Python多线程多进程那些事儿看这篇就够了~~
自己以前也写过多线程,发现都是零零碎碎,这篇写写详细点,填一下GIL和Python多线程多进程的坑~
总结下GIL的坑和python多线程多进程分别应用场景(IO密集、计算密集)以及具体实现的代码模块。

目录
0x01 进程 and 线程 and “GIL”
0x02 python多线程&&线程锁&&threading类
0x03 python队列代码实现
0x04 python之线程池实现
0x05 python多进程并行实现
0x01 进程 and 线程 and “GIL”
进程和线程简单举例:
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程.
有些进程还不止同时干一件事,比如Word,它可以同时进行打字、拼写检查、打印等事情。在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
线程与进程的区别:
简而言之,一个程序至少有一个进程,一个进程至少有一个线程.
进程就是一个应用程序在处理机上的一次执行过程,它是一个动态的概念,而线程是进程中的一部分,进程包含多个线程在运行。
多线程可以共享全局变量,多进程不能。多线程中,所有子线程的进程号相同;多进程中,不同的子进程进程号不同。
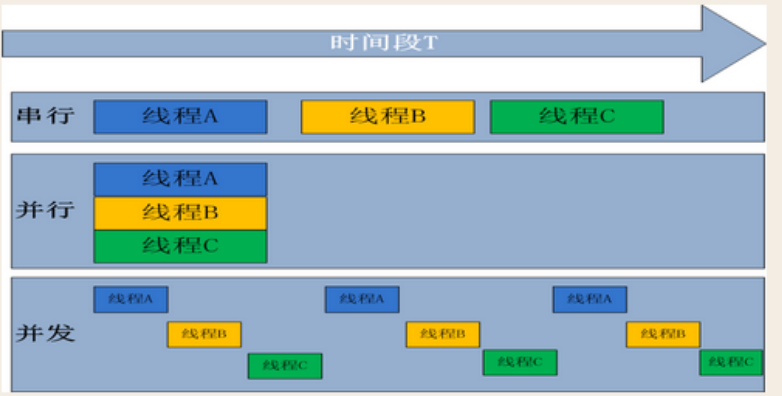
并行和并发
并行处理:是计算机系统中能同时执行两个或更多个处理的一种计算方法。并行处理可同时工作于同一程序的不同方面。并行处理的主要目的是节省大型和复杂问题的解决时间。
并发处理:指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机(CPU)上运行,但任一个时刻点上只有一个程序在处理机(CPU)上运行
同步与异步
同步:指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去。
异步:指进程不需要一直等待下去,而是继续执行下面的操作,不管其他进程的状态,当有消息返回时系统会通知进程进行处理,这样可以提高执行效率
所以为了高效率执行就有了并发编程多线程多进程概念,这里就要提一下“GIL”了~
GIL:
首先需要明确的一点是 GIL 并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
那么CPython实现中的GIL又是什么呢?GIL全称 Global Interpreter Lock
使用Python多线程的人都知道,Python中由于GIL(全局解释锁:Global Interpreter Lock)的存在,在多线程时并没有真正的进行多线程计算。
GIL说白了就是伪多线程,一个线程运行其他线程阻塞,使你的多线程代码不是同时执行,而是交替执行。

下面用代码来说明GIL的多线程是伪多线程。
单线程执行代码:
from threading import Thread import time def my_counter(): i = 0 for _ in range(100000000): i = i + 1 return True def main(): thread_array = {} start_time = time.time() for tid in range(2): t = Thread(target=my_counter) t.start() t.join() end_time = time.time() print("Total time: {}".format(end_time - start_time)) if __name__ == '__main__': main()
两个线程并发执行代码:
from threading import Thread import time def my_counter(): i = 0 for _ in range(100000000): i = i + 1 return True def main(): thread_array = {} start_time = time.time() for tid in range(2): t = Thread(target=my_counter) t.start() thread_array[tid] = t for i in range(2): thread_array[i].join() end_time = time.time() print("Total time: {}".format(end_time - start_time)) if __name__ == '__main__': main()
