
Round 11
前言
好不容易考场上想到5道题的正解,本来以为这次可以考好,但是 T1,T5 挂了,T6 就是调不出来(考完后还调了几个小时)。
T1
很简单的一道题,我们先把 \(0 \sim n - 1\) 每个数计算后存到数组里,然后对于每种相同的数,我们在比它大的数里选 \(m\) 个。
对于选每种数都算出一个答案,最后取最大即可。
至于为什么只有这么点分,因为考试的时候忘记了一个很基本的事情,就是当选定一种数之后,只能让比它大的数通过减少变得跟它一样。
还有一点,就是 map 常数太大了,会被卡掉,明明可以排序的。
code
#include <cstdio>
#include <algorithm>
#include <map>
#define LL long long
using namespace std;
const int N = 3e5 + 5;
LL T, n, m, t, ans, a[N], b[N], la;
int main() {
scanf("%lld", &T);
while (T--) {
scanf("%lld %lld %lld", &n, &m, &t);
for (LL i = 1; i <= n; i++)
a[i] = (i - 1) * (i - 1) % m + 1;
sort(a + 1, a + n + 1);
ans = 0, a[n + 1] = 0, la = 0;
for (int i = 1; i <= n; i++)
if (a[i] != a[i + 1]) {
ans = max(ans, i - la + min(t, n - i));
la = i;
}
printf("%lld\n", ans);
}
return 0;
}
T2
考试时唯一过了的一道题。
并查集,以前还考过。
对于每个字母,我们记录第一次出现的字符串是哪个。
如果当前字符串枚举到一个出现过的字母,就把当前字符串和那个字母第一次出现的字符串合并。
最后我们查一下哪些的父亲是自己的个数就是答案。
code
#include <cstdio>
#include <iostream>
#include <cstring>
using namespace std;
const int N = 2e5 + 5, M = 30, P = 1e6 + 5;
int fa[N], n, l, ans, f[N];
char s[P];
inline int FindSet(int x) {
if (x == fa[x])
return x;
return fa[x] = FindSet(fa[x]);
}
inline void UnionSet(int x, int y) {
int xx = FindSet(x), yy = FindSet(y);
if (xx != yy)
fa[xx] = yy;
}
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i++)
fa[i] = i;
for (int i = 1; i <= n; i++) {
scanf(" %s", s + 1);
l = strlen(s + 1);
for (int j = 1; j <= l; j++)
if (!f[s[j] - 'a'])
f[s[j] - 'a'] = i;
else if (f[s[j] - 'a'] != i)
UnionSet(i, f[s[j] - 'a']);
}
for (int i = 1; i <= n; i++)
ans += i == FindSet(i);
printf("%d\n", ans);
return 0;
}
T3
记忆化搜索。
考试时打的搜索剪枝。
先初始化前缀和 '#' 的个数,方便在 dfs 的时候查询。
