MySQL知识集合
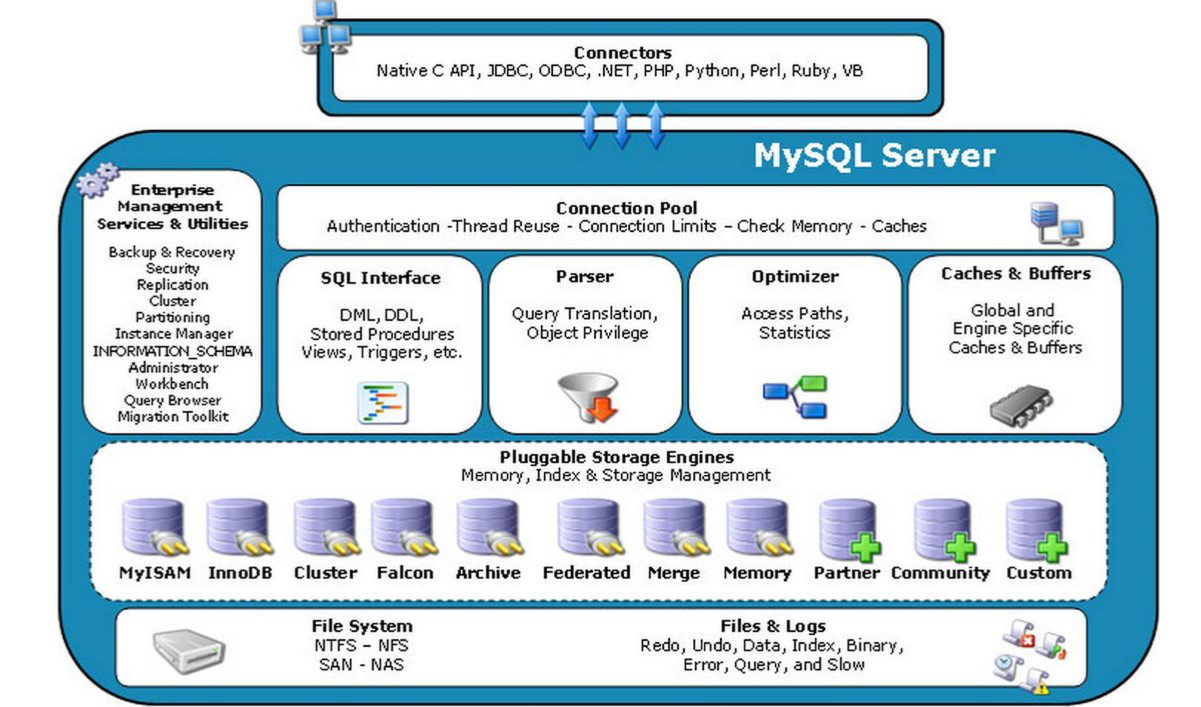
1、Mysql体系架构

2、MySQL文件结构
(1)参数文件:启动MySQL实例的时候,指定一些初始化参数,比如缓冲池大小、数据库文件路径、用户名密码等
-my.cnf读取优先级是从左自右的顺序,但是当默认读取路径都有配置文件时,最后读取的参数的值,会覆盖前面读取的参数的值
-/etc/my.cnf/etc/mysql/my.cnf/usr/local/mysql/etc/my.cnf~/.my.cnf
(2)日志文件:比如:错误日志、二进制日志、慢查询日志、查询日志等等
(3)socket文件:当用UNIX域套接字方式进行连接的时候需要的文件。
(4)pid文件:MySQL实例的进城ID文件。
(5)表结构文件:用来存放MySQL表结构定义文件
(6)储存引擎文件:存储引擎正在储存了纪录和索引等数据
3:索引
1、概念
索引是对数据库表中一个或多个列的值进行排序的数据结构,以协助快速查询、更新数据库表中的数据。索引的实现通常使用
B_TREE及其变种。索引加速了数据访问,因为存储引擎不会再去扫描整张表得到需要的数据;相反,它从根节点开始,根节点保存了子节点的指针,存储引擎会根据指针快速寻找数据。
2、索引的优缺点
优点:大大加快数据的检索速度,这也是创建索引的最主要原因
加速表与表之间的连接
在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间
通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
缺点:时间方面:创建索引和维护索引需要耗费时间,具体地,当对表中的数据进行增加、删除、和修改的时候,索引也要动态的维护,这样降低了数据的维护速度
空间方面:索引需要占物理空间
3、什么情况下设置了索引但无法使用
- 以“%(表示任意0个或多个字符)”开头的like语句,模糊匹配
- OR 语句前后没有同时使用索引
- 数据类型出现隐式转换
- 对于多列索引,必须满足 最左匹配原则
4、什么样的字段适合创建索引
- 经常做查询选择的字段
- 经常做表连接的字段
- 经常出现在 order by ,group by, distinct 字段
5、创建和删除索引的语法
- 查看表中已经存在的index:show index from table_name;
- 使用create index 语句对表增加索引。
create index index_name on table_name(column_list);
create unique index index_name on table_name(column_lsit)
说明:table_name、index_name和column_list具有与ALTER TABLE语句中相同的含义,索引名不可选。另外,不能用CREATE INDEX语句创建PRIMARY KEY索引
3.使用ALTER TABLE语句创建索引
语法如下:
alter table table_name add index index_name(column_list)
alter table table_name add unique(colum_list)
alter table table_name add primary key(column_list)
其中包括普通索引、UNIQUE索引和PRIMARY KEY索引3种创建索引的格式,table_name是要增加索引的表名
