MongoDB学习笔记:快速入门
一、MongoDB 简介
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下,添加更多的节点,可以保证服务器性能。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
二、MongoDB安装及配置
查看:https://www.runoob.com/mongodb/mongodb-linux-install.html
三、MongoDB 特性
- 你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
- Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
- Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
- MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
四、应用场景
大数据量存储场景
MongoDB自带副本集和分片,天生就适用于大数量场景,无需开发人员通过中间件去分库分表,非常方便。
操作日志存储
很多时候,我们需要存储一些操作日志,可能只需要存储比如最近一个月的,一般的做法是定期去清理,在MongoDB中有固定集合的概念,我们在创建集合的时候可以指定大小,当数据量超过大小的时候会自动移除掉老数据。
爬虫数据存储
爬下来的数据有网页,也有Json格式的数据,一般都会按照表的格式去存储,如果我们用了MongoDB就可以将抓下来的Json数据直接存入集合中,无格式限制。
社交数据存储
在社交场景中使用 MongoDB 存储存储用户个人信息及地址位置信息,通过地理位置索引实现附近的人,附近的地点等。
电商商品存储
不同的商品有不同的属性,常见的做法是抽出公共的属性表,然后和SPU进行关联,如果用MongoDB的话那么SPU中直接就可以内嵌属性。
如果你还在为是否应该使用 MongoDB,不如来做几个选择题来辅助决策(注:以下内容改编自 MongoDB 公司 TJ 同学的某次公开技术分享)。
-
应用不需要事务及复杂 join 支持
-
新应用,需求会变,数据模型无法确定,想快速迭代开发
-
应用需要2000-3000以上的读写QPS(更高也可以)
-
应用需要TB甚至 PB 级别数据存储
-
应用发展迅速,需要能快速水平扩展
-
应用要求存储的数据不丢失
-
应用需要99.999%高可用
-
应用需要大量的地理位置查询、文本查询
如果上述有1个符合,可以考虑 MongoDB,2个及以上的符合,选择 MogoDB 绝不会后悔。
来源:https://www.cnblogs.com/williamjie/p/10416294.html
五、数据模型
在MongoDB中:
一个MongoDB 实例可以包含一组数据库,
一个数据库可以包含一组Collection(集合),
一个集合可以包含一组Document(文档)。
一个Document包含一组field(字段),
一个字段都是一个key/value。
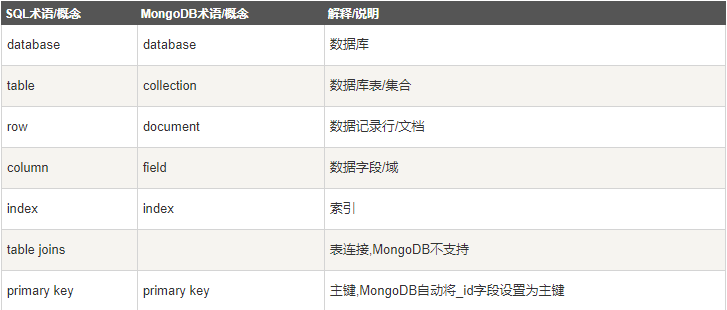
MongoDB与Mysql概念对应表:
六、MongoDB 数据格式及数据类型
数据格式:MongoDB 将数据存储为一个文档,BSON格式。由key 和 value组成。
{ "_id" : ObjectId("5e141148473cce6a9ef349c7"), "title" : "批量更新", "url" : "http://cxytiandi.com/blog/detail/8", "author" : "yinjihuan", "tags" : [ "java", "mongodb", "spring" ], "visit_count" : NumberLong(10), "add_time" : ISODate("2019-02-11T07:10:32.936+0000") }
数据类型
-
字符串 - 这是用于存储数据的最常用的数据类型。MongoDB中的字符串必须为
UTF-8。 - 整型 - 此类型用于存储数值。 整数可以是
32位或64位,具体取决于服务器。 - 布尔类型 - 此类型用于存储布尔值(
true/false)值。 - 双精度浮点数 - 此类型用于存储浮点值。
- 最小/最大键 - 此类型用于将值与最小和最大
BSON元素进行比较。 - 数组 - 此类型用于将数组或列表或多个值存储到一个键中。
- 时间戳 -
ctimestamp,当文档被修改或添加时,可以方便地进行录制。 - 对象 - 此数据类型用于嵌入式文档。
- 对象 - 此数据类型用于嵌入式文档。
- Null - 此类型用于存储
Null值。 - 符号 - 该数据类型与字符串相同; 但是,通常保留用于使用特定符号类型的语言。
- 日期 - 此数据类型用于以UNIX时间格式存储当前日期或时间。您可以通过创建日期对象并将日,月,年的日期进行指定自己需要的日期时间。
- 对象ID - 此数据类型用于存储文档的ID。
- 二进制数据 - 此数据类型用于存储二进制数据。
- 代码 - 此数据类型用于将JavaScript代码存储到文档中。
- 正则表达式 - 此数据类型用于存储正则表达式。
以下原文:https://www.cnblogs.com/Tsoagta/p/8877404.html
MongoDB部署的准备工作
MongoDB可插拔存储引擎
MongoDB提供了一个存储引擎API,作为可插拔存储引擎的接口,使用可插拔存储引擎可以扩大MongoDB的性能,在有限的硬件架构的基础上达到最佳的使用效果。MongoDB提供了多种存储引擎。
l 默认的WiredTiger存储引擎。对于大多数应用来说,WiredTiger的颗粒度并发性以及本地压缩的功能可以提供完美的性能表现和高效的存储表现。
l Encrypted存储引擎可以在脱离单独的文件加密系统的情况下为敏感数据提供加密服务。Enctypted引擎是基于WiredTiger引擎的,所以这篇文章中涉及到WiredTiger引擎的表述同样适用于Encrypetd引擎,此引擎是MongoDB Enterprise Advanced版本的一部分。
l In-Memory存储引擎,可以为高要求的应用可预测的潜在因素以及实时性能分析,此引擎也是MongoDB Enterprise Advanced版本的一部分。
l MMAPv1存储引擎,是MongoDB3.x以及以前版本中使用的存储引擎的升级版本,MMAPv1是MongoDB3.0及以前版本默认使用的存储引擎。
在所有数据库中,MongoDB是唯一允许用户在一个MongoDB集群中使用多个存储引擎的数据库系统。这种灵活性可以提供一种更简单更可靠的方法来满足数据的多样化应用需求。通常,为了满足数据多样化,需要使用不同的数据库系统,并且为了保证一致性以及安全性,需要加入很多复杂的、自定义的代码使数据在不同数据库系统间进行迁移。尽管每个存储引擎对不同的工作负载进行了优化,用户仍然可以在不同的存储引擎中使用相同的MongoDB查询语言、数据模型、扩展方式、安全性以及操作工具。因此,此文档中的最佳实践适用于所有支持的存储引擎。不同存储引擎的使用建议中的不同之处,文档也会做提醒。
在MongoDB复制集中使用多引擎能简化评估以及迁移数据的工作。升级到WiredTiger引擎多现有的复制集是没有影响的;应用会100%兼容系统,使用滚动升级,能在零宕机的情况下完成迁移工作。MongoDB3.2默认的存储引擎就是WiredTiger;如果要使用其他引擎,可以在启动mongod的时候使用—storageEnginge选项。如果使用的是3.2+以上的版本启动的mongod,,并且存在一个或者多个数据库系统,则可以使用任意的数据库创建是使用的存储引擎。
模式设计
开发人员和数据架构师在项目初期就应该一起讨论开发合理的数据模型。数据模型、升级以及MongoDB系统的查询使用应用的需求来驱动的。考虑到MongoDB的动态模型设计特性,开发人员和数据架构师也可以在开发和部署的过程中对数据模型进行迭代以优化性能、存储高效性以及应用特性需要的其他支持。所有这些工作都不需要大规模修改模式。
模式设计的话题讨论是很有意义的,但是本文档不会做深入的讨论。网上有很多相关的资源,包括MongoDB解决方案架构师以及用户的会议演示,还有MongoDB大学的免费网上培训。MongoDB全球咨询服务中的Development Rapid Start service有关于模式设计的咨询。模式设计的几个关键概念如下。
文档模型
