树
0.PTA得分截图

1.本周学习总结
1.1串内容
1.1.1 BF算法(暴力算法)
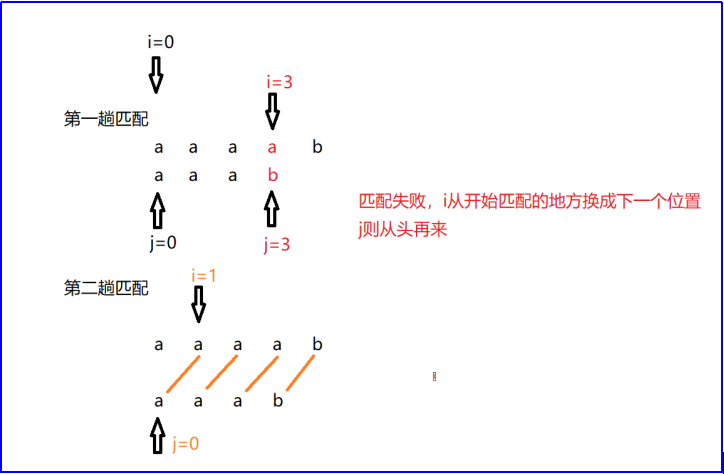
暴力算法的特点:
扫描目标串的i始终是一步一步走,不匹配时则回溯到原来位置的下一个位置。
int BF(string s,string t)
{
int i=0,j=0;
while(i<s.length&&j<t.length)//两个串都没有扫描完
{
if(s.data[i]==t.data[j])
{
i++;j++
}
else
{
i=i-j+1;j=0;//扫描目标串的i回退,子串从头开始匹配
}
if(j>=t.length)
return i-t.length;
else
return -1;匹配失败,返回-1
}
}
1.1.2 KMP算法

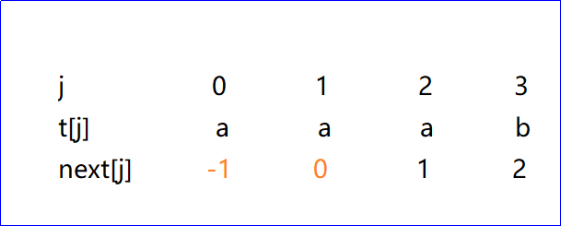
next数组的求法
法一:
-
首先,理解前缀和后缀的意思,前缀,就是以j值前面的所有字符形成的字符串作为一个整体,不包括j值得字符,出去字符串最后一个字符,然后算字串,,后缀就是除去第一个字符,下面得例子可能会讲的比较清楚
-
第一步:设j=0,j=1得next值为1,0
-
第二步:j=2时,字符串aa,前缀字符串 (a) 子串[a],后缀字符串(a) 子串[a],最长相同子串的长度是1
-
第三步,j=3,字符串:aaa, 前缀字符串(aa)的子串有:[a,aa], 后缀字符串(aa)的子串:[aa,a](注意,不是a,aa),所以最长相同子串的长度的长度为2(aa)
法二:
法一是只可以以我们的视角去做,但是计算机不会这么做,它的算法如下:
第一步:设next[0]为-1,next[1]=0
第二步:j=2, t[1] = a = t[next[1]] = t[0],所以next[2]=1
第二步:j=3,t[2] = a = t[next[2]] = t[1], next[3]=1
t[1] = a = t[next[1]] = t[0], next[3]=2
每次到,next[k]=-1时,就停止
void getnext(int next[],string str)
{
int k,j;
j=0;k=-1;
next[0]=-1;
while(j<str.length())
{
if(k==-1||str[j]==str[k])
{
k++,j++;
next[j]=k;
}
else
{
k=next[k];//回溯
}
}
}
int KMP(string str1,string str2)
{
int i=0,j=0;
int len1=str1.length();
int len2=str2.length();
int next[1500];
getnext(next,str2);
while(i<str1.length()&&j<str2.length())
{
if(j==-1||str1[i]==str2[j])
{
j++;i++;
}
else if(str1[i]!=str2[j]&&j==0)
{
i++;
}
else
{
j=next[j];
}
}
if(j>=str2.length())
{
return i-str2.length();
}
else
{
return -1;
}
}
改进的 KMP 算法引进 nextval 数组
| j | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| t[j] | a | a | a | a | b |
| next[j] | -1 | 0 | 1 | 2 | 3 |
| nextval[j] | -1 | -1 | -1 | -1 | 3 |
naxtval数组的定义时naxtval[0]=-1,当t[j]=t[next[j]]时,nextval[j]=nextval[next[j]],否则nextval[j]=next[j]
void GetNexval(string t,int nextval[])
{
int j=0,k=-1;
nextval[0]=-1;
while(j<t.length())
{
if(k==-1||t[j]==t[k])
{
j++,k++;
if(t[j]!=t[k])
{
nextval[j]=k;
}
else
nextval[j]=nextval[k];
}
}
}
1.2 树内容
1.2.1二叉树->每个节点最多两个分支
完全二叉树:

