ELk日志分析收集工具
分析日志的意义:
-
分析日志监控系统运行的状态
-
分析日志来定位程序的bug
-
分析日志监控网站的访问流量
-
分析日志可以知道哪些
sql语句需要优化
收集工具分类
-
日志易:国内一款监控、审计、权限管理,收费软件
-
splunk:按流量收费,国外软件,主要三个部件组成:Indexer、Search Head、Forwarder
- Indexder提供数据的存储,索引,类似于elasticsearch的作用
- Search Head负责搜索,客户接入,从功能上看,一部分是kibana的UI是运行,在Search Head上的,提供所有的客户端可视化功能,还有一部分,是提供分布式的搜索功能,具有Elasticsearch部分功能
- Forwarder负责数据接入,类似Logstash或者filebeat
-
elk
elk简单介绍
ELK官网:https://www.elastic.co/cn/
ELK官方文档:https://www.elastic.co/guide/index.html
ELK中文手册:http://kibana.logstash.es/content/elasticsearch/monitor/logging.html
核心组成
ELK是elasticsearch、Logstashh和Kibana三个系统的首字母组合。
-
Elasticsearch 是一个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
主要功能:用来做数据存储(也是种数据库)、数据搜索、数据分析
-
Logstash 是一个完全开源的工具,它可以对你的日志进行收集,过滤,并将其存储供以后使用(如:搜索)。
-
Kibana 也是一个开源和免费的工具,Kibana可以为Logstash 和 ElasticSearch 提供的日志分析友好的 Web 页面,可以帮助汇总、分析和素搜索重要数据日志。
四大部件
- Logstash:logstash server端用来搜集日志;
- Elasticsearch:存储各类日志;
- Kibanana:web化接口用作查询和可视化日志
- Logstash Forwarder:Logstash client端用来通过 lumberjack 网络协议发送日志到 logstash server;
ELK工作流程
在需要收集日志的所有服务器上部署logstash,作为logstash agent(logstash shipper)用于监控并过滤收集日志,将过滤后的内容发送到 Redis,然后logstash indexer将日志收集在一起交给全文搜索ElasticSearch,可以用ElasticSearch进行自定义搜索通过Kibana 来结合自定义搜索进行页面展示。
部署方式
第一种方式 L-E-K方式:不添加任何其他辅助系统,部署简单快速,容易上手。
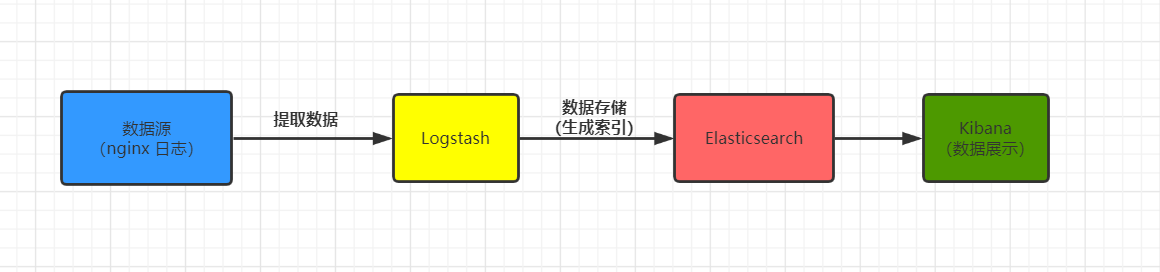
第二种方式:在L-E-K方式之间加一个redis辅助,这样能够减少日志在服务端的积压,把压力转移到ELK服务器上。这种方式添加redis之后,由于redis是内存系统所以相应速度快,而且可以在redis后添加多个消费系统(Logstash),来扩展消费能力,增强处理速度。
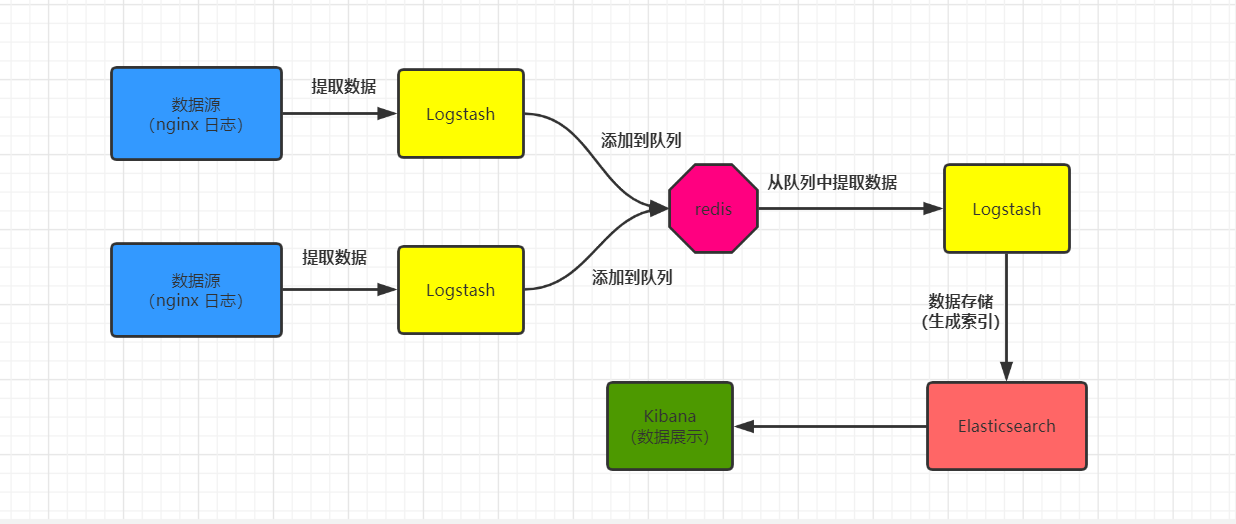
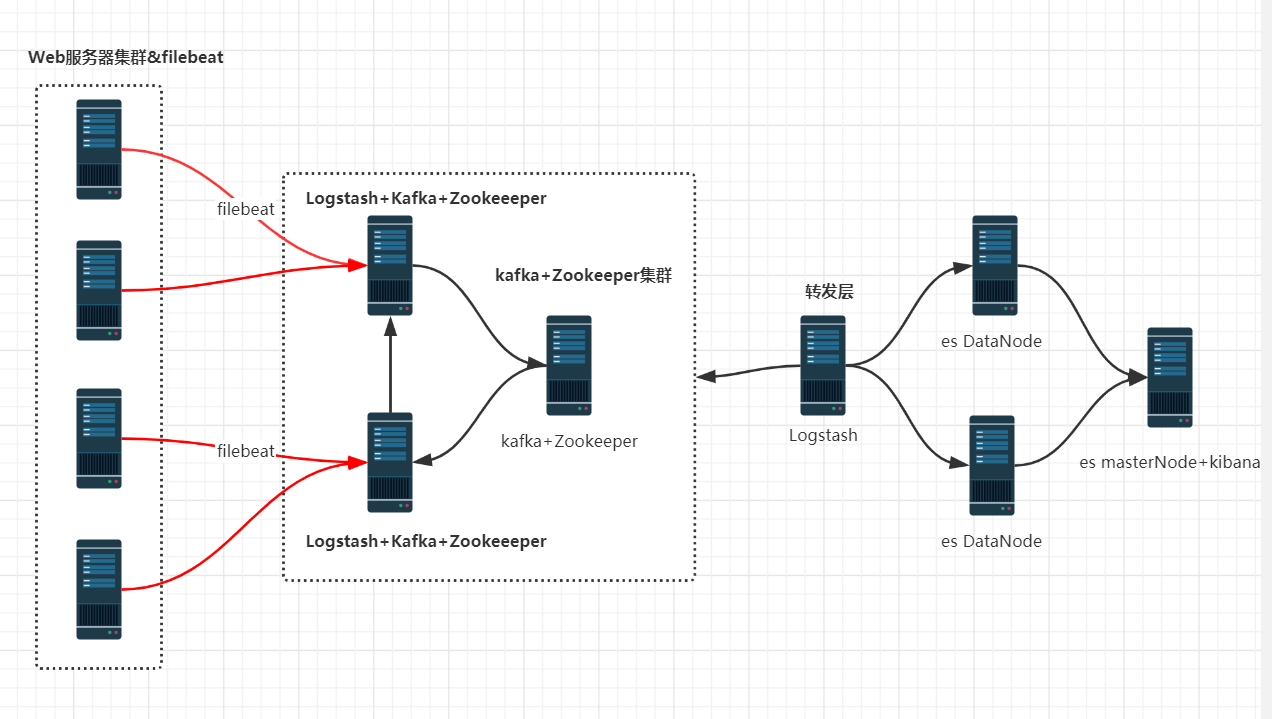
第三种方式:ELK+filebeat+kafka+zookeeper集群架构 kafka做缓存
什么是倒排索引
1. 信息存储到es时,首先把每条语句分成一个一个的词语 2. 根据搜索的内容,进行分配,有匹配到的权重+1 3. 把匹配到的语局给呈现出来
elasticsearch介绍
elasticsearch应用场景
1. 电商平台 2. 高亮显示搜索的词条信息 3. 日志分析elk
elasticsearch特点
1. 高性能: es可以支持一主多从,水平扩展方便 2. 高可用性:一个主节点宕机后不影响用户的使用。 3. 用户使用方便快捷:es采用Java开发,即使不懂Java代码,一样可以使用 4. 功能丰富,配置简单 5. 采用restful封装的接口,可以通过http发起请求
elasticsearch部署方法
| 安装方式 | 优点 | 对运维的要求 |
| docker | 部署方便、开箱即用、启动迅速 | 需要会docker知识、需要制作镜像、修改配置麻烦、数据需要挂载目录 |
| tar | 部署灵活、对系统侵占性小 | 需要写启动脚本文件、目录需要提前规划 |
| rpm | 部署方便、启动脚本安装即用、存放目录标准化 | 软件各个组件分散在不同的目录、卸载不彻底、默认配置需要修改 |
| ansible | 极其灵活、批量部署速度快 | 需要学习ansible语法、需要提前规划、需要专人维护 |
es安装前环境准备
es安装准备
- 系统版本:centos7.6
- ip地址:10.0.0.240
- 主机名:es01
- 内存:2G+
关闭防火墙
systemctl stop firewalld systemctl disable firewalld setenforce 0 sed -i 's/=enforcing/=disabled/g' /etc/selinux/config
配置yum源
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo --安装软件需要
安装jdk
下载地址:https://www.oracle.com/java/technologies/javase-jdk8-downloads.html
注:需要注册账号才可以下载软件包,请使用180以上版本,否侧会出现报错
elk软件包链接:https://pan.baidu.com/s/1wtNI6Zt6f9JDvl6gD2F_6w 提取码:nu1s
mkdir -p /opt/es-software cd /opt/es-software rpm -ivh jdk-8u102-linux-x64.rpm ## 版本测试 java -version java version "1.8.0_102" Java(TM) SE Runtime Environment (build 1.8.0_102-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.102-b14, mixed mode)
es部署
上传es软件
注:如果想下载新的es软件包,我们可以去清华源下载
cd /opt/es-software rpm -ivh elasticsearch-6.6.0.rpm
查看es安装配置文件位置
rpm -qc elasticsearch /etc/elasticsearch/elasticsearch.yml --主配置文件 /etc/elasticsearch/jvm.options --jvm虚拟机配置 /etc/init.d/elasticsearch --init启动文件 /etc/sysconfig/elasticsearch --ES环境变量的相关文件 /usr/lib/sysctl.d/elasticsearch.conf --ES环境变量的相关配置 /usr/lib/systemd/system/elasticsearch.service --服务启动文件
修改es配置文件
egrep -v '^$|#' /etc/elasticsearch/elasticsearch.yml ##配置内容 vim /etc/elasticsearch/elasticsearch.yml node.name: es01 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true ---锁定内存,在启动时会报错 network.host: 10.0.0.240,127.0.0.1 http.port: 9200 ##启动服务 systemctl start elasticsearch systemctl enable elasticsearch
- 解决内存锁定失败问题,官方网址
systemctl edit elasticsearch [Service] LimitMEMLOCK=infinity ##重新载入,并重新启动服务 systemctl daemon-reload systemctl restart elasticsearch ##检查端口是否开启 netstat -lntup -- 正常开启的端口为9200和9300 tcp6 0 0 127.0.0.1:9200 :::* LISTEN 10066/java tcp6 0 0 10.0.0.240:9200 :::* LISTEN 10066/java tcp6 0 0 127.0.0.1:9300 :::* LISTEN 10066/java tcp6 0 0 10.0.0.240:9300 :::* LISTEN 10066/java
- 给java程序设定启动大小
vim /etc/elasticsearch/jvm.options -Xms1g -Xmx1g systemctl start elasticsearch --如果没有,建议这个命令多启动几下
注:这里可能会启动失败,因为java程序比较吃内存,建议多给点内存,内存查看命令free -h
检查es是否正常使用
