Go语言并发机制
Go语言中的并发
使用goroutine编程
使用 go 关键字用来创建 goroutine 。将go声明放到一个需调用的函数之前,在相同地址空间调用运行这个函数,这样该函数执行时便会作为一个独立的并发线程。这种线程在Go语言中称作goroutine。
goroutine的用法如下:
1 2 3 4 5 6 7 8 9 10 11 | //go 关键字放在方法调用前新建一个 goroutine 并执行方法体go GetThingDone(param1, param2);//新建一个匿名方法并执行go func(param1, param2) {}(val1, val2)//直接新建一个 goroutine 并在 goroutine 中执行代码块go { //do someting...} |
因为 goroutine 在多核 cpu 环境下是并行的。如果代码块在多个 goroutine 中执行,我们就实现了代码并行。
如果我们需要了解程序的执行情况,怎么拿到并行的结果呢?需要配合使用channel进行。
使用Channel控制并发
Channels用来同步并发执行的函数并提供它们某种传值交流的机制。
通过channel传递的元素类型、容器(或缓冲区)和传递的方向由“<-”操作符指定。
可以使用内置函数 make分配一个channel:
1 2 3 4 5 | i := make(chan int) // by default the capacity is 0s := make(chan string, 3) // non-zero capacityr := make(<-chan bool) // can only read fromw := make(chan<- []os.FileInfo) // can only write to |
配置runtime.GOMAXPROCS
使用下面的代码可以显式的设置是否使用多核来执行并发任务:
1 | runtime.GOMAXPROCS() |
GOMAXPROCS的数目根据任务量分配就可以,但是不要大于cpu核数。
配置并行执行比较适合适合于CPU密集型、并行度比较高的情景,如果是IO密集型使用多核的化会增加cpu切换带来的性能损失。
了解了Go语言的并发机制,接下来看一下goroutine 机制的具体实现。
Go的CSP并发模型
Go实现了两种并发形式。第一种是大家普遍认知的:多线程共享内存。其实就是Java或者C++等语言中的多线程开发。另外一种是Go语言特有的,也是Go语言推荐的:CSP(communicating sequential processes)并发模型。
