

SQL Server调优
介绍一下背景,我们公司负责运维N多的应有系统,负责提供良好的软、硬件环境,至于应用的开发质量,我们就无能为力了
解决这个问题,我的思路是:
找出CPU占用最大的语句。
分析查询计划。
优化。
1、找出语句
使用SQL Server自带的性能报表(不是报表服务),找出CPU占用最大的语句。如图1所示
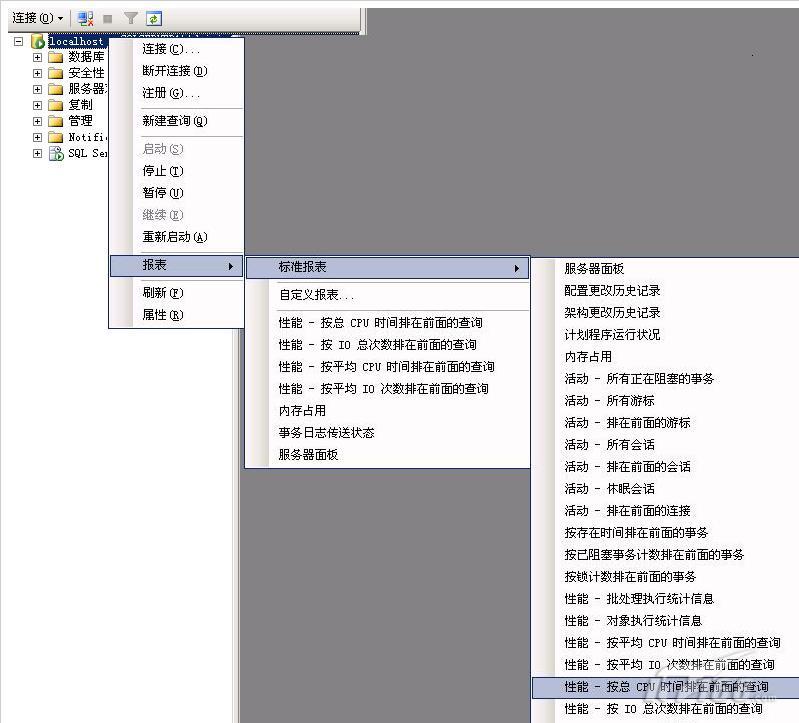
图1 性能报表
我选取了“性能-按总CPU时间排在前面的查询”,得出以下两张报表,如图2所示:
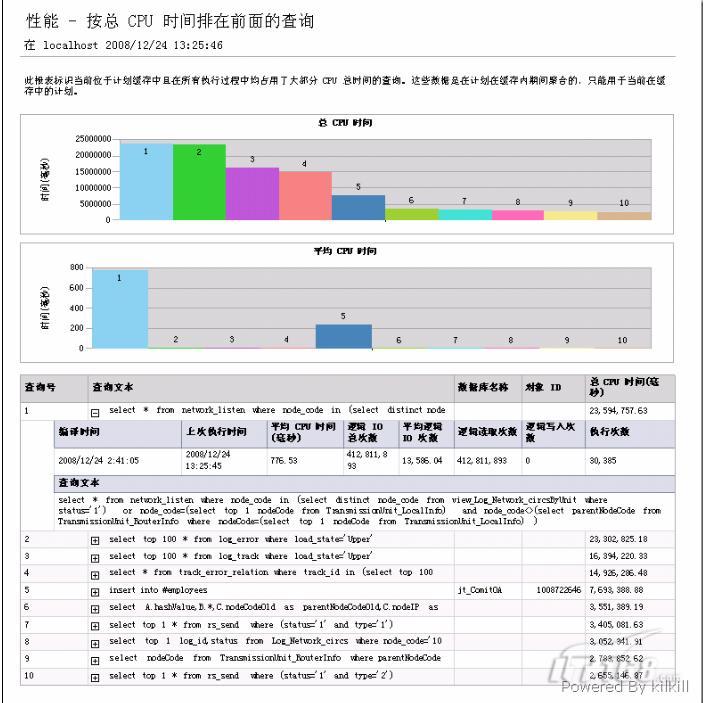
图2 性能-按总CPU时间排在前面的查询
在报表中不能直接把语句Copy出来,非得让我另存为Excel才能Copy语句;而且经常标示不了是语句属于哪个数据库 。
费了我九牛二虎之力才找出该条语句在哪个数据库执行,然后马上备份数据库,在另一个非生产数据库上面还原,创造实验环境。
废话少说,我把语句Copy出来,顺便整理了一下格式。如下:
select *
from network_listen
where
node_code in
(
select distinct node_code
from view_Log_Network_circsByUnit
where status='1'
)
or
node_code=
(
select top 1 nodeCode
from TransmissionUnit_LocalInfo
)
and
node_code<>
(
select parentNodeCode
from TransmissionUnit_RouterInfo
where nodeCode=
(
select top 1 nodeCode from TransmissionUnit_LocalInfo
)
)
2、分析语句
执行计划如下:
图3 查询计划全图
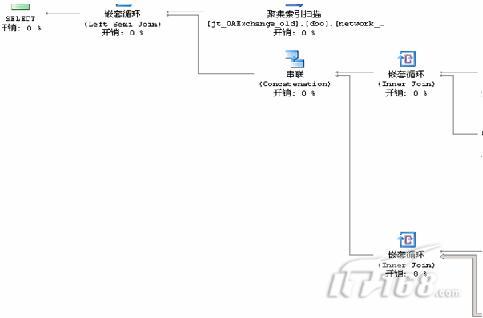
图4 查询计划1