##浏览器的方式: http://10.0.0.240:9200 ##命令行的方式: curl 10.0.0.240:9200 { "name" : "es01", "cluster_name" : "elasticsearch", "cluster_uuid" : "LG2l_0MvRbSWuPwjPzgxFw", "version" : { "number" : "6.6.0", "build_flavor" : "default", "build_type" : "rpm", "build_hash" : "a9861f4", "build_date" : "2019-01-24T11:27:09.439740Z", "build_snapshot" : false, "lucene_version" : "7.6.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" } #创建个索引 curl -XPUT '10.0.0.240:9200/oldboy?pretty' #往这个索引里面插入一条指定id号为1的数据 curl -XPUT '10.0.0.240:9200/oldboy/student/1?pretty' -H 'Content-Type: application/json' -d' { "first_name" : "zhang", "last_name": "san", "age" : 25, "about" : "I love to go rock climbing", "interests": [ "sports" ] }' #往这个索引里面插入一条随机生成一个id的数据 curl -XPUT '10.0.0.240:9200/oldboy/student/2?pretty' -H 'Content-Type: application/json' -d' { "first_name": "li", "last_name" : "si", "age" : 32, "about" : "I like to collect rock albums", "interests": [ "music" ] }' #查询索引当中的一条数据 curl -XGET '10.0.0.240:9200/oldboy/student/1?pretty' #删除索引当中的一条数据 curl -XDELETE '10.0.0.240:9200/oldboy/student/1?pretty' #删除指定的索引 curl -XDELETE '10.0.0.240:9200/oldboy/?pretty' #修改系统默认的副本及分片数量 curl -XPUT '10.0.0.240:9200/_template/template_http_request_record' -H 'Content-Type: application/json' -d' { "index_patterns": ["*"], "settings": { "number_of_shards" : 5, "number_of_replicas" : 1 } }'
- ES和MySQL关系对比
| 数据库 | index(索引) |
| 表 | type(类型) |
| 字段 | Fields(文档有多个字段) |
| 行 | doc(文档) |
ES交互方式
1. curl命令
最繁琐复杂
最容易出错
不需要安装任何软件,只需要有curl命令
2. es-head插件
查看数据方便
操作相对容易
需要node环境
3. kibana
查看数据以及报表格式丰富
操作简单
需要java环境和安装配置kibana
head插件安装
- 下载epel源
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
nodejs编译安装
yum install nodejs npm openssl screen -y #配置nodejs环境 ##查看版本 node -v npm -v ##安装组件 npm install -g cnpm --registry=https://registry.npm.taobao.org --更新为淘宝源 cd /opt/ ##克隆代码 官网https://github.com/mobz/elasticsearch-head git clone git://github.com/mobz/elasticsearch-head.git cd elasticsearch-head/ cnpm install screen -S es-head cnpm run start Ctrl+A+D #通过cnpm的方式来运行head时, 发现无法链接es服务器 vim /etc/elasticsearch/elasticsearch.yml http.cors.enabled: true http.cors.allow-origin: "*"
在谷歌浏览器中安装插件
设置--> 扩展工具-->加载软件包(包在上面的连接目录里面es-head-0.1.4_0.crx.123ok)
- 测试连接
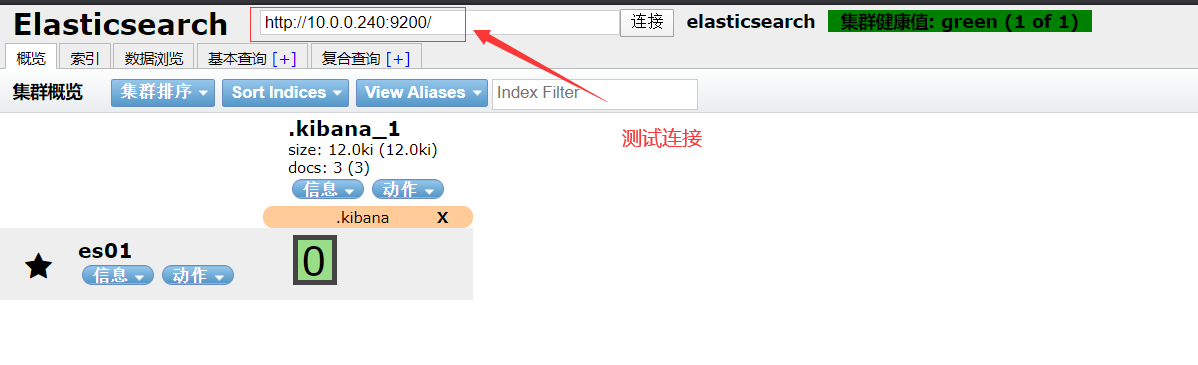
使用docker
docker pull alivv/elasticsearch-head ---docker.hub拉取镜像,对带宽有要求 docker run --name es-head -p 9100:9100 -dit elivv/elasticsearch-head
谷歌浏览器插件
插件地址:https://github.com/mobz/elasticsearch-head
修改文件名为zip后缀
解压目录
拓展程序-开发者模式-打开已解压的目录
连接地址修改为ES的IP地址
head插件和es连接错误解决
#在es配置文件最下面加入下面内容 http.cors.enabled: true http.cors.allow-origin: "*"
head界面简单说明
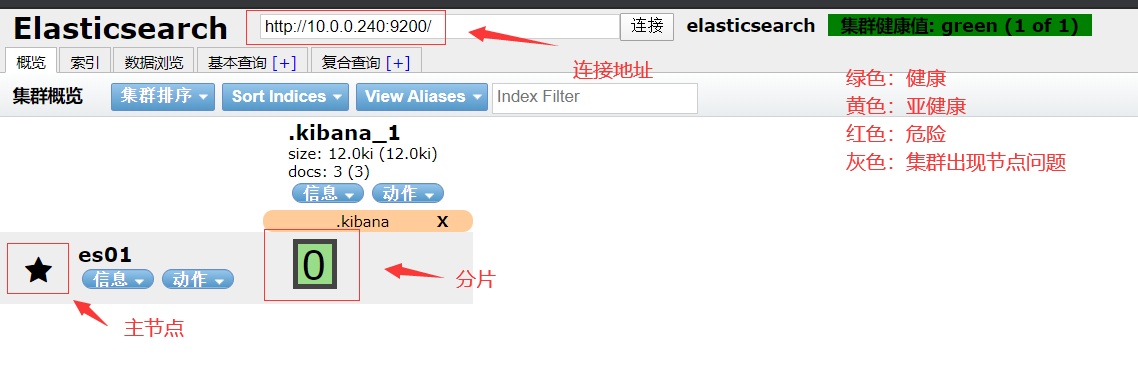
对es数据库的操作
在命令行界面来对es操作
##命令行的方式: curl 10.0.0.240:9200 { "name" : "es01", "cluster_name" : "elasticsearch", "cluster_uuid" : "LG2l_0MvRbSWuPwjPzgxFw", "version" : { "number" : "6.6.0", "build_flavor" : "default", "build_type" : "rpm", "build_hash" : "a9861f4", "build_date" : "2019-01-24T11:27:09.439740Z", "build_snapshot" : false, "lucene_version" : "7.6.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" } #创建个索引 curl -XPUT '10.0.0.240:9200/class?pretty' #往这个索引里面插入一条指定id号为1的数据 curl -XPUT '10.0.0.240:9200/class/student/1?pretty' -H 'Content-Type: application/json' -d' { "first_name" : "zhang", "last_name": "san", "age" : 25, "about" : "I love to go rock climbing", "interests": [ "sports" ] }' #往这个索引里面插入一条随机生成一个id的数据 curl -XPUT '10.0.0.240:9200/class/student/2?pretty' -H 'Content-Type: application/json' -d' { "first_name": "li", "last_name" : "si", "age" : 32, "about" : "I like to collect rock albums", "interests": [ "music" ] }' #查询索引当中的一条数据 curl -XGET '10.0.0.240:9200/class/student/1?pretty' #删除索引当中的一条数据 curl -XDELETE '10.0.0.240:9200/class/student/1?pretty' #删除指定的索引 curl -XDELETE '10.0.0.240:9200/class/?pretty' #修改系统默认的副本及分片数量 curl -XPUT '10.0.0.240:9200/_template/template_http_request_record' -H 'Content-Type: application/json' -d' { "index_patterns": ["*"], "settings": { "number_of_shards" : 5, "number_of_replicas" : 1 } }'
在head插件上面创建索引插入数据
示例:
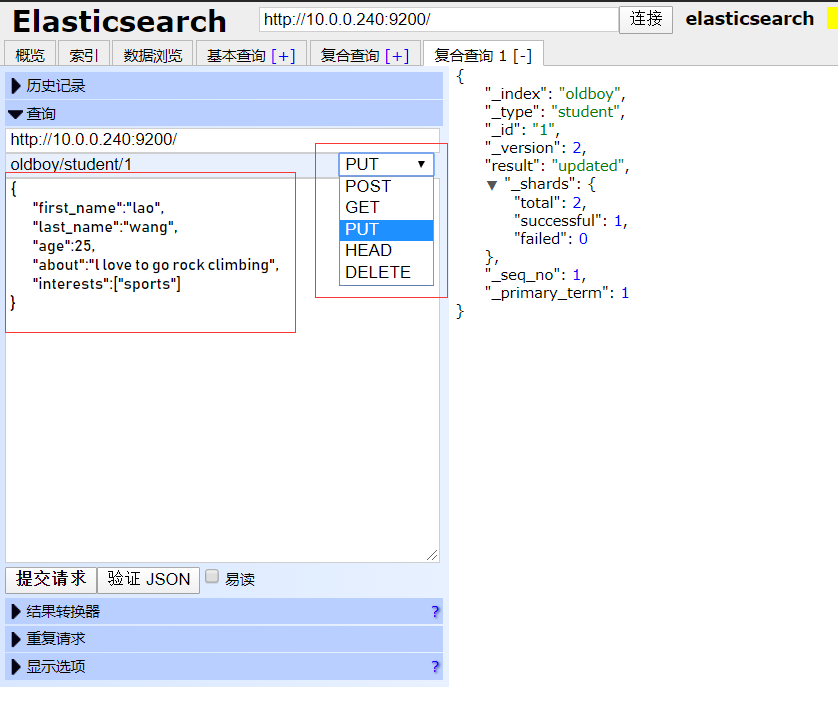
#创建索引: http://10.0.0.240:9200/class 选择--> PUT #插入数据: http://10.0.0.240:9200/class/student/1 { "first_name":"lao", "last_name":"wang", "age":25, "about":"l love to go rock climbing", "interests":["sports"] } #插入第二条数据: http://10.0.0.240:9200/class/student/2 选择--> PUT { "first_name":"wang", "last_name":"wu", "age":27, "about":"I love to go rock climbing", "interests":["music"] } #不指定id号随机插入一条数据: #put不支持不支持分配id号,post支持随机分配id号 http://10.0.0.240:9200/class/student/ 选择-->POST { "first_name":"zhao", "last_name":"liu", "age":29, "about":"I love to go rock climbing", "interests":["eatting"] } #查询指定id号的数据信息: http://10.0.0.240:9200/class/student/1 选择-->GET #查询指定索引所有数据信息: http://10.0.0.240:9200/class/_search 选择-->GET #删除指定的数据: http://10.0.0.240:9200/class/student/1 选择--> DELETE #删除指定索引里面的数据: http:/10.0.0.240:9200/class/ 选择-->DELETE #修改副本及分片: http://10.0.0.240:9200/_template/template_http_request_record 选择-->PUT { "index_patterns": ["*"], "settings": { "number_of_shards" : 5 "number_of_replicas" : 1 } }'
Klibana与es交互
安装kibana
kibana下载地址:https://www.elastic.co/cn/kibana
##安装kibana cd /opt/es-software rpm -ivh kibana-6.6.0-x86_64.rpm ##修改配置文件 vim /etc/kibana/kibana.yml [root@es01 es-software]# egrep -v '^$|#' /etc/kibana/kibana.yml server.port: 5601 server.host: "10.0.0.240" elasticsearch.hosts: ["http://10.0.0.240:9200"] kibana.index: ".kibana" #启动kibana服务 systemctl start kibana #在浏览器中测试kibana服务是否正常 http://10.0.0.240:5601
