分布式追踪系列:OpenTracing与Jaeger
分布式追踪的概念
谷歌在2010年4月发表了一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》(http://1t.click/6EB),介绍了分布式追踪的概念。
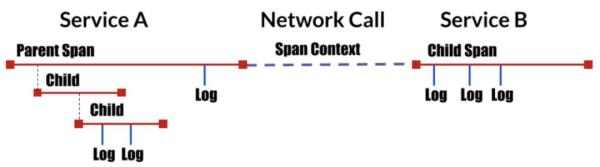
对于分布式追踪,主要有以下的几个概念:
- 追踪 Trace:就是由分布的微服务协作所支撑的一个事务。一个追踪,包含为该事务提供服务的各个服务请求。
- 跨度 Span:Span是事务中的一个工作流,一个Span包含了时间戳,日志和标签信息。Span之间包含父子关系,或者主从(Followup)关系。
- 跨度上下文 Span Context:跨度上下文是支撑分布式追踪的关键,它可以在调用的服务之间传递,上下文的内容包括诸如:从一个服务传递到另一个服务的时间,追踪的ID,Span的ID还有其它需要从上游服务传递到下游服务的信息。
为什么要做分布式追踪
随着搜索系统的扩大和微服务的流行,一次请求涉及的服务往往是很多次调用,这些模块,通常是由不同团队,甚至是不同语言编写的,所以,可能部署在数十台服务器、横款多个数据中心。因此,在排查问题时,就不能人工对调用链路通过日志分析问题,我们需要轻松的获取到调用链上的每次请求的情况,以便能快速定位和分析问题。
所以全链路监控的目标是
- 链路追踪、定位故障
- 各阶段耗时可视化
- 服务依赖调用梳理
- 数据分析,链路优化

什么是 OpenTracing?
OpenTracing 是一个分布式追踪规范。OpenTracing 通过提供平台无关、厂商无关的 API,为分布式追踪提供统一的概念和数据标准,使得开发人员能够方便的添加(或更换)追踪系统的实现。OpenTracing 定义了如下几个术语:
- Span:代表了系统中的一个逻辑工作单元,它具有操作名、操作开始时间以及持续时长。Span 可能会有嵌套或排序,从而对因果关系建模。
- Tags:每个 Span 可以有多个键值对(key: value)形式的 Tags,Tags 是没有时间戳的,支持简单地对 Span 进行注解和补充。
- Logs:每个 Span 可以进行多次 Log 操作,每一次 Log 操作,都需要一个带时间戳的时间名称,以及可选的任意大小的存储结构。
- Trace:代表了系统中的一个数据/执行路径(一个或多个 Span),可以将其理解为 Span 的有向无环图。
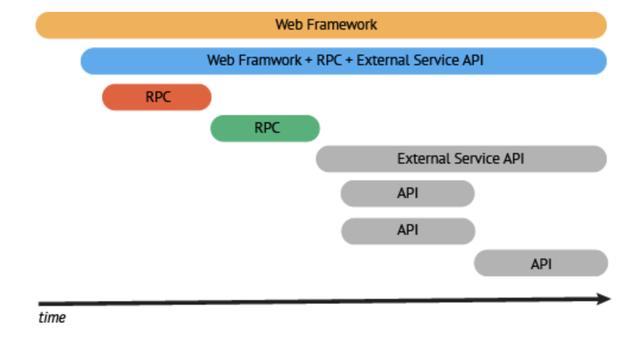
OpenTracing 还有其他一些概念,这里不过多解释。我们看个传统的调用关系例子,如下所示:

在一个分布式系统中,追踪一个事务或者调用流一般如上图所示。虽然这种图对于看清各组件的组合关系是很有用的,但是,它不能很好显示组件的调用时间,以及是串行调用还是并行调用。如果展现更复杂的调用关系,会更加复杂,甚至无法画出这样的图。另外,这种图也无法显示调用间的时间间隔以及是否通过定时调用来启动调用。一种更有效的展现一个典型的 trace 过程,如下图所示:
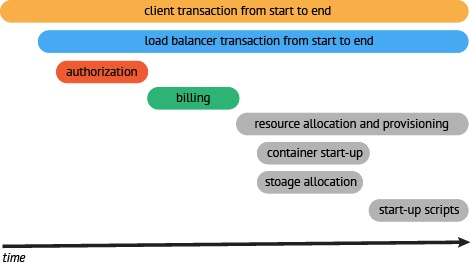
这种展现方式增加了执行时间的上下文,相关服务间的层次关系,进程或者任务的串行或并行调用关系。这样的视图有助于发现系统调用的关键路径。通过关注关键路径的执行过程,项目团队可能专注于优化路径中的关键位置,最大幅度地提升系统的性能。例如:可以通过追踪一个资源定位的调用情况,明确底层的调用情况,发现哪些操作有阻塞的情况。
OpenTracing 标准概念
基于谷歌提出的概念OpenTracing(http://1t.click/6tC)定义了一个开放的分布式追踪的标准。
Span是分布式追踪的基本组成单元,表示一个分布式系统中的单独的工作单元。每一个Span可以包含其它Span的引用。多个Span在一起构成了Trace。
OpenTracing的规范定义每一个Span都包含了以下内容:
- 操作名(Operation Name),标志该操作是什么
- 标签 (Tag),标签是一个名值对,用户可以加入任何对追踪有意义的信息
- 日志(Logs),日志也定义为名值对。用于捕获调试信息,或者相关Span的相关信息
- 跨度上下文呢 (SpanContext),SpanContext负责子微服务系统边界传递数据。它主要包含两部分:
- 和实现无关的状态信息,例如Trace ID,Span ID
