

3.Spark设计与运行原理,基本操作
1、Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
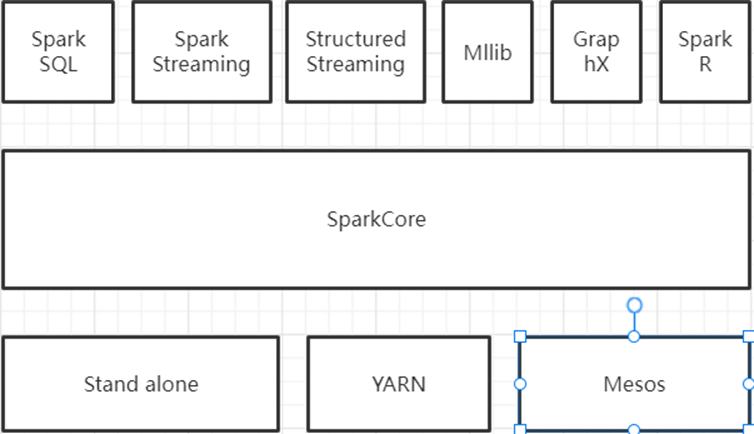
1)SparkCore:
Spark Core 是整个BDAS 生态系统的核心组件,是一个分布式大数据处理框架。Spark Core提供了多种资源调度管理,经过内存计算、有向无环图(DAG)等机制保证分布式计算的快速,并引入了RDD 的抽象保证数据的高容错性。
2)SparkSQL:
Spark SQL 的前身是Shark,它发布时Hive 能够说是SQL on Hadoop 的惟一选择(Hive 负责将SQL 编译成可扩展的MapReduce 做业),鉴于Hive 的性能以及与Spark 的兼容。
3)SparkStreaming:
Spark Streaming 是一个对实时数据流进行高吞吐、高容错的流式处理系统,能够对多种数据源(如Kafka、Flume、Twitter 和ZeroMQ 等)进行相似Map、Reduce 和Join 等复杂操做,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。
4)Mllib和GraphX:
主要一些算法库
5)FusionInsight Spark:
默认运行在YARN集群之上。
6)Structured Streaming:
2.0版本之后的spark独有。知道自己的不足,增加了自己的产品。
7)SparkR:
R 是遵循GNU 协议的一款开源、免费的软件,普遍应用于统计计算和统计制图,可是它只能单机运行。为了可以使用R 语言分析大规模分布式的数据,伯克利分校AMP 实验室开发了SparkR,并在Spark 1.4 版本中加入了该组件。经过SparkR 能够分析大规模的数据集,并经过R Shell 交互式地在SparkR 上运行做业。
2、请详细阐述Spark的几个主要概念及相互关系:
Master, Worker; RDD,DAG;
Application, job,stage,task; driver,executor,Claster Manager