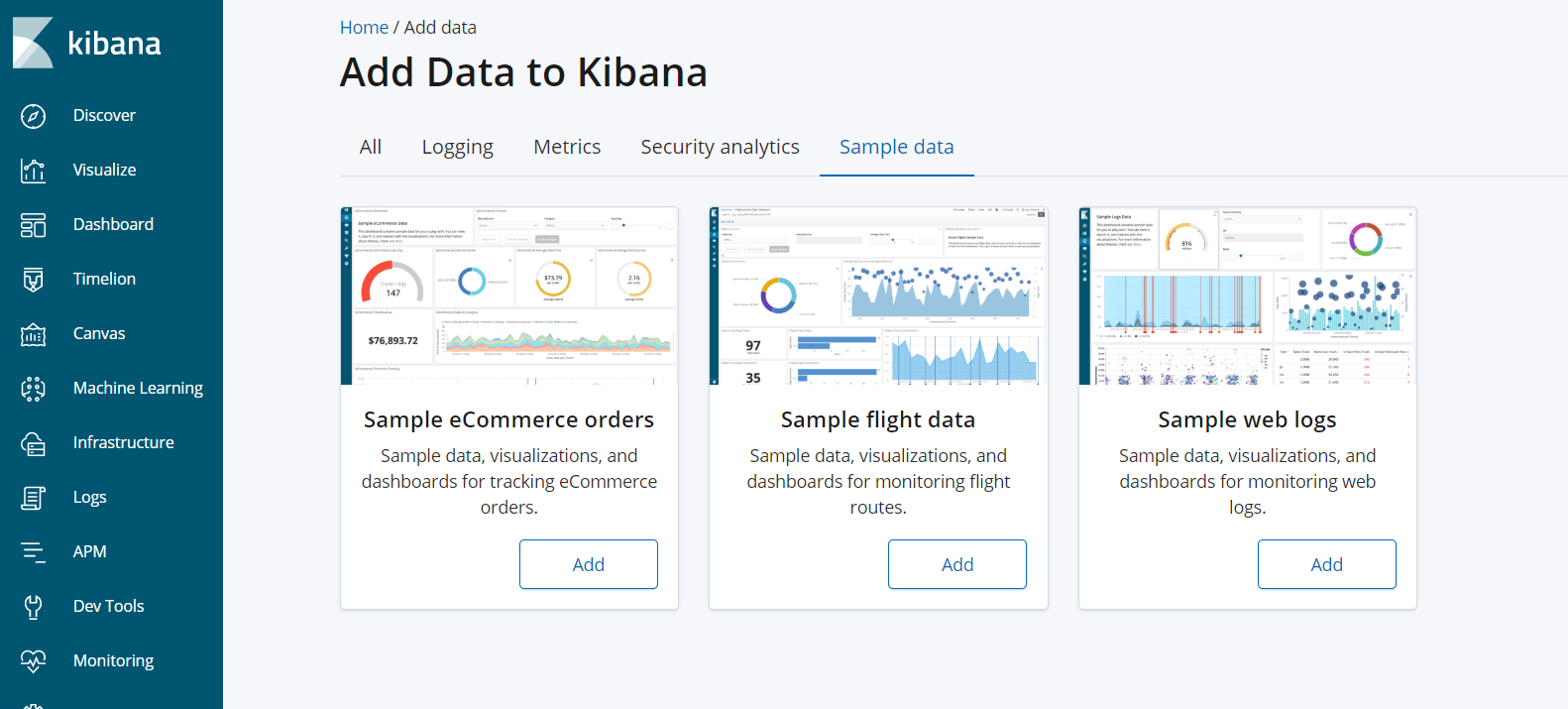
注:这里出现了一些问题,网页显示 K;ibana server is not ready yet,重新刷新网页又好了。
也可能是因为索引给删掉了,使用命令:curl -XDELETE http://10.0.0.240:9200/.kibana_2
在kibana界面往es系统系统数据
Dev Tools--->console #创建一个索引 PUT class #在oldboy索引中插入一条数据 PUT class/student/1 { "name": "zhang san", "age": "29", "xuehao": 1 } #随机插入一条数据 POST class/student/ { "name": "xiaoli", "age": "19", "xuehao": 5 } #查询数据 GET class/student/2 GET class/_search #删除一条数据 DELETE class/student/1 #修改系统默认的分片数和副本数 PUT _template/template_http_request_record { "index_patterns": ["*"], "settings": { "number_of_shards" : 3, "number_of_replicas" : 1 } }
备注:
- 即使又某些索引不在使用,不要马上删除,可以先关闭掉,确定一段时间内没有人使用,在删除。
- 一但索引被创建,分片的数量不能被二次修改,副本的数量可以修改。
修改副本数量的命令
PUT /calss/_settings { "number_of_replicas": 2 }
es集群部署
地址规划:
| 主机名 | ip地址 | node-name | 软件 | 内存 |
| es01 | 10.0.0.240 | es01 | elasticsearch、kibana | 3G |
| es02 | 10.0.0.241 | es02 | elasticsearch | 3G |
| es03 | 10.0.0.242 | es03 | elasticsearch | 3G |
安装es集群
#上传需要安装的包 mkdir /opt/es-software cd /opt/es-software jdk elasticsearch #安装包 rpm -ivh jdk-8u102-linux-x64.rpm rpm -ivh elasticsearch-6.6.0.rpm
修改各节点配置文件
注:这里我们进行两两配置,首尾相接
es01主机:10.0.0.240 10.0.0.241
es02主机:10.0.0.241 10.0.0.242
es03主机:10.0.0.242 10.0.0.24
- 在10.0.0.240主机操作
vim /etc/elasticsearch/elasticsearch.yml [root@es01 es-software]# grep -E -v '^$|#' /etc/elasticsearch/elasticsearch.yml #cluster名称 cluster.name: es01-cluster #node节点名称 node.name: es01 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 10.0.0.240,127.0.0.1 http.port: 9200 #集群连接的主机,两两串联集群 discovery.zen.ping.unicast.hosts: ["10.0.0.240", "10.0.0.241"] #进行选举,有两个主机投票就是集群下一个老大 discovery.zen.minimum_master_nodes: 2 http.cors.enabled: true http.cors.allow-origin: "*"
- 在10.0.0.241主机操作
vim /etc/elasticsearch/elasticsearch.yml [root@es02 es-software]# grep -E -v '^$|#' /etc/elasticsearch/elasticsearch.yml cluster.name: es01-cluster node.name: es02 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 10.0.0.241,127.0.0.1 http.port: 9200 discovery.zen.ping.unicast.hosts: ["10.0.0.241", "10.0.0.242"] discovery.zen.minimum_master_nodes: 2 http.cors.enabled: true http.cors.allow-origin: "*"
- 在10.0.0.242主机操作
vim /etc/elasticsearch/elasticsearch.yml [root@es03 es-software]# grep -E -v '^$|#' /etc/elasticsearch/elasticsearch.yml cluster.name: es01-cluster node.name: es03 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 10.0.0.242,127.0.0.1 http.port: 9200 discovery.zen.ping.unicast.hosts: ["10.0.0.242", "10.0.0.240"] discovery.zen.minimum_master_nodes: 2 http.cors.enabled: true http.cors.allow-origin: "*"
注:集群启动失败排查
- es主配置文件有些地方有误
- es主进程在启动时,直接被
kill -9 - 内存太小,虚拟机所使用的内存达不到要求
命令行查看集群节点
- 主节点查看集群日志,如果一直出现日志就是不正常
[root@es01 ~]# tail -f /var/log/elasticsearch/es01-cluster.log [2020-03-19T13:36:10,179][INFO ][o.e.c.s.ClusterApplierService] [es01] added {{es03}{A3kawMrWQ96njqdzXcTPKA}{obOzQrZVTyuWlvtZ8Q2SSg}{10.0.0.242}{10.0.0.242:9300}{ml.machine_memory=2076762112, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true},}, reason: apply cluster state (from master [master {es02}{C-Tt5jhCRY63fl5Z-7uxDQ}{rMfCPPbSTayguT8XNnVNwQ}{10.0.0.241}{10.0.0.241:9300}{ml.machine_memory=2076762112, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true} committed version [16]])
- node节点查看后台进程
# netstat -lntup tcp6 0 0 127.0.0.1:9200 :::* LISTEN 55201/java tcp6 0 0 10.0.0.241:9200 :::* LISTEN 55201/java tcp6 0 0 127.0.0.1:9300 :::* LISTEN 55201/java tcp6 0 0 10.0.0.241:9300 :::* LISTEN 55201/java
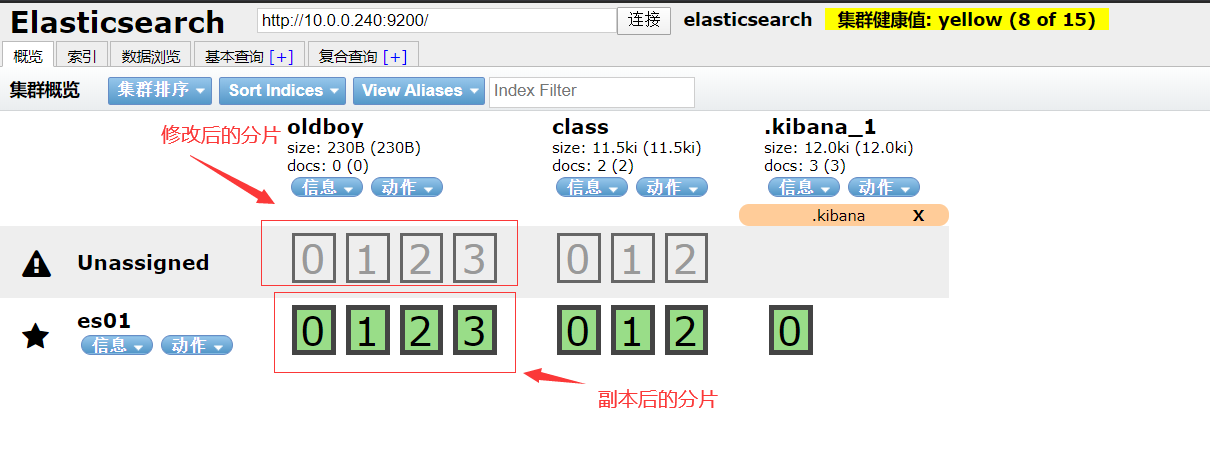
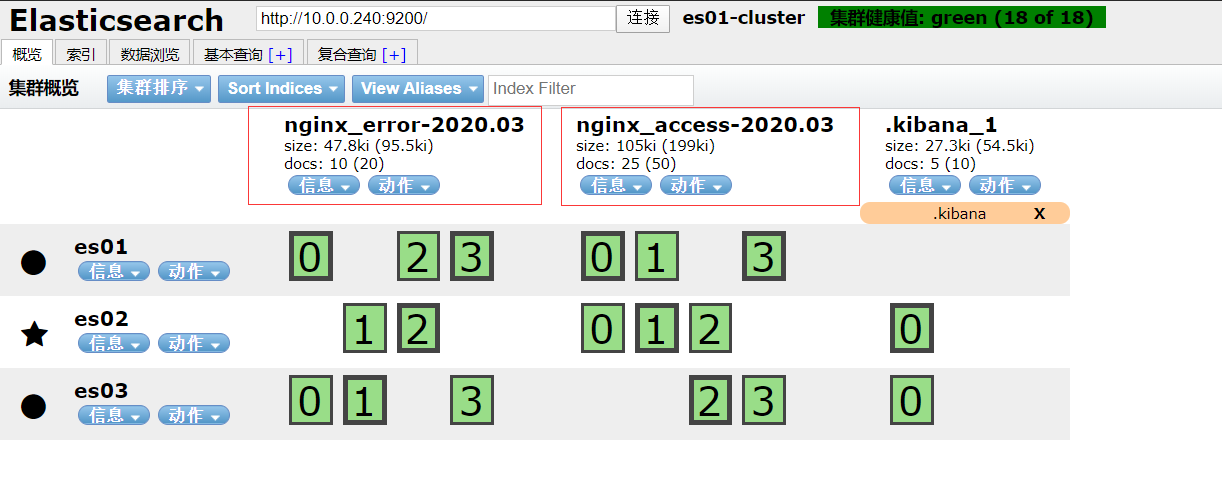
head检查集群是否正常运行
注:粗框是主分片,细框是副本分片
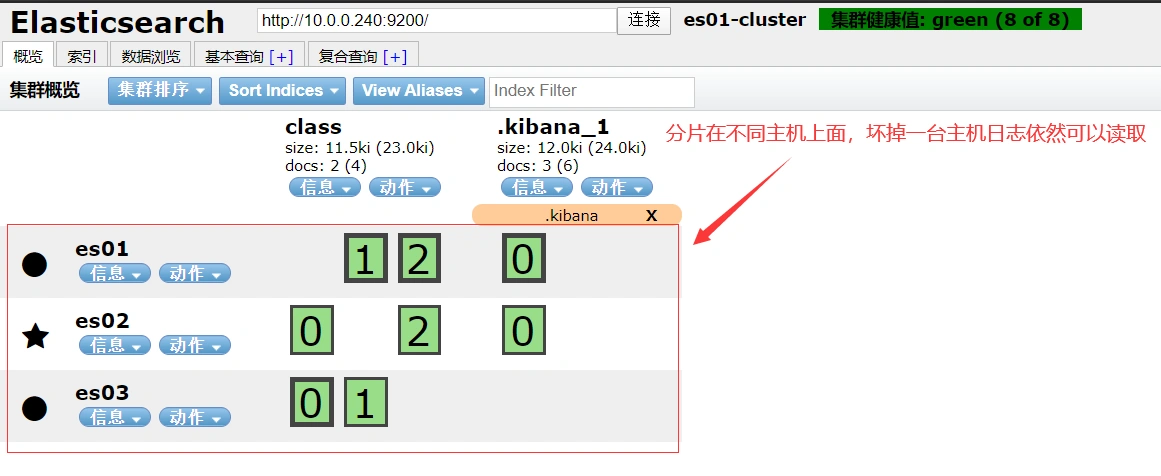
分片和副本的含义
- 分片:把存储到索引里面的数据,分隔一块块的,均匀的存储到不同的节点上面,构成分布式存储分担集群的压力
- 分片各类:分片 和 副本分片
- 主分片:主要是响应修改数据的请求,同时提供查询功能
- 副本分片:主要是提供查询的功能
- 副本:副本就是主分片的备份
台服务器集群,最多可以宕机多少台
- 如果一台一台的宕机,最多可以宕机2台,(需要手动修改配置文件才能保障服务正常使用),正常情况下,一台一台的宕机(宕机一台修好一台,不影响集群的健康状态)
- 前提是1副本,如果同时宕机2台,那么数据就会丢失,集群处于红色状态
- 前提是2个副本,如果同一台一台的宕机没有什么影响,即使是同时宕机2台,通过修改配置文件,也可以正常提供服务。
生产中注意事项
- 索引一但创建成功,分片的数量是不能再修改,但是副本的数量可以人为的修改
- 分片数量多少合适,如果集群中有3个节点,分片的数量为3*3个
- 在配置主机相互发现时,可以两两主机串起来配置
如何监控集群运行状态
curl '10.0.0.240:9200/_cluster/health?pretty' #kibana界面 GET _cat/nodes GET _cat/health
部署备份索引工具elasticdump
- 编译安装nodejs
# 下载 cd /opt wget https://nodejs.org/dist/v13.11.0/node-v13.11.0-linux-x64.tar.xz # 解压 tar xf node-v13.11.0-linux-x64 mv node-v13.11.0-linux-x64 nodejs ##解压以后测试是否成功安装 cd node.js ./bin/node -v v13.11.0 --版本号 ##设置软连接 ln -s /optnodejs/bin/node /usr/local/bin/node ln -s /opt/nodejs/bin/npm /usr/local/bin/npm #使用国内淘宝镜像源(可能需要等几分钟) npm install -g cnpm --registry=https://registry.npm.taobao.org
注:这里git已经安装,下面直接安装hexo 安装命令yum install git -y
- 安装elasticdump
官网地址:https://github.com/taskrabbit/elasticsearch-dump
