[WEB安全] Wfuzz 学习笔记
本篇主要是摘抄自m0nst3r 大表哥的博客系列 https://m0nst3r.me/archives/page/4/
做下笔记,不时查阅。
0x01 简介
wfuzz 是一款Python开发的Web安全测试工具,它不仅仅是一个web扫描器:wfuzz能够通过发现并利用网站弱点/漏洞的方式帮助你使网站更加安全。wfuzz的漏洞扫描功能由插件支持。
wfuzz提供了简洁的编程语言接口来处理wfuzz或Burpsuite获取到的HTTP请求和响应。这使得你能够在一个良好的上下文环境中进行手工测试或半自动化的测试,而不需要依赖web形式的扫描器。
0x02 简单指令
2.1 基础指令
一个典型的wfuzz命令只需要指定一个字典和一个要测试的URL即可,如下:
wfuzz -w ../wordlist/general/test.txt https://m0nst3r.me/FUZZ
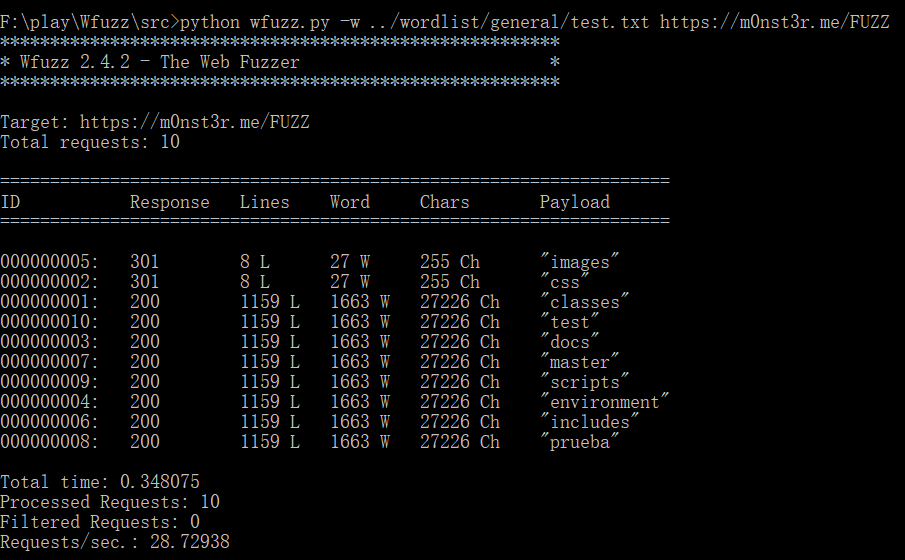
wfuzz的输出使我们能够分析web server的响应,还可根据获得的HTTP响应信息过滤出我们想要的结果,比如过滤响应码/响应长度等等。
每一行输出给我们提供了以下信息:
ID:测试时的请求序号
Response:HTTP响应吗
Lines:响应信息中的行数
Word:响应信息中的字数
Chars:响应信息中的字符数
Payload:当前使用的payload
2.2 指定payload
wfuzz -w /usr/share/wfuzz/wordlist/general/common.txt http://testphp.vulnweb.com/FUZZ
2.3 指定多个payloads
使用 -z 或 -w 参数可以同时指定多个payloads,这时相应的占位符应设置为 FUZZ, … , FUZnZ, 其中n代表了payload的序号。
比如下面的例子,我们同时暴破文件,后缀和目录:
wfuzz -w /usr/share/wfuzz/wordlist/general/common.txt -w /usr/share/wfuzz/wordlist/general/common.txt -w /usr/share/wfuzz/wordlist/general/extensions_common.txt --hc 404 http://testphp.vulnweb.com/FUZZ/FUZ2ZFUZ3Z
0x03 过滤器
wfuzz对结果进行过滤是非常重要的:
wfuzz可根据HTTP响应码和收到的响应的长度(字数,字符数或行数)来过滤。还可以用正则表达式。
过滤的方法有两种:隐藏或显示符合过滤条件的结果。
3.1 隐藏响应结果
通过--hc,--hl,--hw,--hh参数可以隐藏某些HTTP响应。隐藏无法找到的页面的响应如下:
wfuzz -w /usr/share/wfuzz/wordlist/general/common.txt --hc 404 http://testphp.vulnweb.com/FUZZ
可指定多个需要隐藏的条件,如,想要加上隐藏禁止访问的响应:
wfuzz -w /usr/share/wfuzz/wordlist/general/common.txt --hc 404,403 http://testphp.vulnweb.com/FUZZ
在当HTTP返回码相同的时候,用行数,字数,字符数来指定过滤规则比较方便进行过滤。
比如,网站一般会指定一个自定义的错误页面,返回码是200,但实际上起到了一个404页面的作用,我们称之为软404。下面是一个例子:
wfuzz -w /usr/share/wfuzz/wordlist/general/common.txt --hc 404 http://datalayer.io/FUZZ
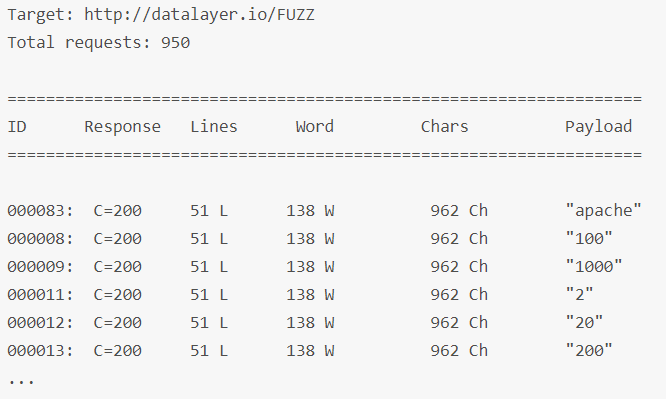
仔细观察上面的结果,我们很容易推断出所有”not found”的返回信息中都有 51个行,138个字,962个字符。
因此,我们需要改进一下我们的过滤条件(增加多个过滤条件):
wfuzz -w /usr/share/wfuzz/wordlist/general/common.txt --hc 404 --hh 962 http://datalayer.io/FUZZ
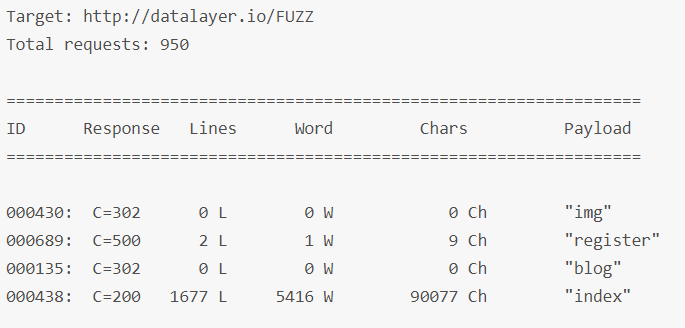
3.2 显示响应结果
显示响应结果的使用方法跟隐藏时的原理一样,只不过参数变为了:--sc(show code),--sl(show lines),--sw(show word),--sh(show chars)。
3.3 使用Baseline(基准线)
过滤器可以是某个HTTP响应的引用,这样的引用我们称为Baseline。
之前的使用--hh进行过滤的例子中,还可以使用下面的命令代替:
wfuzz -w ../wordlist/general/test.txt --hh BBB https://m0nst3r.me/FUZZ{this_is_404}
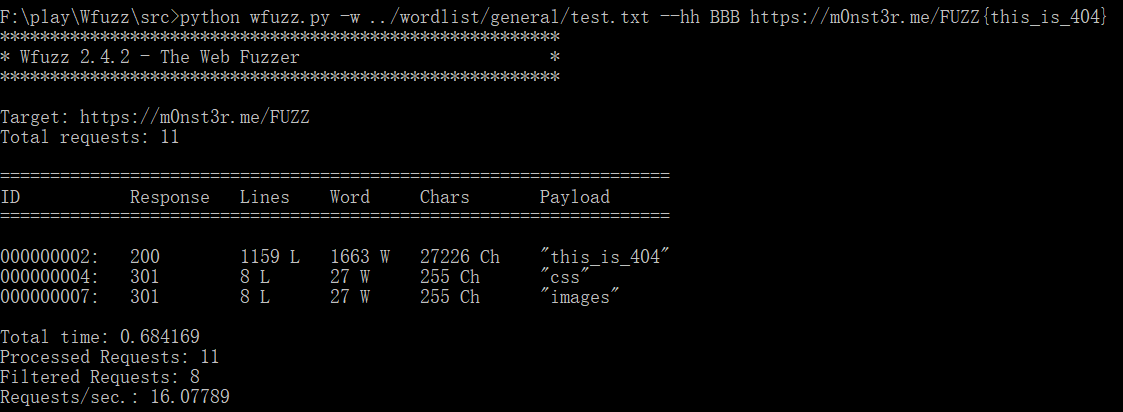
这条命令的意思应该很容易理解:首先解释下https://m0nst3r.me/FUZZ{this_is_404}的意思,这里代表wfuzz第一个请求是请求https://m0nst3r.me/this_is_404这个网址
在{ }内的值用来指定 wfuzz 第一个请求中的 FUZZ 占位符,而这第一个请求被标记为 BBB(BBB不能换成别的)基准线。其次这里使用的参数是--hh,也就是以BBB这条请求中的Chars为基准,其他请求的Chars值与BBB相同则隐藏。
3.4 使用正则表达式过滤
在命令行中,参数--ss和--hs可以接受正则表达式来对返回的结果时行过滤:
举个栗子:在这里一个网站自定义返回页面的内容中包含 Not Found,想根据这个内容进行过滤可以使用如下的命令:
wfuzz -w wordlist --hs "Not Found" http://127.0.0.1/FUZZ
得出结论使用方法:
wfuzz -w wordlist --hs 正则表达式 URL/FUZZ #隐藏
wfuzz -w wordlist --ss 正则表达式 URL/FUZZ #显示
0x04 内置工具
4.1 wfencode
这是wfuzz自带的一个加密/解密(编码/反编码)工具,目前支持内建的encoders的加/解密。
wfencode -e base64 123456
MTIzNDU2
wfencode -d base64 MTIzNDU2
123456
wfuzz的encoder列表如下:
Available encoders:
Category | Name | Summary
----------------------------------------------------------------------------------------------------------
url_safe, url | urlencode | 用`%xx`的方式替换特殊字符, 字母/数字/下划线/半角点/减号不替换
url_safe, url | double urlencode | 用`%25xx`的方式替换特殊字符, 字母/数字/下划线/半角点/减号不替换
url | uri_double_hex | 用`%25xx`的方式将所有字符进行编码
html | html_escape | 将`&`,`<`,`>`转换为HTML安全的字符
html | html_hexadecimal | 用 `&#xx;` 的方式替换所有字符
hashes | base64 | 将给定的字符串中的所有字符进行base64编码
url | doble_nibble_hex | 将所有字符以`%%dd%dd`格式进行编码
db | mssql_char | 将所有字符转换为MsSQL语法的`char(xx)`形式
url | utf8 | 将所有字符以`\u00xx` 格式进行编码
hashes | md5 | 将给定的字符串进行md5加密
default | random_upper | 将字符串中随机字符变为大写
url | first_nibble_hex | 将所有字符以`%%dd?` 格式进行编码
default | hexlify | 每个数据的单个比特转换为两个比特表示的hex表示
url | second_nibble_hex | 将所有字符以`%?%dd` 格式进行编码
url | uri_hex | 将所有字符以`%xx` 格式进行编码
default | none | 不进行任何编码
hashes | sha1 | 将字符串进行sha1加密
url | utf8_binary | 将字符串中的所有字符以 `\uxx` 形式进行编码
