
这次作业:爬取京东商品信息
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver = webdriver.Chrome() def get_good(driver): try: #通过js控制滚轮滑动获取所有商品信息 js_code = ''' window.scrollTo(0,5000); ''' driver.execute_script(js_code)#执行js代码 #等待数据加载 time.sleep(2) good_list = driver.find_elements_by_class_name('gl-item') for good in good_list: good_url = good.find_element_by_css_selector('.p-img a').get_attribute('href') good_name = good.find_element_by_css_selector('.p-name em').text.replace("\n", "--") good_price = good.find_element_by_class_name('p-price').text.replace("\n", ":") good_commit = good.find_element_by_class_name('p-commit').text.replace("\n", " ") good_content = f''' 商品连接:{good_url} 商品名称:{good_name} 商品价格:{good_price} 商品人数:{good_commit} \n ''' print(good_content) with open('jd扩展.txt', 'a', encoding='utf-8')as f: f.write(good_content) next_tag = driver.find_element_by_class_name('pn-next') next_tag.click() time.sleep(2) #递归调用函数 get_good(driver) time.sleep(10) finally: driver.close() if __name__ == '__main__': good_name = input('请输入爬取商品信息:').strip() driver = webdriver.Chrome() driver.implicitly_wait(10) #1. driver.get('https://www.jd.com/') input_tag = driver.find_element_by_id('key') input_tag.send_keys(good_name) input_tag.send_keys(Keys.ENTER)
get_good(driver)
结果部分截图
搜索商品信息凤爪
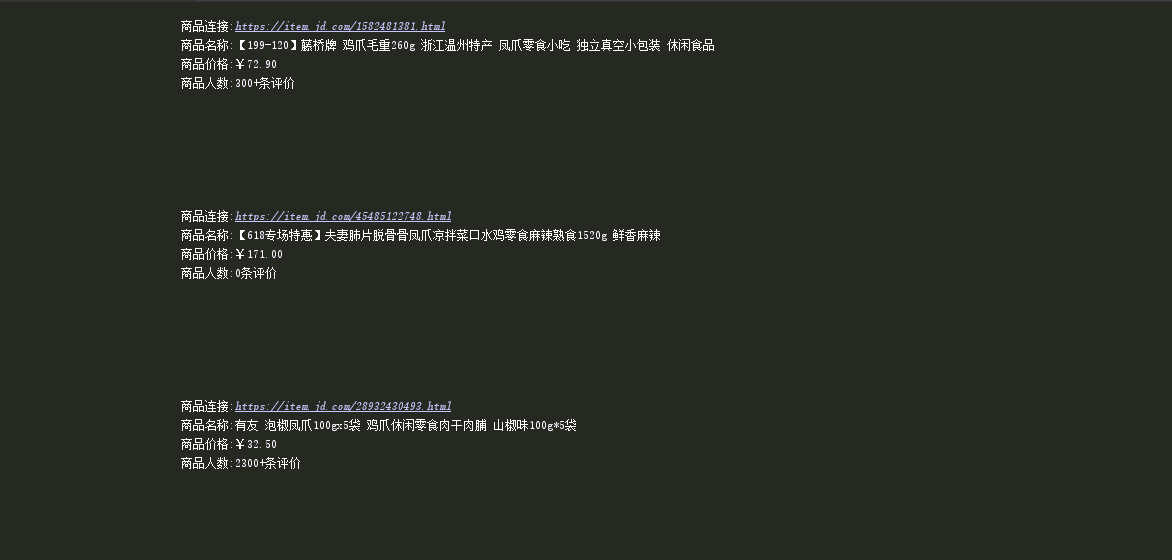
以下为今天所学
1.selenium选择器之Xpath
# from selenium import webdriver # # driver = webdriver.Chrome() from selenium import webdriver driver = webdriver.Chrome() try: #隐式等待:写在get请求前 driver.implicitly_wait(5) driver.get('https://doc.scrapy.org/en/latest/_static/selectors-sample1.html') #显式等待:写在get请求后 #wait.until(...) ''' <html> <head> <base href='http://example.com/' /> <title>Example website</title> </head> <body> <div id='images'> <a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a> <a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a> <a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a> <a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a> <a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a> </div> </body> </html> ''' # 根据Xpath语法查找元素 #/从根节点开始找第一个 html = driver.find_element_by_xpath('/html') #html = driver.find_element_by_Xpath('/head')#报错 print(html.tag_name) #//从根节点开始找任意一个节点 div = driver.find_element_by_xpath('//div') print(div.tag_name) #@ #查找id为images的div节点 div = driver.find_element_by_xpath('//div[@id="image"]') print(div.tag_name) print(div.text) #找到第一个a节点 a = driver.find_element_by_xpath('//a') print(a.tag_name) #找到所有a节点 a_s = driver.find_elements_by_xpath('//a') print(a_s) #找到第一个a节点的href属性 #get_attribute:获取节点中某个属性 a = driver.find_element_by_xpath('//a').get_attribute('href') print(a) finally: driver.close()
2.selenium剩余操作(元素交互操作)
