博客开发系列(二)之分类归类与日期归类的实现
博客开发系列(二)之分类归类与日期归类的实现
分类归类
实现功能
显示博客全部文章分类 显示该分类下有多少篇文章
实现效果

具体实现过程
转载:https://www.cnblogs.com/yanzi-meng/p/7779336.html


回顾一下我们的模型代码,Django 博客有一个 Post 和 Category 模型,分别表示文章和分类: blog/models.py class Post(models.Model): title = models.CharField(max_length=70) body = models.TextField() category = models.ForeignKey('Category') # 其它属性... def __str__(self): return self.title class Category(models.Model): name = models.CharField(max_length=100) 我们知道从数据库取数据都是使用模型管理器 objects 的方法实现的。比如获取全部分类是:Category.objects.all() ,假设有一个名为 test 的分类,那么获取该分类的方法是:Category.objects.get(name='test') 。objects 除了 all、get 等方法外,还有很多操作数据库的方法,而其中有一个 annotate 方法,该方法正可以帮我们实现本文所关注的统计分类下的文章数量的功能。 数据库数据聚合 annotate 方法在底层调用了数据库的数据聚合函数,下面使用一个实际的数据库表来帮助我们理解 annotate 方法的工作原理。在 Post 模型中我们通过 ForeignKey 把 Post 和 Category 关联了起来,这时候它们的数据库表结构就像下面这样: Post 表: id title body category_id 1 post 1 ... 1 2 post 2 ... 1 3 post 3 ... 1 4 post 4 ... 2 Category 表: name id category 1 1 category 2 2 这里前 3 篇文章属于 category 1,第 4 篇文章属于 category 2。 当 Django 要查询某篇 post 对应的分类时,比如 post 1,首先查询到它分类的 id 为 1,然后 Django 再去 Category 表找到 id 为 1 的那一行,这一行就是 post 1 对应的分类。反过来,如果要查询 category 1 对应的全部文章呢?category 1 在 Category 表中对应的 id 是 1,Django 就在 Post 表中搜索哪些行的 category_id 为 1,发现前 3 行都是,把这些行取出来就是 category 1 下的全部文章了。同理,这里 annotate 做的事情就是把全部 Category 取出来,然后去 Post 查询每一个 Category 对应的文章,查询完成后只需算一下每个 category id 对应有多少行记录,这样就可以统计出每个 Category 下有多少篇文章了。把这个统计数字保存到每一条 Category 的记录就可以了(当然并非保存到数据库,在 Django ORM 中是保存到 Category 的实例的属性中,每个实例对应一条记录)。 使用 Annotate 以上是原理方面的分析,具体到 Django 中该如何用呢?在我们的博客中,获取侧边栏的分类列表的方法写在模板标签 get_categories 里,因此我们修改一下这个函数,具体代码如下: blog/templatetags/blog_tags.py from django.db.models.aggregates import Count from blog.models import Category @register.simple_tag def get_categories(): # 记得在顶部引入 count 函数 # Count 计算分类下的文章数,其接受的参数为需要计数的模型的名称 return Category.objects.annotate(num_posts=Count('post')).filter(num_posts__gt=0) 这个 Category.objects.annotate 方法和 Category.objects.all 有点类似,它会返回数据库中全部 Category 的记录,但同时它还会做一些额外的事情,在这里我们希望它做的额外事情就是去统计返回的 Category 记录的集合中每条记录下的文章数。代码中的 Count 方法为我们做了这个事,它接收一个和 Categoty 相关联的模型参数名(这里是 Post,通过 ForeignKey 关联的),然后它便会统计 Category 记录的集合中每条记录下的与之关联的 Post 记录的行数,也就是文章数,最后把这个值保存到 num_posts 属性中。 此外,我们还对结果集做了一个过滤,使用 filter 方法把 num_posts 的值小于 1 的分类过滤掉。因为 num_posts 的值小于 1 表示该分类下没有文章,没有文章的分类我们不希望它在页面中显示。关于 filter 函数以及查询表达式(双下划线)在之前已经讲过,具体请参考 分类与归档。 在模板中引用新增的属性 现在在 Category 列表中每一项都新增了一个 num_posts 属性记录该 Category 下的文章数量,我们就可以在模板中引用这个属性来显示分类下的文章数量了。 templates/base.html <ul> {% for category in category_list %} <li> <a href="{% url 'blog:category' category.pk %}">{{ category.name }} <span class="post-count">({{ category.num_posts }})</span> </a> </li> {% empty %} 暂无分类! {% endfor %} </ul> 也就是在模板中通过模板变量 {{ category.num_posts }} 显示 num_posts 的值。开启开发服务器,可以看到分类名后正确地显示了该分类下的文章数了,而没有文章分类则不会在分类列表中出现。 将 Annotate 用于其它关联关系 此外,annotate 方法不局限于用于本文提到的统计分类下的文章数,你也可以举一反三,只要是两个 model 类通过 ForeignKey 或者 ManyToMany 关联起来,那么就可以使用 annotate 方法来统计数量。比如下面这样一个标签系统: class Post(models.Model): title = models.CharField(max_length=70) body = models.TextField() Tags = models.ManyToMany('Tag') def __str__(self): return self.title class Tag(models.Model): name = models.CharField(max_length=100) 统计标签下的文章数: from django.db.models.aggregates import Count from blog.models import Tag # Count 计算分类下的文章数,其接受的参数为需要计数的模型的名称 tag_list = Tag.objects.annotate(num_posts=Count('post'))