url | uri_triple_hex | 将所有字符以`%25%xx%xx` 格式进行编码
url | uri_unicode | 将所有字符以`%u00xx` 格式进行编码
html | html_decimal | 将所有字符以 `&#dd; ` 格式进行编码
db | oracle_char | 将所有字符转换为Oracle语法的`chr(xx)`形式
db | mysql_char | 将所有字符转换为MySQL语法的`char(xx)`形式
encoders是通过payload参数传进去的。有两种方法:
wfuzz -z file --zP fn=common.txt,encoder=md5 http://testphp.vulnweb.com/FUZZ
wfuzz -z file,common.txt,md5 http://testphp.vulnweb.com/FUZZ
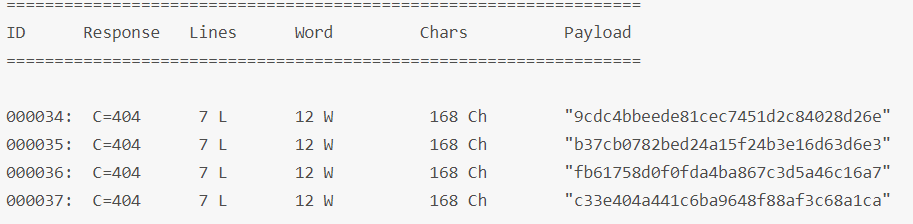
一次指定多个encoders,可以使用一个-号分隔的列表来指定,如:
wfuzz -z list,1-2-3,md5-sha1-none http://testphp.vulnweb.com/FUZZ
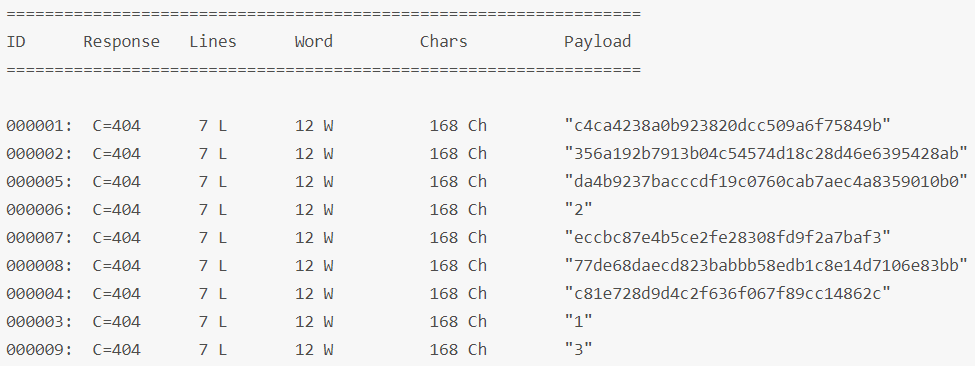
同时按顺序使用多个encoders,可以使用一个@号分隔的列表来指定,如:
wfuzz -z list,1-2-3,sha1-sha1@none http://testphp.vulnweb.com/FUZZ
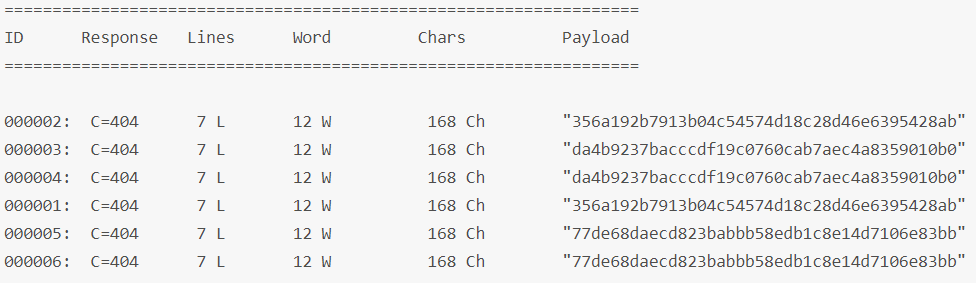
上面参数中的 sha1@none,会将 payload 先进行 sha1,然后传给 none 这个encoder。
4.2 wfpayload
wfpayload是payload生成工具:
python wfpayload.py -z range,0-10

wfuzz中可用payloads列表如下:
Available payloads:
Name | Summary
------------------------------------------------------------------------------------------------------
guitab | 从可视化的标签栏中读取请求
dirwalk | 递归获得本地某个文件夹中的文件名
file | 获取一个文件当中的每个词
autorize | 获取autorize的测试结果Returns fuzz results' from autororize.
wfuzzp | 从之前保存的wfuzz会话中获取测试结果的URL
ipnet | 获得一个指定网络的IP地址列表
bing | 获得一个使用bing API搜索的URL列表 (需要 api key).