CSP并发模型是在1970年左右提出的概念,属于比较新的概念,不同于传统的多线程通过共享内存来通信,CSP讲究的是“以通信的方式来共享内存”。
请记住下面这句话:
Do not communicate by sharing memory; instead, share memory by communicating.
“不要以共享内存的方式来通信,相反,要通过通信来共享内存。”
普通的线程并发模型,就是像Java、C++、或者Python,他们线程间通信都是通过共享内存的方式来进行的。非常典型的方式就是,在访问共享数据(例如数组、Map、或者某个结构体或对象)的时候,通过锁来访问,因此,在很多时候,衍生出一种方便操作的数据结构,叫做“线程安全的数据结构”。例如Java提供的包”java.util.concurrent”中的数据结构。Go中也实现了传统的线程并发模型。
Go的CSP并发模型,是通过goroutine和channel来实现的。
goroutine是Go语言中并发的执行单位。有点抽象,其实就是和传统概念上的”线程“类似,可以理解为”线程“。channel是Go语言中各个并发结构体(goroutine)之前的通信机制。 通俗的讲,就是各个goroutine之间通信的”管道“,有点类似于Linux中的管道。
生成一个goroutine的方式非常的简单:Go一下,就生成了。
1 | go f(); |
通信机制channel也很方便,传数据用channel <- data,取数据用<-channel。
在通信过程中,传数据channel <- data和取数据<-channel必然会成对出现,因为这边传,那边取,两个goroutine之间才会实现通信。
而且不管传还是取,必阻塞,直到另外的goroutine传或者取为止。
有两个goroutine,其中一个发起了向channel中发起了传值操作。(goroutine为矩形,channel为箭头)
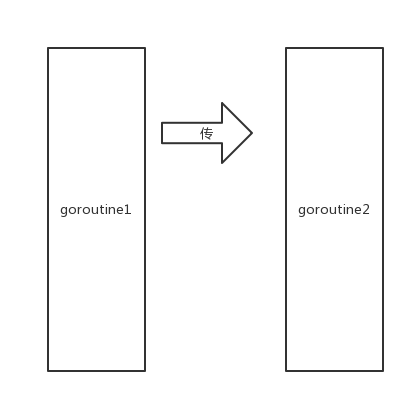
左边的goroutine开始阻塞,等待有人接收。
这时候,右边的goroutine发起了接收操作。

右边的goroutine也开始阻塞,等待别人传送。
这时候,两边goroutine都发现了对方,于是两个goroutine开始一传,一收。
