Python爬虫之反爬虫(随机user-agent,获取代理ip,检测代理ip可用性)
python爬虫之反爬虫(随机user-agent,获取代理ip,检测代理ip可用性)
目录
随机User-Agent 获取代理ip 检测代理ip可用性
随机User-Agent
fake_useragent库,伪装请求头
from fake_useragent import UserAgent ua = UserAgent() # ie浏览器的user agent print(ua.ie) # opera浏览器 print(ua.opera) # chrome浏览器 print(ua.chrome) # firefox浏览器 print(ua.firefox) # safri浏览器 print(ua.safari) # 最常用的方式 # 写爬虫最实用的是可以随意变换headers,一定要有随机性。支持随机生成请求头 print(ua.random) print(ua.random) print(ua.random)
获取代理ip
在免费的代理网站爬取代理ip,免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
代理ip网站 有代理:https://www.youdaili.net/Daili/guonei/ 66代理:http://www.66ip.cn/6.html 西刺代理:https://www.xicidaili.com/ 快代理:https://www.kuaidaili.com/free/
#根据网页结果,适用正则表达式匹配 #这种方法适合翻页的网页
import re
import requests
import time
def get_ip():
url='https://www.kuaidaili.com/free/inha/'
url_list=[url+str(i+1) for i in range(5)] #生成url列表,5代表只爬取5页
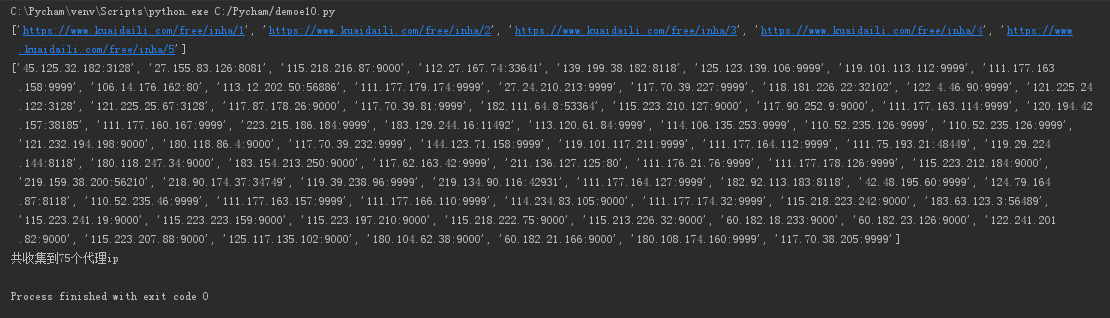
print(url_list)
ip_list = []
for i in range(len(url_list)):
url =url_list[i]
html = requests.get(url=url,).text
regip = '<td.*?>(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})</td>.*?<td.*?>(\d{1,5})</td>'
matcher = re.compile(regip,re.S)
ipstr = re.findall(matcher, html)
time.sleep(1)
for j in ipstr:
ip_list.append(j[0]+':'+j[1]) #ip+port
print(ip_list)
print('共收集到%d个代理ip' % len(ip_list))
return ip_list
if __name__=='__main__':
get_ip()
#先获取特定标签 #解析
import requests
from bs4 import BeautifulSoup
def get_ip_list(obj):
ip_text = obj.findAll('tr', {'class': 'odd'}) # 获取带有IP地址的表格的所有行
ip_list = []