MongoDB把数据以BSON这种二进制方式存放在文档中。BSON编码扩展了流行的JSON格式以支持int、long、decimal和date类型。BSON文档包含一个或者多个键,每个键对应一个值。值的类型包含数组、嵌入式文档和二进制数据。文档大概类似于关系型数据库中的行,而键大概类似于关系型数据库中的列。MongoDB一个文档可以包含所有相关的数据,而关系型数据库中相关联的数据通常是在多个表中的多个行里。比如,在关系型数据库中放在两张表中的父子关系这种数据在MongoDB中可以放在一个文档中。
集合
很多文档组合在一起就形成了集合。一般来说,一个集合中的所有文档的作用对应用来说都是类似的或者说有相关联系的。集合可以理解为关系型数据库中的表。
动态图表以及文档验证
MongoDB的文档在结构上是可以变化的。例如,一张用户表可能包含用户ID以及用户最近登录系统的时间,但是只有一部分文档可能会包含用户的购物地址,有些甚至还包含多个用户购物地址。MongoDB不会强制所有的文档保持同样的结构。因此文档的结构是不需要事先声明的——文档是自描述的。
文档验证功能可以对文档结构、数据类型、数据范围以及字段是否强制存在进行检查,从而允许DBA对数据进行强制性管理。这样一来,DBA就可以管理数据标准,而开发人员就可以享受灵活性文档模型带来多种好处。这些内容在以下博客中有所涉及:《文档验证:》
MongoDB Compass帮助识别有用的验证规则,然后可以在GUI中创建这些规则。
索引
MongoDB使用B树索引来优化查询。索引是在文档级别定义的。MongoDB支持很多类型的索引,包括混合索引、地理索引、TTL、文本搜索、偏重索引、唯一所以以及其他的。详情看后文的索引章节。
事务
更新操作的原子性会影响你应用的模式设计。MongoDB可以在文档级别保证更新的ACID原则。一个原子操作不可能更新多个文档,但是,和JOIN一样,把关系型数据嵌入到MongoDB文档中就可以解决这种需求。
模式设计的深入详情可以在MongoDB文档中查看Data Modeling Considerations for MongoDB
使用MongoDB Compass可视化模式并增加验证规则
MongoDB Compass GUI可以让用户清楚明了的了解数据库中的数据结构,即使不掌握MongoDB的查询语言,也可以对数据进行特定的查询。这些用户通常是创建一个新的MongoDB项目的架构师,或者从开发团队接手过来的已有数据库系统,并且需要在生产环境中维护的。你需要理解数据库中存在哪些数据,怎么定义合适的索引,确认是否需要创建文档验证规则以保证文档结构的一致性。
不用MongoDB Compass,如果想了解数据的大致情况,就需要连接到MongoDB shell,并使用查询语句把文档结构、字段名、数据类型反馈给工程师。同样,需要进行自定义查询,就必须要理解MongoDB的查询语言。
MongoDB Compass会采样集合的子文档中的数据并以图形化的方式展现给用户。通过采样,MongoDB可以在最小化消耗数据库负载的情况下及时的把结果展现给用户。
文档验证可以让DBA对文档结构、数据类型、数据范围、必填字段进行强制性管理。具体的验证规则现在也可以在Compass的GUI中进行管理。通过点击几下鼠标就可以创建并修改验证规则,违反规则的文档也可以清晰的展示出来。DBA使用Compass的CRUD功能解决单个文档中的数据质量问题。
文档大小
MongoDB中BSON文档最大支持16M,用户应该避免一些特定的应用程序无限制的使文档增大。例如,电商平台应用中,很难估算每个商品可能会收到多少用户评价,所以,通常的做法是只显示一部分商品评价,比如最近的以及最广泛的评价。相比把商品和评价放在一个文档中,把每个评价或者一组评价单独放在一个文档中会更方便,同时,在存放商品的文档中存放一些主要的评价以便快速访问即可。
GridFS
大于16M的文件,MongoDB提供了GridFS这种功能,所有的驱动程序都支持这种功能。GridFS可以自动地把大的数据分成多个块,每个块256KB,同时维护这些块的元数据。GridFS能检索单个块也能检索整个文档。比如,应用可以快速的跳转到一段视频的具体某个时间戳的位置。GridFS通常用来存储照片以及视频这些比较大的二进制文件。
空间分配调整(仅与MMAPv1存储引擎相关)
在MongoDB MMAPv1存储引擎中更新文档时,如果有足够的空间,数据就地更新。如果更新的文档比分配的空间大,那么文档就需要重新写在新的位置。迁移文档并更新相关索引的过程会消耗很大的I/O并引起一些本可避免的性能问题。
为了预测数据未来的数据量,默认情况下,每个集合的usePowerOf2Sizes属性是开启的。默认情况下(从MongoDB3.0开始),MongoDB会把分配空间四舍五入成2的幂(比如2,4,8,16,等等),这样会减少由于文档迁移造成I/O增大的几率,代价就是需要增加额外的存储。如果你明确数据添加后不会增加,那可以把noPadding设定为true来节省空间。
另外一种做法是设置noPadding为true,并手动为文档进行空间预留以保证文档有足够的空间。如果应用以可预测的方式把数据加入文档中,则可以先添加文档的键,再添键对应的值,这样可以在文档创建的过程中分配合理的空间。空间预留会最小化文档迁移带来的性能损耗,因此能最小化负载。
以上所涉及的内容仅限于MMAPv1存储引擎,不适用WiredTiger引擎以及以WiredTiger为基础的其他引擎,比如Encrypted引擎,它会为每个更新操作进行重写。
数据生命周期管理
MongoDB可以管理数据的整个生命周期,包括TTL索引以及capped集合。除此之外,使用MongoDB Zones管理员可以创建高效的分层存储模型以管理数据生命周期。管理员把分片分配到Zones中,就通过存储密度来平衡潜在的查询压力,同时,基于时间戳这样的值,把数据集分片到指定的存储设备中可以平衡查询消耗:
l 最新的以及访问频率高的数据可以放在高性能的SSD硬盘中,并开启压缩机制。
l 旧数据访问频率低的数据可以放在性能低的硬盘中,并使用zlib压缩,这样达到最小的存储代价
l 当数据不断增加时,MongoDB会自动在存储层级之间迁移数据,不需要管理员创建工具或者ETL进程来管理数据迁移。
TTL
如果集合中的文档只是在固定的时间段内有效,那么TTL特性可以用来自动删除过期文档也不用查看所有文档的日期并进行一系列的删除操作。比如,如果用户session只能在系统中存在一个小时,那么可以为文档中的lastActivity数据字段的TTL设置成3600秒。后台进程会自动检测所有文档并删除时间超过3600秒的文档。TTL最常见的一个例子就是在特定时间后就会过期的价格。
Capped Collections
Capped Collections是固定大小的集合,支持高流量的数据读写。Capped Collections类似于循环缓冲区:数据按照插入的顺序依次插入文档中,当集合的大小达到设定的阈值后,最先插入的数据会被删除掉,为最新插入的数据腾出空间。例如,把日志信息存储在一个高容量的Capped Collections集合中,就可以快速的检索到最新的日志信息。
删除集合
MongoDB中删除集合的操作是非常高效的。如果你的数据生命周期要求周期性删除大容量的文档,那么涉及数据模型时,最好把这些文档放在单个集合中。删除一个集合要远比删除集合中所有文档要高效的多。这就类似于在关系型数据库中删除一个表要比删除表中所有的行要更高效。
使用WiredTiger时,删除集合后硬盘空间会自动回收,在MMAPv1中删除集合后空间会自动释放,并会用于新文档的使用。
索引
和其他大多数数据库管理系统一样,索引是MongoDB中优化系统性能的重要机制。虽然索引可以把操作的性能提升一个或者多个数量级,但是也会为更新操作、磁盘空间、内存带来不小的负荷。用户任何时候都需要为查询创建合适的索引,但是不应该维护一些没有必要的索引。这对那些需要频繁写入的应用来说尤其重要。
为了操作的简单性,MongoDB Ops Manager 和Cloud Manager平台可以识别丢失的索引并且在不影响应用的情况下自动处理这些索引。
要想了解已存在的索引的使用高效性,可以开启$indexStats这个聚合状态,以便确定索引使用的频率。MongoDB Compass可以把索引情况可视化,让你知道哪些字段使用了索引,他们的索引类型以及使用的频率。
查询优化
MongoDB可以自动对查询进行优化并尽可能高效的对查询进行评估。评估通常包括基于谓词的数据选择和基于排序类别的数据排序。查询优化器会周期性的执行多种查询计划并选择性能变现最好的索引。这种经验式测试结果会以缓存查询计划存储下来并周期性执行。
MongoDB有explain工具,可以显示每个查询优化前后的信息,包括:
l 文档返回数
l 文档读取数
l 使用了哪个索引
l 查询是否被覆盖,如果覆盖了,则文档不需要读取以返回数据
l 内存排序是否执行了,如果执行了,就意味着加入索引会更高效
l 索引扫描数量