存储结构
由于完全二叉树节点有上图的关系,所以用顺序存储结构(不用值为0的下标),即可快速找到自己的双亲节点和孩子节点。但是,并不是所有的二叉树都满足完全二叉树,于是引进链式存储结构
普通二叉树
存储结构:
typedef struct node *BTree;
typedef struct node
{
ElemType data;
struct node *lchild,*rchild;
//每一个左右指针,指向的都是一棵二叉树
}BTNode;
建二叉树:
先序遍历建立二叉树,例如:abc##de#g##f###
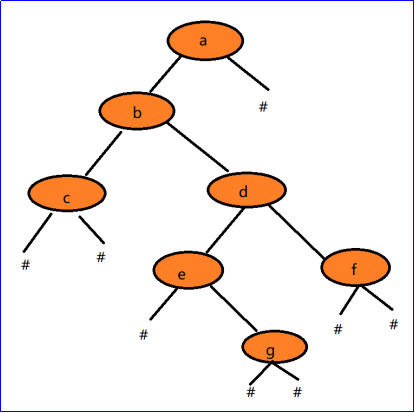
BTree CreateBT(string str,int&i)
{
if(i>=len-1)
return NULL;
if(str[i]=='#')
return NULL;
BTree bt=new BTnode;
bt->data=str[i];
bt->lchild=CreateBT(str,++i);
bt->rchild=CreateBT(str,++i);
}
层次遍历建二叉树,例如:#ABCD#EF#G##H##I //第一个#不算
BTree CreateBTree(string str,int i)
{
int len;
BTree bt;
bt=new TNode;
len=str.size();
if(i>len-1||i<=0)
{
return NULL;
}
if(str[i]=='#')return NULL;
bt->data=str[i];
bt->lchild=CreateBTree(str,2*i);
bt->rchild=CreateBTree(str,2*i+1);
return bt;
}
遍历二叉树
//先序遍历
void PreorderPrintLeaves(BinTree BT)
{
if (BT != NULL)
{
cout<<BT->Data<<" ";
PreorderPrintLeaves(BT->Left);
PreorderPrintLeaves(BT->Right);
}
}
//中序遍历
void PreorderPrintLeaves(BinTree BT)
{
if (BT != NULL)
{
PreorderPrintLeaves(BT->Left);
cout<<BT->Data<<" ";
PreorderPrintLeaves(BT->Right);
}
}
//后序遍历
void PreorderPrintLeaves(BinTree BT)
{
if (BT != NULL)
{
PreorderPrintLeaves(BT->Left);
PreorderPrintLeaves(BT->Right);
cout<<BT->Data<<" ";
}
}
线索二叉树:
引入目的:通过线索加快查找节点的前驱或后继
typedef struct node
{
int data;
int ltag,rtag;,//增加的线索标记
struct node *lchild,*rchild;//右孩子或线索指针
}
例子:
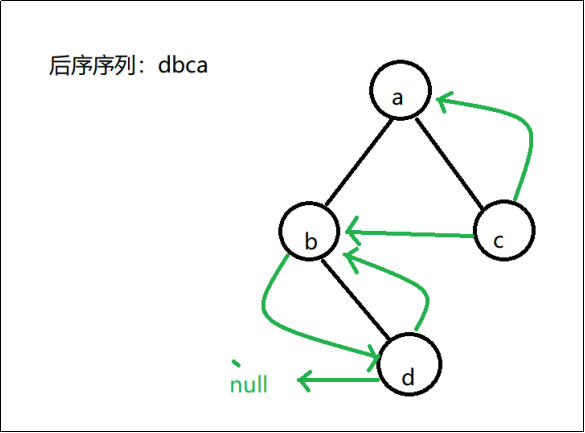
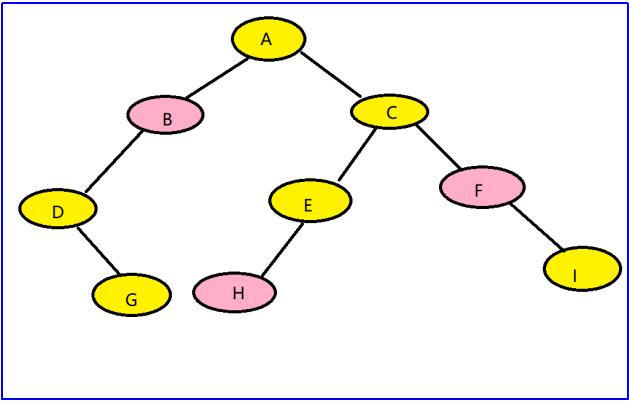
我觉得线索二叉树知道怎么画即可,如图所示,d没有前驱,所以使null,b的前驱是d,后继是c,所以就会有两条指针分别代表前驱后继。同时要注意,我画的图由于工具的限制,但是记住线索是要用虚线画的。
二叉树的应用
-
给定二叉树,求出所有叶子节点,这个比较简单
-
查找节点值为x的层次
-
int Level(BTree bt,int x,int h)//h初值置为1,这里h不能用引用 { int l; if(b==NULL) { return 0; } else if(b->data==x) { return h; } else { l=Level(b->lchild,x,h+1);//在左子树中找 if(l!=0) return l;//在左子树中未找到,再往右子树找 else { return Level(b->rchild,x,h+1); } } } -
判断两棵二叉树是否相似
-
bool Like(BTree b1,BTree b2) { bool like1,like2; if(b1==NULL&&b2==NULL) { return true; } else if(b1==NULL||b2==NULL) { return false; } else { like1=Like(b1->lchild,b2->lchild); like2=Like(b1->rchild,b2->rchild); return (like1&&like2); } }
1.2.2树
树结构->每个节点有n>=0个子节点
性质:
- 节点数=所有节点度之和+1
- 具有n个节点的2次数的最小高度log2n+1
存储结构:
双亲存储结构:
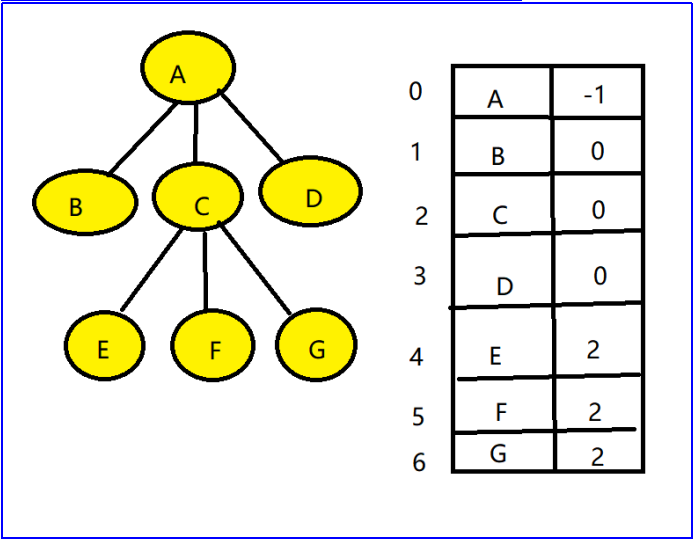
typedef struct
{
int data;
int parent;//存放双亲的位置
}PTree[MaxSize];
应用:并查集->判断是否是同一朋友圈,并且输出朋友圈的最大人数
#include<iostream>
using namespace std;
int Hf[60000];
int Find(int root)
{
if (Hf[root] < 0)return root;//值小于0表示它是一个根节点,值表示的是这个圈子里的人数,返回下标
else //说明有上一个节点
{
return Hf[root] = Find(Hf[root]);
}
}
void Union(int root1, int root2)
{
root1 = Find(root1);//返回的是根节点的下标
root2 = Find(root2);//根节点的下标
if (root1 == root2)return;
Hf[root1] += Hf[root2];//合并圈子
Hf[root2] = root1;
}
int main()
{
int n, m,num;
int root1, root2;
cin >> n >> m;//学生个数和俱乐部的个数
for (int i = 1; i <= n; i++)
{
Hf[i] = -1;//一开始进行初始化
}
for (int i = 1; i <= m; i++)
{
cin >> num;
for (int i = 1; i <= num; i++)
{
if (i == 1)
{
cin >> root1;//在里面选择一个根节点
}
else
{
cin >> root2;
Union(root1, root2);//合并
}
}
}
int max = 0;
for (int i = 1; i <= n; i++)
{
if (Hf[i] < max)max = Hf[i];
}
cout << -max;
}
思路:
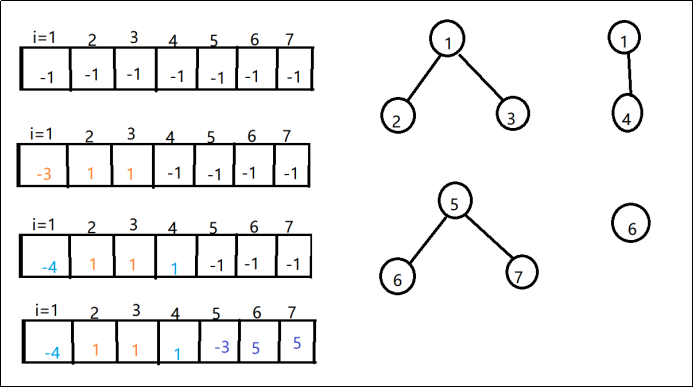
在Hf[]数组里,下标表示人,而值有两重含义,如果值为负数,则说明这个下标是这个朋友圈的根节点,负数的绝对值,则表示这个圈子有多少人,如果值为正数,表示的是当前下标对应的父亲节点是谁,我们可以通过值(父亲节点)当作下标,找父亲的父亲,知道父亲的值为负数,表示是根节点,再把原来下标的值置为根节点的下标。
孩子兄弟链存储结构

