


排序算法中有稳定排序和不稳定排序之分,当相同的元素在排序之后仍保持之前的顺序则是稳定排序。常见的排序算法的时间复杂度为O(n2)、O(nlogn)和线性的。本片文章中,我们先来介绍一下常用的时间复杂度为O(n2)的排序算法
冒泡排序
冒泡排序是最常见的排序算法之一,排序方式简单粗暴。切冒泡排序是一种稳定的排序方式。
冒泡排序将元素两两比较,将较大的一个后移。
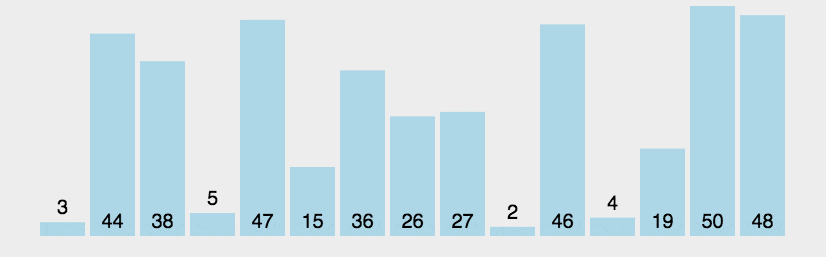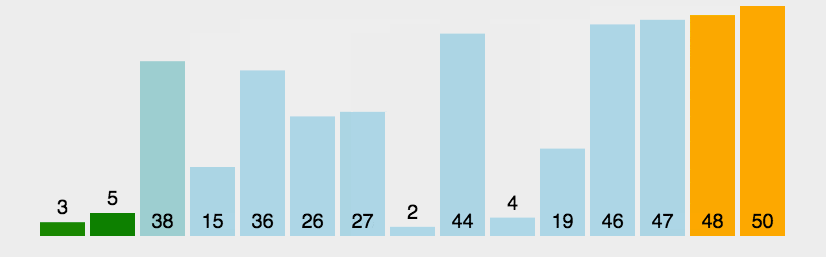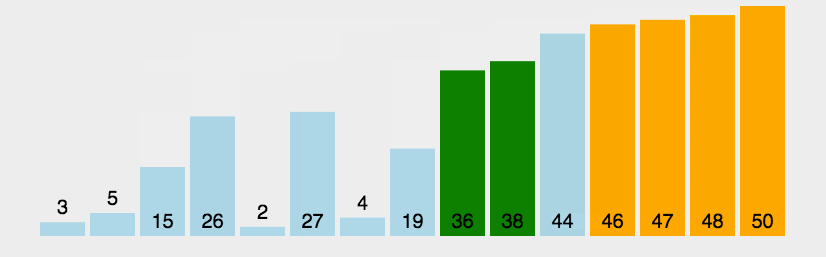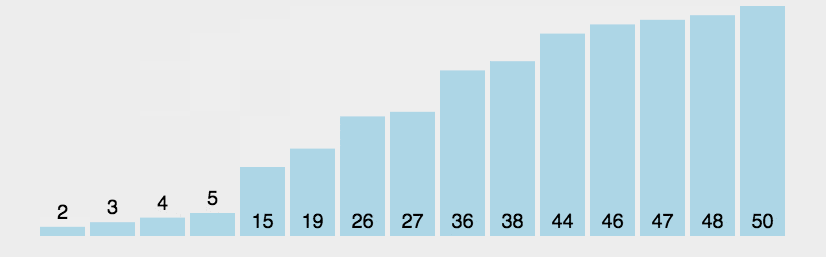
冒泡排序实现的方式多种多样,主要思想就是其中的data[n], data[n+1] = data[n+1], data[n]以及两次循环。
def bubbling(data):
loop = len(data)
while loop > 0:
loop -= 1
n = 0
while n < loop:
if data[n] > data[n+1]:
data[n], data[n+1] = data[n+1], data[n]
n += 1
冒泡算法虽然简单粗暴,但是有很多不足之处,比如:
- 上述图示中,当第一轮比较完成之后,后三位数以及成为有序排列,但是之后还是将其再次对比
- 而且当列表中在循环还未结束前就已经完成排序,但循环还是会继续下去不会停止。
优化思路: - 第一个问题的原因主要出现在有序区的定义上,我们可以将每次元素交换的位置将其记录,并将最后一次交换位置的地方设为有序区的边界。
- 问题二则只需记录循环是否有元素交换,如果没有元素交换则跳出循环即可解决。
# 经过优化的冒泡排序
def bubble(data):
# 获得列表尾部位置
loop = len(data) - 1
while loop > 0:
# change(改变):用来判断本次循环是否有所改变
change = True
n = 0
while n < loop:
if data[n] > data[n+1]:
data[n], data[n+1] = data[n+1], data[n]
record = n
change = False
n += 1
# 判断是否已经完成循环可以跳出
if change:
break
# 每次循环后将尾部移动到最后一次交换的位置
loop = record
鸡尾酒排序
鸡尾酒排序可以算作为冒泡排序的一种变种和优化,在冒泡排序中,我们进行元素比较都是单向的,元素会根据自身大小一点一点向一侧移动,而鸡尾酒排序的不同之处就是将这种单向排序优化成双向排序,当冒泡排序在正方向上循环一次后,会在逆方向上再次比较循环。在一些特殊的情况下大幅度减少计算量,比如在2,3,4,5,6,7,8,1中,我们使用冒泡排序,大循环将要循环9次,但是鸡尾酒排序大循环只需循环两次。鸡尾酒排序在一组数据只有个别数据需要排序时非常实用。鸡尾酒排序只需在大循环中加入反向循环即可。

# 鸡尾酒排序
def bubble(data):
# 获得列表尾部位置
loop = len(data) - 1
while loop > 0:
# change(改变):用来判断本次循环是否有所改变
change = True
# n用来记录当前指向的列表元素位置
n = 0
# 正向循环
while n < loop:
if data[n] > data[n + 1]:
data[n], data[n + 1] = data[n + 1], data[n]
record = n
change = False
n += 1
# 判断是否已经完成循环可以跳出
if change:
break
# 反向循环
while loop > 0:
if data[loop] < data[loop - 1]:
data[loop], data[loop - 1] = data[loop - 1], data[loop]
loop -= 1
# 每次循环后将尾部移动到最后一次交换的位置
loop = record
选择排序
选择排序同样也是一种简单直接的排序方法,选择排序是一种完全依靠交互进行排序的算法,使用选择排序的时候我们同样会将列表分为有序区和无序区,同时我们需要找到本次循环中出现的最小值,然后将其放入有序区尾部。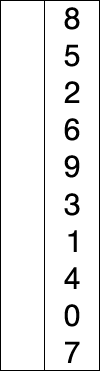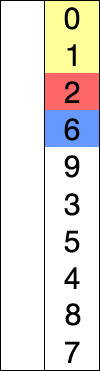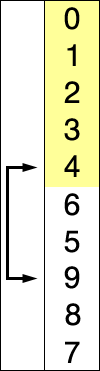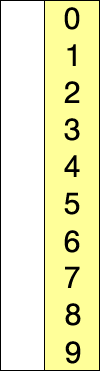
# 选择排序
# 方法1
def selection(data):
# 记录有序区位置
n = 0
while n < len(data):
# 找最小值
i = n
# 初始化最小值
mix = i
while i < len(data):
if data[mix] > data[i]:
# 记录最小值位置
mix = i
i += 1
data[n], data[mix] = data[mix], data[n]
n += 1
# 方法二
def selection_sort(li):
"""选择排序"""
n = len(li)
for i in range(n-1): # 0-7
# 记录最小位置
min_index = i
for j in range(min_index, n):
# print(min_index)
if li[j] < li[min_index]:
min_index = j
li[i], li[min_index] = li[min_index], li[i]
selection_sort(li)
print(li)
插入排序
插入排序同样是将序列分为有序区和无序区,每次在有序区中添加添加一个元素进行排序。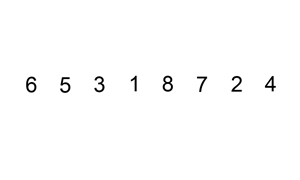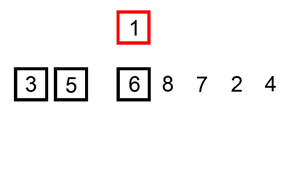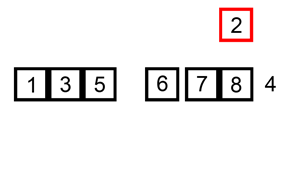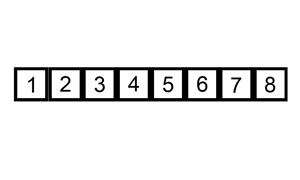
def insertion(data):
# 记录有序区位置
n = 1
# 取到的新元素
i = n
while n < len(data):
while i > 0:
if data[i] < data[i-1]:
data[i], data[i-1] = data[i-1], data[i]
i -= 1
n += 1
i = n
希尔排序
希尔排序是在插入排序的基础上改进的一种排序,相对于普通的插入排序更加的高效。希尔排序是把记录按下标的一定增量分量,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。

通俗的解释希尔排序就是将一组数字分成数组长度相同小组,在对比每个小组对应角标的元素将其排序,然后缩小分组的长度,直到每个元素都成为一组为止。的从上图可以看出整个排序过程进行了四次替换,相对于插入排序有一定的优化。
def shell_sort(data):
# 选择希尔排序默认步长
gap = len(data) // 2
# 判断步长是否足够
while gap > 0:
# 指向每列元素
i = gap
# 步长所对应的每列元素进行排序
# 判断是否已经指向末尾
while i < len(data):
while data[i] < data[i-gap] and i > 0:
data[i], data[i-gap] = data[i-gap], data[i]
i -= 1
print(i)
i += 1
gap = gap // 2
