pandas常用数据清洗方法
- df.duplicated() :判断各行是重复,False为非重复值。
- df.drop_duplicates():删除重复行
- df.fillna(0):用实数0填充na
- df.dropna():按行删除缺失数据,使用参数axis=0;按列删除缺失值,使用参数axis=1,how = "all" 全部是NA才删,"any"只要有NA就删除
- del df['col1']:直接删除某列
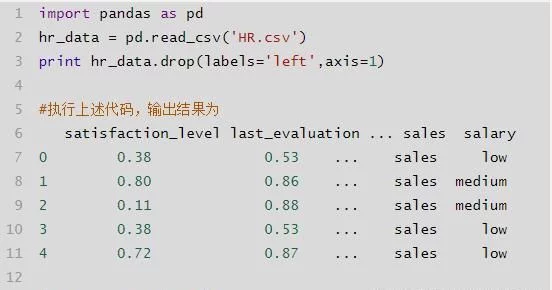
- df.drop([]'col1',……],axis=1):删除指定列,也可以删除指定行
- df.rename(index={'row1':'A'},columns ={'col1':'B'}):重命名索引名和列名
- df.replace():替换df值,前后值可以用字典表,{'1':'A','2:'B'}
- hr_data['col1'].map(function):Series.map,对指定列进行函数转换
- pd.merge(df1,df2,on='col1',how='inner',sort=True):合并两个df,按照共有的列作内连接(交集),outter为外连接(并集),结果排序。
- pd.concat([df1,df2]):多个Series堆叠成多行。
- df1.combine_first(df2):用df2的数据补充df1的缺失值NAN。
数据集介绍
以下各例子均使用如下数据集进行演示。

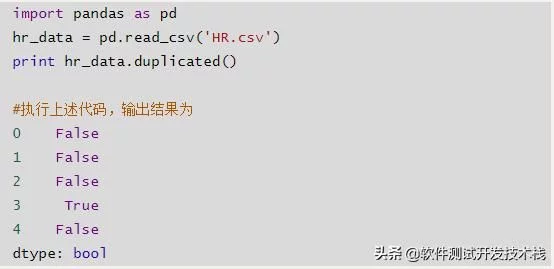
duplicated()
判断各行是重复,False为非重复值。
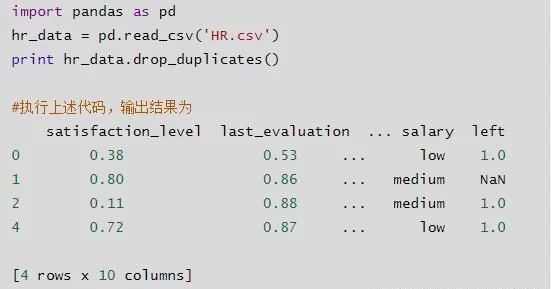
drop_duplicates()
删除重复行
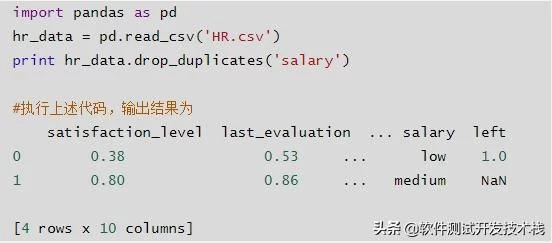
通过指定列,删除重复行
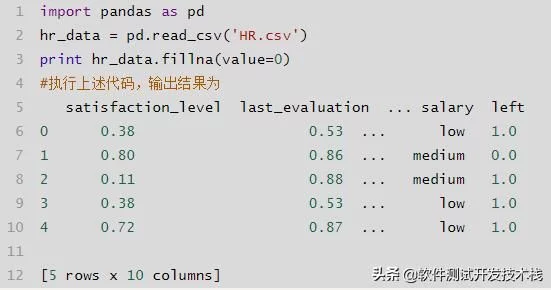
fillna(value=0)
对缺失值进行填充 ,用实数0填充na。
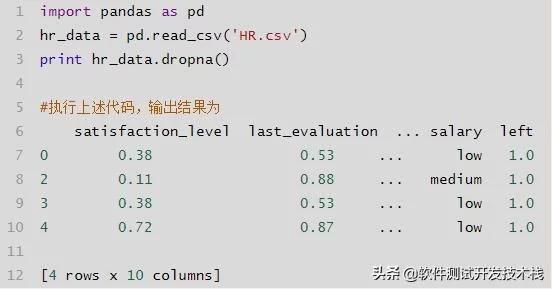
df.dropna()
通常情况下,删除行使用参数axis = 0,删除列使用axis = 1。
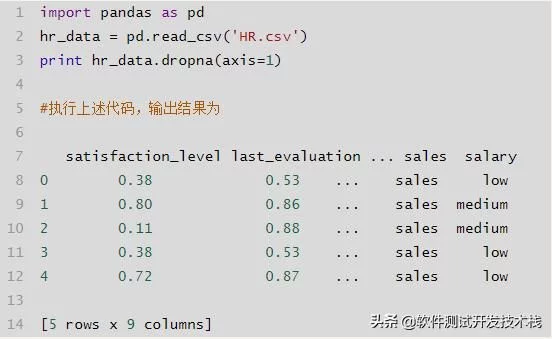
按列删除缺失值,使用参数axis=1。
how = "all" 全部是NA才删,"any"只要有NA就删除

