
Day05.XML、Dom4j、综合案例
反射
- 认知:反射技术就是对类进行解剖,解剖出"构造器"、"成员变量"、"成员方法"
- 构造器: 可以实例化对象
- 成员变量:可以赋值、取值
- 成员方法:调用方法
- 大白话:不使用new关键字,可以实例化对象,可以访问对象中的成员
- 反射技术,通常应用于:框架
- 使用反射技术:
- 核心点:Class类
- Class类是什么呢?
- JVM中只能执行.class字节码文件(Java程序中会存在大量的.class文件)
- .class文件是通过
类加载器读取到内存中,并基于这个.class文件创建出:Class对象- Class对象,就是指一个.class文件
- Class类的作用
- 通过Class对象,获取"构造器"、"成员方法"、"成员变量"
- Class类是什么呢?
- 步骤:
- 1、获取Class对象
- 2、基于Class对象,可以获取:构造器、成员方法、成员变量
- 构造器:Constructor类
- 成员方法:Method类
- 成员变量:Field类
- 3、使用构造器,调用
newInstance(...)方法,来实例化对象 - 4、使用成员方法,调用
invoke(...)方法,来调用方法入栈执行 - 5、使用成员变量,调用
set(...)方法、get(...)方法,对变量进行赋值、取值
- 核心点:Class类
注解
-
认知:
- 注解单独使用,没有任何意义。
- 通常注解会配合反射技术一起使用,常用于框架技术
-
注解的定义:
-
public @interface 注解名{ 数据类型 属性名(); 数据类型 属性名() default 默认值; 数据类型[] 属性名(); }
-
-
注解的使用:
-
@注解名 public class 类{ @注解名(属性名=值) private String 成员变量; @注解名 //@Test public void 成员方法(int 参数){ } }
-
-
元注解:
- 作用:限定注解的使用位置、注解的生命周期
- @Target //指定注解的使用位置
- @Retention //设定注解的生命周期
-
注解解析(注解存在的意义)
-
//API: //判断某个对象(类、接口、成员变量、构造器、成员方法)上是否有使用注解 boolean flag = isAnnotationPresent(注解.class) //获取某个对象上的注解对象 注解名 对象 = getAnnotation(注解.class) 数据类型 变量 = 注解对象.属性;
-
-
示例:
-
//前置铺垫: 一张数据表 对应 类 一行记录 对应 对象 一个字段 对应 成员变量 create table t_student ( sname varchar(20), sage int ); //类 class Student{ private String name; private int age; } //JDBC程序: (程序员自己编写) 连接数据库 创建数据库操作对象 发送sql语句: select ... 处理结果集 while(rs.next()){ age = rs.getInt("sage"); name =rs.getString("sname"); Student stu = new Student(); stu.setName( name ); stu.setAge( age ); } //框架技术: 反射+注解 (别人已经完成的) //1、自定义一些注解 public @interface Entity{ //实体 String table(); //表名 } public @interface property{ //属性 String name(); } //2、解析@Entity、@Property注解 扫描某些包下的的类,发现这些类上有@Entity、@Property注解,就会利用反射 利用反射技术: 获取 Student.class 对象 (Class对象) 解析 类上的@Entity注解 利用反射技术: 获取所有的成员变量 : 解析所有成员变量上的@Property注解 //JDBC程序中使用框架技术中注解 ( 程序员自己编写 ) @Entiry(table="t_student") //表示当前的Student类和数据表t_student关联 class Student{ @Property(name="sname") //表示当前的成员变量name和字段sname关联 private String name; @Property(name="sage") //表示当前的成员变量age和字段sage关联 private int age; }
-
动态代理
-
动态代理,提供了一个代理的对象,有了代理对象后,当访问某个方法时,会被代理对象拦截(拦截后可以对方法进行前增强、后增强【代理对象不会破坏原有方法的代码】)
-
动态代理的特点:
- 动态的创建.class文件
- 动态的加载.class文件到内存中(创建Class对象)
- Proxy类需要一个"类加载器"
- 对程序员来讲,不需要书写代理类
-
动态代理的代码实现:
-
代理对象 = Proxy.newProxyInstance(类加载器 , 父接口 , 处理器) -
类加载器: 动态的加载.class文件 父接口 : 代理类和被代理类需要拥有共同的父接口 处理器: 代理对象拦截了方法后,对方法进行前增强、后增强,是由处理器来书写逻辑 -
代理对象 = Proxy.newProxyInstance( 类.class.getClassLoader(), //类加载器 被代理类.class.getInterfaces(), //父接口 new InvocationHandler(){ public Object invoke( Object 代理对象, Method 被拦截的方法对象 , Object[] 方法中的实参 ){ //业务逻辑 } } )
-
XML,Dom4j、综合案例
今日内容
-
XML
-
Dom4j(解析xml文件)
-
综合案例
教学目标
今日重点
1.书写xml
2.理解如何解析xml
第一章 XML
1 XML概述
目标
- 什么是XML
什么是XML
- 英文:eXtensible Markup Language 可扩展的标记语言,由各种标记(标签,元素)组成。
- 可扩展:所有的标签都是自定义的,可以随意扩展的。如:<abc/>,<姓名>
- 标记语言:整个文档由各种标签组成。清晰,数据结构化!
- XML是通用格式标准,全球所有的技术人员都知道这个东西,都会按照XML的规范存储数据,交互数据!!
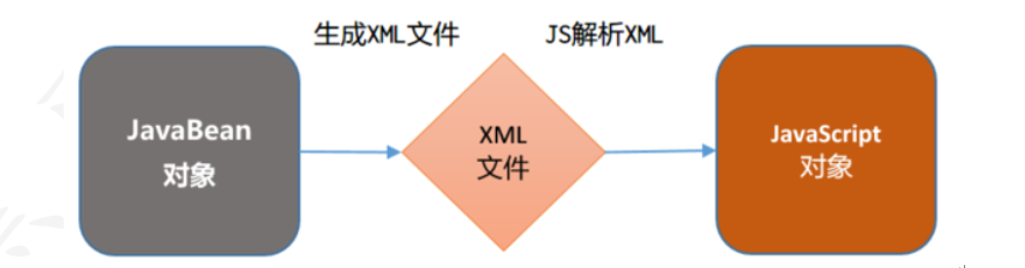
XML作用
作用:总体上来说,就是为了存储维护数据的。
-
数据交换:不同的计算机语言之间,不同的操作系统之间,不同的数据库之间,进行数据交换。
-
配置文件:在后期我们主要用于各种框架的配置文件基本天天见。
比如我们很快会学到连接池:c3p0-config.xml

小结
-
xml是什么?
- 可扩展的标记语言
- 标记:标签。例:
- 标记:标签。例:
- xml文件是由N多个标签组成的
- 可扩展的标记语言
-
主要有哪两个作用?
