MyCAT详解【转】
原文链接:MyCAT详解
作者:Rangle
一、MyCAT概述
MyCAT是一款由阿里Cobar演变而来的用于支持数据库读写分离、分片的分布式中间件。MyCAT可不但支持Oracle、MSSQL、MYSQL、PG、DB2关系型数据库,同时也支持MongoDB等非关系型数据库。基础架构如下:
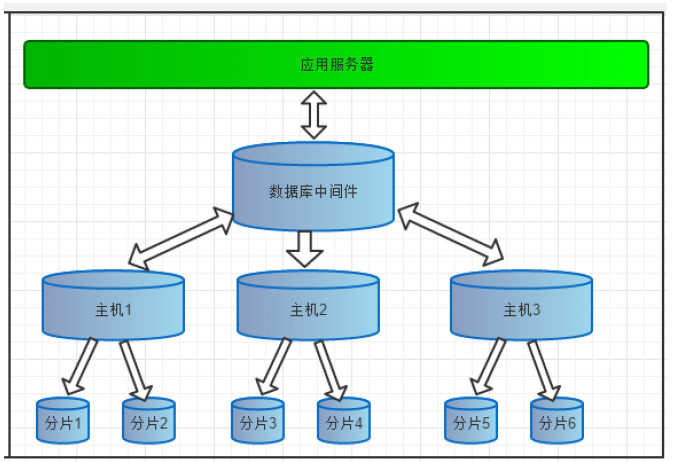
1、MyCAT原理
MyCAT主要是通过对SQL的拦截,然后经过一定规则的分片解析、路由分析、读写分离分析、缓存分析等,然后将SQL发给后端真实的数据块,并将返回的结果做适当处理返回给客户端。
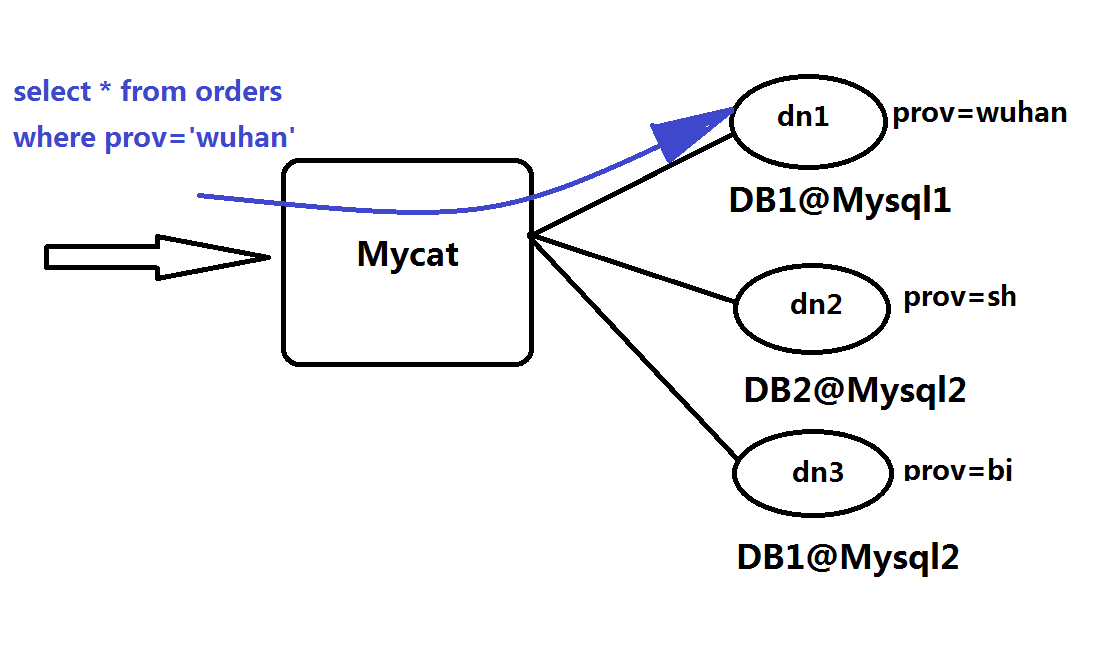
2、MyCAT功能
(1)数据库分片(Sharding)
通过某种条件,将同一数据库中的数据分散的存储到多个数据库中,已达到分散单台数据库设备负载的效果,这就是数据库分片。
a.水平拆分
同一张表的不同记录,根据表的某个字段的某种规则拆分到多个数据库(主机)上,这既是水平拆分。
单库业务表可能会过于庞大,存在单库读写与存储瓶颈,这种情况可以通过水平拆分解决,水平拆分基本架构如下:
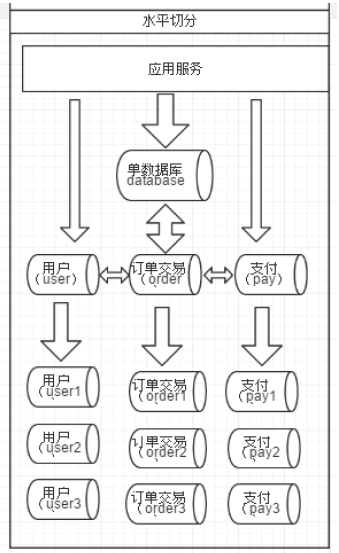
常用水平拆分规则:
*ID
*日期
*特定字段取模
优点:
*拆分规则抽象好,join操作基本可以数据库内完成
*不存在单库大数据,高并发的性能瓶颈
*应用端改造少
*提高了系统稳定性和负载能力
缺点:
*拆分规则难以抽象
*分片事务一致性难以解决
*数据多次扩展难度跟维护量极大
*跨库join性能较差
b.垂直拆分
不同的表切分到不同的数据库(主机)上,这就是垂直拆分。
一般按照业务表进行分类,划分为不同的业务、模块库,耦合度越低,越容易做垂直拆分,垂直拆分基本架构如下:
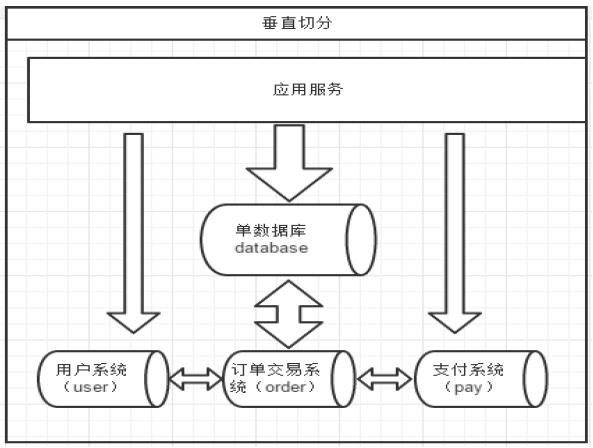
垂直拆分注意点:
跨库Join,采用共享数据源或分库接口调用,根据资源和数据规模、负载而定
优点:
*拆分后业务清晰,拆分规则明确
*系统之间整合或扩展容易
*数据库维护简单
缺点:
*部分业务表无法Join,只能通过接口方式解决,提高了系统复杂度
*受每种业务不同的限制存在单库性能瓶颈,不容易扩展跟性能提高
*事务处理复杂
c.水平拆分和垂直拆分共同缺点
*分布式事务处理困难
*夸节点join困难
*扩数据源管理复杂
d.切分总则
*能不切分的尽量不切分
*如果要切分,选择合适的切分规则,提前规划好
*数据库切分尽量通过数据冗余或表分组来降低跨库join
*业务尽量使用少的多表join
(2)读写分离
(3)黑白名单限制
3、使用场景
(1)单纯读写分离,此时配置最为简单,支持读写分离、主从切换
(2)分库分表,对记录超过1000万的表进行水平拆分,最大支持1000亿单表水平拆分
(3)多租户应用,每个应用一个数据库,但程序只需连接MyCAT,程序不改变,实现多租户化
(4)报表系统,借住MyCAT分表能力,处理大规模的报表统计
(5)替代Hbase,分析大数据
(6)海量实时数据查询
4、优缺点
优点:
(1)支持多种类型数据库的分片
(2)易扩展
(3)
缺点:
二、MyCAT安装
1、下载
官网地址:http://www.mycat.io/
下载地址:http://dl.mycat.io/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
