Web侦察工具HTTrack (爬取整站)
Web侦察工具HTTrack (爬取整站)
HTTrack介绍
爬取整站的网页,用于离线浏览,减少与目标系统交互,HTTrack是一个免费的(GPL,自由软件)和易于使用的离线浏览器工具。它允许您从Internet上下载万维网站点到本地目录,递归地构建所有目录,从服务器获取HTML,图像和其他文件到您的计算机。HTTrack安排原始网站的相关链接结构。只需在浏览器中打开“镜像”网站的页面,即可从链接到链接浏览网站,就像在线查看网站一样。HTTrack也可以更新现有的镜像站点,并恢复中断的下载。HTTrack完全可配置,并具有集成的帮助系统。
HTTrack使用
1.先创建一个目录,用来保存爬下来的网页和数据
1 | root@kali:~# mkdir dvwa |

2.打开Httrack
1 | root@kali:~# httrack |

3.给项目命名
1 | Enter project name :dvwa |

4.保存到哪个目录
1 | Base path (return=/root/websites/) :/root/dvwa |

5.网站的url
1 | Enter URLs (separated by commas or blank spaces) :http://192.168.14.157/dvwa/ |

6.
Action:
(enter)
1 Mirror Web Site(s)
2 Mirror Web Site(s) with Wizard
3 Just Get Files Indicated
4 Mirror ALL links in URLs (Multiple Mirror)
5 Test Links In URLs (Bookmark Test)
0 Quit
:2

//1:直接镜像站点
//2:用向导完成镜像
//3:只get某种特定的文件
//4:镜像在这个url下所有的链接
//5:测试在这个url下的链接
//0:退出
7.是否使用代理

8.你可以定义一些字符,用来爬特定类型的数据,我们全部类型数据都爬得话,设置*

9.设置更多选项,使用help可以看到更多选项,我们默认,直接Enter

10.开始爬站

11.查看结果
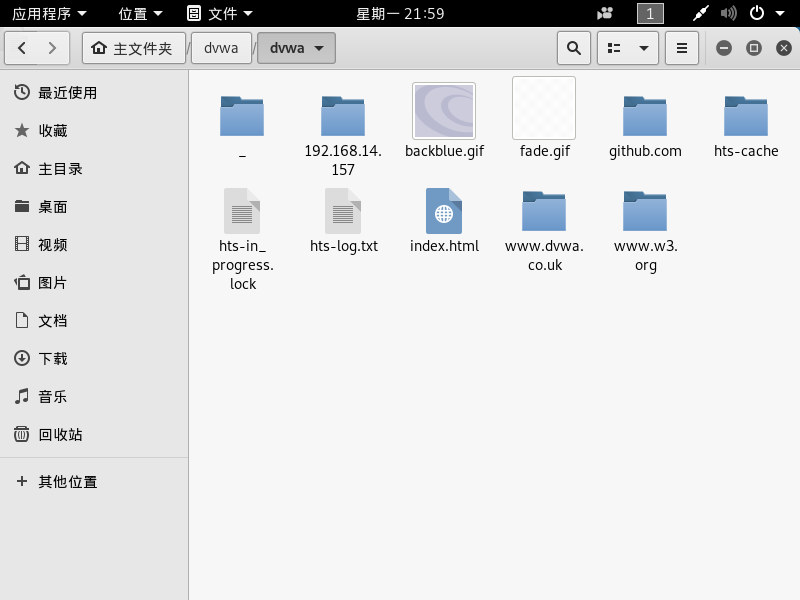


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?