
算法--十大排序算法
排序算法
一、 插入排序
(有序区, 无序区)
把无序区的第一个元素插入有序区的适当位置
import random
num = list()
for i in range(20):
num.append(random.randint(0, 100))
sorted_list = [num[0]]
for i in num[1:]:
state = 1
for j in range(len(sorted_list)-1, -1, -1):
if i >= sorted_list[j]:
sorted_list.insert(j+1, i)
state = 0
break
if state:
# 算法走到判断语句的这一步,说明有序区中无法找到比i还小的值了
sorted_list.insert(0, i)
print(sorted_list)
二、 冒泡排序
(有序区, 无序区)
无序区透过交换出最大元素放在有序区
import random
from tqdm.std import trange
num = list()
for i in range(20):
num.append(random.randint(0, 100))
print(f"num 列表数据:\n {num}")
print("=" * 100 + "\n 冒泡排序为: ")
while True:
state = 0
for i in trange(len(num) -1):
if num[i] > num[i + 1]:
num[i], num[i + 1] = num[i + 1], num[i]
state = 1
if not state:
break
print(num)
三、 选择排序
(有序区, 无序区)
在无序区里找一个最小的元素跟在有序区的后面。 对数组:比较得多,换得少
def selection_sort(arr):
for i in range(len(arr)-1):
min_index = i
for j in range(i+1, len(arr):
if arr[j] < arr[min_index]:
min_index = j
if i != min_index:
arr[i] , arr[min_index] = arr[min_index], arr[i]
return arr
希尔排序
import randon
def pro_list():
num = list()
for i in range(8):
num.append(random.randint(0, 100))
print(f"data of list num is : \n {num}")
return num
def direct_insert_sort(num):
if num is None or len(num) == 1:
return num
num_new = [num[0]]
for i in num[1:]:
state = 1
for j in range(len(num_new)-1, -1, -1):
if i >= num_new[j]:
num_new.insert(j+1, i)
state = 0
break
if state:
num_new.insert(0, i)
return num_new
def shell_sort(num):
num_len = len(num)
gap = num_len // 2
g_len = num // gap
while 1:
for i in range(gap):
d_mid = []
for j in range(g_len):
d_mid.append(num[i+j*gap])
d_mid = direct_insert_sort(d_mid)
for j in range(g_len):
num[i+j*gap] = d_mid[j]
gap = gap // 2
if gap == 0:
print(num)
注
希尔排序是对直接插入排序的改良,在时间复杂度O(n**2) 较好
四、 快速排序
实例:
from time import time
from time import perf_counter
from typing import List
import sys
sys.setrecursionlimit(1000) # 1000次递归堆栈
"""
快速排序和递推的关系:
1、找到一个基准值,
2、将小于基准值的放在左边,大于基准值的放在右边;
3、对基准值左右两边的数进行递归;
"""
def quick_sort(arr):
"""
quick sort
:param: array
:return: array
"""
data = [[], [], []]
# 因为乱序数组,所有第几个都是可以的,理论上是一样的
d_pivot = arr[-1]
for i in arr:
if i < d_pivot:
data[0].append(i)
elif i > d_pivot:
data[2].append(i)
else:
data[1].append(i)
print(f"the data is \n {data}")
if len(data[0]) > 1:
data[0] = quick_sort(data[0])
if len(data[2]) > 1:
data[2] = quick_sort(data[2])
data[0].extend(data[1])
data[0].extend(data[2])
return data[0]
结果:
__name__: __main__
the data is
[[2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 5, 6, 4, 2, 3, 4], [44], [64, 54, 45]]