结果:
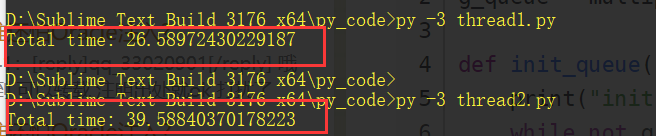
可以看到多线程反而慢了十几秒。。。。。
关于使用多线程反而慢的原因可以参考pcode数量的调度方式~~
我等菜鸟就关心 GIL的存在,是否多线程就废了?当然不是,这里提一下IO密集型和计算密集型
计算密集型
计算密集型,顾名思义就是应用需要非常多的CPU计算资源,在计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。
IO密集型
对于IO密集型的应用,涉及到网络、磁盘IO的任务都是IO密集型任务,大多消耗都是硬盘读写和网络传输的消耗。
那么GIL多线程的不足,其实是对于计算密集型的不足,这个解决可以利用多进程进行解决,而对于IO密集型的任务,我们还是可以使用多多线程进行提升效率。
0x02 python多线程&&线程锁&&threading类
Python的标准库提供了两个模块:thread和threading,thread是低级模块,threading是高级模块,对thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
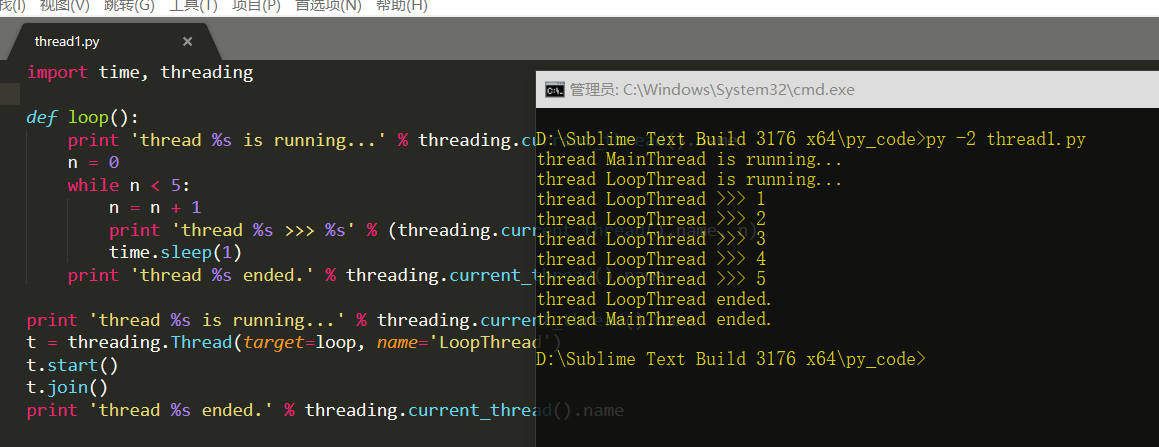
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:
import time, threading # 新线程执行的代码: def loop(): print 'thread %s is running...' % threading.current_thread().name n = 0 while n < 5: n = n + 1 print 'thread %s >>> %s' % (threading.current_thread().name, n) time.sleep(1) print 'thread %s ended.' % threading.current_thread().name print 'thread %s is running...' % threading.current_thread().name t = threading.Thread(target=loop, name='LoopThread') t.start() t.join() print 'thread %s ended.' % threading.current_thread().name
Threading模块的对象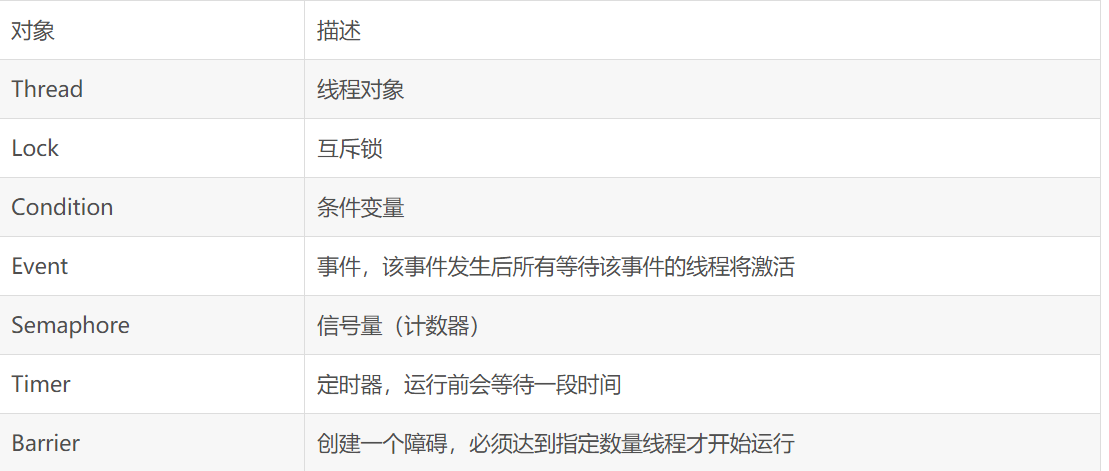
Threading模块的Thread类
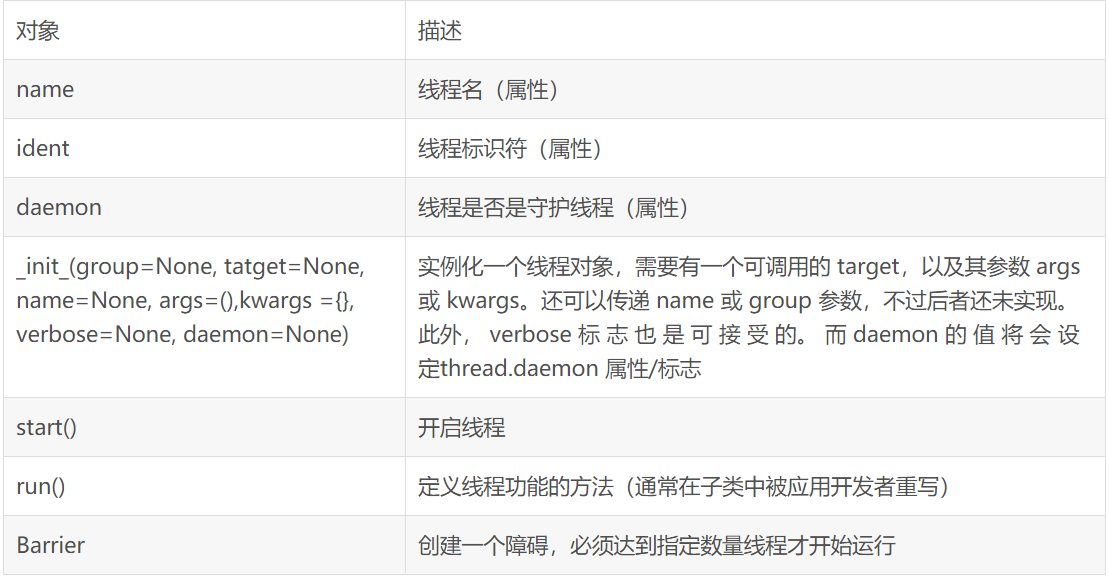
Thread类方法
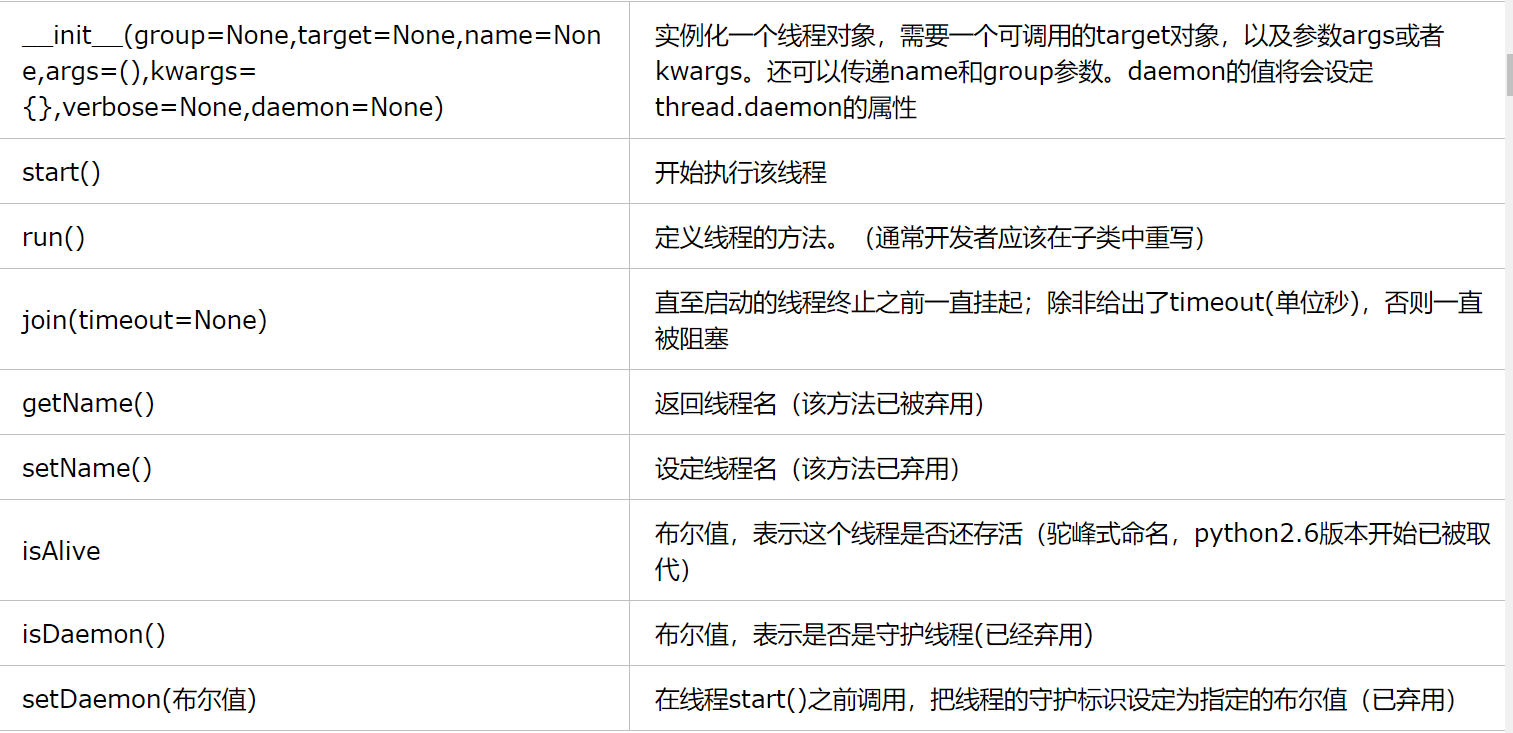
使用Thread类,可以有多种方法创建线程:
- 创建Thread类的实例,传递一个函数
- 创建Thread类的实例,传递一个可调用的类实例
- 派生Thread类的子类,并创建子类的实例
一般的,我们会采用第一种或者第三种方法。
第一种方法:创建Thread类,传递一个函数
下面的脚本中,我们先实例化Thread类,并传递一个函数(及其参数),当线程执行的时候,函数也会被执行:
import threading from time import sleep,ctime import time loops=[1,2,3,4] def loop(name,sleep_time): print('开始循环线程:'+str(name)+'at:'+str(ctime())) sleep(sleep_time) print('循环'+str(name)+'结束于:'+str(ctime())) def main(): print("程序开始于:"+str(ctime())) threads=[] nloops=range(len(loops)) for i in nloops: t=threading.Thread(target=loop,args=(i,loops[i])) #循环 实例化4个Thread类,传递函数及其参数,并将线程对象放入一个列表中 threads.append(t) for i in nloops: threads[i].start() #循环 开始线程 for i in nloops: threads[i].join() #循环 join()方法可以让主线程等待所有的线程都执行完毕。 print('任务完成于:'+str(ctime())) if __name__=='__main__': main()
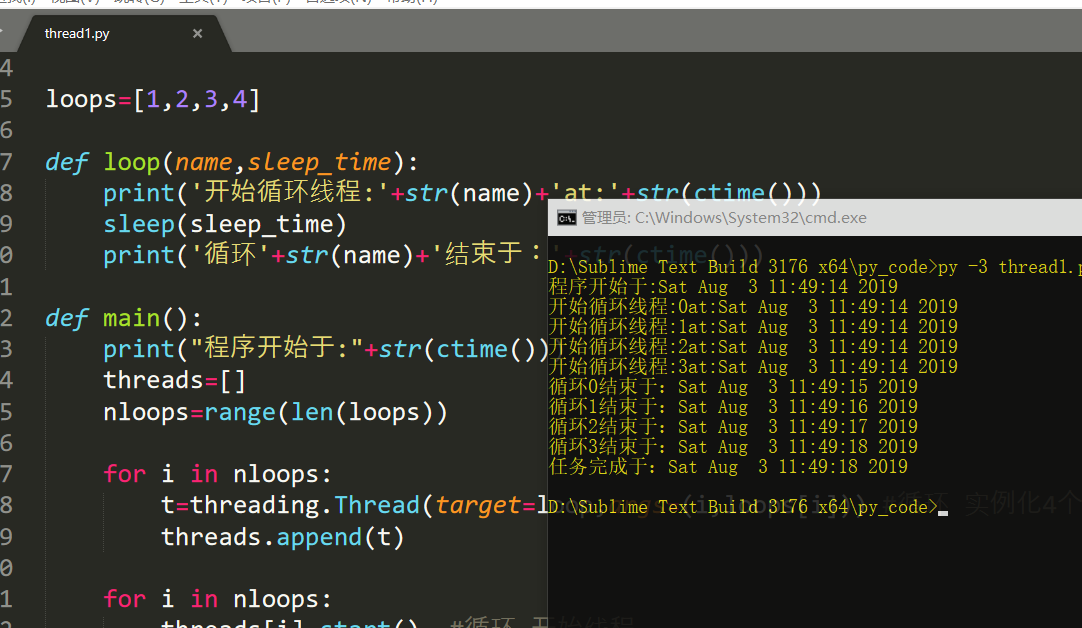
和thread模块相比,不同点在于:实现同样的效果,thread模块需要锁对象,而threading模块的Thread类不需要。
当所有的线程都分配完成之后,通过调用每个线程的start()方法再让他们开始。相比于thread模块的管理一组锁(分配、获取、释放检查锁状态)来说,threading模块的Thread类只需要为每个线程调用join()方法即可。join(timeout=None)方法将等待线程结束,或者是达到指定的timeout时间时。这种锁又称为自旋锁。
第二种方法:创建Thread类的实例,传递一个可调用的类实例
创建线程时,于传入函数类似的方法是传入一个可调用的类的实例,用于线程执行——这种方法更加接近面向对象的多线程编程。比起一个函数或者从一个函数组中选择而言,这种可调用的类包含一个执行环境,有更好的灵活性。
import threading from time import sleep,ctime loops=[1,2,3,4] class ThreadFunc(object): def __init__(self,func,args,name=''): self.name=name self.func = func self.args=args def __call__(self): self.func(*self.args) def loop(nloop,nsec): print('开始循环',nloop,'在:'+str(ctime())) sleep(nsec) print('结束循环',nloop,'于:'+str(ctime())) def main(): print('程序开始于:'+str(ctime())) threads = [] nloops = range(len(loops)) for i in nloops: t = threading.Thread(target=ThreadFunc(loop,(i,loops[i]),loop.__name__)) #传递一个可调用类的实例 threads.append(t) for i in nloops: threads[i].start() #开始所有的线程 for i in nloops: threads[i].join() #等待所有的线程执行完毕 print('任务完成于:'+str(ctime())) if __name__=='__main__': main()
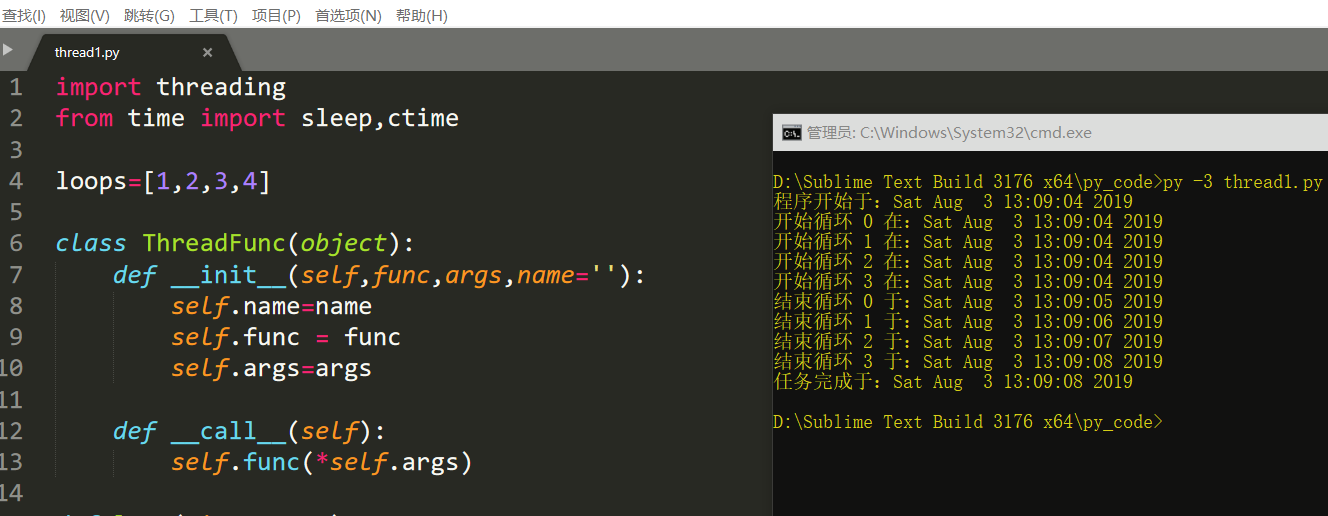
上面主要添加了ThreadFunc类,并在实例化Thread对象时,通过传参的形式同时实例化了可调用类ThreadFunc。这里同时完成了两个实例化。
第三种方法:派生Thread的子类,并创建子类的实例