- 行李项 (Baggage Item)。如果把微服务调用比做从一个城市到另一个城市的飞行, 那么SpanContext就可以看成是飞机运载的内容。Trace ID和Span ID就像是航班号,而行李项就像是运送的行李。每次服务调用,用户都可以决定发送不同的行李。
这里是一个Span的例子:
t=0 operation name: db_query t=x +-----------------------------------------------------+ | · · · · · · · · · · Span · · · · · · · · · · | +-----------------------------------------------------+ Tags: - db.instance:"jdbc:mysql://127.0.0.1:3306/customers - db.statement: "SELECT * FROM mytable WHERE foo='bar';" Logs: - message:"Can't connect to mysql server on '127.0.0.1'(10061)" SpanContext: - trace_id:"abc123" - span_id:"xyz789" - Baggage Items: - special_id:"vsid1738"
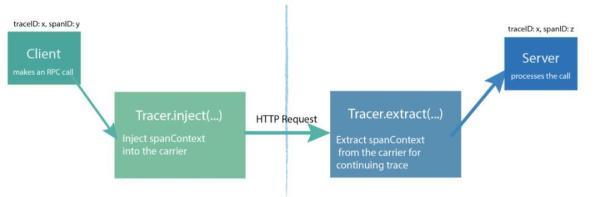
要实现分布式追踪,如何传递SpanContext是关键。OpenTracing定义了两个方法Inject和Extract用于SpanContext的注入和提取。
Inject 伪代码
span_context = ...
outbound_request = ...
# We'll use the (builtin) HTTP_HEADERS carrier format. We
# start by using an empty map as the carrier prior to the
# call to `tracer.inject`.
carrier = {}
tracer.inject(span_context, opentracing.Format.HTTP_HEADERS, carrier)
# `carrier` now contains (opaque) key:value pairs which we pass
# along over whatever wire protocol we already use.
for key, value in carrier:
outbound_request.headers[key] = escape(value)
这里的注入的过程就是把context的所有信息写入到一个叫Carrier的字典中,然后把字典中的所有名值对写入 HTTP Header。
Extract 伪代码
inbound_request = ...
# We'll again use the (builtin) HTTP_HEADERS carrier format. Per the
# HTTP_HEADERS documentation, we can use a map that has extraneous data
# in it and let the OpenTracing implementation look for the subset
# of key:value pairs it needs.
#
# As such, we directly use the key:value `inbound_request.headers`
# map as the carrier.
carrier = inbound_request.headers
span_context = tracer.extract(opentracing.Format.HTTP_HEADERS, carrier)
# Continue the trace given span_context. E.g.,
span = tracer.start_span("...", child_of=span_context)
# (If `carrier` held trace data, `span` will now be ready to use.)
抽取过程是注入的逆过程,从carrier,也就是HTTP Headers,构建SpanContext。
整个过程类似客户端和服务器传递数据的序列化和反序列化的过程。这里的Carrier字典支持Key为string类型,value为string或者Binary格式(Bytes)。
什么是 Jaeger?