文档地址:http://www.mycat.io/document/Mycat_V1.6.0.pdf
2、mycat安装
1)mycat是java语言编写,在安装mycat前需要安装jdk,本次java版本是1.7
[root@node1 ~]# java -version java version "1.7.0_131" OpenJDK Runtime Environment (rhel-2.6.9.0.el6_8-x86_64 u131-b00) OpenJDK 64-Bit Server VM (build 24.131-b00, mixed mode)
2)解压缩mycat(mycat解压缩后即安装完毕)
[root@node1 ~]# tar -xzvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz -C /usr/local/
3)mycat用户创建
groupadd mycat useradd -r -g mycat mycat chown -R mycat.mycat /usr/local/mycat
4)mycat基本配置
环境变量配置:

[root@node1 ~]# vi ~/.bash_profile
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/bin:/usr/local/mycat/bin
export PATH
[root@node1 ~]# source ~/.bash_profile
schema.xml配置:
[root@node1 ~]# cd /usr/local/mycat/conf/
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="node1" database="db01" />
<dataHost name="node1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="10.20.32.23:3306" user="myuser" password="myuser">
<readHost host="hostS2" url="10.20.32.24:3306" user="myuser" password="myuser" />
</writeHost>
<writeHost host="hostS1" url="10.20.32.24:3316" user="myuser" password="myuser" />
</dataHost>
</mycat:schema>
server.xml配置:
[root@node1 ~]# cd /usr/local/mycat/conf/
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sequnceHandlerType">2</property>
<property name="processorBufferPoolType">0</property>
<property name="handleDistributedTransactions">0</property>
<property name="useOffHeapForMerge">1</property>
<property name="memoryPageSize">1m</property>