dfs 的思路就是如果算出当前矩形完全消除的答案。
再将它分成两部分,分别计算完全消除答案,取最小就是消除当前矩形中所有方块的最小答案了。
一个剪枝:通过前缀和查询当前矩形中有多少方块,如果数量为 \(0\),那个可以直接返回 \(0\)了。
至于考试是为什么不打记忆化,我也想打记忆化,但是我的搜索状态没法记忆化。
code
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 55;
int n, p[N][N], f[N][N][N][N];
char ch;
inline int dfs(int x1, int y1, int x2, int y2) {
if (!(p[x2][y2] + p[x1 - 1][y1 - 1] - p[x2][y1 - 1] - p[x1 - 1][y2])) //如果当前矩形中没有方块,直接返回。
return 0;
if (f[x1][y1][x2][y2]) //当前矩形已经求过 ,没必要再求一边。
return f[x1][y1][x2][y2];
int res = max(x2 - x1 + 1, y2 - y1 + 1); //不分成两部分的答案。
for (int i = x1; i < x2; i++) //分别计算横着分和竖着分的答案。
res = min(res, dfs(x1, y1, i, y2) + dfs(i + 1, y1, x2, y2));
for (int i = y1; i < y2; i++)
res = min(res, dfs(x1, y1, x2, i) + dfs(x1, i + 1, x2, y2));
return f[x1][y1][x2][y2] = res;
}
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
scanf(" ");
for (int j = 1; j <= n; j++) {
ch = getchar();
p[i][j] = p[i - 1][j] + p[i][j - 1] - p[i - 1][j - 1] + (ch == '#'); //前缀和。
}
}
printf("%d\n", dfs(1, 1, n, n));
return 0;
}
T4
概率dp。
暴力的思路是枚举哪一条边不选,算出答案,求出所有答案的最小值。
但如果我们枚举的是点,再在以这个点为边的起点的边中选一条边不选,那么时间复杂度就会降到 \(O(nm)\),足以通过此题。
我们先来考虑不删怎么算答案,根据期望的线性性,我们可以从 \(n\) 倒推。
对于当前点 \(i\) 的期望,我们枚举与它连边的点 \(j\),那么 \(j\) 贡献给 \(i\) 的期望为 \(\dfrac{1}{s} \times f_j\)(\(f_j\) 是从 \(n\) 到 \(j\) 的期望边数,\(s\) 是 \(i\) 的出度,也就是以 \(i\) 为起点的边的数量)。
那么我们现在要断掉以 \(i\) 为起点的一条边,根据贪心,我们要让期望边数最小,那么我们肯定就要从枚举到的 \(j\) 里期望最大的删掉。
还有一个很重要的点每条边的起点一定小于终点,所以不会出现环。
注意:如果一个点出边只有一条,那么就不能删掉,因为我们要保证每个点都可以到 \(n\)。
code
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
const int N = 605;
int n, m;
vector<int> ve[N];
double f[N], ans = 1e9;
int main() {
scanf("%d %d", &n, &m);
for (int i = 1, u, v; i <= m; i++) {