l 查询多长时间可以返回结果(仅限于使用executionStats模式)
l 那个可选择的查询方案被否决了(仅限于allPlansExecution模式)
如果查询的过程花费不到1ms,那么解释计划会显示0ms,通常,在一个优化过的系统中,查询时间就不应该超过1ms。执行计划确定后,之前的缓存查询计划就会放弃,但是多样的测试索引计划还是会重复执行保证最佳的执行计划会得到实施。查询计划可以在不执行查询的前提下对查询过程进行估算并返回结果,DBA不需要等到查询过程执行完就可以评估使用哪个查询计划。
MongoDB Compass能可视化解释计划的过程,提供查询过程的一些关键信息,比如返回文档数、执行时间、索引使用情况等等。每个执行管道的状态会当做一个节点展现在一个树壮图中,方便查看多节点的解释计划。
如果索引在应用中会经常使用到,就可以设置notablescan选项,当一个查询要扫描整个文档时就抛出一个异常。
归档
MongoDB有一个数据库归档器的功能,可以记录数据库操作的细粒度的信息。归档器可以记录所有事件的信息,也可以记录那些执行时间超过设定阈值(默认的是100ms)的事件。归档数据会存放在一个封顶集合中,并可以很方便的查询到相关数据。查询这个集合中的内容往往比翻找日志文件要方便的多。
如果出现慢查询,用MongoDB Ops Manager 和Cloud Manager(后文会提到)可以把归档器的输出信息可视化。Visual Query Profiler为运维人员和DBA提供快速简便的方式来分析具体的查询语句。Visual Query Profiler会展示查询和写入的延时的随时间变化趋势,这。样就可以方便的识别出那些是慢查询以及那些查询的延迟最高。在Ops Manager的图形界面中点击一下鼠标就可以开启归档器,会在一个界面中展示并整合所有节点的信息。
Visual Query Profiler会分析系统推荐的索引,并通过自动滚动索引创建选择性的添加索引。
主索引和辅助索引
所有文档都会有一个叫做_id的唯一索引。文档插入时,MongoDB会自动的创建一个_id字段,如果用户没有给这个字段知道值,MongoDB会自动为它分配一个值。所有用户定义的索引都叫做辅助索引。MongoDB支持很多类型的辅助索引,并且可以定义在文档中的任何字段上,包括数组以及子文档。索引类型如下:
l 混合索引
l 地理索引
l 文本搜索索引
l 唯一索引
l 数组索引
l TTL索引
l 稀疏索引
l 偏重索引
l 哈希索引
l 针对不同语言的校对索引(MongoDB3.4以后的版本才有)
索引创建选项
MongoDB中索引和数据是同时更新的,保证在索引上的查询不会返回旧的数据或者删除的数据。模式设计的过程中就应该考虑如何设计合理的索引。MongoDB中默认情况下,索引的创建是个阻塞性操作。由于创建索引会消耗很多时间和资源,所以在复制集的主次节点上,索引的创建都可以在后台进行操作。当开启后台操作后,索引创建的总时间会比前台操作的时间要长一些,但是创建索引的过程任然可以对数据库进行查询操作。
一个通常的经验是,在前台创建索引,先在此节点上,再在降级的主节点上创建。这些过程在Ops Manager 和 Cloud Manager中可以自动实现。
除此之外,在后台可以同时创建多个索引。关于索引创建需要考虑的因素已经索引在线维护的更多信息,请参考Build Index on Replica Sets documentation。
在WiredTiger存储引擎中管理索引
所有的存储引擎都在支持MongoDB丰富的索引功能。使用WiredTiger时,有以下几个可供使用的优化意见:
l WiredTiger默认会开启压缩功能以减少永久性存储和RAM上的索引占用。这使得管理员可以分配更多的工作集用来管理那些访问频率高的文档。压缩比率一般是50%左右,但是鼓励用户通过测试他们自己的工作负荷来确定实际的压缩比例。
l 管理员同样可以把索引放在单独的存储卷上,以带来更快的硬盘换页以及避免资产争夺。
索引限制
跟其他数据库系统一样,MongoDB中的索引也会占用硬盘空间以及消耗内存,所以需要的时候再用索引。索引会影响更新操作的性能。每个更新操作需要先定位到要修改的数据,这个时候就会使用索引,但是索引本身的维护也是需要开销的,这就会降低更新操作的性能。
部署MongoDB时有几个限制因素需要考虑:
l 一个文档最多只能建64个索引
l 索引不能超过2014比特
l 索引名字不能超过125个字母(包括命名空间)
l 没有索引的内存数据排序不能超过32M,这种操作很消耗CPU,内存数据排序最好是创建索引来优化查询
索引的常见错误
下列的使用意见可以避免索引常见的问题:
l 使用混合索引而不用索引交叉:通过多个字段查询内容时,使用混合索引可以提供更好的性能。
l 混合索引:混合索引是通过字段来定义和排序的。所以,如果索引定义在last name、first name、city这三个字段上,查询last name或者查询last name和first name的时候就可以使用刚才创建的索引,但是,如果查询是基于city字段的,则使用刚才的索引并不会起到索引的效果。另一个经验是删除是其他所以前缀的索引。
l 低选择性索引:索引应该建立在那些选择范围比较大的字段上。例如,在性别这个字段上创建索引效果的不明显,不如把索引创建在zip代码或者电话号码这样的字段上。
l 正则表达式:索引是按照值来排序的,所以,前置通配符的效率并不高,还很可能导致全索引扫描。如果表达式中有足够多的区分大小写的字母,则使用后置通配符会更高效。
l 清除不必要的索引:索引会消耗很多资源,它们会占用RAM,字段的值更新时,相关联的索引也需要同时更新,就会导致额外的磁盘I/0消耗。使用$indexStats聚合状态可以决定索引使用的频率,从而查看每个索引的使用高效性。如果有些索引使用不到,就可以删除它以便减少磁盘占用并加快写入速度。在MongoDB Compass GUI中可以查看索引的使用情况。
l 偏重索引:如果一个索引只会被特定的一些文档使用到,则可以通过指定一个过滤条件为索引这是偏重选项。比如,如果一个定义在userId字段上的索引只是在查询未完成订单时才用到,那么,可以为它增加一个订单状态时正在交易中这样的条件。这样,偏重索引可以增加查询性能并减少系统负荷。
工作集
MongoDB会充分使用RAM以加速数据库操作。所有数据的读取和操作都是在内存中完成的。WiredTiger存储引擎使用内部缓存管理数据。MMAPv1使用内存映射文件。从内存中读取数据的时间是以纳秒来度量的,而从硬盘中读取数据的时间是以毫秒来度量的,从内存中读取数据的速度是从硬盘中读取数据的1000000多倍。
通过正常操作获取的数据集合索引叫做工作集。最理想的效果是所有的工作集都是在RAM中。有时候,工作集只代表整个数据的一部分,比如在最常访问的数据是最新以及最受欢迎的产品的应用中。
当MongoDB试图获取不在内存中的数据时就会发生页面错误。如果有空闲的内存,则操作系统会定位到硬盘上的页面中并把数据直接加载到内存中。然而,如果没有足够的内存,操作系统必须把内存中的某个页面数据写入硬盘中,当应用取数据时,把需要的数据页读到内存中。这个过程很耗时,比直接从内存中取数据要慢的多。
有些操作会无意间清楚很多内存中的工作集,这会严重影响系统性能。比如,有一个查询操作扫描了数据库中的所有文档,文档中的数据量超过了RAM的容量,这就会导致文档的所有数据被读取到内存中并导致内存中的工作集别挤出内存到硬盘中。其他一下数据库维护的操作也会引起这样的问题,比如数据库优化或者数据库恢复以及索引重建。
如果你数据库工作集超过了系统RAM的容量,可以考虑增大RAM容量或者增加数据库分片数量。有关这方面的讨论话题,请参考Sharding Best Practices中的有关章节。系统资源达到瓶颈之前部署分片是非常容易的,所以容量规划是一个成功项目的中的一个重要环节。
使用默认的WiredTiger存储引擎时,配置WiredTiger内部缓存大小可以参考https://docs.mongodb.com/manual/administration/production-notes/#id3
如果配置了MMAPv1,关于如何配置RAM大小可以参考:https://docs.mongodb.com/manual/faq/diagnostics/#how-do-i-calculate-how-much-ram-i-need-for-my-application
MongoDB启动和配置
启动
MongoDB同时提供了.ded和.rpm的包用户系统安装、升级、系统迁移以及系统配置。MongoDB的Windows安装包可以通过MSI下载的二进制文件安装,OS X的二进制文件也在tarball2中提供。
数据库配置