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver = webdriver.Chrome() ''' 点击、清除操作 ''' try: driver.implicitly_wait(10) #1.往jd发送请求 driver.get('https://www.jd.com/') #找到输入框输入围城 input_tag = driver.find_element_by_id('key') input_tag.send_keys('围城') #键盘回车 input_tag.send_keys(Keys.ENTER) time.sleep(2) #找到输入框输入墨菲定律 input_tag = driver.find_element_by_id('key') input_tag.clear() input_tag.send_keys("墨菲定律") #找到搜索按钮点击搜索 button = driver.find_element_by_class_name('button') button.click() time.sleep(10) finally: driver.close() ''' 获取cookies ''' from selenium import webdriver import time driver = webdriver.chrome() try: driver.implicitly_wait(10) driver.get('https://www.zhihu.com/explore') print(driver.get_cookies()) time.sleep(10) finally: driver.close() ''' 选项卡 ''' # 选项卡管理:切换选项卡,有js的方式windows.open,有windows快捷键: # ctrl+t等,最通用的就是js的方式 import time from selenium import webdriver browser = webdriver.Chrome() try: browser.get('https://www.baidu.com') # execute_script: 执行javascrpit代码 # 弹窗操作 # browser.execute_script('alert("tank")') # 新建浏览器窗口 browser.execute_script( ''' window.open(); ''' ) time.sleep(1) print(browser.window_handles) # 获取所有的选项卡 # 切换到第二个窗口 # 新: browser.switch_to.window(browser.window_handles[1]) # 旧: # browser.switch_to_window(browser.window_handles[1]) # 第二个窗口往淘宝发送请求 browser.get('https://www.taobao.com') time.sleep(5) # 切换到第一个窗口 browser.switch_to_window(browser.window_handles[0]) browser.get('https://www.sina.com.cn') time.sleep(10) finally: browser.close() ''' ActionChanges动作链 ''' from selenium import webdriver from selenium.webdriver import ActionChains import time driver = webdriver.Chrome() driver.implicitly_wait(10) driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable') try: # driver.switch_to_frame('iframeResult') # 切换到id为iframeResult的窗口内 driver.switch_to.frame('iframeResult') # 源位置 draggable = driver.find_element_by_id('draggable') # 目标位置 droppable = driver.find_element_by_id('droppable') # 调用ActionChains,必须把驱动对象传进去 # 得到一个动作链对象,赋值给一个变量 actions = ActionChains(driver) # 方式一: 机器人 # 瞬间把源图片位置秒移到目标图片位置 # actions.drag_and_drop(draggable, droppable) # 编写一个行为 # actions.perform() # 执行编写好的行为 # 方式二: 模拟人的行为 source = draggable.location['x'] target = droppable.location['x'] print(source, target) distance = target - source print(distance) # perform:每个动作都要调用perform执行 # 点击并摁住源图片 ActionChains(driver).click_and_hold(draggable).perform() s = 0 while s < distance: # 执行位移操作 ActionChains(driver).move_by_offset(xoffset=2, yoffset=0).perform() s += 2 # 释放动作链 ActionChains(driver).release().perform() time.sleep(10) finally: driver.close() ''' 前进、后退 ''' from selenium import webdriver import time driver = webdriver.Chrome() try: driver.implicitly_wait(10) driver.get('[图片]https://www.jd.com/') driver.get('https://www.baidu.com/') driver.get('https://www.cnblogs.com/') time.sleep(2) # 回退操作 driver.back() time.sleep(1) # 前进操作 driver.forward() time.sleep(1) driver.back() time.sleep(10) finally: driver.close()