scanf("%d %d", &u, &v);
ve[u].push_back(v);
}
for (int i = 1; i < n; i++) { //枚举要断掉的边的起点
for (int j = 1; j <= n; j++) //每次都算一个答案
f[j] = 0;
for (int j = n - 1; j; j--) { //倒推算出每个点的期望,可以倒推的原因是保证了u<v
double s = 0;
for (auto k : ve[j]) //算当前点期望
f[j] += f[k], s = max(s, f[k]);
if (i == j && ve[j].size() > 1) //如果当前点是我们要断边的那个点并且出度大于1说明可以选一条最长的断掉
f[j] -= s, f[j] /= (ve[j].size() - 1);
else
f[j] /= ve[j].size(); //否则不断
f[j]++;
}
ans = min(ans, f[1]);
}
printf("%.6lf\n", ans);
return 0;
}
T5
考试时没算 \(f_0 = 1\),导致从 \(n = 6\) 开始就错了,没发现错的原因是暴力一起打错了。
这道题其实很简单,我们 dp 时要保证不算重,只需要保证后几位不同,前面可以随便选。
大概是这样:
这样是选后四个。
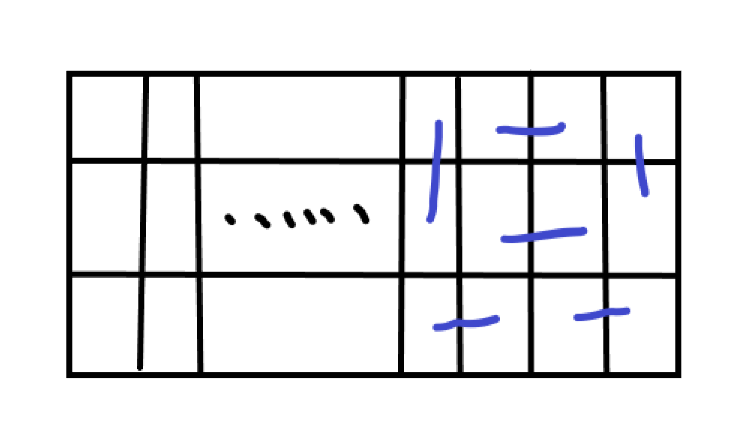
选后两个:
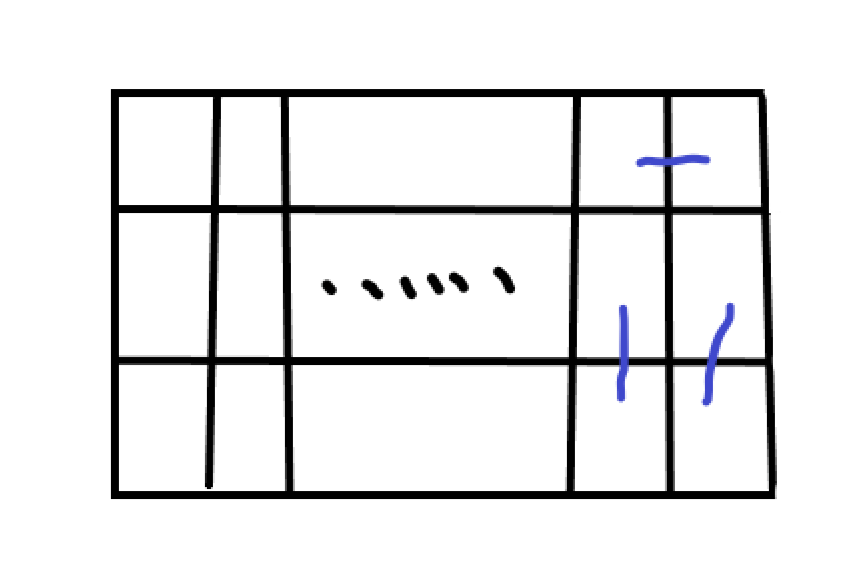
很明显发现他们不一样,那么在这两种情况下,前面的都可以随便选,因为保证了最后面不同。
画一下发现后 \(2\) 个有 \(3\) 种,其他都是 \(2\) 种。
这是后两个的:
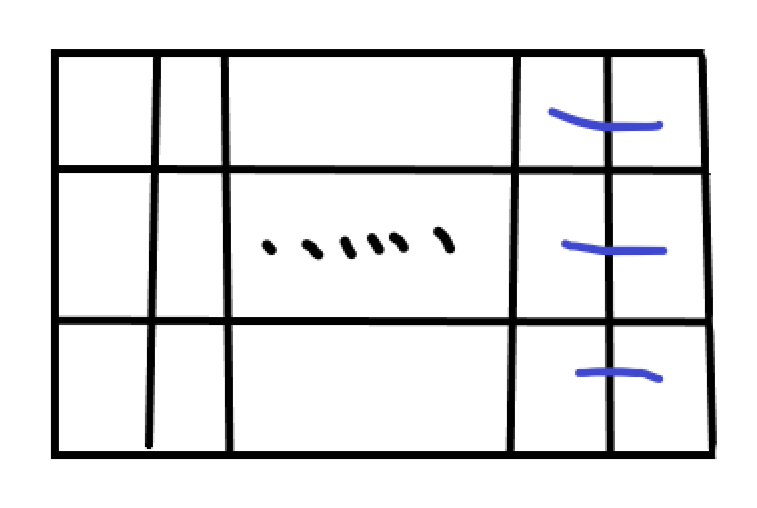
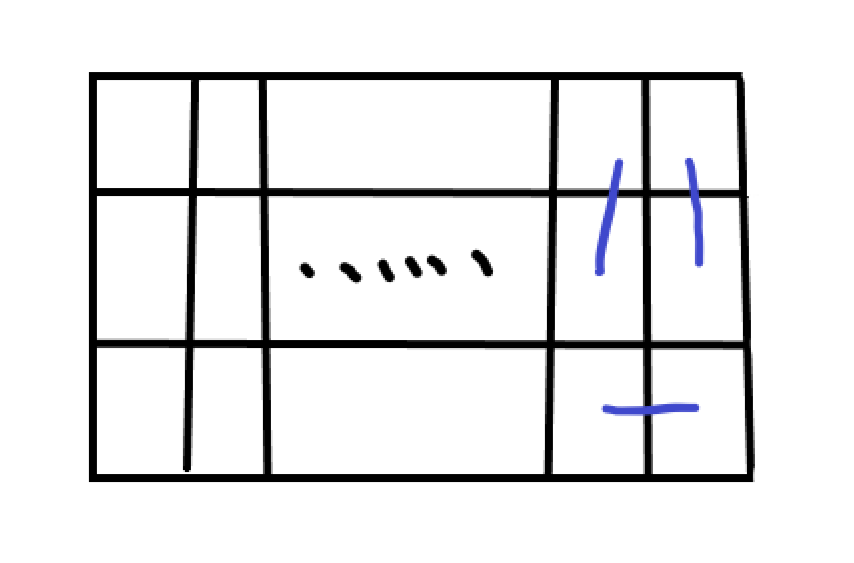
这是后四个的:
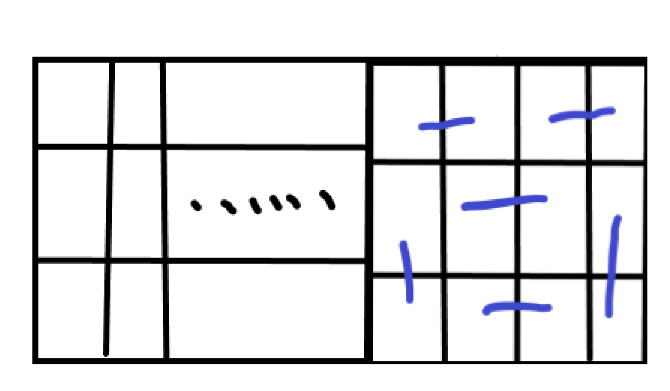
后四个以上的就在后四个的基础上在中间加横着的即可,所以后六个就是这样:
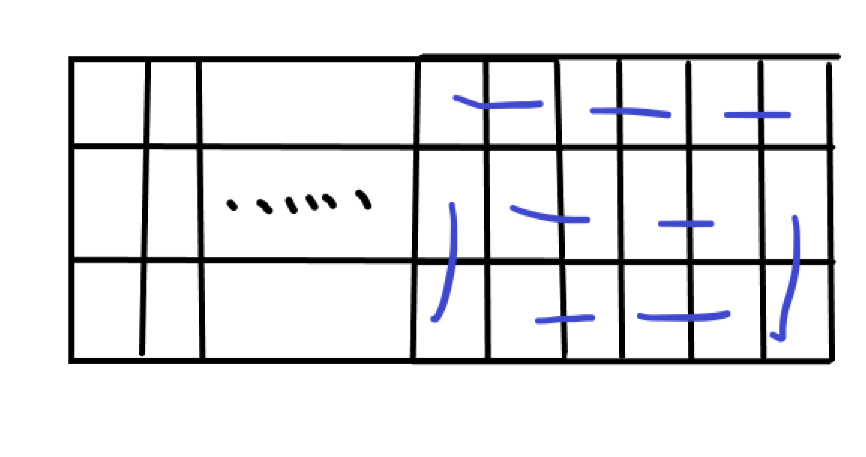
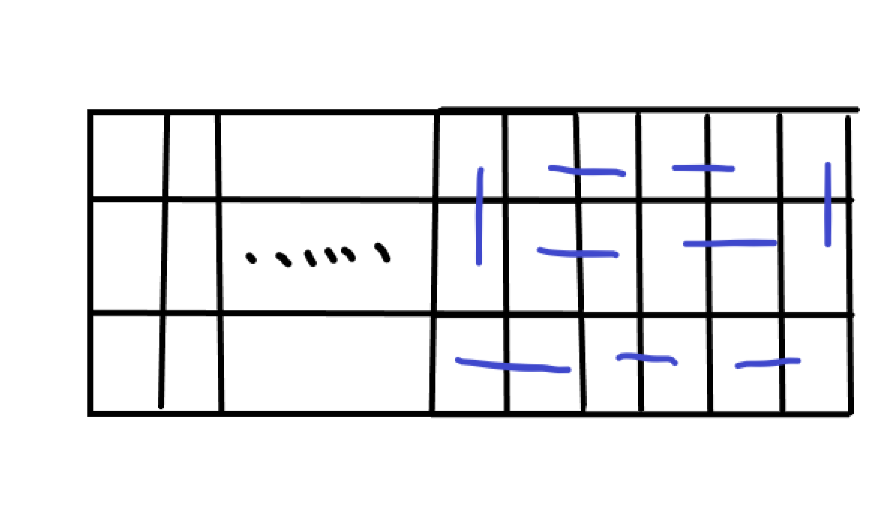
这个时候状态转移方程也就出来了,\(i \in [1, \dfrac{n}{2}]\)(因为为了方便我把 \(n\) 除以 \(2\) 了):
注意:\(f_0 = 1\)。(100 分就这样没了)
这样复杂度是 \(O(n)\) 的,但是我们可以把系数 \(2\) 提出来,得到:\(f_i = 3f_{i - 1} + 2\sum_{j = 0}^{i - 2}f_{j}\)。
所以我们维护两个,一个数是前缀和 \(s\),一个数是 \(f_{i - 1}\)。
很明显更新 \(f_i\):\(f_i = 3 \times f_{i - 1} + 2 \times s\),\(sum = 1 \times f_{i - 1} + 1 \times sum\)。
用乘号的原因是矩阵加速已经呼之欲出了。
初始矩阵:
\(sum\) 其实就是 \(f_0 + f_1\)(别忘了 \(f_0\),重要的事情说三遍)
加速矩阵:
用初始矩阵乘上加速矩阵的 \(n - 2\) 次方后矩阵的第一项就是答案。
code
#include <cstdio>
#include <cstring>
#define LL long long
const int N = 1e6 + 5;
const LL Mod = 1e9 + 7;
struct Matrix {
LL a[5][5];