column_list指出对哪些列进行索引,多列索引用逗号分隔,index_name可选,缺省时MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以同时创建多个索引。
6、删除索引
drop index index_name on table_name ;
alter table table_name drop index index_name ;
alter table table_name drop primary key ;
其中,在前面的两条语句中,都删除了table_name中的索引index_name。而在最后一条语句中,只在删除PRIMARY KEY索引中使用,因为一个表只可能有一个PRIMARY KEY索引,因此不需要指定索引名。如果没有创建PRIMARY KEY索引,但表具有一个或多个UNIQUE索引,则MySQL将删除第一个UNIQUE索引。
如果从表中删除某列,则索引会受影响。对于多列组合的索引,如果删除其中的某列,则该列也会从索引中删除。如果删除组成索引的所有列,则整个索引将被删除。
4、锁的类型、锁的粒度、锁的实现?
锁的类型:共享锁(也叫读锁)、排他锁(也叫写锁)
锁的粒度:表锁、行锁
锁的实现:乐观锁、悲观锁
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次拿数据的时候都会上锁,这样别人想那这个数据就会阻塞直到它拿到锁。传统的关系型数据库很多这种锁机制,比如行锁、表锁、读锁、写锁,在操作之前上锁。JAVA:synchronized关键字 是悲观锁
乐观锁:顾名思义,就很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号邓机制。乐观锁适用于多读的应用类型,提高吞吐量
5、什么是事务?没事务会责会怎么样
事务:在一个事务种的一组SQL,要么都执行,要么都不执行。没有事务会出现脏读、幻读、不可重复读
四大特性:ACID
- 原子性(automicity):事务种的所有sql,要么全执行,要么全部不执行。
- 一致性(comsistency):转账前,A和B的全部账户共500+500.转装后 400+600
- 隔离性(isolation):在A向B转账的整个过程中,只要事务还没有提交(commit),查询A账户和B账户的钱数量不会变化。
- 持久性(durability):一旦转账成功(事务提交),两个账户的钱就会真的发生变化
6、什么是脏读?幻读?不可重复读?什么是事务的隔离级别?Mysql的默认隔离级别是?
-
脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据。
-
不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
-
幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。也就是可以插入新的行记录。
事务的隔离级别:
-
Read uncommitted(读未提交):就是一个事务可以读取另一个未提交事务的数据。会造成脏读,不可重复读。
-
Read committed(读已提交):就是一个事务要等另一个事务提交后才能读取数据。但还是不可重复读。
-
Repeatable read(可重复读):就是在开始读取数据(事务开启)时,不再允许修改操作??