- 存储数据
- 配置文件
2 编写第1个XML文件
需求
编写xml文档,用于描述人员信息,person代表一个人员,id是人员的属性代表人员编号。人员信息包括age年龄、name姓名、sex性别信息。
使用Java类去描述:
class Person{
String id;
int age;
String name;
String sex;
}
Person p = new Person("1","张三",18,"男");
效果

步骤
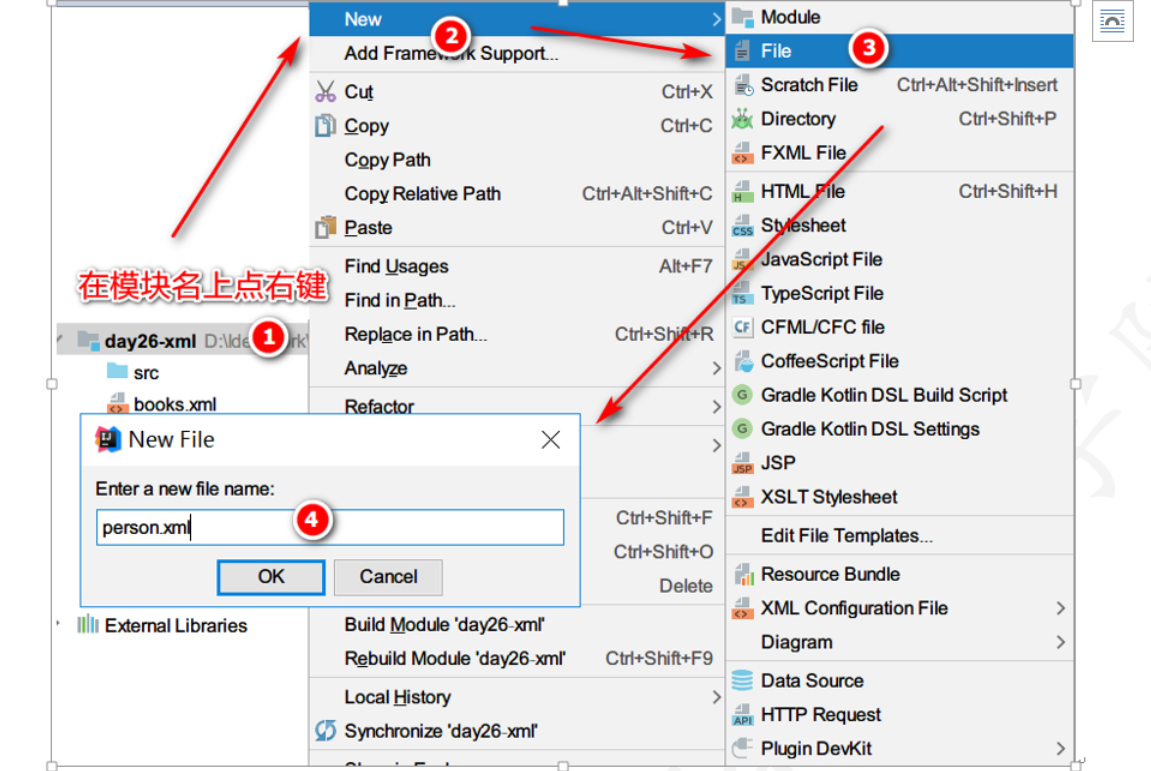
-
选择当前项目鼠标右键新建
新建一个File命名时,以 .xml结尾。这个文件就是xml文件
-
编写person.xml文件
<?xml version="1.0" encoding="UTF-8" ?> <peopel> <person> <id>1</id> <name>张三</name> <age>18</age> <sex>男</sex> </person> <person> <id>2</id> <name>李四</name> <age>20</age> <sex>女</sex> </person> </peopel> -
通过浏览器解析XML的内容

- 注:XML以后通过Java来进行解析,很少直接在浏览器上显示。
小结:
- xml文件,通常以.xml作为后缀名
- xml文件中的首行必须书写:
- xml文件通常是由成对标签(开始标签、结束标签)组成
3 XML的组成:声明和元素
目标
- XML文档中的声明
- XML文档中的元素
XML组成
- 声明
- 元素(标签)
- 属性
- 注释
- 转义字符【实体字符】
- CDATA 字符区
文档声明
<?xml version="1.0" encoding="utf-8" ?> 固定格式
-
IDEA会自动提示。
-
文档声明必须为<?xml开头,以?>结束
-
文档声明必须从文档的1行1列位置开始,必须在xml文档中的首行首列

-
文档声明中常见的两个属性:
- version:指定XML文档版本。必须属性,这里一般选择1.0;
- encoding:指定当前文档的编码,可选属性,默认值是utf-8;
元素(标签、标记)
格式1: <person> 标签体 </person> 有标签体的标签
格式2: <person/> 没有标签体的标签 (空标签)
-
元素是XML文档中最重要的组成部分;
-
普通元素的结构由开始标签、元素体、结束标签组成。【格式1】
-
元素体:元素体可以是元素,也可以是文本,例如:
<person> 标签中可以包含另一个标签 <name>张三</name> </person> -
空元素:空元素只有标签,而没有结束标签,但元素必须自己闭合,例如:
<sex/> -
元素命名
- 区分大小写
- 不能使用空格,不能使用冒号
- 不建议以XML、xml、Xml开头
- 标签名不能数字开头,可以有数字
- 可以使用下划线
可以保持与Java命名标识符一样的规则
-
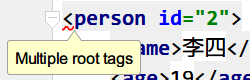
格式化良好的XML文档,有且仅有一个根元素。
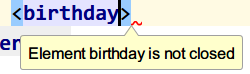
错误演示:
元素没有结束
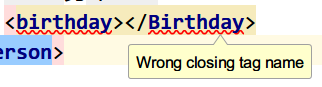
元素大写小写不一致
xml中多个根
小结
-
声明有哪两个常用的属性?
- version
- encoding
-
一个XML有几个根元素?
- 有且只能有一个根元素
-
XML标签命名不能有什么符号?
- 不能使用关键字xml、XML
- 不能有空格、不能有冒号
- 不能以数字作为开头
4 XML的组成:属性、注释和转义字符
属性的语法
<person id="110">
-
属性是元素的一部分,它必须出现在元素的开始标签中
-
属性的定义格式:
属性名=“属性值”,其中属性值必须使用单引或双引号括起来 -
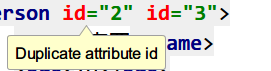
一个元素可以有0~N个属性,但一个元素中不能出现同名属性
-
属性名不能使用空格 , 建议不要使用冒号等特殊字符,且必须以字母开头
建议以Java的标识符定义规则做参考
<person id="123">
<name>张三</name>
</person>
注释
<!-- 注释内容 -->
<!--
注释内容 1
注释内容 2
-->
XML的注释与HTML相同,既以<!--开始,-->结束。不能嵌套。
Java中注释:
// 单行
/* */ 多行注释
/** */ 文档注释
XML注释:
<!-- 注释内容 -->
<!--<person>注释</person>--> <!-- 快捷键:Ctrl+/ :可以将整行进行注释-->
<person>三生三世</person> <!-- 快捷键:Ctrl+Shift+/:局部注释-->
转义字符[实体字符]
XML中的实体字符与HTML一样。因为很多符号已经被文档结构所使用,所以在元素体或属性值中想使用这些符号就必须使用实体字符
| 字符 | 预定义的转义字符 | 说明 |
|---|---|---|
| < | < |
小于(less than) |
| > | > |
大于(greater than) |
| " | " |
双引号(quotation) |
| ' | ' |
单引号(apostrophe) |
| & | & |
和号(ampersand ) |
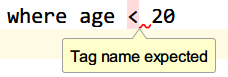
注意:严格地讲,在 XML 中仅有字符 "<"和"&" 是非法的。省略号、引号和大于号是合法的,但是把它们替换为实体引用是个好的习惯。
转义字符应用示例:
假如您在 XML 文档中放置了一个类似 "<" 字符,那么这个文档会产生一个错误,这是因为解析器会把它解释为新元素的开始。因此你不能这样写:
<message>if salary < 1000 then </message>
为了避免此类错误,需要把字符 "<" 替换为实体引用,就像这样:
<message>if salary < 1000 then</message>
小结
-
属性必须出现在标签哪个位置?
