A Survey on Knowledge Graphs:Representation, Acquisition and Applications论文阅读摘要(一)综述
论文标题(A Survey on Knowledge Graphs:Representation, Acquisition and Applications)
下载链接:https://arxiv.org/abs/2002.00388
知识图谱(Knowledge Graph)
知识图谱是对事实的结构化表示,由实体、关系和语义描述构成。
- 实体可以是真实世界的对象也可以是抽象的概念
- 关系代表实体之间的关系
- 语义描述包含具体有定义明确的类型和属性
知识图谱与知识库同义,但稍有不同。当考虑知识图谱的图结构时,它可以看作是一个图,当它涉及形式语义的时候,它可以作为对事实进行解释和推理的知识库。
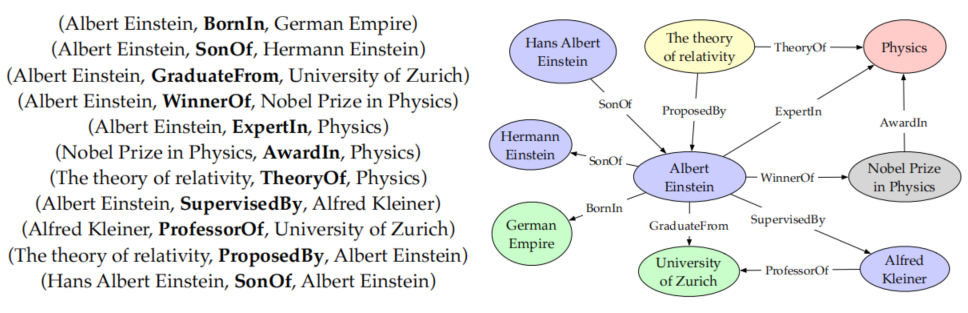
在资源描述框架下(RDF),知识可以事实三元组的形式(head,relation,tail)或(subject,predicate,object)的形式表示;知识也可以表示为为一个有向图,其中节点是实体,边是关系
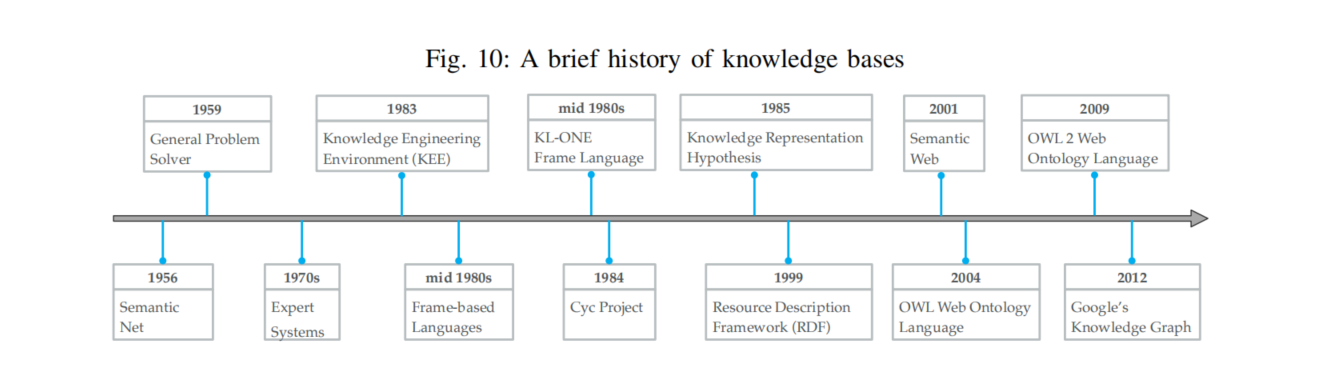
历史背景
-
诞生:
最早可以追溯1956年Richens提出的semantic net(语义网)概念 -
一般问题求解
符号逻辑知识可以追溯到1959年的一般问题求解器。知识库首次被使用于基于知识的推理和问题解决系统。
其中MYCIN是当时著名的基于规则的医学诊断专家系统之一,它的知识库大约有600条规则。 -
19世纪末
后来,人类知识表示的社区看到了基于框架的语言、基于规则和混合表示的发展。
大约19世纪末,Cyc项目开始(1984)。
资源描述框架RDF(1999)和Web本体语言OWL(2004)相继发布,成为语义网络的重要标准
依次诞生:Cyc,RDF(Resource description framework) , OWL(Web Ontology Language) => 变成Semantic Web的重要标准
随后,许多开放知识库或本体被发布:
WordNet,DBpedia,YAGO,and Freebase => Stokman and Vries提出了结构知识的现代概念 -
2012年
Google搜索引擎发布 => 让知识图谱变得更加受关注
与此同时提出了知识融合框架(Knowledge Vault)来构建大规模知识图谱
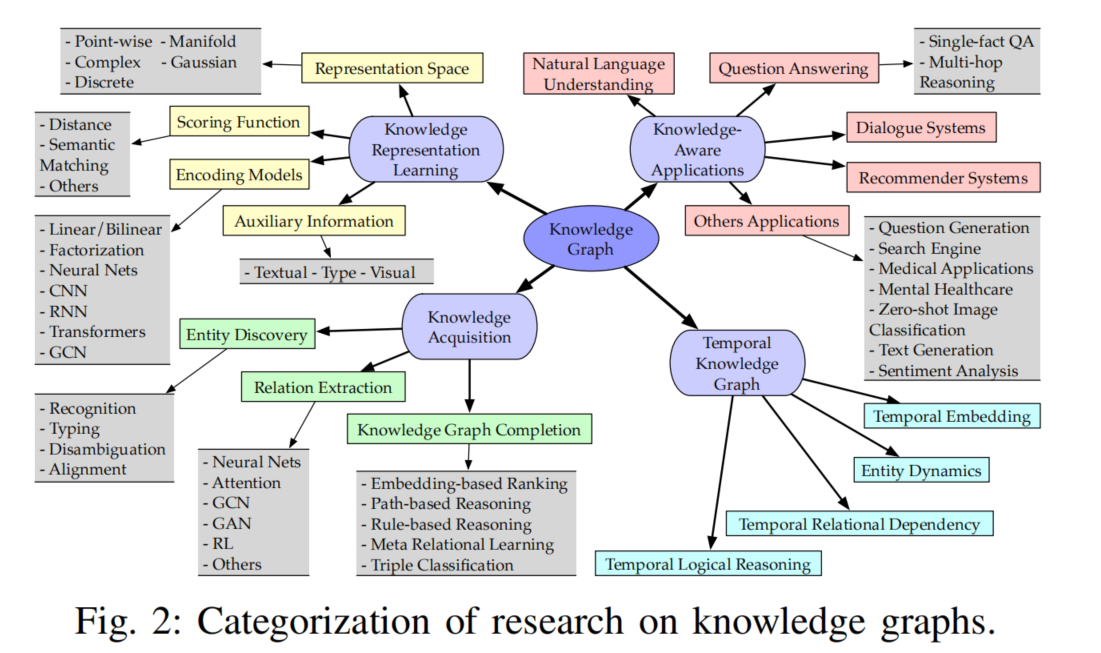
研究的总体分类
包含四个主要方面:
1)知识图谱表示学习(KRL)
2)知识图谱获取
3)时序知识图谱
4)知识感知应用
简单图示:
知识表示学习KRL(Knowledge Representation Learning)
KRL是知识图谱的关键研究问题,为许多知识获取任务和后续下游应用铺平道路。
作者将它分为4个方面
-