#安装es-dump,执行完这里请看下边备注 cnpm install elasticdump -g #指定索引备份命令 mkdir /data elasticdump \ --input=http://10.0.0.240:9200/class \ --output=/data/class.json \ --type=data #通过备份的数据来恢复 elasticdump \ --input=/data/class.json \ --output=http://10.0.0.240:9200/class #把索引可以备份为一个压缩文件的形式(如果要恢复,必须要解压) elasticdump \ --input=http://10.0.0.240:9200/class \ --output=$ \ | gzip > /data/class.json.gz #注意 #恢复的时候需要先解压缩成json #恢复的时候,如果已经存在相同的数据,会被覆盖掉 #如果新增加的数据,则不影响,继续保留
备注:使用nodejs_12.16.1会导致不兼容的情况,需要升级
npm install -g n n latest
中文分词器
有些词语原本不是一个词语,通过中文分词器,人为的把不是一个词语的词,当成一个完整的词语,然后存到es内部的词典当中。
下载安装包
官方下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
#下载到指定目录 cd /opt/es-software #使用命令安装(如果集群有多台机器,每台服务器都要安装) cd /usr/share/elasticsearch /usr/share/elasticsearch/bin/elasticsearch-plugin install file:///opt/es-software/elasticsearch-analysis-ik-6.6.0.zip #把es服务重启一下 systemctl restart elasticsearch #创建一个新的索引(在kibana界面) PUT news #应用中文分词器的模板 curl -XPOST http://localhost:9200/news/text/_mapping -H 'Content-Type:application/json' -d' { "properties": { "content": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" } } }' #往已创建好的索引里面写数据 POST /news/text/1 {"content":"美国留给伊拉克的是个烂摊子吗"} POST /news/text/2 {"content":"公安部:各地校车将享最高路权"} POST /news/text/3 {"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"} POST /news/text/4 {"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"} #通过kibana进行验证词语是否能正常切分 POST /news/_search { "query" : { "match" : { "content" : "中国" }}, "highlight" : { "pre_tags" : ["<tag1>", "<tag2>"], "post_tags" : ["</tag1>", "</tag2>"], "fields" : { "content" : {} } } }
热动态更新词典
#安装nginx服务 yum install nginx -y #添加一个配置文件(gbk字符会出现冲突,如果发有问题,可以删除gbk) cd /etc/nginx/conf.d/ vim www.conf server { listen 80; server_name elk.oldboy.com; location / { root /usr/share/nginx/html/download; charset utf-8,gbk; autoindex on; autoindex_localtime on; autoindex_exact_size off; } } #检查代码是否误 nginx - t systemctl start nginx #创建目录 mkdir /usr/share/nginx/html/download #新建一个文件,存放临时要加入的词语 vim dic.txt 老男孩 老朋友 。。。 #域名解析 要修改一下host文件 10.0.0.240 elk.oldboy.com #在浏览器中测试一下,(当dic.txt文件发生改变时,关注modifily-time etag是否发生变化) elk.oldboy.com #修改IKAnalyzer.cfg.xml(集群中要是有多台服务器,每台服务器都要修改) cd /etc/elasticsearch/analysis-ik vim IKAnalyzer.cfg.xml <entry key="remote_ext_dict">http://10.0.0.240/download/dic.txt</entry> #重启elasticsearch服务 systemctl restart elasticsearch #关注日志文件,看是否有扩展的字典内容加载,如果有加载说明扩展词典已经生效 #在kibana界面测试,根据我们新加入的词语,来创建一个词条 POST /news/text/6 {"content":"北京老女孩教育"} POST /news/text/7 {"content":"北京老男孩教育余小闯"} #当词条写入成功之后,可以用命令检查 POST /news/_search { "query" : { "match" : { "content" : "余小闯" }}, "highlight" : { "pre_tags" : ["<tag1>", "<tag2>"], "post_tags" : ["</tag1>", "</tag2>"], "fields" : { "content" : {} } } }
- 查看
elasticsearch日志,字典更新是否完成
tail -f /var/log/elasticsearch/es01-cluster.log [2020-03-20T22:28:00,576][INFO ][o.w.a.d.Monitor ] [es01] 老男孩 [2020-03-20T22:28:00,578][INFO ][o.w.a.d.Monitor ] [es01] 老朋友 [2020-03-20T22:28:10,586][INFO ][o.w.a.d.Monitor ] [es01] 重新加载词典... [2020-03-20T22:28:10,587][INFO ][o.w.a.d.Monitor ] [es01] try load config from /etc/elasticsearch/analysis-ik/IKAnalyzer.cfg.xml [2020-03-20T22:28:10,999][INFO ][o.w.a.d.Monitor ] [es01] [Dict Loading] http://10.0.0.240/download/dic.txt [2020-03-20T22:28:11,030][INFO ][o.w.a.d.Monitor ] [es01] 老男孩 [2020-03-20T22:28:11,030][INFO ][o.w.a.d.Monitor ] [es01] 老朋友 [2020-03-20T22:28:11,030][INFO ][o.w.a.d.Monitor ] [es01] 重新加载词典完毕.
收集日志的作用
1、今天上午10点访问web站点排名前10的ip 2、统计今天访问前10的url 3、把今天上午10点之前访问量排名前10的ip和昨天这个时间段对比一下,有什么区别 4、发现页面的响应时间超1s,导致web服务响应过慢,找出是否爬虫ip 5、信息在5分钟内给我结果
- 工作中哪些服务器需要收集日志
代理层:nginx
web层:nginx tomcat php java
数据库:mysql mariadb es mongo
系统层:message rsyslog secure
使用filebeat收集nginx日志
安装nginx服务
#准备epel源 wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo #安装nginx yum install nginx -y #添加配置文件 cd /etc/nginx/conf.d/ vim www.conf server { listen 80; server_name elk.oldboy.com; location / { root /code/www; index index.html index.htm; } } #创建目录 mkdir /code/www -p echo "Hello china Search Nginx Log! " > /code/www/index.html #启动nginx服务 nginx -t systemctl start nginx #如果配置了域名,要记得做域名解析 #在浏览器中访问,可以产生一些访问日志 win10HOST解析 elk.oldboy.com
部署filebeat软件
#上传需要安装的软件包并安装 rpm -ivh filebeat-6.6.0-x86_64.rpm #修改配置文件 vim /etc/filebeat/filebeat.yml [root@web01-243 es-software]# egrep -v '^$|#' /etc/filebeat/filebeat.yml filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/access.log output.elasticsearch: hosts: ["10.0.0.240:9200"] #启动filebeat服务 systemctl start filebeat #在head插件界面,检查是否日志已经收集成功
- 插件显示的信息
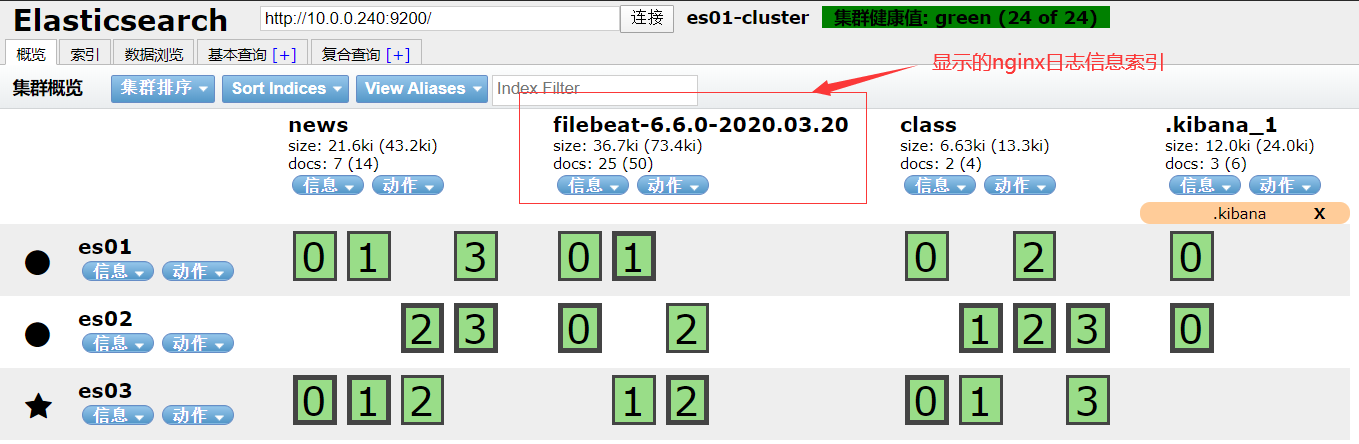
在kibana界面添加index-patterns
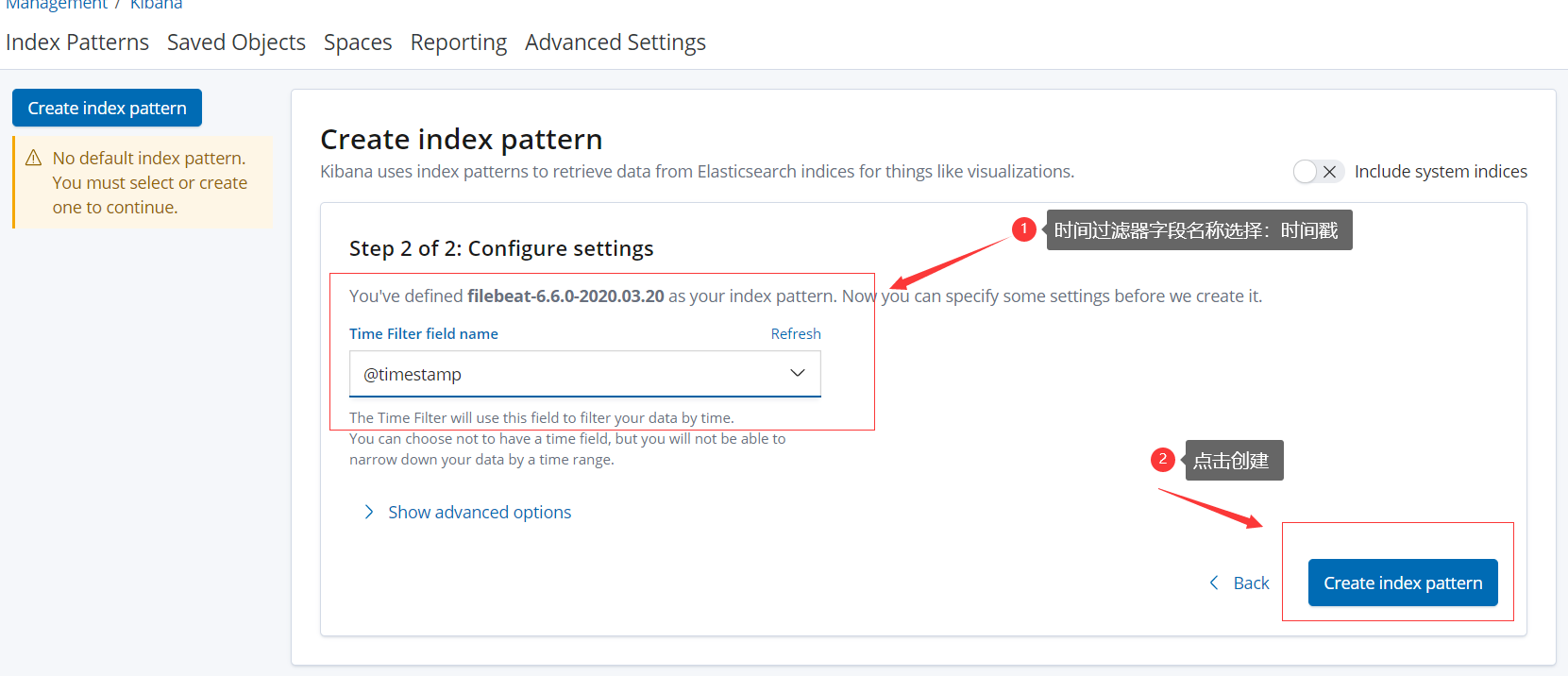
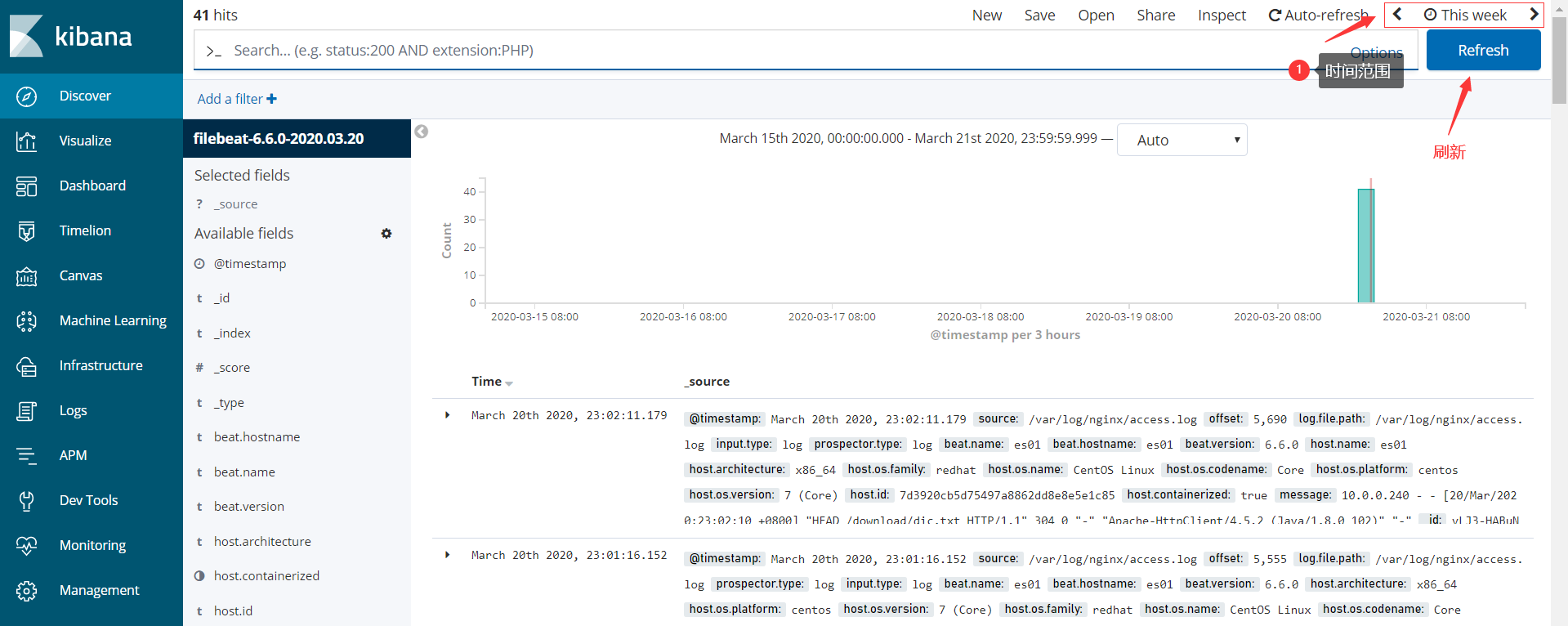
在kibana界面展示收集到的日志信息
使用filebeat收集nginx的json日志
json格式转换官网:https://www.json.cn/