del df['col1']
直接删除某列。

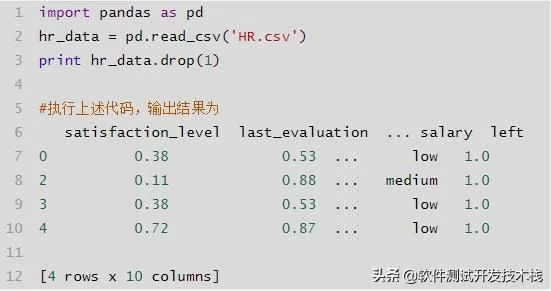
df.drop()
- labels 就是要删除的行列的名字,用列表给定。
- axis=0 删除行,axis=1 删除列。
- index 直接指定要删除的行。
- columns 直接指定要删除的列。
删除指定行
df.rename()
重命名索引名和列名。

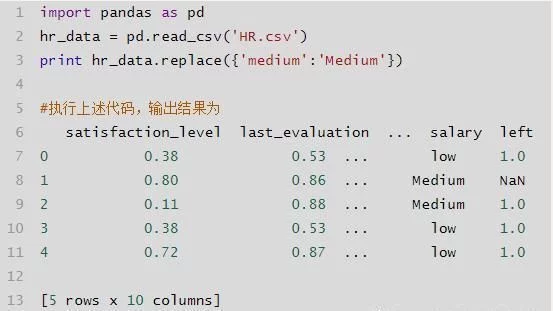
df.replace()
替换df值,前后值可以用字典表,{'1':'A','2:'B'}。
hr_data['col1'].map(function)
Series.map,对指定列进行函数转换。

pd.merge(df1,df2,on='col1',how='inner',sort=True)
merge 函数通过一个或多个键来将数据集的行连接起来。该函数的主要 应用场景是针对同一个主键存在两张包含不同特征的表,通过该主键的连接,将两张表进行合并。合并之后,两张表的行数没有增加,列数是两张表的列数之和减一。
{!-- PGC_COLUMN --}
- on=None 指定连接的列名,若两列需要连接的列名不一样,可以通过left_on和right_on 来具体指定
- how=’inner’,参数指的是左右两个表主键那一列中存在不重合的行时,取结果的方式:inner表示交集,outer 表示并集,left 和right 表示取某一边。

pd.concat([df1,df2])
拼接两个数据集,可在行或者列上合并。
axis=0 是行拼接,拼接之后行数增加,列数也根据join来定,join=’outer’时,列数是两表并集。同理join=’inner’,列数是两表交集。

df1.combine_first(df2)
合并重叠数据,用df2的数据补充df1的缺失值NAN。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?