表示空间 representation space
实体和关系是如何表示的 -
打分函数 scoring function
测量事实三元组的合理性 -
编码模型 encoding models
表示和学习关系交互的编码模型 -
辅助信息 auxiliary information
将辅助信息嵌入到方法中
表示学习包括:point-wise space点向空间、manifold流形、complex verctor space复向量空间、Gaussian distribution高斯分布和discrete space离散空间
打分制通常分为:distance-based(基于距离)和similarity matching based(基于相似性匹配)的打分函数
辅助信息包括:文本信息、视觉信息和类型信息。
现阶段的研究方向关注在编码模型,包括linear/bilinear models(线性/双线性模型),factorization(因式分解)和neural network(神经网络)
知识获取(Knowledge Acquisition)
知识获取任务分为三类:
-
知识图谱补全 KGC(Knowledge Graph Completion)
分为:- 基于嵌入的排序 embedding-based ranking
- 关系路径推理 relation path reasoning
- 基于规则的推理 rule-based reasoning
- 元关系学习 meta relational learning
-
关系提取 RE(relation extraction)
运用了:- 注意力机制 attention mechanism
- 图卷积网络 graph convolutional networks (GCNs)
- 对抗训练 adversarial training
- 强化学习 reinforcement learning
- 深度残差学习 deep residual learning
- 转移学习 transfer learning
-
实体发现 entity discovery
包括:- 识别 recognition
- 消除歧义 disambiguation
- 类型化 typing
- 校准(对齐) alignment
第一个用于扩展现有的知识图谱,而另外两个是从文本中发现新知识(即关系和实体)
时序知识图谱(Temporal Knowledge Graphs)
时序知识图谱结合时序信息进行表示学习,此研究分为4个领域:
1)时序嵌入 (temporal embedding)
2)实体动态 (entity dynamics)
3)时序关系依赖(temporal relational dependency)
4)时序逻辑推理( temporal logical reasoning)
知识感知应用(Knowledge-aware Applications)
包括:
- 自然语言理解 natural language understanding (NLU)
- 问答系统 question answering