typedef struct node
{
int data;
struct node*brother
struct node*son;
}BTnode;
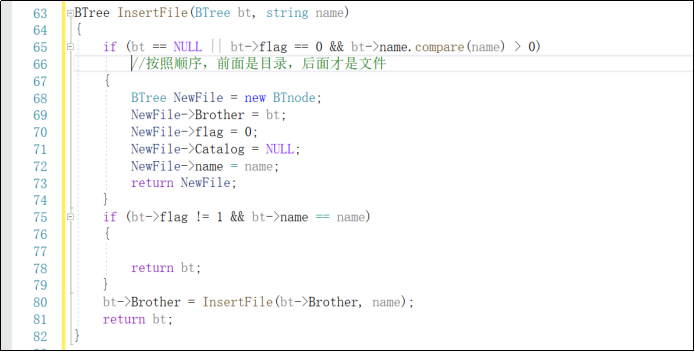
应用:目录树
//伪代码:
Typedef struct node*BTree;
Typedef struct node
{
string name;
BTree Catalog;
BTree Brother;
Bool flag;
}BTnode;
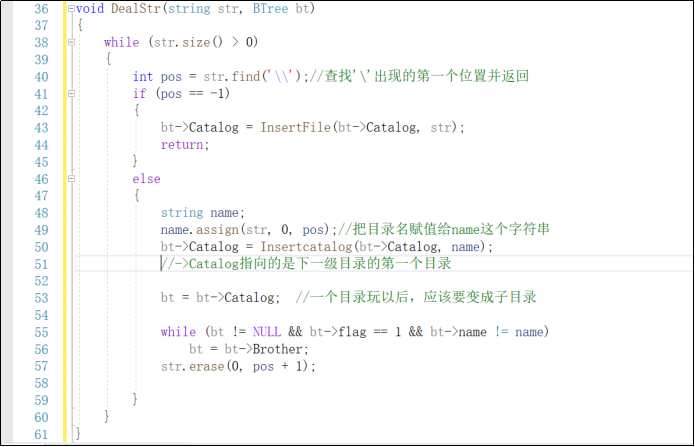
void DealStr(string str, BTree bt)
{
while(str.size()>0)
{
查找字符串中是否有’\’,并记录下位置pos
if(没有)
说明是文件,则进入InsertFile的函数
else
说明是目录,则进入Insertcatalog的函数里
bt=bt->catalog;
同时bt要跳到下一个目录的第一个子目录去,因为刚刚Insertcatalog的函数是插到bt->catalog里面去
while(bt!NULL&&bt->name!=name)
bt=bt->Brother;//找到刚刚插入的目录,然后下一步开始建立它的子目录
str.erase(0, pos + 1);把刚插进去的目录从字符串中去掉
}
}