Jaeger 是 OpenTracing 的一个实现,是 Uber 开源的一个分布式追踪系统,其灵感来源于Dapper 和 OpenZipkin。从 2016 年开始,该系统已经在 Uber 内部得到了广泛的应用,它可以用于微服务架构应用的监控,特性包括分布式上下文传播(Distributed context propagation)、分布式事务监控、根原因分析、服务依赖分析以及性能优化。该项目已经被云原生计算基金会(Cloud Native Computing Foundation,CNCF)接纳为第 12 个项目。
Jaeger 架构
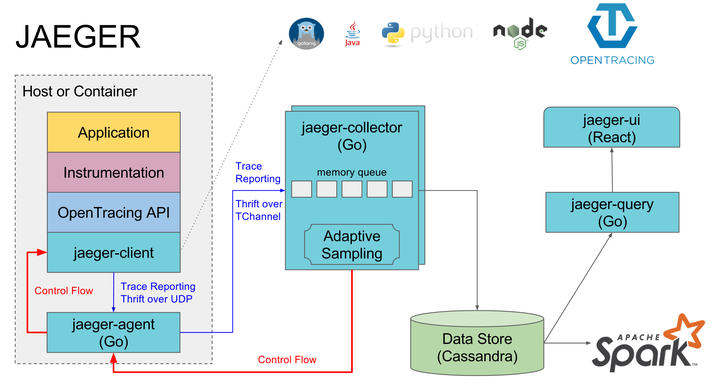
如上图所示,Jaeger 主要由以下几部分组成。
- Jaeger Client - 为不同语言实现了符合 OpenTracing 标准的 SDK。应用程序通过 API 写入数据,client library 把 trace 信息按照应用程序指定的采样策略传递给 jaeger-agent。
- Agent - 它是一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector。它被设计成一个基础组件,部署到所有的宿主机上。Agent 将 client library 和 collector 解耦,为 client library 屏蔽了路由和发现 collector 的细节。
- Collector - 接收 jaeger-agent 发送来的数据,然后将数据写入后端存储。Collector 被设计成无状态的组件,因此您可以同时运行任意数量的 jaeger-collector。
- Data Store - 后端存储被设计成一个可插拔的组件,支持将数据写入 cassandra、elastic search。
- Query - 接收查询请求,然后从后端存储系统中检索 trace 并通过 UI 进行展示。Query 是无状态的,您可以启动多个实例,把它们部署在 nginx 这样的负载均衡器后面。
Jaeger 服务相关端口
Agent
5775 UDP协议,接收兼容zipkin的协议数据
6831 UDP协议,接收兼容jaeger的兼容协议
6832 UDP协议,接收jaeger的二进制协议
5778 HTTP协议,数据量大不建议使用
它们之间的传输协议都是基于thrift封装的。我们默认使用5775作为传输端口。
Collector
14267 tcp agent发送jaeger.thrift格式数据
14250 tcp agent发送proto格式数据(背后gRPC)
14268 http 直接接受客户端数据
14269 http 健康检查
Query
16686 http jaeger的前端,放给用户的接口
16687 http 健康检查
启动 Jaeger + Jaeger UI
我们使用 Docker 启动 Jaeger + Jaeger UI(Jaeger 可视化 web 控制台),运行如下命令:
$ docker run -d -p5775:5775/udp \-p 6831:6831/udp \-p 6832:6832/udp \-p 5778:5778 \-p 16686:16686 \-p 14268:14268 \jaegertracing/all-in-one:latest