-
Serializable (串行化):Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
Mysql的默认隔离级别是:Repeatable read!!
7、什么是死锁?怎么解决?
死锁:两个或多个事务相互占用了对方的锁,就会一直处于等待的状态。
常见的解决死锁的方法:
(1)、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
(2)、在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
(3)、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
如果业务处理不好可以用分布式事务锁或者使用乐观锁
8、多版本并发控制
MySQL的大多数事务型存储引擎实现的都不是简单的行级锁。基于并发性能的考虑,他们一般都同时实现了多版本并发控制(MVCC),不仅MySQL,包括Oracale、PostgreSQL等其他数据库都各自实现了MVCC,但基于实现的机制不尽相同,因为MVCC没有一个统一的标准。InnoDB的MVCC,是通过在每行记录后面保存两个隐藏的列来实现的,一个是创建时间,一个是系统版本号。每开始一个新的事物,系统版本号会自动递增。
9、char和varchar的区别?
- varchar是变长,char是定长
- varchar占用空间更多,会多出一个字节来储存字符长度,超过255个字符使用两个字节
- char无碎片,varchar经常更新会造成碎片
10、MySQL性能优化
-
表结构优化:数据类型的选择通常更小的最好,尽量避免NULL,表字段不宜太多,有时候反范式设计会带来性能的提升。
-
经常查询的列建立索引
-
索引列的基数越大,数据区分度越高,索引的效果越好。
-
对于字符串进行索引,应该制定一个前缀长度,可以节省大量的索引空间。
-
根据情况创建联合索引,联合索引可以提高查询效率。
-
避免创建过多的索引,索引会额外占用磁盘空间,降低写操作效率。
-
访问数据太多导致查询性能下降
-
确定应用程序是否在检索大量超过需要的数据,可能是太多行或列
-
确认MySQL服务器是否在分析大量不必要的数据行
-
避免犯如下SQL语句错误
-
查询不需要的数据。解决办法:使用limit解决
-
多表关联返回全部列。解决办法:指定列名
-
总是返回全部列。解决办法:避免使用SELECT *
-
重复查询相同的数据。解决办法:可以缓存数据,下次直接读取缓存
-
是否在扫描额外的记录。解决办法:
- 使用explain进行分析,如果发现查询需要扫描大量的数据,但只返回少数的行,可以通过如下技巧去优化:
-
使用索引覆盖扫描,把所有的列都放到索引中,这样存储引擎不需要回表获取对应行就可以返回结果。
-
改变数据库和表的结构,修改数据表范式
-
重写SQL语句,让优化器可以以更优的方式执行查询。
-
确定ON或者USING子句中是否有索引。
-
确保GROUP BY和ORDER BY只有一个表中的列,这样MySQL才有可能使用索引。
-
LIMIT偏移量大的时候,查询效率较低
-
可以记录上次查询的最大ID,下次查询时直接根据该ID来查询
11、IN和exists的使用?
exists对外表用loop逐条查询,每次查询都会查看exists的条件语句,当exists里的条件语句能够返回纪录行时
(无论记录行是的多少,只要能返回),条件就为真,返回当前loop到的到这条纪录,反之如果exists里的条 件语句不能返回记录行,则当前loop到的这条记录被丢弃,exists的条件就像一个bool条件,当能返回结果集则为true,不能返回结果集则为 false
in查询相当于多个or条件的叠加,这个比较好理解,比如下面的查询
-
select * from A where cc in (select cc from B),用到了A表上cc列的索引;
-
select * from A where exists(select cc from B where cc=A.cc) ,用到了B表上cc列的索引。
12、什么是交叉链接、内链接、外链接?