import threading from time import sleep,ctime loops=[1,2,3,4] class MyThread(threading.Thread): def __init__(self,func,args,name=''): threading.Thread.__init__(self) self.name = name self.func = func self.args = args def run(self): self.func(*self.args) def loop(nloop,nsec): print('开始循环',nloop,'在:',str(ctime())) sleep(nsec) print('结束循环',nloop,'于:',str(ctime())) def main(): print('程序开始于:',str(ctime())) threads = [] nloops = range(len(loops)) for i in nloops: t = MyThread(loop,(i,loops[i]),loop.__name__) threads.append(t) for i in nloops: threads[i].start() for i in nloops: threads[i].join() print('所有的任务完成于:',str(ctime())) if __name__ =='__main__': main()
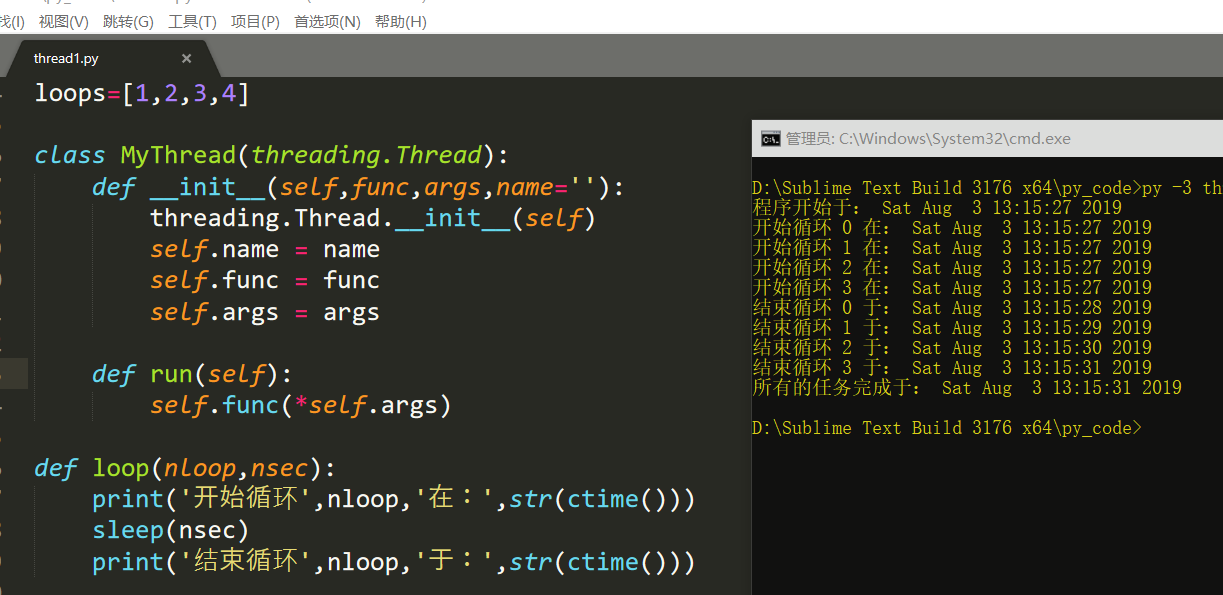
这里继承Threading父类,重写构造函数,重写run函数即可。
threading中还有以下一些属性,简单介绍一下:
Timer类,Timer(int,target=func) 和Thread类类似,只不过它在int秒过后才以target指定的函数开始线程运行
currentThread() 获得当前线程对象
activeCount() 获得当前活动的线程总个数
enumerate() 获得所有活动线程的列表
settrace(func) 设置一跟踪函数,在run执行前执行
setprofile(func) 设置一跟踪函数,在run执行完毕之后执行
这里提一下线程锁:
多线程程序涉及到一个问题,那就是当不同线程要对同一个资源进行修改或利用时会出现混乱,所以有必要引入线程锁。举个例子:
import threading from time import * class MyThread(threading.Thread): def __init__(self,counter,name): threading.Thread.__init__(self) self.counter = counter self.name = name def run(self): self.counter[0] += 1 print self.counter[0] if __name__ == '__main__': counter = [0] for i in range(1,11): t = MyThread(counter,i) t.start()
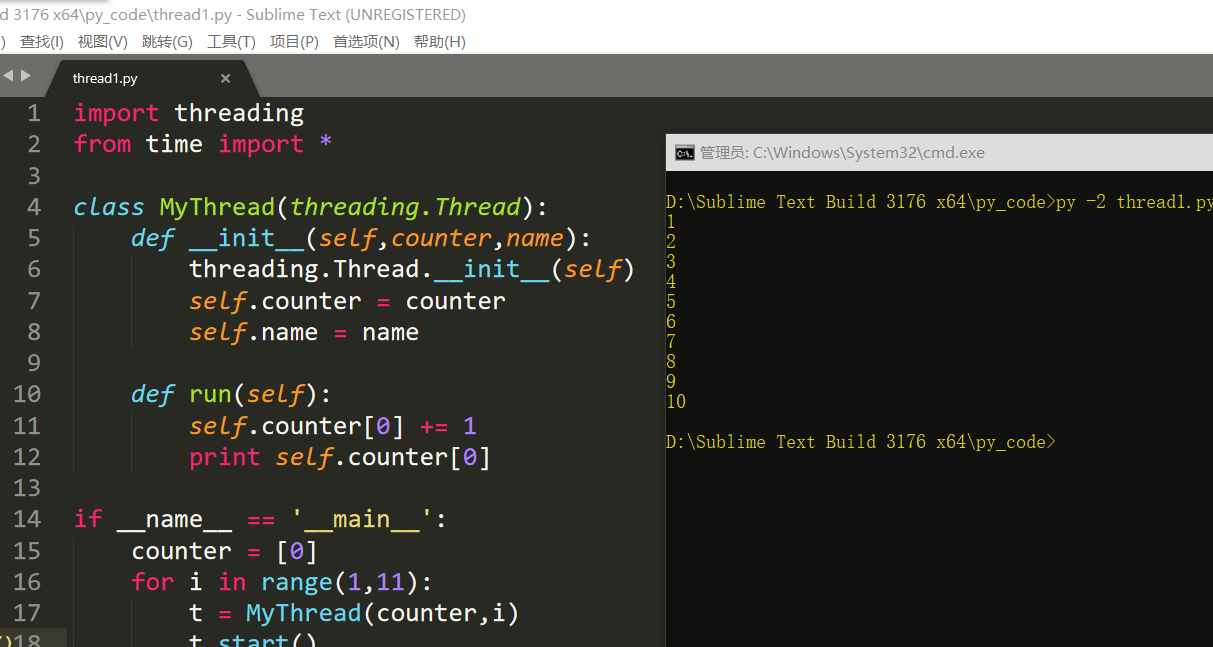
这里并发了10个线程,在没有混乱的情况下,很明显一个线程的name和经过它处理过后的counter中的数字应该相同。因为没有锁可能引发混乱,想象中,我们可能认为,当某个线程要打印counter中的数字时,别的线程对其作出了改变,从而导致打印出的counter中的数字不符合预期。实际上,这段代码的运行结果很大概率是很整齐的1\n2\n3....10。如果要解释一下,1. 虽然称并发10个线程。但是实际上线程是不可能真的在同一个时间点开始,比如在这个例子中t1启动后,要将循环进入下一轮,创建新的线程对象t2,然后再让t2启动。这段时间虽然很短很短,但是确实是存在的。而这段时间的长度,足够让t1的run中,进行自增并且打印的操作。最终,整个结果看上去似乎没什么毛病。
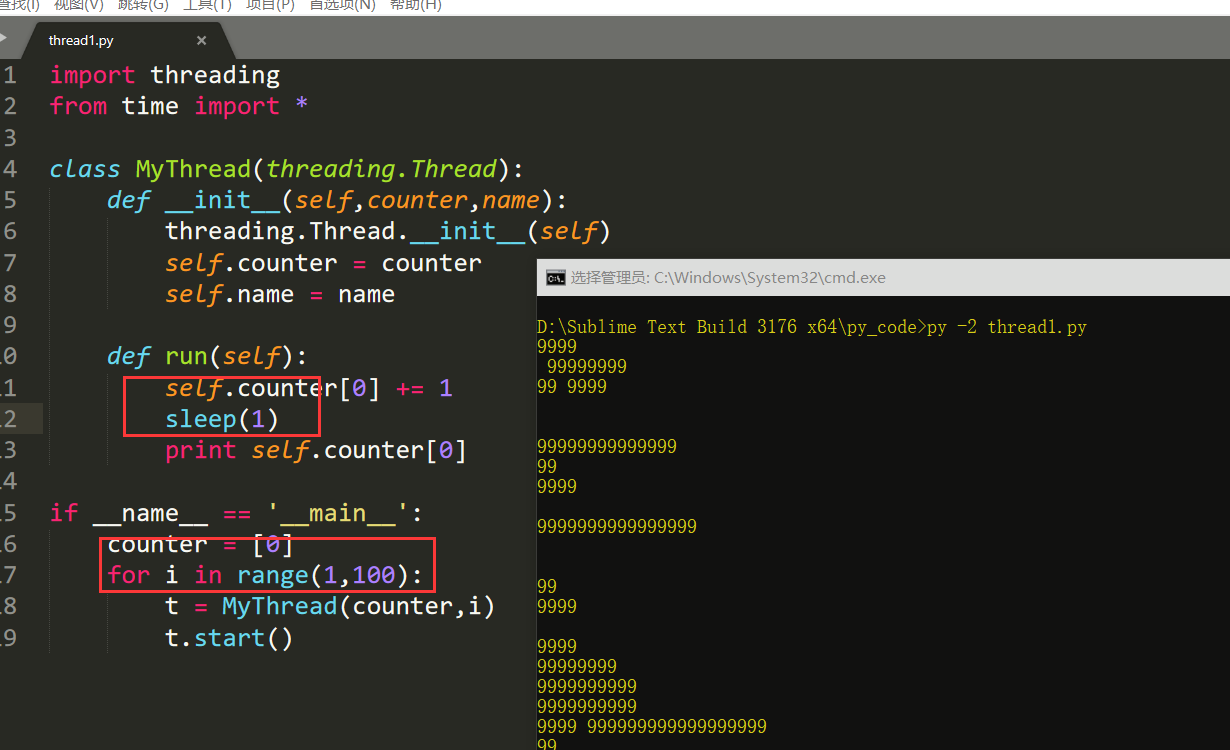
如果我们想要看到“混乱”的情况,显然两个方法。要么缩短for i in range以及创建线程对象的时间,使得线程在自增之后来不及打印时counter被第二个线程自增,这个比较困难;另一个方法就是延长自增后到打印前的这段时间。自然想到,最简单的,用time.sleep(1)睡一秒即可。此时结果可能是10\n10\n...。主要看第一行的结果。不再是1而是10了。说明在自增操作结束,打印数字之前睡的这一秒里,到第10个线程都成功自增了counter,因此即使是第一个线程,打印到的也是经过第10个线程修改的counter了。
线程锁也称互斥锁,可以弥补部分线程安全问题。(线程锁和GIL锁是不一样的东西!)