浏览器打开 localhost:16686,如下所示:

更多参考:
Python接入jaeger:jaeger-client-python
import logging from jaeger_client import Config import time def say_hello(hello_to): with tracer.start_span('say-hello') as span: span.set_tag('hello-to', hello_to) hello_str = format_string(span, hello_to) print_hello(span, hello_str) def format_string(root_span, hello_to): with tracer.start_span('format', child_of=root_span) as span: hello_str = 'Hello, %s!' % hello_to span.log_kv({'event': 'string-format', 'value': hello_str}) return hello_str def print_hello(root_span, hello_str): with tracer.start_span('println', child_of=root_span) as span: print(hello_str) span.log_kv({'event': 'println'}) def init_tracer(service): logging.getLogger('').handlers = [] logging.basicConfig(format='%(message)s', level=logging.DEBUG) # config = Config( # config={ # 'sampler': { # 'type': 'const', # 'param': 1, # }, # 'logging': True, # }, # service_name=service, # ) config = Config( config={ # usually read from some yaml config 'sampler': { 'type': 'const', 'param': 1, }, 'local_agent': { 'reporting_host': 'xxx.xxx.xxx.xxx', 'reporting_port': '5775', }, 'logging': True, }, service_name='your-app-name', validate=True, ) # this call also sets opentracing.tracer return config.initialize_tracer() tracer = init_tracer('hello-world') say_hello("server2") time.sleep(2) tracer.close()
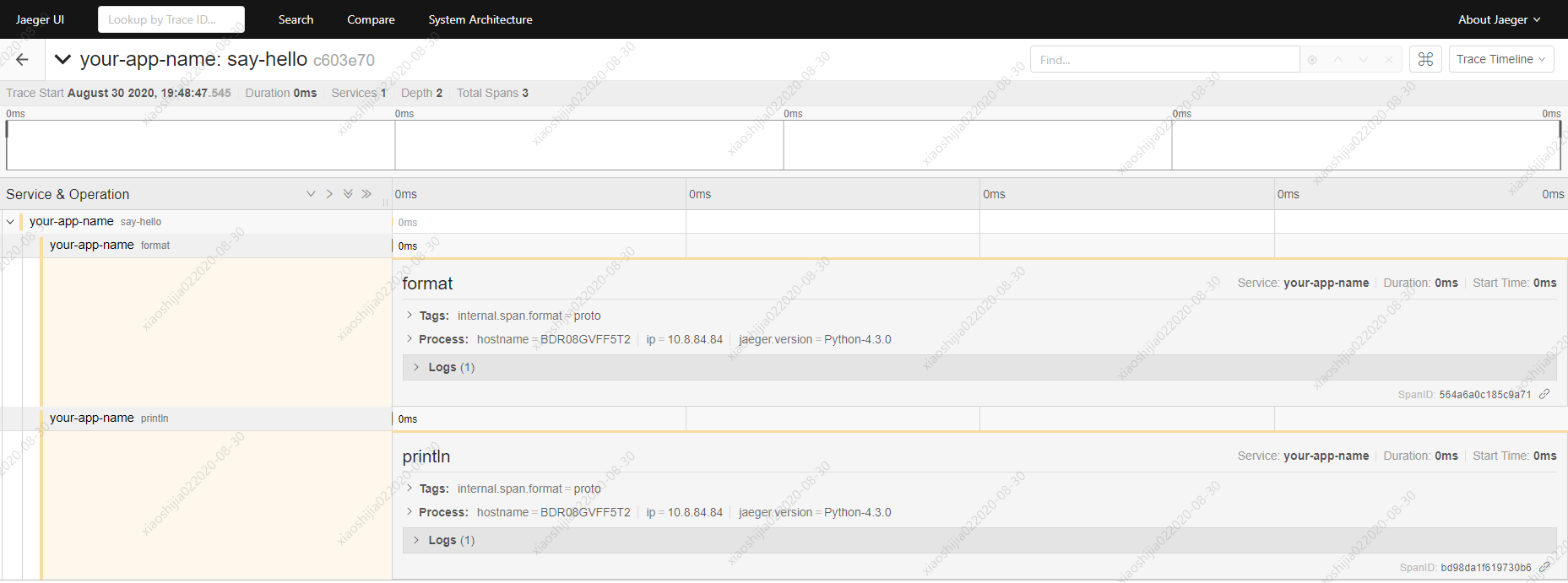
运行后进Jaeger查看结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号