-
和开始标签绑定在一起,书写在开始标签元素的后面
-
<person id="属性值"> </person>
-
-
同一个标签是否可以有同名的属性?
- 不可能。
- 允许有多个属性,属性之间使用空格分隔,但不能出现相同名称的属性
-
为什么要有转义字符(实体字符)?
- 在xml文件中,一些特定的符号已经被xml使用了。例:> & 等
- 希望在xml文档中,使用特定的符号,需要用:转义字符
- < =>
< - & =>
&
- < =>
-
注释的快捷?
- ctrl + /
5 XML的组成:字符区(了解)
当大量的转义字符出现在xml文档中时,会使XML文档的可读性大幅度降低。这时如果使用CDATA段就会好一些。
CDATA (Character Data)字符数据区,格式如下:
<![CDATA[
文本数据 < > & ; " "
]]>
- CDATA 指的是不应由 XML 解析器进行解析的文本数据(Unparsed Character Data)
- CDATA 部分由
<![CDATA[开始,由]]>结束;
例如:
<![CDATA[
if salary < 1000 then
]]
快捷模板:CD 回车

注意:
CDATA 部分不能包含字符串 "]]>"。也不允许嵌套的 CDATA 部分。
标记 CDATA 部分结尾的 "]]>" 不能包含空格或折行。
小结:
- 字符区的特点:
- 原样显示(书写的内容不会被xml解析器解析)
6 DTD约束(能够看懂即可)
1 什么是DTD
DTD(Document Type Definition),文档类型定义,用来约束XML文档。规定XML文档中元素的名称,子元素的名称及顺序,元素的属性等。
2 DTD约束的实现和语法规则(看懂dtd约束,书写符合规范的xml文件)
开发中,我们不会自己编写DTD约束文档,通常情况我们都是通过框架提供的DTD约束文档,编写对应的XML文档。
需求:接下来我们创建一个dtd约束文档,然后按照约束文档书写符合规范的xml文件。
我们先新建一个books.xml文件。
第一步:在项目下面创建一个dtd的文件夹,然后选中文件夹,鼠标右击,新创键一个books.xml文件
第二步:我们先书写books.xml文件中的内容:
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book>
<name>面试宝典</name>
<author>锁哥</author>
<price>78.8</price>
</book>
<book>
<name>java从入门到精通</name>
<author>黑旋风</author>
<price>88.8</price>
</book>
</books>
经过上述四步我们就将books.xml文件书写完毕,接下来我们开始书写DTD约束。
关于DTD约束我们能够看懂即可。如下所示就是上述books.xml文件引入了DTD约束。
简单的DTD约束就写好了,如下所示:
我们直接将如下约束复制到我们上述书写好的books.xml文件中即可,能够读懂即可。
<?xml version="1.0" encoding="UTF-8"?>
<!--
1.在xml内部定义dtd约束的声明 : <!DOCTYPE 根元素 [元素声明]>
2.xml的元素(标签)的声明: <!ELEMENT 元素名称 (元素内容)>
<!ELEMENT books (book)> 表示books标签下是book标签
<!ELEMENT book (name,author,price)> 表示的是book标签下出现的name,author,price子标签
<!ELEMENT name (#PCDATA)> 表示name标签中出现的内容是文本
-->
<!DOCTYPE books [
<!--约束根标签 book* 表示books标签下可以有多个book子标签
* + ? 和正则表达式中表示的意思是一样的
* : 0 1 n
+ : 1 n
? : 0 1
-->
<!ELEMENT books (book*)>
<!--约束book标签-->
<!ELEMENT book (name,author,price)>
<!--约束name,author,price标签
但是这三个标签下就是文本了
#PCDATA 表示标签下内容是文本
-->
<!ELEMENT name (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT price (#PCDATA)>
]>
<books>
<book>
<name>面试宝典</name>
<author>锁哥</author>
<price>78.8</price>
</book>
<book>
<name>java从入门到精通</name>
<author>黑旋风</author>
<price>88.8</price>
</book>
</books>
说明:
1)xml中出现的标签,也叫做元素。那么我们书写的约束可以规范xml中到底能出现哪些标签。除此之外都不能出现。
所以xml中出现的标签都需要我们开发者在dtd约束中声明一下。只有声明了这个标签,xml中才能出现这个标签。如果约束中没有声明,那么xml中就不能出现。
所以,xml中出现的标签需要使用如下的语法(也就是xml中元素的声明语法)。
在xml内部定义dtd约束的声明 :
<!DOCTYPE 根元素 [元素声明]>
xml的元素(标签)的声明:
<!ELEMENT 元素名称 (元素内容)>
元素名:自定义。
元素内容包括:符号、数据类型和标签。
常见符号:? * + () |
常见数据类型:#PCDATA 表示内容是文本,不能是子标签。
标签:就是正常子标签。
2)由于 顺序是name,author,price,所以下面的顺序也得是:
<book>
<name>面试宝典</name>
<author>锁哥</author>
<price>78.8</price>
</book>
前后顺序不能换。
接下来对上述代码的标签添加属性,比如给book属性添加一个address地址,表示将书存放到哪里。
添加属性之后的代码如下所示:
<!DOCTYPE books [
<!--约束根标签 book* 表示books标签下可以有多个book子标签
* + ? 和正则表达式中表示的意思是一样的
-->
<!ELEMENT books (book*)>
<!--约束book标签-->
<!ELEMENT book (name,author,price)>
<!--约束name,author,price标签
但是这三个标签下就是文本了
#PCDATA 表示标签下内容是文本
-->
<!ELEMENT name (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ATTLIST book address CDATA "图书馆"
id ID #REQUIRED
>
]>
<books>
<book address="藏经阁" id="a1">
<name>面试宝典</name>
<author>锁哥</author>
<price>78.8</price>
</book>
<book id="a2">
<name>java从入门到精通</name>
<author>黑旋风</author>
<price>88.8</price>
</book>
</books>
对上述声明属性进行解释说明:
元素名称: 表示该属性使用在哪个标签上;
属性名称: 表示在标签上添加的属性名字;
属性类型: 添加的属性类型。
属性类型有如下几种:
类型 描述
**CDATA 值为字符数据 (character data) **
(en1|en2|..) 此值是枚举列表中的一个值
**ID 值为唯一的 id **
默认值: 表示最开始给属性的默认值。
值 解释
值 属性的默认值
**#REQUIRED 属性值是必需的 **
#IMPLIED 属性不是必需的
#FIXED value 属性值是固定的
7 Schema约束(能够看懂即可)
与dtd约束一样,schema它也是用来约束xml文件的。schema约束书写的时候,它遵守xml的语法规则。在书写schema的时候,就和书写xml文件的文档结构一样。
注意:书写schema文件的时候,它的文件扩展名是xsd。
1 书写schema约束
1、首先创建一个xml文件。然后根据xml文件书写符合规范的schema约束。
创建books.xml文件:
代码如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book>