#修改nginx的配置文件 vim /etc/nginx/nginx.conf log_format json '{ "time_local": "$time_local", ' '"remote_addr": "$remote_addr", ' '"referer": "$http_referer", ' '"request": "$request", ' '"status": $status, ' '"bytes": $body_bytes_sent, ' '"agent": "$http_user_agent", ' '"x_forwarded": "$http_x_forwarded_for", ' '"up_addr": "$upstream_addr",' '"up_host": "$upstream_http_host",' '"upstream_time": "$upstream_response_time",' '"request_time": "$request_time"' ' }'; access_log /var/log/nginx/access.log json; #检查代码是否有误 nginx -t #重启nginx服务 systemctl restart nginx #通过浏览器来访问nginx站点,生产日志,确保日志格式是json #虽然nginx日志格式已经为json格式,但是filebeat无法解析json格式的日志(格式对齐) mv /etc/filebeat/filebeat.yml /etc/filebeat/filebeat.yml.bak cat >/etc/filebeat/filebeat.yml<<EOF filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/access.log json.keys_under_root: true json.overwrite_keys: true output.elasticsearch: hosts: ["10.0.0.240:9200"] EOF #重启filebeat服务 systemctl restart filebeat ps -ef | grep filebeat #在head插件界面,检查日志是否收集成功,是已经把日志切分开

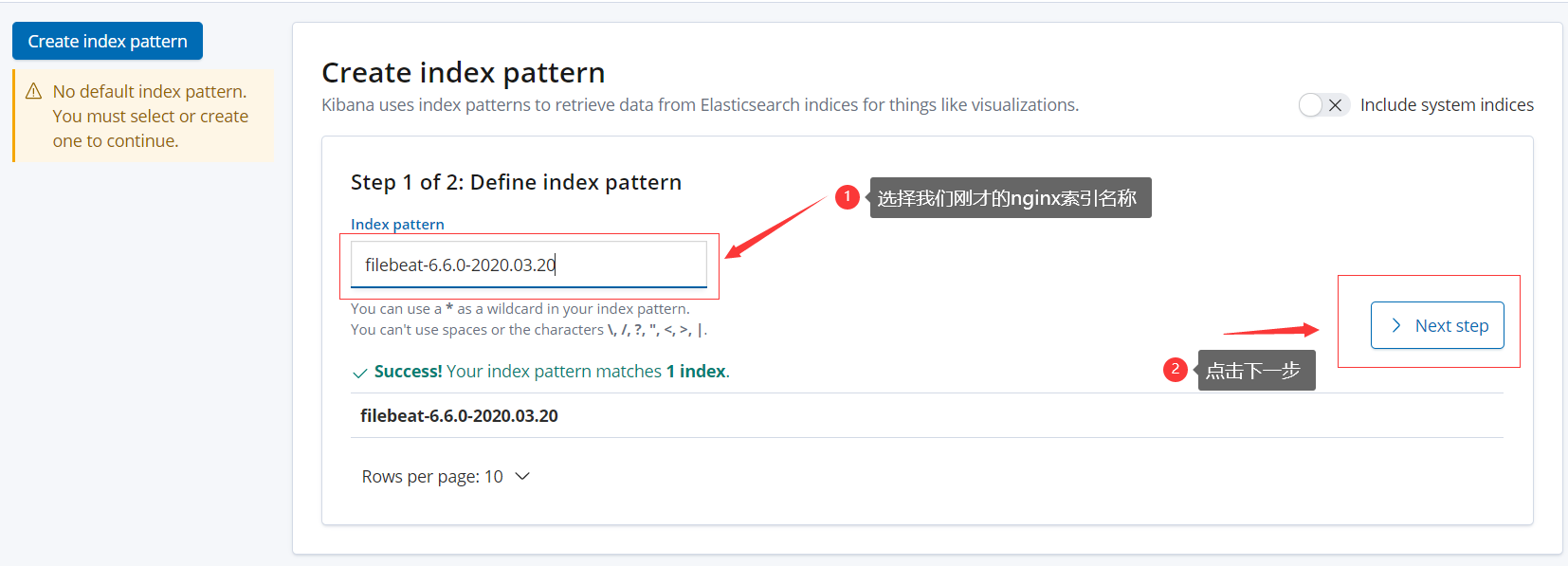
在kibana界面添加index-patterns
1、索引名称可以自定 2、把日志可以按月来收集,如果按天收集太乱 3、如果使用自定义的模板,要加入相应的配置信息
收集nginx的两种日志
#修改filebeat的配置文件 vim filebeat.yml filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/access.log json.keys_under_root: true json.overwrite_keys: true - type: log enabled: true paths: - /var/log/nginx/error.log output.elasticsearch: hosts: ["10.0.0.240:9200"] indices: - index: "nginx-access-%{[beat.version]}-%{+yyyy.MM}" when.contains: source: "/var/log/nginx/access.log" - index: "nginx-error-%{[beat.version]}-%{+yyyy.MM}" when.contains: source: "/var/log/nginx/error.log" #自定义一个模板名称 setup.template.name: "nginx" #模板格式 setup.template.pattern: "nginx-*" setup.template.enabled: false #覆盖以前的模板 setup.template.overwrite: true #重新启动服务 systemctl restart filebeat #在head界面把之前的老索引删除 #重新再生产一些访问的日志和错误日志 #再回到head界面检查日志是否正常收集
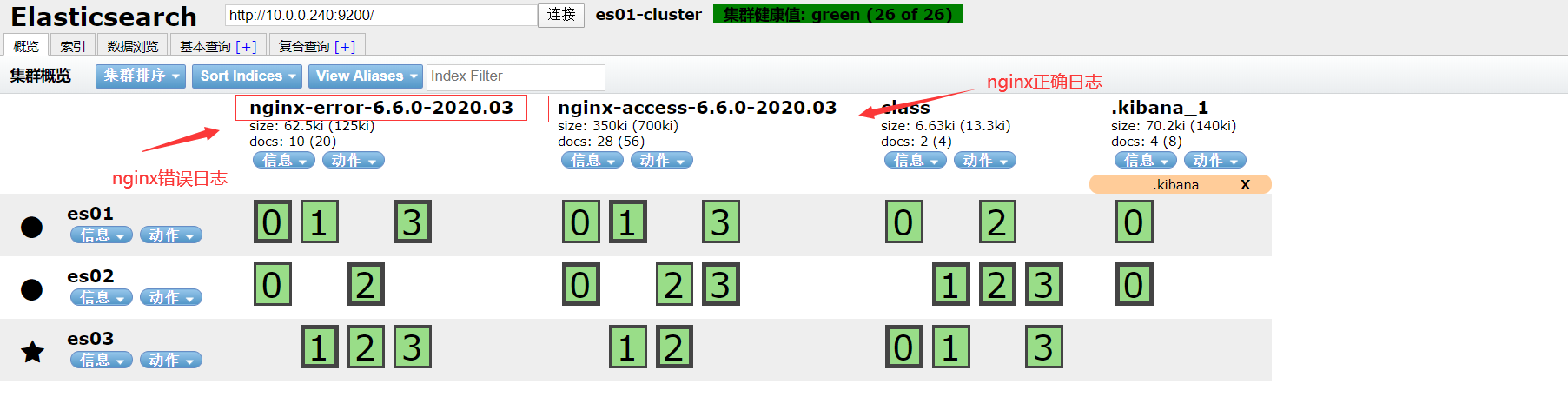
filebeat的nginx模块功能,收集nginx普通日志
#修改nginx日志的格式 vim /etc/nginx/nginx.conf access_log /var/log/nginx/access.log main; #检查语法 nginx -t #启动nginx服务 systemctl start nginx #检查日志信息
打开nginx模块
#进入相应的目录 cd /etc/filebeat/modules.d #打开nginx模块功能 filebeat modules enble nginx mv nginx.yml.disabled nginx.yml #修改nginx模块 vim nginx.yml - module: nginx access: enabled: true var.paths: ["/var/log/nginx/access.log"] error: enabled: true var.paths: ["/var/log/nginx/error.log"] #修改filebeat的主配置文件 vim /etc/filebeat/filebeat.yml output.elasticsearch: hosts: ["10.0.0.240:9200"] indices: - index: "nginx-error-%{[beat.version]}-%{+yyyy.MM}" when.contains: fileset.name: "error" - index: "nginx-access-%{[beat.version]}-%{+yyyy.MM}" when.contains: fileset.name: "access" setup.template.name: "nginx" setup.template.pattern: "nginx-*" setup.template.enabled: false setup.template.overwrite: true filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: true reload.period: 10s #重启filebeat服务 systemctl restart filebeat #发现es缺少相关的插件(如果是集群,每台服务器都要安装) 2020-03-20T12:56:11.819+0800 ERROR pipeline/output.go:100 Failed to connect to backoff(elasticsearch(http://10.0.0.240:9200)): Connection marked as failed because the onConnect callback failed: Error loading pipeline for fileset nginx/access: This module requires the following Elasticsearch plugins: ingest-user-agent, ingest-geoip. You can install them by running the following commands on all the Elasticsearch nodes: sudo bin/elasticsearch-plugin install ingest-user-agent sudo bin/elasticsearch-plugin install ingest-geoip #解决方法,需要在每中es服务器上面安装两个插件 cd /usr/share/elasticsearch/ ./bin/elasticsearch-plugin install file:///opt/es-software/ingest-geoip-6.6.0.zip ./bin/elasticsearch-plugin install file:///opt/es-software/ingest-user-agent-6.6.0.zip #个节点重启es服务和filebeat服务 systemctl restart elasticsearch systemctl restart filebeat #在head界面验证日志是否正常收集
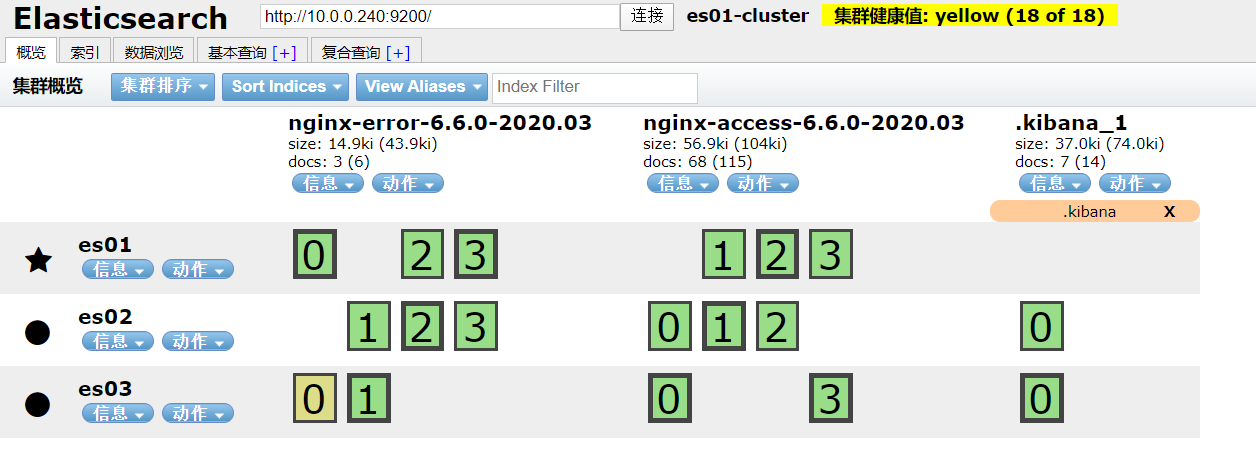
使用filebeat收集tomcat日志
部署tomcat平台
官网文档:https://www.elastic.co/guide/en/beats/filebeat/6.6/multiline-examples.html
#上传java安装包并安装 cd /opt/es-software rpm -ivh jdk-8u102-linux-x64.rpm #上传tomcat安装包并解压 tar xf apache-tomcat-8.5.49.tar.gz -C /opt/ ln -s /opt/apache-tomcat-8.5.49 /opt/tomcat #启动tomcat服务,正常情况下会监听8080端口 cd /opt/tomcat/bin/ ./startup.sh #为了更好的分析日志,需要对tomcat的日志格式进行修改(162行) vim /opt/tomcat/conf/server.xml pattern="{"clientip":"%h","ClientUser":"%l","authenticated":"%u","AccessTime":"%t","method":"%r","status":"%s","SendBytes":"%b","Query?string":"%q","partner":"%{Referer}i","AgentVersion":"%{User-Agent}i"}"/> #重启tomcat服务,让修改后的配置文件生效 ./shutdown.sh ./startup.sh #在浏览器中再次访问tomcat首页,产生一些新的日志 #把新的json日志,做校验处理,是否符合json格式
修改filebeat的配置文件