for i in range(len(ip_text)):
ip_tag = ip_text[i].findAll('td')
ip_port = ip_tag[1].get_text() + ':' + ip_tag[2].get_text() # 提取出IP地址和端口号
ip_list.append(ip_port)
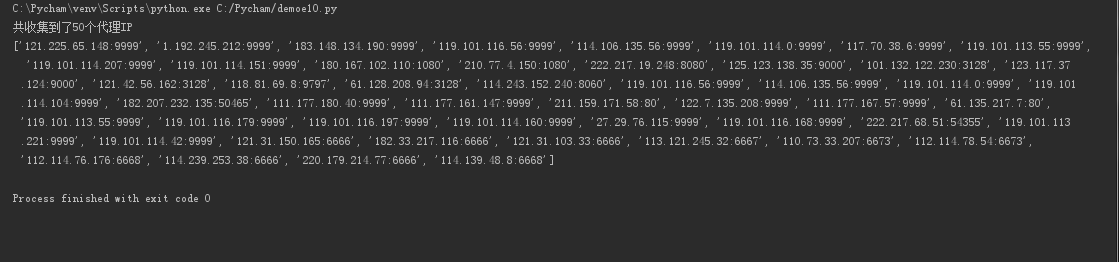
print("共收集到了{}个代理IP".format(len(ip_list)))
print(ip_list)
return ip_list
url = 'http://www.xicidaili.com/'
headers = {
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
request = requests.get(url, headers=headers)
response =request.text
bsObj = BeautifulSoup(response, 'lxml') # 解析获取到的html
lists=get_ip_list(bsObj)
检测代理ip可用性
第一种方法:通过返回的状态码判断
import requests
import random
import re
import time
def get_ip():
url='https://www.kuaidaili.com/free/inha/'
url_list=[url+str(i+1) for i in range(1)]
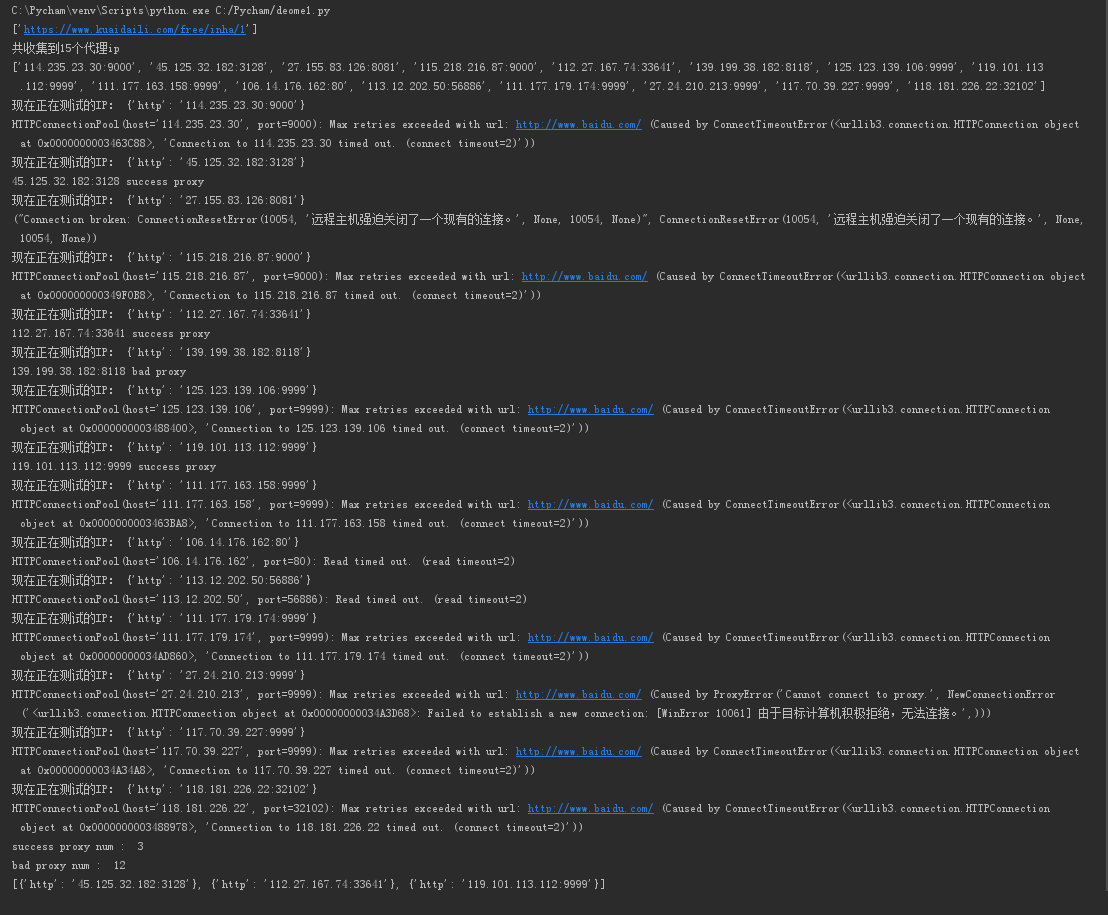
print(url_list)
ip_list = []
for i in range(len(url_list)):
url =url_list[i]
html = requests.get(url=url,).text
regip = '<td.*?>(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})</td>.*?<td.*?>(\d{1,5})</td>'
matcher = re.compile(regip,re.S)
ipstr = re.findall(matcher, html)
time.sleep(1)
for j in ipstr:
ip_list.append(j[0]+':'+j[1])
print('共收集到%d个代理ip' % len(ip_list))
print(ip_list)
return ip_list
def valVer(proxys):
badNum = 0
goodNum = 0
good=[]
for proxy in proxys:
try:
proxy_host = proxy
protocol = 'https' if 'https' in proxy_host else 'http'
proxies = {protocol: proxy_host}
print('现在正在测试的IP:',proxies)
response = requests.get('http://www.baidu.com', proxies=proxies, timeout=2)
if response.status_code != 200:
badNum += 1
print (proxy_host, 'bad proxy')
