
word2vec 详解
word2vec 详解
传统的word2vec
神经网络将词表中的词语作为输入(一般输入哑编码的单词),输出一个低维度的向量表示这个词语,然后用反向传播的方法不断优化参数。输出的低维向量是神经网络第一层的输出,这一层通常也称作Embedding Layer。
缺点:
使用的是全连接的方法,造成计算量比较大
优点:
在于不需要人工进行预料的标注,直接使用未标注的文本训练集作为输入,输出的词向量可以用于下游的业务处理
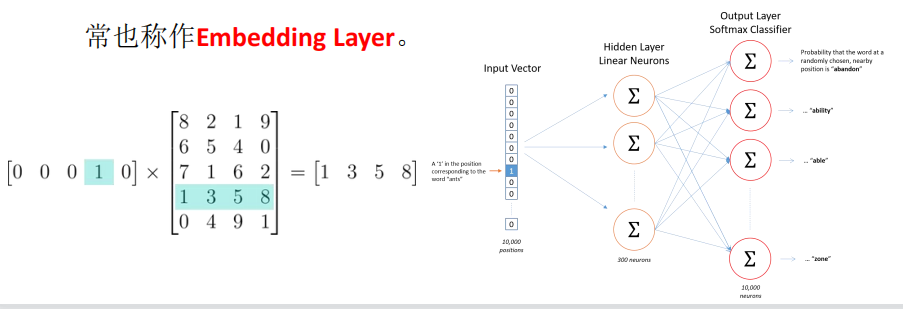
传统的方法(基于深度学习):
输入向量(词的亚编码one hot)与权重系数w相乘(原理类似自编码们从encoder然后decoder)得到编码信息,然后做全连接,但是这样造成的计算量及较大。
改进策略:
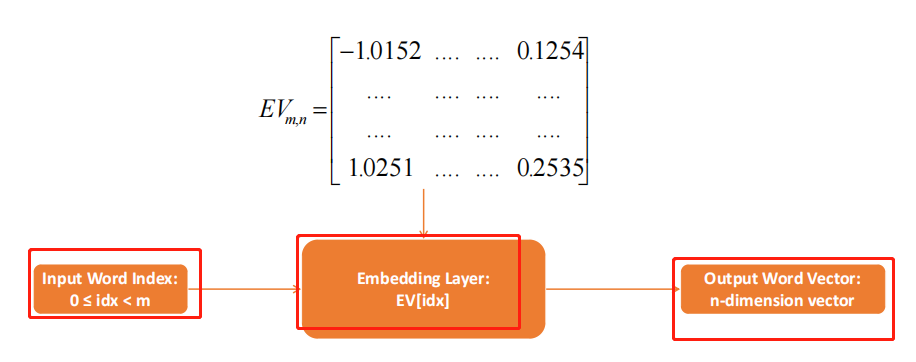
因为输入向量为亚编码(由0,1组成意味着,w与为0的计算始终为0,这是我们可以简化,只需要找到字的索引,利用字的索引找到w所在的行,就可以找到计算的结果(交叉熵损失函数)),然后做全连接计算