内连接(INNER JOIN):有两种,显式的和隐式的,返回连接表中符合连接条件和查询条件的数据行。(所谓的连接表就是数据库在做查询形成的中间表)
外连接(OUTER JOIN):外连接分为左连接或左外连接、右连接或者右外连接、全连接或全外连接。我们简单的就叫:左连接,右连接和全连接
左外连接:返回左表中的所有行,如果左表中行在右表中没有匹配行,则结果中右表中的列返回空值
select t.teacher_name, s.student_name from teacher t, student s where t.id= s.teacher_id(+);
右外连接:恰与左连接相反,返回右表中的所有行,如果右表中行在左表中没有匹配行,则结果中左表中的列返回空值
select t.teacher_name, s.student_name from teacher t, student s where t.id(+) = s.teacher_id;
全外连接:返回左表和右表中的所有行。当某行在另一表中没有匹配行,则另一表中的列返回空值
交叉连接(CROSS JOIN):也称笛卡儿积。
概念:不带WHERE条件句,它将会返回被连接的两个表的笛卡儿积,返回结果的行数等于两个表行数的乘积
13、SQL语句关键字的执行顺序
-
FROM:对FROM子句中的左表和又表执行笛卡尔积,产生虚拟表VT1。
-
ON:对虚拟表T1应用ON筛选,只有那些符合条件的行才被插入虚拟表VT2。
-
JOIN:如果指定了OUTER JOIN ,那么保留表中未匹配的行作为外部行添加到虚拟表VT2中,产生虚拟表VT3,。如果FROM子句包含两个以上表,则对上一个连接生成的VT3和下一个表重复执行步骤1-步骤3,直到处理完表为止。
-
WHERE:对虚拟表VT3应用WHERE条件筛选,只有符合条件的行才被插入到虚拟表VT4中。
-
GROUP BY:根据GROUP BY子句中的列,对VT4中的记录进行分组操作,产生虚拟表VT5。
-
CUBE|ROLLUP:对虚拟表VT5进行CUBE或ROLLUP操作,产生虚拟表VT6。
-
HAVING:对虚拟表VT6应用HAVING过滤器,只有符合条件的记录才被插入虚拟表VT7。
-
SELECT:第二次执行SELECT操作,选择指定的列,插入到虚拟表VT8中。
-
DISTINCT:去除重复的数据,产生虚拟表VT9。
-
ORDER BY:将虚拟表VT9中的记录按照字段进行排序操作产生虚拟表VT10.
-
LIMIT:取出指定行的记录,产生虚拟表VT11,并返回给查询用户。
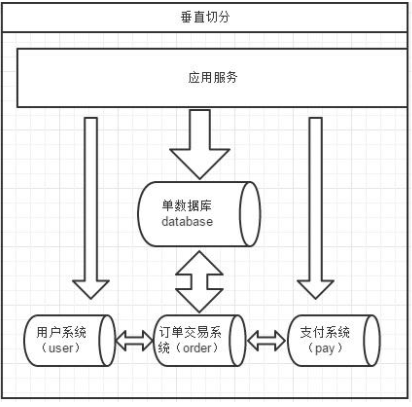
14、垂直切分和水平切分
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面, 如下图:
水平切分
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切
分到其他的数据库中,如下图:
垂直切分的优缺点介绍:
优点:
拆分后业务清晰,拆分规则明确。
系统之间整合或扩展容易。
数据维护简单。
缺点:
部分业务表无法join,只能通过接口方式解决,提高了系统复杂度。
受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
事务处理复杂。
由于垂直切分是按照业务的分类将表分散到不同的库,所以有些业务表会过于庞大,存在单库读写与存储瓶颈,所以就需要水平
拆分来做解决。
水平切分的优缺点介绍:
优点:
拆分规则抽象好,join操作基本可以数据库做。
不存在单库大数据,高并发的性能瓶颈。
应用端改造较少。
提高了系统的稳定性跟负载能力。
缺点:
拆分规则难以抽象。
分片事务一致性难以解决。
数据多次扩展难度跟维护量极大。
跨库join性能较差。
垂直切分和水平切分共同的特点和缺点有:
引入分布式事务的问题。
跨节点Join的问题。
跨节点合并排序分页问题。
多数据源管理问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号