else:
goodNum += 1
good.append(proxies)
print (proxy_host, 'success proxy')
except Exception as e:
print( e)
# print proxy_host, 'bad proxy'
badNum += 1
continue
print ('success proxy num : ', goodNum)
print( 'bad proxy num : ', badNum)
print(good)
if __name__ == '__main__':
ip_list=get_ip()
valVer(ip_list)
第二种方法:使用requests包来进行验证
import requests
import random
import re
import time
def get_ip():
url='https://www.kuaidaili.com/free/inha/'
url_list=[url+str(i+1) for i in range(1)]
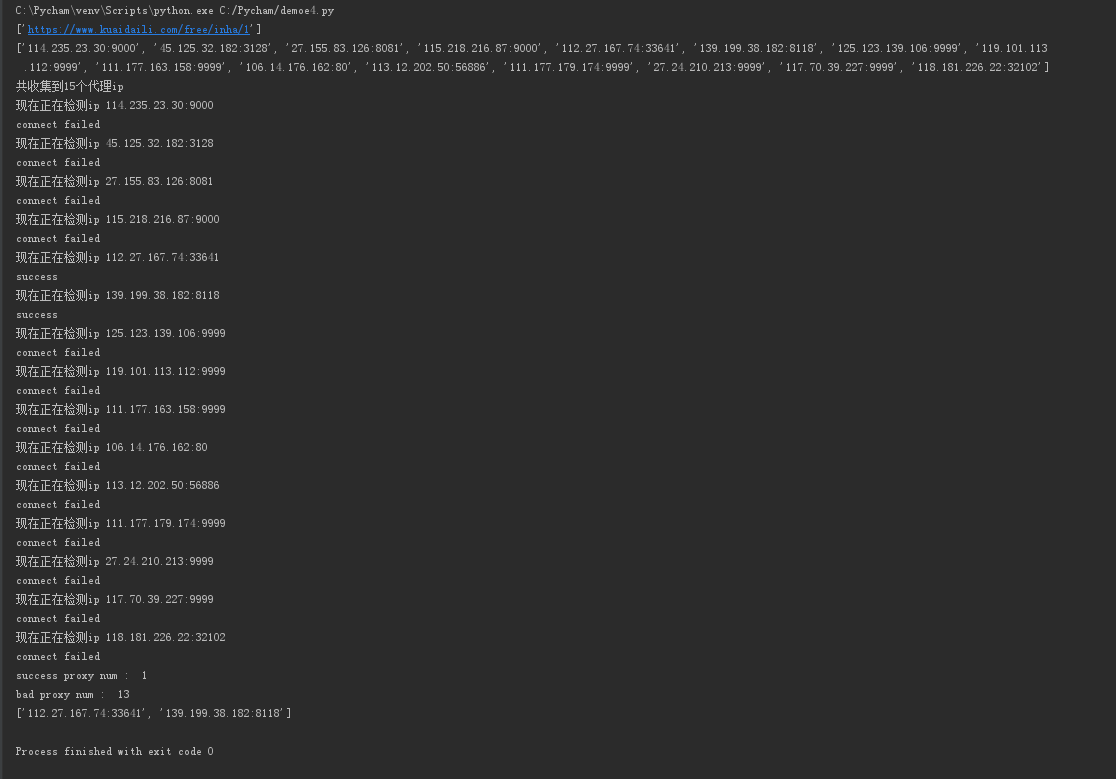
print(url_list)
ip_list = []
for i in range(len(url_list)):
url =url_list[i]
html = requests.get(url=url,).text
regip = '<td.*?>(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})</td>.*?<td.*?>(\d{1,5})</td>'
matcher = re.compile(regip,re.S)
ipstr = re.findall(matcher, html)
time.sleep(1)
for j in ipstr:
ip_list.append(j[0]+':'+j[1])
print(ip_list)
print('共收集到%d个代理ip' % len(ip_list))
return ip_list
def valVer(proxys):
badNum = 0
goodNum = 0
good=[]
for proxy in proxys:
print("现在正在检测ip",proxy)
try:
requests.get('http://wenshu.court.gov.cn/', proxies={"http":"http://"+str(proxy)}, timeout=2)
except:
badNum+=1
print('connect failed')
else:
goodNum=1
good.append(proxy)
print('success')
print ('success proxy num : ', goodNum)
print( 'bad proxy num : ', badNum)
print(good)
if __name__ == '__main__':
ip_list=get_ip()
valVer(ip_list)
第三种方法:使用telnet
import telnetlib
try:
telnetlib.Telnet('127.0.0.1', port='80', timeout=20)
except:
print 'connect failed'
else:
print 'success'
