请求的相同或更高的权限,如果它不持有该权限中的块。 这转化为调用 bcc 的 processAccess(),这与在终端控制器中具有完全相同的效果。 processAccess() 返回后,当前缓存应该有足够的权限来授予子缓存的请求,这是通过调用 tcc 的 processAccess() 来执行的。 此函数采用一个布尔标志,指示块的当前状态是否为独占(即 M 或 E)作为参数之一(回想一下,tcc 无法访问块的当前状态,但只能访问子块的状态 ). 该函数还接受是否由于其子缓存之一的权限降级而导致脏回写的参数。
- At a high level, processAccess() will set the child block state and its own directory state based on the type of the request and the state of the block in the current cache. We elaborate the concrete handling case-by-case. If the request is GETX, then we check the sharer list to see whether the block is currently shared by multiple children caches. If true, sendInvalidates() is called to revoke all shared cache lines in children caches. Note that when tcc begins processing the request, the current cache block state must already be exclusive. This does not contradict the fact that one or more of its children caches may have a shared or exclusive copy of the block. If the invalidation results in a dirty write back, the flag will be set, and the write back will be processed by the coherence controller. After invalidation, we set the requestor as the exclusive owner of the cache line by clearing all bits in the sharer list except the request’s.
在高层次上,processAccess() 将根据请求的类型和当前缓存中块的状态设置子块状态和它自己的目录状态。 具体的处理我们一一阐述。 如果请求是 GETX,那么我们检查共享者列表以查看该块当前是否被多个子缓存共享。 如果为真,则调用 sendInvalidates() 以撤销子缓存中的所有共享缓存行。 请注意,当 tcc 开始处理请求时,当前缓存块状态必须已经是独占的。 这与它的一个或多个子缓存可能具有该块的共享或独占副本这一事实并不矛盾。 如果无效导致脏回写,则将设置标志,并且回写将由一致性控制器处理。 无效后,我们通过清除共享列表中除请求之外的所有位,将请求者设置为缓存行的独占所有者。
- If the request is GETS, the current state of the block after bcc’s processAccess() can be any of the valid state. In MESI protocol, if the current cache holds the block in an exclusive state, and there is no other sharer of the block, tcc could grant E permission to the requestor, since it is certain that the current cache holds a globally unique copy of the line, and could grant write permission to one of its children. If, on the other hand, that the current state is exclusive, but a different child cache owns the block in exclusive state, then invalidation is still needed to downgrade the current owner of the line to shared state (using INVX), before S permission could be granted to the requestor. If the current state is shared, meaning that the block is not exclusively owned by the current cache, but also shared by other caches, the requestor simply gets S state without invalidation. In all three cases, the requestor is marked in the sharer list.
如果请求是 GETS,bcc 的 processAccess() 之后的块的当前状态可以是任何有效状态。 在 MESI 协议中,如果当前缓存以独占状态持有该块,并且该块没有其他共享者,tcc 可以授予请求者 E 权限,因为可以肯定当前缓存持有该块的全局唯一副本 行,并且可以向其子项之一授予写权限。 另一方面,如果当前状态是独占的,但不同的子缓存拥有处于独占状态的块,那么在 S 许可之前,仍然需要失效以将行的当前所有者降级为共享状态(使用 INVX) 可以授予请求者。 如果当前状态是共享的,这意味着该块不是由当前缓存独占,而且还被其他缓存共享,请求者只需获得 S 状态而不会失效。 在所有这三种情况下,请求者都被标记在共享者列表中。
- If the downgrade or full invalidation incurred by GETS or GETX results in a dirty write back, it will be passed to the coherence controller, and handled in processWritebackOnAccess(). Recall that zSim assumes the dirty block is transferred via a side channel, which is not on the critical path of the invalidation process, this does not add to the latency of the operation, but only simply changes the state of the current block from M or E to M (other from states are illegal).
如果 GETS 或 GETX 引起的降级或完全失效导致脏回写,它将被传递到一致性控制器,并在 processWritebackOnAccess() 中处理。 回想一下,zSim 假设脏块是通过侧通道传输的,它不在无效过程的关键路径上,这不会增加操作的延迟,而只是简单地将当前块的状态从 M 或 E 到 M(其他来自州的是非法的)。
- PUTS and PUTX are exclusively used for write backs, which can only occur at non-terminal levels in the hierarchy. These two requests are also first handled by bcc and then tcc. bcc ignores PUTS, since they are clean data and will not change the block state. For PUTX, the block state will transit from M or E to M (other from states are illgeal). tcc, on the other hand, does not ignore PUTS, but clears the bit of the child cache from the sharer list. PUTX is handled in exact the same way as PUTS, if PUTX_KEEPEXCL flag is not set in the request object (this flag demands that dirty data be written back, but keep the child block in E state). In both cases, the child cache state is set to I, indicating that the block has been written back, and is no longer cached by the child level.
PUTS 和 PUTX 专门用于写回,这只能发生在层次结构中的非终端级别。 这两个请求也是先由bcc处理,再由tcc处理。 bcc 忽略 PUTS,因为它们是干净的数据并且不会改变块状态。 对于 PUTX,块状态将从 M 或 E 转移到 M(其他状态是非法的)。 另一方面,tcc 并不忽略 PUTS,而是从共享者列表中清除子缓存的位。 如果在请求对象中未设置 PUTX_KEEPEXCL 标志(此标志要求写回脏数据,但将子块保持在 E 状态),则 PUTX 的处理方式与 PUTS 完全相同。 在这两种情况下,子级缓存状态都设置为 I,表示该块已被回写,不再被子级缓存。
- When a GETX/GETS request reaches the last level cache (LCC), but still cannot find the cached block, or when the LLC evicts a dirty block, where does the request go? In zSim, all memory objects are instances of the base class MemObject, including cache and the main memory. During initialization, the LLC is connected to the main memory by setting its parents list pointing to a main memory object, which also features the elegant access() interface (note that main memory objects do not have invalidate(), since this is added in class BaseCache). As a result, MemReq going beyond the LLC will be sent to main memory objects, which is then simulated just like caches, probably with a significantly different timing.
当一个GETX/GETS请求到达末级缓存(LCC),但仍然找不到缓存块,或者当LLC驱逐了一个脏块时,请求到哪里去了? 在 zSim 中,所有内存对象都是基类 MemObject 的实例,包括缓存和主内存。 在初始化期间,LLC 通过将其父列表设置为指向主内存对象来连接到主内存,该对象还具有优雅的 access() 接口(请注意,主内存对象没有 invalidate(),因为这是在 类 BaseCache)。 因此,超出 LLC 的 MemReq 将被发送到主内存对象,然后像缓存一样模拟,可能具有明显不同的时序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号