stdin | 获得从标准输入中的条目
list | 获得一个列表中的每一个元素,列表用以 - 符号分格
hexrand | 从一个指定的范围中随机获取一个hex值
range | 获得指定范围内的每一个数值
names | 从一个以 - 分隔的列表中,获取以组合方式生成的所有usernames值
burplog | 从BurpSuite的记录中获得测试结果
permutation | 获得一个在指定charset和length时的字符组合
buffer_overflow | 获得一个包含指定个数个A的字符串.
hexrange | 获得指定范围内的每一个hex值
iprange | 获得指定IP范围内的IP地址列表
burpstate | 从BurpSuite的状态下获得测试结果
0x05 wfuzz命令中文帮助
python wfuzz.py --help
********************************************************
* Wfuzz 2.4.2 - The Web Fuzzer *
* *
* Version up to 1.4c coded by: *
* Christian Martorella (cmartorella@edge-security.com) *
* Carlos del ojo (deepbit@gmail.com) *
* *
* Version 1.4d to 2.4.2 coded by: *
* Xavier Mendez (xmendez@edge-security.com) *
********************************************************
Usage: wfuzz [options] -z payload,params <url>
FUZZ, ..., FUZnZ payload占位符,wfuzz会用指定的payload代替相应的占位符,n代表数字.
FUZZ{baseline_value} FUZZ 会被 baseline_value替换,并将此作为测试过程中第一个请求来测试,可用来作为过滤的一个基础。
Options:
-h/--help : 帮助文档
--help : 高级帮助文档
--version : Wfuzz详细版本信息
-e <type> : 显示可用的encoders/payloads/iterators/printers/scripts列表
--recipe <filename> : 从文件中读取参数
--dump-recipe <filename> : 打印当前的参数并保存成文档
--oF <filename> : 将测试结果保存到文件,这些结果可被wfuzz payload 处理
-c : 彩色化输出
-v : 详细输出
-f filename,printer : 将结果以printer的方式保存到filename (默认为raw printer).
-o printer : 输出特定printer的输出结果
--interact : (测试功能) 如果启用,所有的按键将会被捕获,这使得你能够与程序交互
--dry-run : 打印测试结果,而并不发送HTTP请求
--prev : 打印之前的HTTP请求(仅当使用payloads来生成测试结果时使用)
-p addr : 使用代理,格式 ip:port:type. 可设置多个代理,type可取的值为SOCKS4,SOCKS5 or HTTP(默认)
-t N : 指定连接的并发数,默认为10
-s N : 指定请求的间隔时间,默认为0
-R depth : 递归路径探测,depth指定最大递归数量
-L,--follow : 跟随HTTP重定向
-Z : 扫描模式 (连接错误将被忽视).
--req-delay N : 设置发送请求允许的最大时间,默认为 90,单位为秒.
--conn-delay N : 设置连接等待的最大时间,默认为 90,单位为秒.
-A : 是 --script=default -v -c 的简写
--script= : 与 --script=default 等价
--script=<plugins> : 进行脚本扫描, <plugins> 是一个以逗号分开的插件或插件分类列表
--script-help=<plugins> : 显示脚本的帮助
--script-args n1=v1,... : 给脚本传递参数. ie. --script-args grep.regex="<A href=\"(.*?)\">"
-u url : 指定请求的URL
-m iterator : 指定一个处理payloads的迭代器 (默认为product)
-z payload : 为每一个占位符指定一个payload,格式为 name[,parameter][,encoder].
编码可以是一个列表, 如 md5-sha1. 还可以串联起来, 如. md5@sha1.
还可使用编码各类名,如 url
使用help作为payload来显示payload的详细帮助信息,还可使用--slice进行过滤
--zP <params> : 给指定的payload设置参数。必须跟在 -z 或-w 参数后面
--slice <filter> : 以指定的表达式过滤payload的信息,必须跟在-z 参数后面
-w wordlist : 指定一个wordlist文件,等同于 -z file,wordlist
-V alltype : 暴力测试所有GET/POST参数,无需指定占位符
-X method : 指定一个发送请求的HTTP方法,如HEAD或FUZZ
-b cookie : 指定请求的cookie参数,可指定多个cookie
-d postdata : 设置用于测试的POST data (ex: "id=FUZZ&catalogue=1")
-H header : 设置用于测试请求的HEADER (ex:"Cookie:id=1312321&user=FUZZ"). 可指定多个HEADER.
