Data Structure第五次作业讲解
Data Structure第五次作业讲解
写给读者的话(务必阅读)
期中以来,有不少同学向我反应代码写的慢、正确率不高等问题。由于OS已经爆炸闲的没事干 因此我决定将自己原来写的代码重构重构,并整理成博客附上整个思路的讲解。首先,我必须申明,博客所写的东西,是供想提升自己代码水平,理清写码思路的同学用的。我希望同学们能够明白:作为一个考试分数占 80% 的学科,抄袭他人代码完成作业不是白赚了那 20% 的分数,而是失去了一次良好的练兵的机会(从本次开始,文章中给出的代码均已提交评测,抄袭需谨慎)。其次,个人所写代码只是提供一个写码、思考问题的思路,并不代表题目的唯一解法,更不代表最优解法没有提交到课程网站上测试,只在本地通过测试数据,甚至可能有bug噢。我希望我的代码能够起到抛砖引玉的作用,能够让同学对课上内容有更深刻的理解,写代码时能够有更多更好的想法。最后,我希望同学们在完成作业的同时,能够对自己的代码进行复杂度的分析。数据结构的使用,往往离不开对性能的约束,因此,掌握复杂度的分析也是这门课程重要的一环。
关于代码风格
本文中所有的代码风格皆采取 OO 的标准,同时作者也希望同学们能够以这种标准约束自己,这样也会方便助教 debug。简单来说,大致约束如下:
1、符号后带空格。
2、大括号不换行。
3、if、while、for 等括号两端应该带空格,并且一定要用大括号括起来。
4、一行不要写过多字符(不超过60),较长的判断可以换行处理。
5、缩进为 4 个空格,不同层次间要有合适的缩进。
6、一行只声明一个变量,只执行一个语句。
关于使用到的工具
采取了dhy大佬的意见,决定新添加这个栏目,对本次代码中使用到的基础的一些数据结构或是函数进行一些简单的讲解,便于大家的使用和理解。
1、快速读入
inline int read() { //快速读入,可以放在自己的缺省源里面
int x = 0; //数字位
int f = 1; //符号位
char ch = getchar(); //读入第一个字符
while (!isdigit(ch)) { //不是数字
if (ch == '-') { //特判负号
f = -1;
}
ch = getchar();
}
while (isdigit(ch)) { //读入连续数字
x = (x << 3) + (x << 1) + ch - '0'; // x * 10 == (x << 3) + (x << 1)
ch = getchar();
}
return x * f;
}
快速读入是比较好用的一种读入的写法,我这里的实现是通过循环读入直到得到下一个数字,在具体的题目中也可以根据自己的需要对循环的条件和结束条件做更改来读入字符串等。(由于只涉及到简单循环,这里不作更深入的讲解)。切忌不经思考和理解就使用,容易出现读入死循环等问题。
2、链式前向星
在解决需要建边(如:树、图)相关的问题时,比较方便的一种数据结构。写完后发现这次的作业并不会用到,可能会留到第七次作业再讲。
第一题:树叶节点遍历(树-基础题)
题目描述
【问题描述】
从标准输入中输入一组整数,在输入过程中按照左子结点值小于根结点值、右子结点值大于等于根结点值的方式构造一棵二叉查找树,然后从左至右输出所有树中叶结点的值及高度(根结点的高度为1)。例如,若按照以下顺序输入一组整数:50、38、30、64、58、40、10、73、70、50、60、100、35,则生成下面的二叉查找树:
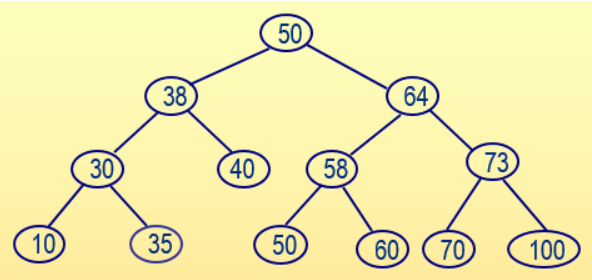
从左到右的叶子结点包括:10、35、40、50、60、70、100,叶结点40的高度为3,其它叶结点的高度都为4。
【输入形式】
先从标准输入读取整数的个数,然后从下一行开始输入各个整数,整数之间以一个空格分隔。
【输出形式】
按照从左到右的顺序分行输出叶结点的值及高度,值和高度之间以一个空格分隔。
【样例输入】
13
50 38 30 64 58 40 10 73 70 50 60 100 35
【样例输出】
10 4
35 4
40 3
50 4
60 4
70 4
