接口限流算法
限流
限流顾名思义,提前对各个类型的请求设置最高的QPS阈值,若高于设置的阈值则对该请求直接返回,不再调用后续资源。
限流需要结合压测等,了解系统的最高水位,也是在实际开发中应用最多的一种稳定性保障手段。
应用场景:如秒杀、抢购、发帖、评论、恶意爬虫等。
限流算法的三种实现
实际限流可以考虑在 Nginx 层对请求限流,或者如果真的要自己在业务方实现一套限流策略的话,可以考虑基于 Redis 实现分布式限流策略。并且在实际应用中,可能还会基于不同的维度进行限流,如用户 id,请求 IP 等,实际应用需要考虑的东西更多。
计数器法是限流算法里最简单也是最容易实现的一种算法。
假设一个接口限制一分钟内的访问次数不能超过100个,维护一个计数器,每次有新的请求过来,计数器加一,这时候判断,如果计数器的值小于限流值,并且与上一次请求的时间间隔还在一分钟内,
允许请求通过,否则拒绝请求,如果超出了时间间隔,要将计数器清零。
import time class CounterLimter: def __init__(self,interval,limit): #初始时间 self.startTime=time.time() #时间窗口 self.interval = interval #限制请求数 self. limit =limit #请求计数 self.requestCount = 0 def acquire(self): now = time.time() if(now < self.startTime +self.interval): if(self.requestCount<self.limit): self.requestCount +=1 return True else: print("在时间窗口内达到最大请求数") print(self.requestCount) return False else: print("超时重置") self.startTime = time.time() self.requestCount = 0 return True Count = CounterLimter(60,100) for i in range(0,200): time.sleep(0.2) Count.acquire()
计数器限流可以比较容易的应用在分布式环境中,用一个单点的存储来保存计数值,比如用Redis,并且设置自动过期时间,这时候就可以统计整个集群的流量,并且进行限流。
计数器方式的缺点是不能处理临界问题,或者说限流策略不够平滑。
假设在限流临界点的前后,分别发送100个请求,实际上在计数器置0前后的极短时间里,处理了200个请求,这是一个瞬时的高峰,可能会超过系统的限制。
计数器限流允许出现 2*permitsPerSecond 的突发流量,可以使用滑动窗口算法去优化,具体不展开。
漏桶算法
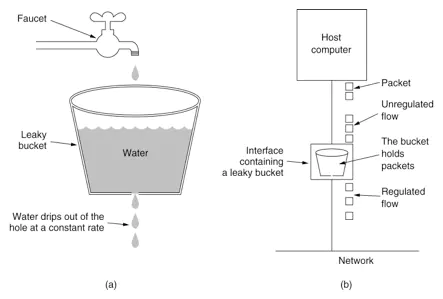
漏桶(Leaky Bucket)算法思路很简单,水(请求)先进入到漏桶里,先触发出水,给漏斗腾出空间,漏桶会以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率.示意图如下:
import time class LeakyBucketRateLimiter(object): def __init__(self, capacity, leak_rate,sec): """ 初始化漏桶 :param capacity: 桶容量 :param leak_rate: 恒定的消费速度(Reqs/秒) :param _water_level:桶当前请求数量 """ self._capacity = float(capacity) self._leak_rate = float(leak_rate) self._water_level = 0.0 self.sec = sec # 上次漏水的时间 self._last_time = time.time() def acquire(self, level=1): # 现在时间戳 now = time.time() #每超过时间间隔self.sec秒,处理一次 if (now - self._last_time >= self.sec): delta = int(self._leak_rate * (now - self._last_time)) #如果桶中的请求数小于应该处理的请求数 if (self._water_level <= delta): delta = self._water_level - 0 self._water_level = 0 else: self._water_level = self._water_level - delta #执行请求:从队列中取出delta个请求 print("请求流出数量:",delta) self._last_time = now # 尝试加水,并看水桶是否满了 if level + self._water_level > self._capacity: print("请求溢出") else: #添加请求到队列中 self._water_level += level print("现在桶中的请求数:",self._water_level) #桶的大小为10,速率为3Reqs/秒 LeakyBucket = LeakyBucketRateLimiter(10,3,1) # for i in range(0,200): time.sleep(0.2) LeakyBucket.acquire()
令牌桶
令牌桶算法(Token Bucket)和 Leaky Bucket 效果一样但方向相反的算法,更加容易理解.随着时间流逝,系统会按恒定1/QPS时间间隔(如果QPS=100,则间隔是10ms)往桶里加入Token(想象和漏洞漏水相反,有个水龙头在不断的加水),如果桶已经满了就不再加了.新请求来临时,会各自拿走一个Token,如果没有Token可拿了就阻塞或者拒绝服务.
令牌桶的另外一个好处是可以方便的改变速度. 一旦需要提高速率,则按需提高放入桶中的令牌的速率. 一般会定时(比如100毫秒)往桶中增加一定数量的令牌, 有些变种算法则实时的计算应该增加的令牌的数量.
import time class TokenBucketRateLimiter(object): def __init__(self, capacity=1, fill_rate=1): """ 初始化令牌桶限流器 :param capacity: 令牌桶容量 :param fill_rate: 放入令牌的速度(Reqs/秒) """ self._capacity = float(capacity) self._rate = float(fill_rate) self._bucket_tokens = float(capacity) # 上次添加令牌的时间 self._last_time = int(time.time()) def acquire(self, tokens=1): # 先执行添加令牌的操作 if self._bucket_tokens < self._capacity: now = time.time() if(now - self._last_time >1): delta = int((now - self._last_time) * self._rate) self._last_time = now self._bucket_tokens = min(self._capacity, self._bucket_tokens + delta) if tokens > self._bucket_tokens: # 无法获取令牌了,数量不够 return False self._bucket_tokens -= tokens return True
漏桶和令牌桶的比较
这两种算法的主要区别在于漏桶算法能够强行限制数据的传输速率,而令牌桶算法在能够限制数据的平均传输速率外,还允许某种程度的突发传输。
在令牌桶算法中,只要令牌桶中存在令牌,那么就允许突发地传输数据直到达到用户配置的门限,因此它适合于具有突发特性的流量。
漏桶和令牌桶算法实现可以一样,但是方向是相反的,对于相同的参数得到的限流效果是一样的。
主要区别在于令牌桶允许一定程度的突发,漏桶主要目的是平滑流入速率,考虑一个临界场景,令牌桶内积累了100个token,可以在一瞬间通过,但是因为下一秒产生token的速度是固定的,
所以令牌桶允许出现瞬间出现permitsPerSecond的流量,但是不会出现2*permitsPerSecond的流量,漏桶的速度则始终是平滑的。
refer:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号