inline Matrix() { memset(a, 0, sizeof(a)); }
inline Matrix operator*(Matrix b) { //矩阵乘法,因为只有2*2,所以没写循环
Matrix c;
c.a[1][1] = (a[1][1] * b.a[1][1] % Mod + a[1][2] * b.a[2][1] % Mod) % Mod;
c.a[1][2] = (a[1][1] * b.a[1][2] % Mod + a[1][2] * b.a[2][2] % Mod) % Mod;
c.a[2][1] = (a[2][1] * b.a[1][1] % Mod + a[2][2] * b.a[2][1] % Mod) % Mod;
c.a[2][2] = (a[2][1] * b.a[1][2] % Mod + a[2][2] * b.a[2][2] % Mod) % Mod;
return c;
}
} ans, s;
inline void qkpow(LL x) { //快速幂
while (x) {
if (x & 1)
ans = ans * s;
s = s * s;
x >>= 1;
}
}
LL n;
int main() {
scanf("%lld", &n);
n /= 2;
if (n == 1)
return puts("3"), 0;
if (n == 2)
return puts("11"), 0;
ans.a[1][1] = 11, ans.a[1][2] = 4; //初始矩阵
s.a[1][1] = 3, s.a[1][2] = 1; //加速矩阵
s.a[2][1] = 2, s.a[2][2] = 1;
qkpow(n - 2);
printf("%lld\n", ans.a[1][1]);
return 0;
}
T6
用平衡树维护数列。
对于操作 \(2\) 直接用两个 split 将 \(x\) 裂出来输出 \(key\) 即可。
对于操作 \(1\),我们肯定要先找一个 \(1 \sim x - 1\) 中下标最大的但是当前高度小于 \(y\) 的,记为 \(a\)。
注意:\(a\) 是从平衡树中分裂出来的点的下标,并不是真实在数列中的下标,\(a\) 在数列中的下标是 \(a\) 在平衡树中的排名,而 \(x\) 确实在数列中的真实下标
很明显发现 \(a + 1 \sim x\) 会被向左移一格,所以移动数量就是 \(\sum_{i = a + 1}^{x}(h_i - y)\),将 \(y\) 提出来 \(\sum_{i = a + 1}^{x}h_i - (x - a)y\),所以对于求移动个数,在 FHQ 种维护一个 \(sum\) 然后将 \(a + 1 \sim x\) 裂出来就可以算出答案。
更重要的点在于如何对数列进行修改达到题目要求效果。
因为 \(a + 1 \sim x\) 会被向左移一格,所以 \(a + 2\) 到 \(x\) 其实没变,只是向左平移了,而 \(a + 1\) 高于 \(y - 1\) 的部分则是给了 \(a\),给完后移到 \(x\) 后,可以想一下为什么。
现在有一个问题就是如何找到 \(a\)。
我们可以维护一个 \(mi\),表示在当前点为根的子树中,最小高度是多少,然后写一个 find 函数。
我们先把 \(1 \sim x - 1\) split 出来,然后我们去这颗分裂出来的树中找,对于当前节点 \(rt\),如果右子树有小于 \(y\) 的就递归右子树,否则如果 \(rt\) 的 \(key\) 小于 \(y\) 就返回 \(rt\),如果还是不行,就递归左子树,如果 \(rt = 0\),就返回 \(0\),因为没找到小于 \(y\) 的。
因为我们保证了先找右子树,再找根,最后找左子树,所以只要找到答案一定就是离 \(x\) 最近的。