<name>面试宝典</name>
<author>锁哥</author>
<price>78.8</price>
</book>
<book>
<name>java从入门到精通</name>
<author>黑旋风</author>
<price>88.8</price>
</book>
</books>
2、接下来我们需要创建一个schema文件:
步骤:
第一步:首先进入文件创建窗口,选中工程鼠标右击,new-->File,然后进入如下页面:
第二步:输入创建的文件的名称和schema文件的后缀名xsd;
第三步:因为schema约束文件本身就是xml,所以声明xml文件的头适用于schema约束的文件。

第四步:将如下的内容复制到上述已经创建好的books.xsd中。然后我们就可以书写schema约束了。
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/books"
elementFormDefault="qualified">
</schema>
说明:
1)schema约束的结构和xml文件书写规范是一样的,表示对xml的声明,
2)xmlns="http://www.w3.org/2001/XMLSchema" 表示此schema文件受到w3组织的指定的约束;
3)targetNamespace="http://www.example.org/books",叫做名称空间,这个相当于java中包的作用,区分不同约束中的不同标签。当需要被当前这个schema文件约束的xml文件,需要通过当前这个名字引入当前schema文件。
4)elementFormDefault="qualified",如果值为qualified,那么当前schema中所有的标签默认都是放在名称空间中的。如果值为unqualified,那么除了schema中的根标签在名称空间即 http://www.example.org/books 包中,其他的标签都不会在这个包中。在开发中,我们都是书写默认值qualified。
上述了解完成之后,接下来我们读一下一个完整的schema约束:
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/books"
elementFormDefault="qualified">
<!-- 在此处书写schema约束语法 -->
<element name="books">
<complexType><!-- 声明books是复杂标签 -->
<sequence><!-- 通过sequence标签指定子标签的顺序 -->
<element name="book" maxOccurs="unbounded">
<complexType>
<sequence>
<element name="name" type="string"></element>
<element name="author" type="string"></element>
<element name="price" type="double"></element>
</sequence>
<attribute name="address"></attribute>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
说明:
1.xml中出现的标签需要使用
所以xml中第一个出现的books标签需要使用
element标签中的 name属性 就是xml中 可以书写的标签的名字。
2.为了方便schema约束的书写,我们将xml中的标签简单的分为2大类:
a) 简单标签 : 标签中只有文本数据;
b) 复杂标签:标签中有子标签或者属性加上文本数据;
在element标签中需要使用complexType声明当前的element标签name属性指定的是一个复杂标签。
如果是简单标签可以使用simpleType。
3.上述在books.xml文件中我们发现books标签是复杂标签,针对复杂标签,需要在当前的标签中书写子标签来限制当前复杂标签中的其他内容。
所以我们需要使用
A)books标签中出现的子标签是book,由于book也是一个标签,所以我们也需要使用
B)并且book标签也是一个复杂标签,所以我们需要使用
C)book标签中也有子标签,所以还需要使用
D)最后发现book标签在books.xml出现了多次,所以需要给
大于等于1次
5.最后在里面写上book标签中出现的3个name,author,price子标签的声明。并且针对book标签中出现的属性。我们需要使用
在books.xml文件中增加一个address属性:

所以在books.xsd即schema约束中添加一个属性。注意
2 在xml文件中引入schema约束
在books.xml文件中引入schema约束的步骤:
第一步:首先鼠标放在根标签books后面,打个空格,然后将如下内容复制到books后面
代码如下:
<books xmlns="default namespace"
xsi:schemaLocation="{namespace} {location}"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
然后引入schema约束的图解
最终完整代码:
<?xml version="1.0" encoding="UTF-8"?>
<books xmlns="http://www.example.org/books"
xsi:schemaLocation="http://www.example.org/books books.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
>
<book address="藏经阁">
<name>面试宝典</name>
<author>锁哥</author>
<price>78.8</price>
</book>
<book>
<name>java从入门到精通</name>
<author>黑旋风</author>
<price>88.8</price>
</book>
</books>
说明:
1)xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance",表示当前xml文件是一个受schema约束的实例,这里不需要改变;
2)xmlns="http://www.example.org/books",schema约束文件中的targetNamespace的值,表示在books.xml文件中引入名称空间;
3)xsi:schemaLocation="http://www.example.org/books books.xsd",
schema约束文件中的targetNamespace的值 schema约束文件的路径
第二章 Dom4j
1 XML解析
1.1 解析概述
当将数据存储在XML后,我们就希望通过程序获取XML的内容。我们使用Java基础所学的IO知识是可以完成的,不过需要非常繁琐的操作才可以完成,且开发中会遇到不同问题(只读、读写)。
人们为不同问题提供不同的解析方式,使用不同的解析器进行解析,方便开发人员操作XML。
1.2 解析方式和解析器
开发中比较常见的解析方式有三种,如下:
-
DOM:要求解析器把整个XML文档装载到内存,并解析成一个Document对象
a)优点:元素与元素之间保留结构关系,故可以进行增删改查操作。
b)缺点:XML文档过大,可能出现内存溢出
-
SAX:是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。并以事件驱动的方式进行具体解析,每执行一行,都触发对应的事件。
a)优点:处理速度快,可以处理大文件
b)缺点:只能读,逐行后将释放资源,解析操作繁琐。
-
PULL:Android内置的XML解析方式,类似SAX。(了解)
解析器,就是根据不同的解析方式提供具体实现。有的解析器操作过于繁琐,为了方便开发人员,有提供易于操作的解析开发包
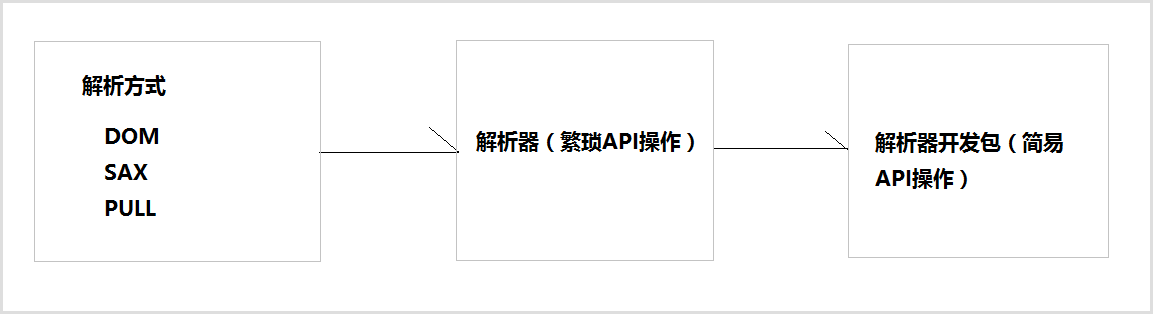
常见的解析器

2 Dom4j的基本使用
2.1 DOM解析原理及结构模型
解析原理
将整个XML文档加载到内存,生成一个DOM树,并获得一个Document对象,通过Document对象就可以对DOM树进行操作。以下面books.xml文档为例。
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="0001">