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
互斥锁有三个常用步骤
lock = threading.Lock() # 取得锁 lock.acquire() # 上锁 lock.release() # 解锁
改一下上面的代码:
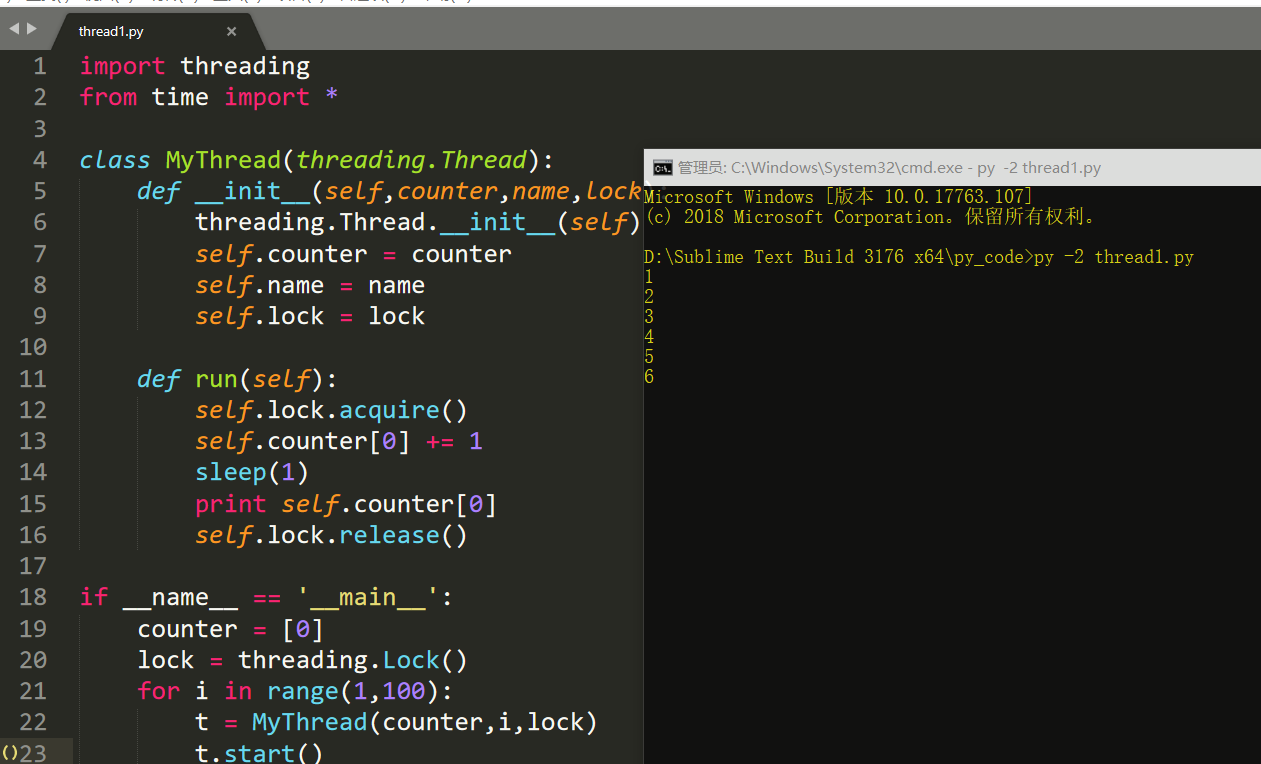
import threading from time import * class MyThread(threading.Thread): def __init__(self,counter,name,lock): threading.Thread.__init__(self) self.counter = counter self.name = name self.lock = lock def run(self): self.lock.acquire() self.counter[0] += 1 sleep(1) print self.counter[0] self.lock.release() if __name__ == '__main__': counter = [0] lock = threading.Lock() for i in range(1,100): t = MyThread(counter,i,lock) t.start()
锁也可以使用with lock来加锁
with lock:
xxxxxxxxxx
和Lock类类似的还有一个RLock类,与Lock类的区别在于RLock类锁可以嵌套地acquire和release。也就是说在同一个线程中acquire之后再acquire也不会报错,而是将锁的层级加深一层。只有当每一层锁从下到上依次都release开这个锁才算是被解开。RLock锁也称递归锁,
这里还要提一下一个更强大的锁 Condition
上面提到的threading.Lock类提供了最为简单的线程锁的功能。除了Lock和RLock以外,其实threading还补充了其他一些很多的带有锁功能的类。Condition就是其中最为强大的类之一。
acquire(): 线程锁 release(): 释放锁 wait(timeout): 线程挂起,直到收到一个notify通知或者超时(可选的,浮点数,单位是秒s)才会被唤醒继续运行。wait()必须在已获得Lock前提下才能调用,否则会触发RuntimeError。 notify(n=1): 通知其他线程,那些挂起的线程接到这个通知之后会开始运行,默认是通知一个正等待该condition的线程,最多则唤醒n个等待的线程。notify()必须在已获得Lock前提下才能调用,否则会触发RuntimeError。notify()不会主动释放Lock。 notifyAll(): 如果wait状态线程比较多,notifyAll的作用就是通知所有线程
改下上面的代码:
import threading from time import * class MyThread(threading.Thread): def __init__(self,counter,name,con): threading.Thread.__init__(self) self.counter = counter self.name = name self.con = con def run(self): self.con.acquire() self.counter[0] += 1 sleep(1) print self.counter[0] con.notify() con.wait() self.con.release() if __name__ == '__main__': counter = [0] con = threading.Condition() for i in range(1,100): t = MyThread(counter,i,con) t.start()
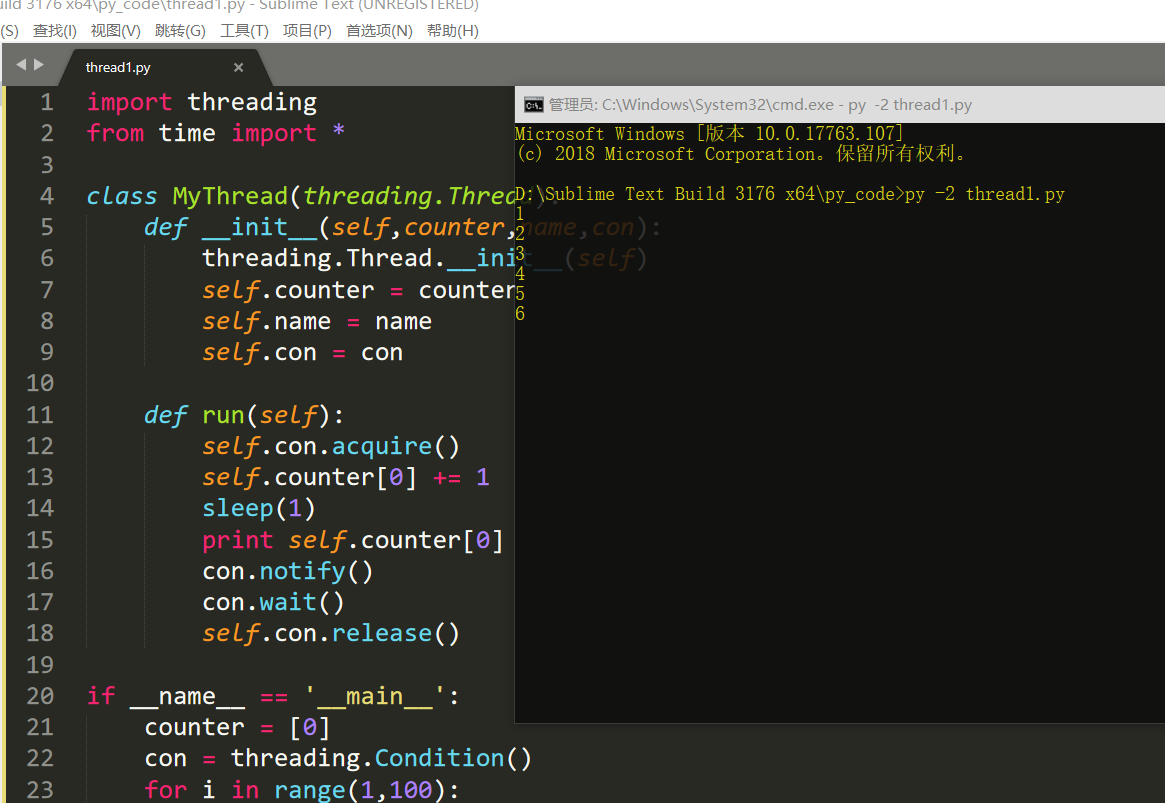
注意释放锁relase是必要的,不然会出现死锁的现象。
信号量(BoundedSemaphore类)
互斥锁同时只允许一个线程更改数据,而Semaphore信号量是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
import threading from time import * class MyThread(threading.Thread): def __init__(self,counter,name): threading.Thread.__init__(self) self.counter = counter self.name = name def run(self): semaphore.acquire() self.counter[0] += 1 sleep(1) print self.counter[0] semaphore.release() if __name__ == '__main__': counter = [0] semaphore = threading.BoundedSemaphore(5) for i in range(1,100): t = MyThread(counter,i) t.start()
事件(Event类)
python线程的事件用于主线程控制其他线程的执行,事件是一个简单的线程同步对象,其主要提供以下几个方法:
| 方法 | 注释 |
|---|---|
| clear | 将flag设置为“False” |
| set | 将flag设置为“True” |
| is_set | 判断是否设置了flag |
| wait | 会一直监听flag,如果没有检测到flag就一直处于阻塞状态 |
事件处理的机制:全局定义了一个“Flag”,当flag值为“False”,那么event.wait()就会阻塞,当flag值为“True”,那么event.wait()便不再阻塞。