注:如果操作 \(1\) 的 \(y\) 大于 \(h_{x}\) 那么这次操作也不能进行。
code
#include <cstdio>
#include <cstdlib>
#include <utility>
#include <ctime>
#include <algorithm>
#define LL long long
#define int long long
using namespace std;
const int N = 2e5 + 5;
struct Treap {
int tot, root;
struct node {
int l, r, rank, siz, f;
LL key, sum, mi;
} a[N];
inline int New(int val) {
a[++tot].key = val, a[tot].rank = rand();
a[tot].siz = 1, a[tot].mi = val, a[tot].sum = val;
a[tot].l = a[tot].r = a[tot].f = 0, a[a[tot].l].mi = a[a[tot].r].mi = 1e15; //初始化。
return tot;
}
inline void push_up(int rt) {
a[rt].siz = a[a[rt].l].siz + a[a[rt].r].siz + 1;
a[rt].mi = 1e15; //更新以当前点为根的子树下的最小值,方便find函数使用。
if (a[rt].key)
a[rt].mi = a[rt].key;
if (a[rt].l)
a[rt].mi = min(a[rt].mi, a[a[rt].l].mi);
if (a[rt].r)
a[rt].mi = min(a[rt].mi, a[a[rt].r].mi);
if (!a[a[rt].l].mi)
a[a[rt].l].mi = 1e15;
if (!a[a[rt].r].mi)
a[a[rt].r].mi = 1e15;
a[a[rt].l].f = a[a[rt].r].f = rt; //求出每个点的父节点,方便查询排名。
a[rt].sum = a[a[rt].l].sum + a[a[rt].r].sum + a[rt].key; //更新更新以当前点为根的子树的高度和,方便查询移动个数。
}
inline int merge(int rt1, int rt2) {
if (!rt1)
return rt2;
if (!rt2)
return rt1;
if (a[rt1].rank < a[rt2].rank) {
a[rt1].r = merge(a[rt1].r, rt2);
push_up(rt1);
return rt1;
} else {
a[rt2].l = merge(rt1, a[rt2].l);
push_up(rt2);
return rt2;
}
}
inline pair<int, int> split(int rt, int k) {
if (!rt)
return make_pair(0, 0);
if (a[a[rt].l].siz + 1 <= k) {
pair<int, int> ans = split(a[rt].r, k - a[a[rt].l].siz - 1);
a[rt].r = ans.first;
push_up(rt);
return make_pair(rt, ans.second);
} else {
pair<int, int> ans = split(a[rt].l, k);
a[rt].l = ans.second;
push_up(rt);
return make_pair(ans.first, rt);