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<property name="systemReserveMemorySize">384m</property>
<property name="useZKSwitch">true</property>
</system>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
5)mycat启动
[root@node1 conf]# mycat start Starting Mycat-server... [root@node1 conf]#
6)mycat状态检查
[root@node1 conf]# mycat status Mycat-server is running (27956).
三、MyCAT使用
1、mycat常用命令
./mycat start 启动 ./mycat stop 停止 ./mycat console 前台运行 ./mycat install 添加到系统自动启动(暂未实现) ./mycat remove 取消随系统自动启动(暂未实现) ./mycat restart 重启服务 ./mycat pause 暂停 ./mycat status 查看启动状态
四、MyCAT重要概念
1、逻辑库(schema)
逻辑库是mycat中间件层配置的对应实际一个或多个业务数据库集群构成。
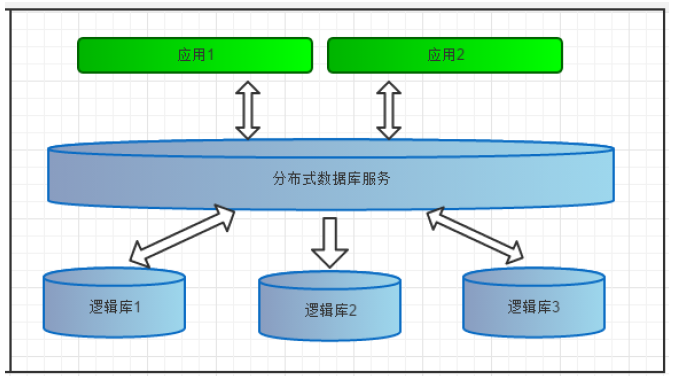
2、逻辑表(table)
a.逻辑表是mycat切分到多个数据库或者不切分对应用程序显示的统一的表。
b.分片表是原有的大表,经过分片,分布在不同数据库、相同数据库的保留相同表结构,但数据不同的表。
c.非分片表是未做切分的表。
d.ER表基于E-R关系分片策略,子表记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组保证数据join不会跨库操作。
e.全局表,业务系统中变化不大、数据量不大(十万以下),但又需要经常关联的表,mycat采用冗余在各个节点一个份来完成。
3、分片节点(dataNode)
数据库分片后,一个大表被切分到不同的分片数据库上,每个表分片所在的数据库就是分片节点。
4、分片主机(dataHost)
分片节点所在的服务器,数据切分后,每个分片节点不一定都会独占一台服务器,同一个分片服务器可能存储多个分片节点,尽量使读写压力高的分片节点均衡的放在不同的节点主机上。
5、分片规则(rule)
按照某种业务规则把数据分到某个分片节点上的规则,就是分片规则。(分片规则非常重要,直接决定后续数据处理复杂度)
6、全局序列号(sequence)
当数据库分片后,原有的主键约束在分布式条件下无法使用,因此需要引入外部机制保证数据唯一表示,这种保证全局的数据唯一表示机制就是全局序列号(sequence)。
7、多租户
多用户的环境共用相同的系统、程序组件,并且确保各用户间数据的隔离性。
a.一个用户一个数据库,隔离级别最高、安全性最好,费用最高
b.共享数据库,隔离数据架构,每个用户一个schema
c.共享数据库,共享数据架构,共享database、schema,通过表tenantID区分租户数据
更多阅读:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号