用户应该把数据库的配置信息存放在mongod的配置文件中。这样系统管理员可以为整个集群实施合理的配置信息。配置文件支持mongod命令行提供的所有选项。MongoDB支持流行的自动化管理工具比如Chef和Puppet。Ops Manager 和 Cloud Manager平台可以自动配置复制集合分片集群的复杂拓扑,这些内容文档后面会提到。
升级
建议用户经常升级数据库系统,不仅可以使用新系统中的最新特性以及稳定性,还能修复系统bug。系统升级应该现在非生产环境中测试。
MongoDB支持滚动升级,在不宕机的情况下完成升级,复制集中每个成员都可以单独升级,不会影响数据库的可用性。复制集中的每个成员可以运行不同版本的MongoDB,也可以配置不同的存储引擎。作为保障,升级前最好参考MongoDB版本说明,看各个版本升级是否有特定的顺序要求,或者两个版本之间是否存在不兼容。Ops Manager 和Cloud Manager中,这些操作可以自动完成。
数据迁移
用户应该进行评估并为应用做出设计出最佳数据模型,而不是简单的把原有系统的数据直接导入MongoDB中。传统关系型数据库中,数据更多的是以CSV这样的文件类型在系统之间进行迁移。MongoDB数据库可以接受CSV类型的文件系统,但是这只是数据迁移的第一步工作。通常来说,MongoDB的文档数据模型有很多优势和选择性,而这在关系型数据库是没有的。
Mongoimport 和mongoexport工具可以把JSON或者CSV文件导入或者导出到MongoDB文件系统中。这些工具只是在数据初始化的时候有用。Mongodump和mongorestore工具或者Ops Manager以及Cloud Manager备份工具可以在MongoDB系统之间数据迁移的时候用到。
把JSON文件导入系统中有很多选择,包括mongoimport,自定义脚本、ELT工具。
硬件
以下的意见旨在为你的MongoDB系统的硬件提供高质量的指导。硬件的具体配置还要依赖于你的数据、查询频率、性能SLA、访问量以及底层硬件设施的容量。MongoDB有非常丰富的经验帮助客户选择合适的硬件并进行配置,我们会经常协助客户进行容量规划以及优化他们的MongoDB系统。当你为项目选择硬件时,可以查考以下资料,会有很大的帮助:Health Check、Operations Rapid Start, 以及Production Readiness consulting packages。
MongoDB对商业硬件支持度很高,对硬件需求和限制很少。通常来说,MongoDB会最大程度的利用RAM和CPU时钟速度。
内存
MongoDB会最大程度的使用RAM以增加系统性能。一般来说,RAM越大越好。跟其他数据库一样,当工作负载开始请求不在RAM中的数据时,MongoDB的性能下降。MMAPv1会让操作系统自己去管理RAM的使用,而默认的WiredTiger存储引擎则是更多的由用户决定分配多少RAM给WiredTiger内部缓存,默认的是RAM*60%-1G,WiredTiger也会利用操作系统的文件缓存系统,而文件缓存系统则会利用系统中剩余的可以内存。
存储
MongoDB不需要共享存储,可以使用本地附加的存储以及固态硬盘。MongoDB中的大多数磁盘访问模式都没有顺序属性,因此客户可能会使用SSD来获得大幅的性能提升。由于MongoDB的非顺序访问模式,商用SATA旋转硬盘的表现可以跟昂贵的旋转驱动器相媲美,与其把预算花在更贵的旋转驱动上,不如把这些开支放在增加RAM以及使用SSD上来的更高效。使用SSD的另一个好处是,如果内存中的工作集满了,则硬盘中的闪存会提供性能优势。
尽管使用SSD可以获取高性能,MongoDB中的日志功能由于其连续写入机制,可以为系统提供更快更方便的硬盘体验。本文档中后续关于日志的章节会有更多的介绍
建议MongoDB部署时使用RAID10。RAID5和RAID6由于其本身显示提供不了足够的性能。RAID0可以提供良好的读写性能,但是系统冗余性不足。MongoDB的复制集可以为数据提供高可用性,要满足系统的高可用,应该考虑复制集、RAID机制以及其他因素。
压缩
使用默认的WiredTiger存储引擎时,MongoDB本身就支持压缩功能。压缩机制能大概减少80%的存储占用,由于从硬盘中读取的数据字节少,能提供更高的存储I/O扩展性。与其他压缩算法一样,管理员使用压缩功能,虽然提供了存储能力,同时带来了较高的CPU负载,因此在你自己的环境中对压缩带来的影响进行测试是非常重要重要的。
MongoDB为文档、索引、日志提供了丰富的压缩选项。默认的Snappy压缩算法在较高的文档以及日志压缩比率(一般是70%,具体要看数据)和较低的CPU负载之间提供了很好的平衡性,zlib算法虽然压缩比率高,但是当数据写入硬盘以及从硬盘中读取时也会导致较高的CPU周期。WiredTiger的索引使用前缀压缩,减少内存中的索引存储的占比,为那些经常访问的数据腾出空间。管理员可以修改默认的压缩设置。压缩机制也可以根据集合的创建指定在特定的集合上使用。
CPU
MongoDB在更快的CPU上能提供更好的性能。MongoDB的WiredTiger存储引擎比MMAPv1能更丰富的利用多核处理器资源。Encrypted存储引擎由于一部分CPU要用来进行加密和解密的工作,会比WiredTiger多平均15%的系统负载,具体的数量还要看你的数据集大小。
每个主机的进程
要获取最佳性能,建议用户在每个主机上单独运行一个mongod。使用虚拟化和容器技术为系统分配合理的容量和资源,这样在单个服务器上就可以运行多个MongoDB进程且不存在资源争夺。使用WiredTiger存储引擎时,管理员需要估算每个实例使用总RAM的比例,并为每个实例分配合理的缓存大小。
为了系统可用性,同一个复制集的多个成员不应该部署在同一个硬件设备上,也不应该共用任何单一的故障资源,比如电源。如果系统部署在云上,确保虚拟化厂商的跨可用性部署能力,以保证每个复制集的成员在物理上是隔离的,不会共用一个电源、应用程序或者网络。
虚拟化以及IaaS
在虚拟化以及云环境中,用户可以把MongoDB部署在裸机之上。一般来说,部署在裸机上的系统其性能表现是最好的,尽管很多MongoDB用户会考虑IaaS平台,比如AmazonWeb Services' Elastic Compute Cloud (AWS EC2), Google Compute Engine, Microsoft Azure, Rackspace以及其他的。
调整mongos和配置服务器进程
对于分片系统,除了数据存储进程,还需要另外部署两个系统:mongos查询路由以及配置服务器。分片服务器是物理隔离的多个服务器。关于分片的更多信息,详见水平扩展相关的章节。所有查询操作会被一个叫做mongos的路由进程路由到合适的分片服务器上。Mongos决定一个查询怎么路由,配置服务器维护的是元数据。Mongos和配置服务器是同样重要的,但是两个都有不同的尺寸要求。
分片中,MongoDB会把文档分成块。MongoDB把块与分片服务器之间的关系当做元数据存放在配置服务器中。每个分片部署中,最少有单个配置服务器以保证任何时候元数据的可用性。分片的元数据访问频率比较大:每个mongos维护一部分缓存数据,这些缓存数据会周期性在后台进行更新,一般是由集群扩张引起的数据平衡操作时。因此配置服务器的硬件配置就尤其需要考虑可用性使用冗余电源、冗余RAID控制器以及冗余存储。配置服务器可以部署成复制集,但是最多只能有50个成员。
一般MongoDB分片系统中会有多个mongos实例。很少有用户为每个应用部署一个mongos实例。Mongos服务器的最佳数量取决于应用的具体负载:有些场合下mongos只是查询路由到合适的分片上,有些场合下mongos除了路由查询还需要把结果集进行合并。评估每个mongos的内存需求时,需要考虑如下几个方面:
l 在mongos中缓存的分片元数据的总大小
l 每个应用链接会消耗1MB
Mongos进程使用的RAM是有限的,CPU越快或者网速越快mongos的表现越好。
操作系统和文件系统
Linux的配置
MongoDB只支持64位的操作系统。安装MMAPv1存储引擎的MongoDB支持32位系统,但是仅仅是为老系统提供向后兼容的作用。WiredTiger存储引擎的MongoDB不支持32位操作系统。
生产环境中MongoDB应该部署在Linux2.6.36内核版本或者以上版本中,使用EXT4或者XFS文件系统;避免使用EXT3,EXT3文件系统是非常古老的文件系统,对数据库系统来说不是最佳的选择。比如,MMAPv1会为数据预分配空间。EXT3文件系统中,预分配操作实际上会写0s到硬盘中以实现空间分配,这是非常耗时的。EXT4和XFS文件系统中,预分配是当做逻辑操作执行的,所以更高效。
使用WiredTiger时,强烈建议使用XFS避免使用EXT4时出现的性能问题。
Linux中部署MongoDB时可以参考以下推荐的配置:
l 关闭数据库文件存储卷的atime属性
l 不要使用HugePages这样的虚拟内存页,使用正常的虚拟内存页MongoDB会表现更好
l 在BIOS中关闭NUMA或者在mongod中禁用UNMA
l 确保存储数据文件的块设备的readahead属性相对较小,因为大部分读取都是非顺序的。比如,可以把readahead设置成32(16KB)。
l 使用NTP这样的同步服务器保证各个主机之间的时间同步,这在分片集群中尤其重要。在虚拟机上部署的MongoDB同样需要注意这个问题。
Linux系统可以控制每个进程和每个用户上打开的文件以及资源的数量。默认的设置堆MongoDB系统是足够用的。通常情况下,一个操作系统、虚拟机和容器上应该只运行MongoDB进程以保证MongoDB不用跟其他进程进行资源抢夺。
由于每个部署的系统对资源的要求都是独一无二的,以下的几个推荐配置可以用在mongod和mongos实例中。使用ulimit属性来应用这些设置:
l -f(文件大小):不限制
l -t(CPU时间):不限制
l -v(虚拟内存):不限制
l -n(打开文件数):大于20000
l -m(内存大小):不限制
l -u(进程数量):大于20000
使用ulimit为MongoDB进行资源限制的更过信息可以参考MongoDB文档中Linux ulimit Settings章节
网络
管理员需要永远保证MongoDB运行在一个可信任的网络环境中,防止未知应用对数据库进行访问。与MongoDB系统进行交互的预知进程是有限的:应用服务器、监控进程、以及运行在复制集和分片集群上的其他MongoDB进程。
MongoDB的进程默认都是与系统上的网络接口进行绑定的。如果你的系统不止一个网络接口,你就需要把你的MongoDB进程与私有接口或者内部网络接口进行绑定。
MongoDB Security Tutorials章节中有关于MongoDB默认端口数量、MongoDB防火墙设置、VPN以及相关话题的更多详情。本手册后面的内容也会提及系统部署的安全方面的最佳实践。
在虚拟机上运行时,使用半虚拟化驱动程序来实现优化的网络和存储接口,以最小的开销在虚拟机和管理程序之间传递指令
集群内网络压缩
作为分布式数据库系统,MongoDB依赖于查询路由与复制集节点指点高效的网络传输。MongoDB3.4引进了一种新的方式对集群之间的信息往来进行网络压缩。基于snappy压缩算法,网络压力可以被压缩到70%以上,不仅可以在宽带有限的环境中提高性能,还能减少网络消耗。
压缩功能默认是关闭的,可以设置networkMessageCompressors为snappy以打开压缩功能。压缩和解压缩会增加CPU的负载,一般会占用百分之几的负载。在CPU资源比较足但是宽带成为性能瓶颈的环境中使用压缩功能是非常理想的。
生产验证的建议
关于操作系统、文件系统、存储设备以及其他相关话题的配置的最新意见可以参考MongoDB Production Notes。
持续可用性
正常操作情况下,MongoDB系统的表现会根据性能以及功能需求来确定。但是,总会有一些必然的故障或者意外的操作会以不同的方式对系统造成影响,硬件、网卡、电源以及其他的硬件组间都存在故障的风险。这些风险可以通过硬件冗余来避免。同时,MongoDB系统也可以在软件层面实现数据冗余性。
日志
MongoDB通过预写日志操作以实现存储引擎的快速灾备恢复以及持久性。服务器宕机的情况下,日志系统可以在系统重启后对数据进行恢复。
日志系统的具体表现取决于配置的存储引擎:
l WiredTiger存储引擎能保证在两个检查点之间写操作可以持久性写到到硬盘中。WiredTiger引擎使用检查点实现数据刷入硬盘中,默认情况下,每60秒或者写入数据达到2G时,就会进行一次刷入操作。所以,如果不开启日志属性的话,WiredTiger会丢失60秒以上的写入数据,尽管这些风险可以通过复制集来避免。
l MMAPv1默认每100ms就会把数据写入到硬盘中,如果日志系统部署在分立的设备中,则默认是30ms。除了可以保证持久性,日志功能还可以防止系统在未知宕机的情况下的数据腐败。MMAPv1默认是开启日志功能的。生产环境中都应该开启日志功能。
WiredTiger和MMAPv1共有的一个特性是压缩功能,以减少存储容量。
为了额外的保证,管理员可以配置日志写关注,这样MongoDB只会在数据写入日志后才确认。
数据冗余
MongoDB使用本地复制集会维护多个数据副本。建议用户使用复制集防止数据系统掉线。MongoDB中的复制集故障转移是全自动的,不需要人工进行干预。
复制集由多个复制集成员组成。任何时候,一个成员充当主节点,其他成员充当此节点。如果主节点由于各种原因(比如主机宕机)出现故障,其中的一个次节点会自动被选举为主节点并接受所有的写入操作。
选举的过程是由复杂的算法控制的,保证所有次节点中最合适的成员被推举为主节点以较少不必要的故障风险。选举算法包含很多变量,包括分析历史数据确认哪些复制集成员从主节点哪里过去到最新的数据,心跳以及连接状态,还有其他用户定义的优先级。例如,管理员可以设置,次数据中心的副职及成员只有在主数据中心的主节点故障后才能被推举为主节点的候选人。一旦新的主节点被选举出来,其余的次节点就会自动的从新的主节点同步数据。如果之前的主节点重新上线了,会发现自己已经不再是主节点,并充当次节点的角色。
MongoDB复制集中的成员是可配置的,复制集成员越多,就可以为系统提供越大的保障。一个节点宕机,系统还是会正常运行。遇到故障后,DBA和系统管理员应该及时恢复或者替换有故障的设备以减轻系统暂时的弹性压力。
多数据中心复制集
MongoDB副本集允许在数据中心内部和跨数据中心进行灵活的部署设计,从而解决服务器,机架和区域级别的故障。如果MongoDB复制集是跨多个机房部署的,则遇到自然或人为灾难,单个机房的故障可以在不宕机的情况下得到解决。
写关注
MongoDB中,当把数据写入数据库中时,管理员可以使用写关注这个功能保证数据的持久性,并可以指定不同的级别。下面介绍的这几个选项可以在每个链接、每个数据库、每个集合甚至每个操作中进行配置。
l Write Acknowledged:这是写关注默认的配置。Mongo会去确认写操作的执行结果,并把网络、主键重复、文档重复以及其他异常反馈给客户端。
l Journal Acknowledged:只有数据被写入到主节点的日志后,mongod才会确认写操作的执行结果。这个配置能保证mongod在意外宕机的情况下写操作仍然可以写入到磁盘中。
l Replica Acknowledged:也可以等到数据同步到其他复制集成员后再确认,并且支持指定到具体那几个成员中。这就可以保证写操作写入到此节点的日志中。由于复制集成员可以在一个数据中心跨机架部署,也可以跨机房部署,所以把写操作执行到其他复制集成员中可以提供极大的耐用性。
l Majority:这种写关注的配置会等数据应用到复制集中的大多数成员中后,才确认。也能保证数据写入这些复制集成员的日志中。
l Data Center Awareness:使用标签集,可以创建复杂的策略保证数据可以写入具体的复制集组合中。比如,你可以创建这样一条策略,要求数据至少写入两个洲的三个数据中心才行,或者一个数据中心分布在不同机架的两个服务器中。详情见Data Center Awareness。
复制集读选项
默认情况下,读取是从主节点读取的,这样能保证一致性。如果系统读取量比较大,建议使用MongoDB的自动分片功能,把读取操作分散到多个主节点上。
有些应用的复制集可以提高MongoDB系统的容错性。比如,分析系统以及商务智能系统这类的应用就可以在次节点上进行查询操作,这样就可以较少主节点上的负载,实现在单个系统中提供业务和分析操作。还可以直接把读取操作路由到离用户最近的复制集上,对于全球分布部署的应用来说就可以有效的减少读取延迟。
primaryPreferred配置选项是个非常实用的选项,它的作用就是只有在主节点故障时把读取路由到次节点上。在故障转移的过程中实现读取的可持续性。
读关注
为保证数据的隔离性和一致性,把readConcern配置为majority就可以保证,只有主节点的数据被写到大多数复制集成员后,应用才能读取到主节点的数据,并且在故障的时候不能回滚。
MongoDB3.4的读关注增加了“linearizable”属性,这个属性保证当次节点被暂时选为主节点的时候,主节点的数据不会被回滚。配置这个属性会在一定程度上影响系统的延迟性,因此,需要设置一个maxTimeMS值,保证操作不会长时间执行。
MMAPv1中,没有readconcern这个属性。
主节点选举
主节点不可达的时候,如果你使用了read preperence属性而不是默认的primary属性,那么系统任然可以读取数据,但是不能写入数据到复制集中,除非出现以下情况:
l 主节点恢复
l 举行选举后,其中一个此节点选举为主节点