当前word2vec实现(并没有使用全连接,而是使用负采样和哈夫曼树):
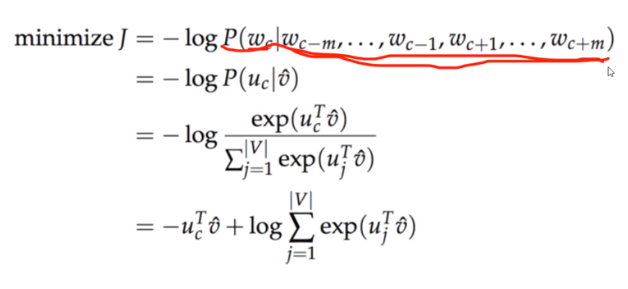

对比:
如果使用哈夫曼树总共计算log(【字典数大小】)
而是使用全连接则【字典数大小】* 神经元数
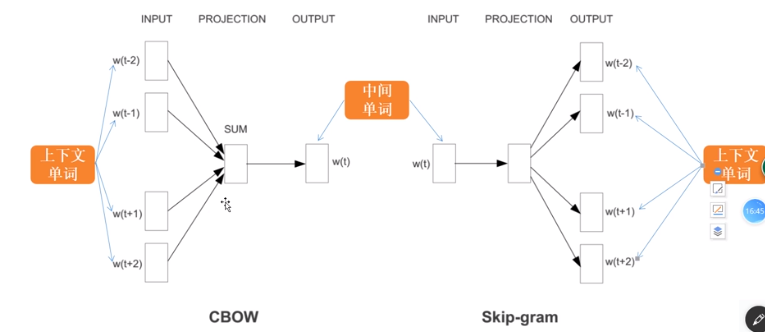
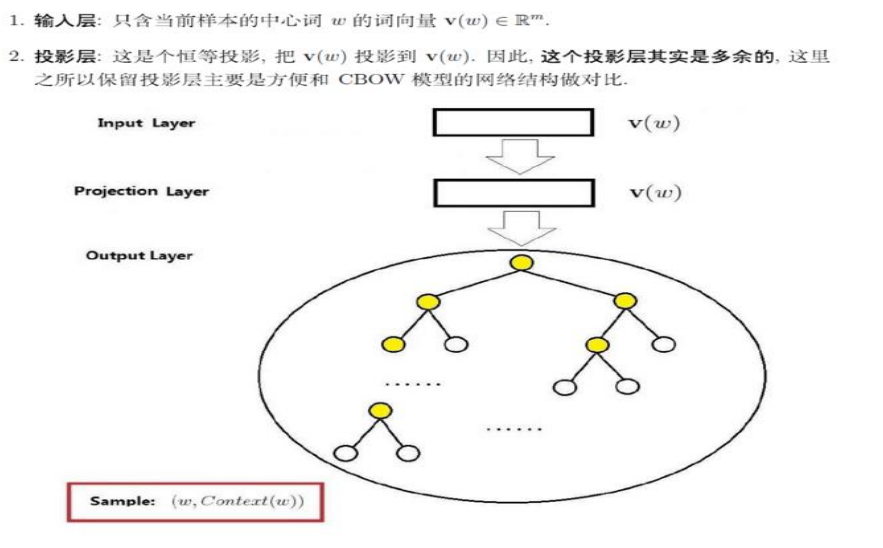
Skip-Gram实现
(与CBOW相同,只不过顺序稍微不同)
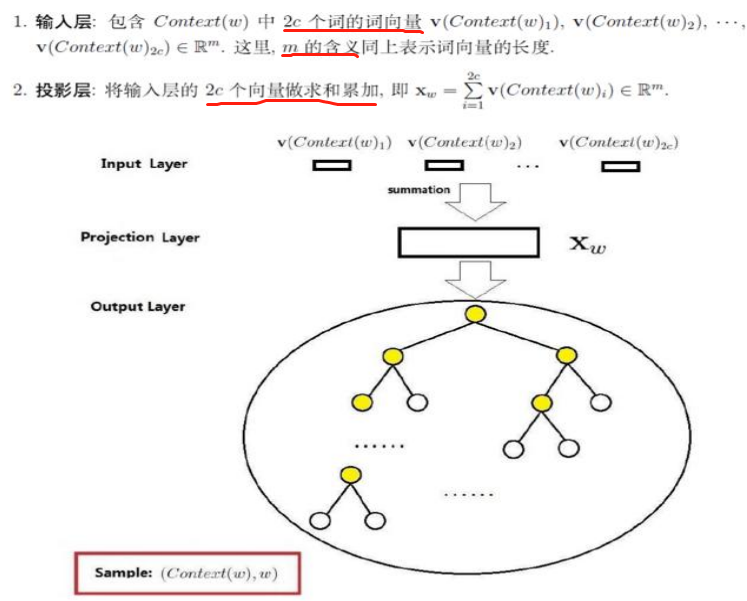
训练过程:
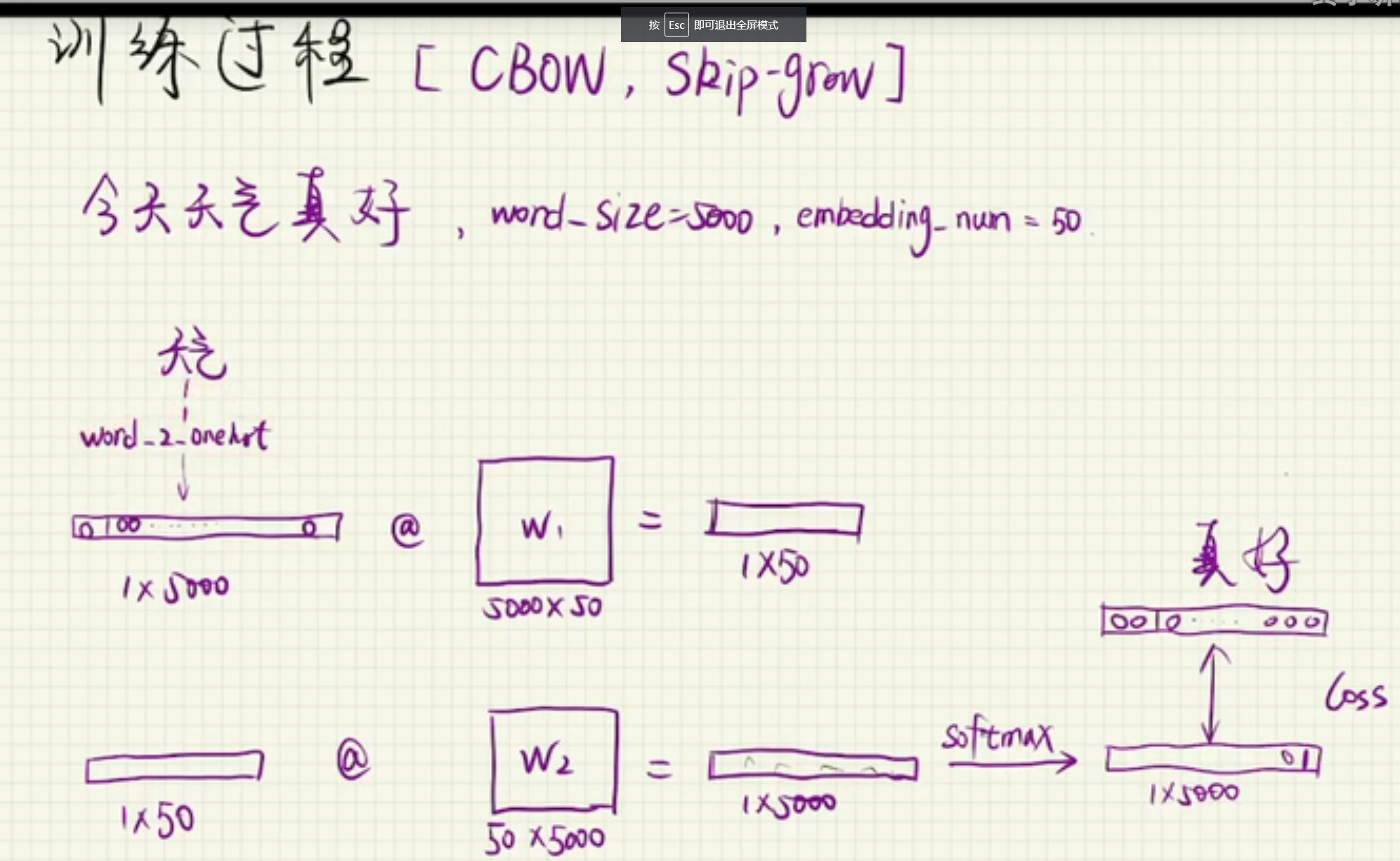
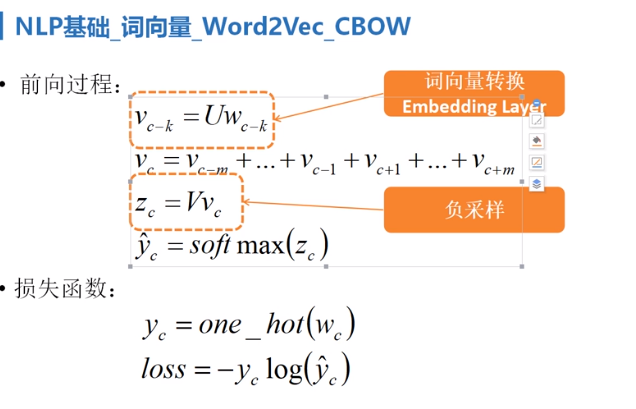
过程详解,首先“天气”这个中文词语,在词语表中查表,知道其对应的索引是多少,从而可以在w1的权重举证中,根据
索引可以直接知道,“天气”词语对应的权重是多少,得到一个1x50的向量,然后和w2矩阵(50x5000)相乘,得到1x5000
的向量,此时得到的向量不是由0和1组成的,我们使用softmax 来对其,进行一个转换,转换后向量的维度不变,使得
最大位置的值为1,其余位置的值为0,从而得到了一个one hot的向量编码,根据查表可以知道得到的向量对应的词是
什么,然后和我们需要预测到的词“真好”,做比较,看看差值是多少,也就是loss值是多少,当loss值较大,即预测到的
词和“天气”相差较大,我们就反向更新w2,w1的权重矩阵,这样反复多次训练,直到预测的向量和“真好”已知的向量相差较小,
loss值较小,我们停止训练,然后反向更新w1,w2的矩阵,获取当前的w1的权重矩阵,认为是我们要的词向量。
总结:
由于是上下文,既希望向左又希望向右,所以Skip-Gram效果没有CBOW好



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?