#利用Event类模拟红绿灯 import threading import time event = threading.Event() def lighter(): count = 0 event.set() #初始值为绿灯 while True: if 5 < count <=10 : event.clear() # 红灯,清除标志位 print("\33[41;1mred light is on...\033[0m") elif count > 10: event.set() # 绿灯,设置标志位 count = 0 else: print("\33[42;1mgreen light is on...\033[0m") time.sleep(1) count += 1 def car(name): while True: if event.is_set(): #判断是否设置了标志位 print("[%s] running..."%name) time.sleep(1) else: print("[%s] sees red light,waiting..."%name) event.wait() print("[%s] green light is on,start going..."%name) light = threading.Thread(target=lighter,) light.start() car = threading.Thread(target=car,args=("MINI",)) car.start()
定时器(Timer类)
定时器,指定n秒后执行某操作
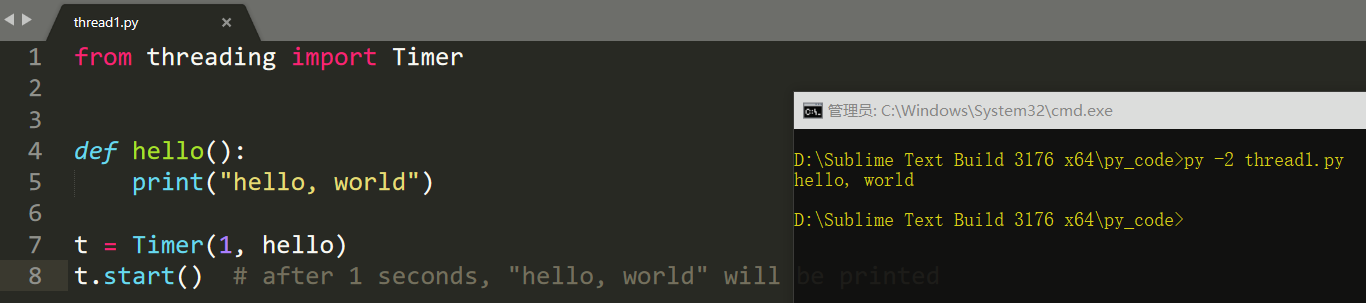
from threading import Timer def hello(): print("hello, world") t = Timer(1, hello) t.start() # after 1 seconds, "hello, world" will be printed
0x03 python队列代码实现
Queue队列
Queue用于建立和操作队列,常和threading类一起用来建立一个简单的线程队列。
队列有很多种,根据进出顺序来分类,可以分成
Queue.Queue(maxsize) FIFO(先进先出队列)
Queue.LifoQueue(maxsize) LIFO(先进后出队列)
Queue.PriorityQueue(maxsize) 为优先级越高的越先出来,对于一个队列中的所有元素组成的entries,优先队列优先返回的一个元素是sorted(list(entries))[0]。至于对于一般的数据,优先队列取什么东西作为优先度要素进行判断,官方文档给出的建议是一个tuple如(priority, data),取priority作为优先度。
如果设置的maxsize小于1,则表示队列的长度无限长
FIFO是常用的队列,其一些常用的方法有:
Queue.qsize() 返回队列大小 Queue.empty() 判断队列是否为空 Queue.full() 判断队列是否满了 Queue.get([block[,timeout]]) 从队列头删除并返回一个item,block默认为True,表示当队列为空却去get的时候会阻塞线程,等待直到有有item出现为止来get出这个item。如果是False的话表明当队列为空你却去get的时候,会引发异常。在block为True的情况下可以再设置timeout参数。表示当队列为空,get阻塞timeout指定的秒数之后还没有get到的话就引发Full异常。 Queue.put(...[,block[,timeout]]) 向队尾插入一个item,同样若block=True的话队列满时就阻塞等待有空位出来再put,block=False时引发异常。同get的timeout,put的timeout是在block为True的时候进行超时设置的参数。 Queue.task_done() 从场景上来说,处理完一个get出来的item之后,调用task_done将向队列发出一个信号,表示本任务已经完成 Queue.join() 监视所有item并阻塞主线程,直到所有item都调用了task_done之后主线程才继续向下执行。这么做的好处在于,假如一个线程开始处理最后一个任务,它从任务队列中拿走最后一个任务,此时任务队列就空了但最后那个线程还没处理完。当调用了join之后,主线程就不会因为队列空了而擅自结束,而是等待最后那个线程处理完成了。
结合threading和Queue可以构建出一个简单的生产者-消费者模型,注意,线程队列的意义并不是进一步提高运行效率,而是使线程的并发更加有组织。新线程想要加入队列开始执行,必须等一个既存的线程完成之后才可以。举个例子,比如
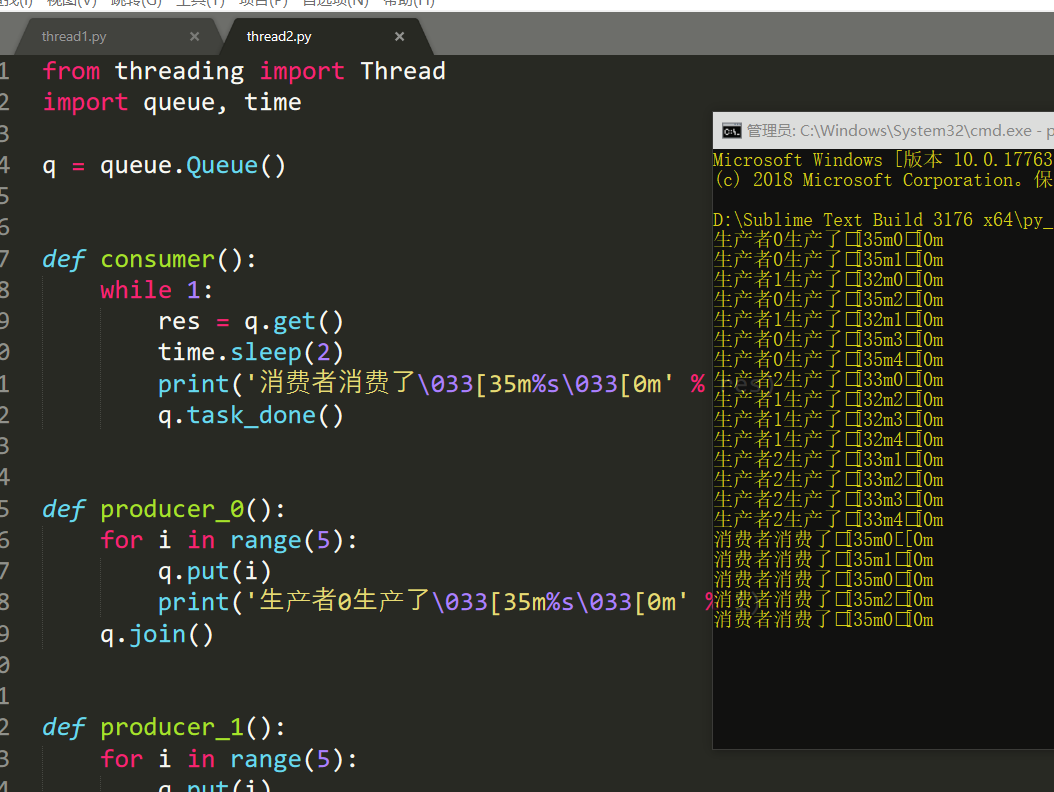
from threading import Thread import queue, time q = queue.Queue() def consumer(): while 1: res = q.get() time.sleep(2) print('消费者消费了\033[35m%s\033[0m' % res) q.task_done() def producer_0(): for i in range(5): q.put(i) print('生产者0生产了\033[35m%s\033[0m' % i) q.join() def producer_1(): for i in range(5): q.put(i) print('生产者1生产了\033[32m%s\033[0m' % i) q.join() def producer_2(): for i in range(5): q.put(i) print('生产者2生产了\033[33m%s\033[0m' % i) q.join() if __name__ == '__main__': t0 = Thread(target=producer_0, ) t1 = Thread(target=producer_1, ) t2 = Thread(target=producer_2, ) t0.start() t1.start() t2.start() consumer_t = Thread(target=consumer, ) consumer_t.daemon = True consumer_t.start() t0.join() t1.join() t2.join() print('主线程~')