#进行filebeat主配置文件所在的目录 cd /etc/filebeat/ vim filebeat.yml [root@web01-243 logs]# cat /etc/filebeat/filebeat.yml filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/access.log json.keys_under_root: true json.overwrite_keys: true tags: ["access"] - type: log enabled: true paths: - /var/log/nginx/error.log tags: ["error"] - type: log enabled: true paths: - /opt/tomcat/logs/localhost_access_log.2020-03-21.txt json.keys_under_root: true json.overwrite_keys: true tags: ["tomcat"] output.elasticsearch: hosts: ["10.0.0.240:9200"] indices: - index: "nginx-access-%{[beat.version]}-%{+yyyy.MM}" when.contains: tags: "access" - index: "nginx-error-%{[beat.version]}-%{+yyyy.MM}" when.contains: tags: "error" - index: "tomcatl-access-%{[beat.version]}-%{+yyyy.MM}" when.contains: tags: "tomcat" setup.template.name: "nginx" setup.template.pattern: "nginx-*" setup.template.enabled: false setup.template.overwrite: true #重启filebeat服务 systemctl restart filebeat ps -ef | grep filebeat #到head插件界面验证,日志是否能正常收集
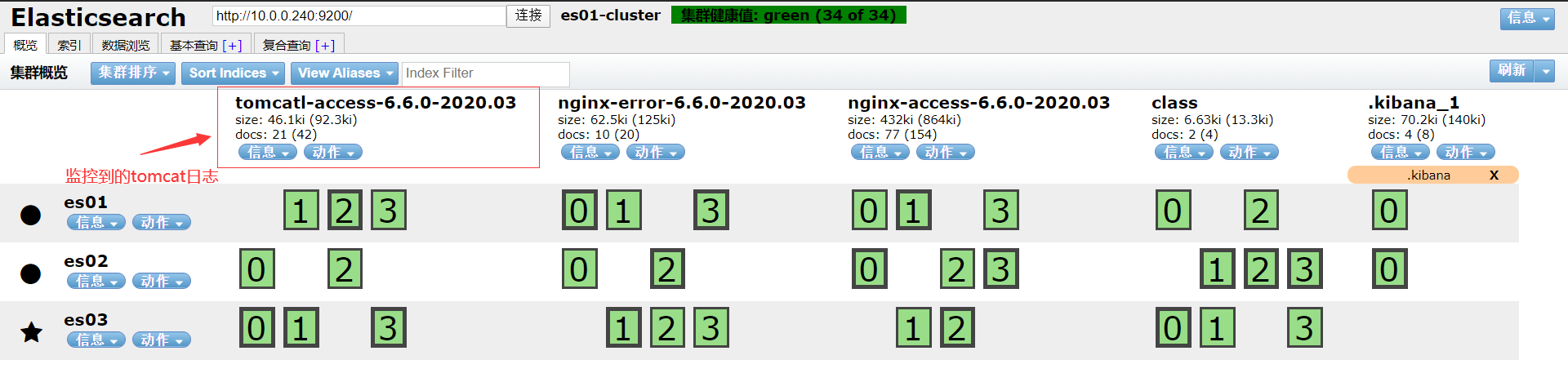
在kibana界面展示tomcat日志
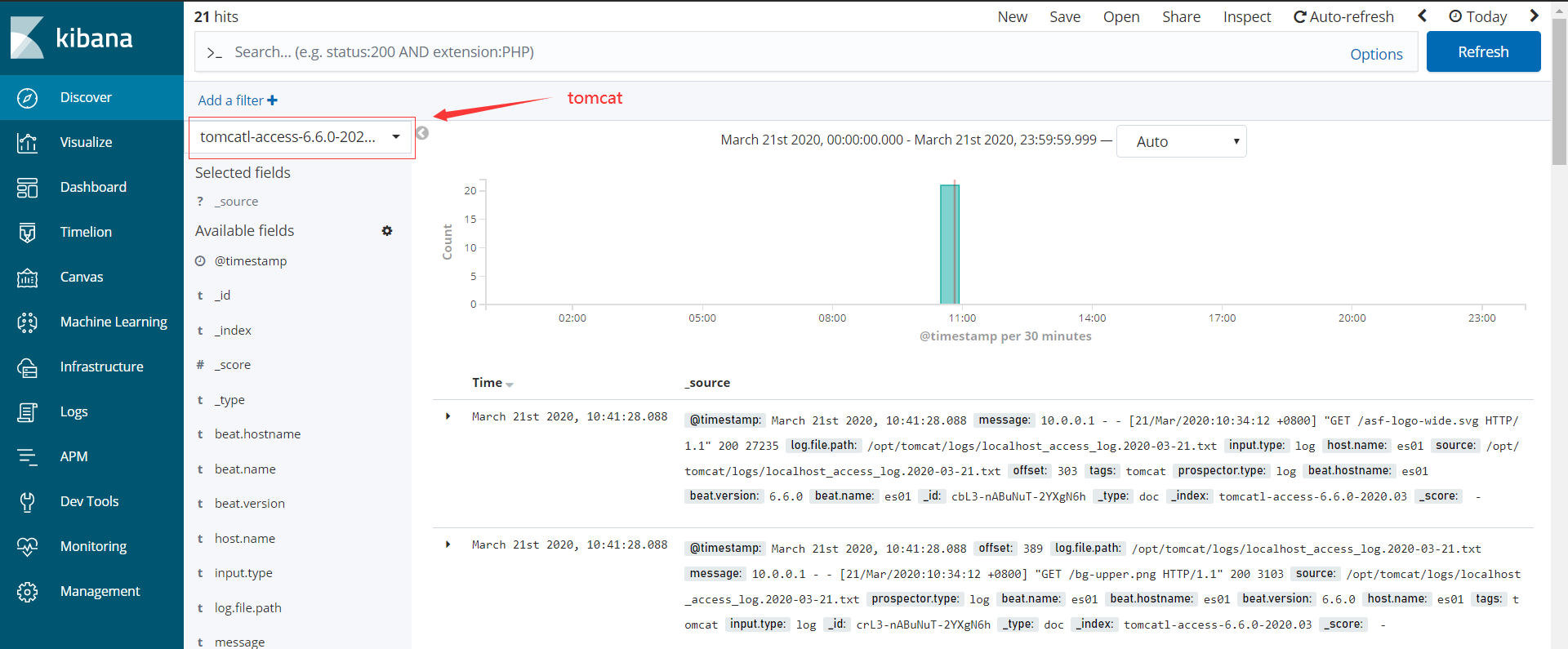
使用filebeat收集java日志
部署一个java环境
#使用elasticsearch这个环境,修改es的配置文件 vim /etc/elasticsearch/elasticsearch.yml aanode.name: oldboy02 #重启es服务 systemctl restart elasticsearch #使用命令查看elasticsearch日志信息,发现有报错的信息输出 tail -f /var/log/ealsticsearch/elasticsearch.log
安装收集日志工具
#安装filebeat工具,修改相应的主配置文件,把默认的配置文件改一名 vim /etc/filebeat/filebeat.yml filebeat.inputs: - type: log enabled: true paths: - /var/log/elasticsearch/elasticsearch.log multiline.pattern: '^\[' multiline.negate: true multiline.match: after output.elasticsearch: hosts: ["10.0.0.240:9200"] - index: "es-%{[beat.version]}-%{+yyyy.MM}" setup.template.name: "es" setup.template.pattern: "es-*" setup.template.enabled: false setup.template.overwrite: true #重启filebeat服务 systemctl restart filebeat #head界面检查日志是否能正常收集
在kibana界面展示收集的日志信息
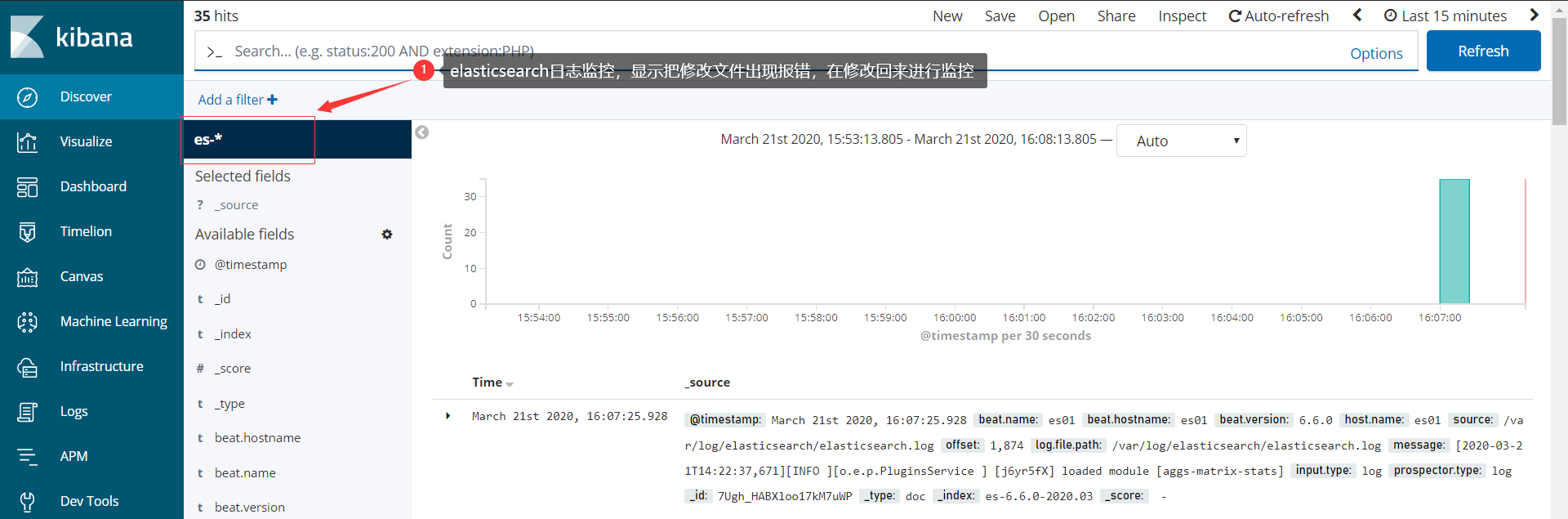
使用filebeat收集MySQL慢日志
部署一个MySQL环境
#安装mariadb yum install mariadb-server -y #启动mariadb服务 systemctl start mariadb #确认慢日志功能是否开启 show variables like '%slow_query_log%'; --------------------+--------------------+ | Variable_name | Value | +---------------------+--------------------+ | slow_query_log | OFF | | slow_query_log_file | web01-243-slow.log #开启慢日志功能 vim /etc/my.cnf [mysqld] slow_query_log=ON slow_query_log_file=/var/log/mariadb/slow.log long_query_time=1 #重新启动mariadb服务 systemctl restart mariadb #生成一些慢查询语句 mysql select sleep(2) user,host from mysql.user; #确认慢日志是否生成 cat /var/log/mariadb/slow.log
修改配置文件,启用filebeat对应的模块
#开启模块化功能(加动配置文件最下方) vim /etc/filebeat/filebeat.yml filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: true reload.period: 10s #重启filebeat服务 systemctl restart filebeat #打开mysql模块(也可以通过修改模块的名称来开启) filebeat modules list filebeat modules enable mysql #修改mysql模块配置 vim /etc/filebeat/modules.d/mysql.yml - module: mysql error: enabled: true var.paths: ["/var/log/mariadb/mariadb.log"] slowlog: enabled: true var.paths: ["/var/log/mariadb/slow.log"] #修改filebeat的主配置文件 vim /etc/filebeat/filebeat.yml output.elasticsearch: hosts: ["10.0.0.240:9200"] indices: - index: "mysql-error-%{[beat.version]}-%{+yyyy.MM}" when.contains: source: "/var/log/mariadb/mariadb.log" - index: "mysql-slow-%{[beat.version]}-%{+yyyy.MM}" when.contains: source: "/var/log/mariadb/slow.log" setup.template.name: "mysql" setup.template.pattern: "mysql-*" setup.template.enabled: false setup.template.overwrite: true filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: true reload.period: 10s #重启filebeat服务 systemctl restart filebeat #为了测试需要,别外生成一些慢日志和错误 #在head界面检查日志是否收集成功
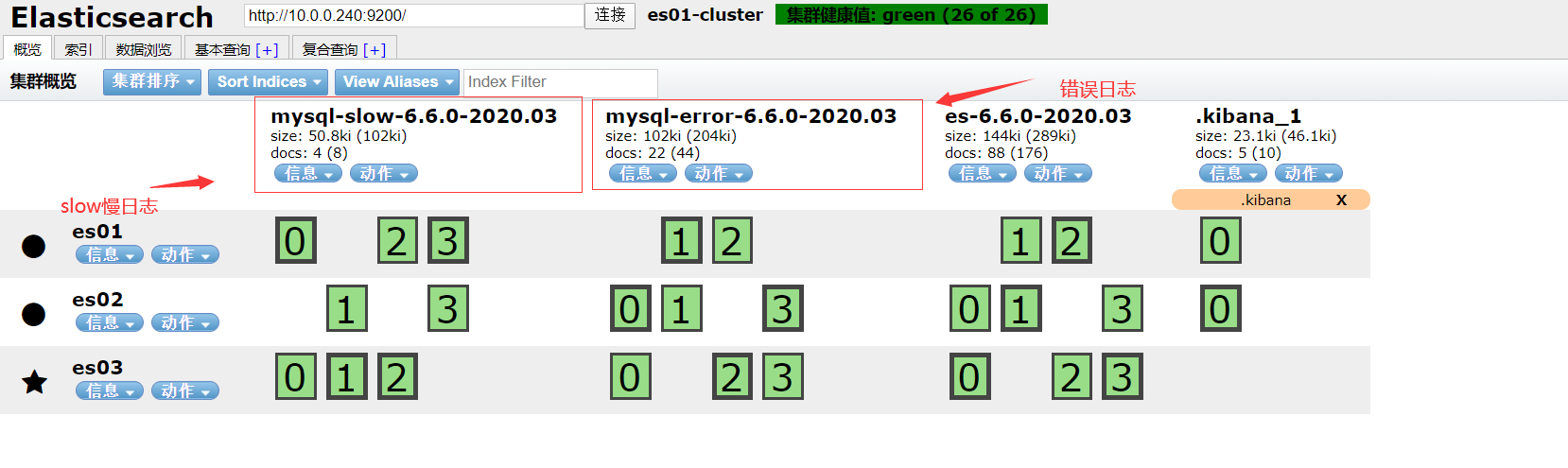
kibana界面添加index-patterns
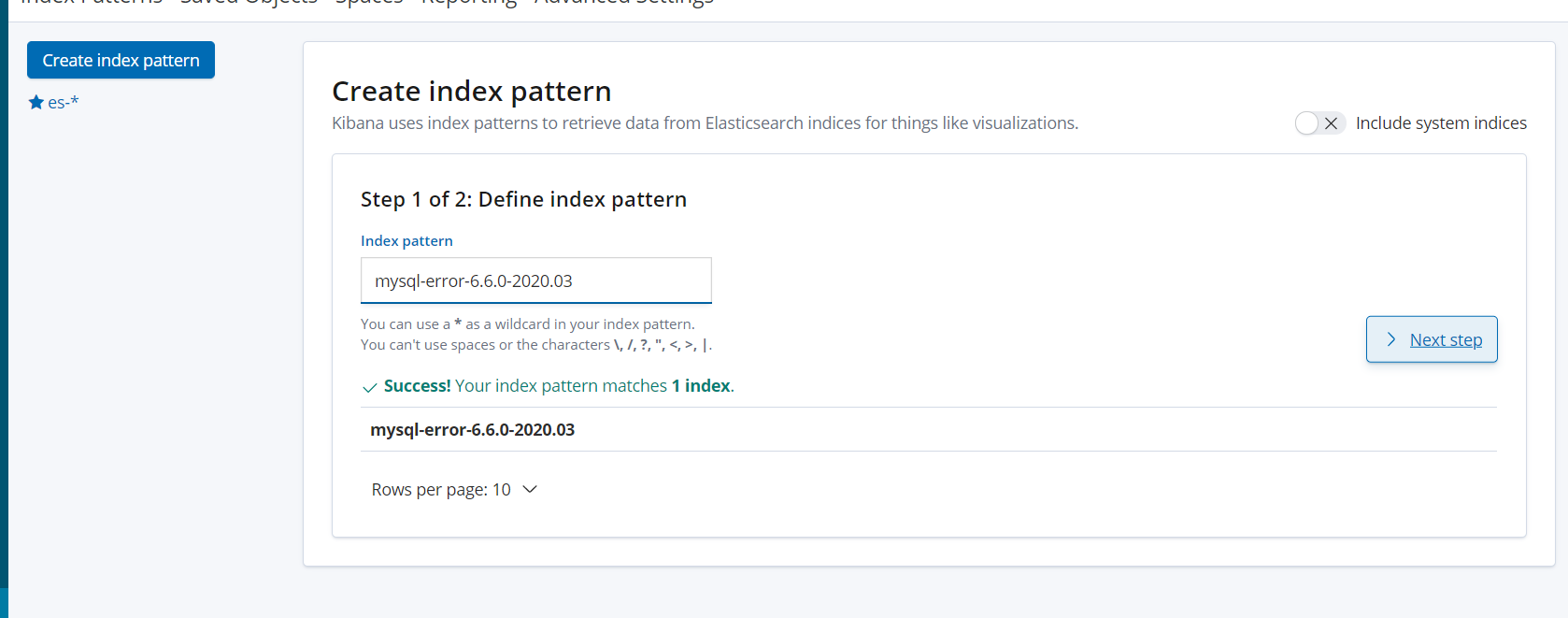
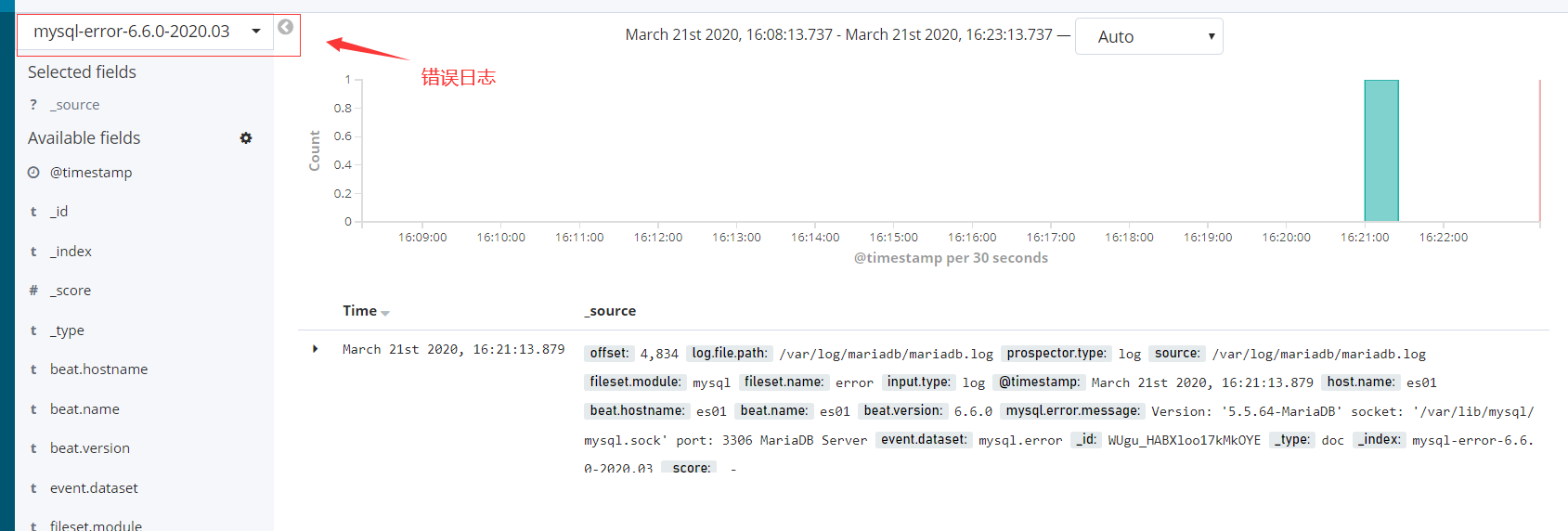
kibana界面展示收集到的日志信息
- 错误日志信息
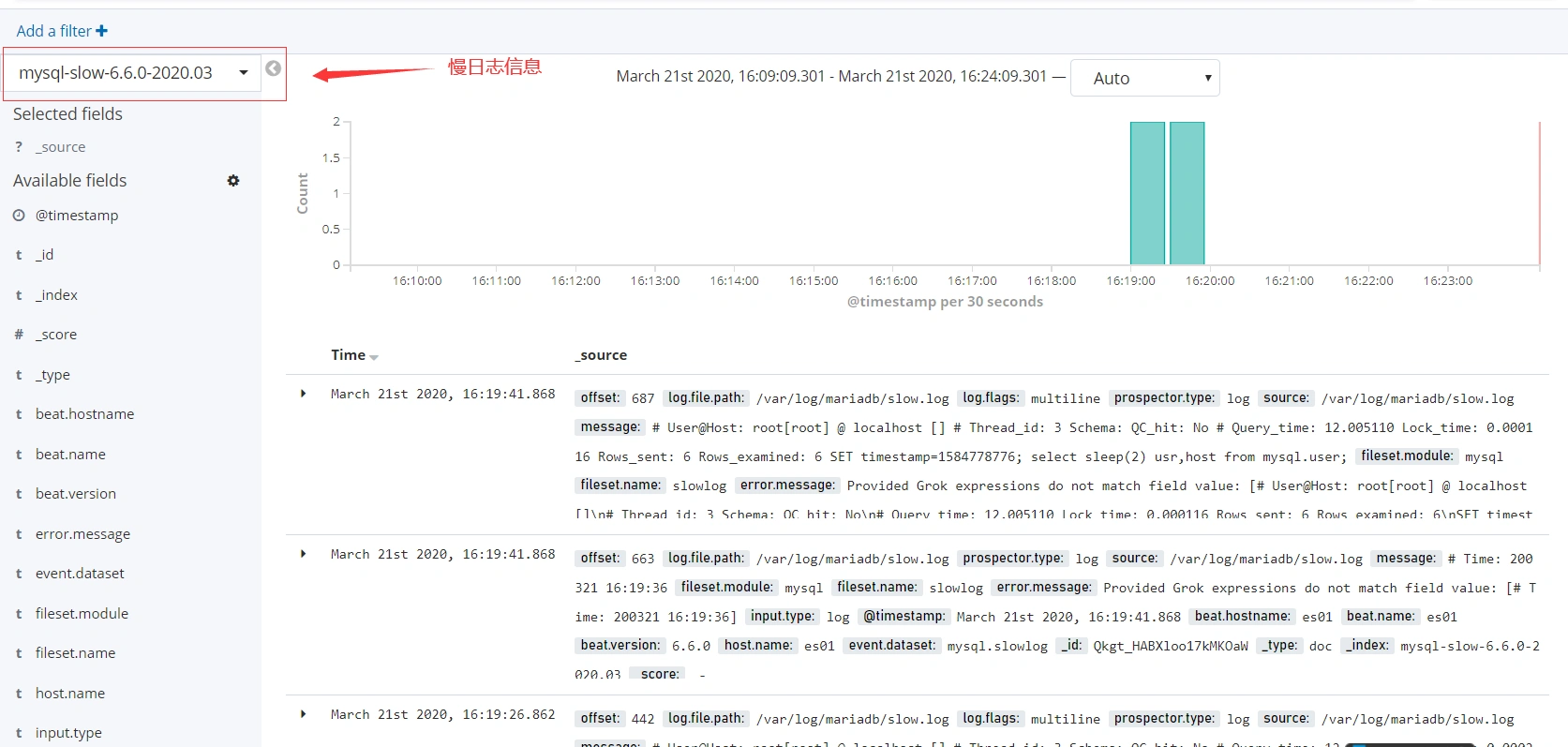
- 慢日志信息
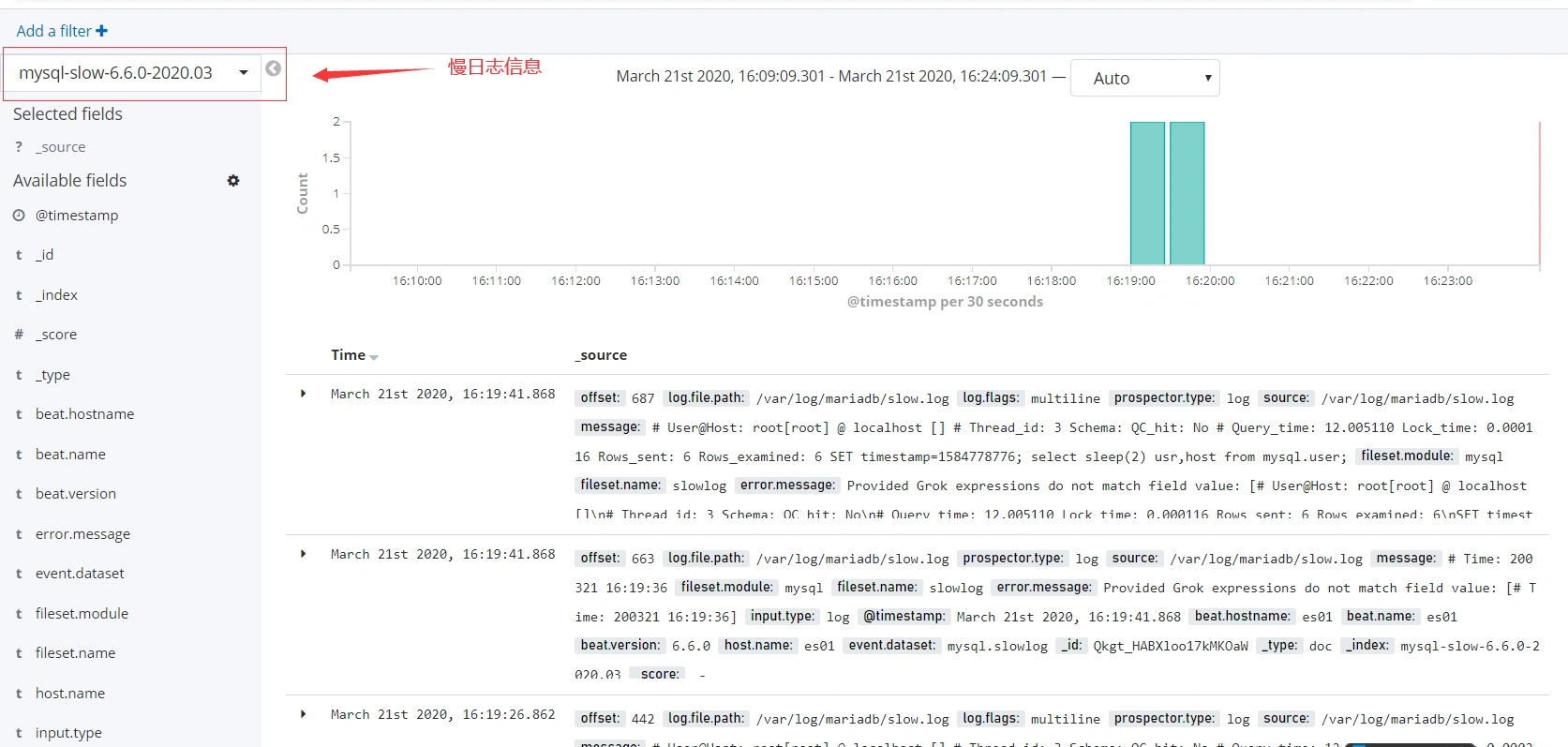
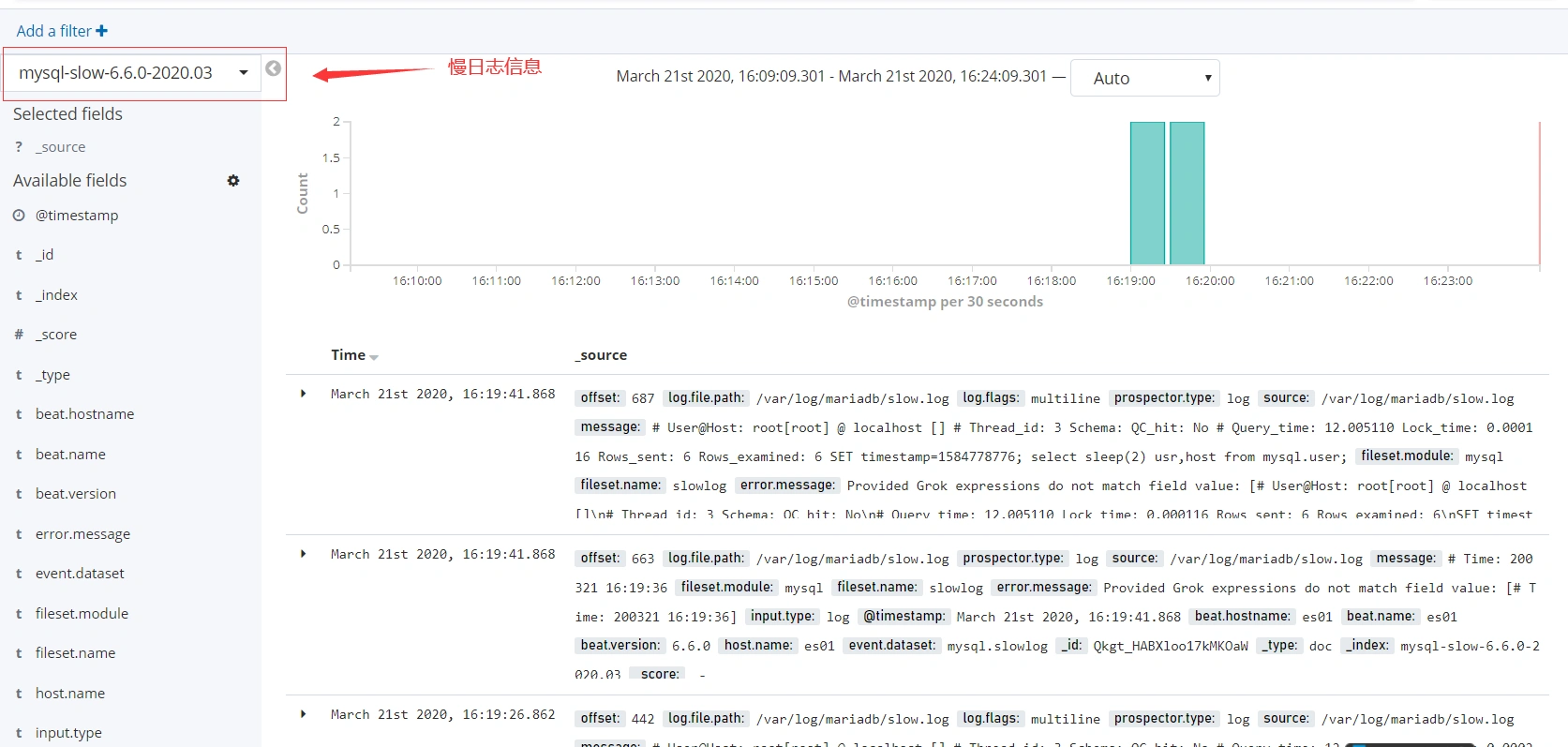
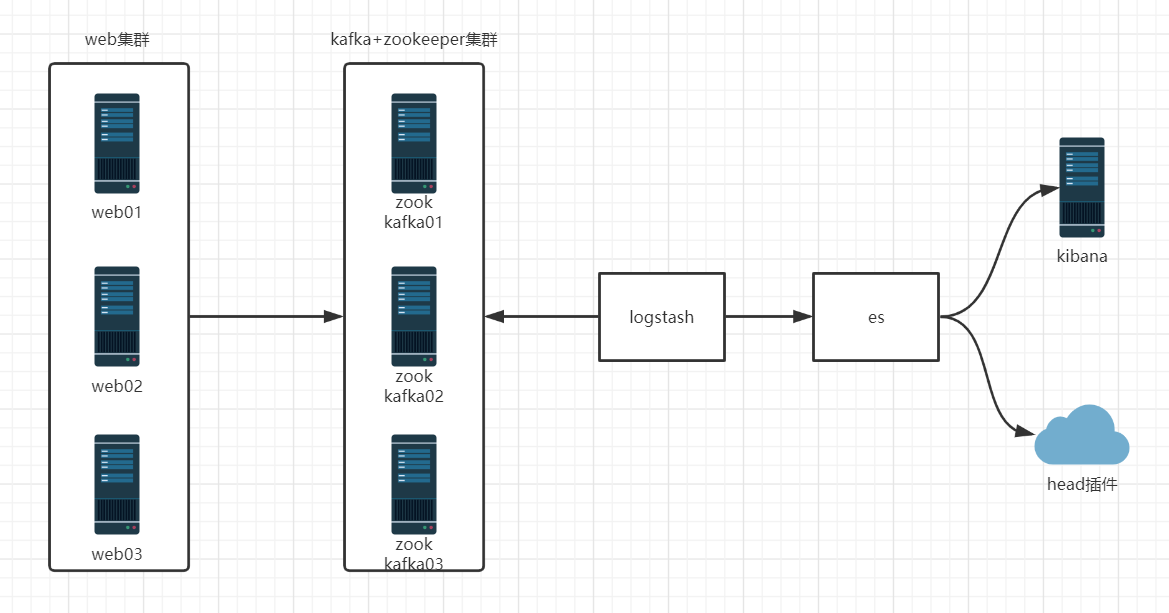
使用redis做缓存收集日志
部署redis环境
- 架构图
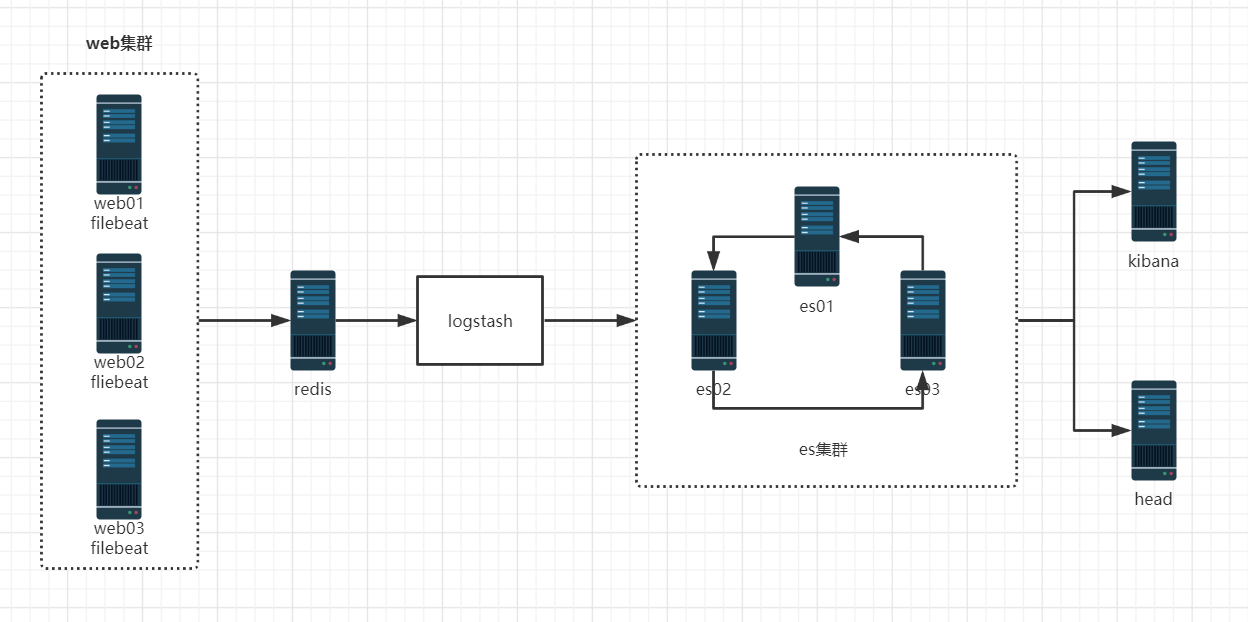
- 环境准备
| 主机名 | IP地址 | 节点 | 服务 |
| es01 | 10.0.0.240 | es-cluster、es01 | redis、logstash、es、nginx、kibana |
| es02 | 10.0.0.241 | es02 | es |
| es03 | 10.0.0.242 | es03 | es |
官方编译下载地址:https://redis.io/download
#配置epel源 wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo #安装redis yum install redis -y #修改redis配置文件 vim /etc/redis.conf bind 10.0.0.240 #启动redis服务 systemctl start redis
修改filebeat的配置文件
#把nginx的日志格式改为json #修改filebeat的主配置文件 vim /etc/filebeat/filebeat.yml filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/access.log json.keys_under_root: true json.overwrite_keys: true tags: ["access"] - type: log enabled: true paths: - /var/log/nginx/error.log tags: ["error"] output.redis: hosts: ["10.0.0.240"] keys: - key: "nginx_access" when.contains: tags: "access" - key: "nginx_error" when.contains: tags: "error" setup.template.name: "nginx" setup.template.pattern: "nginx_*" setup.template.enabled: false setup.template.overwrite: true #重启filebeat服务 systemctl restart filebeat
检查redis能否收集日志