图5 查询计划2

图6 查询计划3
从整个查询计划来看,主要开销都花在了图5的那个部分——两个“聚集索引扫描”。
查看一下这两个数“聚集索引扫描”,搞什么飞机呢?

奇怪了,查询语句里面没有Log_Nwtwork_circs 这个表啊,再仔细分析一下这个执行计划,嫌疑最大的就是view_Log_Network_circsByUnit这个视图了。
查看一下这个试图的定义:
CREATE VIEW [dbo].[view_Log_Network_circsByUnit]
AS
SELECT B.*
FROM (
SELECT node_code, MAX(end_time) AS end_time
FROM Log_Network_circs
GROUP BY node_code
) A
LEFT OUTER JOIN
dbo.Log_Network_circs B
ON
A.node_code = B.node_code
AND
A.end_time = B.end_time
看着有点晕是吧,那么看看下图
3、优化
SQL写得好不好,咱不说,反正我是不能改SQL的,而且应该可以判断出整个查询最耗时的地方就是用在搞这张试图了。
那就只能针对这个试图调优啦。仔细观察这个试图,实际上就涉及到一个表 Log_Network_circs,下面是该表的表结构:
[log_id] [varchar](30) NOT NULL,
[node_code] [varchar](100) NULL,
[node_name] [varchar](100) NULL,
[server_name] [varchar](100) NULL,
[start_time] [datetime] NULL,
[end_time] [datetime] NULL,
[status] [varchar](30) NULL,
CONSTRAINT [PK_LOG_NETWORK_CIRCS] PRIMARY KEY CLUSTERED
(
[log_id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
数据量有489957条记录,不算太大。
根据 3、经常与其他表进行连接的表,在连接字段上应该建立索引;
感觉上得在 node_code 和 end_time 这两字段上建立一个复合索引,大概定义如下:
ON Log_Network_circs
(
node_code ASC,
end_time ASC
)
保险起见,我把需要调优的语句copy到一个文件里,然后打开“数据库引擎优化顾问”,设置好数据库,得出以下调优结果:

CREATE NONCLUSTERED INDEX [_dta_index_Log_Network_circs_24_559341057__K2_K6] ON [dbo].[Log_Network_circs]
(
[node_code] ASC,
[end_time] ASC
)WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [PRIMARY]
嗯,结果差不多,具体参数再说。
按照“数据库引擎优化顾问”给出的建议,建立 STATISTICS 和 INDEX 。
再看看优化后的执行计划
明显查询 view_Log_Network_circsByUnit 这个视图的执行计划不一样了。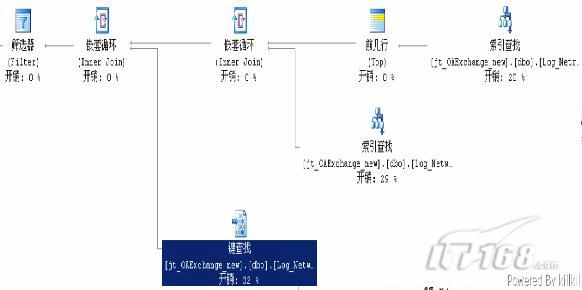
不看广告,看疗效,使用统计功能。执行以下语句:
SET STATISTICS TIME on;
(2 行受影响)
表 'Log_Network_circs'。扫描计数 2,逻辑读取 13558 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'TransmissionUnit_RouterInfo'。扫描计数 0,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'TransmissionUnit_LocalInfo'。扫描计数 3,逻辑读取 6 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'network_listen'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 719 毫秒,占用时间 = 719 毫秒。
(2 行受影响)
表 'Log_Network_circs'。扫描计数 2,逻辑读取 9 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'TransmissionUnit_RouterInfo'。扫描计数 0,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'TransmissionUnit_LocalInfo'。扫描计数 3,逻辑读取 6 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'network_listen'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 2 毫秒。
逻辑读取数,总执行时间都大大缩减,开来调优还是挺成功的。