}
}
inline int find(int rt, LL k) {
if (!rt)
return 0;
if (a[a[rt].r].mi < k)
return find(a[rt].r, k);
if (a[rt].key < k)
return rt;
return find(a[rt].l, k);
}
inline int get_rank(int rt) {
int res = 0;
for (int i = rt; i; i = a[i].f)
if (a[a[i].f].r == i)
res += a[a[a[i].f].l].siz + 1;
return res + a[a[rt].l].siz + 1;
}
} BST;
int n, q, opt, x, y, T;
signed main() {
srand(time(0));
scanf("%lld", &T);
while (T--) {
scanf("%lld %lld", &n, &q);
BST.tot = BST.root = 0;
for (int i = 1; i <= n; i++) {
scanf("%d", &x);
BST.root = BST.merge(BST.root, BST.New(x));
}
while (q--) {
scanf("%lld", &opt);
if (opt == 1) {
scanf("%lld %lld", &x, &y);
pair<int, int> ans = BST.split(BST.root, x - 1);
int a = BST.find(ans.first, y); //找到离x最近的高度又小于y的点的编号。
int rank = BST.get_rank(a); //求出在序列中真实下标。
BST.root = BST.merge(ans.first, ans.second); //分裂后要合并回去。
pair<int, int> A1 = BST.split(BST.root, x); //将x这个点分裂出来。
pair<int, int> A2 = BST.split(A1.first, x - 1);
if (!a || BST.a[A2.second].key < y) { //如果没有高度比y小的或y大于x的当前高度当前操作就 不能进行。
puts("0");
BST.root = BST.merge(BST.merge(A2.first, A2.second), A1.second);
} else {
BST.root = BST.merge(BST.merge(A2.first, A2.second), A1.second); //将a+1~x裂出来求高度和。
pair<int, int> a1 = BST.split(BST.root, x);
pair<int, int> a2 = BST.split(a1.first, rank);
printf("%lld\n", BST.a[a2.second].sum - (y - 1) * (x - rank));
BST.root = BST.merge(BST.merge(a2.first, a2.second), a1.second); //合并回去。
if (rank == x - 1) { //代码是根据考场恶臭代码调的,其实这个if没必要,只需要下面的else的内容就可以了。
pair<int, int> ans1 = BST.split(BST.root, x);
pair<int, int> ans2 = BST.split(ans1.first, x - 1);
pair<int, int> ans3 = BST.split(ans2.first, rank);
