Linux学习之文本处理命令(五)
---恢复内容开始---
Linux 系统之文本处理命令
(一)基于关键字搜索
(二)基于列处理文本
(三)文本统计
(四)文本排序
(五)删除重复行
(六)文本比较
(七)处理文本内容
(八)搜索替换
(一)基于关键字搜索
grep命令
用以基于关键字搜索文本
语法
grep [OPTIONS] [关键字] [FILE]
OTPIONS
-i 在搜索的时候忽略大小写 -n 显示结果所在行数 -v 输出不带关键字的行 -Ax 在输出的时候包含结果所在行之后的指定行数
-Bx 在输出的时候包含结果所在行之前的指定行数
应用举例
在 /root/test/test1文件中搜索含有read关键字的内容并输出
grep "read" /root/test/test1
下面这条命令也可以完成上条命令的功能(这里关键字不加双引号也行)
cat /root/test/test1 | grep "read"
在根目录下查找用户为hadoop的文件,只输出含有haige关键字的内容
find / -user hadoop | grep haige

(二)基于列处理文本
cut命令
用以基于列处理文本内容
语法
cut [OPTIONS] [FILE]
OPTIONS
-d 指定字段的分隔符,默认的字段分隔符为“TAB”
-b 按字节切割,仅显示行中指定直接范围的内容
-c 按字符切割,仅显示行中指定范围的字符
-f 显示指定字段的内容(对-c与 -b参数同样适用指定)
#:第#字段
#,#[,#]:离散的多个字段,例如1,3,6
混合使用:1-3,7
#- :从#开始字段、字节、字节之后的所有字段
-# :从开始到#字符、字段、字节
-n 与“-b” 选项连用,不分割多字节字符
-complement 选项提取指定字段之外的列
--out-delimiter=<字段分隔符> 指定输出内容是的字段分割符
--version 显示指令的版本信息
应用举例
test文件
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
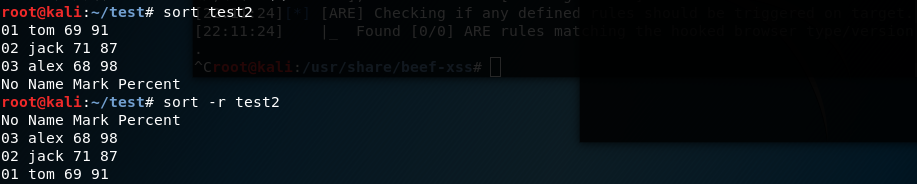
输出test2文件每一行的前三个字符
cut -c1-3 test2
输出test2文件每一行的前五个字符
cut -c-5 test2
输出test2文件每一行的前五个字节
cut -b1-5 test2
(三)文本统计
wc命令
收集文本统计数据。
计数单词总数,行总数,字节总数和字符总数
语法
wc [OPTIONS] [FILE]
OPTIONS
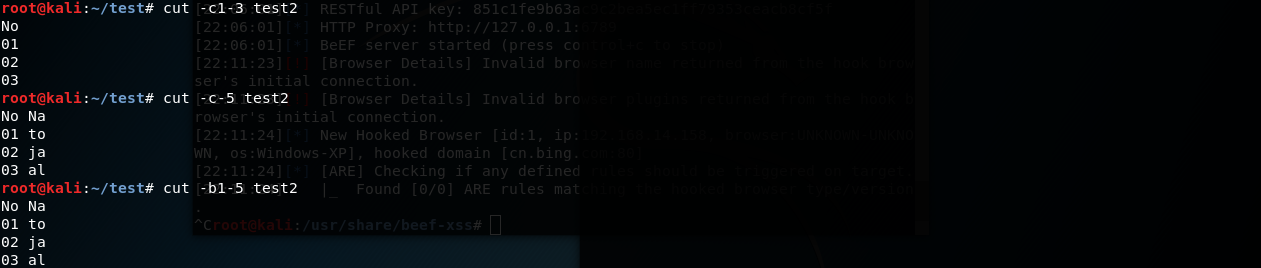
-l 只计数行数 -w 只计数单词总数 -c 只计数字节总数 -m 只计数字符总数 -L 显示文件中最长行的长度
应用举例
wc -l test2
wc -w test2
wc -c test2
wc -m test2
wc -L test2
(四)文本排序
sort命令
把整理过的文本显示在STDOUT,不改变原始文件
语法
sort [OPTIONS] files
OPTIONS
-r : 执行反方向(由上至下)整理 -n : 执行按数字大小整理 -f : 选项忽略(FOLD)字符串中的字符大小写 -u : 选项(独特,unique)删除输出中的重复行 -t c : 选项使用c作为字段界定符 -k x : 选项按照使用c字符分隔X列来整理能够使用 -c : 检查文件是否已经按照顺序排序
应用举例
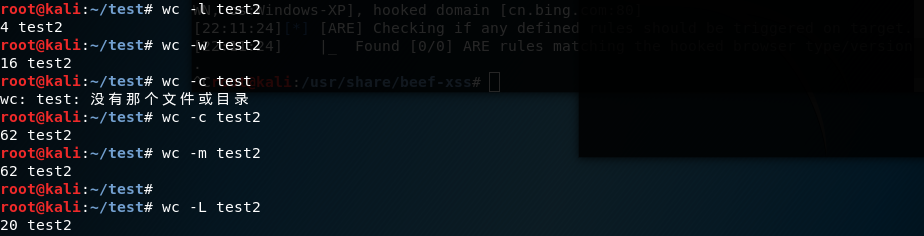
按字母顺序排序
sort test2
按字母顺序的反方向排序
sort -r test2
(五)删除重复行
uniq命令
用于检查及删除文本文件中重复出现的行列
语法
uniq [OPTION] [FILE]
OPTIONS
-c:显示每行重复出现的次数 -d:仅显示重复过的行 -u:仅显示不曾重复的行
常和sort 命令一起配合使用:
sort userlist.txt | uniq -c
应用举例
两种删除重复行的方法: 1.命令 sort -u 可以用以删除重复行 2.命令uniq 用以删除重复的相邻行
(六)文本比较
diff命令
用以比较两个文件的区别
语法
diff [OPTIONS] [FILE] [FILE]
OPTIONS
-<行数> 指定要显示多少行的文本。此参数必须与-c或-u参数一并使用
