OpenCV入门(三十一)快速学会OpenCV 30 K近邻算法
作者:Xiou
1.K近邻算法概述
机器学习算法是从数据中产生模型,也就是进行学习的算法(下文也简称为算法)。我们把经验提供给算法,它就能够根据经验数据产生模型。在面对新的情况时,模型就会为我们提供判断(预测)结果。例如,我们根据“个子高、腿长、体重轻”判断一个孩子是个运动员的好苗子。把这些数据量化后交给计算机,它就会据此产生模型,在面对新情况时(判断另一个孩子能不能成为运动员),模型就会给出相应的判断。
比如,要对一组孩子进行测试,首先就要获取这组孩子的基本数据。这组数据包含身高、腿长、体重等数据,这些反映对象(也可以是事件)在某个方面的表现或者性质的事项,被称为属性或特征。而具体的值,如反映身高的“188 cm”就是特征值或属性值。这组数据的集合“(身高=188 cm,腿长=56 cm,体重=46 kg), ……,(身高=189cm,腿长=55 cm,体重=48 kg)”,称为数据集,其中每个孩子的数据称为一个样本。
从数据中学得模型的过程称为学习(learning)或者训练(training)。在训练过程中所使用的数据称为训练数据,其中的每个样本称为训练样本,训练样本所组成的集合称为训练集。
当然,如果希望获取一个模型,除了有数据,还需要给样本贴上对应的标签(label)。例如,“((个子高、腿长、体重轻),好苗子)”。这里的“好苗子”就是标签,通常我们将拥有了标签的样本称为“样例”。
学得模型后,为了测试模型的效果,还要对其进行测试,被测试的样本称为测试样本。输入测试样本时,并不提供测试样本的标签(目标类别),而是由模型决定样本的标签(属于哪个类别)。比较测试样本预测的标签与实际样本标签之间的差别,就可以计算出模型的精确度。
大多数的机器学习算法都来源于日常生活实践。K近邻算法是最简单的机器学习算法之一,主要用于将对象划分到已知类中,在生活中被广泛使用。例如,教练要选拔一批长跑运动员,如何选拔呢?他使用的可能就是K近邻算法,会选择个子高、腿长、体重轻,膝、踝关节围度小,跟腱明显,足弓较大者作为候选人。他会觉得这样的孩子有运动员的潜质,或者说这些孩子的特征和运动员的特征很接近。
K近邻算法的本质是将指定对象根据已知特征值分类。例如,看到一对父子,一般情况下,通过判断他们的年龄,能够马上分辨出哪位是父亲,哪位是儿子。这是通过年龄属性的特征值来划分的。
K近邻算法在获取各个样本的特征值之后,计算待识别样本的特征值与各个已知分类的样本特征值之间的距离,然后找出k个最邻近的样本,根据k个最邻近样本中占比最高的样本所属的分类,来确定待识别样本的分类。
2.代码实例
在OpenCV中,不需要自己编写复杂的函数实现K近邻算法,直接调用其自带的模块函数即可。本节通过一个简单的例子介绍如何使用OpenCV自带的K近邻模块。
代码实例(1):演示OpenCV自带的K近邻模块的使用方法。
本例中有两组位于不同位置的用于训练的数据集,如图20-14所示。两组数据集中,一组位于左下角;另一组位于右上角。随机生成一个数值,用OpenCV中的K近邻模块判断该随机数属于哪一个分组。
上述两组数据中,位于左下角的一组数据,其x、y坐标值都在(0, 30)范围内。位于右上角的数据,其x、y坐标值都在(70, 100)范围内。根据上述分析,创建两组数据,每组包含20对随机数(20个随机数据点):
● 第1组随机数rand1中,其x、y坐标值均位于(0, 30)区间内。
● 第2组随机数rand2中,其x、y坐标值均位于(70, 100)区间内。接下来,为两组随机数分配标签:
● 将第1组随机数对划分为类型0,标签为0。
● 将第2组随机数对划分为类型1,标签为1。然后,生成一对值在(0, 100)内的随机数对:
test = np.random.randint(0, 100, (1, 2)).astype(np.float32)
最后,使用OpenCV自带的K近邻模块判断生成的随机数对test是属于rand1所在的类型0,还是属于rand2所在的类型1。
代码实例:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 用于训练的数据
# rand1数据位于(0,30)
rand1 = np.random.randint(0, 30, (20, 2)).astype(np.float32)
# rand2数据位于(70,100)
rand2 = np.random.randint(70, 100, (20, 2)).astype(np.float32)
# 将rand1和rand2拼接为训练数据
trainData = np.vstack((rand1, rand2))
# 数据标签,共两类:0和1
# r1Label对应着rand1的标签,为类型0
r1Label = np.zeros((20, 1)).astype(np.float32)
# r2Label对应着rand2的标签,为类型1
r2Label = np.ones((20, 1)).astype(np.float32)
tdLable = np.vstack((r1Label, r2Label))
# 使用绿色标注类型0
g = trainData[tdLable.ravel() == 0]
plt.scatter(g[:, 0], g[:, 1], 80, 'g', 'o')