100 4
【样例说明】
按照从左到右的顺序输出叶结点(即没有子树的结点)的值和高度,每行输出一个。
题目大意
按照题目所给的要求建一颗排序二叉树。
题目思路
我们构造一个存储权值、左右儿子信息的结构体来存储这颗排序二叉树即可。
代码实现
#include<stdio.h>
#include<ctype.h>
#define maxn 1000005
inline int read() { //快速读入,可以放在自己的缺省源里面
int x = 0; //数字位
int f = 1; //符号位
char ch = getchar(); //读入第一个字符
while (!isdigit(ch)) { //不是数字
if (ch == '-') { //特判负号
f = -1;
}
ch = getchar();
}
while (isdigit(ch)) { //读入连续数字
x = (x << 3) + (x << 1) + ch - '0'; // x * 10 == (x << 3) + (x << 1)
ch = getchar();
}
return x * f;
}
typedef struct tree {
int son[2]; //存储儿子,0代表左儿子,1代表右儿子。
int val;//存储权值
} Tree;
Tree tr[maxn];
int root;
int cnt;
void ins(int* rt, int val) {
if (!(*rt)) {//不存在结点,可以新建一个存下当前值
*rt = ++cnt; //分配一个新的编号为 cnt + 1 的结点
tr[*rt].val = val;
return;
}
ins(&tr[*rt].son[tr[*rt].val <= val], val);
//当前结点存在,按照排序二叉树的约束继续尝试插入
//显然 t[*rt].val <= val 时,应该在右子树 ,正好编号为 1
}
void dfs(int rt,int dep) {//遍历子树输出
if (!rt) {
return;
}
if (!tr[rt].son[0] && !tr[rt].son[1]) {//为叶子结点。
printf("%d %d\n", tr[rt].val, dep);
}
// 继续遍历子树,记得增加深度。
dfs(tr[rt].son[0], dep + 1);
dfs(tr[rt].son[1], dep + 1);
}
int main() {
int n = read();
int i;
for (i = 0; i < n; ++i) {
int x = read();
ins(&root, x);
}
dfs(root, 1);
return 0;
}
复杂度分析
最坏的情况,插入成一条单链,每次插入的复杂度是 O(n) ,总体的复杂度是 O(n²)。
第二题:词频统计(树实现)
题目描述
【问题描述】
编写程序统计一个英文文本文件中每个单词的出现次数(词频统计),并将统计结果按单词字典序输出到屏幕上。
要求:程序应用二叉排序树(BST)来存储和统计读入的单词。
注:在此单词为仅由字母组成的字符序列。包含大写字母的单词应将大写字母转换为小写字母后统计。在生成二叉排序树不做平衡处理。
【输入形式】
打开当前目录下文件article.txt,从中读取英文单词进行词频统计。
【输出形式】
程序应首先输出二叉排序树中根节点、根节点的右节点及根节点的右节点的右节点上的单词(即root、root->right、root->right->right节点上的单词),单词中间有一个空格分隔,最后一个单词后没有空格,直接为回车(若单词个数不足三个,则按实际数目输出)。
程序将单词统计结果按单词字典序输出到屏幕上,每行输出一个单词及其出现次数,单词和其出现次数间由一个空格分隔,出现次数后无空格,直接为回车。
【样例输入】
当前目录下文件article.txt内容如下:
"Do not take to heart every thing you hear."
"Do not spend all that you have."
