
day03.29模块功能
re模块的其他功能
re模块当中的分组输出功能:
findall()、search()的分组功能是用小括号来表示分组区分字符。
findall()默认是分组优先展示;如果说正则表达式中如果有括号分组,那么在展示匹配结果的时候,默认只演示括号内正则表达式匹配到的内容!!!
findall()的分组展示:

# (?:) 括号前面加问号冒号>>>取消分组有限展示的机制 # eg: import re ret = re.findall('a(b)c', 'abcabcabcabc') print(ret) # ['b', 'b', 'b', 'b'] ret = re.findall('a(?:b)c', 'abcabcabcabc') print(ret) # ['abc', 'abc', 'abc', 'abc'] ret = re.findall('(a)(b)(c)', 'abcabcabcabc') print(ret) # [('a', 'b', 'c'), ('a', 'b', 'c'), ('a', 'b', 'c'), ('a', 'b', 'c')] ret = re.findall('(?P<aaa>a)(b)(c)', 'abcabcabcabc') print(ret) # [('a', 'b', 'c'), ('a', 'b', 'c'), ('a', 'b', 'c'), ('a', 'b', 'c')] print(ret.group('aaa'))
search()的分组展示:
search()可以用索引取到分组内的数据
import re ret = re.search('a(b)c', 'abcabcabcabc') # 可以通过索引的方式单独获取分组内匹配到的数据 print(ret.group()) # abc print(ret.group(0)) # abc print(ret.group(1)) # b ret = re.search('a(b)(c)', 'abcabcabcabc') print(ret.group()) # abc print(ret.group(0)) # abc print(ret.group(1)) # b 可以通过索引的方式单独获取分组内匹配到的数据 print(ret.group(2)) # c 可以通过索引的方式单独获取分组内匹配到的数据 ''' ps:针对search和match有几个分组,group方法括号内最大就可以写几;若超出最大分组,程序会处在运行等待的阶段,等待新的数据传入 '''
分组之后不同的组还可以给组起别名,用来替代不同组的数据:
import re ret = re.search('a(?P<name1>b)(?P<name2>c)', 'abcabcabcabc') print(ret.group('name1')) # b print(ret.group('name2')) # c
from collections import namedtuple
from collections import namedtuple # 1、先产生一个元组对象模板 point = namedtuple('坐标',['x','y']) # 2、创建诸多元组数据 p1 = point(1,2) p2 = point(10,8) print(p1,p2) # 坐标(x=1, y=2) 坐标(x=10, y=8) print(p1.x) # 1 print(p1.y) # 2 person = namedtuple('人物','name age gender') p1 = person('jason',18,'male') p2 = person('kevin',28,'female') print(p1,p2) # 人物(name='jason', age=18, gender='male') 人物(name='kevin', age=28, gender='female') print(p1.name,p1.age) # jason 18
card = namedtuple('扑克牌', ['花色', '点数']) c1 = card('黑桃♠', 'A') c2 = card('黑梅♣', 'K') c3 = card('红心❤', 'A') print(c1, c2, c3) print(c1.点数)
- 双端队列
队列:先进先出,默认是只有一端只能进;另外一端只能出。
双端队列:两端都可以进出。
# 双端队列
import queue q = queue.Queue(3) # 最大只能放三个元素 # 存放元素 q.put(123) q.put(321) q.put(222) q.put(444) # 如果队列满了 继续添加则原地等待 # 获取元素 print(q.get()) # 123 print(q.get()) # 321 print(q.get()) # 222 print(q.get()) # 如果队列空了,程序会显示运行中,继续获取则原地等待新的数据输入
deque是为了高效实现插入和删除的双向列表,适用于队列和栈
# 队列添加元素 from collections import deque q = deque([1, 2, 3]) print(q) q.append(444) # 右边添加元素 print(q) q.appendleft(666) # 左边添加元素 print(q) q.pop() # 右边弹出元素 q.popleft() # 左边弹出元素
- 字典的相关功能
# 正常的字典内部是无序的 d1 = dict([('name','jason'),('pwd',123),('hobby','study')]) print(d1) # {'pwd': 123, 'name': 'jason', 'hobby': 'study'} print(d1.keys()) # dict_keys(['name', 'pwd', 'hobby']) # 有序字典 from collections import OrderedDict d2 = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) print(d2) # OrderedDict([('a', 1), ('b', 2), ('c', 3)]) d2['x'] = 111 d2['y'] = 222 d2['z'] = 333 print(d2) # OrderedDict([('a', 1), ('b', 2), ('c', 3), ('x', 111), ('y', 222), ('z', 333)]) print(d2.keys()) # odict_keys(['a', 'b', 'c', 'x', 'y', 'z'])
eg:
''' 有如下值集合 [11,22,33,44,55,67,77,88,99,999] 将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中 ''' # 方式1 l1 = [11, 22, 33, 44, 55, 67, 77, 88, 99, 999] new_dict = {'k1': [], 'k2': []} for i in l1: if i > 66: new_dict['k1'].append(i) else: new_dict['k2'].append(i) print(new_dict) # {'k1': [67, 77, 88, 99, 999], 'k2': [11, 22, 33, 44, 55]} # 方式2 from collections import defaultdict values = [11, 22, 33, 44, 55, 67, 77, 88, 99, 90] my_dict = defaultdict(list) # 字典所有的值默认都是列表 {'':[],'':[]} for value in values: if value > 66: my_dict['k1'].append(value) else: my_dict['k2'].append(value)
- 计数器counter
用来统计字符串中所有字符出现的次数。
res = 'abcdeabcdabcaba' # 使用for循环 new_dict = {} for i in res: if i not in new_dict: # 字符第一次出现 应该创建一个新的键值对 new_dict[i] = 1 else: new_dict[i] += 1 print(new_dict) # {'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1} # 使用collections模块 from collections import Counter r = Counter(res) print(r) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1}) print(r.get('a')) # 可以当成字典使用
time模块
time模块的常用方法:
time.sleep(secs) # 推迟指定的时间运行,单位为秒 time.time() # 获取当前时间戳
表示时间的三种方式:
- 时间戳
距离1970年1月1日0时0分0秒至此相差的秒数 type(time.time()) # float
- 结构化时间
time.localtime() tm_year(年) 比如2011 tm_mon(月) 1 - 12 tm_mday(日) 1 - 31 tm_hour(时) 0 - 23 tm_min(分) 0 - 59 tm_sec(秒) 0 - 60 tm_wday(weekday) 0 - 6(0表示周一) tm_yday(一年中的第几天) 1 - 366 tm_isdst(是否是夏令时) 默认为0
- 格式化时间
人最容易接收的一种时间格式 eg:2000/1/21 11:11:11
time.strftime()
'%Y-%m-%d %H:%M:%S' # 2022-03-29 11:31:30 '%Y-%m-%d %X' # 2022-03-29 11:31:30 %y # 两位数的年份表示(00-99) %Y # 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
时间类型的转换
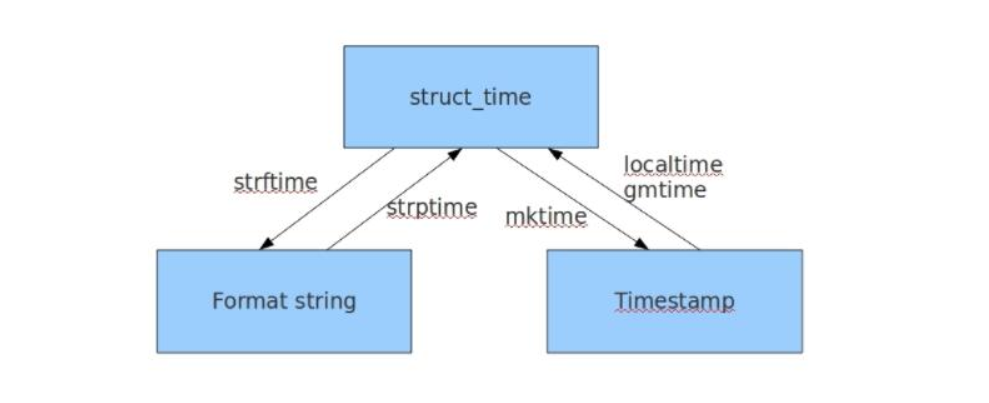
格式化时间 <==> 结构化时间 <==> 时间戳 # 时间戳<-->结构化时间 gmtime localtime # 结构化时间<-->格式化时间 strftime strptime time.strptime("2017-03-16","%Y-%m-%d") time.strptime("2017/03","%Y/%m") 前后必须一致
datetime模块
datetime的基本使用:
import datetime print(datetime.date.today()) # 2022-03-29 print(datetime.datetime.today()) # 2022-03-29 19:42:26.657556 # date 意思就是年月日 # datetime 意思就是年月日和时分秒
单个获取时间数据:
import datetime res = datetime.date.today() print(res.year) # 2022 print(res.month) # 3 print(res.day) # 29 print(res.weekday()) # 1 weekday指的是星期0-6 print(res.isoweekday()) # 2 isoweekday指的是星期1-7
获取时间差:
# 时间差 import datetime ctime = datetime.datetime.today() time_tel = datetime.timedelta(days=4) # 有很多时间选项,定时启动 print(ctime) # 22022-03-29 19:47:00.461201 print(ctime + time_tel) # 2022-04-02 19:47:00.461201 print(ctime - time_tel) # 2022-03-25 19:47:00.461201 res = ctime + time_tel print(res - ctime) # 4 days, 0:00:00 ''' 针对时间计算的公式 日期对象 = 日期对象 +/- timedelta对象 timedelta对象 = 日期对象 +/- 日期对象 '''
random模块
random模块又称随机数模块,一般用来随机产生一个一定范围的随机数值。
import random print(random.random()) # 随机产生一个0到1之间的小数 print(random.uniform(2, 4)) # 随机产生一个2到4之间的小数 print(random.randint(0, 9)) # 随机产生一个0到9之间的整数(包含0和9) print(random.randint(1, 6)) # 相当于掷骰子 l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13] random.shuffle(l) # 随机打乱一个数据集合,相当于洗牌 print(l) ll1 = ['特等奖', '张飞抱回家', '如花', '百万现金大奖', '群内配对'] print(random.choice(ll1)) # 随机抽取一个,相当于抽奖 ll2 = ['如花', 'C老师', 'R老师', 'J老师', 'M老师', '张飞', '龙龙'] print(random.sample(ll2, 2)) # 随机指定个数抽样,相当于抽样


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?