如果主节点只是短时间内不可达(比如,短暂的网络故障),那么最好的方式就是等待主节点重新恢复故障。然而,如果主节点在短时间内恢复不了,那么最好是系统可以快速选举出新的主节点接管主节点的工作。很显然,这些情况在实际中都需要权衡。
MongoDB3.2引进了一种增强的复制集协议,可以在主节点出现故障后快速的实现服务恢复,同时保证系统持久性。增强的复制集协议扩展了Raft一致算法,增强了系统部署的灵活性,同时保证对原有复制集结构的兼容性。尤其是,这种协议支持replica set arbiters, replica set member election priorities。
增强协议通过优化算法,可以在主节点故障时快速的选举中合适的次节点。故障转移的时间又很多因素决定,比如网络延迟。避免系统出现不必要的故障是非常重要的,使用electionTimeoutMillis参数可以调整故障恢复时系统的表现:
l 参数值越大,故障恢复时间越长,但是可以减小系统对网络延迟的敏感性以及主节点上的负载
l 参数值越小,故障恢复时间越短,但是会增加系统对网络延迟的敏感性以及主节点上的负载。
MongoDB系统扩展
用分片进行水平扩展
MongoDB使用分片技术来实现数据库水平扩展的目的,分片对应用来说是透明的,不可见的。分片可以把系统的数据分布在多个复制集中,通过自动数据平衡功能,MongoDB保证在数据体积增大或者集群扩大或者减少的情况下,数据可以平均的分布在各个分片服务器中。MongoDB分片的好处就是在不增加应用的复杂性的前提下,可以突破单个服务器RAM和I/O的瓶颈限制。
MongoDB提供三种分片策略以支持多样化的查询模式:
l Range-based 分片:系统会根据片键把文档分配到不同的分片服务器上。片键值相似的文档有可能会被分配到同一个分片服务器上。这种方式适合于那些基于范围的查询的应用。
l Hash-based 分片:在这种分片方式下,文档会根据片键的MD5哈希值平均的分配到各个分片服务器上。片键值大小差不多的文档一般不会被分配在位置相邻的分片服务器中。这种方法保证了在分片之间均匀分布的写入 - 只要分片密钥具有较高的基数 - 使其成为写密集型工作负载的最佳选择。
l Zones:MongoDB Zones可以精确控制物理存储数据的位置,适应很多部署场景,比如地理位置、硬件以及配置,或者应用。管理员可以修改片键范围来不断的完善数据存放规则,MongoDB也会自动的把数据迁移到新的域中。MongoDB3.4添加了新的帮助功能以及Ops Manager and Cloud Manager中额外的选项以便配置Zones,用以管理庞大的系统部署。
尽管分片的功能强大,但是同时也会为系统部署带来一定的复杂性,并且它也会对基础架构提出一定的需求。所以,只要在需要的时候才可以根据实际的需求对系统进行分片。
在如下几个场景下用户就应该考虑使用分片。
l RAM有限制:系统活跃工作集以及索引如果超过系统RAM的最大容量,则可以考虑使用分片
l 硬盘I/O有限制:系统有大量的写入操作,并且系统写入速度远远不能满足需求或者I/O已经限制了数据刷入硬盘的速度。
l 存储限制:数据集的容量超过系统单个节点所能承受的压力。
l 对地理位置有需求:数据需要被分配到指定的数据中心以实现读写的低延迟。或者,创建多温度存储设施,把热数据和冷数据分离开。
如果遇到上述的场景,或者可能在以后会遇到上述场景的,就应该及时使用分片,不要等到容量已经不够用的时候在分片。使用分片设计数据模型的时候,需要考虑在那个集合上进行分片,以及使用哪个联合片键。如果系统已经达到了最大容量值,那么在不影响应用的前提下对系统进行分片是很有挑战性的。
分片最佳实践
使用分片时可参考如下实践:
选择合适的片键:选择片键需要考虑如下三个方面:
- 基数:数据分区默认是由64M的块来管理的。片键基数底(比如用户的家乡)会把文档分散在较小范围的几个分片上,这样可能就需要频繁的对块进行重新平衡。所以,片键的基数需要大些。
- 写入分片:数据写入应该最终分散到所有分片服务器上。如果片键是单调增长的,那么即使片键的基数大,数据也会写入到单个服务器上,这样会产生写入高峰点。所以片键应该最终都分布开来。
- 查询隔离:查询应该被指定到具体的分片上以最大化系统的扩展性。如果查询不能分离到具体的分片上,那么所有的片键会在一种分散/集中的模式下进行查询,这样查询的效率很低。
在需要之前就提前进行容量扩展:在系统过载前对系统进行容量扩充,那么集群更易于维护及管理。
至少运行三台配置服务器以便保证系统的冗余性:生产环境至少运行三台配置服务器,并且服务器放在可以应对各种故障的网络拓扑里。
使用复制集:复制集和分片是完全可以兼容的。所有的部署都应该使用复制集,有需要的情况下再使用分片。分片允许数据库使用多个服务器以便满系统的冗余性。复制集则可以在服务器间、服务集群间甚至数据中心之间维护多份数据样本。
使用多个mongos实例。
使用最佳实践实现批量导入:提前把数据分散到多个数据块中,在写入过程中不需要进行数据平衡。或者,在批量数据导入的过程中禁用数据平衡器。同样,使用多个mongos实例平行导入,也能减少压力。
动态数据平衡
数据导入MongoDB系统后,系统会通过集群中的平衡器这一进程对数据进行动态平衡。平衡器同一时间只会移动文档中的一个数据块并且只会在数据块的容量超过允许值后才进行操作,这样可以最小化平衡操作对系统造成的影响。当然,也可以禁用平衡器或者对其进行配置使其更小化的影响系统性能。
地理分布
MongoDB中可以把具体的片键范围分配到具体的物理分片中。Zones分片可以让管理员控制集群中文档的地理位置。
系统管理员可以结合复制集、Zones分片、读偏好以及写关注这些特性来部署地理分布式集群,这样用户可以直接在本地数据中心进行数据读取。管理员可以把分片集合限制到具体的分片服务器中,有效的为不同的用户提供分片服务。比如,我们可以把所有关于USA的数据分配到位于美国的分片服务器上。
MongoDB管理:规划、监控、灾备恢复
Ops Manager是由开发MongoDB数据库系统的工程师开发的一款管理工具,也是运行MongoDB的最简单的一种方式,运营团队使用Ops Manager可以方便的部署、监控、备份以及扩展MongoDB系统。Ops Manager中的很多功能在MongoDB Cloud Manager服务中也是可用的。Cloud Manager支持数以千计级别的部署。使用MongoDB Enterprise Advanced的组织可以选择使用Ops Manager或者Cloud Manager。
Ops Manager和Cloud Manager提供了最佳实践以保证数据库系统的健康及优化。通过可靠的自动的鼠标操作或者API来代替繁复的手动操作任务。
l 部署:任何结构任何规模的都可以
l 升级:不宕机,几分钟即可完成
l 扩容:应用不下线的前提下完成系统扩容
l 例行性备份:灾难是不可预测的,但是在Ops Manager和Cloud Manager中只需要点几下鼠标即可实现集群在运行的情况下恢复到任何备份的时间点。
l 性能警告:可支持监控100台以上的节点,为系统提供预警信息。
l Roll Out Indexes:从备节点开始到主节点逐个增加索引,避免增加索引的时候影响应用的性能
l Manage Zones:配置Zones以决定数据存储在什么位置
部署、升级
Ops Manager通过安装在每个服务器上的代理与服务器进行数据交互,因此它可以协调MongoDB系统中服务器的关键操作任务。服务器可以部署在公有云上也可以部署在私有数据中心。Ops Manager能高效可靠的完成传统上需要管理员手动完成的操作,比如部署新的集群、系统升级、创建新的备份时间点、迁移索引等等。
Ops Manager能持续的评估系统并做出调整来应对系统中出现的问题。
l 在各个服务器中安装Ops Manager代理,也可以通过Chef或者Puppet这样的配置工具进行安装。
l 管理员为系统创建一个调整目标或者修改目标(比如系统升级、oplog的大小调整、增加新的分片等)
l 代理周期性检查Ops Manager服务中心是否有更新,如果有就接受调整指示。
l 代理接受调整指示后会按照指示目标去实现。通过复杂的规则引擎,调整目标改变后,代理会及时调整自己的目标计划。如果遇到宕机情况比如重大事故或者网络问题,代理就会修改目标计划,达到一个安全状态。
l 几分钟之后,调整目标系统就会安全可靠的实现。
除了部署新的数据库系统外,Ops Manager和Cloud Manager可以导入已经存在的MongoDB系统并接管他们的控制权。
除了初始化部署外,Ops Manager和Cloud Manager还可以动态的调整系统容量—增加分片和复制集的数量。其他维护任务,比如MongoDB升级或者调整oplog的大小这些复杂的手动操作,在Ops Manager和Cloud Manager中都可以通过点击鼠标来轻松实现,并且全部是在不影响业务系统的情况下。