"Do not sleep as long as you want;"
【样例输出】
do not take
all 1
as 2
do 3
every 1
have 1
hear 1
heart 1
long 1
not 3
sleep 1
spend 1
take 1
that 1
thing 1
to 1
want 1
you 3
【样例说明】
程序首先在屏幕上输出程序中二叉排序树上根节点、根节点的右子节点及根节点的右子节点的右子节点上的单词,分别为do not take,然后按单词字典序依次输出单词及其出现次数。
题目大意
题目的核心和第一题并没有什么区别,只不过我们处理的东西从数字变成了字符串。
题目思路
和上一题类似,我们采取快读类似的思路改下读入就能简单的解决这个问题了。
代码实现
#include<stdio.h>
#include<ctype.h>
#include<string.h>
#define maxn 1000005
typedef struct tree {
int son[2];
int num;
char s[35];
} Tree;
Tree tr[maxn];
int root;
int cnt;
int len;
char s[maxn];
char buffer[maxn];
char deal(char c) {
return islower(c) ? c : c - 'A' + 'a';
}
int get_nxt(int pos, int buffer_len) {
len = 0;
while (pos < buffer_len && !isalpha(buffer[pos])) { //不是字母,说明不是单词
++pos;
}
while (pos < buffer_len && isalpha(buffer[pos])) { //循环读入连续字母。
s[len++] = deal(buffer[pos++]);
}
return pos;
}
void ins(int *rt) {//与第一题类似,这里不作赘述
if (!(*rt)) {
*rt = ++cnt;
strcpy(tr[*rt].s, s);
tr[*rt].num = 1;//初始化个数
return;
}
if (!strcmp(tr[*rt].s, s)) { // strcmp 返回 0,说明是同一个单词。
++tr[*rt].num;
return;
}
ins(&tr[*rt].son[strcmp(s, tr[*rt].s) > 0]); //大于 0 进入右子树。
}
void dfs(int rt) { //遍历树输出
if (!rt) {
return;
}
dfs(tr[rt].son[0]);
printf("%s %d\n", tr[rt].s, tr[rt].num);
dfs(tr[rt].son[1]);
}
int main() {
FILE *IN;
IN = fopen("article.txt", "r");
while (fgets(buffer, maxn - 5, IN) != NULL) {
int pos = 0;
int buffer_len = strlen(buffer);
while (pos < buffer_len) {//当前字符串没有处理完
pos = get_nxt(pos, buffer_len); //获得下个单词,并更新当前位置
if (len) { //len不为 0,说明读到了单词。
s[len] = '\0';
ins(&root);
}
}
}
int nw = root;
int i;
for (i = 0; i < 3; ++i) { //按照题目要求,从根开始,往右子树走
printf("%s ",tr[nw].s);
nw = tr[nw].son[1];
}
puts("");
dfs(root);
return 0;
}
复杂度分析
和上题复杂度类似,最坏复杂度是 O(n² * 最长单词长度) 的。
第三题:计算器(表达式计算-表达式树实现)
题目描述
【问题描述】
从标准输入中读入一个整数算术运算表达式,如24 / ( 1 + 2 + 36 / 6 / 2 - 2) * ( 12 / 2 / 2 )= ,计算表达式结果,并输出。
要求:
1、表达式运算符只有+、-、*、/,表达式末尾的=字符表示表达式输入结束,表达式中可能会出现空格;
2、表达式中会出现圆括号,括号可能嵌套,不会出现错误的表达式;
3、出现除号/时,以整数相除进行运算,结果仍为整数,例如:5/3结果应为1。
4、要求采用表达式树来实现表达式计算。
表达式树(expression tree):
我们已经知道了在计算机中用后缀表达式和栈来计算中缀表达式的值。在计算机中还有一种方式是利用表达式树来计算表达式的值。表达式树是这样一种树,其根节点为操作符,非根节点为操作数,对其进行后序遍历将计算表达式的值。由后缀表达式生成表达式树的方法如下:
l 读入一个符号:
l 如果是操作数,则建立一个单节点树并将指向他的指针推入栈中;