<name>JavaWeb开发教程</name>
<author>张孝祥</author>
<sale>100.00元</sale>
</book>
<book id="0002">
<name>三国演义</name>
<author>罗贯中</author>
<sale>100.00元</sale>
</book>
</books>
结构模型
DOM中的核心概念就是节点,在XML文档中的元素、属性、文本,在DOM中都是节点!所有的节点都封装到了Document对象中。
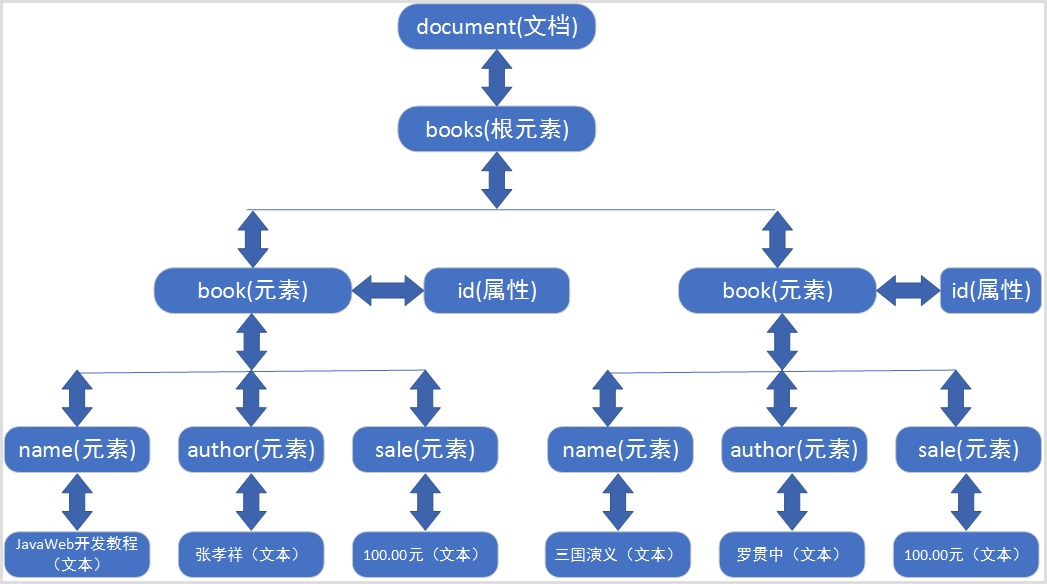
结论:使用Document对象,就可以去访问DOM树中的每一个节点
引入dom4j的jar包
去官网下载 zip 包。http://www.dom4j.org/
通常我们会在项目中创建lib文件夹,将需要依赖的库放在这里。
库导入方式:
-
在IDEA中,选择项目鼠标右键--->弹出菜单-->open Module settings”-->Dependencies-->+-->JARs or directories... 找到dom4j-1.6.1.jar,成功添加之后点击"OK" 即可。
-
直接右键选择:Add as Library
小结
dom4j的解析思想,先把xml文档加载到内存中,从而得到一个DOM树,并创建一个Document对象去维护dom树。
利用Document对象,就可以去解析DOM树(解析XML文件)
回顾上午内容:
- xml文档
- xml是由一些标签组成
- xml的后缀名:.xml
- xml文档的组成内容:
- 文档声明(固定的)
- 标签(标记、元素)
- 属性
- 注释
- 转义字符
- 字符区
- xml:可扩展的标记语言。所有的标记都是自定义的(书写的随意性比较高)
- xml约束:约束xml文档
- dtd约束
- schema约束
- 比dtd约束更灵活、更强大(针对数据的类型也可以约束)
- xml解析
- 对xml文档的内容进行解析,解析出xml中的一些数据
- 解析方式:
- dom4j
- 实现原理:
- 把整个xml文档加载到内存中,并生成一个DOM树,基于dom树创建一个Document对象
- 利用Document对象来对xml进行解析
- 实现原理:
- xpath
- dom4j
2.2 常用的方法
dom4j 必须使用核心类SaxReader加载xml文档获得Document,通过Document对象获得文档的根元素,然后就可以操作了。
SAXReader对象
| 方法 | 作用 |
|---|---|
| SAXReader sr = new SAXReader(); | 构造器 |
| Document read(String url) | 加载执行xml文档 |
Document对象
| 方法 | 作用 |
|---|---|
| Element getRootElement() | 获得根元素 |
Element对象
| 方法 | 作用 |
|---|---|
| List<Element> elements(String ele ) | 获得指定名称的所有子元素。可以不指定名称 |
| Element element(String ele) | 获得指定名称第一个子元素。 |
| String getName() | 获得当前元素的元素名 |
| String attributeValue(String attrName) | 获得指定属性名的属性值 |
| String elementText(Sting ele) | 获得指定名称子元素的文本值 |
| String getText() | 获得当前元素的文本内容 |
小结
解析xml的步骤:
- 创建SaxReader对象,调用read方法关联xml文件,得到一个Document对象
- 通过Document对象,获取根元素
- 获取根元素之后,就可以层层深剥,运用Element相关的API进行解析其子元素
2.3 方法演示
复制资料下的常用xml中"books.xml",内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="0001">
<name>JavaWeb开发教程</name>
<author>张孝祥</author>
<sale>100.00元</sale>
</book>
<book id="0002">
<name>三国演义</name>
<author>罗贯中</author>
<sale>100.00元</sale>
</book>
</books>
注意:为了便于解析,此xml中没有添加约束
解析此文件,获取每本书的id值,以及书本名称,作者名称和价格.
步骤分析:
- 创建一个SaxReader对象,调用read方法加载一个xml文件获得文档对象
- 通过文档对象,获取根元素
- 通过根元素一层一层的进行解析子元素。
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.util.List;
public class Demo01 {
public static void main(String[] args) throws DocumentException {
//1. 创建一个SaxReader对象,调用read方法加载一个xml文件获得文档对象
SAXReader sr = new SAXReader();
Document doc = sr.read("day15/xml/book.xml");
//2. 通过文档对象,获取根元素
Element rootElement = doc.getRootElement();
//3. 通过根元素一层一层的进行解析子元素。
//获取所有的子元素
List<Element> bookElements = rootElement.elements("book");
for (Element bookElement : bookElements) {
//System.out.println(bookElement);
//解析属性
String id = bookElement.attributeValue("id");
System.out.println("id = " + id);
//获取子元素文本
String name = bookElement.elementText("name");
String author = bookElement.elementText("author");
String sale = bookElement.elementText("sale");
System.out.println("name = " + name);
System.out.println("author = " + author);
System.out.println("sale = " + sale);
System.out.println("----------------------");
}
}
}
需求二:
将xml中文件数据解析成为java对象,每个book解析为一个book类型的对象。然后将book对象放到一个集合中存储。
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="0001">
<name>JavaWeb开发教程</name>
<author>张孝祥</author>
<sale>100.00元</sale>
</book>
<book id="0002">
<name>三国演义</name>
<author>罗贯中</author>
<sale>100.00元</sale>
</book>
</books>
步骤分析:
- 先创建一个Book类对应book元素
- 创建一个ArrayList集合用来存储解析后的book对象
- 创建SaxReader对象,调用read方法加载xml文件,得到文档对象
- 通过文档对象获取根元素,然后层层解析
代码实现:
public class Demo02 {
public static void main(String[] args) throws DocumentException {
//定义一个集合用来存储解析的Book对象
ArrayList<Book> books = new ArrayList<>();
//1. 创建一个SaxReader对象,调用read方法加载一个xml文件获得文档对象
SAXReader sr = new SAXReader();
Document doc = sr.read("day15/xml/book.xml");