DAGScheduler, TaskScheduler.
1)Master
主要是控制、管理和监督整个spark集群。
2)Worker
worker是spark的工作节点,用于执行任务的提交。
3)RDD
是Spark中最重要的一个概念,是弹性分布式数据集,是一种容错的、可以被并行操作的元素集合,是Spark对所有数据处理的一种基本抽象。
4)DAG
DAG是一个有向无环图,在Spark中, 使用 DAG 来描述我们的计算逻辑。
5)Application
是Spark API 编程的应用程序,它包括实现Driver功能的代码和在程序中各个executor上要执行的代码,一个application由多个job组成。
6)Job
是有多个stage构建的并行的计算任务,job是由spark的action操作来触发的,在spark中一个job包含多个RDD以及作用在RDD的各种操作算子。
7)Stage
DAG Scheduler会把DAG切割成多个相互依赖的Stage,划分Stage的一个依据是RDD间的宽窄依赖。
8)Task
是spark中最独立的计算单元,由Driver Manager发送到executer执行,通常情况一个task处理spark RDD一个partition。
9)Driver
驱动器节点,它是一个运行Application中main函数并创建SparkContext的进程。
10)Executor
是真正执行计算任务的组件,它是application运行在worker上的一个进程。
11)Cluster Manager
集群管理器,它存在于Master进程中,主要用来对应用程序申请的资源进行管理,根据其部署模式的不同,可以分为local,standalone,yarn,mesos等模式。
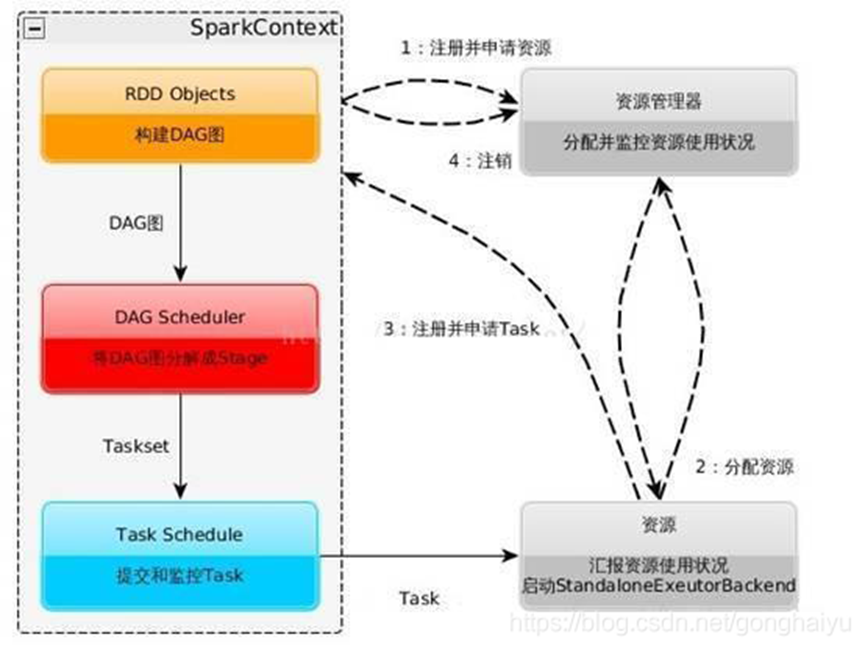
12)DAGScheduler
是面向stage的高层级的调度器,DAG Scheduler把DAG拆分为多个Task,每组Task都是一个stage,解析时是以shuffle为边界进行反向构建的,每当遇见一个shuffle,spark就会产生一个新的stage,接着以TaskSet的形式提交给底层的调度器(task scheduler),每个stage封装成一个TaskSet。