# 使用蓝色标注类型1
b = trainData[tdLable.ravel() == 1]
plt.scatter(b[:, 0], b[:, 1], 80, 'b', 's')
# plt.show()
# test为用于测试的随机数,该数在0到100之间
test = np.random.randint(0, 100, (1, 2)).astype(np.float32)
plt.scatter(test[:, 0], test[:, 1], 80, 'r', '*')
# 调用OpenCV内的K近邻模块,并进行训练
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, tdLable)
# 使用K近邻算法分类
ret, results, neighbours, dist = knn.findNearest(test, 5)
# 显示处理结果
print("当前随机数可以判定为类型:", results)
print("距离当前点最近的5个邻居是:", neighbours)
print("5个最近邻居的距离: ", dist)
# 可以观察一下显示,对比上述输出
plt.show()
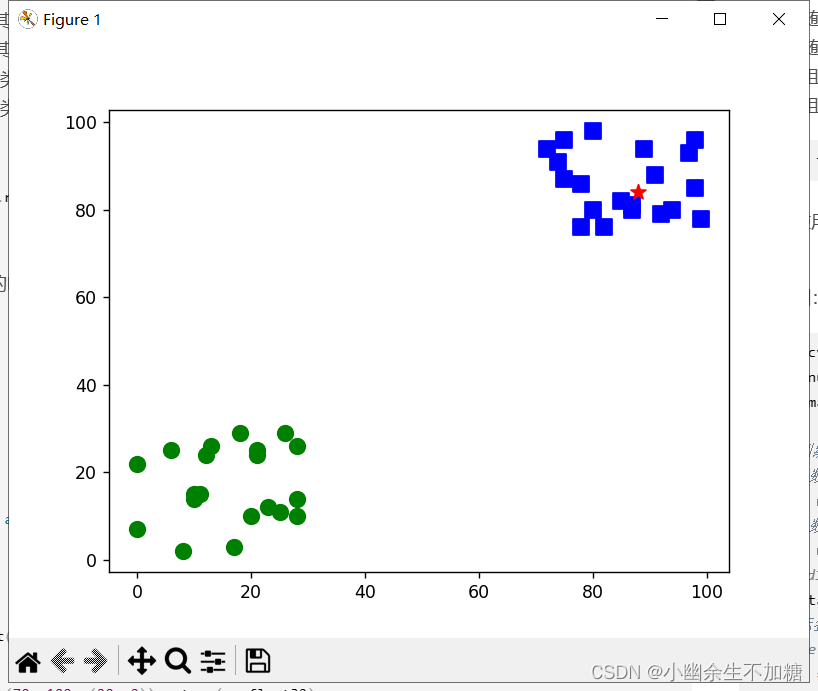
同时,程序还会显示如图所示的运行结果。从图中可以看出,随机点(星号点)距离右侧小方块(类型为1)的点更近,因此被判定为属于小方块的类型1。
代码实例(2)使用OpenCV自带的函数完成对手写数字的识别
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取样本(特征)图像的值
s='image\\' # 图像所在的路径
num=100 # 共有的样本数量
row=240 # 特征图像的行数
col=240 # 特征图像的列数
a=np.zeros((num, row, col)) # 用来存储所有样本的数值
#print(a.shape)
n=0 # 用来存储当前图像的编号
for i in range(0,10):
for j in range(1,11):
a[n, :, :]=cv2.imread(s+str(i)+'\\'+str(i)+'-'+str(j)+'.bmp',0)
n=n+1
# 提取样本图像的特征
feature=np.zeros((num, round(row/5), round(col/5))) # 用来存储所有样本的特征值
#print(feature.shape) # 看看特征值的形状是什么样子
#print(row) # 看看row的值,有多少个特征值(100)
for ni in range(0, num):
for nr in range(0, row):
for nc in range(0, col):
if a[ni, nr, nc]==255:
feature[ni, int(nr/5), int(nc/5)]+=1
f=feature # 简化变量名称
# 将feature处理为单行形式
train = feature[:, :].reshape(-1,
round(row/5)*round(col/5)).astype(np.float32)
#print(train.shape)
# 贴标签,要注意,是range(0,100)而非range(0,101)
trainLabels = [int(i/10) for i in range(0,100)]
trainLabels=np.asarray(trainLabels)
#print(*trainLabels) # 打印测试看看标签值
##读取图像值
o=cv2.imread('image\\test\\5.bmp',0) # 读取待识别图像
of=np.zeros((round(row/5), round(col/5))) # 用来存储待识别图像的特征值
for nr in range(0, row):
for nc in range(0, col):
if o[nr, nc]==255:
of[int(nr/5), int(nc/5)]+=1
test=of.reshape(-1, round(row/5)*round(col/5)).astype(np.float32)
# 调用函数识别图像
knn=cv2.ml.KNearest_create()
knn.train(train, cv2.ml.ROW_SAMPLE, trainLabels)
ret, result, neighbours, dist = knn.findNearest(test, k=5)
print("当前随机数可以判定为类型:", result)
print("距离当前点最近的5个邻居是:", neighbours)
print("5个最近邻居的距离: ", dist)
运行上述程序,程序运行结果为:
当前随机数可以判定为类型: [[5.]]
距离当前点最近的5个邻居是: [[5. 3. 5. 3. 5.]]
5个最近邻居的距离: [[77185. 78375. 79073. 79948. 82151.]]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号