//2. 通过文档对象,获取根元素
Element rootElement = doc.getRootElement();
//3. 通过根元素一层一层的进行解析子元素。
//获取所有的子元素
List<Element> bookElements = rootElement.elements("book");
for (Element bookElement : bookElements) {
//System.out.println(bookElement);
//解析属性
String id = bookElement.attributeValue("id");
System.out.println("id = " + id);
//获取子元素文本
String name = bookElement.elementText("name");
String author = bookElement.elementText("author");
String sale = bookElement.elementText("sale");
//将解析的字符串封装成为对象,放到集合
Book book = new Book(id,name,author,sale);
books.add(book);
}
//将集合遍历,打印book对象
for (Book book : books) {
System.out.println("book = " + book);
}
}
}
class Book{
private String id;
private String name;
private String author;
private String sale;
public Book() {
}
public Book(String id, String name, String author, String sale) {
this.id = id;
this.name = name;
this.author = author;
this.sale = sale;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getSale() {
return sale;
}
public void setSale(String sale) {
this.sale = sale;
}
@Override
public String toString() {
return "Book{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", author='" + author + '\'' +
", sale='" + sale + '\'' +
'}';
}
}
3 使用xpath技术结合DOM4J技术读取xml文件(了解)
1.概念介绍
问题:通过上面的案例我们发现有个小问题.就是获取标签的过程太过繁琐。我们需要一层一层的去获取。假设xml嵌套了50层的话,对于我们开发者来说是非常繁琐的。所以我们希望应该有这样的技术,一下子直接就能获取我们所需要的标签对象。这就是我们接下来需要学习的xpath技术。
xpath技术 也是 W3C 组织制定的快速获取 xml文件中某个标签的技术。
xpath其实就像在文件系统中定位文件,所以我们学习xpath主要学习xpath的路径表达式。
2.XPath使用步骤
步骤1:导入jar包(dom4j-1.6.1.jar(dom4j核心包)和jaxen-1.1-beta-6.jar(xpath依赖的包))
步骤2:通过dom4j的SaxReader获取Document对象

步骤3:使用document常用的api结合xpath的语法完成选取XML文档元素节点进行解析操作。
说明:
- Node叫做节点,DOM里面所有的类型都是Node的子类
- 比如Document Element Attribute 都是 Node的子类
- Node中的两个方法可以使用XPath:
| 方法 | 作用 |
|---|---|
| List |
获取符合表达式的元素集合 |
| Element selectSingleNode("表达式") | 获取符合表达式的唯一元素 |
3.XPath语法(了解)
在学习如何使用XPath之前,我们先将课后资料中的tianqi.xml放到项目根目录下,然后我们在演示如何使用xpath。
3.1全文搜索路径表达式方式 掌握
- 代表无论中间有多少层,直接获取所有子元素中满足条件的元素
- 一个“/”符号,代表逐级写路径
- 2个“//”符号,不用逐级写路径,可以直接选取到对应的节点,是全文搜索匹配的不需要按照逐层级 重点
- 需求1:获取天气预报里的所有湿度,不论有多少层
- 需求2:获取广州里面的3个最高温度
//代表无论中间有多少层,直接获取所有子元素中满足条件的元素
@Test
public void demo03() throws Exception {
//全文搜索 //
SAXReader reader = new SAXReader();
Document document = reader.read("tianqi.xml");
//获取天气预报里的所有湿度,不论有多少层
List<Node> list = document.selectNodes("//湿度");
//遍历打印
for (Node node : list) {
System.out.println(node.getText());
}
System.out.println("--------------");
//获取广州里面的3个最高温度
List<Node> list1 = document.selectNodes("/天气预报/广州//最高温度");
for (Node node : list1) {
System.out.println(node.getText());
}
}
第三章 综合案例
学习目标:
- 理解所谓的框架是如何实现的,如何使用框架
1、需求
需求:自定义dao层jdbc框架
- 为了方便程序员操作数据库,让程序员更关注于sql代码层面和业务层面
2、案例效果
使用到的技术:
- 反射
- 注解
- 动态代理
- xml解析:xpath
3、案例分析
自定义jdbc框架开发步骤:
1、通过软配置方式,和数据库连接
- 解析xml配置文件,获得:driver、url、username、password
- 德鲁伊连接池
- 根据配置文件中的参数,创建连接池对象
2、创建@Select注解
- 解析@Select注解中value值:
select查询语句
3、创建映射类Mapper
- 把从@Select注解中解析出来的
select查询语句,赋值给Mapper中的sql成员变量
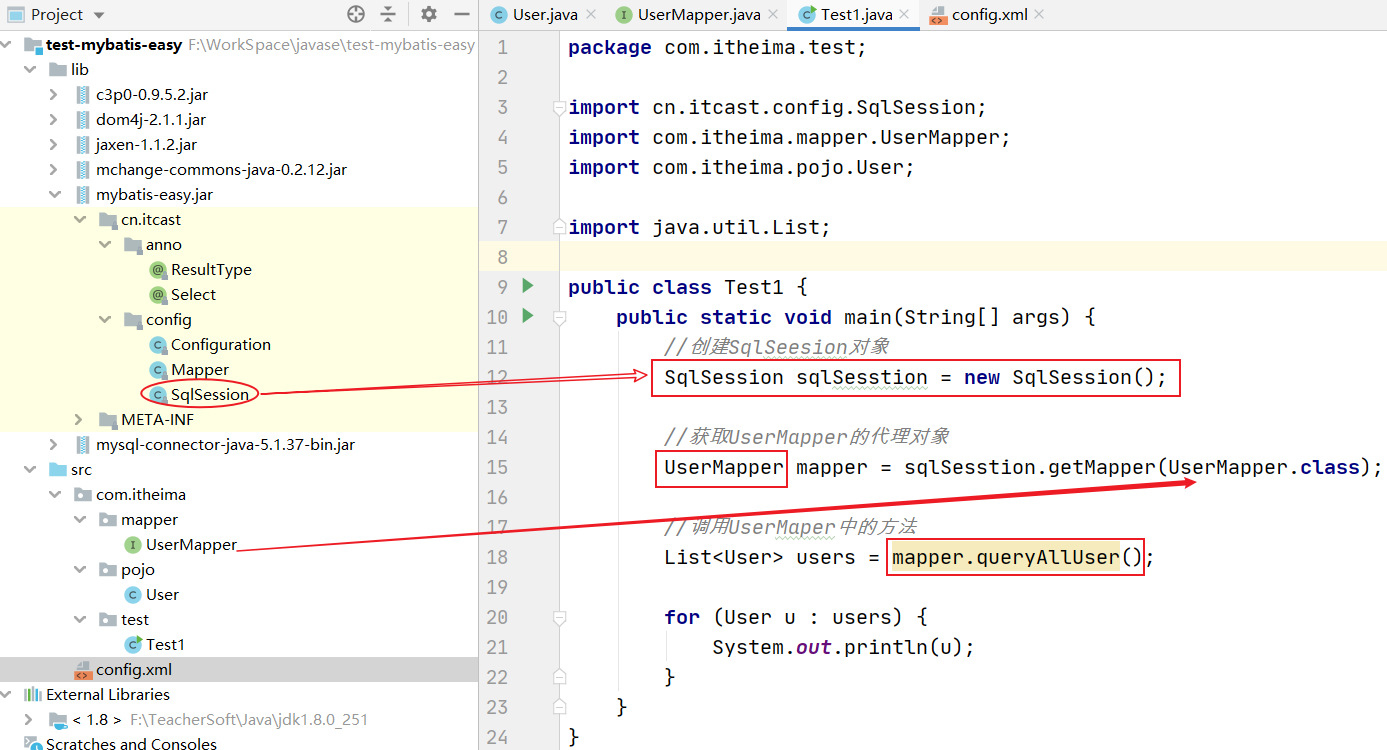
4、创建SqlSession类
- 提供getMapper()方法,用来获取代理对象
- 说明:程序员在获取到代理对象后,利用代理对象调用某个方法时,会被代理对象拦截处理
4、自定义JDBC框架-代码实现
4.1、Configuration
/*配置类
1. 解析XML文件
2. 创建德鲁伊连接池
*/
public class Configuration {
/* 定义数据库连接对象相关属性 */
private String driver;//驱动
private String url;//连接地址
private String username;//登录名
private String password;//密码
/* Mapper接口的全名称 */
private String interName;
/* 数据库连接池对象 */
private DataSource dataSource;
/* 映射类对象 */
private Mapper mapper = new Mapper();
//无参构造方法
public Configuration() {
try {
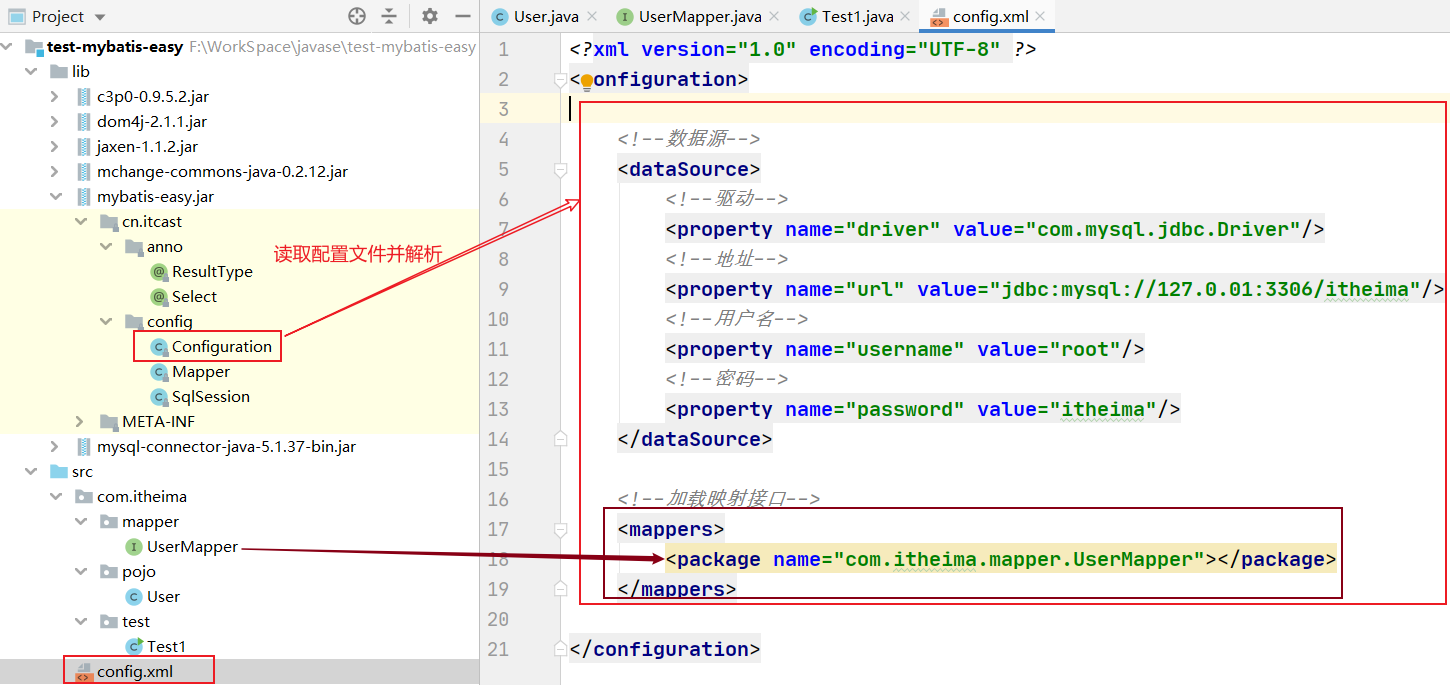
//解析"config.xml"文件
SAXReader reader = new SAXReader();
InputStream is = Configuration.class.getClassLoader().getResourceAsStream("config.xml");
Document doc = reader.read(is);
//调用自定义方法: 将核心配置文件中的数据封装到Configuration类的属性中