- 推荐系统 recommendation systems
- 各种现实世界任务 miscellaneous real-world tasks
这些应用程序注入知识以促进表示学习
发展前景和方向
复杂推理 Complex Reasoning
知识表示和推理的数值计算需要一个连续的向量空间来捕获实体和关系之间的语义。虽然嵌入式方法对复杂逻辑推理有局限性,但关系路径和符号逻辑的两个方向值得进一步探索。一些很有前途的方法比如:循环关系路径编码、基于GNN的消息传递知识图谱、基于强化学习的路径查找和推理等,都是处理复杂推理的新方法。
对于逻辑规则和嵌入的组合,最近的一些工作将马尔可夫逻辑网络(Markov logic network)与KGE结合起来,旨在利用逻辑规则并处理它们的不确定性。
利用有效的嵌入实现对不确定性和领域知识的概率推理将是一个值得关注的研究方向。
统一的框架 Unified Framework
大多数的工作都用不同的模型分别制定了知识获取KGC和关系提取,Han等人提出将它们置于同一屋檐下,并提出了一个相互关注的知识图谱和文本信息共享的联合学习框架。
对知识表示和推理的统一理解很少被探索,但是,以一种类似于图网络结构的统一框架的方式进行统一的研究值得探索。
可解释性 Interpretability
最近的神经模型在透明性和可解释性方面有局限性,尽管它们获得了令人印象深刻的性能。一些方法结合黑盒神经模型和符号推理,通过结合逻辑规则来提高互操作性。可解释性可以说服人们相信预测。因此,进一步的工作应涉及提高预测知识的可解释性和可靠性。
可扩展性 Scalability
可扩展性在大规模的知识图谱中是至关重要的。
知识聚合 Knowledge Aggregation
全球知识的聚集是知识感知应用的核心。例如:推荐系统使用知识图谱对用户-项目相互和文本分类进行建模,将文本和知识图谱编码到语义空间中。现有的知识聚合方法大多设计了注意力机制和GNNs等神经结构。自然语言处理社区通过Transformer和BERT模型等变体的大规模预训练得到了发展。与此同时,最近的一项发现表明,对在非结构化文本上的预训练语言模型可以获得某些事实知识。大规模的预训练可以是一种直接的知识注入方式。然而,以一种有效的、可解释的方式重新思考知识聚合的方式也具有重要意义。
自动构造 Automatic Construction and Dynamics
当前的知识图谱高度依赖手工构造,这是劳动密集型且是昂贵的。知识图谱在不同认知智能领域的广泛应用,需要从大规模的非结构化内容中自动构建知识图谱。近年来的研究主要是在半自动建设,面对多模态、异构和大规模应用,自动化建设仍然是一个巨大的挑战。
主流研究集中在静态知识图谱上,包括预测时间范围的有效性,学习时间信息和实体动力学。许多事实只在一个特定的时期成立。动态知识图谱以及捕获动态的学习算法,可以通过考虑时间性质来解决传统知识表示和推理的局限性。
**仅供自己学习使用,如有错误欢迎指出**

 浙公网安备 33010602011771号
浙公网安备 33010602011771号