-b 忽略空格造成的不同 -B 忽略空行造成的不同 -r 比较子目录中的文件 -u 以合并的方式来显示文件内容的不同。多用于补丁 -y 可以将屏幕分成左右两部分,来比较两个文件之间的差异。 -a diff预设只会逐行比较文本文件; -c 显示全部内容,并标出不同之处; -n或–rcs 将比较结果以RCS的格式来显示 -N或–new-file 在比较目录时,若文件A仅出现在某个目录中,预设会显示:Only in目录,文件A 若使用-N参数,则diff会将文件A 与一个空白的文件比较; -p 若比较的文件为C语言的程序码文件时,显示差异所在的函数名称-q或–brief 仅显示有无差异,不显示详细的信息
-q或–brief 仅显示有无差异,不显示详细的信息; -x<文件名或目录>或–exclude<文件名或目录> 不比较选项中所指定的文件或目录; -X<文件>或–exclude-from<文件> 您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件; -e 将比较的结果保存成一个ed脚本,之后ed程序可以执行该脚本文件,从而将file1修改成与file2的内容相同,这一般在patch的时候有用
应用举例
diff test1 test2
diff -y test1 test2

(七)处理文本内容
tr命令
用以处理文本内容,可以非常容易地实现 sed 的许多最基本功能。您可以将 tr 看作为 sed 的(极其)简化的变体:它可以用一个字符来替换另一个字符,或者可以完全除去一些字符。您也可以用它来除去重复字符
语法
tr [OPTIONS] ["string1_to_translate_from"] ["string2_to_translate_to"] < input_file
OPTIONS
-c 用字符串1中字符集的补集替换此字符集,要求字符集为ASCII。 -d 删除字符串1中所有输入字符。 -s 删除所有重复出现字符序列,只保留第一个;即将重复出现字符串压缩为一个字符串。 input-file是转换文件名。虽然可以使用其他格式输入,但这种格式最常用
字符范围
指定字符串1或字符串2的内容时,只能使用单字符或字符串范围或列表。 [a-z] a-z内的字符组成的字符串。 [A-Z] A-Z内的字符组成的字符串。 [0-9] 数字串。 \octal 一个三位的八进制数,对应有效的ASCII字符。 [O*n] 表示字符O重复出现指定次数n。因此[O*2]匹配OO的字符串。 tr中特定控制字符的不同表达方式 速记符含义八进制方式 \a Ctrl-G 铃声\007 \b Ctrl-H 退格符\010 \f Ctrl-L 走行换页\014 \n Ctrl-J 新行\012 \r Ctrl-M 回车\015 \t Ctrl-I tab键\011 \v Ctrl-X \030
应用举例
1.删除
删除指定字符
tr -d 'TMD' < file
或者
cat file | tr -d 'TMD' >new_file
删除文件file中出现的换行'\n'、制表'\t'字符
cat file | tr -d "\n\t" > new_file
删除“连续着的”重复字母,只保留第一个
cat file | tr -s [a-zA-Z] > new_file
删除空行
cat file | tr -s "\n" > new_file
删除Windows文件“造成”的'^M'字符
# cat file | tr -d "\r" > new_file
或者
# cat file | tr -s "\r" "\n" > new_file
【注意】这里-s后面是两个参数"\r"和"\n",用后者替换前者
2.替换
(小写 --> 大写)
cat file | tr [a-z] [A-Z] > new_file
(大写 --> 小写)
cat file | tr [A-Z] [a-z] > new_file
(数字 --> 小写)
cat file | tr [0-9] [a-j] > new_file
用空格符\040替换制表符\011
cat file | tr -s "\011" "\040" > new_file
把路径变量中的冒号":",替换成换行符"\n"
echo $PATH | tr -s ":" "\n"
(八)搜索替换
sed命令
用以搜索并替换文本,sed是非交互式的编辑器。它不会修改文件,除非使用shell重定向来保存结果。默认情况下,所有的输出行都被打印到屏幕上。
命令与选项
sed命令告诉sed如何处理由地址指定的各输入行,如果没有指定地址则处理所有的输入行。
选项