0x04 python之线程池实现
线城池
对于任务数量不断增加的程序,每有一个任务就生成一个线程,最终会导致线程数量的失控。对于任务数量不端增加的程序,固定线程数量的线程池是必要的。
threadpool模块
threadpool是一个比较老的模块了,支持py2 和 py3 。
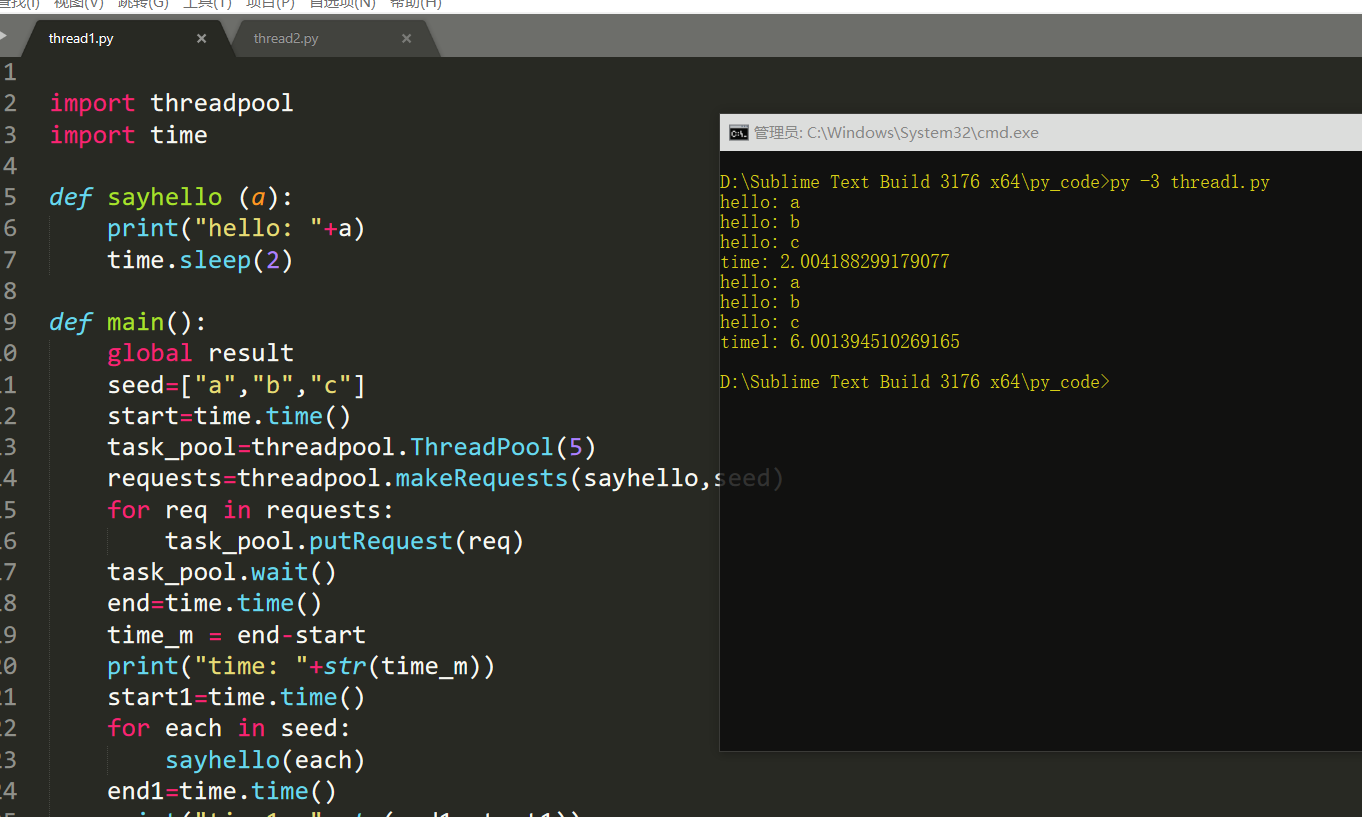
import threadpool import time def sayhello (a): print("hello: "+a) time.sleep(2) def main(): global result seed=["a","b","c"] start=time.time() task_pool=threadpool.ThreadPool(5) requests=threadpool.makeRequests(sayhello,seed) for req in requests: task_pool.putRequest(req) task_pool.wait() end=time.time() time_m = end-start print("time: "+str(time_m)) start1=time.time() for each in seed: sayhello(each) end1=time.time() print("time1: "+str(end1-start1)) if __name__ == '__main__': main(
concurrent.futures模块
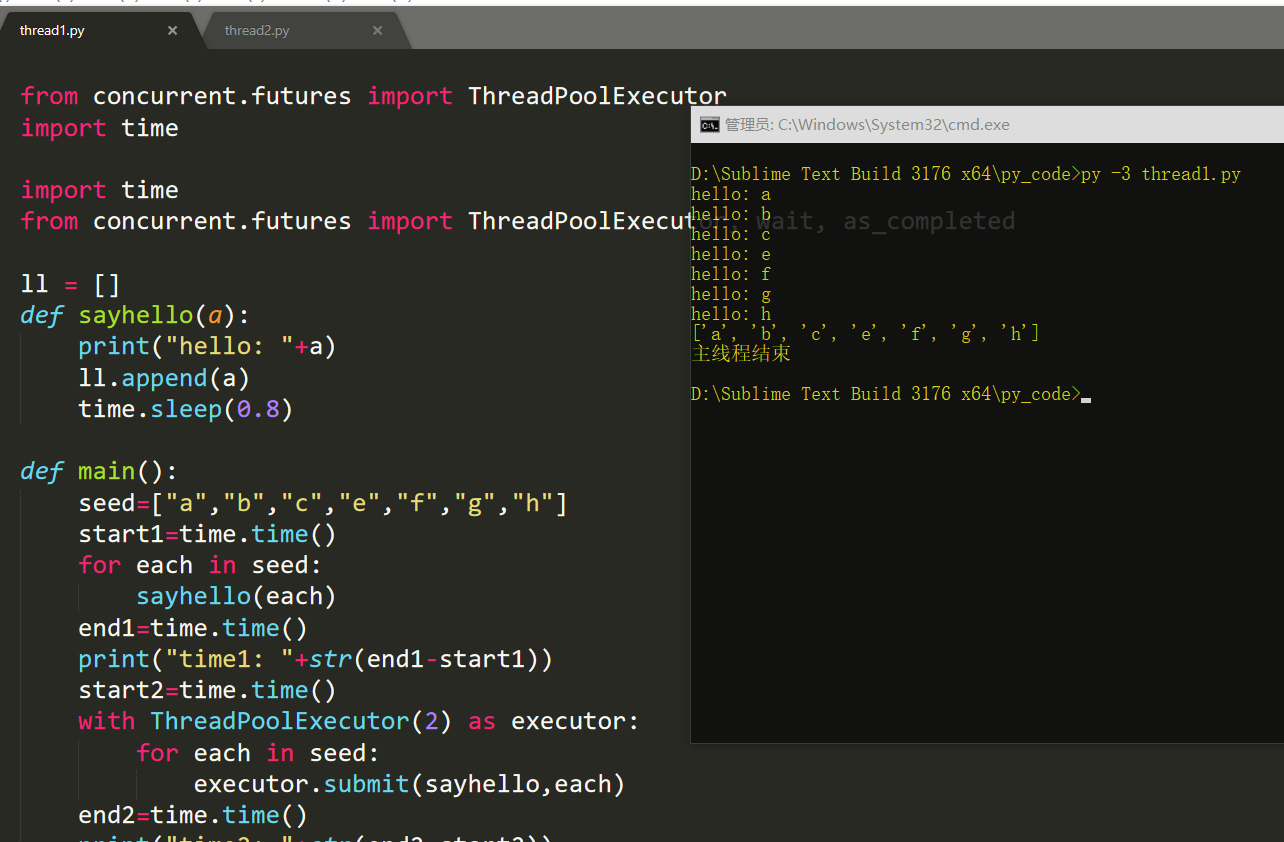
from concurrent.futures import ThreadPoolExecutor import time import time from concurrent.futures import ThreadPoolExecutor, wait, as_completed ll = [] def sayhello(a): print("hello: "+a) ll.append(a) time.sleep(0.8) def main(): seed=["a","b","c","e","f","g","h"] start1=time.time() for each in seed: sayhello(each) end1=time.time() print("time1: "+str(end1-start1)) start2=time.time() with ThreadPoolExecutor(2) as executor: for each in seed: executor.submit(sayhello,each) end2=time.time() print("time2: "+str(end2-start2)) def main2(): seed = ["a", "b", "c", "e", "f", "g", "h"] executor = ThreadPoolExecutor(max_workers=10) f_list = [] for each in seed: future = executor.submit(sayhello, each) f_list.append(future) wait(f_list) print(ll) print('主线程结束') def main3(): seed = ["a", "b", "c", "e", "f", "g", "h"] with ThreadPoolExecutor(max_workers=2) as executor: f_list = [] for each in seed: future = executor.submit(sayhello, each) f_list.append(future) wait(f_list,return_when='ALL_COMPLETED') print(ll) print('主线程结束') if __name__ == '__main__': main3()
vthread模块
import vthread pool_1 = vthread.pool(5,gqueue=1) # open a threadpool with 5 threads named 1 pool_2 = vthread.pool(2,gqueue=2) # open a threadpool with 2 threads named 2 @pool_1 def foolfunc1(num): time.sleep(1) print(f"foolstring1, test3 foolnumb1:{num}") @pool_2 def foolfunc2(num): time.sleep(1) print(f"foolstring2, test3 foolnumb2:{num}") @pool_2 def foolfunc3(num): time.sleep(1) print(f"foolstring3, test3 foolnumb3:{num}") for i in range(10): foolfunc1(i) for i in range(4): foolfunc2(i) for i in range(2): foolfunc3(i)
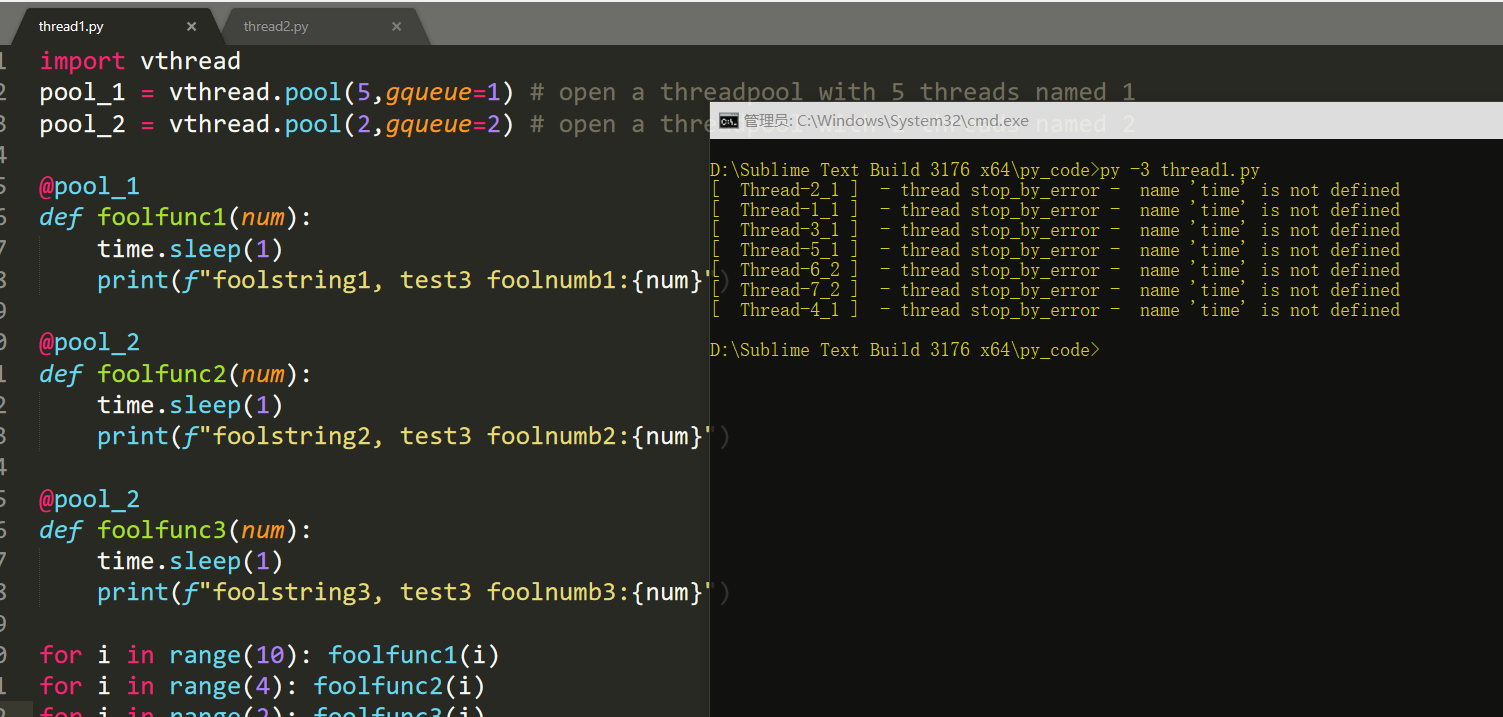
0x05 python多进程并行实现