l 如果是运算符,就从栈中弹出指向两棵树T1和T2的指针(T1先弹出)并形成一棵新树,树根为该运算符,它的左、右子树分别指向T2和T1,然后将新树的指针压入栈中。
例如输入的后缀表达为:
ab+cde+**
则生成的表达式树为:
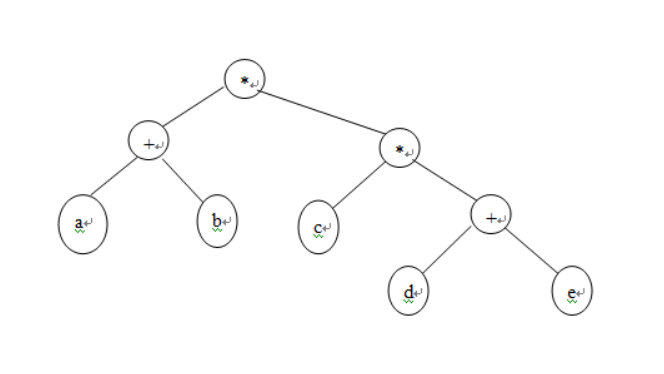
【输入形式】
从键盘输入一个以=结尾的整数算术运算表达式。操作符和操作数之间可以有空格分隔。
【输出形式】
首先在屏幕上输出表达式树根、左子节点及右子节点上的运算符或操作数,中间由一个空格分隔,最后有一个回车(如果无某节点,则该项不输出)。然后输出表达式计算结果。
【样例输入】
24 / ( 1 + 2 + 36 / 6 / 2 - 2) * ( 12 / 2 / 2 ) =
【样例输出】
* / /
18
题目大意
表达式计算,要求用表达式树来实现。
题目思路
表达式树的实现有很多方式,一种是通过类似于递归下降的方式来实现(建议同学们自行去了解一下),而这个题比较经典的是转成后缀表达式再生成表达式树。
这里我们还是给出后缀表达式的实现过程:
1、依次读取输入的表达式,如果是操作数,则把它放入到输出中。
2、如果是操作符,栈为空的话直接将该操作符入栈;如果栈非空,则比较栈顶操作符和该操作符优先级,如果栈顶操作符优先级小于该操作符,则该操作符入栈;否则弹出栈顶操作符并将其放入到输出中,直到栈为空或者发现优先级更低的操作符为止。
3、如果是括号,比如'('和')',则特殊处理。如果是'('的话,直接入栈;如果是')',那么就将栈顶操作符弹出写入到输出中,直到遇到一个对应的'(',但是这个'('只弹出不写入到输出中。注意:"("可以理解为优先级最高。
4、当表达式读取完毕后,如果栈中还有操作符,则依次弹出操作符并写入到输出中。
计算后缀表达式的步骤:
1、是数字,直接压入栈
2、是符号,取出栈顶的两个值计算后成为新栈顶。
最后,给出后缀表达式转表达式树的步骤:
1、遇到数字,创建叶节点, 压栈;
2、遇到运算符, 创建运算符节点, 弹出栈顶两个节点作为运算符节点的左右子节点, 压栈;
代码实现
#include<stdio.h>
#include<ctype.h>
#include<string.h>
#define maxn 1000005
int len; //记录字符串长度
int top; //记录栈顶
char s[maxn]; //读入并转换的表达式
char sta[maxn]; //当前的符号栈
int pri[256]; //定义符号的优先级
void getSuf() { // 读入并将表达式转换为后缀形式
char c;
pri['+'] = pri['-'] = 1;
pri['*'] = pri['/'] = pri['%'] = 2;
while (1) {
c = getchar();
if (isdigit(c)) {
while(isdigit(c)) {
s[len++] = c;
c = getchar();
}
s[len++] = ' '; // 后缀表达式数字可能相连,因此添加空格避免数字连续。
}
if (c == '=') {
break;
}
if (pri[c]) { //说明是一个符号,需要与栈中符号优先级进行比较
while (top && pri[sta[top]] && pri[sta[top]] >= pri[c]) {//注意 () 优先级为 0
s[len++] = sta[top--];
}
sta[++top] = c;
}
if (c == '(') {
sta[++top] = c;
}
if (c == ')') { //需要将 ( 之前所有符号弹出
while(sta[top] != '(') {
s[len++] = sta[top--];
}
--top;
}
}
while (top) {
s[len++] = sta[top--];
}
}
int numSta[maxn]; //数字栈
int numTop; //数字栈栈顶
int calc(int x, char c, int y) {
if (c == '+') {
return x + y;
}
if (c == '-') {
return x - y;
}
if (c == '*') {
return x * y;
}
if (c == '/') {
return x / y;
}
if (c == '%') {
return x % y;
}
}
typedef struct tree {
int type;
int num;
char c;
int son[2];
} Tree;
Tree tr[maxn];
int tree_sta[maxn];
int tree_top;
int cnt;
void print(int x) {
if (tr[x].type == 1) {
printf("%d ", tr[x].num);
} else {
printf("%c ", tr[x].c);
}
}
void calcSuf() {
int i = 0;
while (i < len) {
if (isdigit(s[i])) { //是数字,准备压入数字栈