--basic/ntlm/digest auth : 格式为 "user:pass" or "FUZZ:FUZZ" or "domain\FUZ2Z:FUZZ"
--hc/hl/hw/hh N[,N]+ : 以指定的返回码/行数/字数/字符数作为判断条件隐藏返回结果 (用 BBB 来接收 baseline)
--sc/sl/sw/sh N[,N]+ : 以指定的返回码/行数/字数/字符数作为判断条件显示返回结果 (用 BBB 来接收 baseline)
--ss/hs regex : 显示或隐藏返回结果中符合指定正则表达式的返回结果
--filter <filter> : 显示或隐藏符合指定filter表达式的返回结果 (用 BBB 来接收 baseline)
--prefilter <filter> : 用指定的filter表达式在测试之前过滤某些测试条目
0x06 Wfuzz常用指令
6.1 URL中的参数
通过在URL中在?后面设置FUZZ占位符,我们就可以使用wfuzz来测试URL传入的参数:
wfuzz -z range,0-10 --hl 97 http://testphp.vulnweb.com/listproducts.php?cat=FUZZ
6.2 POST请求
如果想使用wfuzz测试form-encoded的数据,比如 HTML表单那样的,只需要传入-d参数即可:
wfuzz -w wordlist -d "uname=FUZZ&pass=FUZZ" --hc 302 http://testphp.vulnweb.com/userinfo.php
6.3 Cookies
在测试请求中加入自己设置的cookies,可以使用-b参数指定,多个cookies使用多次。
wfuzz -w wordlist -b cookie=value1 -b cookie2=value2 http://testphp.vulnweb.com/FUZZ
以上命令可生成如下的HTTP请求:
GET /attach HTTP/1.1
Host: testphp.vulnweb.com
Accept: */*
Content-Type: application/x-www-form-urlencoded
Cookie: cookie=value1; cookie2=value2
User-Agent: Wfuzz/2.2
Connection: close
探测cookie字段的话,可以使用下面的命令:
wfuzz -w wordlist -b cookie=FUZZ http://testphp.vulnweb.com/
6.4 自定义请求头
使用-H参数来指定HTTP请求的请求头,多次指定多次使用。
wfuzz -w wordlist -H "myheader: headervalue" -H "myheader2: headervalue2" http://testphp.vulnweb.com/FUZZ
生成的HTTP请求如下:
GET /agent HTTP/1.1
Host: testphp.vulnweb.com
Accept: */*
Myheader2: headervalue2
Myheader: headervalue
Content-Type: application/x-www-form-urlencoded
User-Agent: Wfuzz/2.2
Connection: close
我们还可以修改存在的请求头,比如修改User-Agent头:
wfuzz -w wordlist -H "myheader: headervalue" -H "User-Agent: Googlebot-News" http://testphp.vulnweb.com/FUZZ
生成的HTTP请求如下:
GET /asp HTTP/1.1
Host: testphp.vulnweb.com
Accept: */*
Myheader: headervalue
Content-Type: application/x-www-form-urlencoded
User-Agent: Googlebot-News
Connection: close
Headers也可以被测试:
wfuzz -w wordlist -H "User-Agent: FUZZ" http://testphp.vulnweb.com/
6.5 探测HTTP请求方法
