
爬虫综合大作业
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
作业要求:
可以用pandas读出之前保存的数据:
newsdf = pd.read_csv(r'F:\duym\gzccnews.csv')
一.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)
保存到MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
三.爬虫注意事项
1.设置合理的爬取间隔,不会给对方运维人员造成压力,也可以防止程序被迫中止。
- import time
- import random
- time.sleep(random.random()*3)
2.设置合理的user-agent,模拟成真实的浏览器去提取内容。
- 首先打开你的浏览器输入:about:version。
- 用户代理:
- 收集一些比较常用的浏览器的user-agent放到列表里面。
- 然后import random,使用随机获取一个user-agent
- 定义请求头字典headers={’User-Agen‘:}
- 发送request.get时,带上自定义了User-Agen的headers
作业详情:
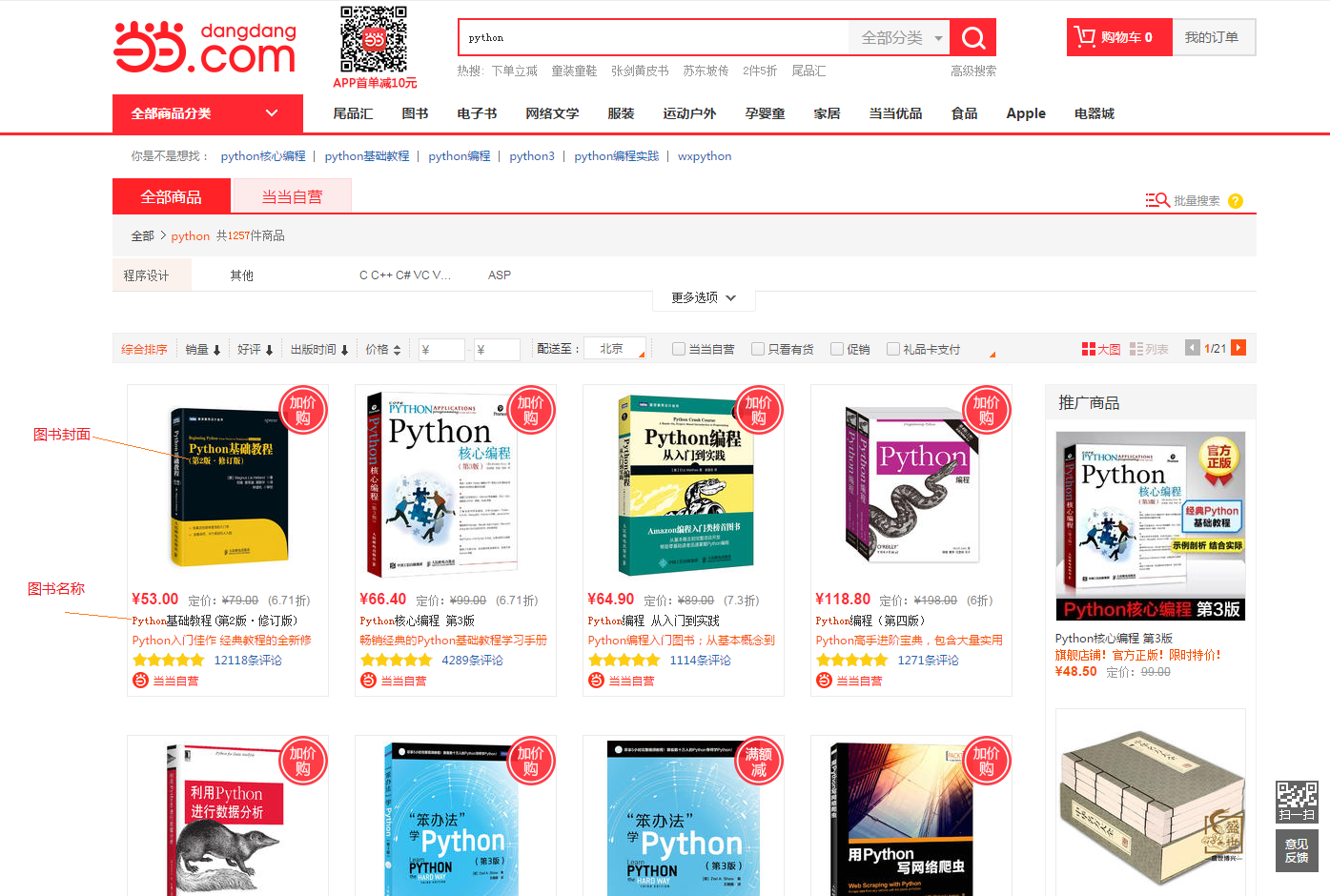
任何网站皆可爬取,就看你要不要爬取而已。本次选取的爬取目标是当当网,爬取内容是 以 Python 为关键字搜索出来的页面中所有书籍的信息。具体如下图所示:
2 爬取过程
总所周知,每个站点的页面 DOM 树是不一样的。所以我们需要先对爬取页面进行分析,再确定自己要获取的内容,再定义程序爬取内容的规则。
确定 URL 地址
我们可以通过利用浏览器来确定URL 地址,为 urllib 发起请求提供入口地址。接下来,我们就一步步来确定请求地址。
搜索结果页面为 1 时,URL 地址如下:

搜索结果页面为 3 时,URL 地址如下:

搜索结果页面为 21 时,即最后一页,URL 地址如下:

http://search.dangdang.com/?key=python&act=input&show=big&page_index=。而 page_index 的值,我们可以通过循环依次在地址后面添加。