pair<int, int> ans4 = BST.split(ans3.first, rank - 1);
int d = BST.a[ans2.second].key - y + 1;
BST.a[ans4.second].key += d, BST.a[ans2.second].key -= d;
BST.a[ans4.second].sum += d, BST.a[ans2.second].sum -= d;
BST.a[ans4.second].mi += d, BST.a[ans2.second].mi -= d;
BST.root = BST.merge(BST.merge(BST.merge(ans4.first, ans4.second), ans3.second), BST.merge(ans2.second, ans1.second));
} else {
pair<int, int> ans1 = BST.split(BST.root, x);
pair<int, int> ans2 = BST.split(ans1.first, rank - 1);
pair<int, int> ans3 = BST.split(ans2.second, 2);
pair<int, int> ans4 = BST.split(ans3.first, 1); //ans1.second是 x+1~n,ans2.first是 1~a-1,ans3.second是a+2~x,ans4.first是a,ans4.second是a+1。
int d = BST.a[ans4.second].key - y + 1; //a+1高出y-1的部分就是a加上的部分。
BST.a[ans4.second].key -= d, BST.a[ans4.first].key += d;
BST.a[ans4.second].sum -= d, BST.a[ans4.first].sum += d;
BST.a[ans4.second].mi -= d, BST.a[ans4.first].mi += d;
BST.root = BST.merge(ans2.first, BST.merge(ans4.first, BST.merge(ans3.second, BST.merge(ans4.second, ans1.second)))); //合并时将a+1移到x后。
}
}
} else {
scanf("%lld", &x);
pair<int, int> ans1 = BST.split(BST.root, x);
pair<int, int> ans2 = BST.split(ans1.first, x - 1);
printf("%lld\n", BST.a[ans2.second].key);
BST.root = BST.merge(BST.merge(ans2.first, ans2.second), ans1.second);
}
}
for (int i = 1; i <= n; i++) {
pair<int, int> ans1 = BST.split(BST.root, i);
pair<int, int> ans2 = BST.split(ans1.first, i - 1);
printf("%lld ", BST.a[ans2.second].key);
BST.root = BST.merge(BST.merge(ans2.first, ans2.second), ans1.second);
}
puts("");
}
return 0;
}
总结
要理性分配时间,知道 T6 很有可能调不出来应该先打暴力再去检查前面的题,不应该死磕一道题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号