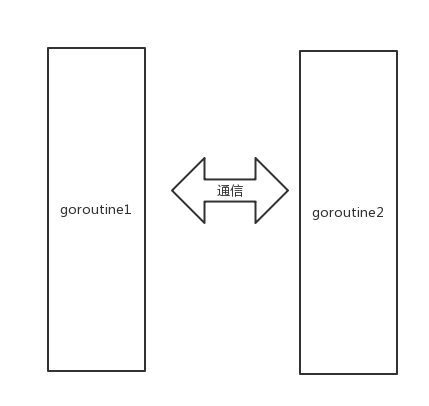
这便是Golang CSP并发模型最基本的形式。
几种不同的多线程模型
用户线程与内核级线程
线程的实现可以分为两类:用户级线程(User-LevelThread, ULT)和内核级线程(Kemel-LevelThread, KLT)。用户线程由用户代码支持,内核线程由操作系统内核支持。
多线程模型
多线程模型即用户级线程和内核级线程的不同连接方式。
(1)多对一模型(M : 1)
将多个用户级线程映射到一个内核级线程,线程管理在用户空间完成。
此模式中,用户级线程对操作系统不可见(即透明)。

优点:
这种模型的好处是线程上下文切换都发生在用户空间,避免的模态切换(mode switch),从而对于性能有积极的影响。
缺点:所有的线程基于一个内核调度实体即内核线程,这意味着只有一个处理器可以被利用,在多处理环境下这是不能够被接受的,本质上,用户线程只解决了并发问题,但是没有解决并行问题。
如果线程因为 I/O 操作陷入了内核态,内核态线程阻塞等待 I/O 数据,则所有的线程都将会被阻塞,用户空间也可以使用非阻塞而 I/O,但是还是有性能及复杂度问题。
(2) 一对一模型(1:1)
将每个用户级线程映射到一个内核级线程。
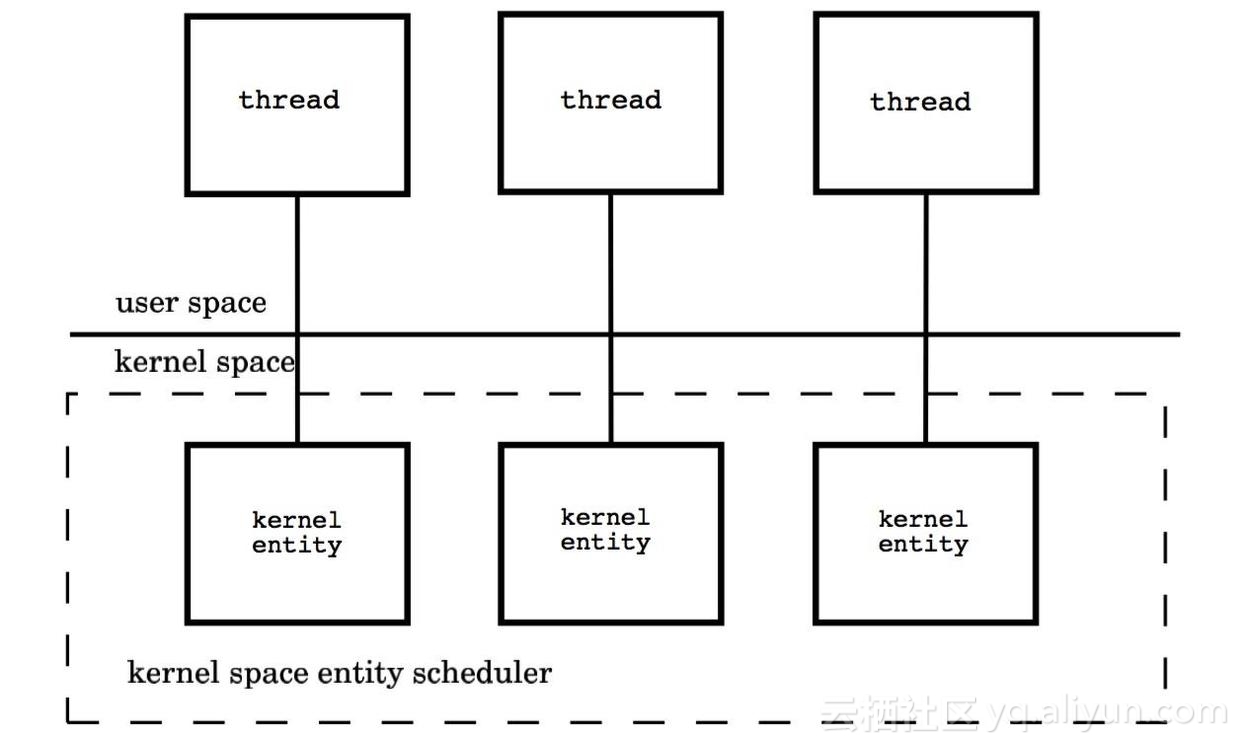
每个线程由内核调度器独立的调度,所以如果一个线程阻塞则不影响其他的线程。
优点:在多核处理器的硬件的支持下,内核空间线程模型支持了真正的并行,当一个线程被阻塞后,允许另一个线程继续执行,所以并发能力较强。
缺点:每创建一个用户级线程都需要创建一个内核级线程与其对应,这样创建线程的开销比较大,会影响到应用程序的性能。
(3)多对多模型(M : N)
内核线程和用户线程的数量比为 M : N,内核用户空间综合了前两种的优点。
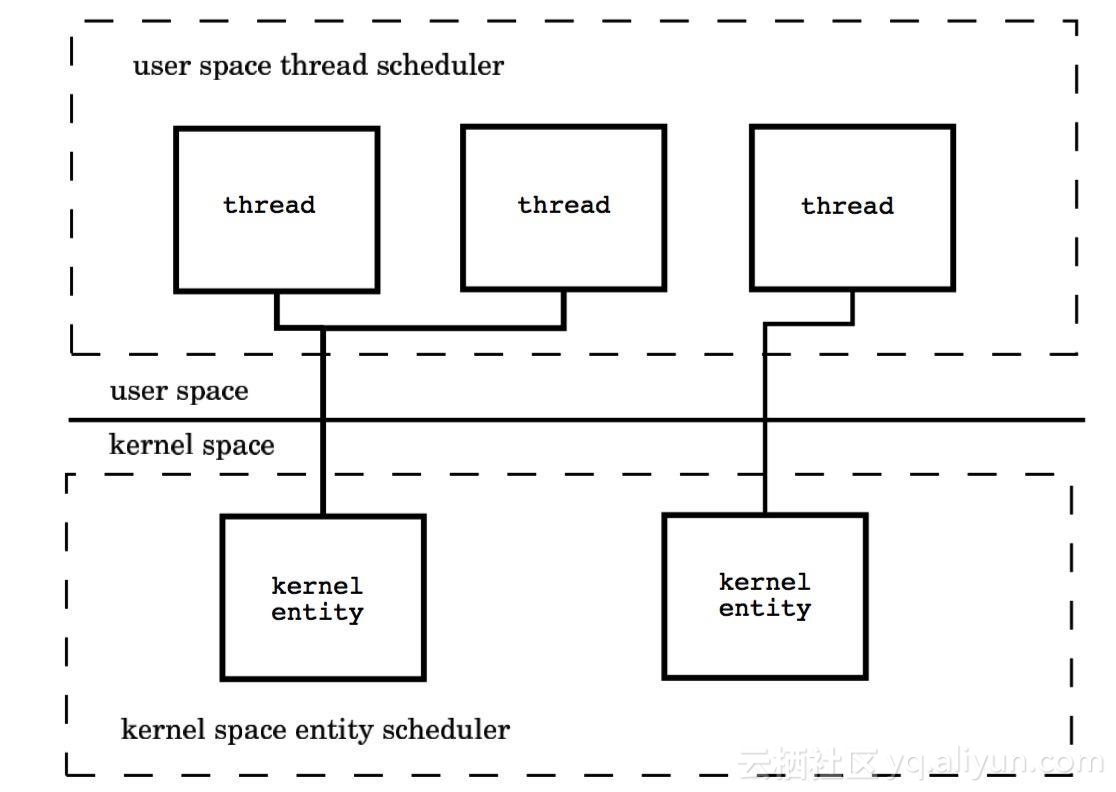
这种模型需要内核线程调度器和用户空间线程调度器相互操作,本质上是多个线程被绑定到了多个内核线程上,这使得大部分的线程上下文切换都发生在用户空间,而多个内核线程又可以充分利用处理器资源。
goroutine机制的调度实现
goroutine机制实现了M : N的线程模型,goroutine机制是协程(coroutine)的一种实现,golang内置的调度器,可以让多核CPU中每个CPU执行一个协程。
理解goroutine机制的原理,关键是理解Go语言scheduler的实现。
调度器是如何工作的