#连接redis redis-cli -h 10.0.0.240 #使用命令检查 info db0:keys=1,expires=0,avg_ttl=0 -- > [root@es01 conf.d]# redis-cli -h 10.0.0.240 10.0.0.240:6379> keys * 1) "nginx_error" 2) "nginx_access" 10.0.0.240:6379> LLEN nginx_error (integer) 11 10.0.0.240:6379> LLEN nginx_access (integer) 44
安装logstash工具
#进入目录 cd /opt/es-software #上传logstash安装包,并安装 rpm -ivh logstash-6.6.0.rpm #添加一个配置文件 cd /etc/logstash/conf.d vim nginx_log.conf input { redis { host => "10.0.0.240" port => "6379" db => "0" key => "nginx_access" data_type => "list" } redis { host => "10.0.0.240" port => "6379" db => "0" key => "nginx_error" data_type => "list" } } filter { mutate { convert => ["upstream_time", "float"] convert => ["request_time", "float"] } } output { stdout {} if "access" in [tags] { elasticsearch { hosts => "http://10.0.0.240:9200" manage_template => false index => "nginx_access-%{+yyyy.MM}" } } if "error" in [tags] { elasticsearch { hosts => "http://10.0.0.240:9200" manage_template => false index => "nginx_error-%{+yyyy.MM}" } } } #可以放到前台测试logstash能否正常取日志(如果正常,前台会打印日志信息) /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/nginx_log.conf #在head界面验证
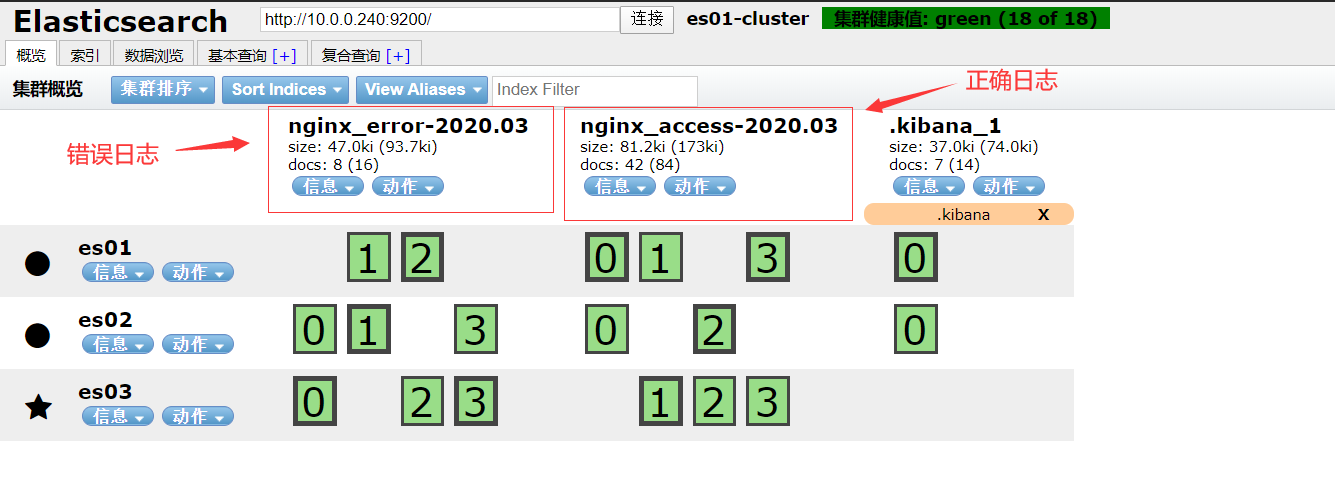
- 在kibana界面添加index-patterms
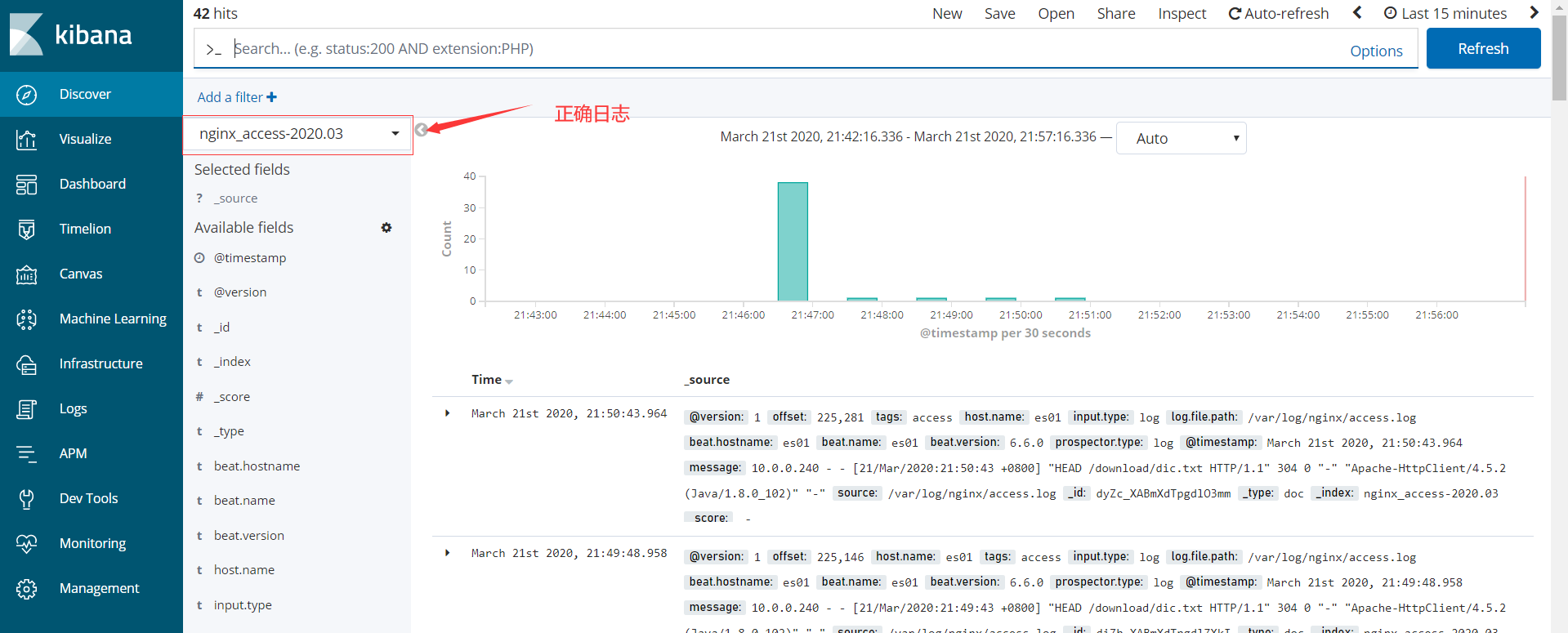
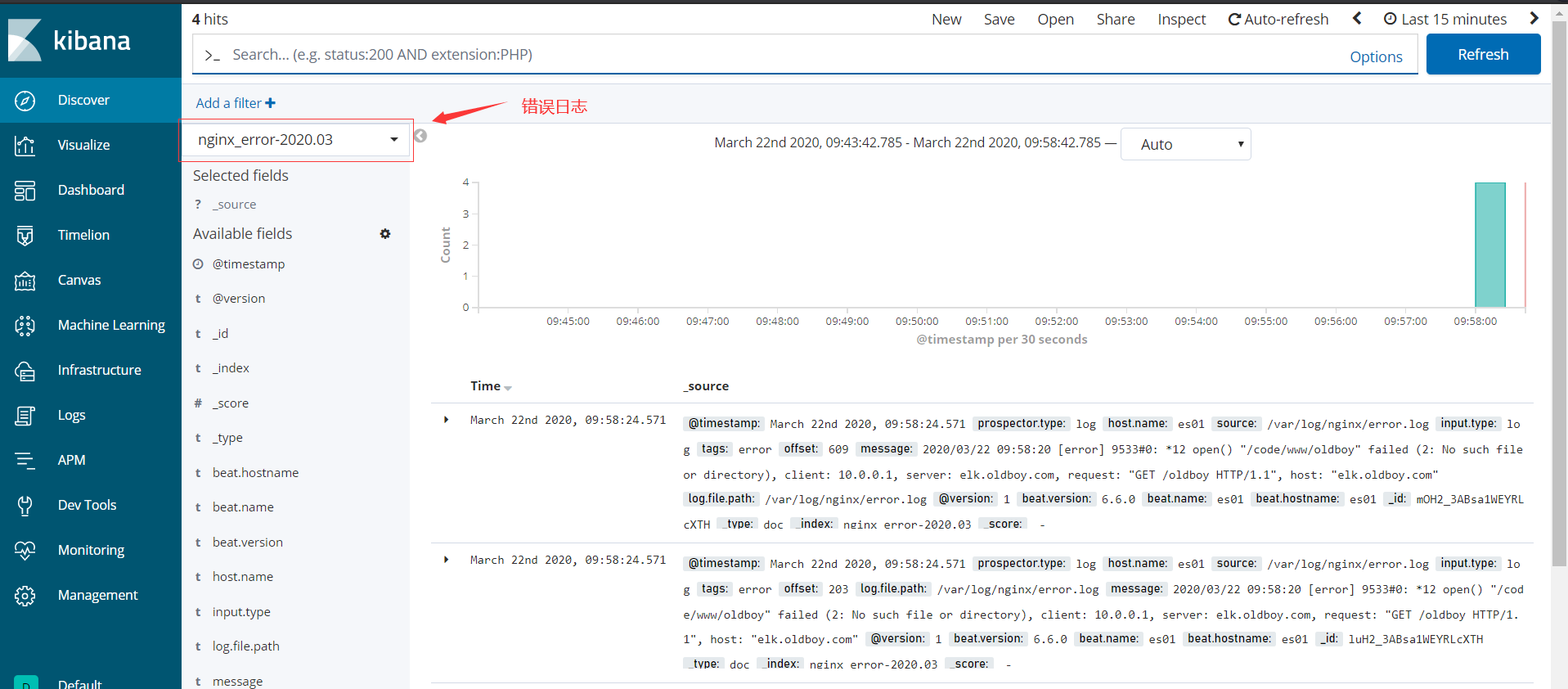
使用Kafka做缓存收集日志
- 结构图:
- 原理图:
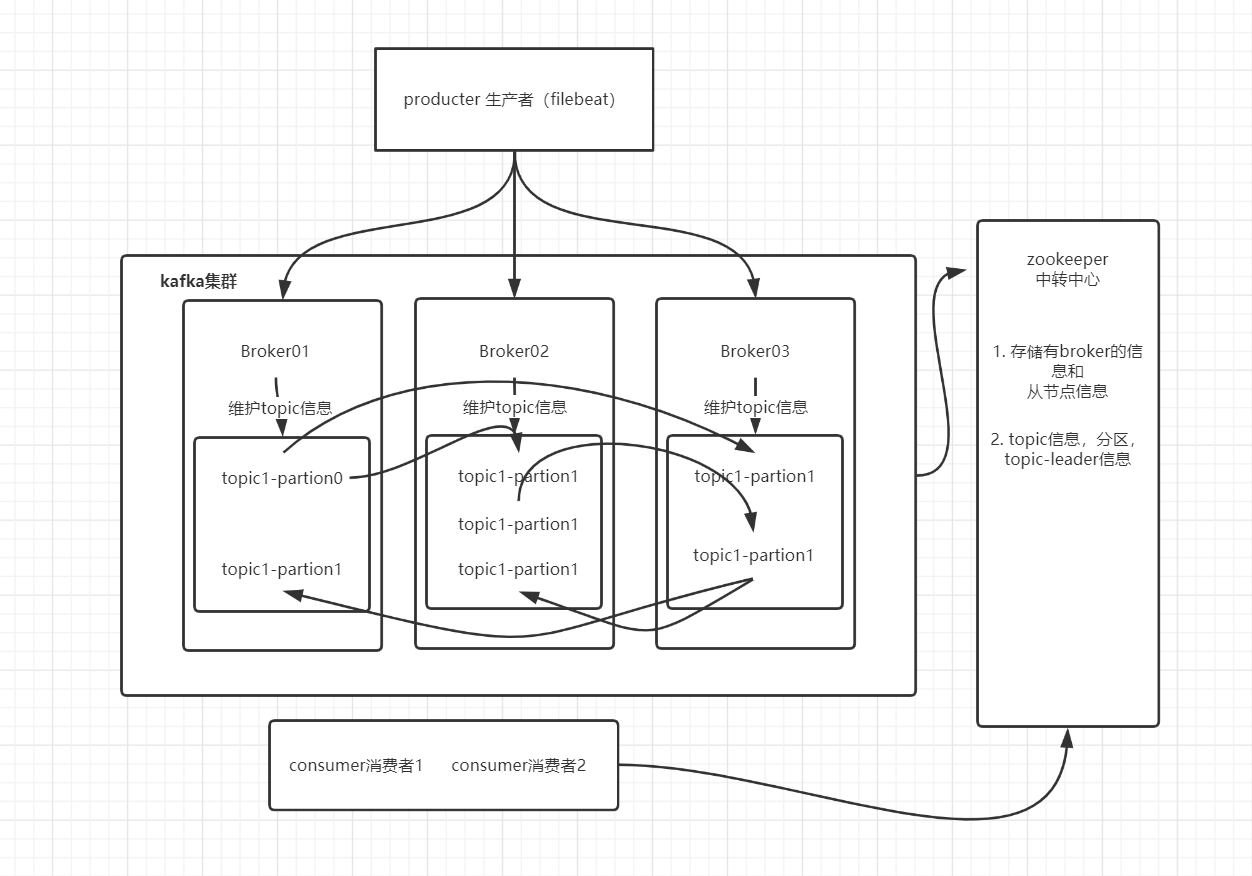
- kafka是分布式发布-订阅消息系统
- zookeeper:存储了一些关于
consumer和broker的信息 - producer 直接连接 Broker
- zookeeper:保存了topic相关配置,例如topic列表,每个topic的 partition数量、副本的位置,这些分区信息及与Broker的对应关系所有, topic的访问控制信息也是由zookeeper维护的,记录消息分区与consumer之间的关系
- broker:多个broker,其中一个会被选举为控制器。从多个broker中选出控制器,这个工作就是zookeeper负责的控制器负责管理整个集群所有分区和副本的控制,例如某个分区的leader故障了,控制器会选择新的leader
- Producer:直接连接Broker
- partition:一个topic可以分为多个partion,每个partion是一个有序的队列。
- Broker:缓存代理,kafka集群中的一台或多台服务器统称broker,存储topic
- topic:kafka处理资源的消息源(feeds of messages)的不同分类
配置hosts
注:每台主机内存建议大于3G,否则java后台进行启动失败
- 三台主机都要配置
10.0.0.240 es01 10.0.0.241 es02 10.0.0.242 es03
安装配置zookeeper
注:三台都要配置
#把需要的软件包上传 cd /opt/es_software #解压软件并做软件连接 tar zxf zookeeper-3.4.11.tar.gz -C /opt/ ln -s /opt/zookeeper-3.4.11/ /opt/zookeeper #创建一个数据目录 mkdir -p /data/zookeeper #把zoo_sample.cfg复制一个zoo.cfg文件 cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg #修改zoo.cfg配置文件 vim /opt/zookeeper/conf/zoo.cfg # 服务器之间或客户端与服务器之间维持心跳的时间间隔 # tickTime以毫秒为单位 tickTime=2000 # 集群中的follower服务器(F)与leader服务器(L)之间的初始连接心跳数 initLimit=10 # 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数 syncLimit=5 dataDir=/data/zookeeper # 客户端连接端口 clientPort=2181 # 三个接点配置,格式为: server.服务编号=服务地址、LF通信端口、选举端口 server.1=10.0.0.240:2888:3888 server.2=10.0.0.241:2888:3888 server.3=10.0.0.242:2888:3888
配置主机id
注:每台主机myid都不一样(三台都要配置)
echo "1" > /data/zookeeper/myid cat /data/zookeeper/myid
zookeeper所有节点启动
/opt/zookeeper/bin/zkServer.sh start #状态信息 ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
检查节点运行状态
/opt/zookeeper/bin/zkServer.sh status #es01主机状态 ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Mode: follower --> 追随者 #es02主机状态 ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Mode: leader -->领导者 #es03状态 ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Mode: follower --> 追随者
测试zookeeper
#在一个节点上执行,创建一个频道 /opt/zookeeper/bin/zkCli.sh -server 10.0.0.240:2181 create /test "hello" #在其他节点上看能否接收到 /opt/zookeeper/bin/zkCli.sh -server 10.0.0.240:2181 get /test
安装部署Kafka
注:每个节点都配置,注意ip不同
#es01操作 #上传安装包 cd /opt/es_software/ #解压并创建软连接 tar zxf kafka_2.11-1.0.0.tgz -C /opt/ ln -s /opt/kafka_2.11-1.0.0/ /opt/kafka #创建一个日志目录 mkdir /opt/kafka/logs #修改配置文件 vim /opt/kafka/config/server.properties # broker的id,值为整数,且必须唯一,在一个集群中不能重复 broker.id=1 listeners=PLAINTEXT://10.0.0.240:9092 # 处理网络请求的线程数量,默认为3个 num.network.threads=3 # 执行磁盘IO操作的线程数量,默认为8个 num.io.threads=8 # socket服务发送数据的缓冲区大小,默认100KB socket.send.buffer.bytes=102400 # socket服务接受数据的缓冲区大小,默认100KB socket.receive.buffer.bytes=102400 # socket服务所能接受的一个请求的最大大小,默认为100M socket.request.max.bytes=104857600 # kafka存储消息数据的目录 log.dirs=/opt/kafka/logs # 每个topic默认的partition数量 num.partitions=1 # 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量 num.recovery.threads.per.data.dir=1 #topic的offset的备份份数。建议设置更高的数字保证更高的可用性 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 #每个日志文件删除之前保存的时间 log.retention.hours=24 #这个属性就是每个文件的最大尺寸;当尺寸达到这个数值时,就会创建新文件 log.segment.bytes=1073741824 #检查日志分段文件的间隔时间,以确定是否文件属性是否到达删除要求。 log.retention.check.interval.ms=300000 # Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开 zookeeper.connect=10.0.0.240:2181,10.0.0.241:2181,10.0.0.242:2181 # 连接zookeeper的超时时间,6s zookeeper.connection.timeout.ms=6000 group.initial.rebalance.delay.ms=0
前台测试能否正常启动
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
测试创建topic
注:zookeeper保存信息为:topic创建的副本是3个,分区是3个,topic主体叫做Kafkatest
/opt/kafka/bin/kafka-topics.sh --create --zookeeper 10.0.0.241:2181,10.0.0.242:2181,10.0.0.240:2181 --partitions 3 --replication-factor 3 --topic kafkatest #创建信息 Created topic "kafkatest".