前面也说了python多线程的弊端和GIL的内容,适合IO密集型,而如果解决计算密集型时候的多线程呢?那就是多进程。
每个进程的GIL互不影响,多进程来并行编程。
multiprocessing模块
python中多线程无法利用多核优势,如果想要充分地使用多核cpu的资源(os.cpu_count()),在python中大部分情况需要使用多进程,python提供了multiprocessing。
multiprocessing并非是python的一个模块,而是python中多进程管理的一个包
multiprocessing模块用来开启子进程,并在子进程中执行我们定制的任务(比如函数),该模块与多线程模块threading的编程接口类似。
multiprocessing模块的功能众多:支持子进程,通信和共享数据,执行不同形式的同步,提供了process、Queue、Lock等组件。
需要再次强调的一点是:与线程不同,进程没有任何共享状态,进程修改的数据,改动仅限与该进程内。
process类
创建进程的类:
Process([group [, target [, name [, args [, kwargs]]]]])
一些创建process类的参数
roup参数未使用,值始终为None target表示调用对象,即子进程要执行的任务 args表示调用对象的位置参数元组,args=(1,2,'egon',) kwargs表示调用对象的字典,kwargs={'name':'egon','age':18} name为子进程的名称
简单创建进程:
import multiprocessing def worker(num): """thread worker function""" print('Worker:', num) return if __name__ == '__main__': jobs = [] for i in range(5): p = multiprocessing.Process(target=worker, args=(i,)) jobs.append(p) p.start()
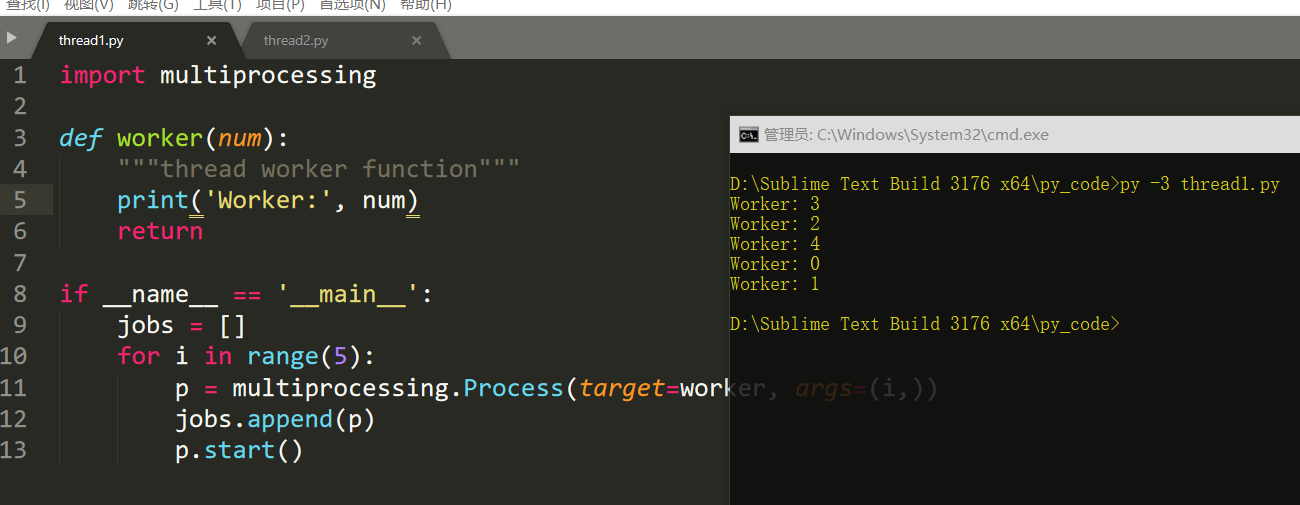
当前进程名:
multiprocessing.current_process().name
守护进程:
mutilprocess.setDaemon(True)
一些常用的函数
p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
一些属性:
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
p.name:进程的名称
p.pid:进程的pid
p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
开启子进程例子:
#开进程的方法一: import time import random from multiprocessing import Process def piao(name): print('%s piaoing' %name) time.sleep(random.randrange(1,5)) print('%s piao end' %name) p1=Process(target=piao,args=('egon',)) #必须加,号 p2=Process(target=piao,args=('alex',)) p3=Process(target=piao,args=('wupeqi',)) p4=Process(target=piao,args=('yuanhao',)) p1.start() p2.start() p3.start() p4.start() print('主线程')
join(),当某个进程fork一个子进程后,该进程必须要调用wait等待子进程结束发送的sigchld信号,对子进程进行资源回收等相关工作,否则,子进程会成为僵死进程,被init收养。所以,在multiprocessing.Process实例化一个对象之后,该对象有必要调用join方法,因为在join方法中完成了对底层wait的处理。
from multiprocessing import Process import time import random class Piao(Process): def __init__(self,name): self.name=name super().__init__() def run(self): print('%s is piaoing' %self.name) time.sleep(random.randrange(1,3)) print('%s is piao end' %self.name) p=Piao('egon') p.start() p.join(0.0001) #等待p停止,等0.0001秒就不再等了 print('开始') #join:主进程等,等待子进程结束 #join:主进程等,等待子进程结束
创建守护进程例子:
from multiprocessing import Process import time import random class Piao(Process): def __init__(self,name): self.name=name super().__init__() def run(self): print('%s is piaoing' %self.name) time.sleep(random.randrange(1,3)) print('%s is piao end' %self.name) p=Piao('egon') p.daemon=True #一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行 p.start() print('主')
完毕。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号