因此, urllib 请求代码可以这样写:# 爬取地址, 当当所有 Python 的书籍, 一共是 21 页 url = "http://search.dangdang.com/?key=python&act=input&show=big&page_index=" index = 1 while index <= 21: # 发起请求 request = urllib.request.Request(url=url+str(index), headers=headers) response = urllib.request.urlopen(request) index = index + 1 # 解析爬取内容 parseContent(response) time.sleep(1) # 休眠1秒
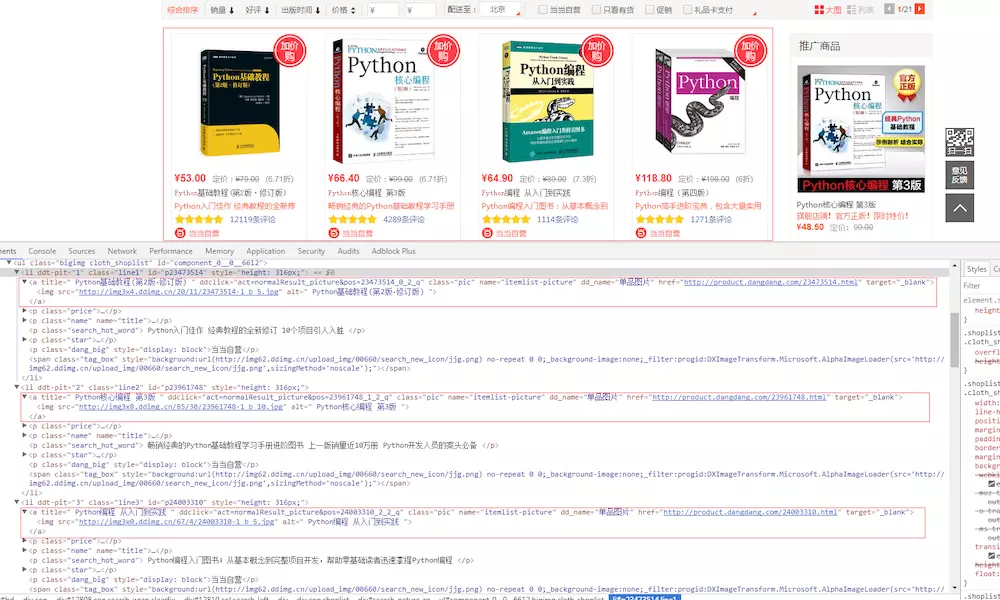
确定爬取节点
有了 URL 地址,就能使用 urllib 获取到页面的 html 内容。到了这步,我们就需要找到爬取的节点的规则,以便于 BeautifulSoup 地解析。为了搞定这个问题,就要祭出大招 —— Chrome 浏览器的开发者功能(按下 F12 键就能启动)。我们按下 F12 键盘,依次对每本书进行元素检查(在页面使用鼠标右键,点击“检查”即可),具体结果如下:
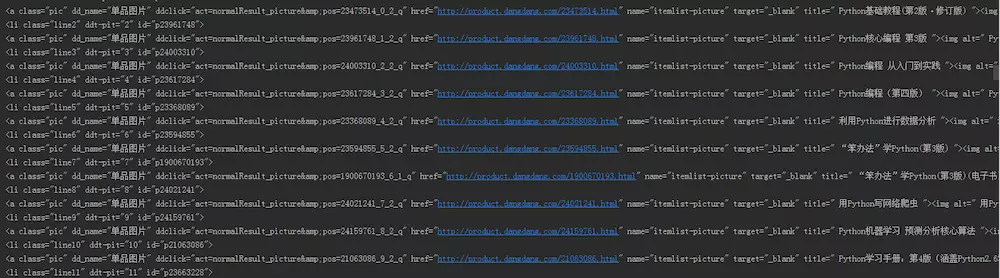
运行结果如下:
fileName = 'PythonBook.csv' # 指定编码为 utf-8, 避免写 csv 文件出现中文乱码 with codecs.open(fileName, 'w', 'utf-8') as csvfile: filednames = ['书名', '页面地址', '图片地址'] writer = csv.DictWriter(csvfile, fieldnames=filednames) writer.writeheader() for book in books: # print(book) # print(book.attrs) # 获取子节点<img> # (book.children)[0] if len(list(book.children)[0].attrs) == 3: img = list(book.children)[0].attrs['data-original'] else: img = list(book.children)[0].attrs['src'] writer.writerow({'书名': book.attrs['title'], '页面地址': book.attrs['href'], '图片地址': img})
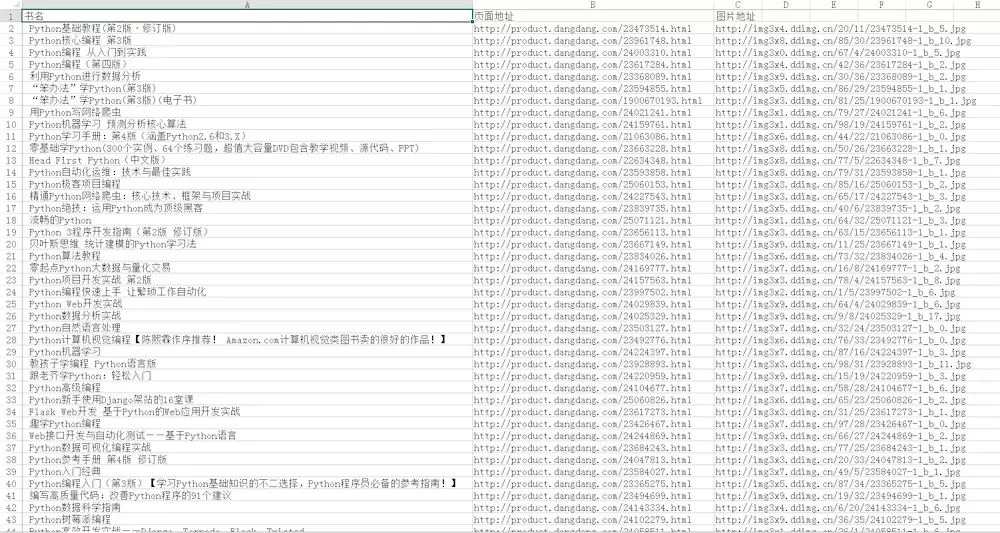
最后,我们将上面代码整合起来即可。我就把爬取结果截下图:

import time from bs4 import BeautifulSoup import requests import csv import codecs url = "http://search.dangdang.com/?key=python&act=input&show=big&page_index=" headers = { 'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6' } fileName = 'dangdang_PythonBook.csv' def parseContent(response): soup = BeautifulSoup(response, "lxml") books = soup.find_all('a',class_='pic') # 指定编码为 utf-8, 避免写 csv 文件出现中文乱码 with codecs.open(fileName, 'a+' ,encoding='utf_8_sig') as f: filednames = ['书名', '页面地址', '图片地址'] writer = csv.DictWriter(f,filednames) # writer.writeheader() for book in books: if len(list(book.children)[0].attrs) == 3: img = list(book.children)[0].attrs['data-original'] else: img = list(book.children)[0].attrs['src'] writer.writerow({filednames[0]: book.attrs['title'], filednames[1]: book.attrs['href'], filednames[2]: img}) index = 1 while index <= 2: request = requests.get(url=url+str(index), headers=headers) print('第' + str(index) + "页") index = index + 1
parseContent(request.text) time.sleep(1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号