3.破解登录
from selenium import webdriver from selenium.webdriver import ChromeOptions import time r''' 步骤: 1.打开文件的查看,显示隐藏文件 2.找到C:\Users\社会我静哥\AppData\Local\Google\Chrome\User Data 删除Default文件 3.重新打开浏览器,并登了百度账号 -此时会创建一个新的Default缓存文件 ''' #获取options对象 options = ChromeOptions() #获取cookies保存路径 # 'C:\Users\社会我静哥\AppData\Local\Google\Chrome\User Data' profile_directory = r'--user-data-dir=C:\Users\社会我静哥\AppData\Local\Google\Chrome\User Data' # 添加用户信息目录 options.add_argument(profile_directory) # 把参数加载到当前驱动中 chrome_options默认参数,用来接收options对象 driver = webdriver.Chrome(chrome_options=options) try: driver.implicitly_wait(10) driver.get('https://www.baidu.com/') ''' BDUSS:FmS2FEZ1JWdVZqUG15YlZ-YnA1cUkwVXR-NGN3Q2laa3NTRzVCNmdBa3YzeTlkRVFBQUFBJCQAAAAAAAAAAAEAAAC7LAGbbG92ZXN1bW1lcjkyNQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAC9SCF0vUghdZW ''' # 添加用户cookies信息 # name、value必须小写 driver.add_cookie({"name": "BDUSS", "value": "FmS2FEZ1JWdVZqUG15YlZ-YnA1cUkwVXR-NGN3Q2laa3NTRzVCNmdBa3YzeTlkRVFBQUFBJCQAAAAAAAAAAAEAAAC7LAGbbG92ZXN1bW1lcjkyNQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAC9SCF0vUghdZW"}) # 刷新操作 driver.refresh() time.sleep(20) finally: driver.close()
4.selenium爬取一页京东商品信息
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver = webdriver.Chrome() try: driver.implicitly_wait(10) driver.get('https://www.jd.com/') input_tag = driver.find_element_by_id('key') input_tag.send_keys('macbook') input_tag.send_keys(Keys.ENTER) good_list = driver.find_elements_by_class_name('gl-item') for good in good_list: good_url = good.find_element_by_css_selector('.p-img a').get_attribute('href') good_name = good.find_element_by_css_selector('.p-name em').text.replace("\n","--") good_price= good.find_element_by_class_name('p-price').text.replace("\n",":") good_commit = good.find_element_by_class_name('p-commit').text.replace("\n"," ") good_from = good.find_element_by_class_name('J_im_icon').text.replace("\n"," ") good_content = f''' 商品连接:{good_url} 商品名称:{good_name} 商品价格:{good_price} 商品人数:{good_commit} 商品商家:{good_from} \n ''' print(good_content) with open('jd.txt','a',encoding='utf-8')as f: f.write(good_content) time.sleep(10) finally: driver.close()
总结:今天学到了selenium的多种用法,很多也比request的模块使用起来更方便,很期待明天的破解滑动验证

 浙公网安备 33010602011771号
浙公网安备 33010602011771号