1.2.3哈夫曼树
定义:具有带权路劲长度最小的二叉树称为哈夫曼树
特点:n1=0,n=2n0-1
哈夫曼树的建立:
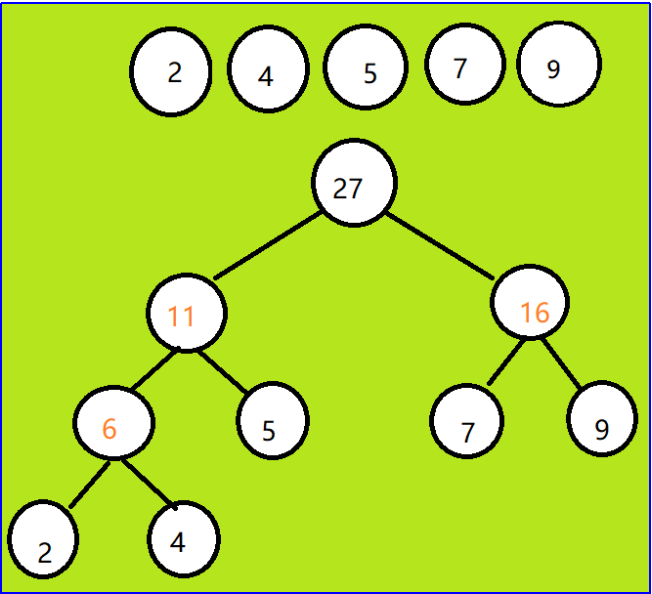
每次都把权值最小和次小的根节点选出来,然后把他们之和的根节点放入到集合之中,原来的最小和次小从集合之中去掉,重复操作,直到只剩一个节点
WPL值->带权路径长度
上图中的带权路径长度是:WPL=(2+4) * 3+5 *2+(7+9) *2=60
同时,我们可以观察到那些后来由叶子节点之和组成的新节点,算一下这些东西的和,是6+11+16+27=60,发现很巧,他们是相等的,其实,可以发现,所有的哈夫曼树都有这个规律。
伪代码:
for i=0 to i<n
将节点push进优先级栈
While(q.size()>1)
{
While(j<2)
{
将两个节点pop出栈,算出节点之和node
j++;
}
将node再push入栈
Weigth+=node;
node重新置为0;
}


1.2.4谈谈你对树的认识及感悟
树是一个一对多的结构,所以,它的表现形式就更加多样,我们可以借助顺序表来进行层次建树,对于复杂一点的问题,我们可以通过孩子兄弟法建立起一层层的目录,通过哈夫曼树,求最小一组人消费,通过并查集,可以使我们找到具有相同关系的一组人,所以,对于一个复杂的数据结构,它的存在意义,是为了解决更复杂的问题,我们现在学习的东西越来越多,遇到的问题也越来越难,对于知识点的融合,对于不同问题如何寻找最优结构,使我们永远要追求的。
2.1 题目: 2N皇后


代码:



2.1.1 设计思路:
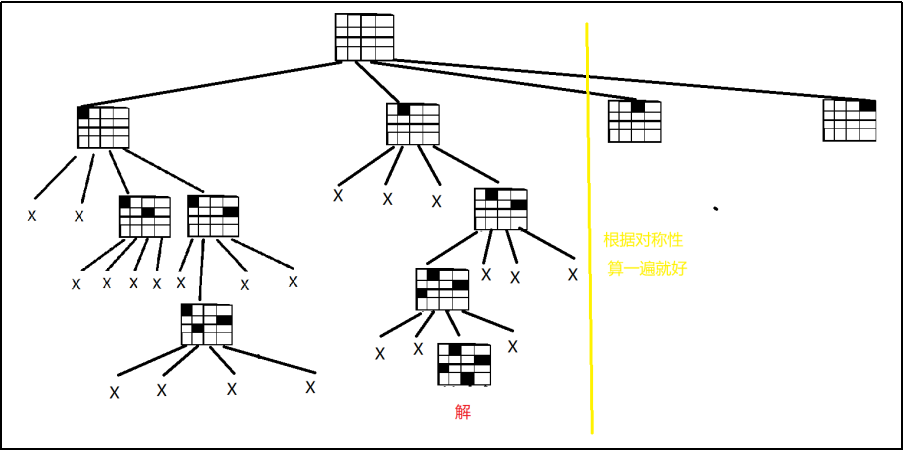
-
首先,理解一下题目的意思,要求相同颜色的皇后不能同行同列或者是同一条斜线。
-
本题的约束条件:
-
同行的不会有,判断同一列是否有相同皇后,因为是从上到下进行,此处引进b[],w[]数组进行判断是否在同一列
-
判断是否同一条斜线, 用这个条件进行判断abs(x - i) == abs(y - b[i])
-
先把黑皇后安排好在,再去安排白皇后
动态图
这里面,有一个使用递归进行回溯的过程,可以更好的理解递归的过程。
2.1.2伪代码
定义a[i][j]存储格子的状态,status[i][j]里置一记录黑皇后的位置
b[],w[]记录每一条路径,用来判断可行不可行
int main()
{
输入n
for循环初始化a[][],status[][],b[],a[];
DFSBlack(0);
}
int isLegal(int *b,int y,int x)
{
fori=0 to i<x
if(b[i]==x||abs(y-i)==abs(x-b[i]))
{
return 0;
}
return 1;
}
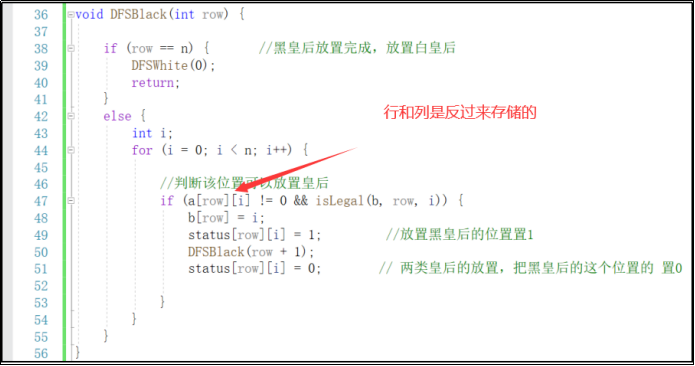
void DFSBlack(int row)
{
if(列与n)
{
说明此时已经有一种黑皇后可行方案
去安排白皇后
DFSWhite(0);
return;
}
else
{
for i=0 to i=n-1
{
if(a[row][i]地图里是可以放置棋子的,isLegal(b,row,i)判断不在同一条斜线和同列)
{
判断成功,则记录下当前行满足条件的列所对应的行b[row]=i
status[row][i]置为1表示放置黑皇后
BFSBlack(row+1);递归进行下一列的判断
status[row][i]=0;是失败进行恢复
}
}
}
}
白皇后的判断和黑皇后的判断差不多,多了额外的条件
2.1.3 运行结果
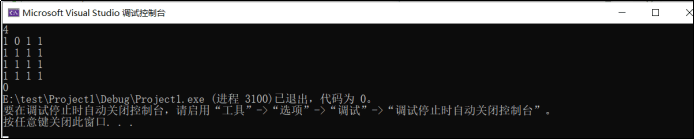

2.1.4 分析该题目解题优势及难点
这里面其实认真说起来,比较重要的一个递归就是黑皇后白皇后本身的递归过程,这段代码,我觉得比较巧妙的地方是这个数据定义,其实感觉到现在,写代码对我来说,难的更多是起点,如果去定义一个我满意的数据结构,顺序表?链表?这道题虽然不会让我联想到链表,但是代码里定义的那几个数组,我却不一定会想到,并且,其实我觉得对我来说,无论什么题,对重复的题目学会应用递归,就是一个很神奇的东西,因为我其实不太会用递归,而学会递归,去处理重复的东西,真的可以省很多事情。
2.2 题目:横向打印二叉树(遍历树+模拟)



代码:


2.2.1 设计思路
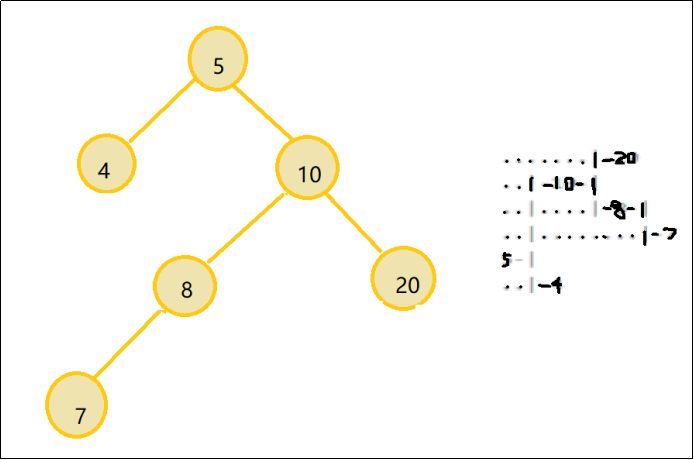
- 本题是打印一个排序二叉树,左根右按照由小到大排序,按题意来说,由上到下的数值依次减小,所以采取的是RDL遍历
- 这题比较麻烦的是如何打印,由题意可知,对于什么时候输出|或者.的判断条件为该结点父结点的父结点存在且该父节点的左孩子的左孩子或者右孩子的右孩子为当前结点时,“|”位置替换为“.”其他情况下“|”的位置不变。那么本题是通过字符串p实现这个功能
- 代码思路:
- 1.建树,同时,将数字转成字符串的形式,后面比较容易处理
- 2.对树进行RDL遍历,对于当前节点前的字符串进行处理,看是输出|还是.
2.2.2伪代码
int main()
{
while(cin>>x)
{
ins(node,x,-1);
建立二叉树
}
对字符串s,p,root进行初始化
dfs(node,s,p);
进入遍历函数
}
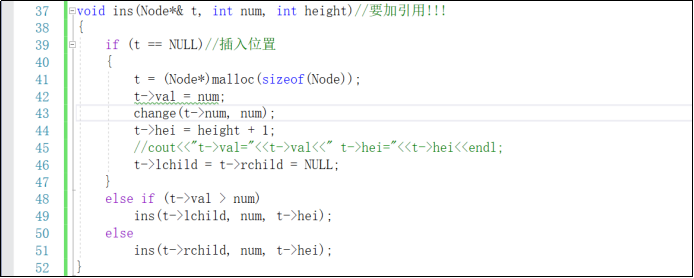
void ins(Node*& t,int num,int height)
{
if(如果t是空)
{
为t new一个空间
并且将num转化成字符串
然后对结构体里的成员进行赋值
将左右孩子置为NULL
}
else if(num比根节点要小)
{
ins(t->lchild,num.t->hei)
则插入到左子树
}
else
{
插入到右子树
}
}
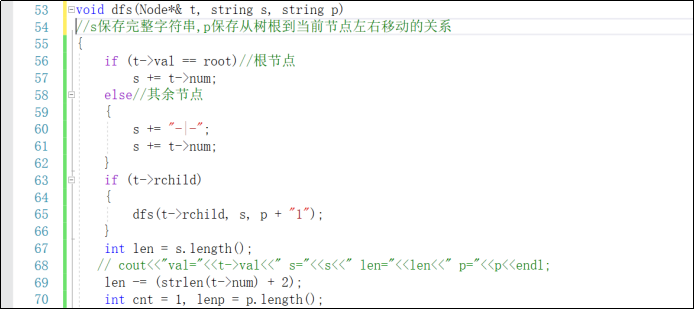
void dfs(Node*&t,string s,string p)
{//s保存的是完整的字符串,p保存的是从树根到当前节点左右移动的关系,0表示左孩子,是右孩子
if(t->val==root)
{
如果是根节点,
直接给s加上根节点的值
}
else
{
不是的根节点,要先给s赋值上”-|-“
因为后面就是对”|“”-“这两个字符进行处理,转换成”.“
再赋值上节点的值
}
if(t节点有右孩子)
{
则递归处理右孩子
dfs(t->rchild,s,p+"1");右孩子p赋上1
}
算出字符串s的长度len,要减去当前节点值加上-|的长度
cnt=1;
for i=0 to i=len
{
if(s[i]是数字或'-')
{
输出.
}
else if(str[i]是'|'')
{
if(父节点的左孩子的左孩子或者右孩子的右孩子为当前结点)
在p里面表示为p[cnt]=p[cnt-1]=0或1
{
输出.
}
else
{
输出|
}
cnt++;
}
}
if(t是根节点)
{
输出值
}
else
{
输出|-加值
}
if(当前节点存在孩子节点)
{
输出-|
}
输出回车
if(当前节点存在左孩子)
{
递归处理dfs(t->lchild,s,p+"0");
}
}
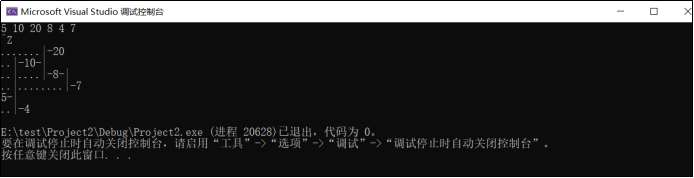
2.2.3运行结果
2.2.4分析该题目解题优势及难点
-
这道题,我觉得首先要会的就是建树,学会边输入边建树,并且按照左边小,右边大的规则进行建树
-
第二,我觉得最难的是对题意的理解,题目并没有和我们明确的说明规则,这时候,我们只好根据样例进行判断,判断什么时候需要用.或者|,并且,这时在参数表里有两个字符串,s字符串进行存储从根节点到当前节点的一条路径,让后从i=0开始对这个字符串进行处理,把里面|在满足条件的情况下输出.,那一开始能想到对这个s字符串的如何赋值,也是一个难点,为什么对非根节点要先赋上-|-,而p字符串是由01组成的字符串,由它巧妙的对|进行一个助攻。
2.3 题目:监控二叉树
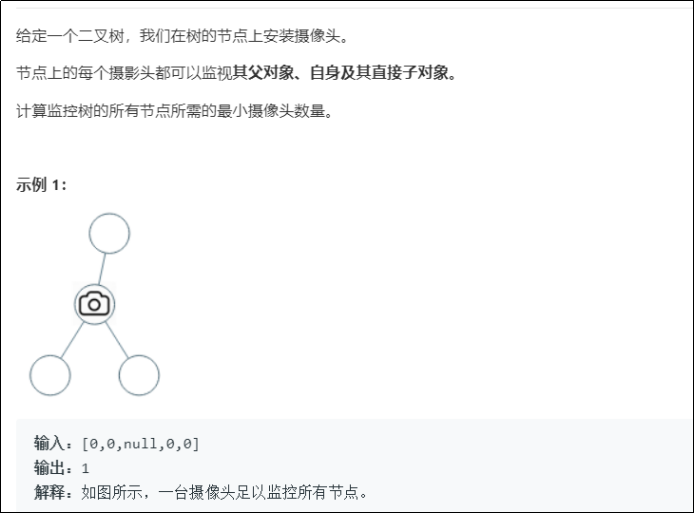

