OpenCV实例(八)行人跟踪
作者:Xiou
1.目标跟踪概述
目标跟踪是对摄像头视频中的移动目标进行定位的过程,它有着广泛的应用,本章将介绍这一主题。实时目标跟踪是许多计算机视觉应用的重要任务,例如监控(surveillance)、基于感知的(perceptual)用户界面、增强现实、基于对象的视频压缩以及辅助驾驶等。
可用多种方式实现目标跟踪,而最优的跟踪技术在很大程度跟具体任务有关。
为了跟踪视频中的所有目标,首先要完成的任务是识别视频帧中那些可能包含移动目标的区域。有很多实现视频目标跟踪的方法,这些方法的目的稍微不同。例如,当跟踪所有移动目标时,帧之间的差异会变得有用;当跟踪视频中移动的手时,基于皮肤颜色的均值漂移方法是最好的解决方案;当知道跟踪对象的一方面时,模板匹配会是不错的技术。
2.基于背景差分检测运动物体
2.1 实现基本背景差分器
实现基本背景差分器为了实现基本背景差分器,我们采用以下几步:
(1)开始用摄像头捕捉帧。
(2)丢弃9帧,这样摄像头才有时间适当调整自动曝光,以适应场景中的光照条件。(3)取第10帧,将其转换为灰度图像,对其进行模糊,并把模糊图像作为背景的参考图像。
(4)对于每个后续帧,对其进行模糊,将其转换为灰度图像,再计算模糊帧和背景参考图像之间的绝对差值。对差值图像进行阈值化、平滑和轮廓检测处理。绘制并显示主要轮廓的边框。
将前面的几步展开为更小的步骤,我们可以考虑用8个连续的代码块来实现脚本:(1)首先,导入OpenCV,并定义blur、erode和dilate运算的核的大小:

(2)试着从摄像头捕捉10帧:

(3)如果无法采集到10帧,就退出。否则,将第10帧图像转换为灰度图像,并对其进行模糊:

(4)在这一阶段,我们有了背景的参考图像。现在,我们继续采集更多帧,这样就可以检测运动物体了。对每一帧的处理都从灰度转换和高斯模糊操作开始:

(5)现在,我们对当前帧的模糊、灰度版本,以及背景图像的模糊、灰度版本进行比较。具体来说,我们将使用OpenCV的cv2.absdiff函数求这两幅图像之间差值的绝对值(或大小)。然后,应用阈值来获得纯黑白图像,并通过形态学运算对阈值化图像进行平滑处理。以下是相关的代码:

(6)现在,如果技术运行良好,阈值图像应该在运动物体处包含白色斑点。我们想找到白色斑点的轮廓,并在其周围绘制边框。为了进一步过滤可能不是真实物体的微小变化,我们将应用一个基于轮廓面积的阈值。如果轮廓太小,就认为它不是真正的运动物体。(当然,“太小”的界定可能会因摄像头的分辨率和应用程序而有所不同,在某些情况下,你可能根本不希望应用此测试。)下面是检测轮廓和绘制边框的代码:

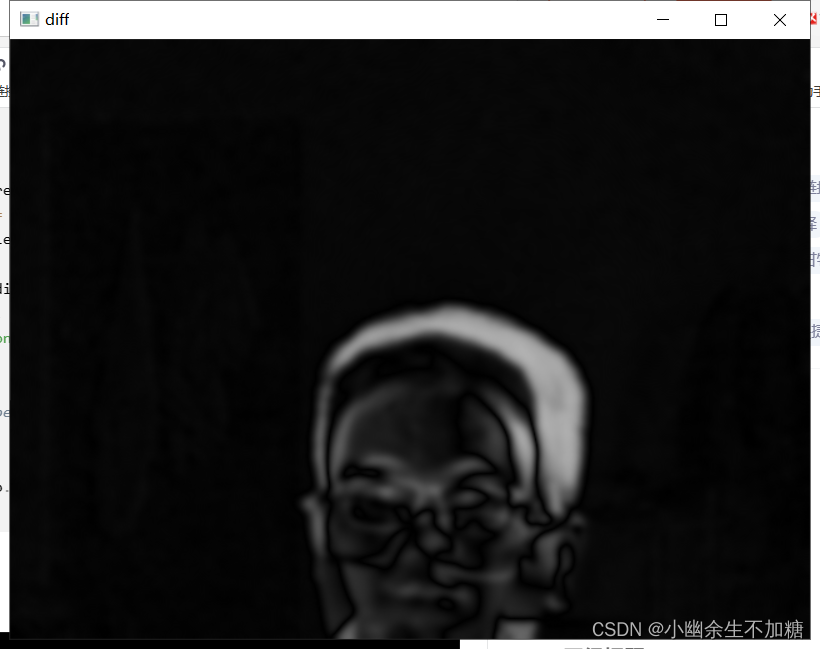
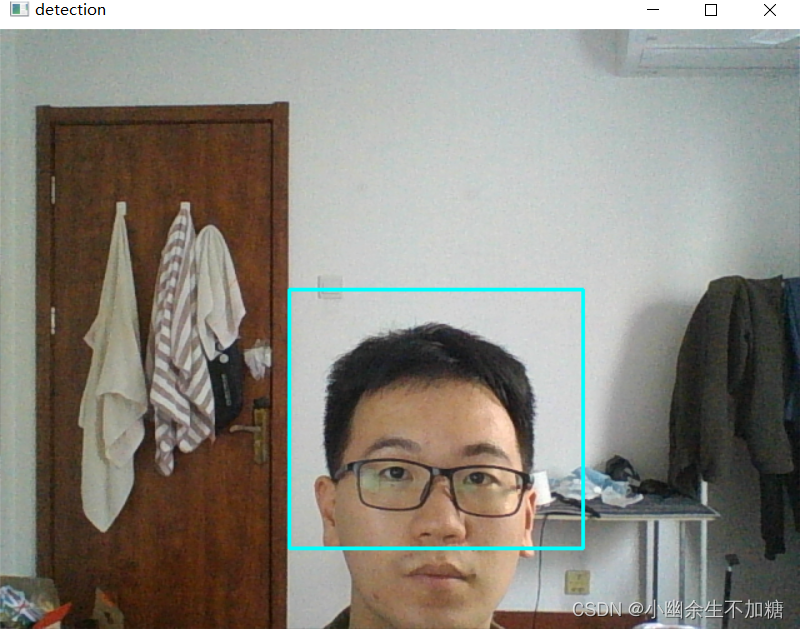
(7)显示差值图像、阈值化图像以及带有矩形边框的检测结果:

(8)继续读取帧,直到用户按下Esc键退出:
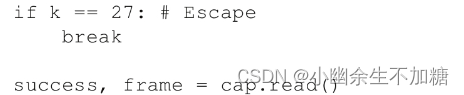
代码实例:
import cv2
OPENCV_MAJOR_VERSION = int(cv2.__version__.split('.')[0])
BLUR_RADIUS = 21
erode_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
dilate_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (9, 9))
cap = cv2.VideoCapture(0)
# Capture several frames to allow the camera's autoexposure to adjust.
for i in range(10):
success, frame = cap.read()
if not success:
exit(1)
gray_background = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray_background = cv2.GaussianBlur(gray_background,
(BLUR_RADIUS, BLUR_RADIUS), 0)
success, frame = cap.read()
while success:
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray_frame = cv2.GaussianBlur(gray_frame,
(BLUR_RADIUS, BLUR_RADIUS), 0)
diff = cv2.absdiff(gray_background, gray_frame)
_, thresh = cv2.threshold(diff, 40, 255, cv2.THRESH_BINARY)
cv2.erode(thresh, erode_kernel, thresh, iterations=2)
cv2.dilate(thresh, dilate_kernel, thresh, iterations=2)
if OPENCV_MAJOR_VERSION >= 4:
# OpenCV 4 or a later version is being used.
contours, hier = cv2.findContours(thresh, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
else:
# OpenCV 3 or an earlier version is being used.
# cv2.findContours has an extra return value.
# The extra return value is the thresholded image, which is
# unchanged, so we can ignore it.
_, contours, hier = cv2.findContours(thresh, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
if cv2.contourArea(c) > 4000:
x, y, w, h = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 255, 0), 2)
cv2.imshow('diff', diff)
cv2.imshow('thresh', thresh)
cv2.imshow('detection', frame)
k = cv2.waitKey(1)
if k == 27: # Escape
break
success, frame = cap.read()
输出结果:

2.2 使用MOG背景差分器
(1)用MOG背景差分器替换基本背景差分模型。
(2)使用视频文件(而不是摄像头)作为输入。
(3)取消高斯模糊。
(4)调整阈值、形态学和轮廓分析步骤中使用的参数。
这些修改会影响位于整个脚本中几个不同地方的几行代码。靠近脚本的顶部,我们初始化MOG背景差分器并修改形态学核的大小,如下面代码块中的粗体所示:

注意OpenCV提供了一个函数cv2.createBackgroundSubtractorMOG2来创建cv2.BackgroundSubtractorMOG2实例。该函数接受一个参数detectShadows,将其设置为True,就会标记出阴影区域,而不会标记为前景的一部分。
输出结果:

由于抛光的地板和墙壁,这个场景不仅包含阴影,也包含反射内容。当启用阴影检测时,我们可以使用一个阈值来移除掩模上的阴影和反射部分,大厅里的人周围只留下一个准确的检测矩形。可是,当禁用阴影检测时,有两个检测结果,可以说,两个检测结果都是不准确的。其中一个覆盖了男子及其影子和地板上的倒影。第二个则覆盖了该男子在墙上的倒影。可以说,这些都是不准确的检测,因为即使这个人的影子和反射是运动物体的视觉产物,但是它们并不是真正的运动物体。
2.3 使用卡尔曼滤波器寻找运动趋势
卡尔曼滤波器主要(但不完全)是由鲁道夫·卡尔曼(Rudolf Kalman)在20世纪50年代后期开发出来的一种算法。卡尔曼滤波器在许多领域都有实际应用,尤其是从核潜艇到飞机的各种交通工具的导航系统。
卡尔曼滤波器递归地对有噪声的输入数据流进行操作,以产生底层系统状态的统计最优估计。在计算机视觉背景下,卡尔曼滤波器可以对跟踪物体的位置进行平滑估计。
我们来考虑一个简单的例子。想象桌子上有一个红色小球,并想象有一个摄像头对着此场景。将球作为要跟踪的主体,然后用手指轻弹小球。球将根据运动规律开始在桌子上滚动。如果球在特定的方向上以1米/秒的速度滚动,那么很容易估计出球在1秒后的位置:它将在1米远的地方。卡尔曼滤波器应用这样的规律,根据先前收集到的帧的跟踪结果来预测当前视频帧中物体的位置。
卡尔曼滤波器本身并没有收集这些跟踪结果,但是它会根据来自另一种算法(如MeanShift)的跟踪结果更新物体的运动模型。自然,卡尔曼滤波器无法预见作用在球上的力(例如与桌上的铅笔的碰撞),但是它可以在事后根据跟踪结果更新它的运动模型。通过使用卡尔曼滤波器,我们可以获得比单独跟踪的结果更稳定、更符合运动规律的估计结果。
根据前面的描述,我们认为卡尔曼滤波器算法有两个阶段:
·预测(在第一阶段):卡尔曼滤波器使用计算到当前时间点的协方差估计物体的新位置。
·更新(在第二阶段):卡尔曼滤波器记录物体的位置,并调整协方差用于下一个计算周期。
代码实例:
import cv2
import numpy as np
# Create a black image.
img = np.zeros((800, 800, 3), np.uint8)
# Initialize the Kalman filter.
kalman = cv2.KalmanFilter(4, 2)
kalman.measurementMatrix = np.array(
[[1, 0, 0, 0],
[0, 1, 0, 0]], np.float32)
kalman.transitionMatrix = np.array(
[[1, 0, 1, 0],
[0, 1, 0, 1],
[0, 0, 1, 0],
[0, 0, 0, 1]], np.float32)
kalman.processNoiseCov = np.array(
[[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]], np.float32) * 0.03
last_measurement = None
last_prediction = None
def on_mouse_moved(event, x, y, flags, param):
global img, kalman, last_measurement, last_prediction
measurement = np.array([[x], [y]], np.float32)
if last_measurement is None:
# This is the first measurement.
# Update the Kalman filter's state to match the measurement.
kalman.statePre = np.array(
[[x], [y], [0], [0]], np.float32)
kalman.statePost = np.array(
[[x], [y], [0], [0]], np.float32)
prediction = measurement
else:
kalman.correct(measurement)
prediction = kalman.predict() # Gets a reference, not a copy
# Trace the path of the measurement in green.
cv2.line(img, (last_measurement[0], last_measurement[1]),
(measurement[0], measurement[1]), (0, 255, 0))
# Trace the path of the prediction in red.
cv2.line(img, (last_prediction[0], last_prediction[1]),
(prediction[0], prediction[1]), (0, 0, 255))
last_prediction = prediction.copy()
last_measurement = measurement
cv2.namedWindow('kalman_tracker')
cv2.setMouseCallback('kalman_tracker', on_mouse_moved)
while True:
cv2.imshow('kalman_tracker', img)
k = cv2.waitKey(1)
if k == 27: # Escape
cv2.imwrite('kalman.png', img)
break
输出结果:

运行程序并移动鼠标。如果鼠标在高速下突然转弯,你会注意到预测线(红色)会比测量线(绿色)更宽。这是因为预测跟随鼠标运动到那时的动量。
3.跟踪行人
素材:

应用程序将遵循以下逻辑:
(1)从视频文件中捕获帧。
(2)使用前20帧来填充背景差分器的历史记录。
(3)基于背景差分,使用第21帧识别运动的前景物体。我们将把这些当作行人对待。对于每个行人,分配一个ID和一个初始跟踪窗口,然后计算直方图。
(4)对于随后的每一帧,使用卡尔曼滤波器和MeanShift跟踪每个行人。如果这是一个实际的应用程序,可能需要存储每个行人在场景中的路径记录,以便用户稍后对其进行分析。然而,这种类型的记录保存不在本示例中探讨。此外,在实际的应用程序中,需要确保能够识别进入场景的新的行人,但是目前我们将只专注于跟踪场景中靠近视频开始处的那些物体。
代码实例:
import cv2
import numpy as np
OPENCV_MAJOR_VERSION = int(cv2.__version__.split('.')[0])
class Pedestrian():
"""A tracked pedestrian with a state including an ID, tracking
window, histogram, and Kalman filter.
"""
def __init__(self, id, hsv_frame, track_window):
self.id = id
self.track_window = track_window
self.term_crit = \
(cv2.TERM_CRITERIA_COUNT | cv2.TERM_CRITERIA_EPS, 10, 1)
# Initialize the histogram.
x, y, w, h = track_window
roi = hsv_frame[y:y+h, x:x+w]
roi_hist = cv2.calcHist([roi], [0], None, [16], [0, 180])
self.roi_hist = cv2.normalize(roi_hist, roi_hist, 0, 255,
cv2.NORM_MINMAX)
# Initialize the Kalman filter.
self.kalman = cv2.KalmanFilter(4, 2)
self.kalman.measurementMatrix = np.array(
[[1, 0, 0, 0],
[0, 1, 0, 0]], np.float32)
self.kalman.transitionMatrix = np.array(
[[1, 0, 1, 0],
[0, 1, 0, 1],
[0, 0, 1, 0],
[0, 0, 0, 1]], np.float32)
self.kalman.processNoiseCov = np.array(
[[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]], np.float32) * 0.03
cx = x+w/2
cy = y+h/2
self.kalman.statePre = np.array(
[[cx], [cy], [0], [0]], np.float32)
self.kalman.statePost = np.array(
[[cx], [cy], [0], [0]], np.float32)
def update(self, frame, hsv_frame):
back_proj = cv2.calcBackProject(
[hsv_frame], [0], self.roi_hist, [0, 180], 1)
ret, self.track_window = cv2.meanShift(
back_proj, self.track_window, self.term_crit)
x, y, w, h = self.track_window
center = np.array([x+w/2, y+h/2], np.float32)
prediction = self.kalman.predict()
estimate = self.kalman.correct(center)
center_offset = estimate[:,0][:2] - center
self.track_window = (x + int(center_offset[0]),
y + int(center_offset[1]), w, h)
x, y, w, h = self.track_window
# Draw the predicted center position as a blue circle.
cv2.circle(frame, (int(prediction[0]), int(prediction[1])),
4, (255, 0, 0), -1)
# Draw the corrected tracking window as a cyan rectangle.
cv2.rectangle(frame, (x,y), (x+w, y+h), (255, 255, 0), 2)