int x = s[i++] - '0';
while(isdigit(s[i])) {
x = (x << 3) + (x << 1) + s[i++] - '0';
}
numSta[++numTop] = x;
//新建数字类型结点,压入结点栈
++cnt;
tr[cnt].type = 1; //数字类型为 1
tr[cnt].num = x;
tree_sta[++tree_top] = cnt;
}
if (pri[s[i]]) { //是符号,对栈顶两个数字计算得到新栈顶
int a = numSta[numTop--];
int b = numSta[numTop--];
numSta[++numTop] = calc(b, s[i], a);
//新建符号类型结点,将栈顶的两个结点记作左右结点压入结点栈。
++cnt;
tr[cnt].type = 2; //字符类型为 2
tr[cnt].c = s[i];
//注意栈顶的应该是右儿子
tr[cnt].son[1] = tree_sta[tree_top--];
tr[cnt].son[0] = tree_sta[tree_top--];
tree_sta[++tree_top] = cnt;
}
++i;
}
}
void print_ans() {
int root = tree_sta[tree_top]; //如果运行正常,树根应该在栈顶
print(root);
print(tr[root].son[0]);
print(tr[root].son[1]);
puts("");
printf("%d\n", numSta[numTop]);
}
int main() {
getSuf();
calcSuf();
print_ans();
return 0;
}
后缀表达式的部分就不再赘述,而建树部分穿插在其中就能十分简单地完成这道题。
复杂度分析
每个字符被处理了两次,复杂度是 O(|S|) 的。(S代表字符串长度)
第四题:网络打印机选择
题目描述
【问题描述】
某单位信息网络结构呈树型结构,网络中节点可为交换机、计算机和打印机三种设备,计算机和打印机只能位于树的叶节点上。如要从一台计算机上打印文档,请为它选择最近(即经过交换机最少)的打印机。
在该网络结构中,根交换机编号为0,其它设备编号可为任意有效正整数,每个交换机有8个端口(编号0-7)。当存在多个满足条件的打印机时,选择按树前序遍历序排在前面的打印机。
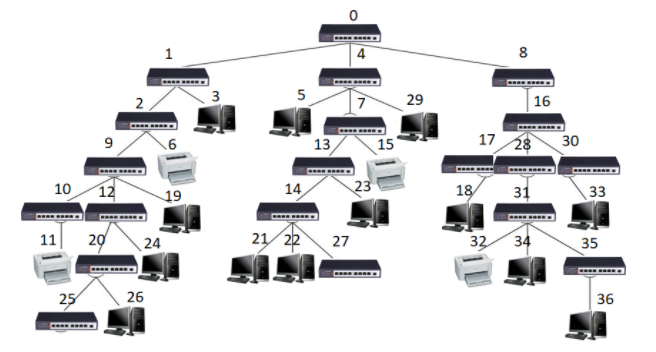
【输入形式】
首先从标准输入中输入两个整数,第一个整数表示当前网络中设备数目,第二个整数表示需要打印文档的计算机编号。两整数间以一个空格分隔。假设设备总数目不会超过300。
然后从当前目录下的in.txt读入相应设备配置表,该表每一行构成一个设备的属性,格式如下:
<设备ID> <类型> <设备父节点ID> <端口号>
<设备ID>为一个非负整数,表示设备编号;<类型>分为:0表示交换机、1表示计算机、2表示打印机;<设备父结点ID>为相应结点父结点编号,为一个有效非负整数;<端口号>为相应设备在父结点交换机中所处的端口编号,分别为0-7。由于设备配置表是按设备加入网络时的次序编排的,因此,表中第一行一定为根交换机(其属性为0 0 -1 -1);其它每个设备结点一定在其父设备结点之后输入。每行中设备属性间由一个空格分隔,最后一个属性后有换行符。
【输出形式】
向控制台输出所选择的打印机编号,及所经过的交换机的编号,顺序是从需要打印文档的计算机开始,编号间以一个空格分隔。
【样例输入】
37 19
in.txt中的信息如下:
0 0 -1 -1
1 0 0 0
2 0 1 2
3 1 1 5
4 0 0 1
5 1 4 0
6 2 2 2
7 0 4 2
8 0 0 4
9 0 2 0
10 0 9 0
11 2 10 3
12 0 9 2
13 0 7 0
14 0 13 0
15 2 7 3
16 0 8 1
17 0 16 0
18 1 17 5
19 1 9 5
20 0 12 1
21 1 14 1
22 1 14 2
23 1 13 2
24 1 12 5
25 0 20 1
26 1 20 2
27 0 14 7
28 0 16 1
29 1 4 3
30 0 16 7
31 0 28 0
32 2 31 0
33 1 30 2
34 1 31 2
35 0 31 5
36 1 35 3
【样例输出】
11 9 10
题目大意
要求在树上,对指定类型的结点,找到最近的前序遍历最小的对应类型结点。
题目思路
居然是新题,可恶啊,虽然还是一 A 了 这个题理论上存在用 DP 的方式 O(n) 求出解,再用 O(n) 把答案求出来的方法,过程比较复杂,这里就不作赘述,实在想知道的同学可以私戳我或者课上找我给你讲讲。我们这里就讲一种比较好写的暴力 O(n²) 的做法,我们先读入建树,DFS 一遍求出前序遍历的顺序(即DFN)。之后从给定的起点暴力 DFS,每经过一个结点打上标记防止重复访问并压入栈,到达打印机结点时比较当前最优解看是否替换就可以了。当然这个题也可以通过暴力枚举打印机倍增爬树法来实现,复杂度是 O(nlogn) 的,同样需要同学们自行学习一些知识才能实现(