Go语言中支撑整个scheduler实现的主要有4个重要结构,分别是M、G、P、Sched,
前三个定义在runtime.h中,Sched定义在proc.c中。
- Sched结构就是调度器,它维护有存储M和G的队列以及调度器的一些状态信息等。
- M结构是Machine,系统线程,它由操作系统管理的,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息。
- P结构是Processor,处理器,它的主要用途就是用来执行goroutine的,它维护了一个goroutine队列,即runqueue。Processor是让我们从N:1调度到M:N调度的重要部分。
- G是goroutine实现的核心结构,它包含了栈,指令指针,以及其他对调度goroutine很重要的信息,例如其阻塞的channel。
Processor的数量是在启动时被设置为环境变量GOMAXPROCS的值,或者通过运行时调用函数GOMAXPROCS()进行设置。Processor数量固定意味着任意时刻只有GOMAXPROCS个线程在运行go代码。
参考这篇传播很广的博客:http://morsmachine.dk/go-scheduler
我们分别用三角形,矩形和圆形表示Machine Processor和Goroutine。
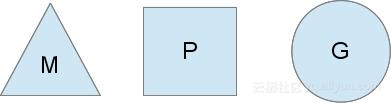
在单核处理器的场景下,所有goroutine运行在同一个M系统线程中,每一个M系统线程维护一个Processor,任何时刻,一个Processor中只有一个goroutine,其他goroutine在runqueue中等待。一个goroutine运行完自己的时间片后,让出上下文,回到runqueue中。
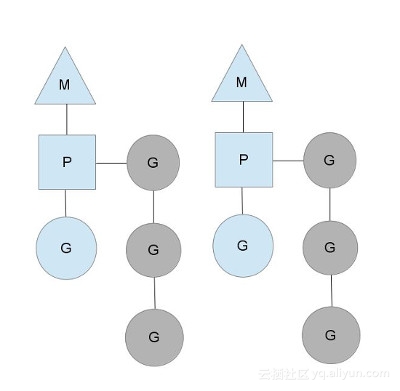
以上这个图讲的是两个线程(内核线程)的情况。一个M会对应一个内核线程,一个M也会连接一个上下文P,一个上下文P相当于一个“处理器”,一个上下文连接一个或者多个Goroutine。P(Processor)的数量是在启动时被设置为环境变量GOMAXPROCS的值,或者通过运行时调用函数runtime.GOMAXPROCS()进行设置。Processor数量固定意味着任意时刻只有固定数量的线程在运行go代码。Goroutine中就是我们要执行并发的代码。图中P正在执行的Goroutine为蓝色的;处于待执行状态的Goroutine为灰色的,灰色的Goroutine形成了一个队列runqueues