-e 进行多项编辑,即对输入行应用多条sed命令时使用 -n 取消默认的输出 -f 指定sed脚本的文件名
sed命令
a\ 在当前行后添加一行或多行。多行时除最后一行外,每行末尾需用“\”续行
c\ 用此符号后的新文本替换当前行中的文本。多行时除最后一行外,每行末尾需用"\"续行
i\ 在当前行之前插入文本。多行时除最后一行外,每行末尾需用"\"续行
d 删除行
h 把模式空间里的内容复制到暂存缓冲区
H 把模式空间里的内容追加到暂存缓冲区
g 把暂存缓冲区里的内容复制到模式空间,覆盖原有的内容
G 把暂存缓冲区的内容追加到模式空间里,追加在原有内容的后面
l 列出非打印字符
p 打印行
n 读入下一输入行,并从下一条命令而不是第一条命令开始对其的处理
q 结束或退出sed
r 从文件中读取输入行
! 对所选行以外的所有行应用命令
s 用一个字符串替换另一个
g 在行内进行全局替换
w 将所选的行写入文件
x 交换暂存缓冲区与模式空间的内容
y 将字符替换为另一字符(不能对正则表达式使用y命令)
正则表达式元字符
注意:与grep一样,sed也支持特殊元字符,来进行模式查找、替换。不同的是,sed使用的正则表达式是括在斜杠线"/"之间的模式
^ 行首定位符 /^my/ 匹配所有以my开头的行
$ 行尾定位符 /my$/ 匹配所有以my结尾的行
. 匹配除换行符以外的单个字符 /m..y/ 匹配包含字母m,后跟两个任意字符,再跟字母y的行
* 匹配零个或多个前导字符 /my*/ 匹配包含字母m,后跟零个或多个y字母的行
[] 匹配指定字符组内的任一字符 /[Mm]y/ 匹配包含My或my的行
[^] 匹配不在指定字符组内的任一字符 /[^Mm]y/ 匹配包含y,但y之前的那个字符不是M或m的行
\(..\) 保存已匹配的字符1,20s/\(you\)self/\1r/ 标记元字符之间的模式,并将其保存为标签1,之后可以使用\1来引用它。最多可以定义9个标签,从左边开始编
号,最左边的是第一个。此例中,对第1到第20行进行处理,you被保存为标签1,如果发现youself,则替换为your。
& 保存查找串以便在替换串中引用 s/my/**&**/ 符号&代表查找串。my将被替换为**my**
\< 词首定位符 /\<my/ 匹配包含以my开头的单词的行
\> 词尾定位符 /my\>/ 匹配包含以my开头的单词的行
x\{m\} 连续m个x /9\{5\}/ 匹配包含连续5个9的行
x\{m,\} 至少m个x /9\{5,\}/ 匹配包含至少连续5个9的行
x\{m,n\} 至少m个,但不超过n个x /9\{5,7\}/ 匹配包含连续5到7个9的行
应用举例
p命令
命令p用于显示模式空间的内容。默认情况下,sed把输入行打印在屏幕上,选项-n用于取消默认的打印操作。当选项-n和命令p同时出现时,sed可打印选定的内容。
sed '/my/p' datafile #默认情况下,sed把所有输入行都打印在标准输出上。如果某行匹配模式my,p命令将把该行另外打印一遍。 sed -n '/my/p' datafile #选项-n取消sed默认的打印,p命令把匹配模式my的行打印一遍。
d命令
命令d用于删除输入行。sed先将输入行从文件复制到模式空间里,然后对该行执行sed命令,最后将模式空间里的内容显示在屏幕上。如果发出的是命令d,当前模式空间里的输入行会被删除,不被显示。
sed '$d' datafile #删除最后一行,其余的都被显示 sed '/my/d' datafile #删除包含my的行,其余的都被显示
s命令
sed 's/^My/You/g' datafile #命令末端的g表示在行内进行全局替换,也就是说如果某行出现多个My,所有的My都被替换为You。 sed -n '1,20s/My$/You/gp' datafile #取消默认输出,处理1到20行里匹配以My结尾的行,把行内所有的My替换为You,并打印到屏幕上。 sed 's#My#Your#g' datafile #紧跟在s命令后的字符就是查找串和替换串之间的分隔符。分隔符默认为正斜杠,但可以改变。无论什么字符(换行符、反斜线除外),只要紧跟s命令,就成了新的串分隔符。
e选项
-e是编辑命令,用于sed执行多个编辑任务的情况下。在下一行开始编辑前,所有的编辑动作将应用到模式缓冲区中的行上。
sed -e '1,10d' -e 's/My/Your/g' datafile #选项-e用于进行多重编辑。第一重编辑删除第1-3行。第二重编辑将出现的所有My替换为Your。因为是逐行进行这两项编辑(即这两个命令都在模式空间的当前行上执行),所以编辑命令的顺序会影响结果。