the data is
[[2, 2, 2, 3], [4, 4, 4, 4], [15, 5, 9, 7, 6, 12, 5, 5, 6]]
the data is
[[2, 2, 2], [3], []]
the data is
[[], [2, 2, 2], []]
the data is
[[5, 5, 5], [6, 6], [15, 9, 7, 12]]
the data is
the data is
[[9, 7], [12], [15]]
the data is
[[], [7], [9]]
the data is
[[], [45], [64, 54]]
the data is
[[], [54], [64]]
cost time: 0.02152619999833405
the array is [2, 2, 2, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 9, 12, 15, 44, 45, 54, 64]
(base) PS D:\workplace\project\machine-project> & D:/program/Python/python.exe "d:/workplace/project/machine-project/work/query_and _sort/quick_sort.py"
__name__: __main__
the data is
[[2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 5, 6, 4, 2, 3, 4], [44], [64, 54, 45]]
the data is
[[2, 2, 2, 3], [4, 4, 4, 4], [15, 5, 9, 7, 6, 12, 5, 5, 6]]
the data is
[[2, 2, 2], [3], []]
the data is
[[], [2, 2, 2], []]
the data is
[[5, 5, 5], [6, 6], [15, 9, 7, 12]]
the data is
the data is
[[9, 7], [12], [15]]
the data is
[[], [7], [9]]
the data is
[[], [45], [64, 54]]
the data is
[[], [54], [64]]
cost time: 0.018394199898466468 s
the array is [2, 2, 2, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 9, 12, 15, 44, 45, 54, 64]
(base) PS D:\workplace\project\machine-project> & D:/program/Python/python.exe "d:/workplace/project/machine-project/work/query_and _sort/quick_sort.py"
__name__: __main__
the data is
[[2, 15, 5, 9, 7, 6, 4, 12, 5, 4, 2, 5, 6, 4, 2, 3, 4], [44], [64, 54, 45]]
the data is
[[2, 2, 2, 3], [4, 4, 4, 4], [15, 5, 9, 7, 6, 12, 5, 5, 6]]
the data is
[[2, 2, 2], [3], []]
the data is
[[], [2, 2, 2], []]
the data is
[[5, 5, 5], [6, 6], [15, 9, 7, 12]]
the data is
[[], [5, 5, 5], []]
the data is
[[9, 7], [12], [15]]
the data is
[[], [7], [9]]
the data is
[[], [45], [64, 54]]
the data is
[[], [54], [64]]
cost time: 0.015949249267578125 s
the array is [2, 2, 2, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7, 9, 12, 15, 44, 45, 54, 64]
快速排序,选择一个基准,然后将小于基准值的部分数组放在一遍,大于基准数的数组放在另一边,
然后进行递归可以得到最后一组数
++++++注意++++++
递归的优化和循环的关系,同时在python中使用带缓存的方式,来进行优化的操作。
十大排序之--python实现
python代码实现:
- 冒泡排序
# 冒泡排序
def buble_sort(list):
for i in range(len(list)-1):
exchange = False
for j in range(len(list)-1 - i):
if list[j] > list[j+1]:
list[j], list[j+1] = list[j+1], list[j]
exchange = True
if not exchange:
return
- 选择排序
# 选择排序
def select_sort(list):
for i in range(len(list)-1):
min_loc = i
for j in range(i+1, len(list)):
if list[i] < list[min_loc]:
min_loc = j
list[i], list[min_loc] = list[min_loc], list[i]
- 插入排序
# 插入排序
def insert_sort(list):
for i in range(1, len(list)):