三者关系的宏观的图为:

抛弃P(Processor)
你可能会想,为什么一定需要一个上下文,我们能不能直接除去上下文,让Goroutine的runqueues挂到M上呢?答案是不行,需要上下文的目的,是让我们可以直接放开其他线程,当遇到内核线程阻塞的时候。
一个很简单的例子就是系统调用sysall,一个线程肯定不能同时执行代码和系统调用被阻塞,这个时候,此线程M需要放弃当前的上下文环境P,以便可以让其他的Goroutine被调度执行。
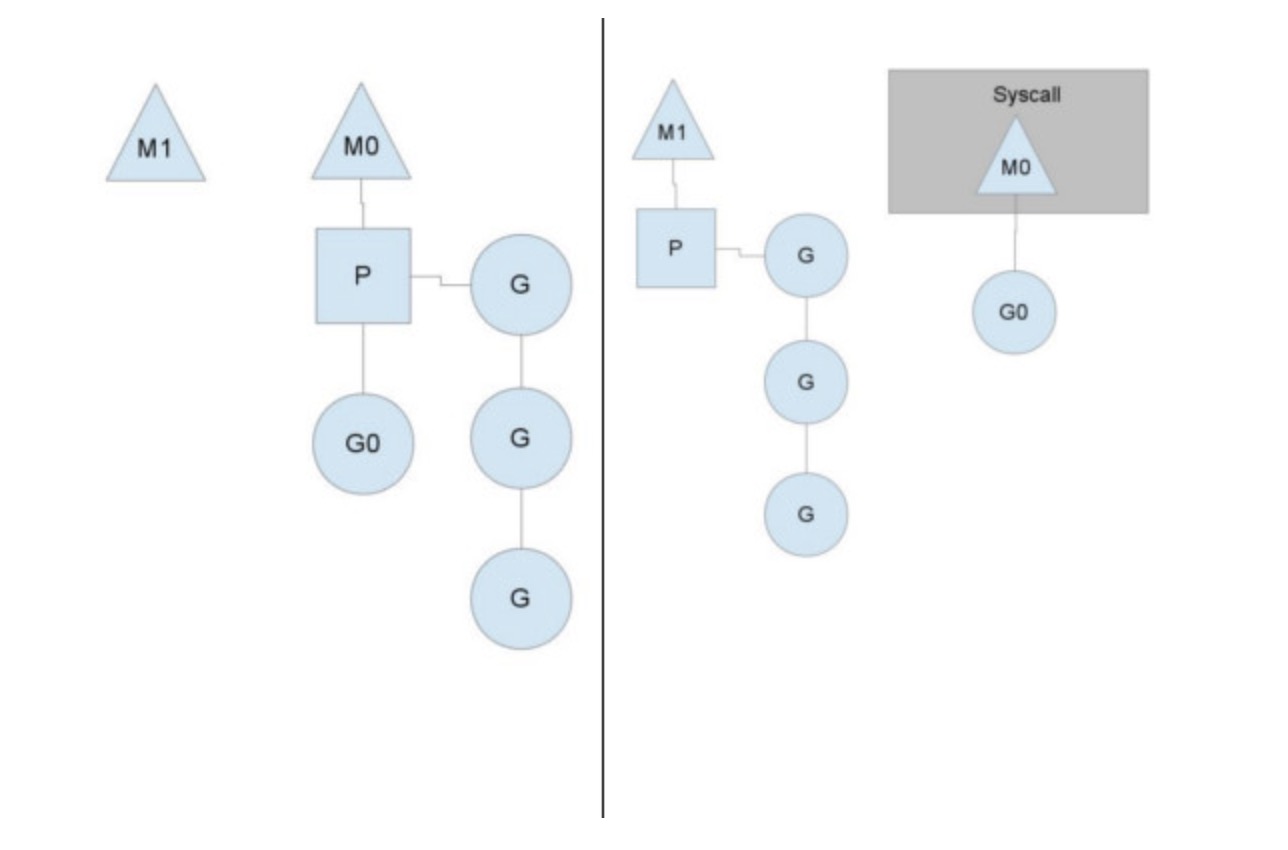
如上图左图所示,M0中的G0执行了syscall,然后就创建了一个M1(也有可能本身就存在,没创建),(转向右图)然后M0丢弃了P,等待syscall的返回值,M1接受了P,将·继续执行Goroutine队列中的其他Goroutine。
当系统调用syscall结束后,M0会“偷”一个上下文,如果不成功,M0就把它的Gouroutine G0放到一个全局的runqueue中,然后自己放到线程池或者转入休眠状态。全局runqueue是各个P在运行完自己的本地的Goroutine runqueue后用来拉取新goroutine的地方。P也会周期性的检查这个全局runqueue上的goroutine,否则,全局runqueue上的goroutines可能得不到执行而饿死。
均衡的分配工作
按照以上的说法,上下文P会定期的检查全局的goroutine 队列中的goroutine,以便自己在消费掉自身Goroutine队列的时候有事可做。假如全局goroutine队列中的goroutine也没了呢?就从其他运行的中的P的runqueue里偷。
每个P中的Goroutine不同导致他们运行的效率和时间也不同,在一个有很多P和M的环境中,不能让一个P跑完自身的Goroutine就没事可做了,因为或许其他的P有很长的goroutine队列要跑,得需要均衡。
该如何解决呢?
Go的做法倒也直接,从其他P中偷一半!

参考:
https://yq.aliyun.com/articles/72365
http://morsmachine.dk/go-scheduler
https://studygolang.com/articles/11825


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?