DBA的日常工作需要在生产环境中迁移新的索引。为了最小化影响生产环境,最好是进行滚动索引创建,也就是现在次节点进行操作,再把主节点降为次节点并对其进行索引创建。这些操作可以手动完成,但是在Ops Manager 和Cloud Manager中,这些操作是完全自动化的,减少操作失误以及发生故障的几率。
管理员可以直接使用Ops Manager的图形化界面,也可以从已有的企业工具,比如流行的监控软件以及架构框架中调用Ops Manager的API接口。
监控、容量规划
对于MongoDB应用,系统性能和容量规划都两个很重要的话题。规划应该为以下几方面建立一个基线:数据体积、系统负载、系统性能、系统容量使用率。这些基线应该能反应出你期望的系统在生产环境中所表现的负载。而且要周期性的拿出来作为你修改用户数量、应用特性、性能以及其他配置的参考数据。
基线可以帮助你了解系统何时按照设计的方式运行,何时会出现影响用户体验的问题。监控系统的不同寻常的变现可以避免系统出现问题。下面会介绍监控MongoDB常用的监控工具以及需要监控的不同方面。
使用Ops Manager 和Cloud Manager对系统进行监控
Ops Manager可以监控100多个关键数据库以及系统的监控指标,包括操作计数器、内存、CPU、复制集状态、打开连接数、队列以及节点状态,并且可以使用图标、自定义仪表盘展示,还可以自动发出告警。
各种指标可以在浏览器中进行处理、聚合、报警提示以及视图化展示,使管理员轻松的掌控MongoDB的实时监控状况。查看的视图可以添加明确的权限控制,不同的项目团队只能看自己的应用,系统管理员可以查看所有的组织的内容。
MongoDB3.4中系统每隔10秒就可以收集数据,之前的系统则是每隔60秒。
历史性能数据可以用来创建操作基线以供容量规划使用。通过Ops Manager的API接口与已有的健康工具进行集成也很方便。
监控指标很多时,管理员可以自定义告警。告警的通知方式也多种多样,有SMS、邮件、webhooks、Flowdock, HipChat, 和Slack,或者集成到PagerDuty这样的管理系统中,这样可以在小问题升级成故障前主动预警潜在的问题。
使用Cloud Manager时,MongoDB的技术支持工程师也可以获取到监控数据,省去不同团队之间发送日志文件的过程,快速解决问题
硬件监控
Munin node是一款开源软件,可以监控磁盘以及RAM利用率等指标。Ops Manager可以从Munin node中收集监控数据,并且可以把Ops Manager中可用的数据提供给Munin node。由于每个应用以及部署都是独一无二的,建议用户为所有监控指标设置合理的监控阈值。
Mongotop
mongotop是MongoDB自带的一个功能组件。可以跟踪并展示MongoDB集群当前读写性能。mongotop可以在集合层面提供统计数据。
Mongostat
mongostat是MongoDB自带的一个功能组件。能展示MongoDB系统中所有服务器的实时分析数据。mongostat可以综合展示系统所有操作,比如更新、插入操作的数量、缺页、索引缺失以及系统其它的健康因素。mongostat类似于Linux操作系统中的vmstat工具。
MongoDB Compass
对输出的文字信息进行解析能快速的解决查询性能问题。MongoDB Compass可以把mongotop和mongostat生成的实时数据图形化展示,允许DBA生成服务器状态和查询性能的即时快照。
其他常用工具
对于很多常用的开源监控工具,MongoDB都有可用的插件。如果MongoDB配置的存储引擎是WiredTiger,请确保下列工具使用的是WiredTiger编译过的驱动:
l Nagios
l Ganglia
l Cacti
l Scout
l Zabbix
l Datadog
Linux工具
可以用来监控MongoDB系统其他方面性能的常用工具如下:
l iostat:为存储子系统提供使用情况分析数据
l vmstat:监控虚拟内存的使用情况
l netstat:监控网络状态
l sar:周期性获取系统的趋势数据并存储下来方便分析
Windows工具
Windows系统中,性能监控器对监控系统状态是个不错的选择。
监控相关
Ops Manager 和Cloud Manager可以监控数据库指定的指标,包括页面错误、ops计数、队列长度、连通性以及复制集的状态。每个监控指标都可以设定告警,在系统出现问题之前主动的给管理员提供预警信息。
应用日志和数据库日志
应用日志和数据库日志是系统排错的主要依据。有时候为了确认系统的故障是否是由应用引起的,就需要把应用日志和数据库日志关联起来。比如,用户写入高峰期会增加MongoDB系统写入容量,就会使底层存储过载。如果不把应用日志和数据库日志关联起来排错,遇到上述问题很可能认为是MongoDB的运行的程序引起的,而不会想到是应用引起的这个问题。
如果遇到错误或者意外的情况发生,提技术case的时候应该同时提供日志信息。主次节点以及mongod服务器、配置服务器上的日志信息会帮助技术支持软对快速的定位的问题的发生原因。
页面错误
工作集数据超过内存,或者其他操作把工作集数据移出内存时,MongoDB系统的页面错误会激增。页面错误是MongoDB系统正常操作的一部分,但是建议管理员监控页面错误的容量,以便查看工作集的大小是否超过内存。大部分情况下,MongoDB系统的底层问题很有可能是由页面错误引起的。
硬盘
除了内存,硬盘I/O也是MongoDB的一个关键性能指标,因为日志信息和数据写入会定时刷入到硬盘中。数据写入压力很大时,会引起硬件设备过载、进程抢夺资源以及RAID配置无法承受写入压力等情况。尽管引起问题的原因很多,使用iostat可以查看症状,比如较高的硬盘利用率和较高的写入队列等。
CPU
有很多因素会使CPU的利用率增高。这在很多情况下是正常的,但是如果不是由于硬盘饱和或者页面错误导致的CPU利用率高,那么说明系统中肯定异常。比如,MapReduce中的无限循环,或者在没有索引的工作集中进行大量的数据写入,都会在不影响硬盘或者页面错误的情况下导致CPU过载。
连接
MongoDB有连接池的功能,这样就可以充分利用资源。每个链接会消耗1M的RAM,所以需要谨慎的监控连接数,不要使连接数占用过多的RAM,节省资源用户工作集。连接数过载通常是由于客户端没有正常关闭链接,尤其是使用垃圾回收机制关闭链接的JAVA。
队列
如果MongoDB不能及时完成所有请求,那么请求就会形成队列。一个健壮的系统,它的队列是比较低的。如果度量标准开始偏离了基线性能,比如,可能是由页面错误或者长时间的查询引起的,那么,应用的请求就会形成队列。因此,查看系统是否存在影响用户体验的一个重要指标就是队列。
系统配置
MongoDB部署过程中经常需要对硬件进行调整。比如,我们经常会用硬盘子系统取代现有硬盘以便提供更好的性能和更大的容量。当硬件原件调整后,需要确认他们的配置适应系统部署。MongoDB对操作系统的性能和底层硬件是很敏感的,通常情况下,系统的默认设置并不是很理想。比如,文件系统的默认readahead值是几M,但是,通常会把这个值优化到32KB。如果新的存储系统使用默认的readahead值,而不进行优化,那么应用的性能会大幅降低。
分片平衡器
分片的一个目的就是要平均的把数据分散到多个服务器中。如果各个服务器资源的利用率不是平均分配的,那说明系统肯定有潜在的问题存在。比如,分片键如果选择不合适,就会导致数据分配不均匀。这种情况下,大多数查询会被路由到单个mongod服务器中。因此,MongoDB系统会试图重新分配数据,使数据达到理想的平衡状态。尽管重新分配会使文档达到比较理想的分布状态,但是重新平衡的过程也会涉及到一些潜在的工作,重新平衡的过程也会使系统达到理想的性能状态。通过运行db.currentOp()可以查看当前系统运行的进程,包括集群中运行的重新平衡进程。
MongoDB3.4中,平衡器支持多线程数据迁移。多个节点可以同时进行迁移工作,有效的提高迁移效率。除此之外,平衡器的节流功能默认的是关闭的,可以把迁移的速度提高10倍以上。
如果系统部署过程中,需要加入新的片键,那么就有必要对数据进行重载,因为片键的值是固定不变的。建议编写脚本来读取文档,并且更新片键,并把数据再写回到数据库中。
复制延迟
复制延迟就是数据写入主节点后,往次节点同步所花费的时间。低延迟是很正常的,但是如果延迟比较高,那么说明系统肯定是有问题的。引起复制延迟的常见的原因有网络延迟、网络连接问题、硬盘延迟,比如次节点的吞吐量比主节点的吞吐量小。
配置服务器可用性
分片环境中,至少需要三个配置服务器。配置服务器是系统的至关重要的一部分,通过配置服务器可以知道分片中文档的地理分布状态。如果配置服务器其中有一个出现问题,数据库还能运行,但是平衡器确不能迁移数据,同时所有进行的进程会被锁定,直到所有三台配置服务器都正常。