loadConfigXml(doc);
//调用自定义方法: 初始化数据库连接池对象
createDataSource();
} catch (Exception e) {
e.printStackTrace();
}
}
//初始化数据库连接池对象
private void createDataSource() throws Exception {
//创建c3p0核心类对象
ComboPooledDataSource cpds = new ComboPooledDataSource();
//使用对象调用方法将四大连接参数给数据库连接池
cpds.setDriverClass(driver);
cpds.setJdbcUrl(url);
cpds.setUser(username);
cpds.setPassword(password);
//将cpds赋值给成员变量ds
this.dataSource = cpds;//数据库连接池对象
}
//将核心配置文件中的数据封装到Configuration类属性中
private void loadConfigXml(Document doc) {
/*
//使用document对象调用方法获取property标签:
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://127.0.0.1:3306/itheima"/>
<property name="username" value="root"/>
<property name="password" value="itheima"/>
*/
List<Node> list = doc.selectNodes("//property");
//遍历List集合
for (Node node : list) {
//强制转换
Element e = (Element) node;
//获取property标签的name属性值
String name = e.attributeValue("name");//双引号中的name是property标签的name属性 driver
//获取property标签的value属性值
String value = e.attributeValue("value");//双引号中的value是property标签的value属性 com.mysql.jdbc.Driver
//将value的值赋值给成员变量
switch (name) {
case "driver":
this.driver = value;//数据库驱动
break;
case "url":
this.url = value;//连接url
break;
case "username":
this.username = value;//登录名
break;
case "password":
this.password = value;//密码
break;
}
}
//<package name="xxx.xxx.UserMapper"></package>
Node node = doc.selectSingleNode("//package");
Element e = (Element) node;
//Mapper接口的全名称
this.interName = e.attributeValue("name");//"xxx.xxx.UserMapper"
}
public String getDriver() {
return driver;
}
public void setDriver(String driver) {
this.driver = driver;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getInterName() {
return interName;
}
public void setInterName(String interName) {
this.interName = interName;
}
public DataSource getDataSource() {
return dataSource;
}
public void setDataSource(DataSource dataSource) {
this.dataSource = dataSource;
}
public Mapper getMapper() {
return mapper;
}
public void setMapper(Mapper mapper) {
this.mapper = mapper;
}
}
4.2、注解
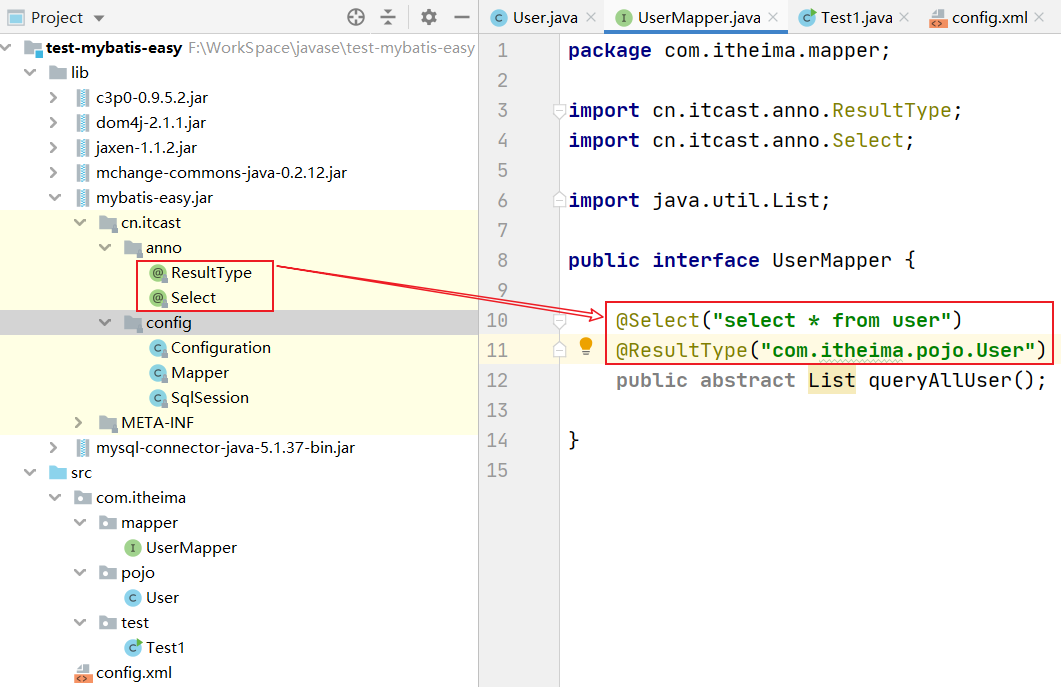
@Select
//查询时使用的注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Select {
String[] value();
}
@ResultType
//查询结果的封装类型
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface ResultType {
String value();
}
4.3、映射类:Mapper
package cn.itcast.config;
public class Mapper {
private String sql;//存储sql语句
private String resultType;//结果类型
public Mapper() {
}
public Mapper(String sql) {
this.sql = sql;
}
public String getSql() {
return sql;
}
public void setSql(String sql) {
this.sql = sql;
}
public String getResultType() {
return resultType;
}
public void setResultType(String resultType) {
this.resultType = resultType;
}
}
4.4、SqlSession类
@SuppressWarnings("all")
public class SqlSession {
/**
* 动态代理
*/
public <T> T getMapper(Class<T> clazz) {
//类加载器: 负责加载代理类到内存中
ClassLoader classLoader = SqlSession.class.getClassLoader();
//父接口
Class[] interfaces = {clazz};
T mapperProxy = (T) Proxy.newProxyInstance(classLoader, interfaces, new InvocationHandler() {
//在调用方法时,代理对象执行invoke方法,返回List
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//创建核心配置类对象
Configuration config = new Configuration();
/******** 解析 @Select、@ResultType *******/
Class clazz = Class.forName(config.getInterName());
Method[] methods = clazz.getMethods();
//遍历数组
for (Method m : methods) {
//判断是否有注解
boolean boo = m.isAnnotationPresent(Select.class);
boolean boo2 = m.isAnnotationPresent(ResultType.class);
if (boo && boo2) {
//获取@Select注解对象
Select select = m.getAnnotation(Select.class);
//获取属性值
String[] value = select.value();//{"select * from user"}
String sql = value[0];
//给Mapper对象中的sql成员变量赋值
config.getMapper().setSql(sql);
//获取@ResultType注解对象
ResultType resultType = m.getAnnotation(ResultType.class);