日期归类
实现功能
显示具体到每年每月的分类列表 点击不同的日期分类,在页面显示同一个月份的文章
datetime.datetime和datetime.date模块
datetime模块 In [1]: from datetime import datetime In [2]: datetime.now() Out[2]: datetime.datetime(2018, 11, 19, 9, 30, 34, 795738) In [3]: print(datetime.now()) 2018-11-19 09:30:40.604522
date模块 In [1]: import datetime In [5]: print(datetime.date(2018,11,11)) 2018-11-11
设计表
class BlogType(models.Model): type_name=models.CharField(max_length=15,verbose_name="博客类型") def __str__(self): return self.type_name class Blog(models.Model): #博客标题 title=models.CharField(max_length=50,verbose_name="文章标题") #博客类型 blog_type=models.ForeignKey(BlogType,on_delete=models.DO_NOTHING,verbose_name="博客类型") #博客作者 author=models.ForeignKey(User,on_delete=models.DO_NOTHING,verbose_name="作者") #博客内容 content=models.TextField() #创建文章的时间 created_time=models.DateTimeField(auto_now_add=True,verbose_name="发表时间") #最后修改的时间 last_updated_time=models.DateTimeField(auto_now=True,verbose_name="最后修改时间") #日期 date = models.DateField(auto_now_add=True,verbose_name="日期") def __str__(self): return self.title
后台展示

匹配:这里的日期是从前端传过来的,下面的匹配对应这个字段类型
date = models.DateField(auto_now_add=True,verbose_name="日期")
# 匹配日期,date
User.objects.filter(date__date=datetime.date(2018, 8, 1))
User.objects.filter(date__date__gt=datetime.date(2018, 8, 2))
# 匹配年,year
User.objects.filter(date__year=2018)
User.objects.filter(date__year__gte=2018)
# 匹配月,month
User.objects.filter(date__month__gt=7)
User.objects.filter(date_time__month__gte=7)
# 匹配日,day
User.objects.filter(date__day=8)
User.objects.filter(date__day__gte=8)
# 匹配周,week_day
User.objects.filter(date__week_day=2)
User.objects.filter(date__week_day__gte=2)
# 匹配时,hour
User.objects.filter(date__hour=9)
User.objects.filter(date__hour__gte=9)
# 匹配分,minute
User.objects.filter(date__minute=15)
User.objects.filter(date__minute_gt=15)
# 匹配秒,second
User.objects.filter(date__second=15)
User.objects.filter(date__second__gte=15)
# 按天统计归档
today = datetime.date.today()
select = {'day': connection.ops.date_trunc_sql('day', 'date')}
deploy_date_count = Task.objects.filter(
create_time__range=(today - datetime.timedelta(days=7), today)
).extra(select=select).values('day').annotate(number=Count('id'))
models.DateTimeField的过滤
models.DateTimeField的过滤
auto_now_add 自动添加,以添加记录时日期
auto_add 每次更新记录,自动更新
库里我想存储models.DateTimeField类型, 不想存储models.DateField类型, 因为time还需要展示的
People.objects.filter(add_time__lt = datetime.datetime(2018,11,19))
日期归档具体实现
#日期归档
dates = Blog.objects.dates('created_time', 'month', order="DESC")
将dates参数传到前端
我们这里不使用键值对的方式发生数据,而通过正则匹配
{% for blog_date in dates %} <!--通过?参数名字=value&参数名字=value 来传递多个参数。django后台不需要进行参数的添加的,只需要通过request.GET.get(‘参数名字’)来获取传递的参数。--> <li><a href="/blog_date/{{ blog_date|date:'Y' }}/{{ blog_date|date:'m'}}&nid=1"> {{blog_date|date:"Y-m" }}</a></li> {% endfor %}
url匹配
re_path('(?P<archiveYear>[\d]{4})/(?P<archiveMonth>[\d]{2})',views.get_blog_date)
将archiveYear与archiveMonth传到后端,放到def get_blog_date(request,archiveYear,archiveMonth),匹配数据
article_list =Blog.objects.all().filter(date__year=archiveYear).filter(date__month=archiveMonth)