配置服务器默认部署形式是复制集。配置服务器的复制集可以跨越三个以上的机房以及多达50个复制集成员,提供高度可用性以及低延迟性。
灾备恢复:备份和恢复
系统应该具有完善的备份以及恢复机制保证你的关键数据免受灾难性故障,比如数据中心遭遇洪水或者火灾,再比如代码错误或者无意的删除集合这样的人为失误。拥有合理的备份和恢复策略,管理员就可以在无数据丢失的情况下恢复系统,企业也能满足监管和规范要求。最好可以定期备份。备份也可以在不影响生产系统的前提下用来作为开发、演示、QA部署环境。
Ops Manager 和 Cloud Manager的备份是在系统操作的几秒后就会持续维护的。如果MongoDB集群遇到故障,最近的备份可能最会延迟几秒钟,这样可以最小化数据丢失。Ops Manager和Cloud Manager是MongoDB中唯一能提供复制集时间点备份以及分片集群快照的工具。你可以快速安全地把系统恢复到任意的具体的时间节点。Ops团队使用Ops Manager和Cloud Manager可以安全可靠的对系统进行自动恢复。点击几下鼠标就可以建立完整的开发、测试以及恢复环境。也可以把备份指定到具体的集合上,加快备份的速度同时减少备份空间。
由于Ops Manager只读oplog,所以在线性能影响可以达到最小化。
使用MongoDB Enterprise Advanced你可以部署Ops Manager以控制你本地数据中心的备份,或者使用Cloud Manager服务的现收现付模式。专门的MongoDB工程师全天候监控用户备份,在出现问题时提醒操作团队。
Ops Manager和Cloud Manager并不是唯一的备份机制,还有其他选择:
l 文件系统备份
l MongoDB自带的mongodump工具
文件系统备份
文件系统备份可以快速高效的创建文件系统的快照,可以作为数据库的备份以及恢复使用。单实例数据库可以使用db.fsyncLock()命令暂时停止操作以便对系统做快照,这个操作会把所有等待写入的数据刷入到硬盘中,并把整个mongod实例锁定防止新的数据写入,使用db.fsyncUnlock()命令可以解锁。
关于如何使用文件系统创建的备份的更多信息,请参考MongoDB文档中的Backup and Restore with Filesystem Snapshots章节。
只有Ops Manager和Cloud Manager可以自动为MongoDB分片集群提供自动备份功能。
mongodump
mongodump是MongoDB自带的一个可以在线备份的工具,它可以知道导出整个数据库,也可以只导出固定的集合或者一组查询结果。MongoDB在dump数据的过程中会记录oplog中的内容,这样就可以备份某个时间点的数据,使用mongorestore进行恢复时,再回放oplog中的内容。使用mongorestore可以把mongodump导出的数据再导入到数据库中。
第三方监控方案与MongoDB做集成
Ops Manager API通过编程访问自动化功能和监控数据,提供与外部管理框架的集成。
除此之外,MongoDB Enterprise Advanced还可以把系统信息发给SNMP,支持第三方监控对数据进行集中化管理和聚合。
APM集成
很多运营团队都使用APM平台在统一的管理界面中一览整个IT架构的运行情况。不管是由于设备、硬件、网络、API、应用代码还是数据库等等引起的影响客户体验的问题都会及时得到解决。
Mongodb驱动器可以把查询性能指标提供给APM工具。管理员可以监控每个操作所消耗的时间,并识别出那些慢查询以便进行分析和优化。
除此之外,Ops and Cloud Manager还提供了与New Relic平台集成的相关包。Cloud Manager中的重要指标可在APM中图形化展示,对MongoDB的健康状况做监控。
如上图所示,APM界面可以展示所有的监控指标。管理员也可以运行New Relic对监控数据进行监控并生成数据数据仪表盘以实时追踪KPI指标。
安全
跟其他软件一样,管理员在部署MongoDB的时候必须考虑系统安全以及风险。对于风险转移,并没有完美的解决方案,维护系统安全是一个不断优化的过程。
深度防御
生产环境中建议使用深度防御的方式,它可以为风险管理提供不同的解决方法。
深度防御的目的就是要把系统环境进行分层,防止单个节点出现问题后,入侵者或者不信任的连接访问到数据库系统中的底层数据。减少风险的最有效的方式是控制权限、遵循最小权限机制、建立健全的安全机制并遵循实际的最佳实践。
MongoDB Enterprise Advanced具有丰富的防御、预测依据访问控制的特性,提供很多现代数据库具有的完善的安全机制:
l 用户权限管理:对于数据库、集合以及文档中的固定的域中的敏感数据提供工业标准级别的权限控制。
l 审计:保证监管以及内部合规
l 加密:保证数据在网络传输以及写入硬盘后的安全性
l 管理员控制:快速识别潜在漏洞,并减少其影响
认证
MongoDB可以在数据库系统内部通过挑战/响应机制以及x.509KPI进行管理,或者通过MongoDB Enterprise Advanced与第单方安全机制比如LDAP、Windows Active Directory, 和 Kerberos进行集成。
授权
管理员可以对用户、应用、以及查询后那些数据进行权限控制。还可以定义不同的角色,实现访问数据和管理数据的不同实体之间的职责分离。
审计
管理员使用MongoDB Enterprise Advanced可以为许多操作构建和过滤审计跟踪,不管是DML、DCL还是DDL。比如,不仅可以记录并审核检索特定文档的用户的身份,还可以记录在会话期间对数据库执行的其他操作。审计日志可以以不同的方式展示,比如展示在控制台,或者syslog或者直接输入到文件中(JSON或者BSON),这些信息可以用来做分析。
加密
MongoDB的数据可以在网络层进行加密,也可以在硬盘上进行加密。
MongoDB支持SSL,所以客户端可以通过加密通道连接MongoDB。如果在FIPS验证加密模块中运行FIPS模式时,MongoDB还支持140-2加密。
使用Encrypted存储引擎后,对静态数据的保护就成为了数据库的一个整体特性。在本地硬盘上对数据进行加密可以省去外部加密机制带来的管理以及性能开销。这种新的存储引擎只允许有对应凭据的链接才能取到加密数据。
对原始数据库进行加密时,系统会随机生成一个加密码,把数据加密后,只有使用正确的解码密码才能看到数据。这个过程对应用来说是透明的。MongoDB支持很多加密算法—默认的是CBC模式下的AES-156,当然也支持GCM模式下的AES-256。
只读、编辑视图
从MongoDB3.4开始,DBA可以定义非物化视图,只显示底层集合的一部分数据,比如,过滤具体字段的视图。DBA可以定义从其他集合聚合生成的视图。
使用MongoDB标准查询语句以及聚合管道可以定义视图,允许包含或排除字段、屏蔽特定字段值、过滤、模式转换、分组、分类、限制以及使用$lookup和 $graphLookup进行数据的链接。
广告时间
MongoDB Atlas:MongoDB数据即服务
MongoDB可以为你运行数据库!MongoDB Atlas提供MongoDB的所有特性,无需繁琐的操作。MongoDB Atlas可以按需付费,让你把时间和经理放在你所擅长的事情上。
MongoDB Atlas的上手很简单,通过简明的GUI界面选择实例大小、分区以及以所需要的特性。MongoDB提供一下服务:
l 安全特性,保护你的数据安全
l 内置复制集特性,高可用,支持灾备恢复
l 备份功能以及制定到时间点的数据恢复
l 细粒度的监控机制可以随时了解何时该对系统进行扩容,通过点击数据就可以完成实例的添加
l 自动打补丁,点击鼠标就可以完成重大版本的升级,以便使用最新的MongoDB特性
l 可以按地区、云服务商选择自己所需,同时支持按需收费
MongoDB Atlas功能强大,从概念验证、测试以及问答环境到完整的生产环境集群都可以满足。如果你觉得所有的数据库操作都由自己进行操作,那么把数据库 系统迁移到你自己的基础设施上也很方面。
MongoDB Stitch:后端即服务
MongoDB Stitch是后端即服务,为开发人员提供MongoDB的类似于REST的API,与其他服务也有很好的组合性,可配置灵活的数据权限控制。Stitch同时为JavaScript,iOS和Android提供原生SDK。
.内置的集成可以使你的前端连接到你最喜欢的第三方服务:Twilio, AWS S3, Slack,
Mailgun, PubNub, Google等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号