tmp = list[i]
j = i - 1
while j >= 0 and list[j] > tmp:
list[j+1] = list[j] # 有序区往后面移动一位
j -= 1
list[j+1] = tmp
- 快速排序
# 快速排序
def partition(li, left, right):
"""
将li列表中小于li[left]的数放在左边,大于li[left]的数放在右边
"""
tmp = li[left]
while left < right:
while left < right and li[right] >= tmp: # li 在区间[left, right]中从右向左进行遍历,碰到值小于tmp时停止
right -= 1
li[left] = li[right]
while left < right and li[left] <= tmp: # li 在区间[left, right]中从左向右进行遍历,碰到值大于tmp时停止
left += 1
li[right] = li[left]
li[left] = tmp
return left
def quick_sort(li, left, right):
if left < right:
mid = partition(li, left, right)
quick_sort(li, left, mid-1)
quick_sort(li, mid+1, right)
if __name__ == '__main__':
import random
li = [random.randint(0, 100) for _ in range(10)]
print(li)
quick_sort(li, 0, len(li)-1)
print(li)
- 堆排序
# 堆排序
# 参考网址: https://blog.csdn.net/wenwenaier/article/details/121314974
def sift(list, low, high): #调整函数
"""
:param list: 列表
:param low: 堆的根节点位置
:param high: 堆最后一个元素的位置
:return:
"""
i = low # 最开始指向根节点的位置
j = 2 * i + 1 # j开始i节点的左孩子节点
tmp = list[low] # 把对堆顶存起来
while j <= high: # 只要j位置有效
if j + 1 <= high and list[j+1] > list[j]: # 右孩子节点存在, 右孩子(j + 1) > 左孩子(j)
j = j + 1 # j指向右孩子
if list[j] > tmp: # j 大于堆顶元素(此时为孩子中较大的元素)
list[i] = list[j] # j元素被提拔网上一层
i = j # 往下看一层
j = 2 * i + 1 # j 跟着变化
else: # 堆顶元素 > 左孩子, 把tmp放到i的位置上
break
list[i] = tmp # 把tmp放到叶子节点上
def heap_sort(list):
# 开始构建一个大顶堆
n = len(list)
# n-2 //2 知道i父节点时,有足够长的子节点
for i in range((n-2)//2, -1, -1): # 左闭右开, 步长
# i 表示建堆时,调整部分的根下标
sift(list, i, n-1) # 开始时i为n-1元素的父节点位置, n-1为最后的叶子节点
# 堆建完成
for i in range(n-1, -1, -1):
# i指向当前堆的最后一个元素
list[0], list[i] = list[i], list[0]
sift(list, 0, i-1) # i-1最新的高
- 归并排序
# 归并排序
def merge(list, low, mid, high):
i = low
j = mid + 1
ltmp = []
# 中间值左右两边都有数的情况
while i <= mid and j <= high:
if list[i] < li[j]:
ltmp.append(list[i])
i += 1
else:
ltmp.append(list[j])
j += 1
# 右边没数
while i <= mid:
ltmp.append(list[i])
i += 1
# 左边没数
while j <= high:
ltmp.append(list[j])
j += 1
list[low:high+1] = ltmp
def merge_sort(list, low, high):
"""
:param list:
:param low: list 索引下限
:param high: list 索引上限
"""
if low < high:
mid = (low +high) // 2
merge_sort(list, low, mid)
merge_sort(list, mid+1, high)
merge(list, low, mid, high)
- 桶排序
算法思想:
桶排序假设待排序的一组数均匀独立的分布在一个范围中,并将这一范围划分成几个子范围(桶)。
然后基于某种映射函数f (高效与否的关键就在于这个映射函数的确定),
将待排序列的关键字 k 映射到第i个桶中 (即桶数组B 的下标i) ,那么该关键字k 就作为 B[i]中的元素。
接着将各个桶中的数据分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排) 。
然后依次枚举输出 B[0]….B[M] 中的全部内容即完成了一个数组的桶排列。
桶排序可以有很多方法,具体区别在于映射函数、桶、以及桶内排序的方法不同。
由于要构造桶,因此需要额外的空间,空间复杂度为o(n+k),时间复杂度为o(n+k),最好是o(N),且桶排序是稳定的.