具体视图函数
ef get_blog_date(request,archiveYear,archiveMonth):
# 获取当前页码
nid = request.GET.get('nid')
# 2019-03-01 匹配日期
article_list =Blog.objects.all().filter(date__year=archiveYear).filter(date__month=archiveMonth)
category = get_tags()
# 获取总博文总数量
count = len(article_list)
# 初始化页面处理的对象,有两个参数在初始化函数里,设置了默认数值 ,这里把年份和月份传入到分页中
page_obj = cut_page2.PageInfo(count, nid,archiveYear,archiveMonth)
data_list = article_list[page_obj.start():page_obj.end()]
# 日期归档
dates = Blog.objects.dates('created_time', 'month', order="DESC")
return render(request, "blog.html",
{'article_list': article_list, "page_obj": page_obj, 'data_list': data_list, 'dates': dates,
'category': category})
# 参数: #数据总个数 #当前页 #每页显示多少条数据 #最多每页多个页号 class PageInfo(object): def __init__(self,totalCount,current,year,month,totalItem=5,peritems=10,): #数据总个数 self._count=totalCount #当前页 try: v=int(current) if v<=0: v=1 self.__current=v except Exception as e: self.__current = 1 #每页显示的行数 self.__totalItem=totalItem #最多显示页面 self.__peritems = peritems self.year=year self.month=month #设置一页数据的开始和结束 #数据开始的页数 def start(self): return (self.__current-1)*self.__totalItem #数据结束的页数 def end(self): return self.__current*self.__totalItem #求出总页数 @property def num_pages(self): a,b=divmod(self._count,self.__totalItem) # print(a,b) if b==0: return a return a+1 #生成所有的页号 def page_num_range(self): # 当前页面 # self.current_page # 总页数 # self.num_pages # 最多显示的页码个数 # self.max_pager_num if self.num_pages < self.__peritems: return range(1, self.num_pages + 1) part = int( self.__peritems/ 2) if self.__current - part < 1: return range(1, self.__peritems + 1) if self.__current + part > self.num_pages: return range(self.num_pages + 1 - self.__peritems, self.num_pages + 1) return range(self.__current - part, self.__current + part + 1) #所有的a标签 def page_str(self): #用来存放所有页号a标签 page_list=[] # "/blog_date/{{ blog_date|date:'Y' }}/{{ blog_date|date:'m'}}&nid=1" #首页 head_page="<li><a href='/blog_date/%s/%s&nid=1'>首页</a></li>"%(self.year,self.month) page_list.append(head_page) #上一页 print(self.__current) if self.__current ==1: prev="<li><a href='#'><<</a></li>" else: prev="<li><a href='/blog_date/%s/%s&nid=%s'><<</a></li>"%(self.year,self.month,self.__current-1) page_list.append(prev) for i in self.page_num_range(): if i==self.__current: temp="<li><a style='font-size:30px;' href='/blog_date/%s/%s&nid=%s'>%s</a></li>"%(self.year,self.month,i,i) else: temp="<li><a href='/blog_date/%s/%s&nid=%s'>%s</a></li>"%(self.year,self.month,i,i) page_list.append(temp) #下一页 if self.__current==self.num_pages: next = "<li><a href='#'>>></a></li>" else: next = "<li><a href='/blog_date/%s/%s&nid=%s'>>></a></li>" % (self.year,self.month,self.__current + 1) page_list.append(next) # 尾页 b_page="<li><a href='/blog_date/%s/%s&nid=%s'>尾页</a></li>"%(self.year,self.month,self.num_pages) page_list.append(b_page) return ''.join(page_list)
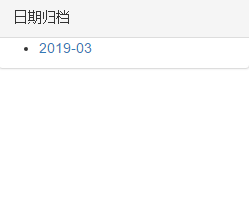
具体实现效果
参考:http://www.cnblogs.com/iiiiiher/p/9981817.html
参考:https://www.jianshu.com/p/1c258d8d542a
参考:https://www.django.cn/article/show-15.html?tdsourcetag=s_pcqq_aiomsg
参考:https://www.jianshu.com/p/3f846ecbd945

 浙公网安备 33010602011771号
浙公网安备 33010602011771号