
OpenCV入门(三十)快速学会OpenCV 29 支持向量机SVM
OpenCV入门(三十)快速学会OpenCV 29 支持向量机SVM
作者:Xiou
1.支持向量机SVM概述
支持向量机(Support Vector Machine, SVM)是一种二分类模型,目标是寻找一个标准(称为超平面)对样本数据进行分割,分割的原则是确保分类最优化(类别之间的间隔最大)。当数据集较小时,使用支持向量机进行分类非常有效。支持向量机是最好的现成分类器之一,这里所谓的“现成”是指分类器不加修改即可直接使用。
在对原始数据分类的过程中,可能无法使用线性方法实现分割。支持向量机在分类时,把无法线性分割的数据映射到高维空间,然后在高维空间找到分类最优的线性分类器。
Python提供了不同的实现支持向量机的库(例如sk-learn库、LIBSVM库等), OpenCV也提供了对支持向量机的支持,对于上述库,基本都可以直接使用,无须深入了解支持向量机的原理。
在不同的维度下,支持向量机都会尽可能寻找类似于二维空间中的直线的线性分类器。例如,在二维空间,支持向量机会寻找一条能够划分当前数据的直线;在三维空间,支持向量机会寻找一个能够划分当前数据的平面(plane);在更高维的空间,支持向量机会尝试寻找一个能够划分当前数据的超平面(hyperplane)。
一般情况下,把能够可以被一条直线(更一般的情况,即一个超平面)分割的数据称为线性可分的数据,所以超平面是线性分类器。
“支持向量机”是由“支持向量”和“机器”构成的。
● “支持向量”是离分类器最近的那些点,这些点位于最大“间隔”上。通常情况下,分类仅依靠这些点完成,而与其他点无关。
● “机器”指的是分类器。综上所述,支持向量机是一种基于关键点的分类算法。
SVM案例介绍
2.1 语法介绍
在使用支持向量机模块时,需要先使用函数cv2.ml.SVM_create()生成用于后续训练的空分类器模型。该函数的语法格式为:
svm = cv2.ml.SVM_create( )
获取了空分类器svm后,针对该模型使用svm.train()函数对训练数据进行训练,其语法格式为:
训练结果= svm.train(训练数据,训练数据排列格式,训练数据的标签)
式中参数的含义如下:
● 训练数据:表示原始数据,用来训练分类器。例如,前面讲的招聘的例子中,员工的笔试成绩、面试成绩都是原始的训练数据,可以用来训练支持向量机。
● 训练数据排列格式:原始数据的排列形式有按行排列(cv2.ml.ROW_SAMPLE,每一条训练数据占一行)和按列排列(cv2.ml.COL_SAMPLE,每一条训练数据占一列)两种形式,根据数据的实际排列情况选择对应的参数即可。
● 训练数据的标签:原始数据的标签。
● 训练结果:训练结果的返回值。
例如,用于训练的数据为data,其对应的标签为label,每一条数据按行排列,对分类器模型svm进行训练,所使用的语句为:
返回值 = svm.train(data, cv2.ml.ROW_SAMPLE, label)
完成对分类器的训练后,使用svm.predict()函数即可使用训练好的分类器模型对测试数据进行分类,其语法格式为:
(返回值,返回结果) = svm.predict(测试数据)
以上是支持向量机模块的基本使用方法。在实际使用中,可能会根据需要对其中的参数进行调整。OpenCV支持对多个参数的自定义,例如:可以通过setType()函数设置类别,通过setKernel()函数设置核类型,通过setC()函数设置支持向量机的参数C(惩罚系数,即对误差的宽容度,默认值为0)。
2.2 代码实例
代码(1):已知老员工的笔试成绩、面试成绩及对应的等级表现,根据新入职员工的笔试成绩、面试成绩预测其可能的表现。
根据题目要求,首先构造一组随机数,并将其划分为两类,然后使用OpenCV自带的支持向量机模块完成训练和分类工作,最后将运算结果显示出来。具体步骤如下。
1.生成模拟数据首先,模拟生成入职一年后表现为A级的员工入职时的笔试和面试成绩。构造20组笔试和面试成绩都分布在[95, 100)区间的数据对:
a = np.random.randint(95,100, (20, 2)).astype(np.float32)
上述模拟成绩,在一年后对应的工作表现为A级。接下来,模拟生成入职一年后表现为B级的员工入职时的笔试和面试成绩。构造20组笔试和面试成绩都分布在[90, 95)区间的数据对:
b = np.random.randint(90,95, (20, 2)).astype(np.float32)
上述模拟成绩,在一年后对应的工作表现为B级。最后,将两组数据合并,并使用numpy.array对其进行类型转换:
data = np.vstack((a, b))
data = np.array(data, dtype='float32')
2.构造分组标签首先,为对应表现为A级的分布在[95, 100)区间的数据,构造标签“0”:
aLabel=np.zeros((20,1))
接下来,为对应表现为B级的分布在[90, 95)区间的数据,构造标签“1”:
bLabel=np.ones((20,1))
最后,将上述标签合并,并使用numpy.array对其进行类型转换:
label = np.vstack((aLabel, bLabel))
label = np.array(label, dtype='int32')
3.训练用支持向量机模块对已知的数据和其对应的标签进行训练:
svm = cv2.ml.SVM_create()
result = svm.train(data, cv2.ml.ROW_SAMPLE, label)
4.分类生成两个随机的数据对(笔试成绩,面试成绩)用于测试。可以用随机数,也可以直接指定两个数字。这里,我们想观察一下笔试和面试成绩差别较大的数据如何分类。用如下语句生成成绩:
test = np.vstack([[98,90], [90,99]])
test = np.array(test, dtype='float32')
然后,使用函数svm.predict()对随机成绩分类:
(p1, p2) = svm.predict(test)
5.显示分类结果将基础数据(训练数据)、用于测试的数据(测试数据)在图像上显示出来:
plt.scatter(a[:,0], a[:,1], 80, 'g', 'o')
plt.scatter(b[:,0], b[:,1], 80, 'b', 's')
plt.scatter(test[:,0], test[:,1], 80, 'r', '*')
plt.show()
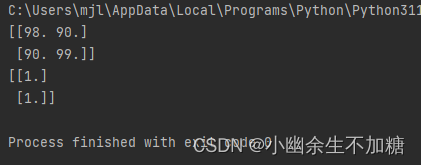
将测试数据及预测分类结果显示出来:
print(test)
print(p2)
完整代码如下所示:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 第1步 准备数据
# 表现为A级的员工的笔试、面试成绩
a = np.random.randint(95,100, (20, 2)).astype(np.float32)
# 表现为B级的员工的笔试、面试成绩
b = np.random.randint(90,95, (20, 2)).astype(np.float32)
# 合并数据
data = np.vstack((a, b))
data = np.array(data, dtype='float32')
# 第2步 建立分组标签,0代表A级,1代表B级
#aLabel对应着a的标签,为类型0-等级A
aLabel=np.zeros((20,1))
#bLabel对应着b的标签,为类型1-等级B
bLabel=np.ones((20,1))
# 合并标签
label = np.vstack((aLabel, bLabel))
label = np.array(label, dtype='int32')
# 第3步 训练
# 用ml机器学习模块 SVM_create() 创建svm
svm = cv2.ml.SVM_create()
# 属性设置,直接采用默认值即可
#svm.setType(cv2.ml.SVM_C_SVC) # svm type
#svm.setKernel(cv2.ml.SVM_LINEAR) # line
#svm.setC(0.01)
# 训练
result = svm.train(data, cv2.ml.ROW_SAMPLE, label)
# 第4步 预测
# 生成两个随机的笔试成绩和面试成绩数据对
test = np.vstack([[98,90], [90,99]])
test = np.array(test, dtype='float32')
# 预测
(p1, p2) = svm.predict(test)
# 第5步 观察结果
# 可视化
plt.scatter(a[:,0], a[:,1], 80, 'g', 'o')
plt.scatter(b[:,0], b[:,1], 80, 'b', 's')
plt.scatter(test[:,0], test[:,1], 80, 'r', '*')
plt.show()
# 打印原始测试数据test,预测结果
print(test)
print(p2)
输出结果:
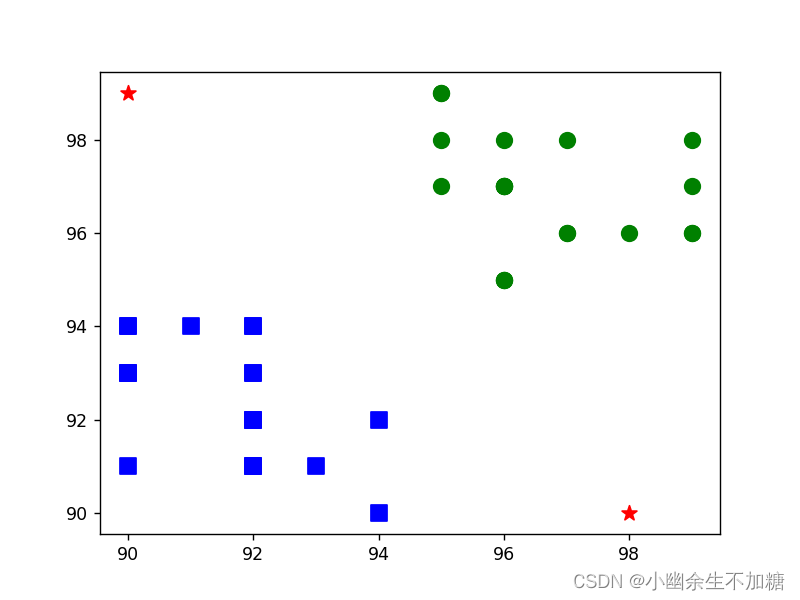
图中左下角的方块代表测评成绩为A级的员工,右上角的小圆点代表测评成绩为B级的员工,另外的两个五角星代表需要分类的新入职员工。
运行结果表明:
● 笔试成绩为98分,面试成绩为90分,对应的分类为1,即该员工一年后的测评可能为B级(表现良好)。
● 笔试成绩为90分,面试成绩为99分,对应的分类为1,即该员工一年后的测评可能为B级(表现良好)。
因为我们采用随机方式生成数据,所以每次运行时所生成的数据会有所不同,运行结果也就会有所差异。
