互联网中常见的推荐算法
原文链接:各种互联网中常见的推荐算法锦集
我们在上网购物、看小说、买电影票的时候,都会遇到各种各样的推荐,给我们推荐一些我们曾经买过或收藏过的同类型产品,或者是推荐一些我们看过的小说题材相同的小说。那这些产品推荐都是如何实现的呢?
我们今天就来聊聊这些“无聊”的算法。
在互联网的应用中,常用的推荐算法有:协同过滤推荐算法(Collaborative Filtering Recommendation)、内容推荐算法(Content-based Recommendation)、相似性推荐算法(Similarity Recommendation)、关联规则推荐算法(Association Rule Based Recommendaion)。不同的算法都有不同的应用场景,合理的应用这些算法,能够为我们带来更多的经济效益。
协同过滤推荐算法(Collaborative Filtering Recommendation)
协同过滤算法在电子商务领域可以说是炙手可热,很多的电商平台都是使用的它来做的自己平台的商品推荐。
啥是协同过滤呢?
简而言之,就是找到相同兴趣的群体,将这个群体中感兴趣的其他信息推荐给用户。
我们用一个简单的例子来说明这个算法:
我喜欢看网络小说,但是,看网络小说最讨厌的是什么?就是书荒。一本书看完了,下一本看什么呢?挨个的翻开看几章?浪费时间。看书评吧,不是喷子就是托。
这个时候,协同过滤就有用了。
我是用户A,我喜欢看《极品家丁》、《斗破苍穹》、《诛仙》,这些是我的兴趣。怎么定义我的兴趣呢?可以是我看过超过100章的书,可以是我收藏的书,可以是我好评过的书,总之,我们要先行定义一个纬度。
我的兴趣有了,其他用户也会有同样的兴趣,当其他用户的兴趣和我的兴趣相同时,就可以把这些用户感兴趣的书都推荐给我了。
具体的实施步骤如下:
我们先要建立一个大表,X轴就是我们所有的小说(从数据库中可以获得),Y轴就是我们所有的用户(从数据库中可以获得)。


然后我们将每个用户感兴趣的小说在XY的交叉点中都标注出来(在日志中可以获得),也就如下表示:

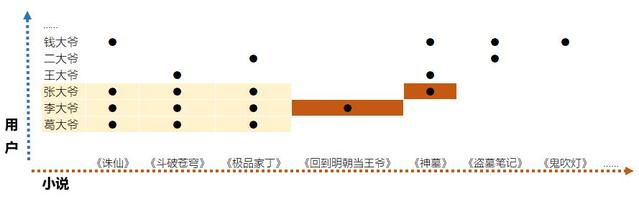
标注出来以后,我们就可以看到,我这个葛大爷的爱好是《极品家丁》、《斗破苍穹》和《诛仙》,而张大爷和李大爷和我有相同的兴趣爱好。而张大爷和李大爷还比我多看了一些小说,而这多出来的部分,就体现除了协同,也就可以作为对我的推荐了。
下一次,当我打开看小说的APP的时候,系统就可以向我推荐这两本小说了,而我也就有很大的可能性去打开观看。
内容推荐算法(Content-based Recommendation)
啥是内容推荐算法呢?
内容推荐算法,其实就是对于用户的历史数据进行分析,抽象出内容的共性,然后根据这些共性进行推荐的算法。
我们也举一个例子来说明一下:
我还是喜欢看小说,我经常通过一些条件来搜索小说,我常常搜索:完本、玄幻、200万字以上。而我搜索的行为,就成了我的历史日志记录。根据我的这些日志记录进行共性的抽象,然后在根据抽象出来的共性内容去搜索小说,然后把这些小说推荐给我。
具体的实施步骤如下:
我通过搜索,选中了3本书并且进行了阅读,而这三次我分别搜索了
玄幻、男频、完本、200万字以上
玄幻、男频、完本、100-200万字
玄幻、男频、连载、不限

我们根据上诉内容进行抽象,可以得到一个最终的结果,就是玄幻、男频、不限、不限的结果,根据这个结果,我们可以去进行搜索,然后按照最新更新或者小说热度对结果集进行排序后推荐给用户,这样,这个结果也能够满足用户的需求。
当然,如果用户查询的次数非常多,导致结果的精度差,我们还可以有其他的一些手段来提高精确度,例如只使用最近3天的查询记录或者只使用最近3次查询记录。
相似性推荐算法(Similarity Recommendation)
协同过滤推荐算法和内容推荐算法都是需要用户有一定量的历史数据,然后再根据这些历史数据进行分析再进行推荐。
那针对新用户应该怎么办呢?那么相似性推荐算法就能够解决这个问题。
啥是相似性推荐算法?
相似性推荐算法,也叫相似度推荐算法,是通过对物品的特性进行分析,然后找出类似物品进行推荐的一种算法。
在相似性算法中,有一个距离(Distance)的概念,两者的距离越近,表示两者相似性越高,距离越远,则相似性越低。通过这个概念,如果我点击了一个小说,那么系统就可以根据这个小说于其他小说的相似性高低,为我推荐合适的小说了。
而计算这个距离,又有非常多的方式,这也是相似性算法的核心。有欧几里得距离(Eucledian Distance)曼哈顿距离(Manhattan Distance)明可夫斯基距离(Minkowski distance)余弦相似度(Cosine Similarity)等等很多种算法,我这里就不具体讲算法了(我也讲不明白,哈哈,大家有兴趣可以自己百度)。
具体实施步骤如下:
我还是喜欢看小说,我打开了《诛仙》这本书,这本书都有些什么属性呢?