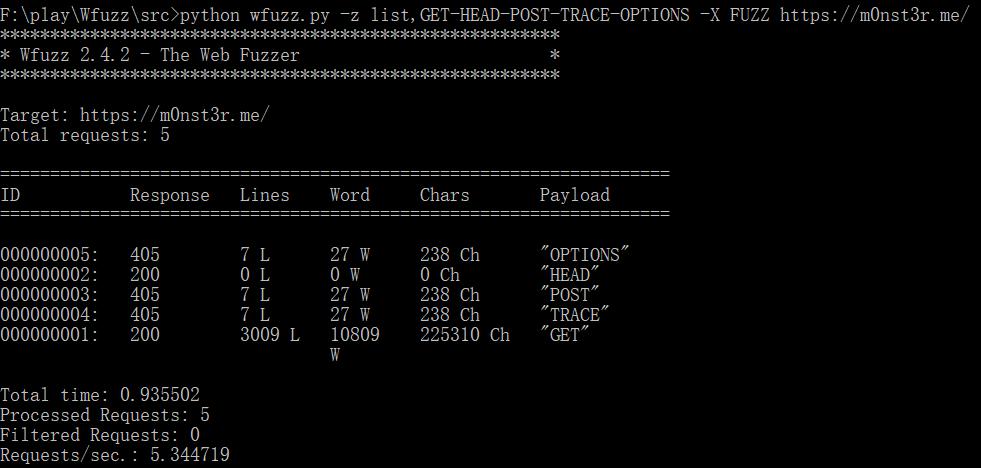
HTTP请求方法的测试可通过指定-X参数指定:
wfuzz -z list,GET-HEAD-POST-TRACE-OPTIONS -X FUZZ http://testphp.vulnweb.com/
6.6 使用代理
如果在测试时想要使用代理的话,只需要传入-p参数即可:
wfuzz -w common.txt -p localhost:8080 http://testphp.vulnweb.com/FUZZ
默认情况下,指定的代理是HTTP Basic类型的,如果想用其他类型的代理,可通过指定类型来使用:
wfuzz -w common.txt -p localhost:2222:SOCKS5 http://testphp.vulnweb.com/FUZZ
多个代理可使用多个-p参数同时指定:
wfuzz -w common.txt -p localhost:8080 -p localhost:9090 http://testphp.vulnweb.com/FUZZ
这样每次请求都会选取不同的代理进行。
6.7 递归测试
使用-R参数可以指定一个payload被递归的深度。例如,暴破目录时,我们想使用相同的payload对已发现的目录进行测试,可以使用如下命令:
wfuzz -z list,"web\-sec-admin-CVS-cgi\-bin" -R 2 https://m0nst3r.me/FUZZ
倘若目录中存在-的话,注意要用/进行转义哦~

6.8 测试速度与效率
根据对目标的影响和自身的承受能力及带宽,wfuzz提供了一些参数可以用来调节HTTP请求引擎。
- 使用-t参数可以增加或减少同时发送HTTP请求的数量。
- 使用-s参数可以调节每次发送HTTP的时间间隔。
6.9 输出到文件
wfuzz通过printers插件来将结果以不同格式保存到文档中,printers一共有如下几种格式:
raw | `Raw` output format
json | Results in `json` format
csv | `CSV` printer ftw
magictree | Prints results in `magictree` format
html | Prints results in `html` format
使用-f参数,指定值的格式为输出文件位置,输出格式。
举个栗子:将结果以 html 格式输出到 test2.html 中:
wfuzz -f test2.html,html -w ../wordlist/general/test.txt https://m0nst3r.me/FUZZ

直接使用不同格式在命令行输出的话,可使用下面的命令:
wfuzz -o json -w ../wordlist/general/test.txt https://m0nst3r.me/FUZZ
0x07 wfuzz的配置文件
wfuzz的全局配置文件位于~/.wfuzz/wfuzz.ini
[kbase]
#这里配置忽略的后缀,用 - 号分隔
discovery.blacklist = .svg-.css-.js-.jpg-.gif-.png-.jpeg-.mov-.avi-.flv-.ico
[connection]
concurrent = 50 #并发数
conn_delay = 90 #连接间隔
req_delay = 90 #请求间隔
retries = 3 #重试次数
user-agent = Mozilla/5.0 (X11; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0 #UA,默认为Wfuzz/版本
[general]
default_printer = raw #默认输出格式
cancel_on_plugin_except = 1 #插件出错则退出
concurrent_plugins = 3 #最多同时指定的插件数量
lookup_dirs = /usr/share/wfuzz/wordlist,. #查找字典的目录,若让wfuzz自动查找字典,则在命令行中只指定字典名字即可
encode_space = 1 #编码空格
[plugins]
bing_apikey = #设置bing API在key

 浙公网安备 33010602011771号
浙公网安备 33010602011771号