测试获取toppid
/opt/kafka/bin/kafka-topics.sh --describe --zookeeper 10.0.0.241:2181,10.0.0.242:2181,10.0.0.240:2181 --topic kafkatest #测试信息 Topic:kafkatest PartitionCount:3 ReplicationFactor:3 Configs: Topic: kafkatest Partition: 0 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1 Topic: kafkatest Partition: 1 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2 Topic: kafkatest Partition: 2 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
测试删除topic
/opt/kafka/bin/kafka-topics.sh --delete --zookeeper 10.0.0.241:2181,10.0.0.242:2181,10.0.0.240:2181 --topic kafkatest #测试信息 Topic kafkatest is marked for deletion. Note: This will have no impact if delete.topic.enable is not set to true.
Kafka测试命令发送信息
#创建命令 /opt/kafka/bin/kafka-topics.sh --create --zookeeper 10.0.0.241:2181,10.0.0.242:2181,10.0.0.240:2181 --partitions 3 --replication-factor 3 --topic messagetest #测试发送消息 /opt/kafka/bin/kafka-console-producer.sh --broker-list 10.0.0.241:9092,10.0.0.242:9092,10.0.0.240:9092 --topic messagetest #其他节点测试接收 /opt/kafka/bin/kafka-console-consumer.sh --zookeeper 10.0.0.241:2181,10.0.0.242:2181,10.0.0.240:2181 --topic messagetest --from-beginning #测试获取所有的频道 /opt/kafka/bin/kafka-topics.sh --list --zookeeper 10.0.0.241:2181,10.0.0.242:2181,10.0.0.240:2181
测试成功放入后台
/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
修改filebeat配置文件
vim /etc/filebeat/filebeat.yml filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/access.log json.keys_under_root: true json.overwrite_keys: true tags: ["access"] - type: log enabled: true paths: - /var/log/nginx/error.log tags: ["error"] output.kafka: hosts: ["10.0.0.240:9092", "10.0.0.241:9092", "10.0.0.242:9092"] topic: 'filebeat' setup.template.name: "nginx" setup.template.pattern: "nginx_*" setup.template.enabled: false setup.template.overwrite: true #重启filebeat服务 systemctl restart filebeat
修改logstash配置文件
vim /etc/logstash/conf.d/kafka.conf input { kafka{ bootstrap_servers=>"10.0.0.240:9092" topics=>["filebeat"] group_id=>"logstash" codec => "json" } } filter { mutate { convert => ["upstream_time", "float"] convert => ["request_time", "float"] } } output { stdout {} if "access" in [tags] { elasticsearch { hosts => "http://10.0.0.240:9200" manage_template => false index => "nginx_access-%{+yyyy.MM}" } } if "error" in [tags] { elasticsearch { hosts => "http://10.0.0.240:9200" manage_template => false index => "nginx_error-%{+yyyy.MM}" } } } #重新启动logstash服务 systemctl restart logstash netstat -lntup | grep 9092 --> 出现会慢一些 #查看logstash的日志信息 tail -f /var/log/logstash/logstash-plain.log
报错处理:
free -h查看内存大小- 查看logstash日志信息
- Kafka配置文件内容是否正确
在head界面查看效果
访问一些错误和正确日志
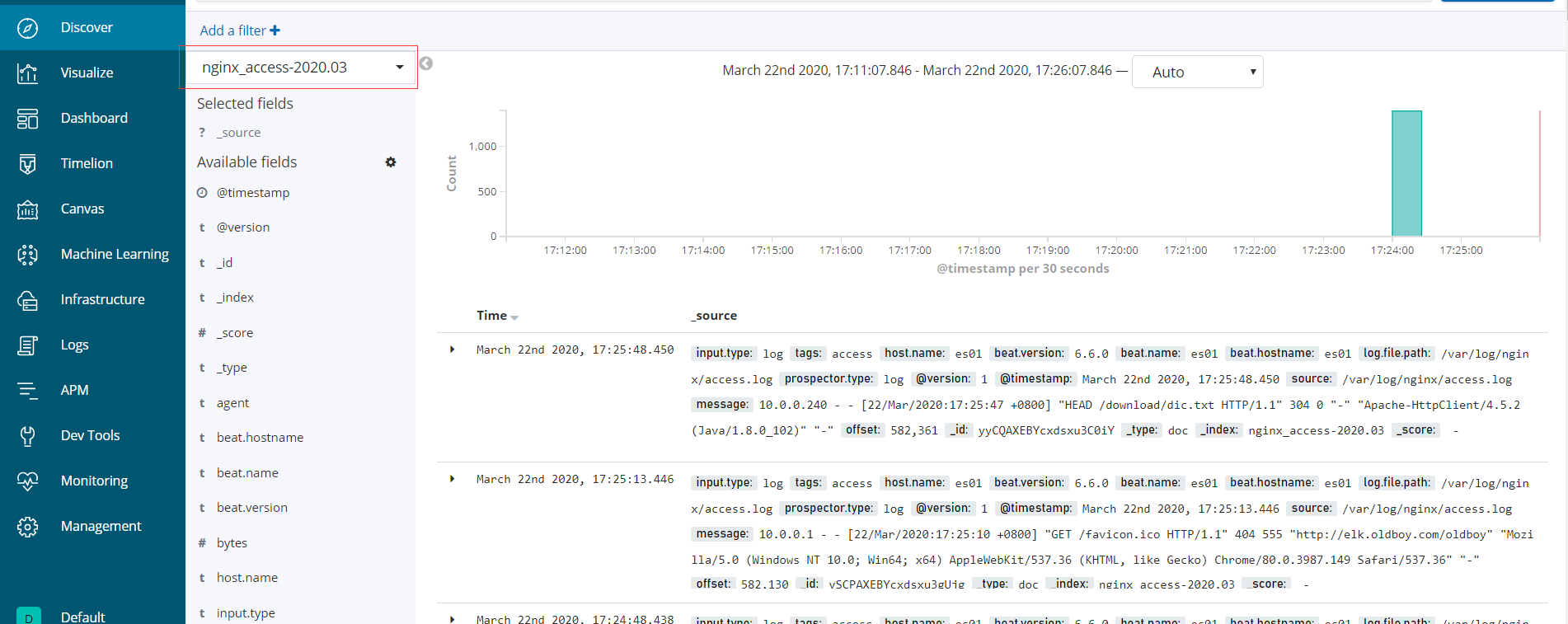
在kibana界面添加index-patterns
在网盘包里面有一个access.tar.gz我们可以将日志放入nginx的日志里面,查看效果
cat access.log >> /var/log/nginx/access.log
- 正确日志信息
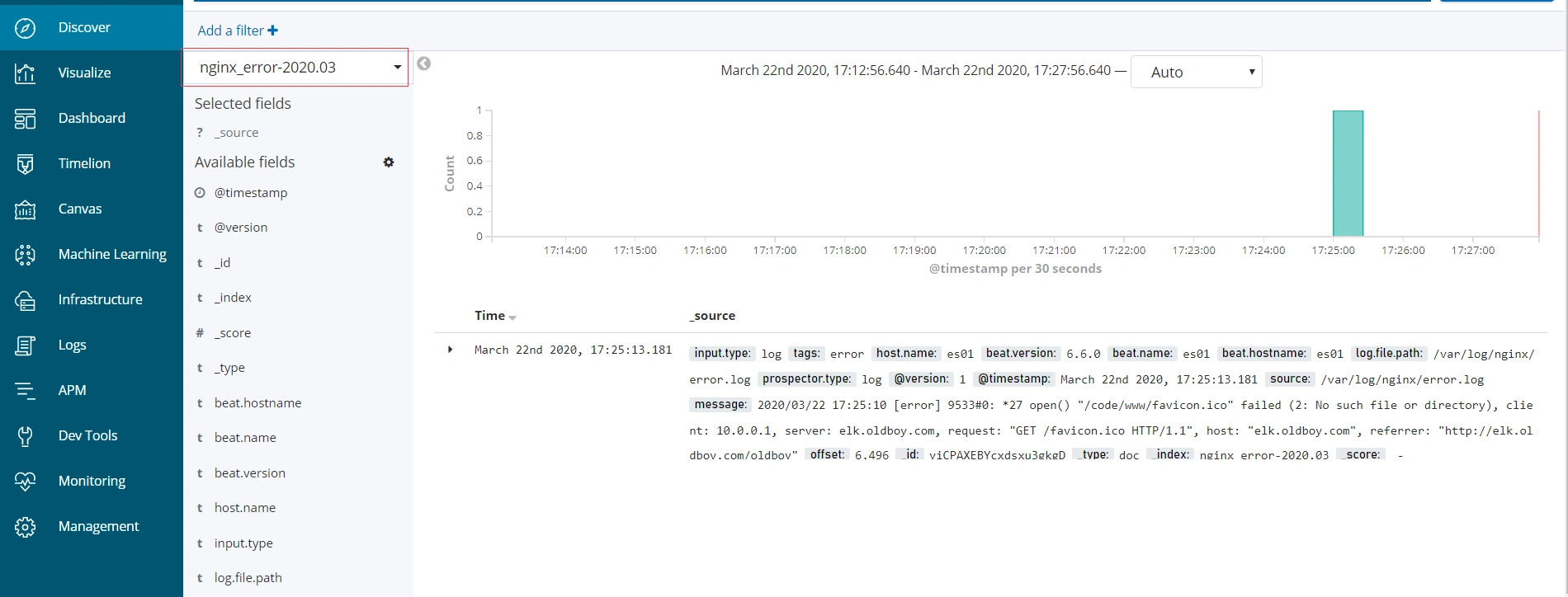
- 错误日志
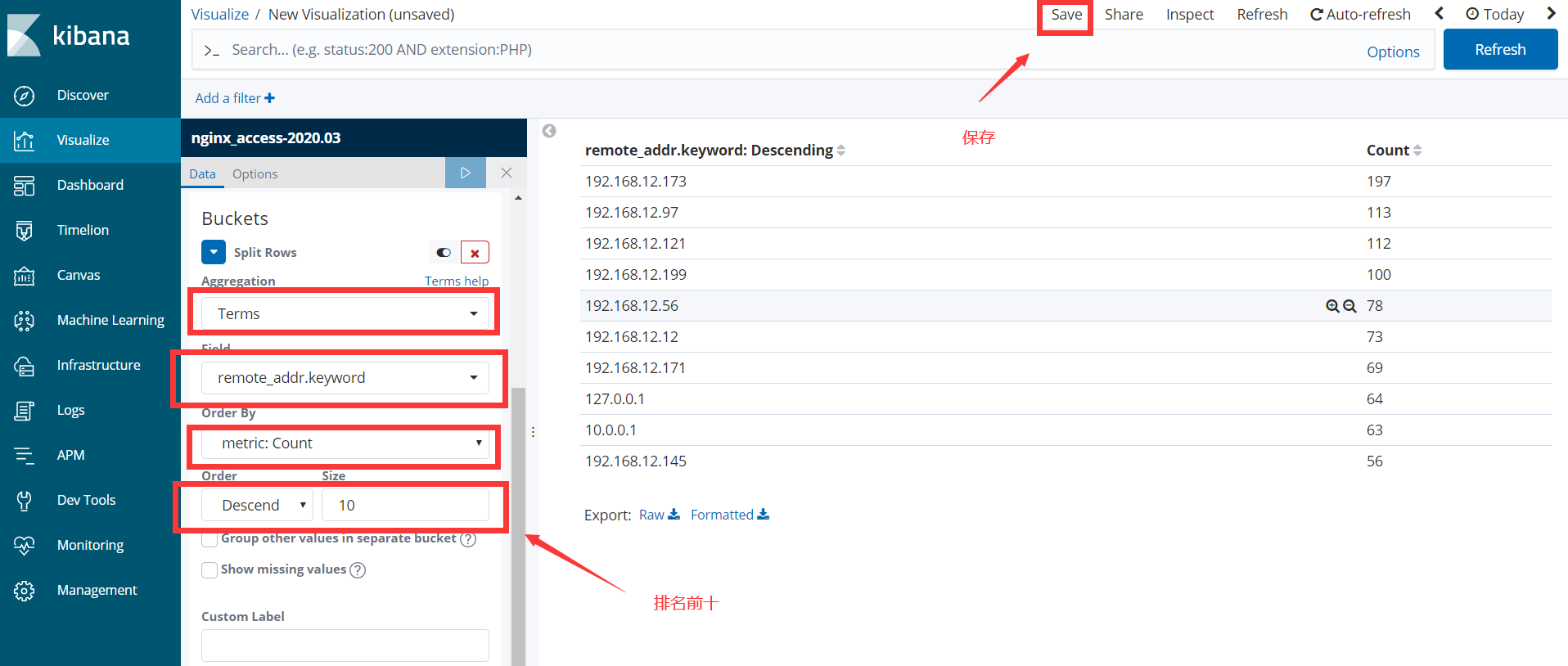
创建图形

 浙公网安备 33010602011771号
浙公网安备 33010602011771号