代码实现
#include<stdio.h>
#include<ctype.h>
inline int read() { //快速读入,可以放在自己的缺省源里面
int x = 0; //数字位
int f = 1; //符号位
char ch = getchar(); //读入第一个字符
while (!isdigit(ch)) { //不是数字
if (ch == '-') { //特判负号
f = -1;
}
ch = getchar();
}
while (isdigit(ch)) { //读入连续数字
x = (x << 3) + (x << 1) + ch - '0'; // x * 10 == (x << 3) + (x << 1)
ch = getchar();
}
return x * f;
}
#define maxn 1000005
typedef struct tree{
int son[8];
int prt;
int type;
} Tree;
Tree tr[maxn];
int n, m;
int root;
int DFN[maxn];
int dfn;
void getDFN(int x) { //遍历一遍求出DFN序,便于我们后续的操作
if (!x) {
return;
}
DFN[x] = ++dfn;
int i;
for (i = 0; i < 8; ++i) {
if (!tr[x].son[i]) {
continue;
}
getDFN(tr[x].son[i]);
}
}
void pre() { //预处理建树
FILE* IN = fopen("in.txt", "r");
int i;
for (i = 0; i < n; ++i) {
int id;
fscanf(IN, "%d", &id);
++id; //为了便于操作,我们对id做一个偏移。
if (i == 0) {
root = id;
}
fscanf(IN, "%d%d", &tr[id].type, &tr[id].prt);
int pos;
fscanf(IN, "%d", &pos);
if (tr[id].prt != -1) {
++tr[id].prt;//同样是偏移
tr[tr[id].prt].son[pos] = id;
}
}
getDFN(root);
}
#define INF 0x7fffffff
int vst[maxn];
int sta[maxn];
int top;
int ans[maxn];
int ansLen = INF;
int ansDFN;
int check(int x) { //看当前解是否比历史最优解更优
return ansLen > top || (ansLen == top && ansDFN > DFN[x]);
}
void dfsAns(int x) {
if (tr[x].type == 2) {
if (check(x)) {
//更新最优解
ansLen = top;
int i;
for (i = 1; i <= ansLen; ++i) {
ans[i] = sta[i];
}
ansDFN = DFN[x];
}
return;
}
if (tr[x].prt != -1 && !vst[tr[x].prt]) {
vst[tr[x].prt] = 1; //开始访问 prt
sta[++top] = tr[x].prt; //压入栈
dfsAns(tr[x].prt);
--top;
vst[tr[x].prt] = 0; //结束访问
}
int i;
for (i = 0; i < 8; ++i) {
if (!tr[x].son[i] || vst[tr[x].son[i]]) {
continue;
}
vst[tr[x].son[i]] = 1; //开始访问 son[i]
sta[++top] = tr[x].son[i]; //压入栈
dfsAns(tr[x].son[i]);
--top;
vst[tr[x].son[i]] = 0; //结束访问
}
}
int main() {
n = read();
m = read() + 1;
pre();
vst[m] = 1;//不要忘记初始结点随时都被访问
dfsAns(m);
//ansLen 显然存储着我们打印机的编号,其余都是我们经过的交换机
printf("%d ", ans[ansLen] - 1); //输出时记得消去偏移
int i;
for (i = 1; i < ansLen; ++i) {
printf("%d ", ans[i] - 1); //输出时记得消去偏移
}
return 0;
}
复杂度分析
如上面所述,这种暴力方法的复杂度是 O(n²) 的。
偷懒警告
选做题哈夫曼树大家应该都会建看着比较麻烦,实验题限制比较多,也没有什么特别的简化的思路,这里就不赘述了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架