python爬虫之下载文件的方式总结以及程序实例
python爬虫之下载文件的方式以及下载实例
目录
第一种方法:urlretrieve方法下载
第二种方法:request download
第三种方法:视频文件、大型文件下载
实战演示
第一种方法:urlretrieve方法下载
程序示例:
import os
from urllib.request import urlretrieve
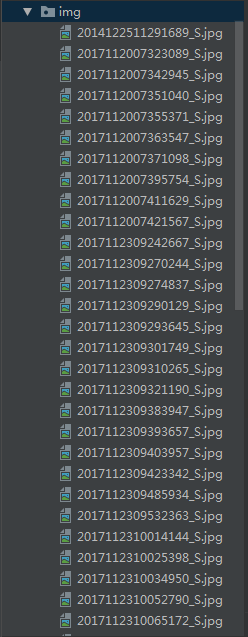
os.makedirs('./img/',exist_ok=True) #创建目录存放文件
image_url = "https://p0.ssl.qhimg.com/t01e890e06c93018fa8.jpg"
urlretrieve(image_url,'./img1/image1.png') #将什么文件存放到什么位置
补充知识:
os.makedirs() 方法用于递归创建目录。像 mkdir(), 但创建的所有intermediate-level文件夹需要包含子目录。 语法 makedirs()方法语法格式如下: os.makedirs(path, mode=0o777) 参数 path -- 需要递归创建的目录。 mode -- 权限模式。 返回值 该方法没有返回值。
第二种方法:request download
程序示例:
import requests
image_url='https://p0.ssl.qhimg.com/t01e890e06c93018fa8.jpg'
r = requests.get(image_url)
with open('./img1/image1.png','wb') as f:
f.write(r.content)
补充知识:
with open的使用格式
with open(’文件名‘,‘读写方式’)as f:
f.read() #读取是整个文件
f.readline() #读取第一行
f.readlines() #读取每一行,可以结合for使用(参考我上述完整代码),记得都要带方法都要带括号,不然返回的是内存地址
f.close() #关闭文件 文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的
f.write() #写入文件
第三种方法:视频文件、大型文件下载
可以设置每次存储文件的大小,所以可以下载大型文件,当然也可以下载小文件。
程序示例:
import requests
image_url = 'https://p0.ssl.qhimg.com/t01e890e06c93018fa8.jpg'
r = requests.get(image_url,stream=True) #stream=True #开启时时续续的下载的方式
with open(filename, 'wb') as f: for chunk in r,iter_content(chunk_size=32): #chunk_size #设置每次下载文件的大小
f.write(chunk) #每一次循环存储一次下载下来的内容
实战演示
下面一个简单的使用爬虫下载图片的程序
爬取的是一个旅游网站的地图
程序示例:
import requests
import os
from bs4 import BeautifulSoup
from urllib.request import urlretrieve
def main():
url = 'http://www.onegreen.net/maps/List/List_933.html'
os.makedirs('./img/',exist_ok=True) #创建目录存放文件
html = requests.get(url).text #获取网页html
soup = BeautifulSoup(html,'lxml')
img_url = soup.find_all('img') #获取所有的img标签,我在这里只是演示下载,所有不做进一步的筛选
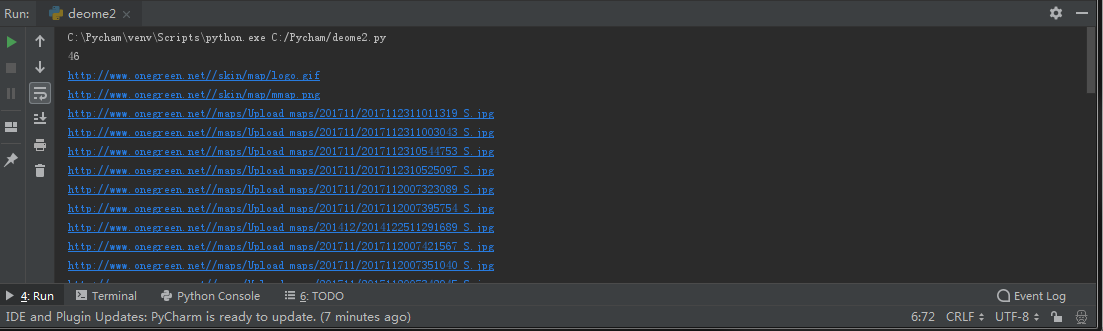
print(len(img_url))
for url in img_url:
ul = url['src'] #获取src属性
img = 'http://www.onegreen.net/' + ul #补全图片url
print(img)
urlretrieve(img , './img/%s' % ul.split('/')[-1]) #存储图片
if __name__ =='__main__':
main()
程序运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号