我们为小说设置了8个属性,也就相当于8个维度,我们将《诛仙》这本书的所有属性作为了原点,然后通过距离算法计算这些属性之间的距离,汇总后,总距离最近的,也就是最值得推荐的。
假设:属性相同的距离为0,反之为1。
我们就可以得到distance = f(题材)+f(作者)+f(状态)+……+f(类型);
我们去遍历所有的小说,然后计算这个距离。找到一本《诛仙前传:蛮荒行》的书。这本书的属性有6个都与《诛仙》相同,2个不同。最后我们计算出distance为2,是距离最近的一本书,于是进行了推荐。

我们这里虽然将不同的属性权重都假设相同了,但是在现实中,不同属性的权重是不同的。也由于这个不是基于用户的历史数据来做出的推荐,因此,每个用户的推荐结果也是相同的。
关联规则推荐算法(Association Rule Based Recommendaion)
关联规则推荐是电商中使用比较广泛的一种推荐算法,最经典的一个案例就是,把啤酒放在尿布的旁边,能够提升啤酒的销量。
啥是关联规则推荐呢?
要明白关联规则推荐,先要明白关联规则。关联规则就是通过对数据的挖掘和分析,找出物体与物体之间的关联性。而关联规则推荐就是依靠物体之间的关联性进行的一种推荐。
我们还是用我看小说来举例吧
当我找到一本我喜欢看的书的时候,这本书是《诛仙》,我将它加入到了我的书单中,这时,系统就为了推荐了其他几本书(《神墓》、《盘龙》等等),告诉我也可以一起加入到书架中,这种推荐,一般就是关联规则推荐。
关联规则推荐是如何实施的呢?我们再来说一下具体的实施步骤:
首先,我们要找出数据进行分析。
我们把所有的书单都找到,并且将书单中的书都一一列举出来。

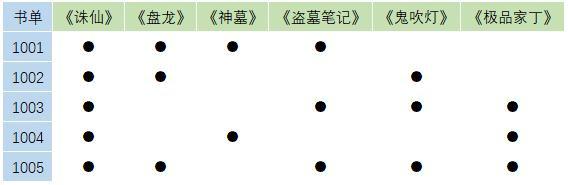
然后,就开始计算关联规则的支持度。
什么是支持度(Support)?支持度就是所有书单中,某一本书或者几本书的组合所占的比例。例如:《诛仙》在所有的书单中都存在,那么它的支持度就是100%,《神墓》只在两个书单中有,那么它的支持度就是40%。

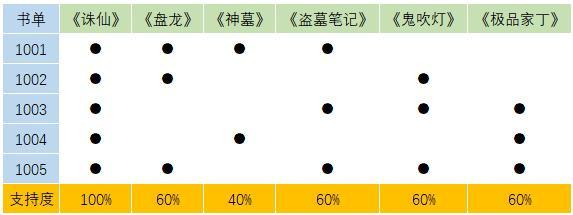
单个商品的支持度我们计算出来以后,接下来我们就是需要计算多商品组合的支持度了。我们将商品两两进行组合,来计算支持度,只有在书单中同时出现这个组合时,才进行计算。我们这里有六本书,那么组合的数量就是15种(5+4+3+2+1=15)。


到这里,其实我们已经可以做出推荐了,我们可以将支持度高的书或组合推荐给用户,这样,这个书就更容易被用户所接受。
接下来,我们就要开始计算关联规则的置信度了。
什么是置信度(Confidence)?当用户往书单添加《神墓》的时候,有多大的概率会去添加《盗墓笔记》呢?这个概率就是《神墓》->《盗墓笔记》的置信度。
《神墓》的支持度(S[神])为40%,《神墓》和《盗墓笔记》(S[神->盗])为20%,那么,《神墓》->《盗墓笔记》的置信度就等于50%(S[神->盗]/S[神])
最后,我们就要来分析关联规则的提升度了
根据支持度的计算,我们发现,收藏《盘龙》书的人,100%都会去收藏《诛仙》,那么是不是说,当用户将《盘龙》进行收藏的时候,我们去推荐《诛仙》是最好的呢?


No,不是这样的。我们为什么要去推荐《诛仙》?那是因为我们想提高《诛仙》的阅读量。但是,我们分析数据后发现,虽然在用户收藏《盘龙》的时候去推荐《诛仙》,用户100%会收藏,但是单独推荐《诛仙》,用户也是100%收藏。这个关联规则推荐并不能为《诛仙》带来更高的阅读量,因此用户收藏《诛仙》和收藏《盘龙》的行为是没有直接关系的。
如何来判断关联规则推荐的效果呢?那就是提升度了。
我们用书A->书B的置信度,同书B的支持度做比较,进行计算:
当比值大于1时,代表在收藏书A时推荐书B是有效的;
当比值等于1时,代表在收藏书A时推荐书B是无意义的,两者没有关联;
当比值小于1时,代表在收藏书A时推荐书B是无效的,不如直接推荐书B。
小结
这里只是简单的抛砖引玉的讲了一下这些算法,但是真正的内容还有很多,我也还在持续的学习当中。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?