String type = resultType.value();//获取属性值
config.getMapper().setResultType(type);
}
}
/*******************************/
//获取映射对象
Mapper mapper = config.getMapper();
//利用映射对象,获取sql语句
String sql = mapper.getSql();
//利用映射对象,获取类型
String resultType = mapper.getResultType();
Class cl = Class.forName(resultType);
//获取数据库连接池对象
DataSource ds = config.getDataSource();
//利用连接池对象,获取Connection对象
Connection conn = ds.getConnection();
//调用自定义方法: 执行sql查询语句
List list = queryForList(conn, sql, cl);
return list;
}
});
//代理对象返回给getMapper的调用者 UserMapper mapper = sqlSession.getMapper(UserMapper.class);//mapperProxy
return mapperProxy;
}
public List queryForList(Connection conn, String sql, Class clazz) throws SQLException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
List userList = new ArrayList();
//通过连接对象得到预编译的语句对象
PreparedStatement ps = conn.prepareStatement(sql);
//执行SQL语句,得到结果集
ResultSet rs = ps.executeQuery();
while (rs.next()) {
//获取构造方法对象,并实例化
Object user = clazz.getConstructor().newInstance();
//获取所有的成员变量(包含私有成员变量)
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) { //field可以是:id name passwd age gender adddate
//得到成员变量的名字
String name = field.getName();
//暴力破解: 取消权限检查
field.setAccessible(true);
//rs.getObject(name) 表示根据数据表的列名取出数据表中的列值 因为User类中的成员变量名必须和数据表列名一致
//例如: name 的值是birthday 那么这里 rs.getObject(name)---》rs.getObject("age")获取数据表的年龄20
Object table_value = rs.getObject(name);
//void set(Object obj, Object value)给成员变量赋值,参数1:对象名 参数2:要赋的值
field.set(user, table_value);
}
//user对象添加到集合中
userList.add(user);
}
//释放资源
rs.close();
ps.close();
conn.close();
//返回集合
return userList;
}
}
5、自定义JDBC框架的使用
5.1、数据表
CREATE TABLE user (
id int(11) NOT NULL PRIMARY KEY AUTO_INCREMENT,
name varchar(30) DEFAULT NULL,
passwd varchar(20) DEFAULT NULL,
age int(3) DEFAULT NULL,
gender varchar(2) DEFAULT NULL,
adddate date DEFAULT NULL
);
# 测试数据
INSERT INTO user VALUES (null, 'itcast', '123123', '10', '男', '2020-12-11');
5.2、创建实体类
public class User {
private int id;
private String name;
private String passwd;
private int age;
private String gender;
private Date adddate;
public User() {
}
public User(int id, String name, String passwd, int age, String gender, Date adddate) {
this.id = id;
this.name = name;
this.passwd = passwd;
this.age = age;
this.gender = gender;
this.adddate = adddate;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPasswd() {
return passwd;
}
public void setPasswd(String passwd) {
this.passwd = passwd;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public Date getAdddate() {
return adddate;
}
public void setAdddate(Date adddate) {
this.adddate = adddate;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", passwd='" + passwd + '\'' +
", age=" + age +
", gender='" + gender + '\'' +
", adddate=" + adddate +
'}';
}
}
5.3、UserMapper接口
public interface UserMapper {
//查询所有用户
@Select("select * from user")
@ResultType("com.itcast.pojo.User")
public abstract List queryAllUser();
}
5.4、配置文件:config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<!--数据源-->
<dataSource>
<!--驱动-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<!--地址-->
<property name="url" value="jdbc:mysql://127.0.0.1:3306/itheima"/>
<!--用户名-->
<property name="username" value="root"/>
<!--密码-->
<property name="password" value="itheima"/>
</dataSource>
<!--加载映射接口-->
<mappers>
<package name="com.itcast.mapper.UserMapper"></package>
</mappers>
</configuration>
5.5、测试类
public class Test1 {
@Test
public void testSelect() {
//实例化
SqlSession sqlSession = new SqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = mapper.queryAllUser();
for (User u : users) {
System.out.println(u);
}
}
}
今日作业
1.书写xml: person book
2.解析xml
3.熟悉综合案例流程:反射 动态代理 解析注解
4.预习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号