代码:
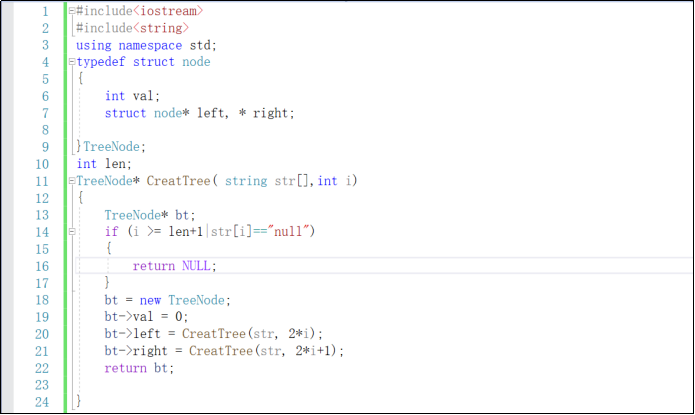
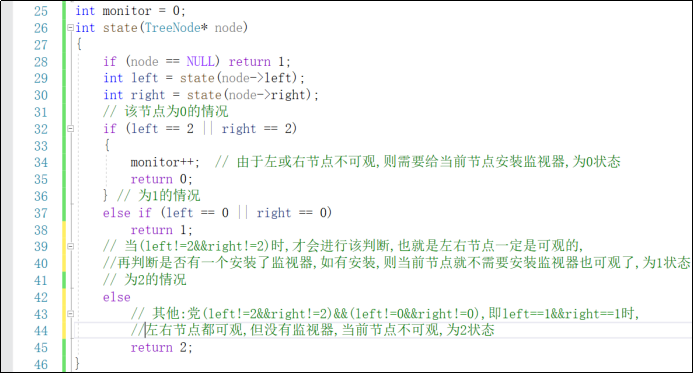
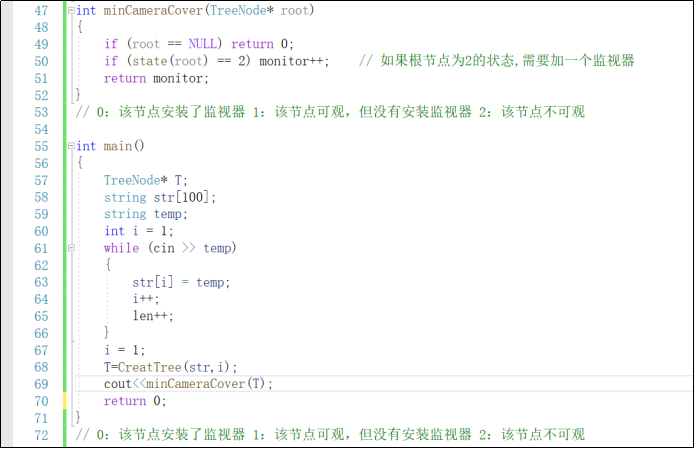
2.3.1 设计思路
首先,这道题要对叶子节点的状态进行分析:
-
1.节点如果是NULL,则可以选择父亲的父亲进行监控,即叶子节点的父亲节点
-
2.左右孩子不为空,且左右孩子没有被监控,则在当前节点设置监控。
-
3.左右孩子有一个已经设置了监控,则当前节点不需要设置监控,可以让当前节点的父亲节点设置监控
-
1.所以我们将监控设置到叶子节点的父节点,然后移除已经被覆盖的节点,所以需要从下往上判断当前节点的状态
-
2.重复1,知道所有节点都被移除
2.3.2伪代码
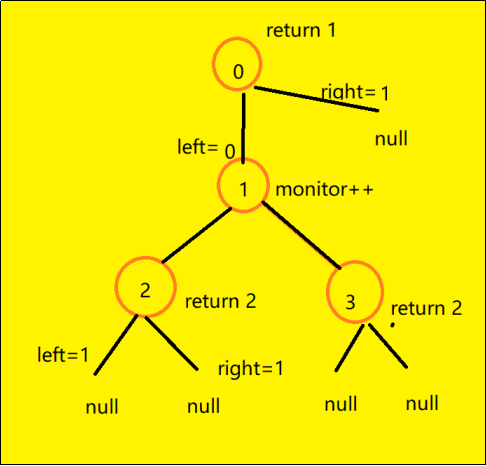
//0:该节点装有监控
//1.该节点可以监控,但是没有安装监控
//2该节点不可以监控
int monitor=0;
int state(TreeNode*node)
{
if(树为空)return 1;
int left=state(node->left);
int right=state(node->right);
//这两步是从下往上回溯的
if(当前节点为叶子节点的父节点,即left||right==2)
{
monitor++;
return 0;
}
else if(当前节点的孩子节点其中已经装有监控)
{
则当前节点不用装监控
return 1;
}
else//叶子节点不用装监控
{
return 2;
}
}
int minCameraCover(TreeNode* root)
{
if(根节点是空)return 0;
if(如果根节点需要装监控)monitor++;
return monitor;
}
int main()
{
建树
进入 minCameraCover(T);
return 0;
}
2.3.3 运行结果