13)TaskScheduler
负责每一个具体任务的执行。
相互关系
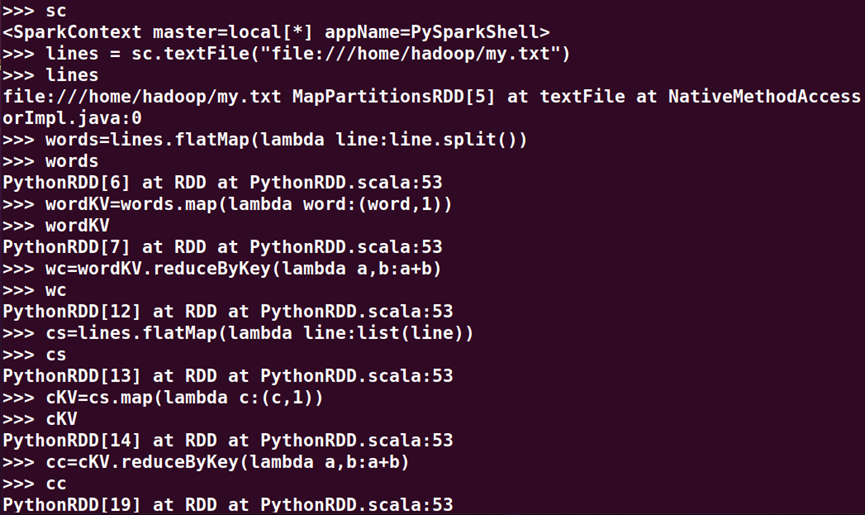
3、在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
>>> sc
>>> lines = sc.textFile("file:///home/hadoop/my.txt")
>>> lines
>>> words=lines.flatMap(lambda line:line.split())
>>> words
>>> wordKV=words.map(lambda word:(word,1))
>>> wordKV
>>> wc=wordKV.reduceByKey(lambda a,b:a+b)
>>> wc
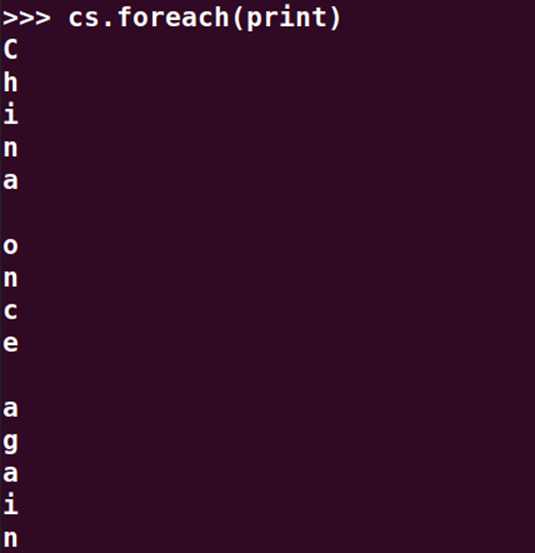
>>> cs=lines.flatMap(lambda line:list(line))
>>> cs
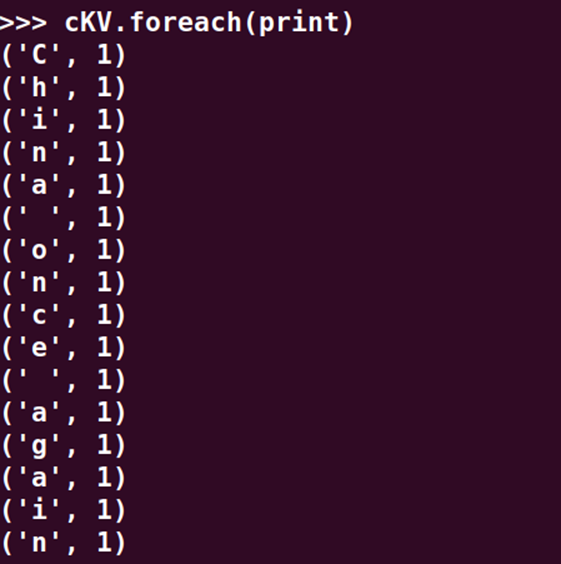
>>> cKV=cs.map(lambda c:(c,1))
>>> cKV
>>> cc=cKV.reduceByKey(lambda a,b:a+b)
>>> cc
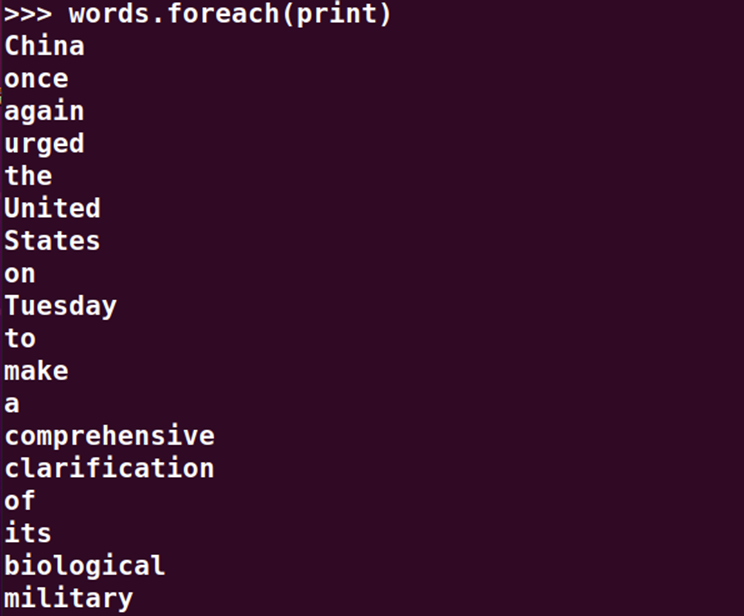
>>> lines.foreach(print)

>>> words.foreach(print)
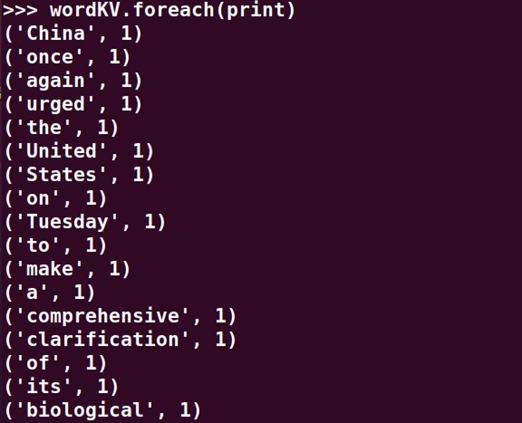
>>> wordKV.foreach(print)
>>> cs.foreach(print)
>>> cKV.foreach(print)
>>> wc.foreach(print)

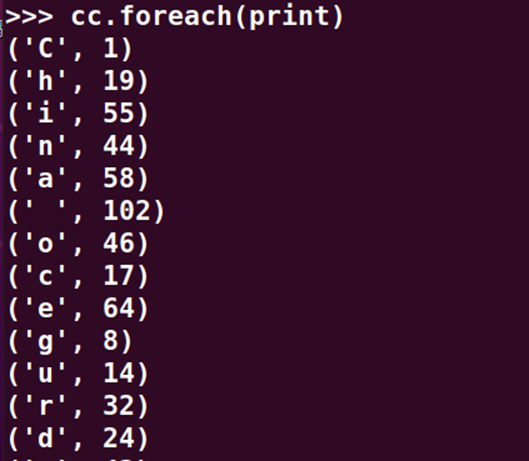
>>> cc.foreach(print)
RDD转换关系图