# Draw the ID above the rectangle in blue text.
cv2.putText(frame, 'ID: %d' % self.id, (x, y-5),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 0),
1, cv2.LINE_AA)
def main():
cap = cv2.VideoCapture('pedestrians.avi')
# Create the KNN background subtractor.
bg_subtractor = cv2.createBackgroundSubtractorKNN()
history_length = 20
bg_subtractor.setHistory(history_length)
erode_kernel = cv2.getStructuringElement(
cv2.MORPH_ELLIPSE, (3, 3))
dilate_kernel = cv2.getStructuringElement(
cv2.MORPH_ELLIPSE, (8, 3))
pedestrians = []
num_history_frames_populated = 0
while True:
grabbed, frame = cap.read()
if (grabbed is False):
break
# Apply the KNN background subtractor.
fg_mask = bg_subtractor.apply(frame)
# Let the background subtractor build up a history.
if num_history_frames_populated < history_length:
num_history_frames_populated += 1
continue
# Create the thresholded image.
_, thresh = cv2.threshold(fg_mask, 127, 255,
cv2.THRESH_BINARY)
cv2.erode(thresh, erode_kernel, thresh, iterations=2)
cv2.dilate(thresh, dilate_kernel, thresh, iterations=2)
# Detect contours in the thresholded image.
if OPENCV_MAJOR_VERSION >= 4:
# OpenCV 4 or a later version is being used.
contours, hier = cv2.findContours(
thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
else:
# OpenCV 3 or an earlier version is being used.
# cv2.findContours has an extra return value.
# The extra return value is the thresholded image, which
# is unchanged, so we can ignore it.
_, contours, hier = cv2.findContours(
thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
hsv_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
# Draw green rectangles around large contours.
# Also, if no pedestrians are being tracked yet, create some.
should_initialize_pedestrians = len(pedestrians) == 0
id = 0
for c in contours:
if cv2.contourArea(c) > 500:
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x+w, y+h),
(0, 255, 0), 1)
if should_initialize_pedestrians:
pedestrians.append(
Pedestrian(id, hsv_frame,
(x, y, w, h)))
id += 1
# Update the tracking of each pedestrian.
for pedestrian in pedestrians:
pedestrian.update(frame, hsv_frame)
cv2.imshow('Pedestrians Tracked', frame)
k = cv2.waitKey(110)
if k == 27: # Escape
break
if __name__ == "__main__":
main()
输出结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号