2.3.4 分析题目解题优势及难点
- 弄清楚对于节点而言,每个节点都有三个状态,分别是孩子节点都为空,此时,该节点是叶子节点,监控应该设置在当前节点的父亲节点,第二种是孩子节点一个为空,一个不为空(没有被监视),此时这个节点要设置监控,最后一种是孩子节点有一个有设置监控,则当前节点不用设置监控,所以,三个状态分别用0,1,2来表示,这是一个优势,通过回溯的值,来决定三个节点之间的关系。
- 这道题,解题思路也很重要,从下往上进行回溯,回溯的过程中,对于已经访问过的节点则可以选择忽略,而对于上面还没访问过的,也可以忽略,那么始终都是三个节点之间的关系,就很巧妙
2.4.1题目:打家劫舍l
有n个房子,排成一排,已知每个房子的糖果数目,要求不能在相邻两个房子里偷糖果,这样会暴露自己,走一遍所有屋子,最多能拿多少颗糖果

代码:

2.4.1 设计思路->动态规划
遍历的时候,分两种情况,偷第一个房子的糖果,和不偷第一个房子的糖果,简而言之,就是透或不偷。
- 前者糖果数=第一个房子的糖果数加剩余房子的最大糖果数
- 后者的糖果数=除了第一个房子的其余房子可得的最大糖果数
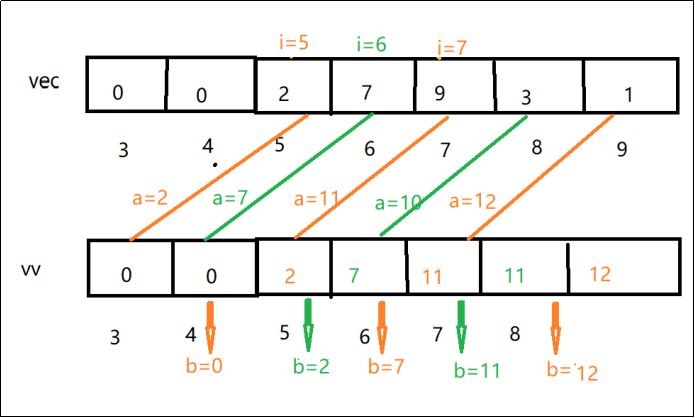
如图所示,可能画的有点复杂,直接看vec数组里,如果偷第一个房子,那么就是2,2+9,2+9+1,分别代表a=2,a=11,a=12如果不偷第一个房子,偷第二个房子,那就是7,7+3,分别代表a=7,a=10,那b的作用就是记录下到当前下标,可偷到的最大糖果数,b分别是2,7,11,12
2.4.2 伪代码
int main()
{
输入n
为vec提前申请n个空间,全部自动初始化为0
将数据存入到vec数组中,存入到n后面
int res = NiceGetCandies(vec);
}
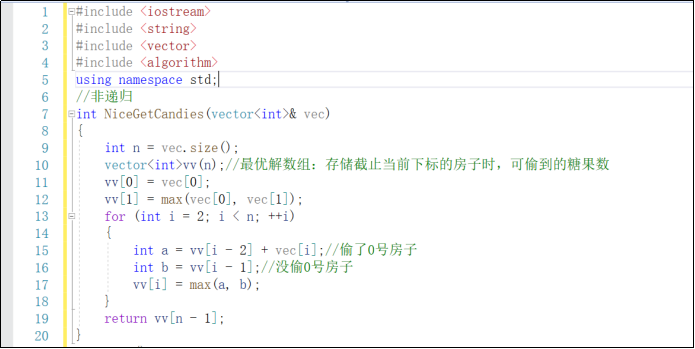
int NiceGetCandies(vector<int>& vec)
{
申请一个vec数组大小的vv数组,存储截止当前下标房子时,可得到的糖果数
初始化全部置为0
vv[0]=vec[0];
vv[1]==max(vec[0],vec[1]);
for i=2 to i=n-1
{
a=vv[i-2]+vec[i];//a存储的是是偷了0号房子能够得到的糖果数量
b=vv[i-1];//没偷0号房子得到的糖果数
vv[i]=max(a,b);//比较二种大小,多的存储进去
}
}
2.4.3 运行结果

2.4.4 分析题目解题优势及难点
这道题,其实不算很难,就算是我们不用上面的代码,我们也可以通过遍历两遍,算出偷第一个房子的糖果数,与偷第二个房子的糖果进行比较,这样思路虽然简单,但是要遍历两遍,这这道题,就只用了一遍,就可以把正确答案算出来,借助另外一个数组,并且,对于数组的初始化,也进行了一点的设计,这个思路比较灵活,我觉得值得学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号