r命令
r命令是读命令。sed使用该命令将一个文本文件中的内容加到当前文件的特定位置上。
sed '/My/r introduce.txt' datafile #如果在文件datafile的某一行匹配到模式My,就在该行后读入文件introduce.txt的内容。如果出现My的行不止一行,则在出现My的各行后都读入introduce.txt文件的内容。
w命令
sed -n '/hrwang/w me.txt' datafile
a\ 命令
a\ 命令是追加命令,追加将添加新文本到文件中当前行(即读入模式缓冲区中的行)的后面。所追加的文本行位于sed命令的下方另起一行。如果要追加的内容超过一行,则每一行都必须以反斜线结束,最后一行除外。最后一行将以引号和文件名结束。
sed '/^hrwang/a\ >hrwang and mjfan are husband\ >and wife' datafile #如果在datafile文件中发现匹配以hrwang开头的行,则在该行下面追加hrwang and mjfan are husband and wife
i\ 命令
i\ 命令是在当前行的前面插入新的文本。
c\ 命令
sed使用该命令将已有文本修改成新的文本。
n命令
sed使用该命令获取输入文件的下一行,并将其读入到模式缓冲区中,任何sed命令都将应用到匹配行紧接着的下一行上。
sed '/hrwang/{n;s/My/Your/;}' datafile
注:如果需要使用多条命令,或者需要在某个地址范围内嵌套地址,就必须用花括号将命令括起来,每行只写一条命令,或这用分号分割同一行中的多条命令。
y命令
该命令与UNIX/Linux中的tr命令类似,字符按照一对一的方式从左到右进行转换。例如,y/abc/ABC/将把所有小写的a转换成A,小写的b转换成B,小写的c转换成C。
sed '1,20y/hrwang12/HRWANG^$/' datafile #将1到20行内,所有的小写hrwang转换成大写,将1转换成^,将2转换成$。 #正则表达式元字符对y命令不起作用。与s命令的分隔符一样,斜线可以被替换成其它的字符。
q命令
q命令将导致sed程序退出,不再进行其它的处理。
sed '/hrwang/{s/hrwang/HRWANG/;q;}' datafile
h命令和g命令
#cat datafile My name is hrwang. Your name is mjfan. hrwang is mjfan's husband. mjfan is hrwang's wife. sed -e '/hrwang/h' -e '$G' datafile sed -e '/hrwang/H' -e '$G' datafile #通过上面两条命令,你会发现h会把原来暂存缓冲区的内容清除,只保存最近一次执行h时保存进去的模式空间的内容。而H命令则把每次匹配hrwnag的行都追加保存在暂存缓冲区。 sed -e '/hrwang/H' -e '$g' datafile sed -e '/hrwang/H' -e '$G' datafile #通过上面两条命令,你会发现g把暂存缓冲区中的内容替换掉了模式空间中当前行的内容,此处即替换了最后一行。而G命令则把暂存缓冲区的内容追加到了模式空间的当前行后。此处即追加到了末尾。
sed脚本
sed脚本就是写在文件中的一列sed命令。脚本中,要求命令的末尾不能有任何多余的空格或文本。如果在一行中有多个命令,要用分号分隔。执行脚本时,sed先将输入文件中第一行复制到模式缓冲区,然后对其执行脚本中所有的命令。每一行处理完毕后,sed再复制文件中下一行到模式缓冲区,对其执行脚本中所有命令。使用sed脚本时,不再用引号来确保sed命令不被shell解释。例如sed脚本script:
#handle datafile 3i\ ~~~~~~~~~~~~~~~~~~~~~ 3,$s/\(hrwang\) is \(mjfan\)/\2 is \1/ $a\ We will love eachother forever!!
#sed -f script datafile My name is hrwang Your name is mjfan ~~~~~~~~~~~~~~~~~~~~~ mjfan is hrwang's husband. mjfan is hrwang's wife. We will love eachother forever!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号