使用场景: 元素范围较大, eg: 1到1亿之间
# 桶排序
def bucket_sort(li, n=100, max_num=10000):
bucket = [[] for _ in range(n)] # 创建二维列表
for var in li:
i = min(var // (max_num//n), n-1)
bucket[i].append(var)
# 对添加到第i个桶的数据插入到合适位置
for j in range(len(bucket[i])-1, 0, -1):
if bucket[i][j] < bucket[i][j-1]:
bucket[i][j], bucket[i][j-1] = bucket[i][j-1], bucket[i][j]
else:
break
sorted_list = []
for buc in bucket:
sorted_list.extend(buc)
return sorted_list
if __name__ == '__main__':
import random
l = list(range(100))
random.shuffle(l)
print(l)
print(bucket_sort(l))
- 希尔排序
算法思想:
分组插入排序
步骤:
去一个整数 d1 = n/2,将元素分成d1个组, 每个组相邻元素之间间隔为d1,
在各组内直接使用直接插入排序;
取第二个整数d2 = d1/2, 重复上述分组排序过程,知道dn = 1, 即所有在同一
组内直接插入排序;
希尔排序,每趟并不使某些元素有序, 而是使整体数据越来越接近有序, 最后
一趟使所有数据有序
时间复杂度比较复杂,并且和选取的gap有关
def insert_sort_gap(li, gap):
for i in range(gap, len(li)): # 表示摸到的牌的下标
tmp = li[i]
j = i - gap # j 表示手里牌的下标
while j >= 0 and li[j] > tmp: # 使同等间隔的数一次增加,变得有序
li[j + gap] = li[j]
j -= gap
li[j + gap] = tmp # 之后tmp 就没作用了
def shell_sort(li):
d = len(li) // 2
while d >= 1:
insert_sort_gap(li, d) # 每一趟,使间隔的数变得有序
d //= 2
if __name__ == '__main__':
import random
l = list(range(10))
random.shuffle(l)
print(l)
shell_sort(l)
print(l)
- 计数排序
对列表进行排序,列表范围在0到100,时间复杂度为O(n)
def count_sort(li, max_sort=100):
"""
:param li:
:param max_sort: list中的最大值
"""
count = [0 for _ in range(max_sort+1)] # 列举0到最大值
# count表示li中的值在(0, max_sort)中出现的次数, 值与索引对应
for var in li:
count[var] += 1
li.clear()
for index, val in enumerate(count):
for i in range(val):
li.append(index)
if __name__ == '__main__':
import random
l = [random.randint(0, 100) for _ in range(100)]
print(l)
count_sort(l)
print(l)
- 基数排序
可以认为是多关键词排序:
eg: 假如现在有一个员工表, 要求按照薪资排序,
薪资相同的员工按照年龄排序。
对[32,13,94,52,17,54,93]进行基数排序

按个位数分桶:
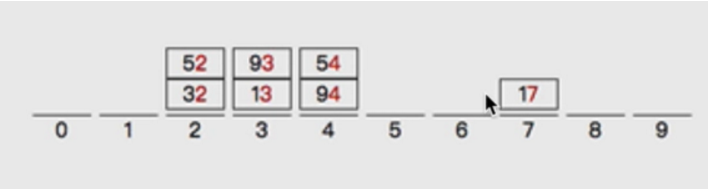
按个位数排序:

按十位分桶:
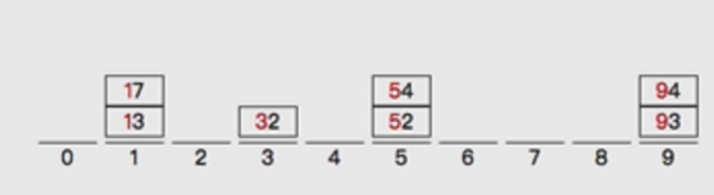
按十位排序:

最终排序结果:

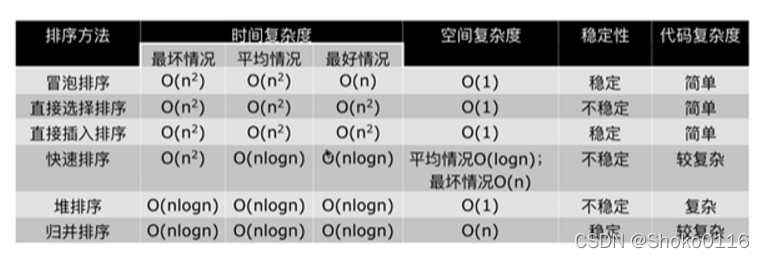
复杂度分析:

def radix_sort(li):
max_num = max(li)
it = 0 # 迭代次数
while 10 ** it <= max_num:
bucket = [[] for _ in range(10)] # 创建二维列表
# 开始分桶
for var in li:
digit = (var // 10 ** it) % 10
bucket[digit].append(var)
# 分桶完成
li.clear()
# 粪桶的数据,再次排序后,放进li中
for buc in bucket:
li.extend(buc)
it += 1
if __name__ == '__main__':
import random
li = [random.randint(0, 100) for _ in range(100)]
print(li)
radix_sort(li)
print(li)
复杂度分析:
参考博客:

