爬虫的基本操作
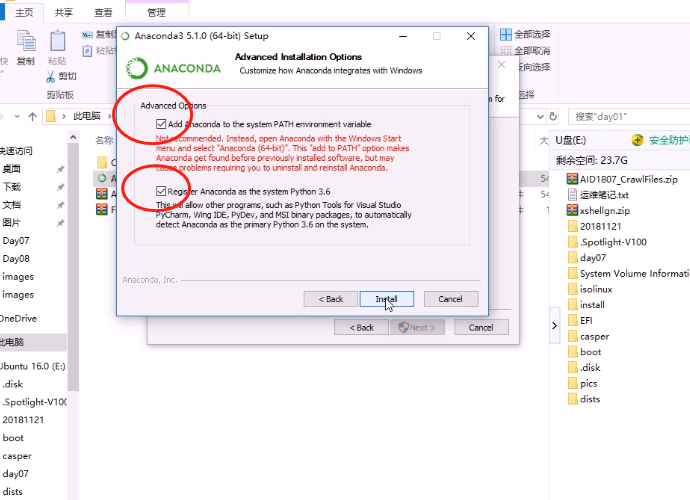
anaconda安装
打开浏览器的开发者模式--设置--更多工具--扩展程序
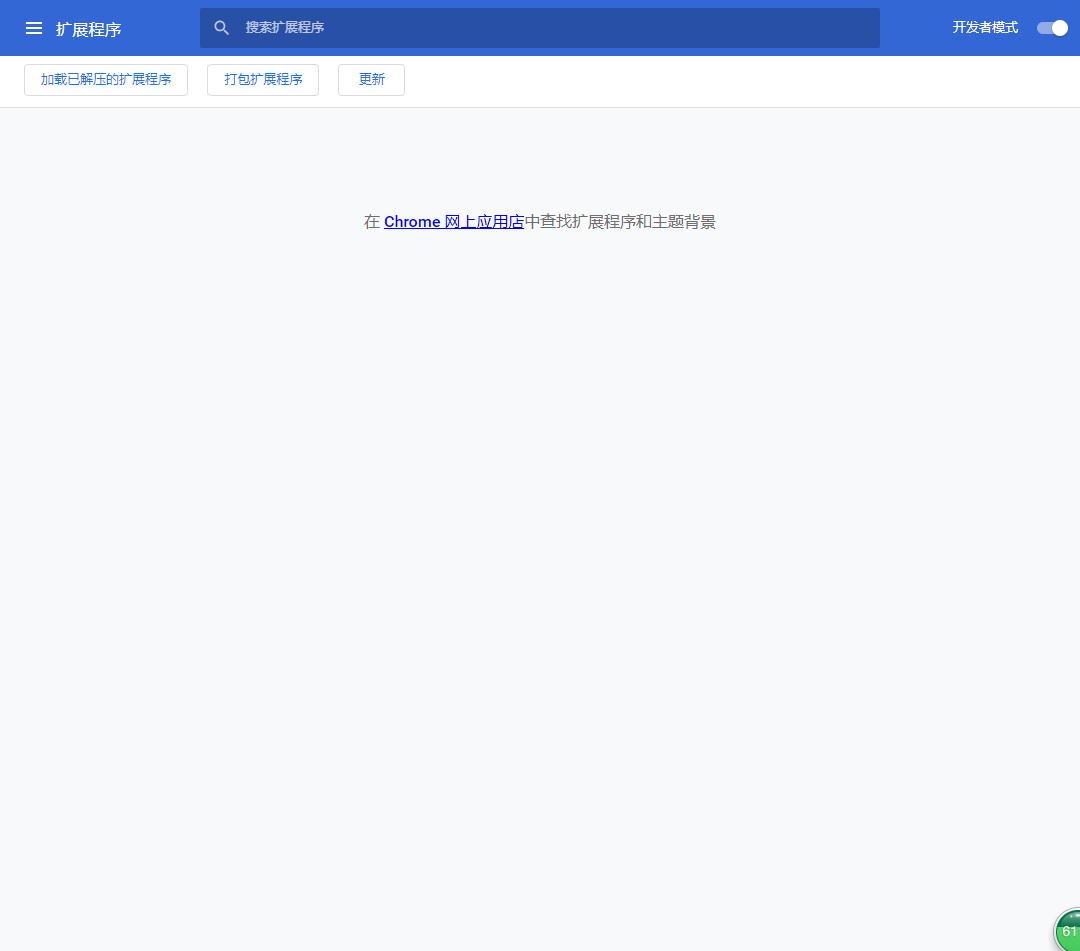
安装xpath解析工具到浏览器扩展程序

使用xpath插件查询元素ctrl+shif+x

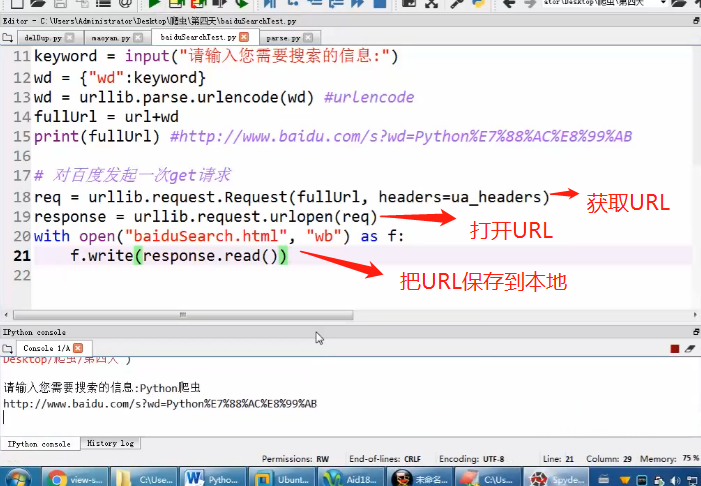
获取url地址并获取源码
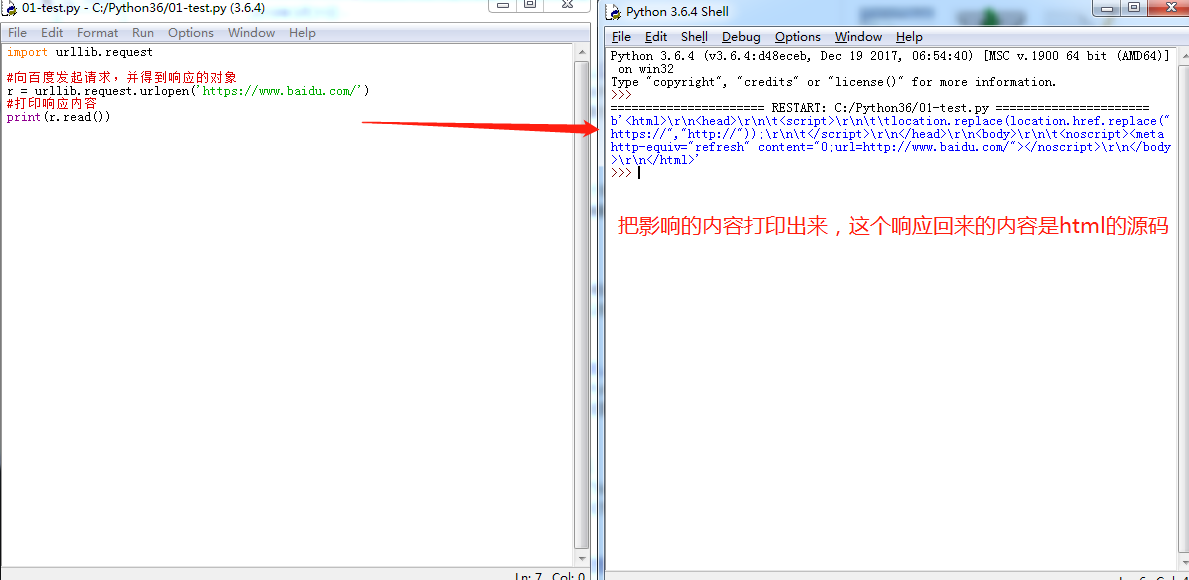
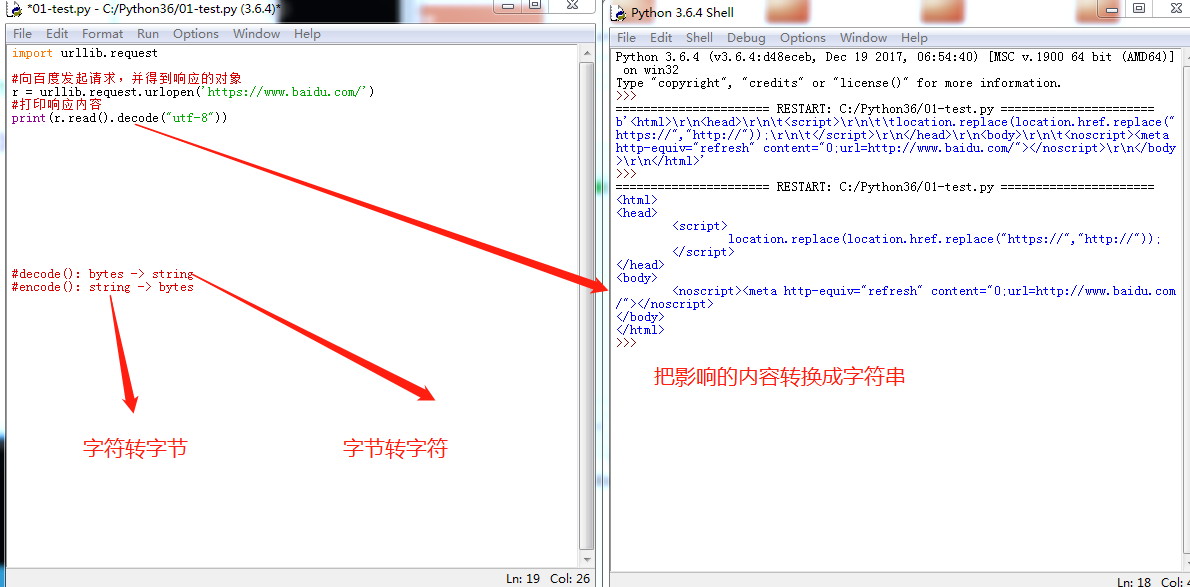
把获取的URL响应内容从字节转换成字符decode
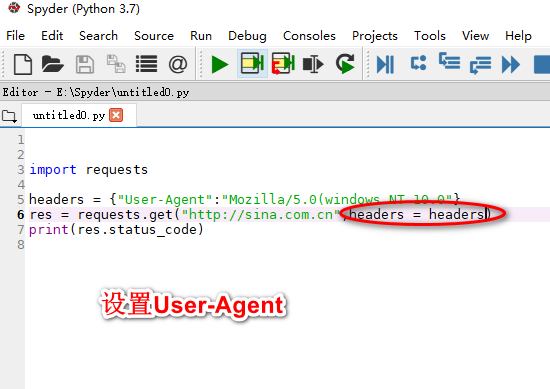
创建一个新的User-Agent

返回url的影响码getcode
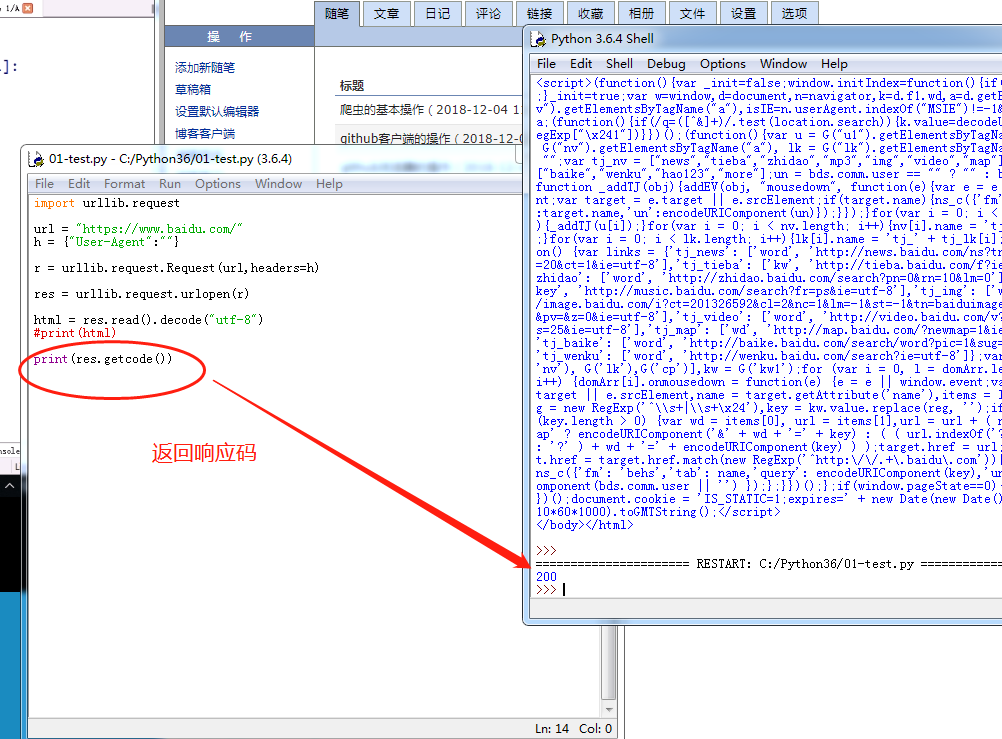
返回访问的URL地址geturl
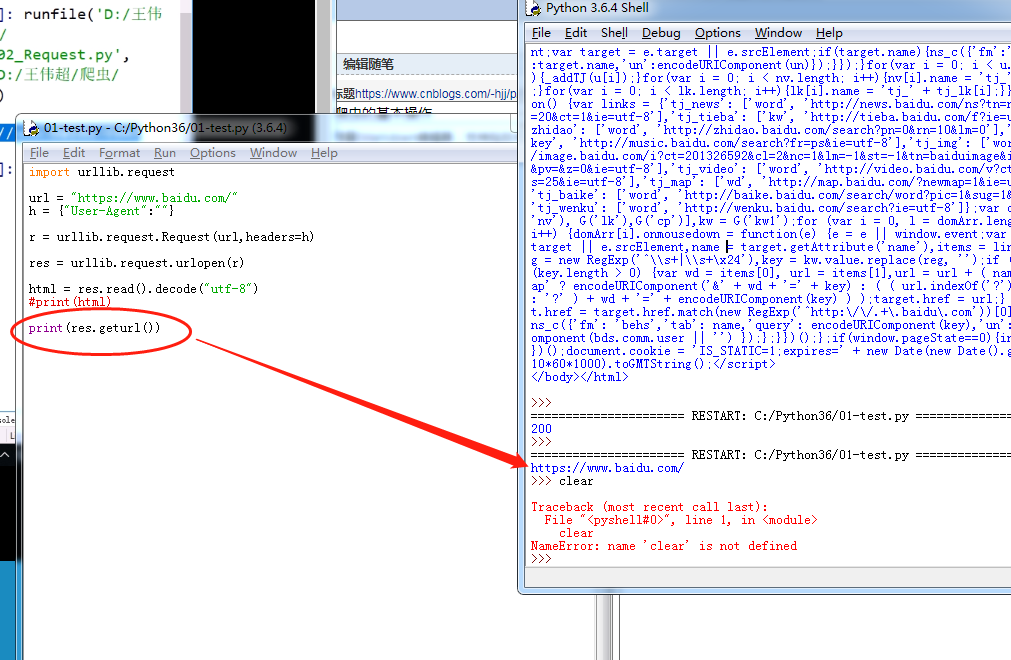
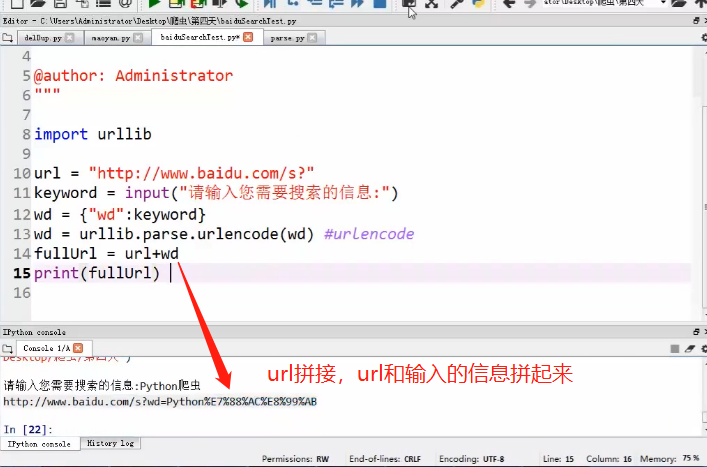
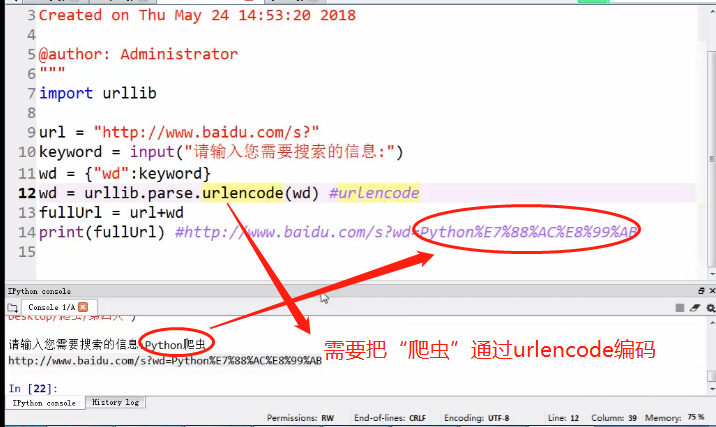
URL拼接
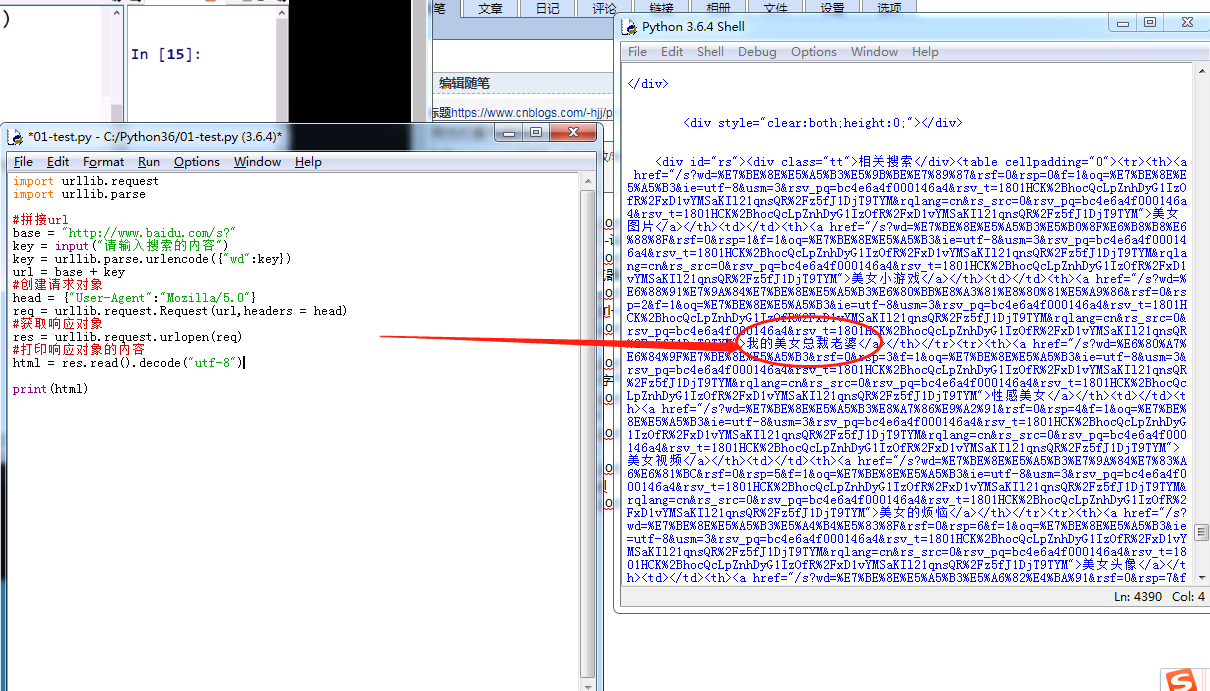
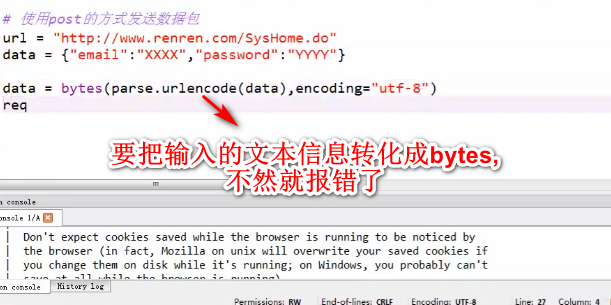
把URL响应的内容保存到本地的HTML文件(urlencode转码)
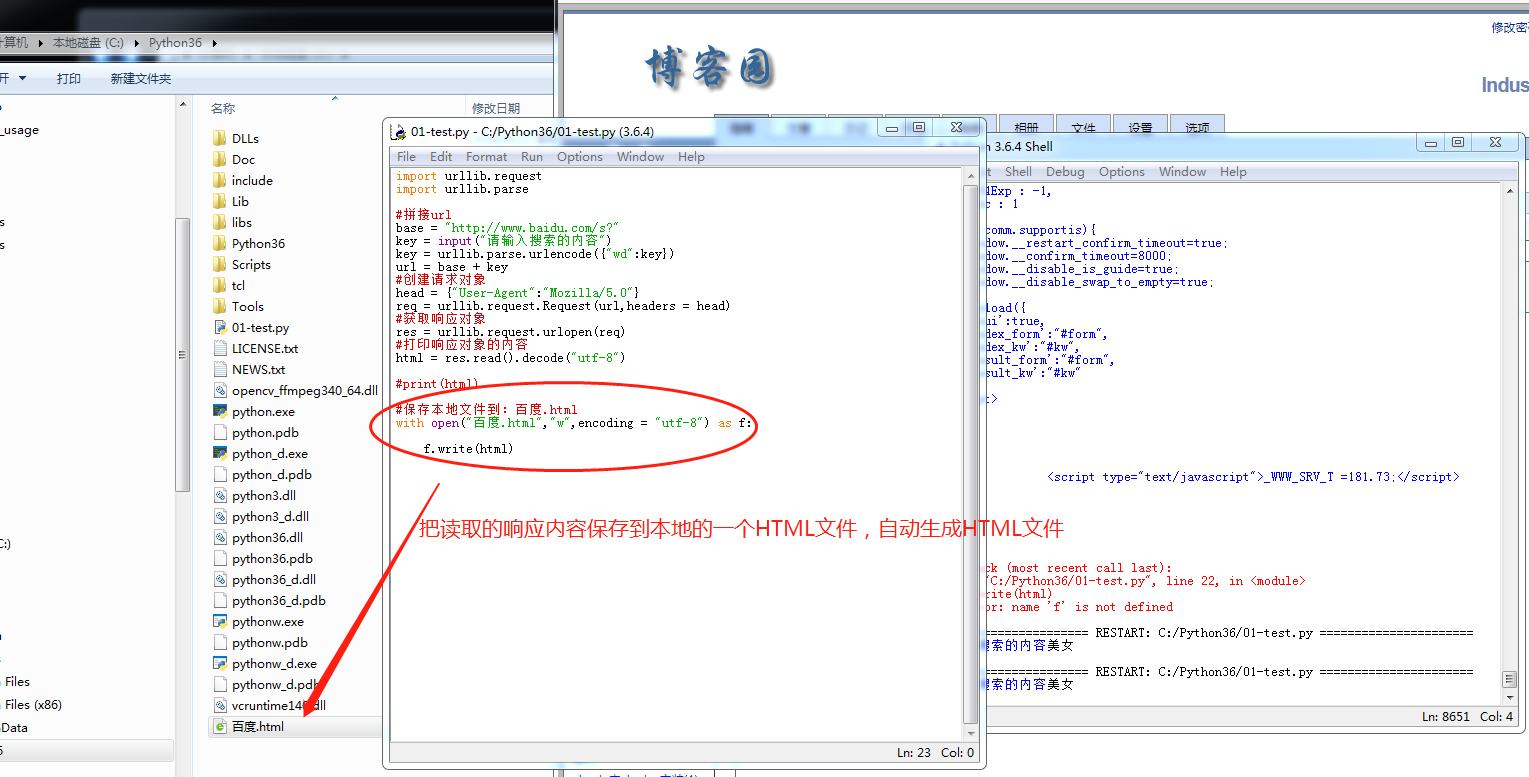
URL响应的内容保存到本地html(quote转码)
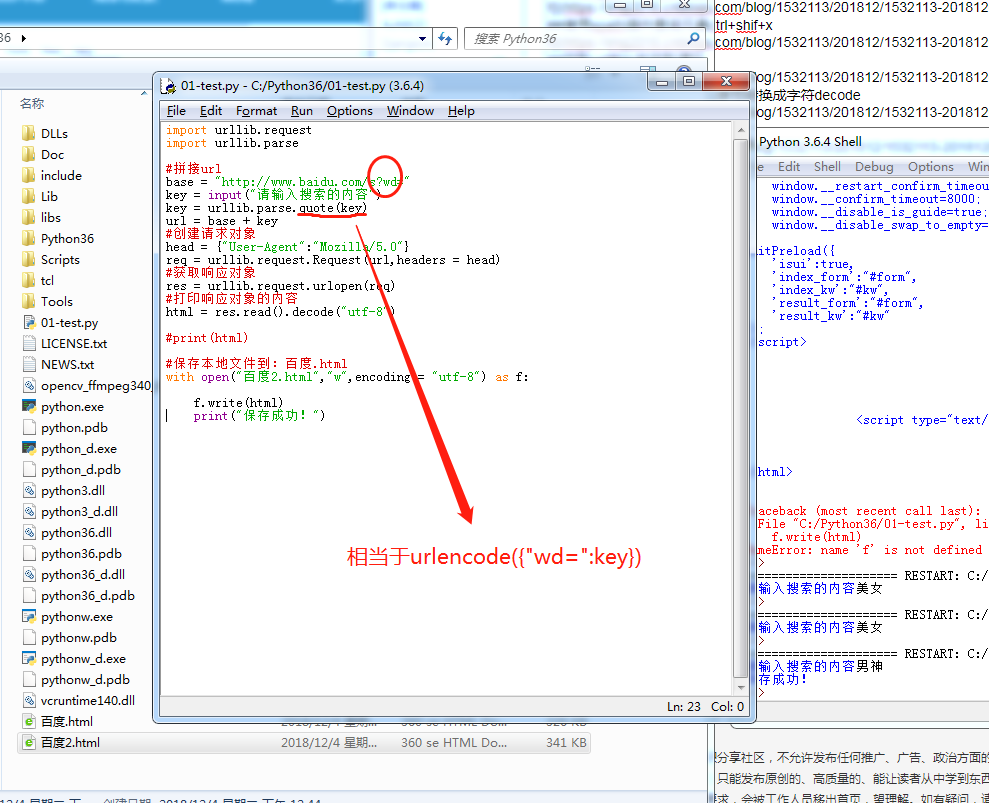
爬取三个网页保存到本地仓库
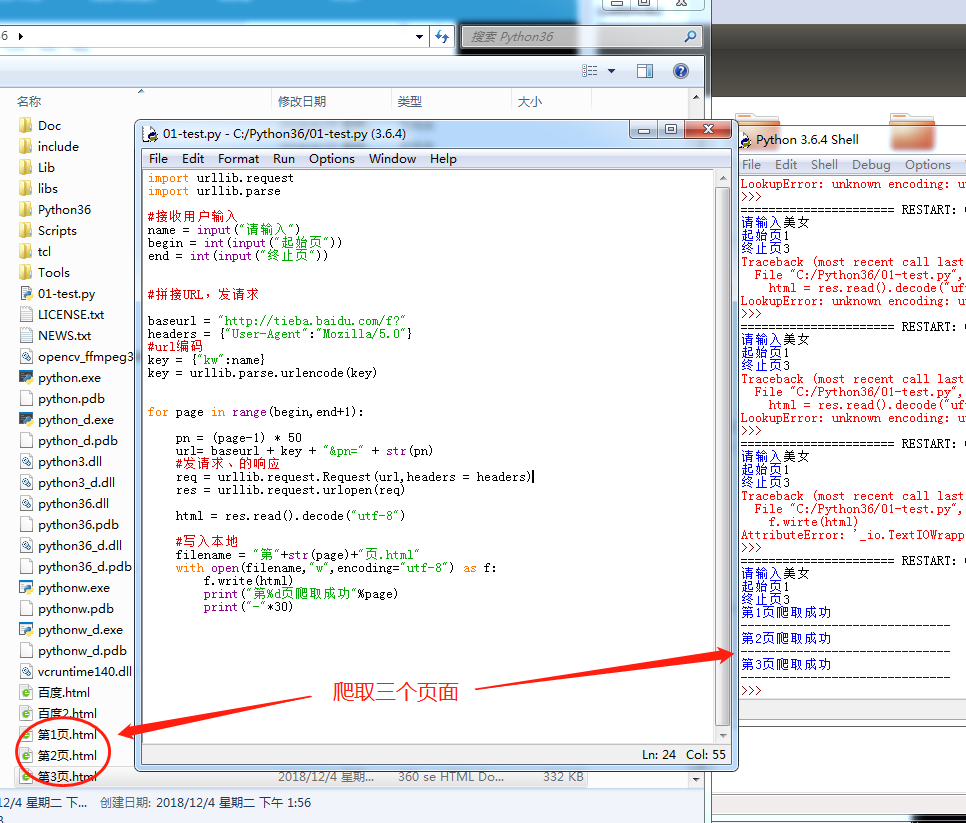
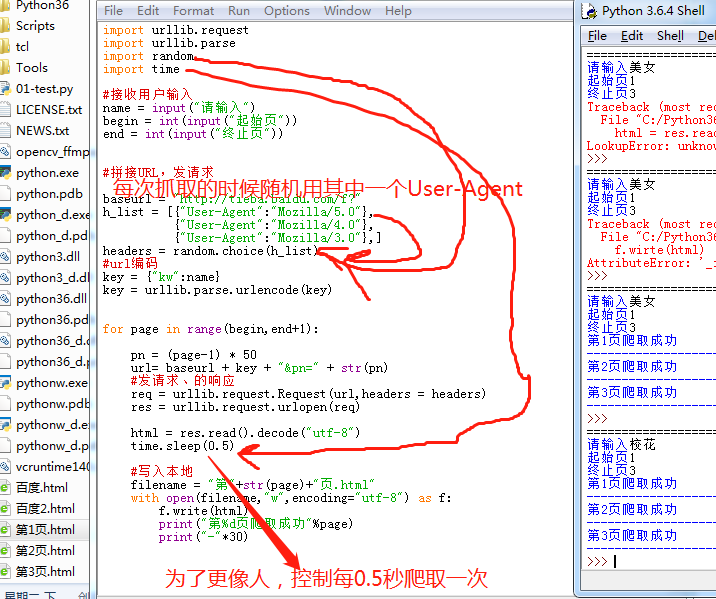
爬取三个网页保存是运用多个User-Agent和延迟爬取时间,可以增加爬取的安全性
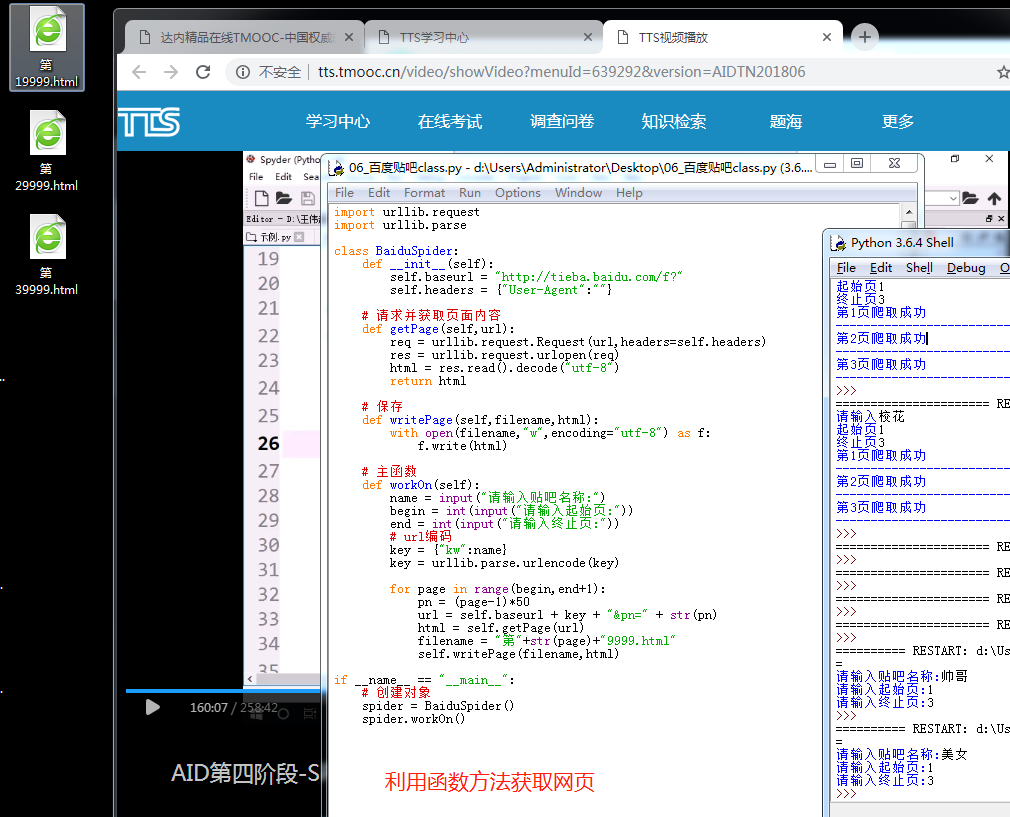
利用函数的方法来获取网页
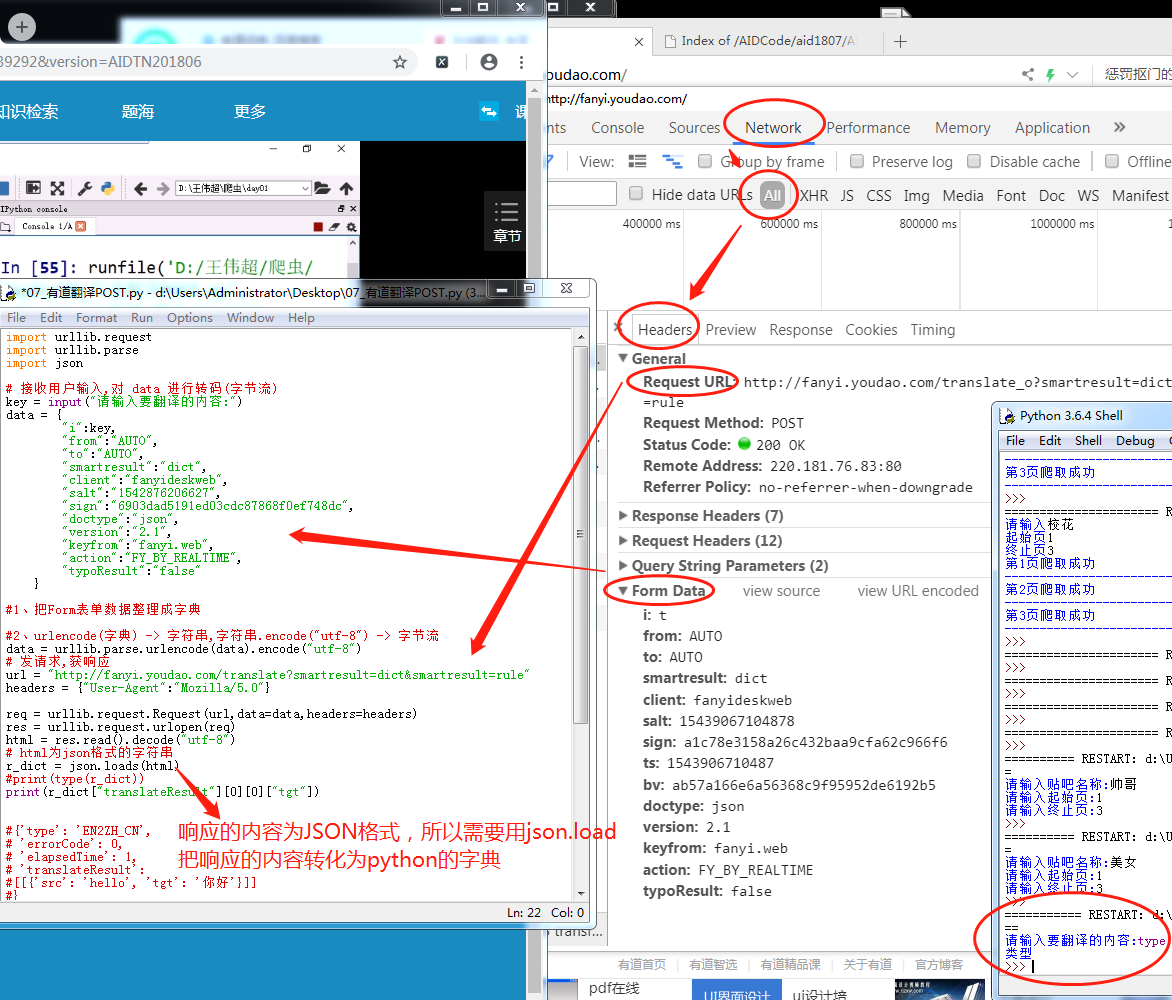
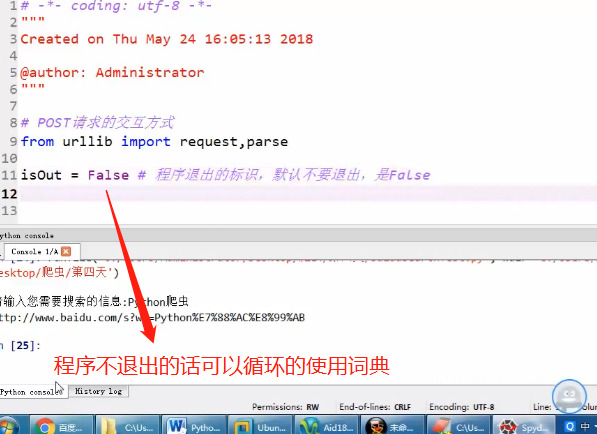
form(post)有道翻译的抓取
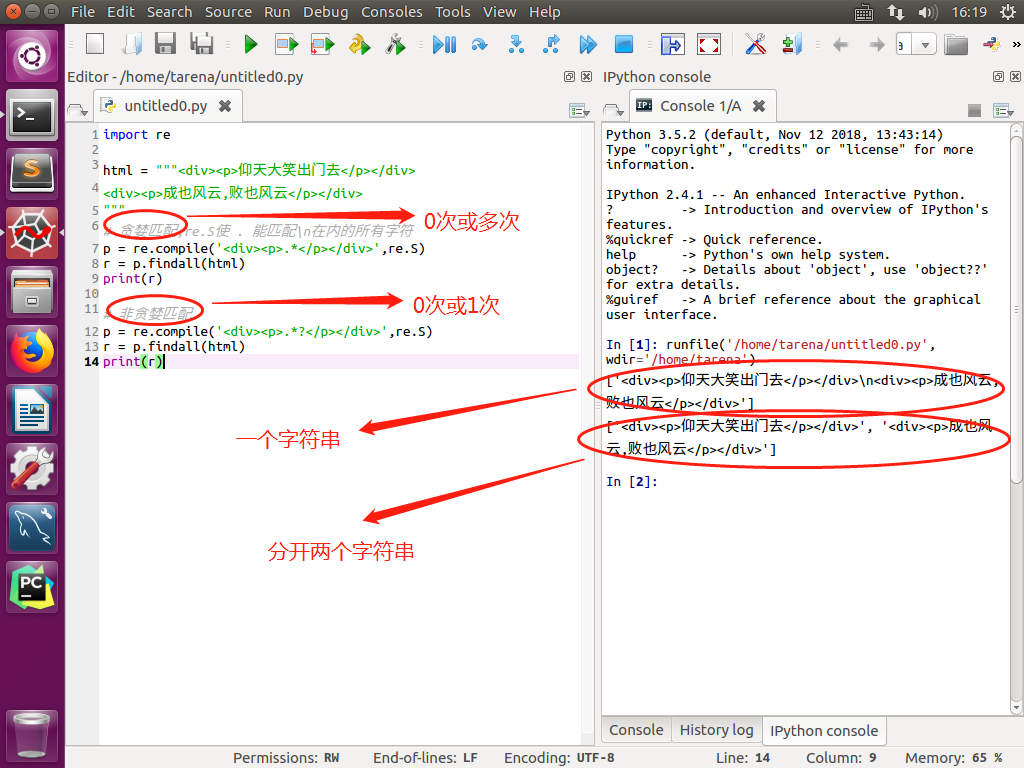
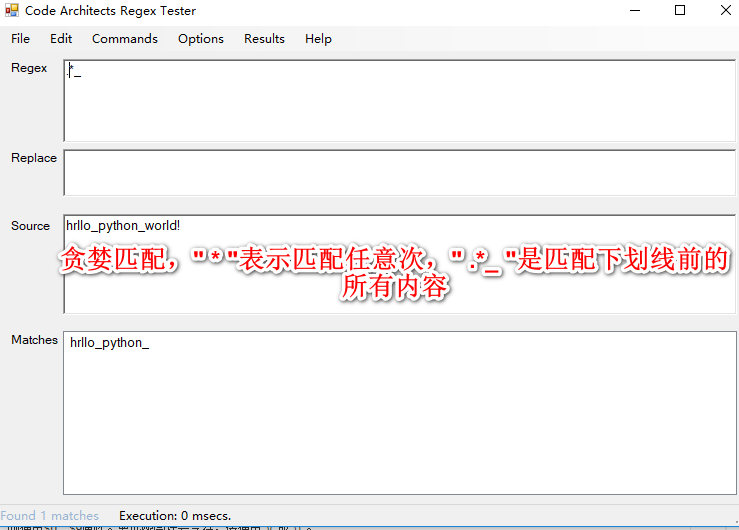
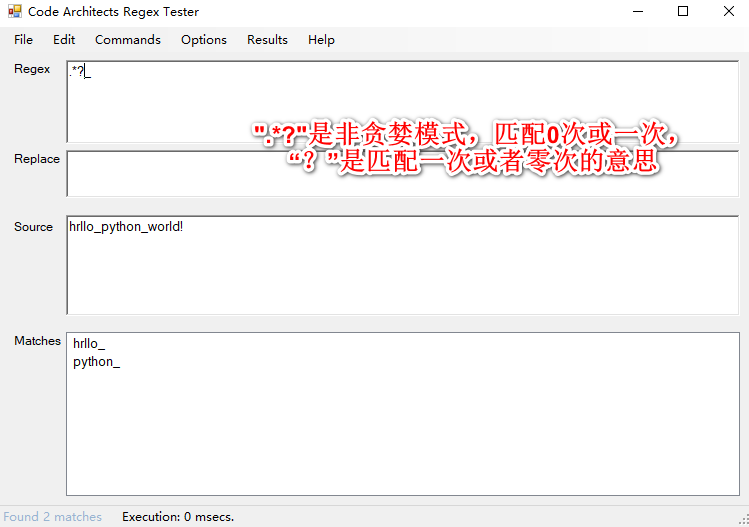
贪婪匹配.和非贪婪匹配.?
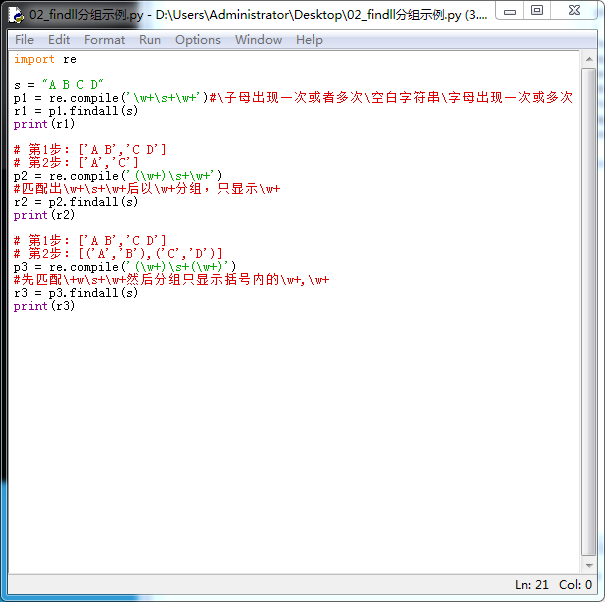
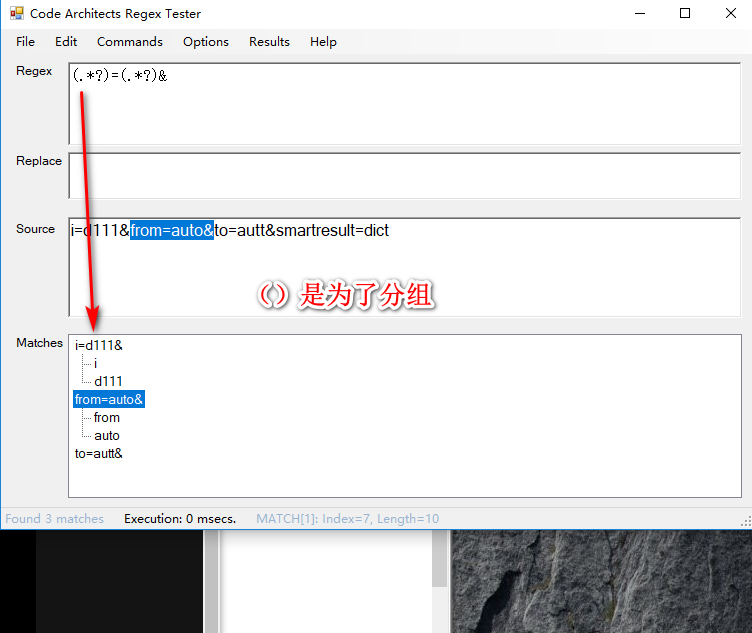
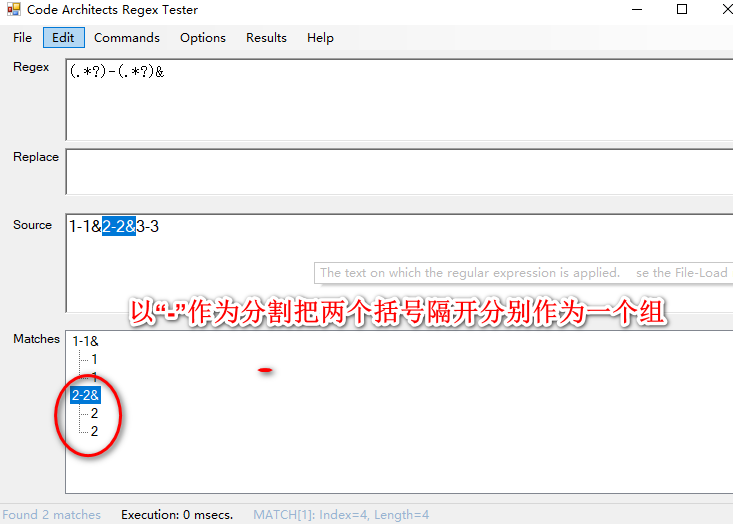
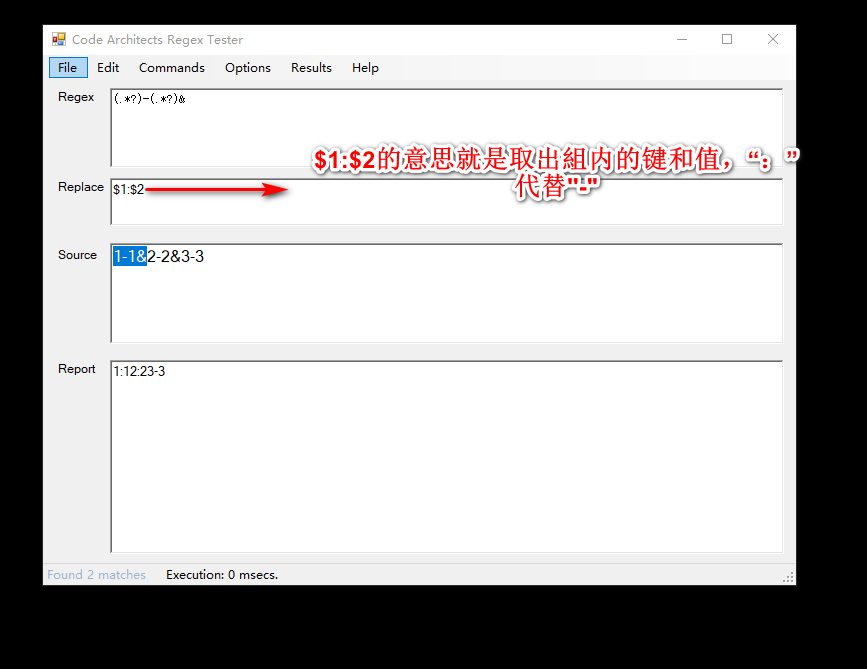
匹配方式分组显示
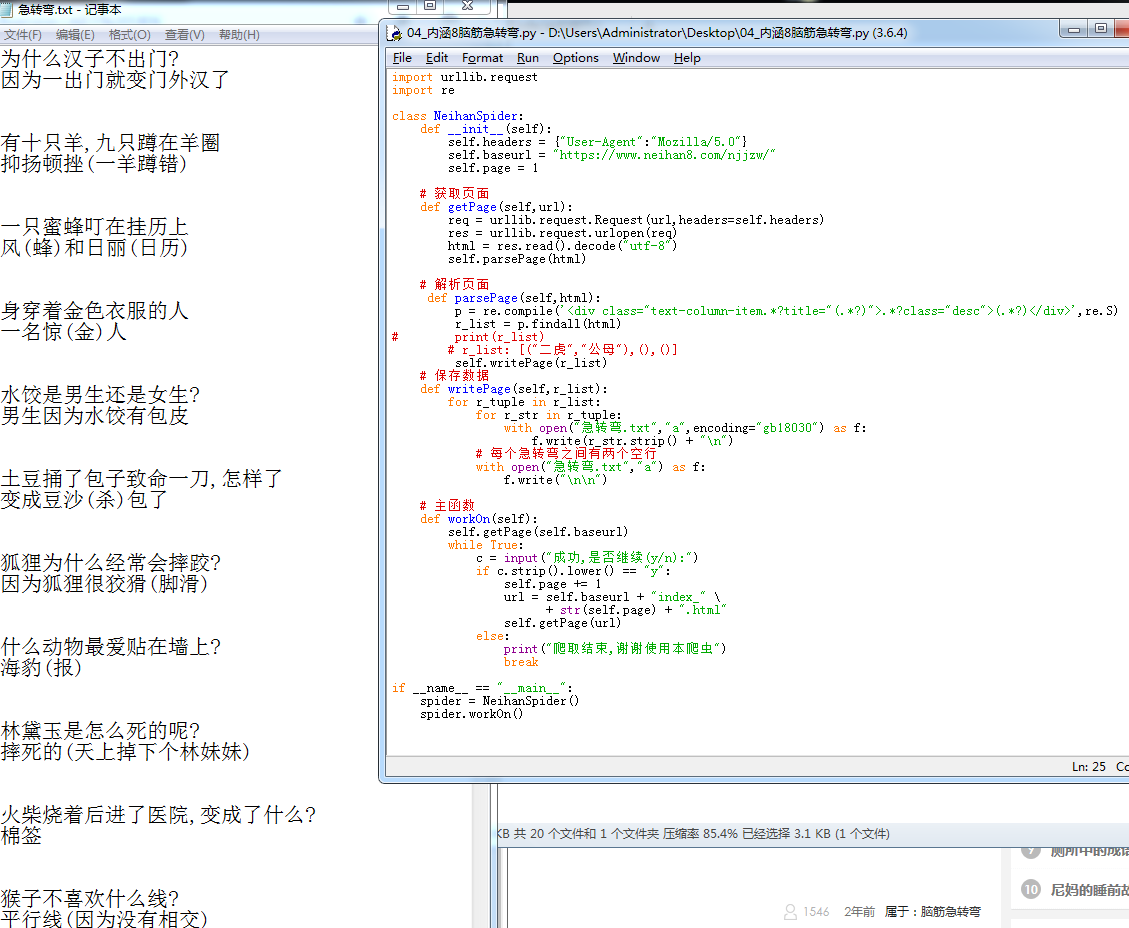
脑筋急转弯爬取案例
csv方式写入对象
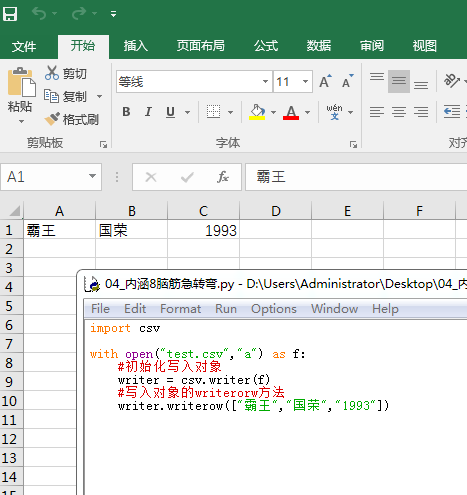
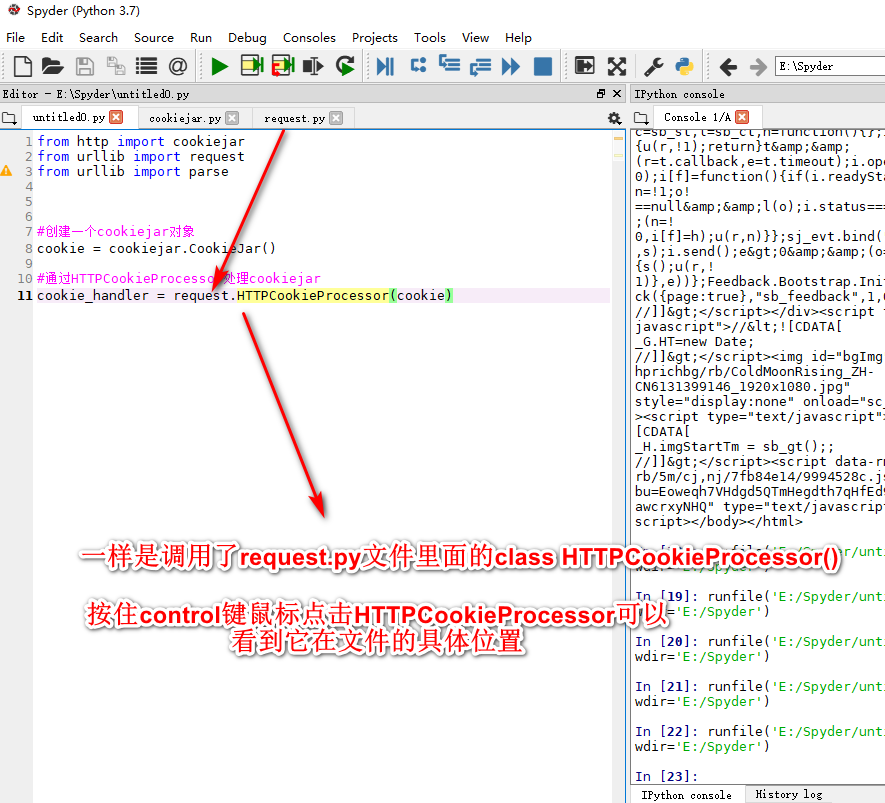
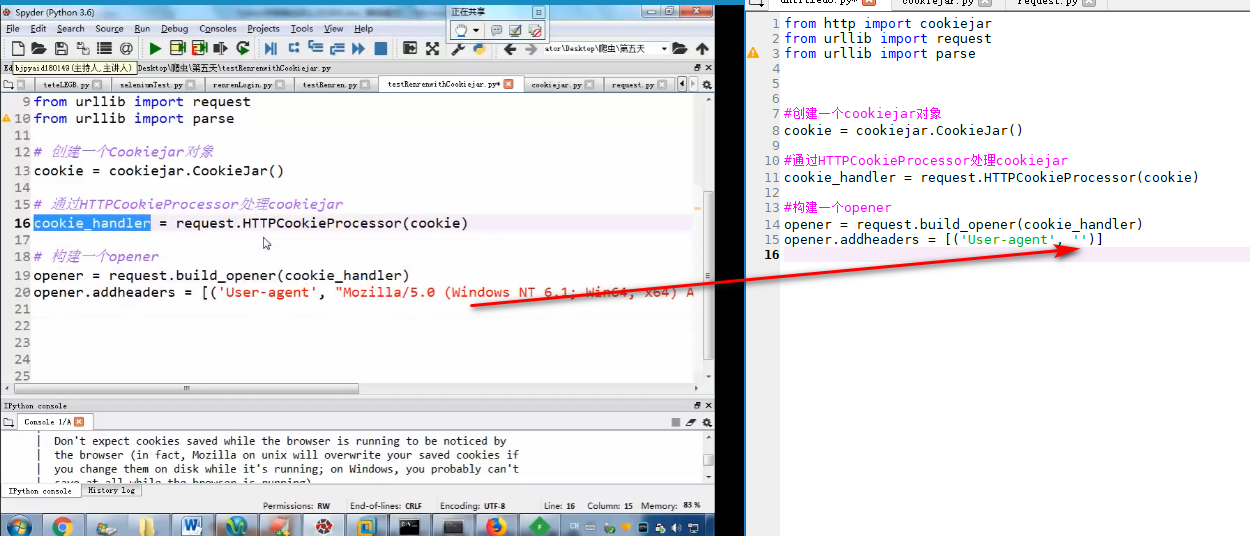
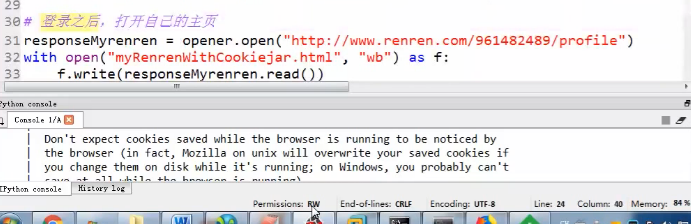
用cookie模拟登陆爬取个人主页信息
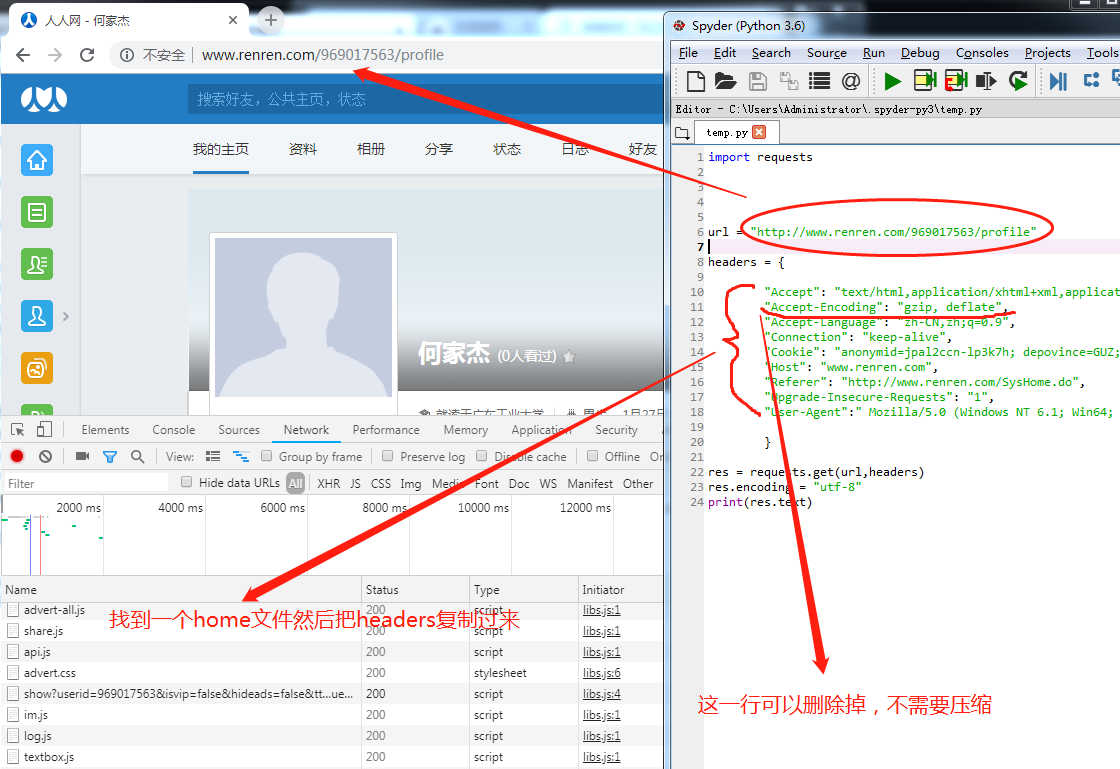
request接受post提交的信息(有道翻译)
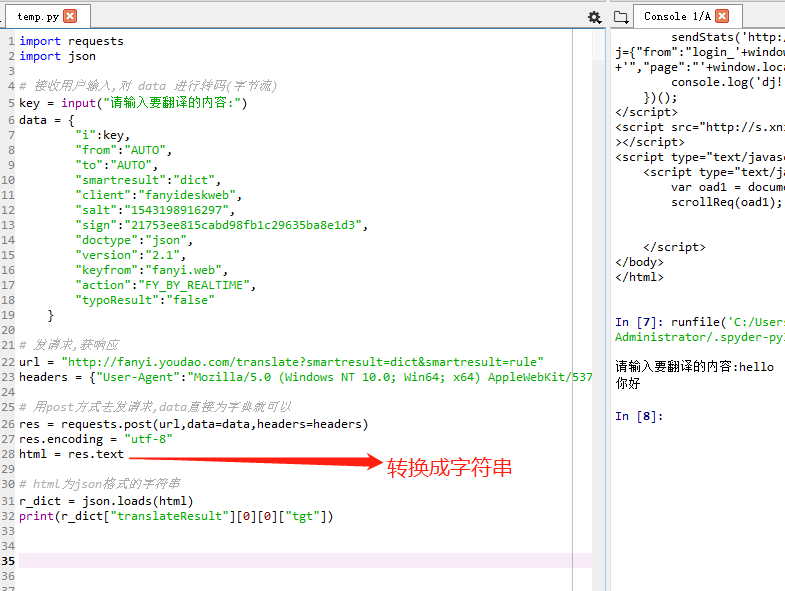
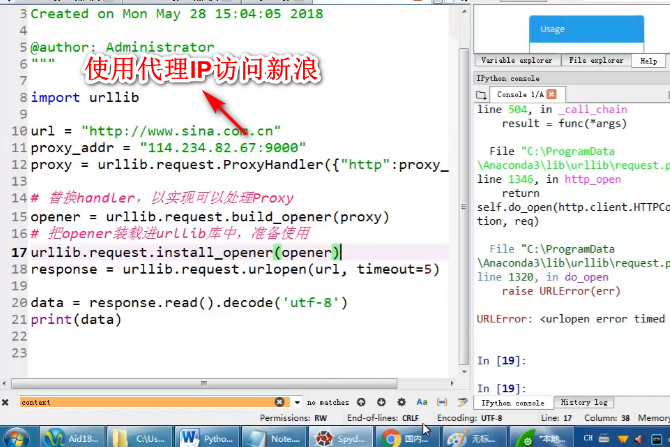
使用代理IP访问
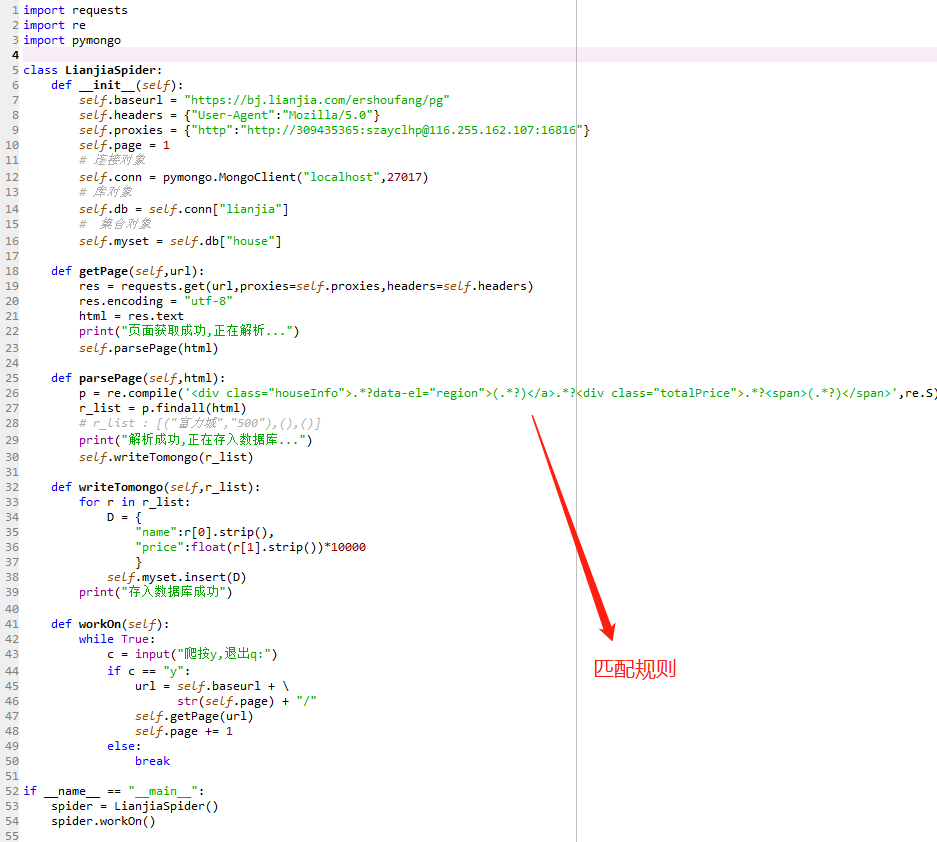
爬取链家房源信息保存到数据库中
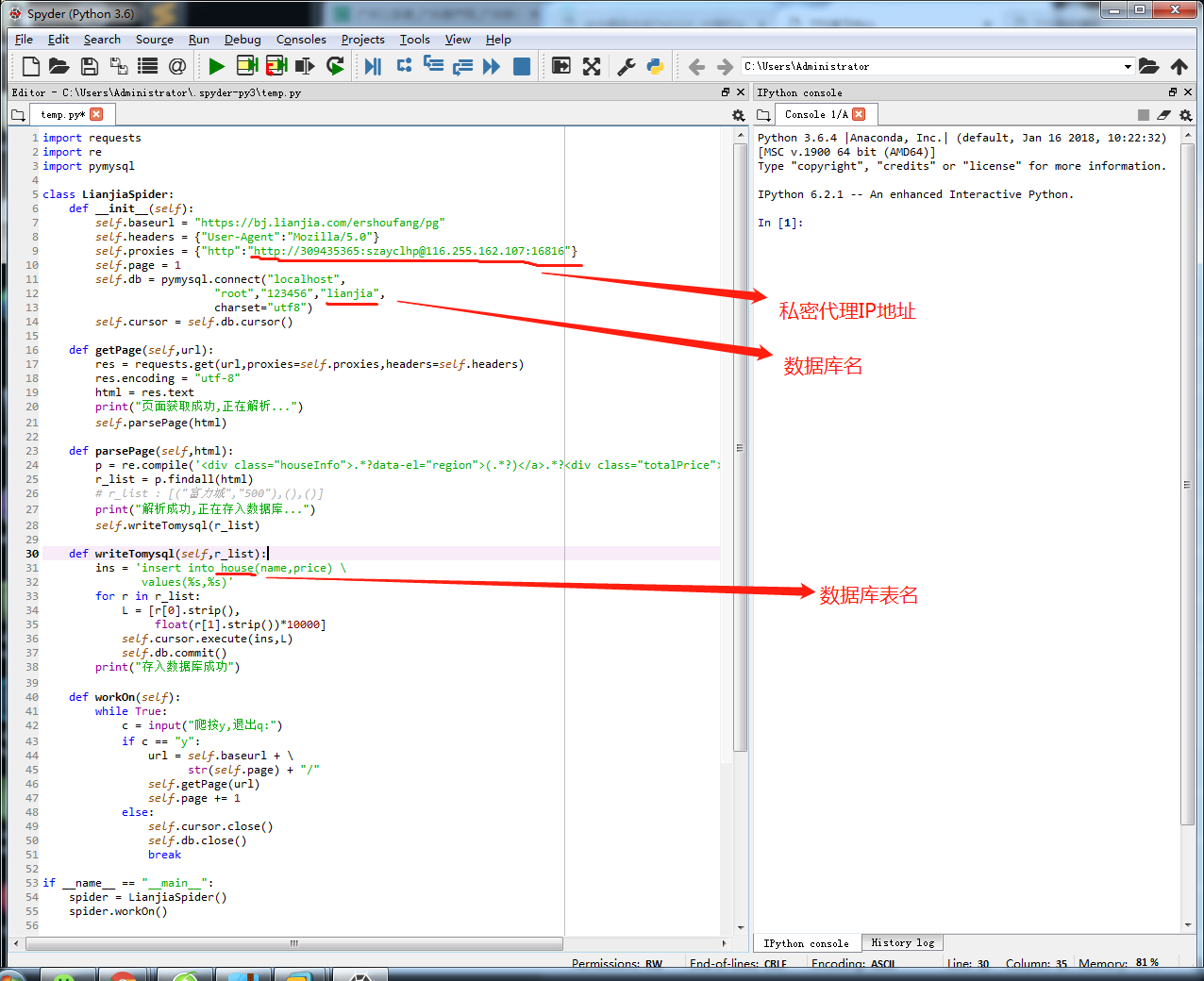
爬取链家房源信息保存到数据库中
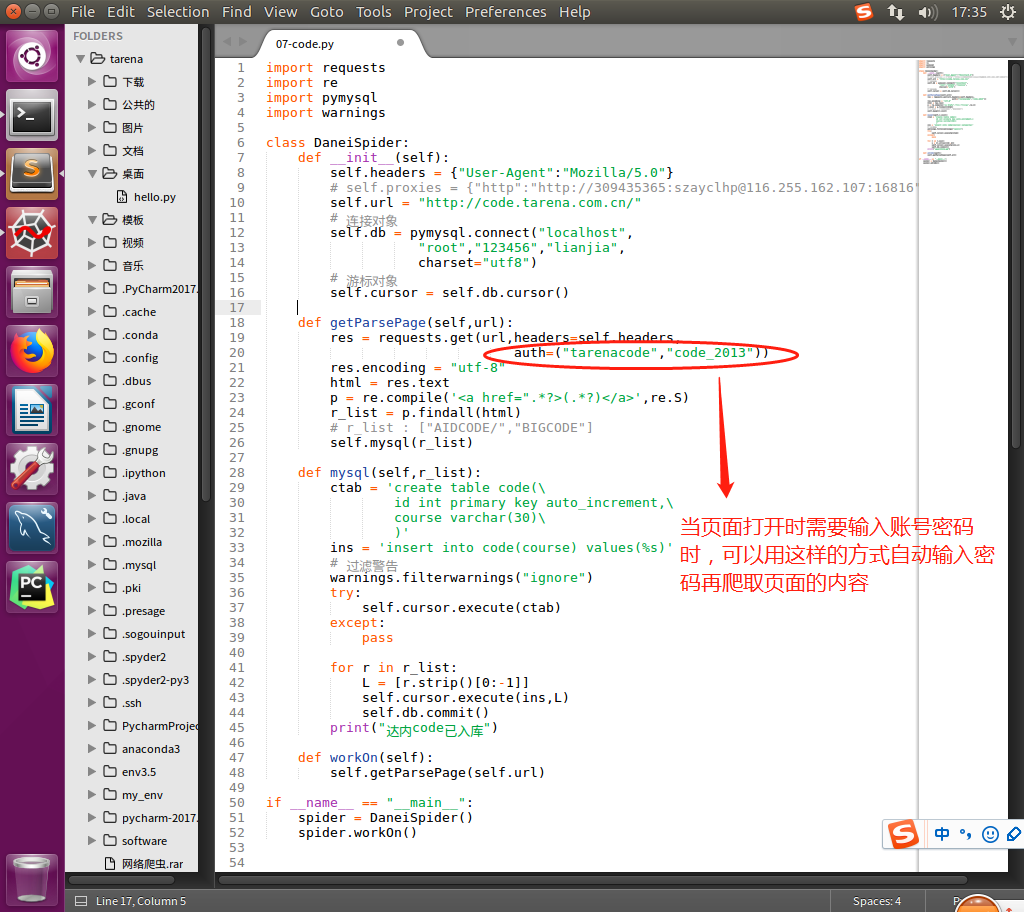
爬取需要账号密码登录的页面
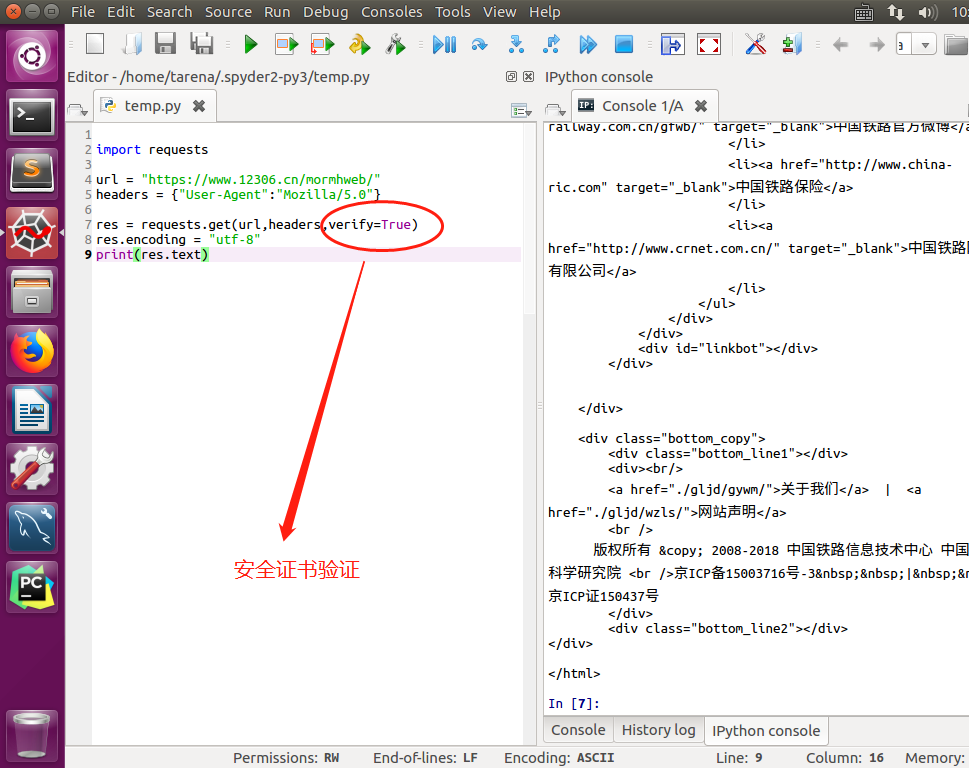
CA安全证书验证verify
urllib.request的handler处理器定义urlopen方法
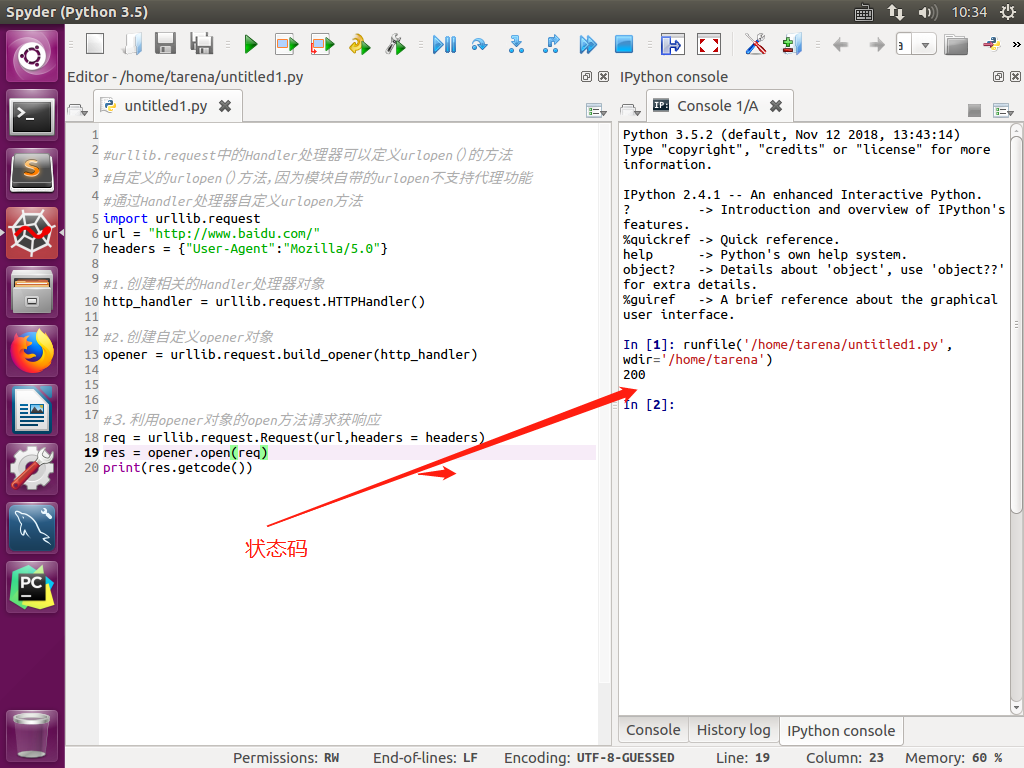
Handler处理器的分类
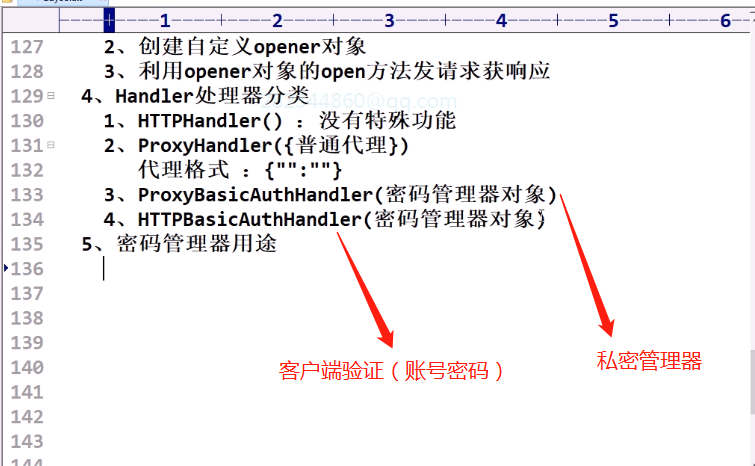
密码管理器对象操作的实现步骤
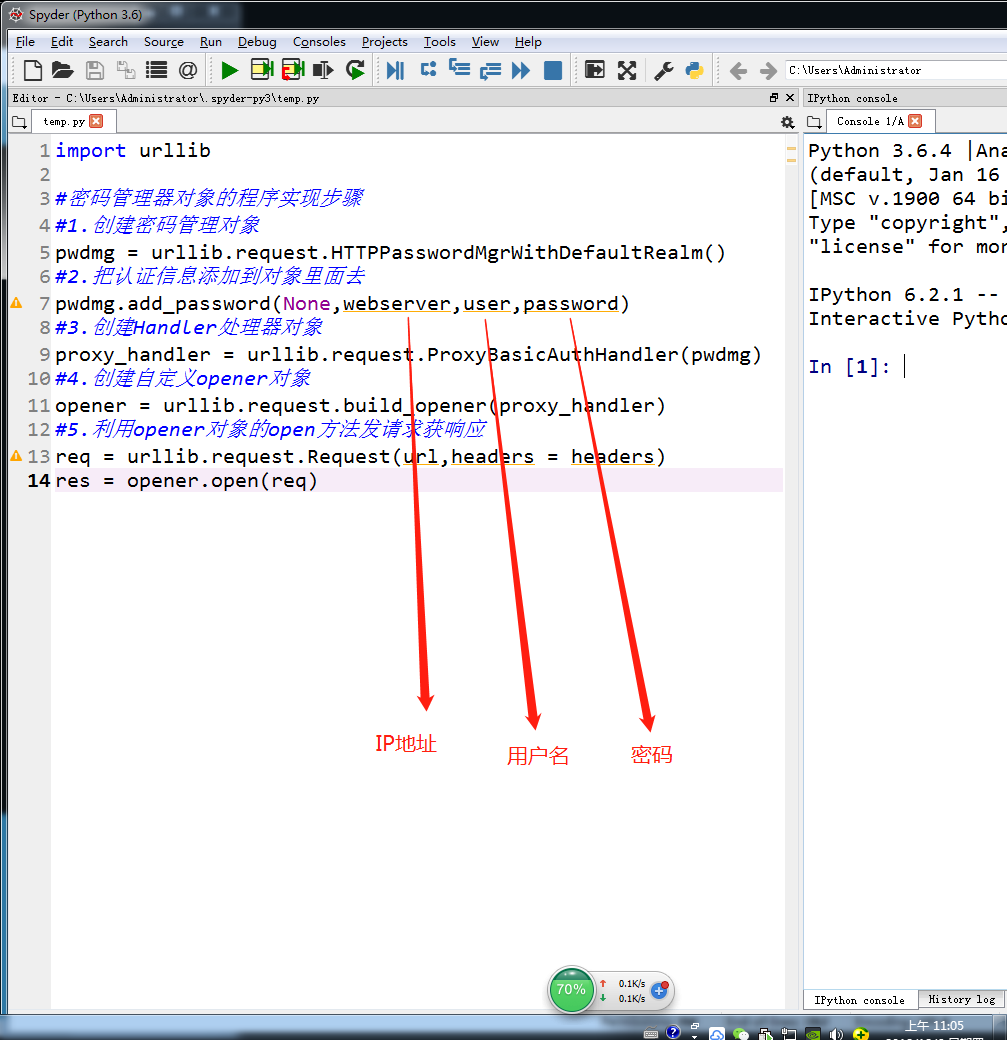
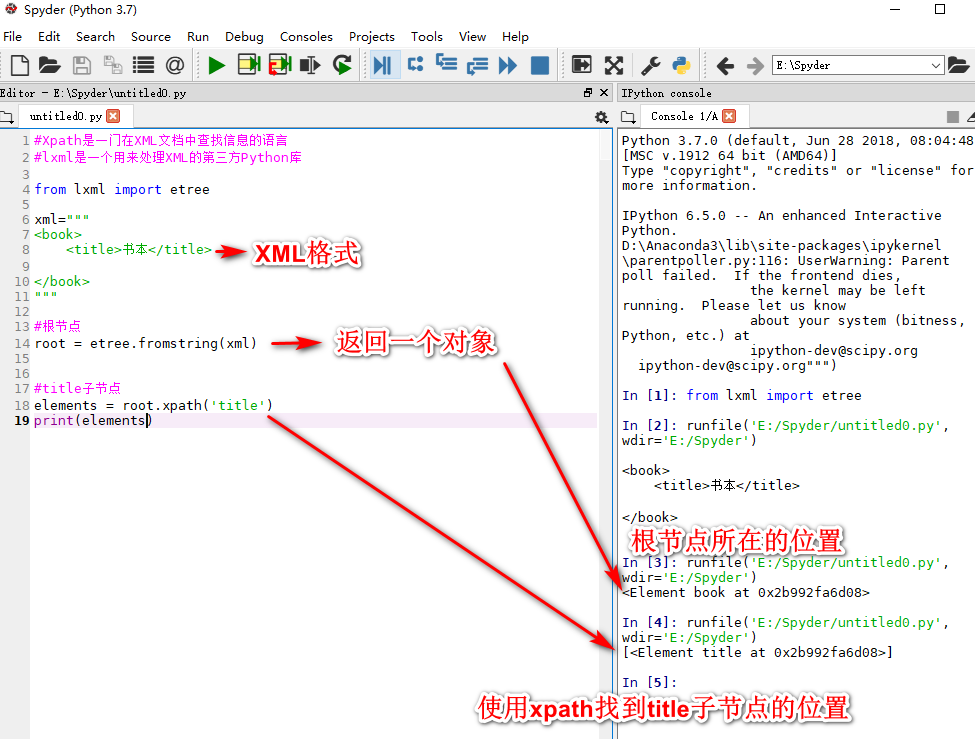
lxml和xpath的使用
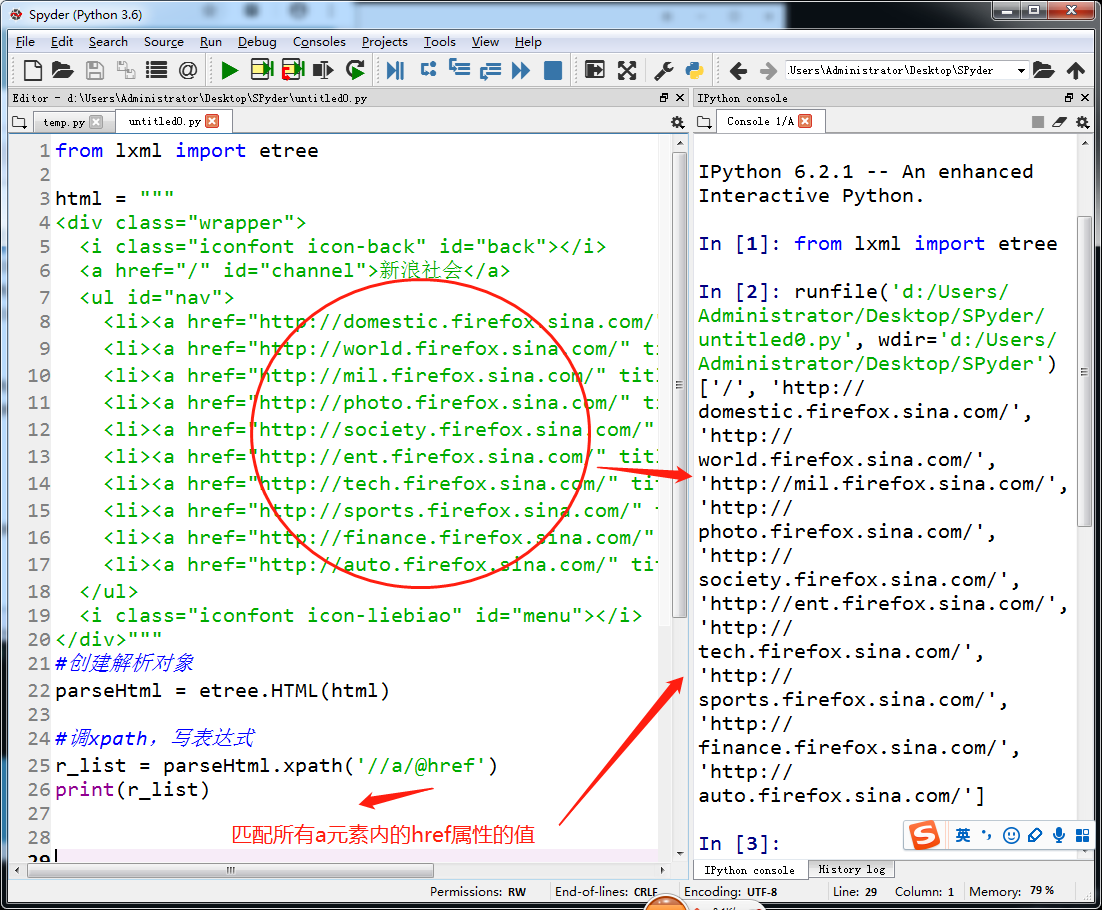
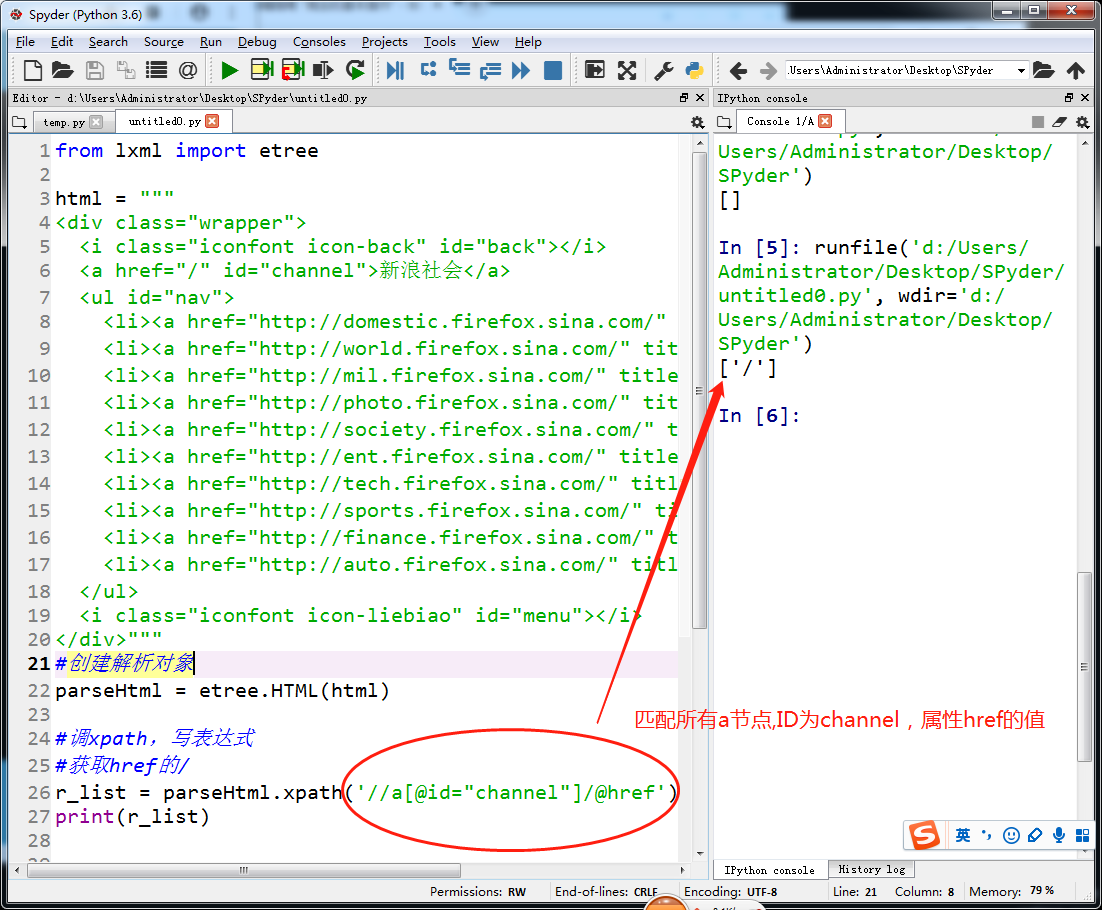
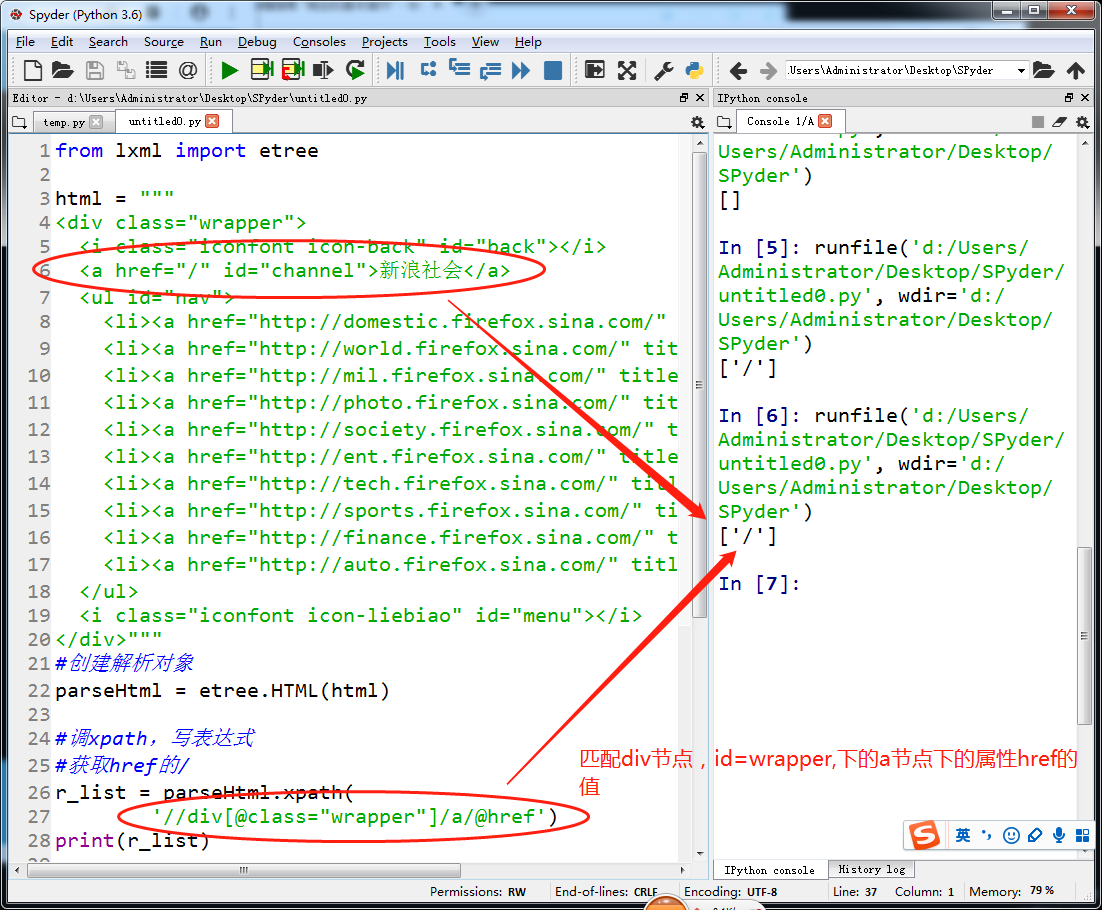
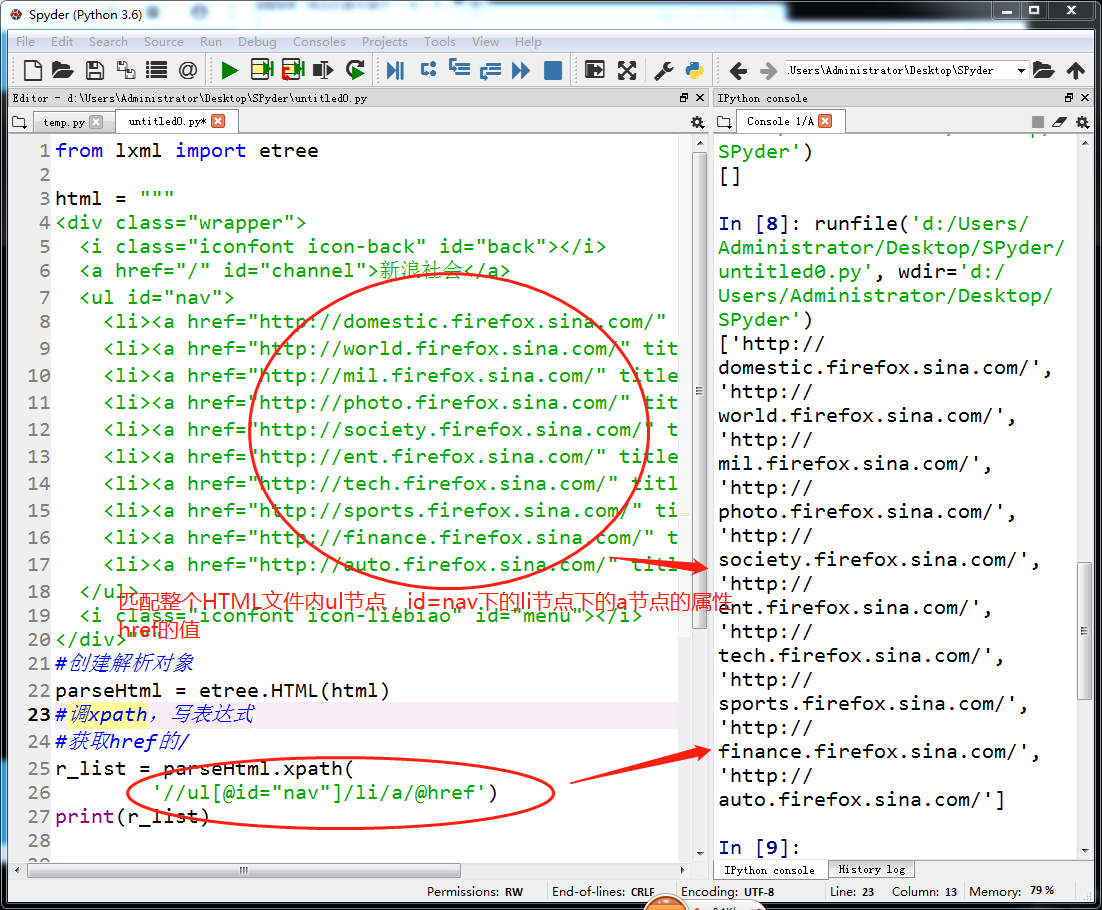
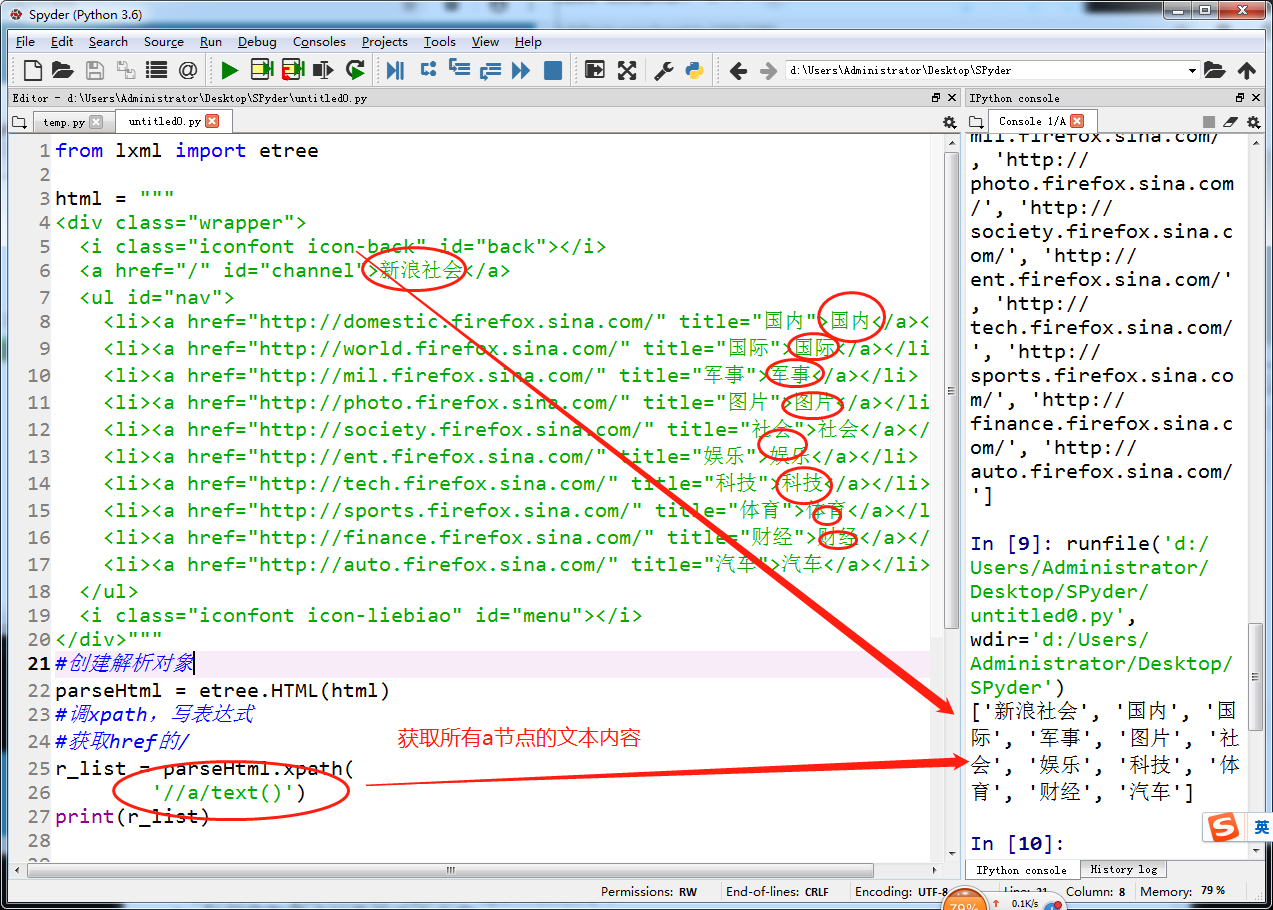
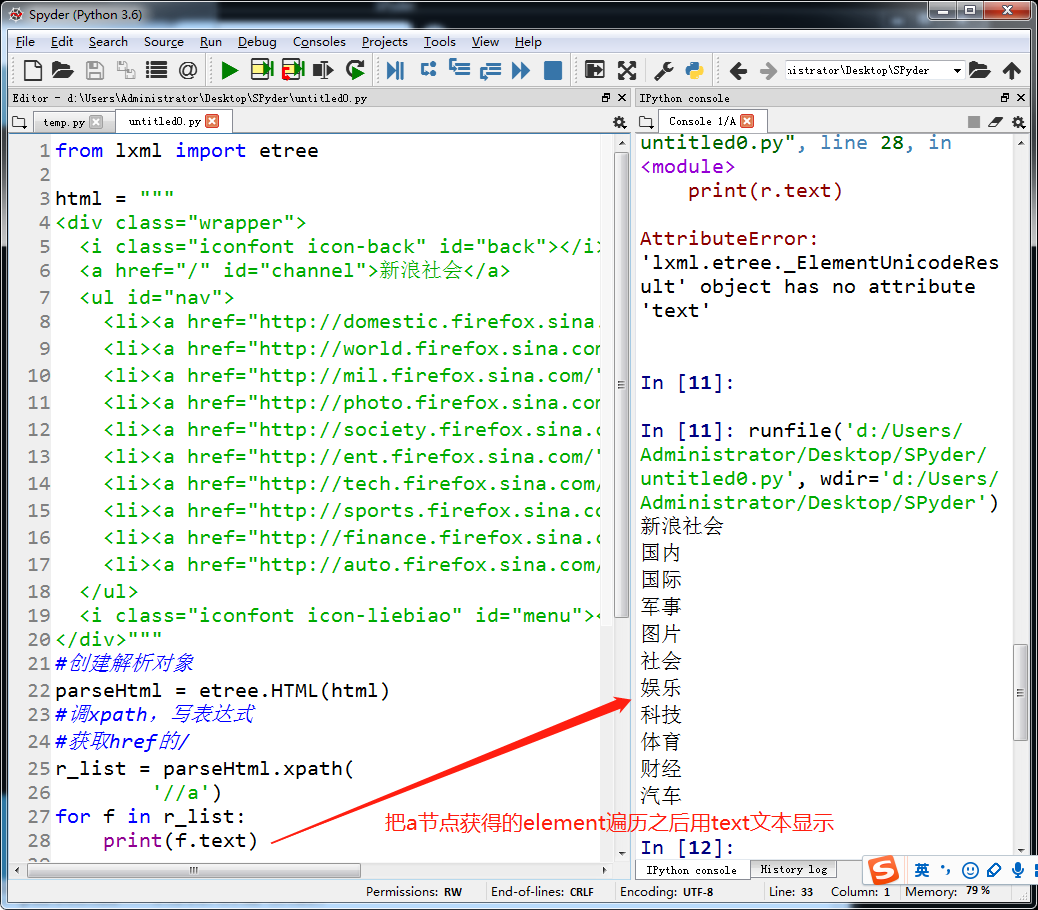
抓取百度贴吧图片(校花吧)

import requests
from lxml import etree
import urllib.parse
class ImageSpider:
def __init__(self):
self.headers = {"User-Agent":"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)"}
self.baseurl = ""
# 获取所有帖子URL列表
def getPageUrl(self,url):
# 获取校花吧页面的html
res = requests.get(url,headers=self.headers)
res.encoding = "utf-8"
html = res.text
# 提取页面中所有帖子的URL
parseHtml = etree.HTML(html)
t_list = parseHtml.xpath('//div[@class="t_con cleafix"]/div/div/div/a/@href')
# t_list : ["/p/32093","/p/203920","","",""]
for t_link in t_list:
t_url = "http://tieba.baidu.com" + t_link
self.getImageUrl(t_url)
# 获取每个帖子中图片的URL列表
def getImageUrl(self,t_url):
# 获取1个帖子的响应html
res = requests.get(t_url,headers=self.headers)
res.encoding = "utf-8"
html = res.text
# 从html响应中获取图片URL列表
parseHtml = etree.HTML(html)
img_list = parseHtml.xpath('//div[@class="d_post_content j_d_post_content clearfix"]/img/@src')
for img_link in img_list:
self.writeImage(img_link)
# 保存图片
def writeImage(self,img_link):
# 获取每个图片的二进制
res = requests.get(img_link,headers=self.headers)
res.encoding = "utf-8"
html = res.content
# 保存到本地(以图片链接的后12位作为文件名)
filename = img_link[-8:]
with open(filename,"wb") as f:
f.write(html)
print(filename,"下载成功")
# 主函数
def workOn(self):
name = input("请输入贴吧名:")
begin = int(input("请输入开始页:"))
end = int(input("请输入结束页:"))
for pn in range(begin,end+1):
# 拼接贴吧页面URL
pn = (pn-1)*50
kw = {"kw":name}
kw = urllib.parse.urlencode(kw)
fullurl = \
"http://tieba.baidu.com/f?" + \
kw + "&pn=" + str(pn)
# 直接调类内函数
self.getPageUrl(fullurl)
if __name__ == "__main__":
spider = ImageSpider()
spider.workOn()
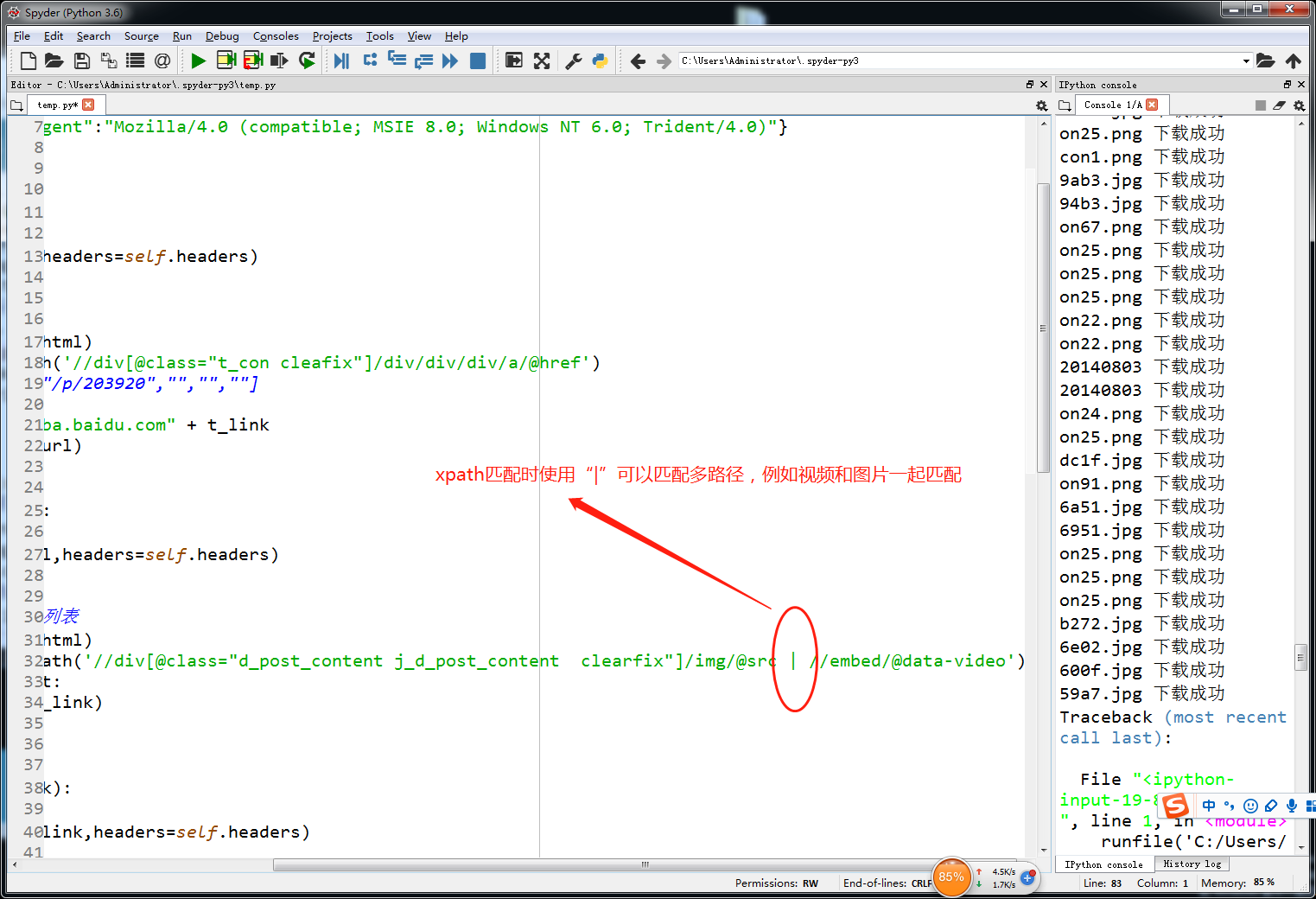
xpath使用“ | ”可以多路径匹配
爬取糗事百科xpath

import requests
import pymongo
from lxml import etree
class QiushiSpider:
def __init__(self):
self.headers = {"User-Agent":"Mozilla/5.0"}
# 连接对象
self.conn = pymongo.MongoClient("localhost",
27017)
# 库对象
self.db = self.conn["Qiushi"]
# 集合对象
self.myset = self.db["qiushiinfo"]
# 获取页面
def getPage(self,url):
res = requests.get(url,headers=self.headers)
res.encoding = "utf-8"
html = res.text
self.parsePage(html)
# 解析并存入数据库
def parsePage(self,html):
# 创建解析对象
parseHtml = etree.HTML(html)
# 获取每个段子的节点对象列表
base_list = parseHtml.xpath('//div[contains(@id,"qiushi_tag_")]')
for base in base_list:
# 节点对象可调用xpath
# 用户昵称
username = base.xpath('./div/a/h2')
if len(username) == 0:
username = "匿名用户"
else:
username = base.xpath('./div/a/h2')[0].text.strip()
# 段子内容
content = base.xpath('.//div[@class="content"]/span')
# 好笑数量
laughNum = base.xpath('.//i')[0]
# 评论数量
pingNum = base.xpath('.//i')[1]
d = {
"username":username,
"content":content[0].text.strip(),
"laughNum":laughNum.text,
"pingNum":pingNum.text
}
self.myset.insert(d)
print("成功")
if __name__ == "__main__":
spider = QiushiSpider()
spider.getPage("https://www.qiushibaike.com/8hr/page/1/")
获取帖子中真实的URL(反爬机制)
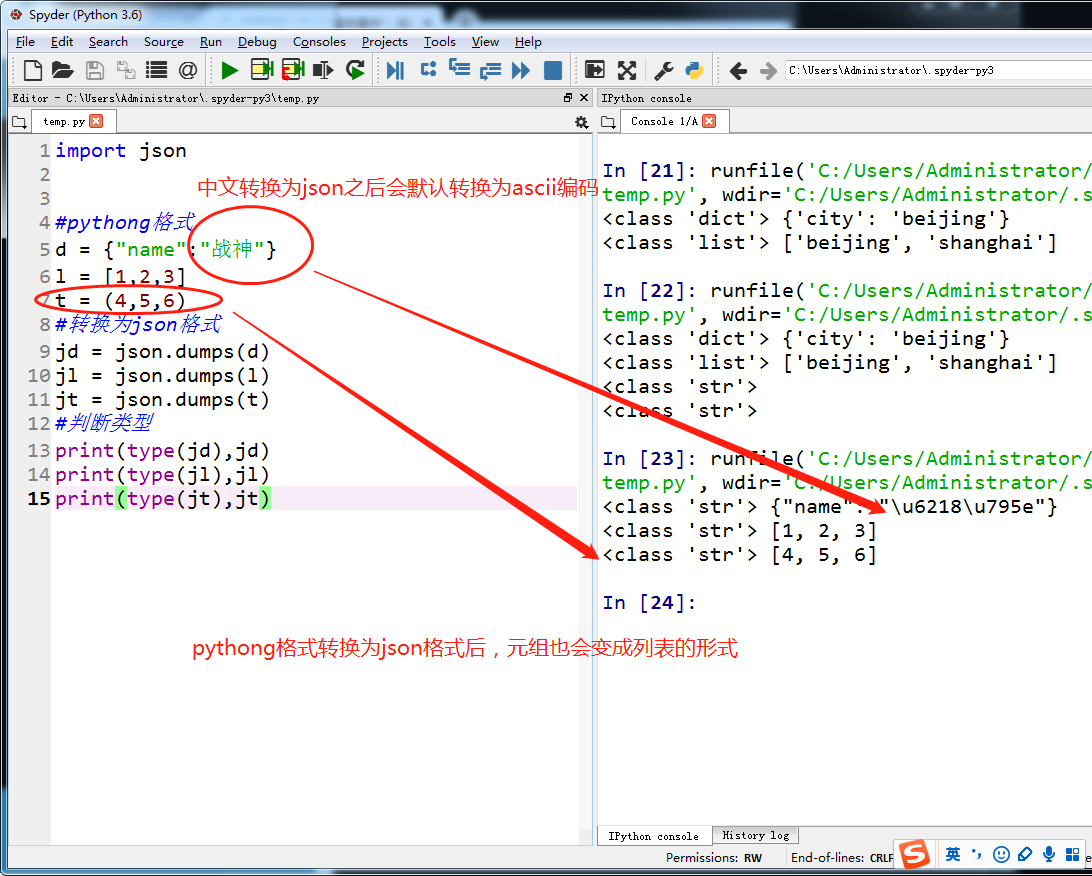
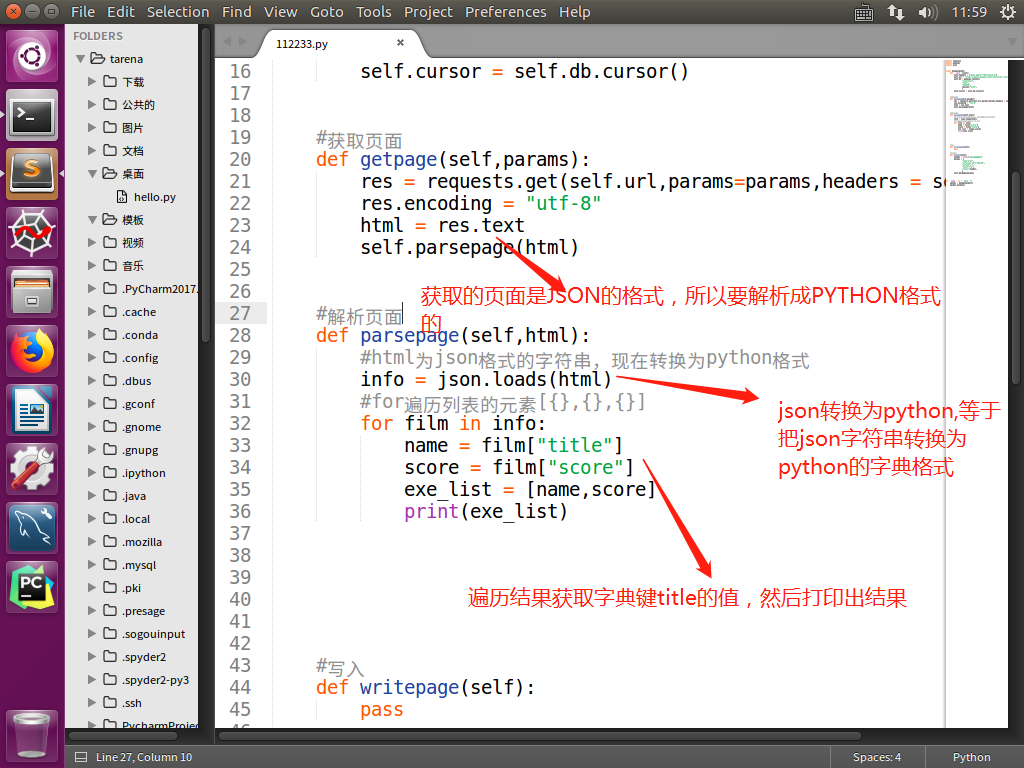
把json格式字符串转换为python格式
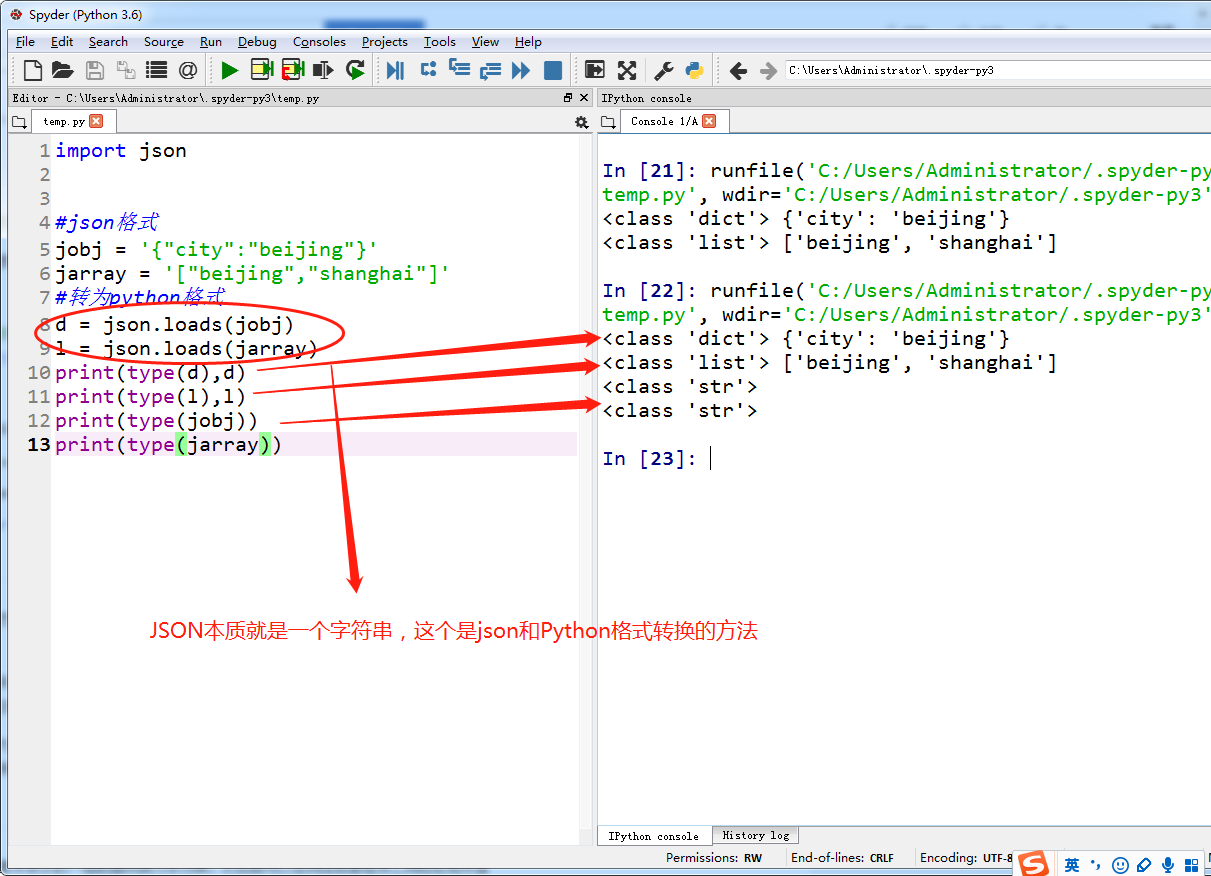
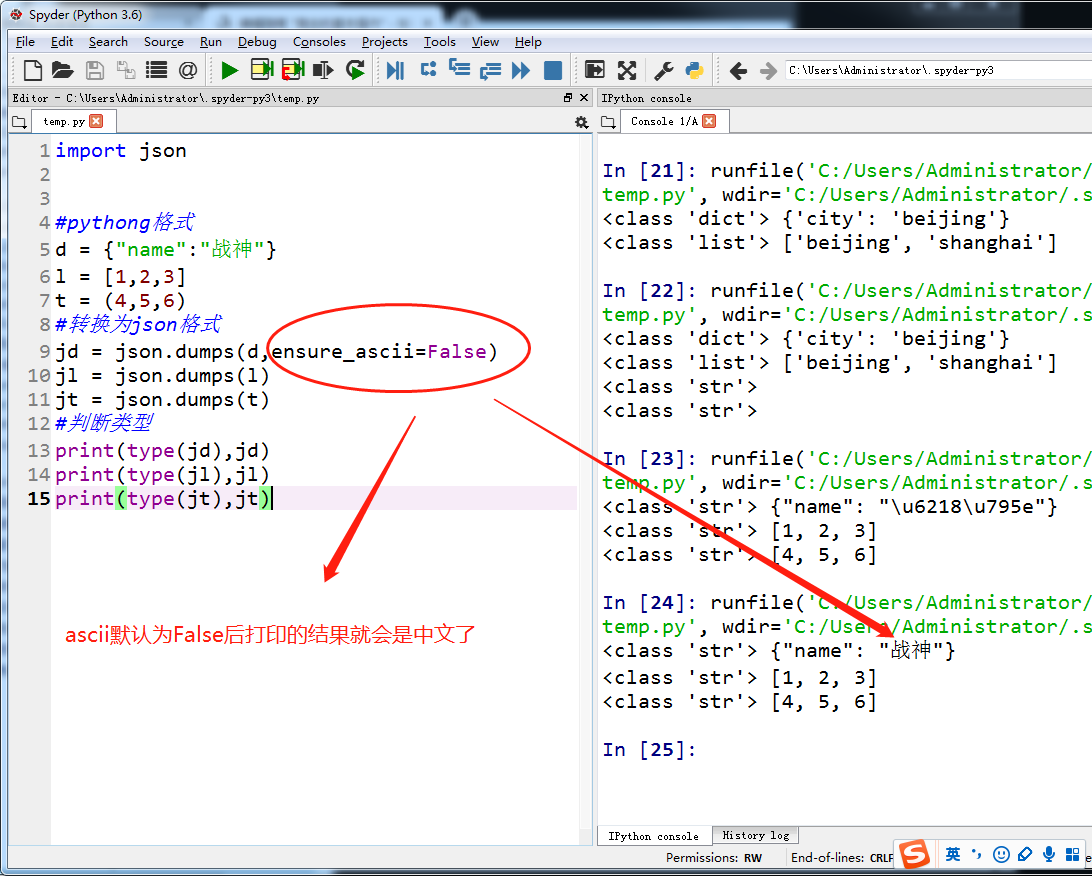
把python格式转换为json格式
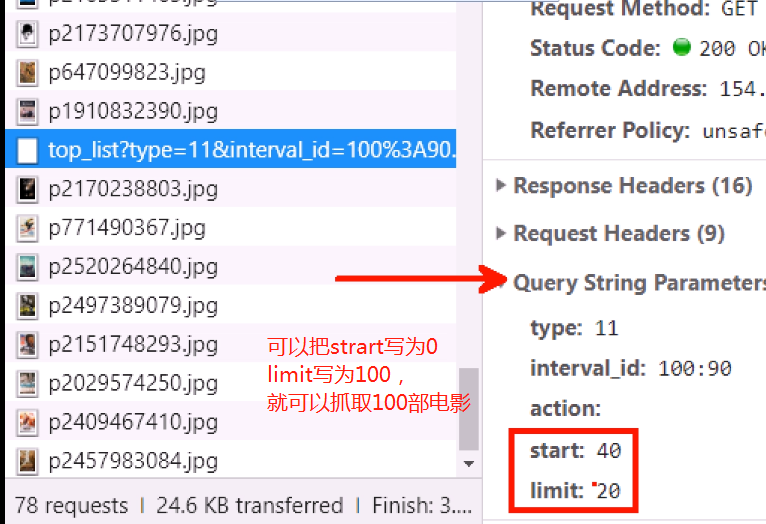
抓取猫眼电影时,遇到动态加载的ajax页面时,需要抓取Query String和发送请求时的Request uRL
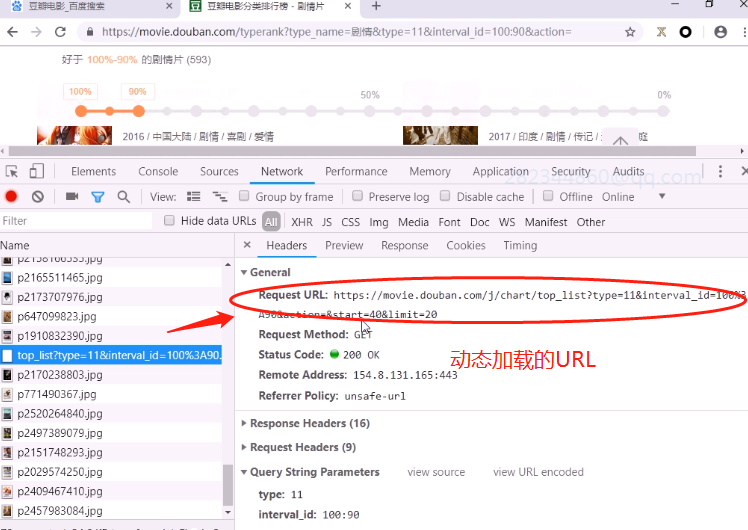
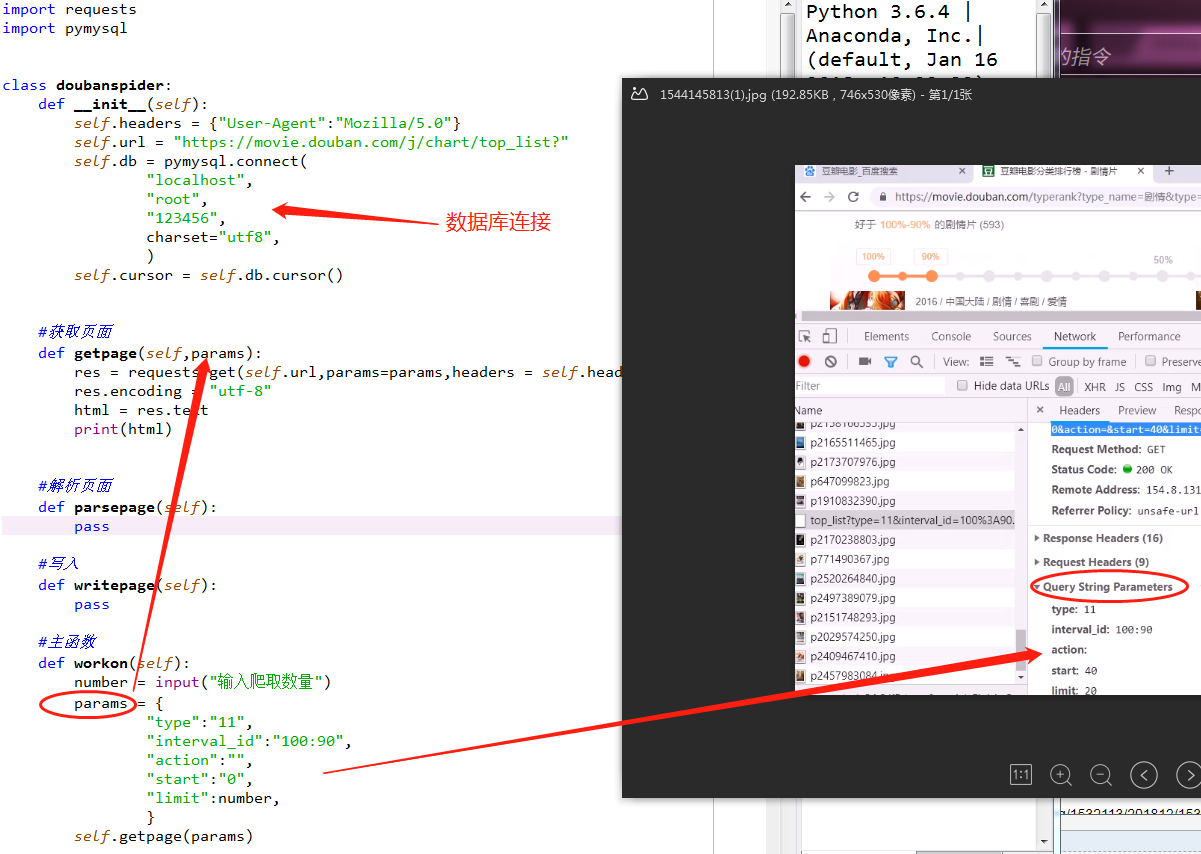
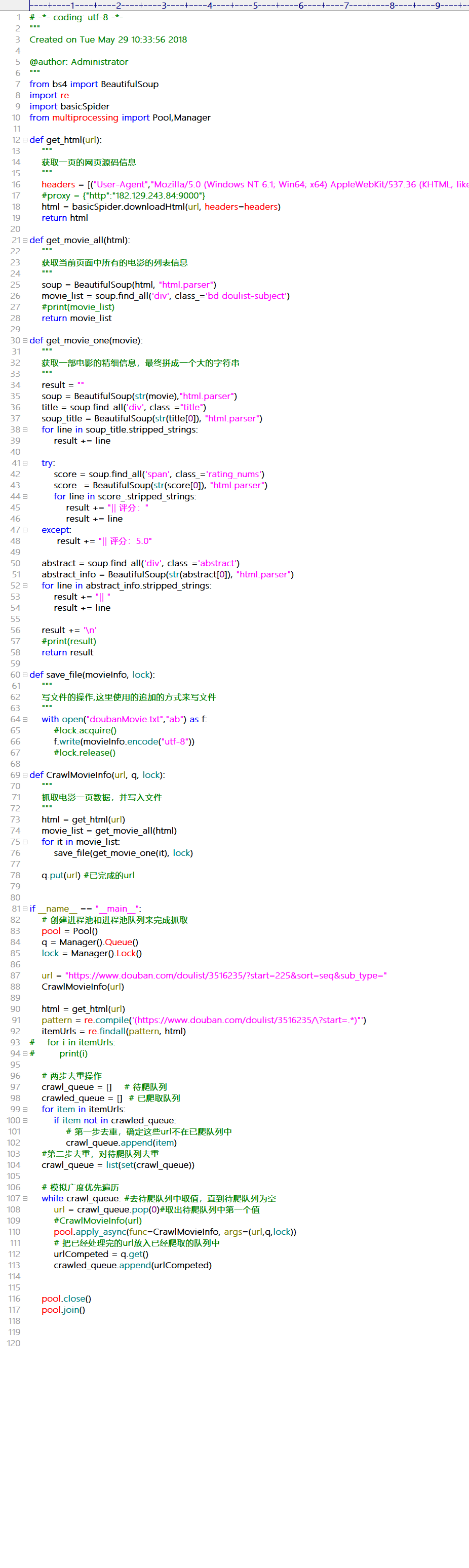
豆瓣电影抓取(动态页面,ajax)
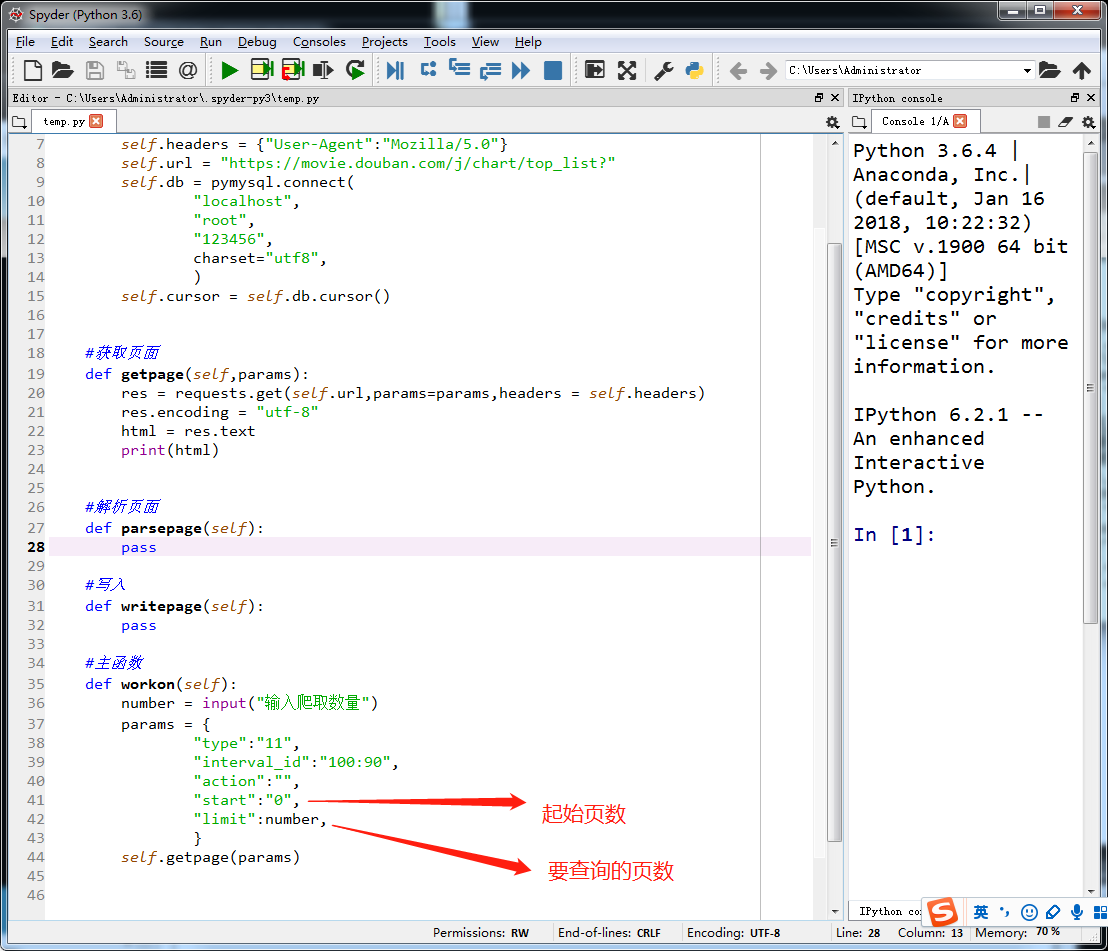
测试抓取的效果
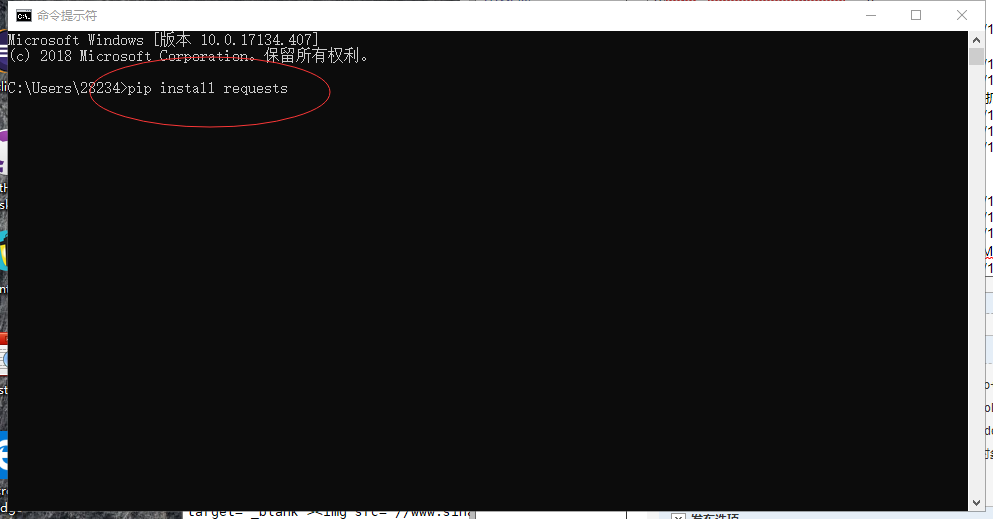
当新安装的spyder没有requests库或者其他时使用CMD安装(windows)
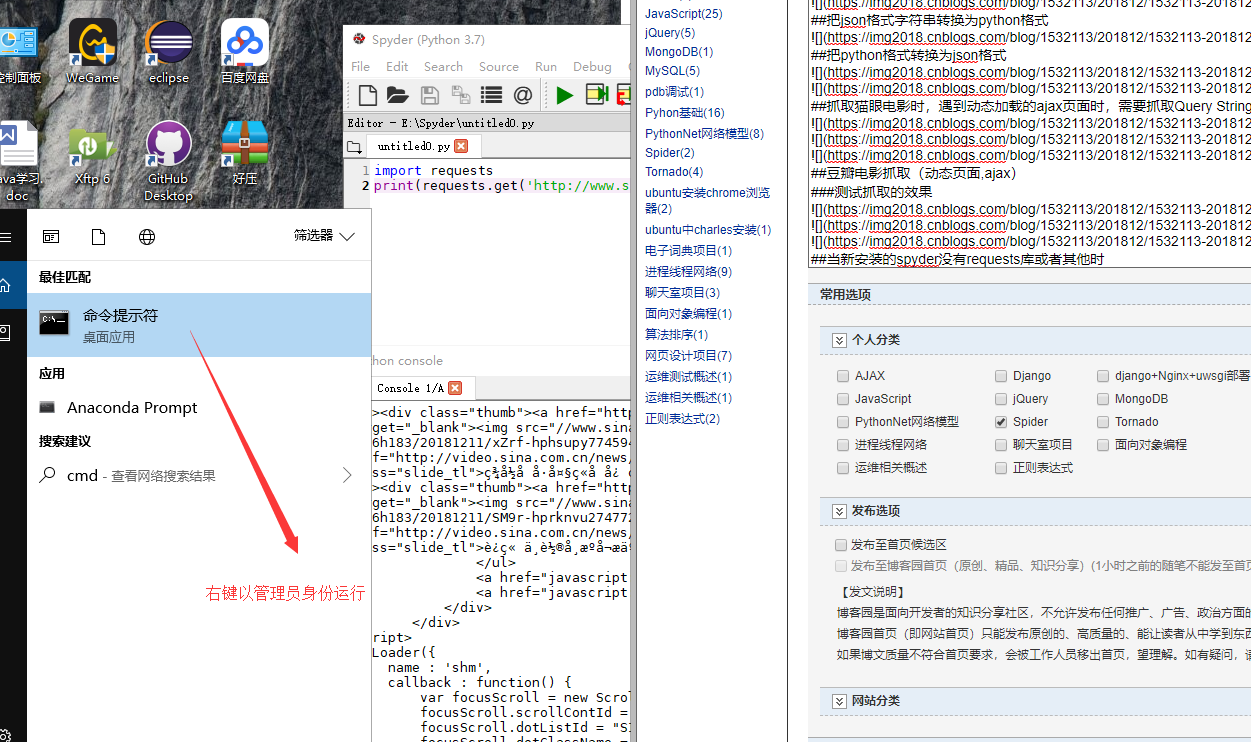
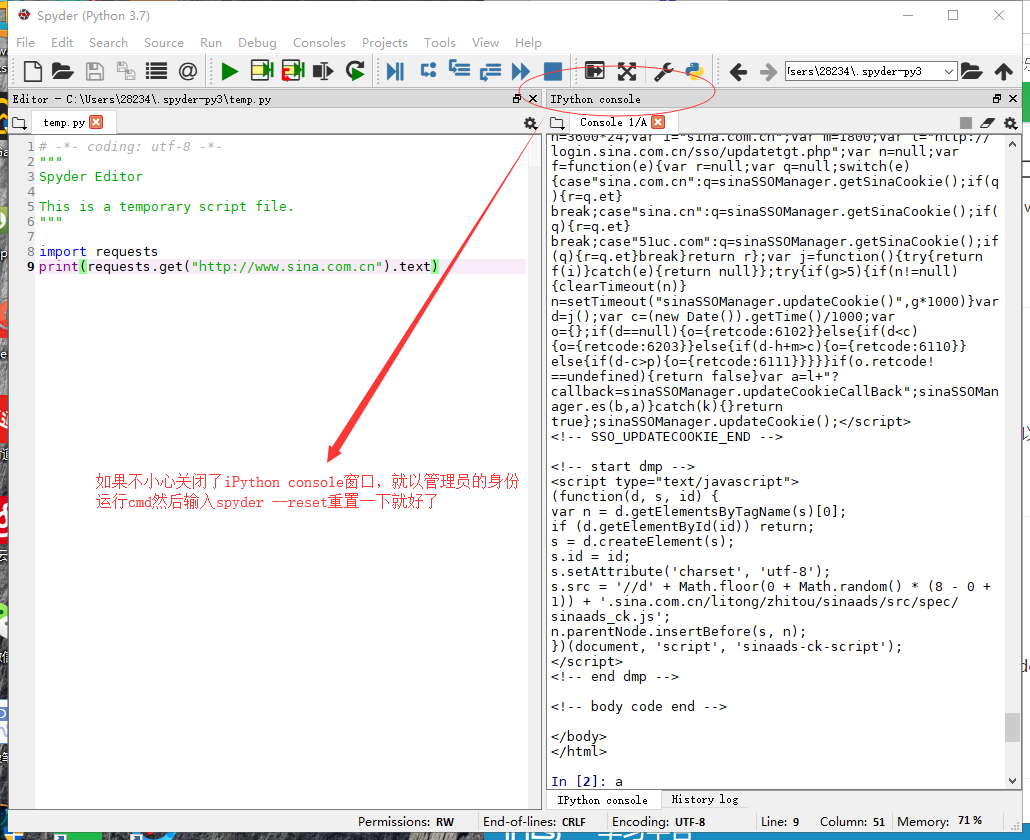
不小心关闭了ipython console窗口就重置
with open as f (打开模式)

from urllib import request 的方法来获取HTML页面

使用builtwith获取网站的技术架构

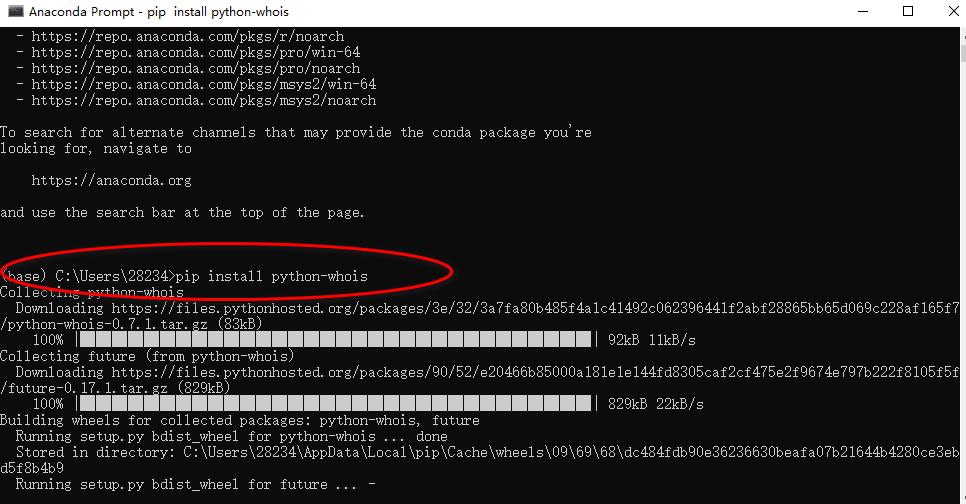
python-whois查看网站所有者
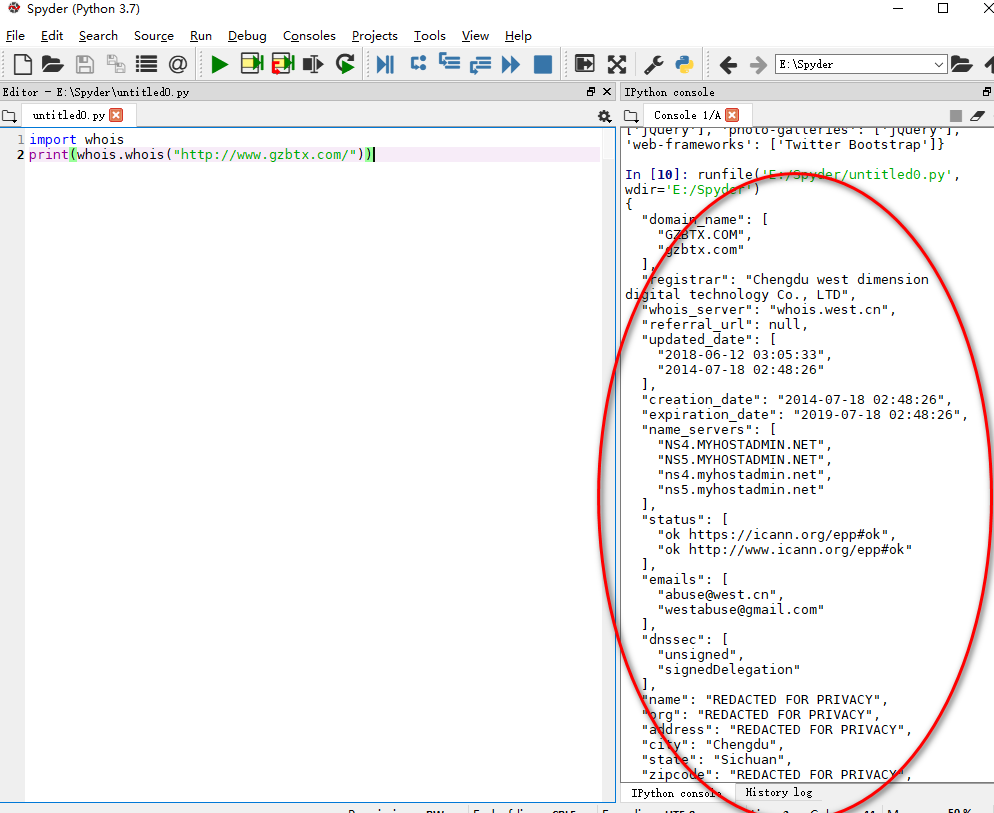
staus_code获取网站的状态码
URL基本格式(https://www.baidu.com)

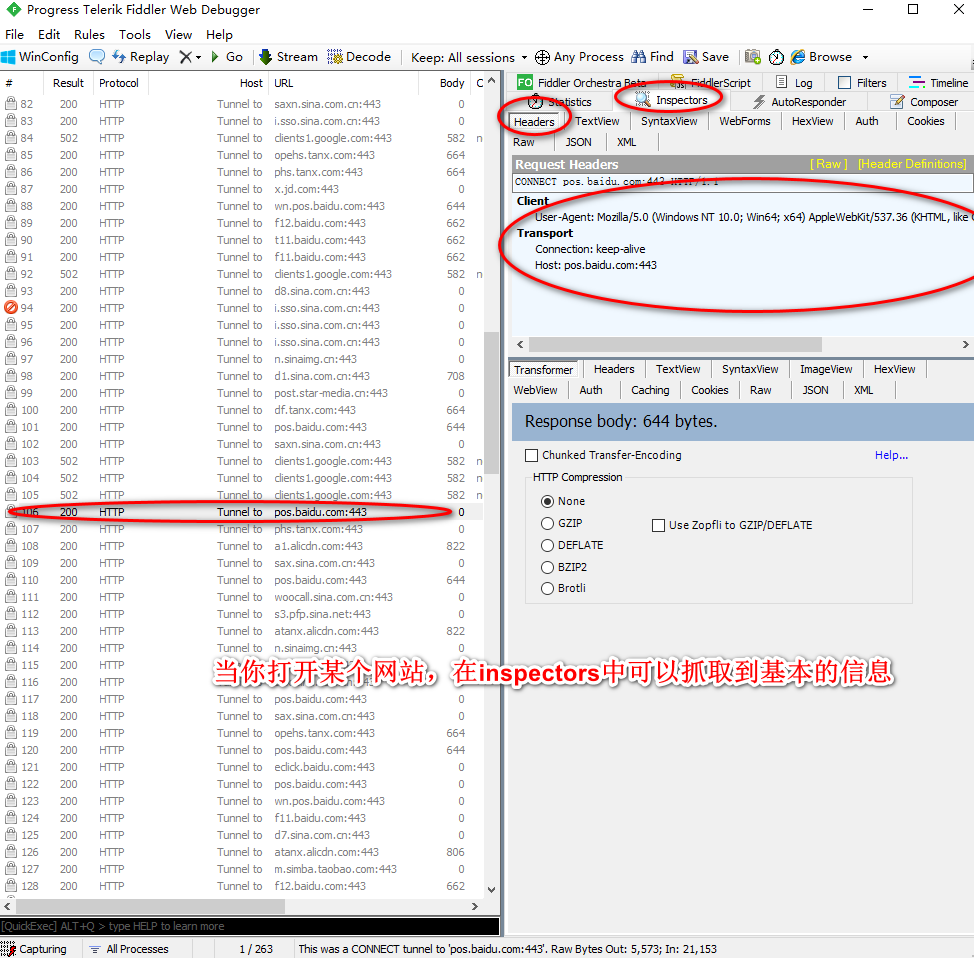
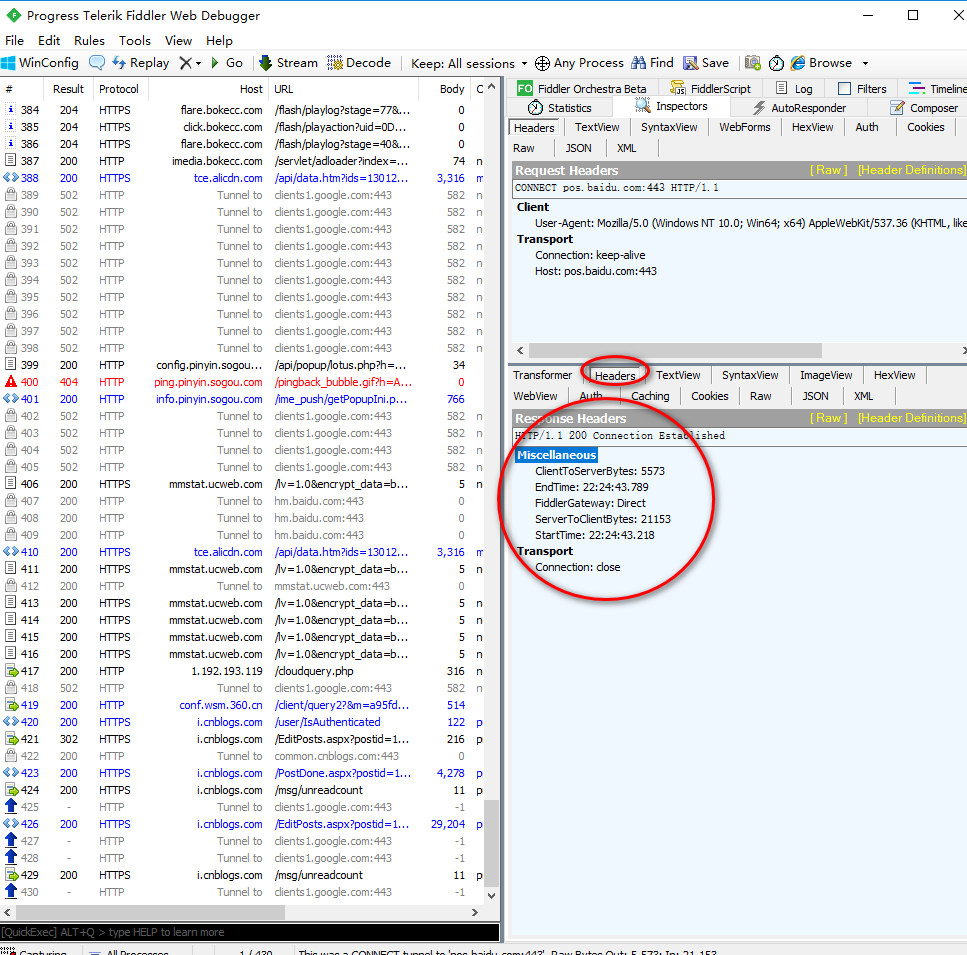
使用fiddler4获取某个网站的基本信息
设置headers的User-Agent
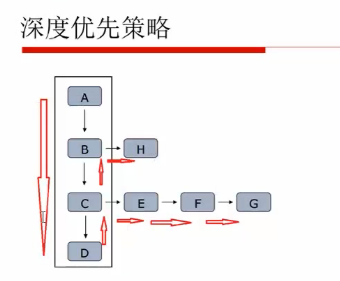
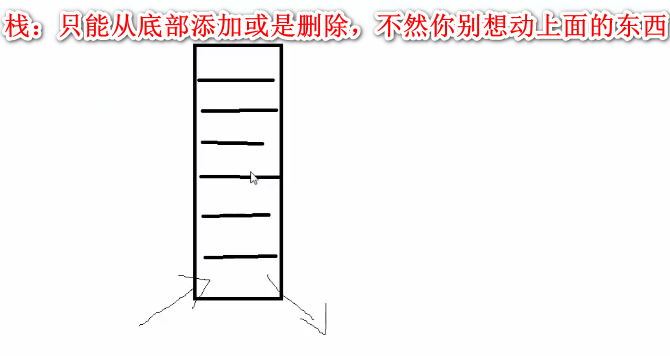
爬虫的深度优先策略(递归数据结构,堆栈结构)
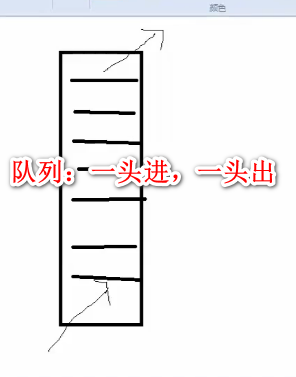

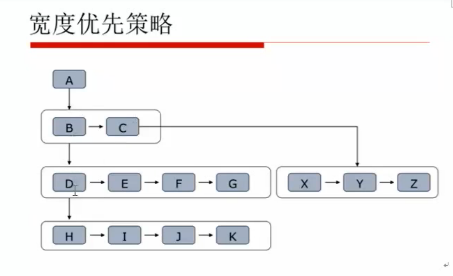
爬虫的宽度(广度)优先策略
完全二叉树
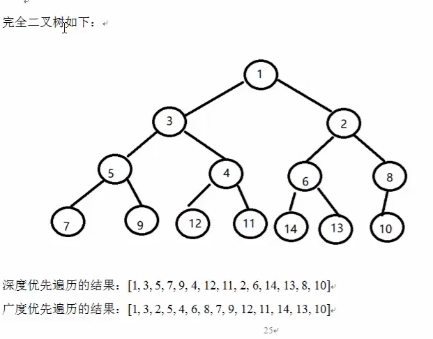
广度优先遍历

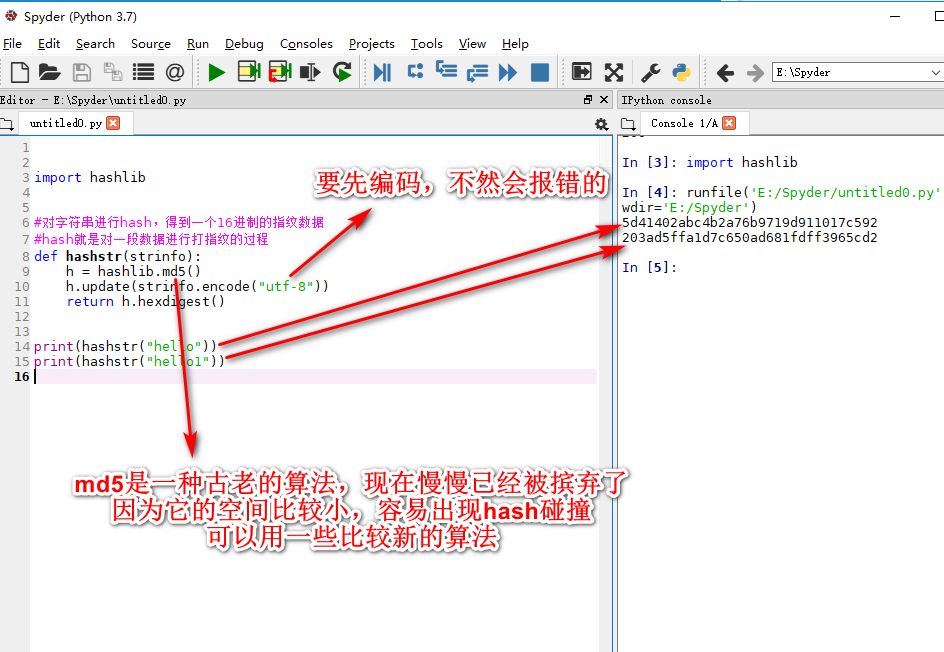
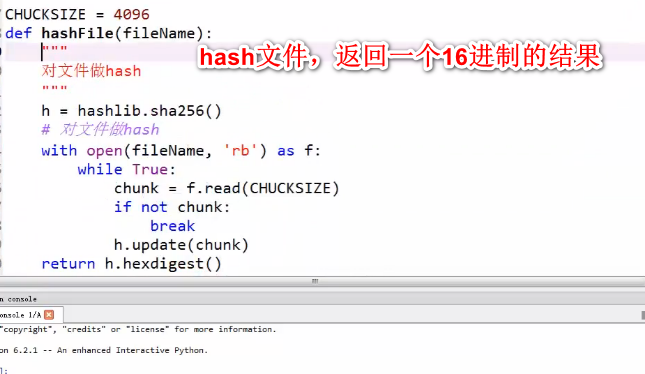
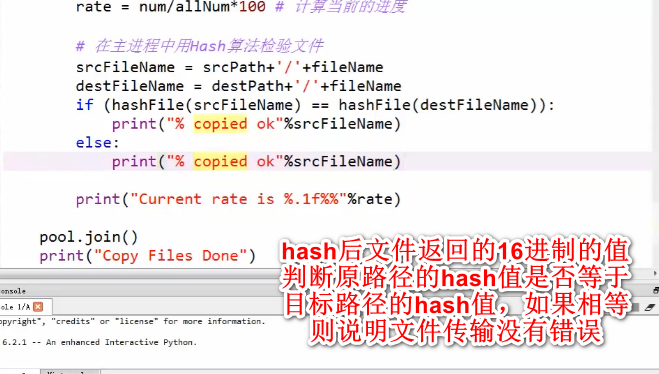
hash算法(打印成16进制,需要先编码utf8)
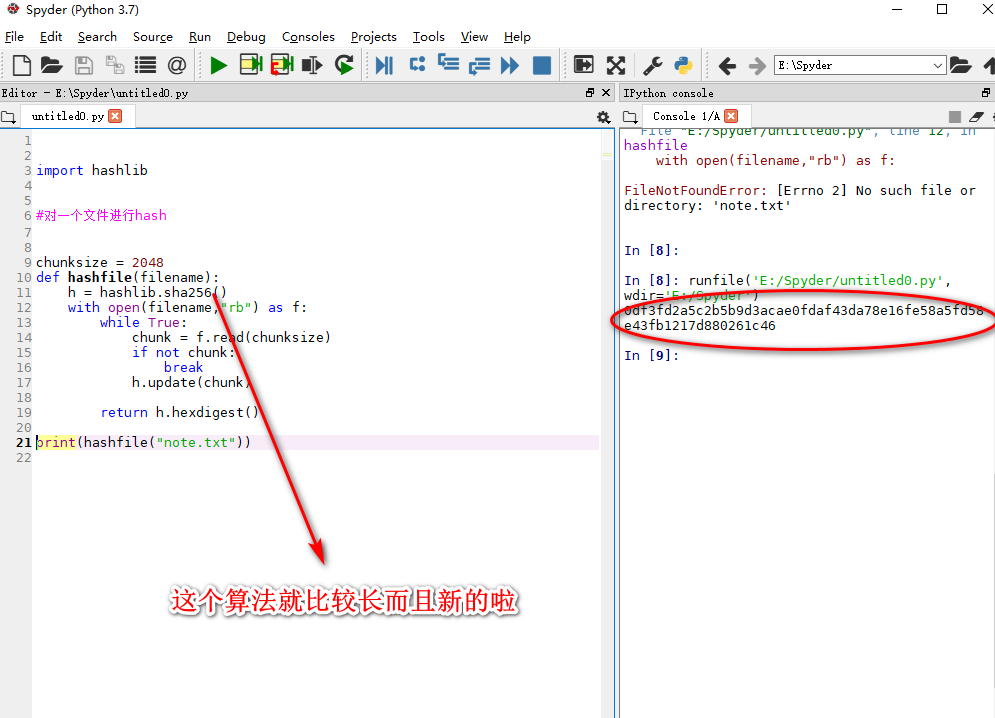
hash一个文件
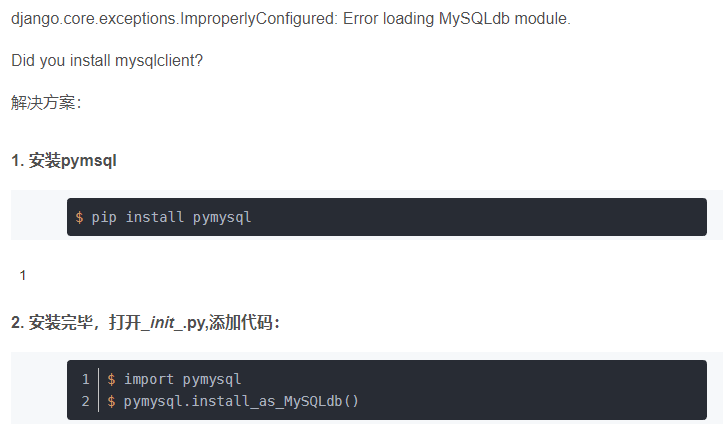
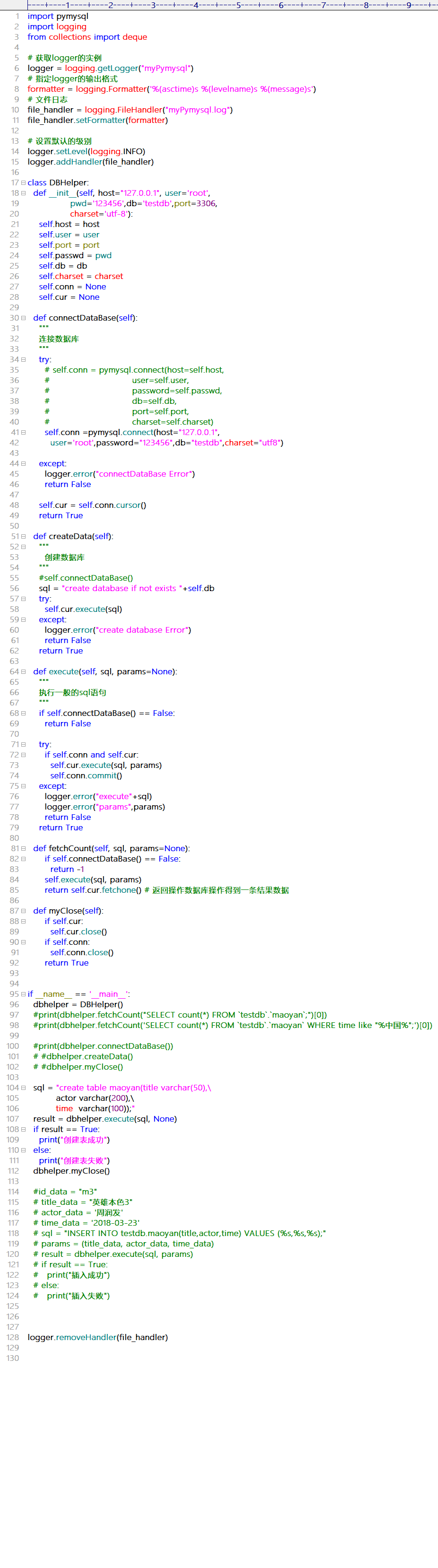
pymysql导入
xpath and lxml
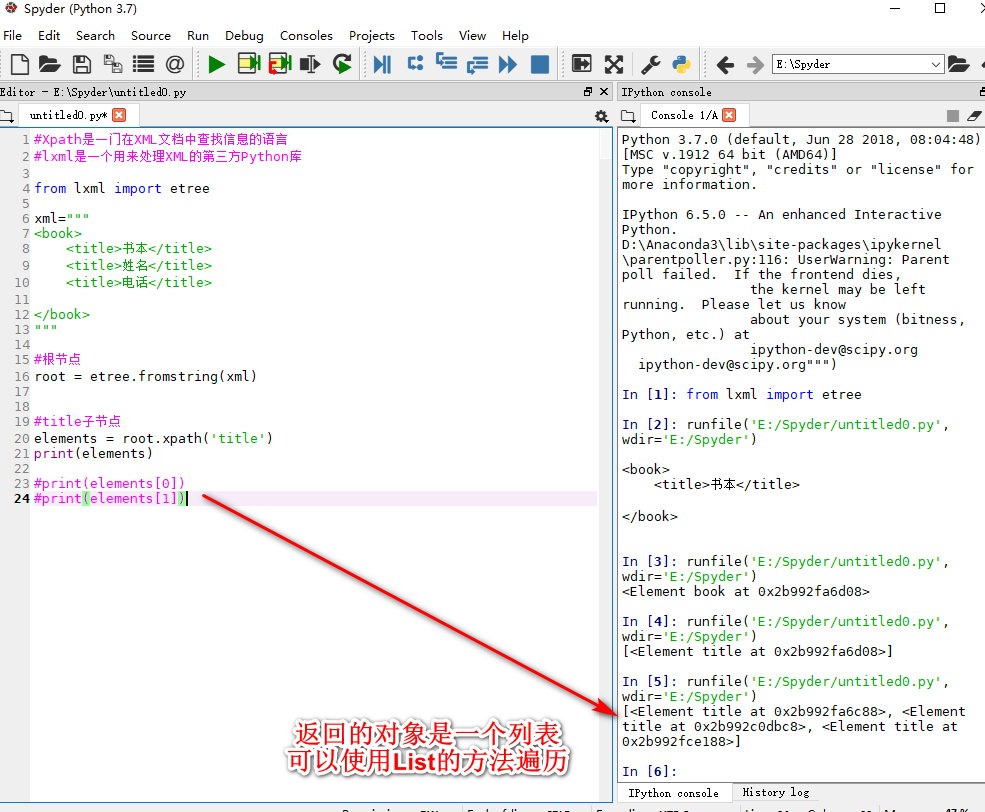
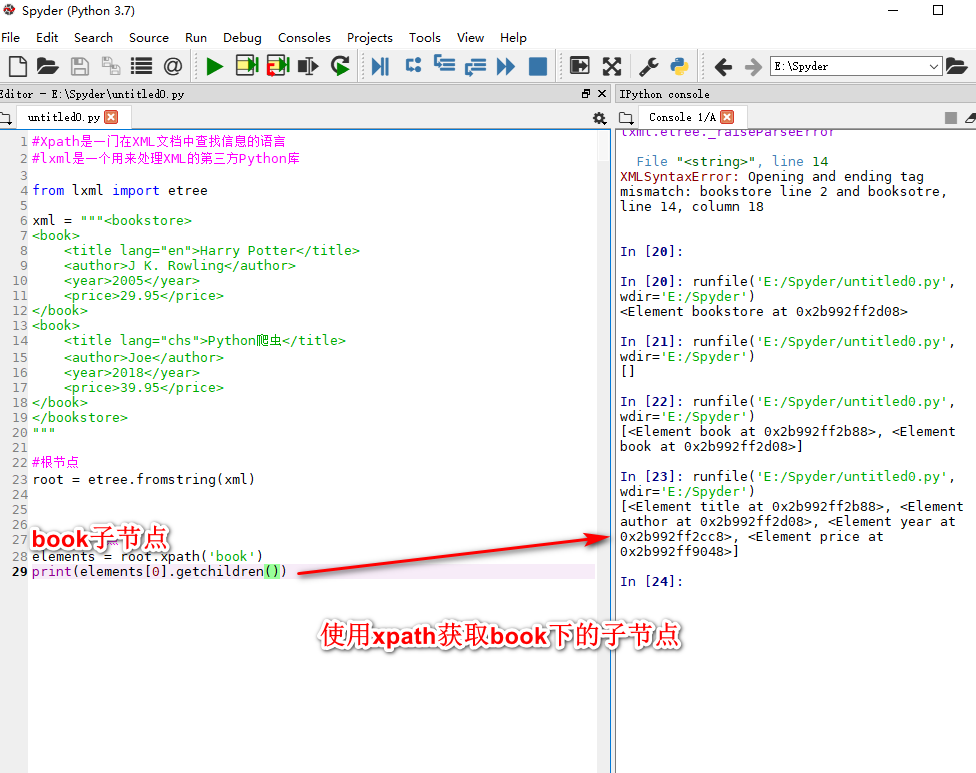
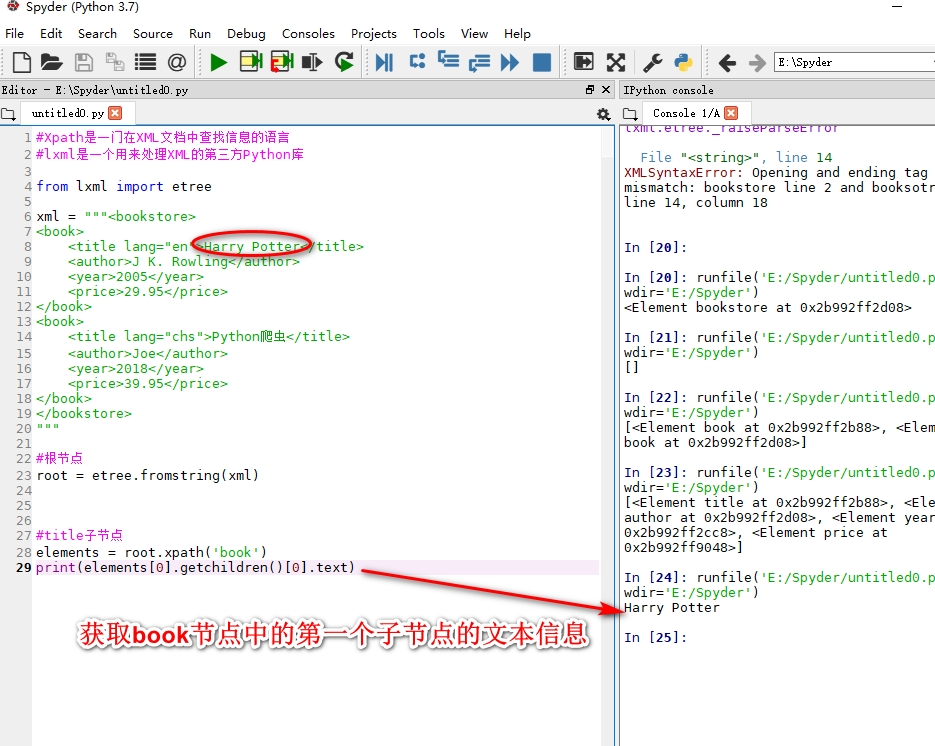
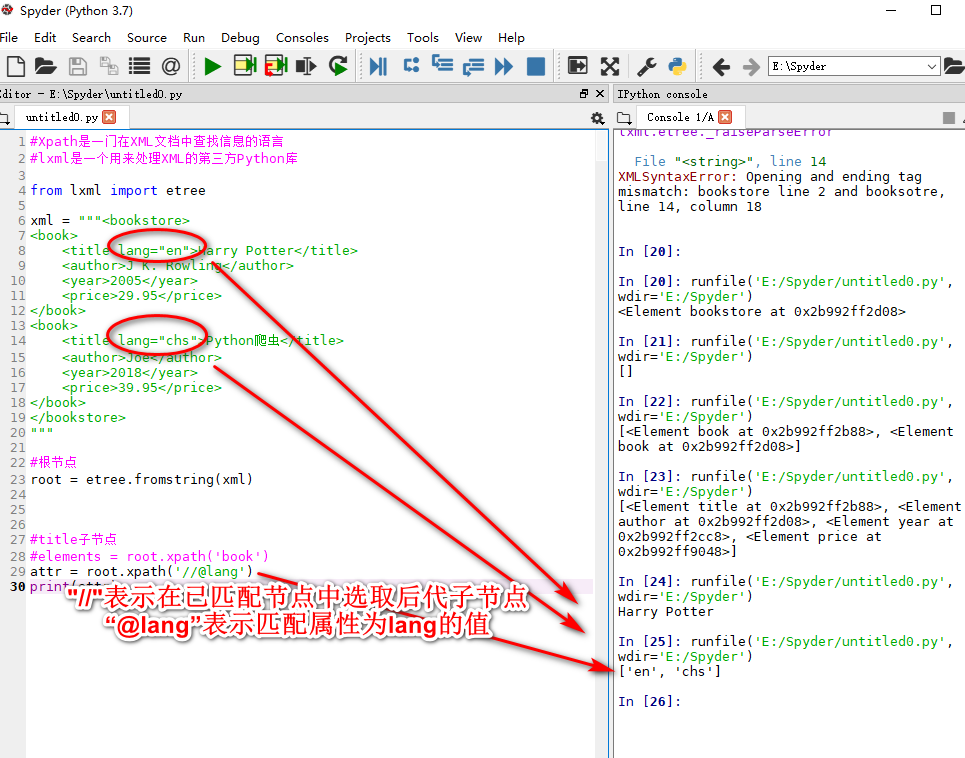
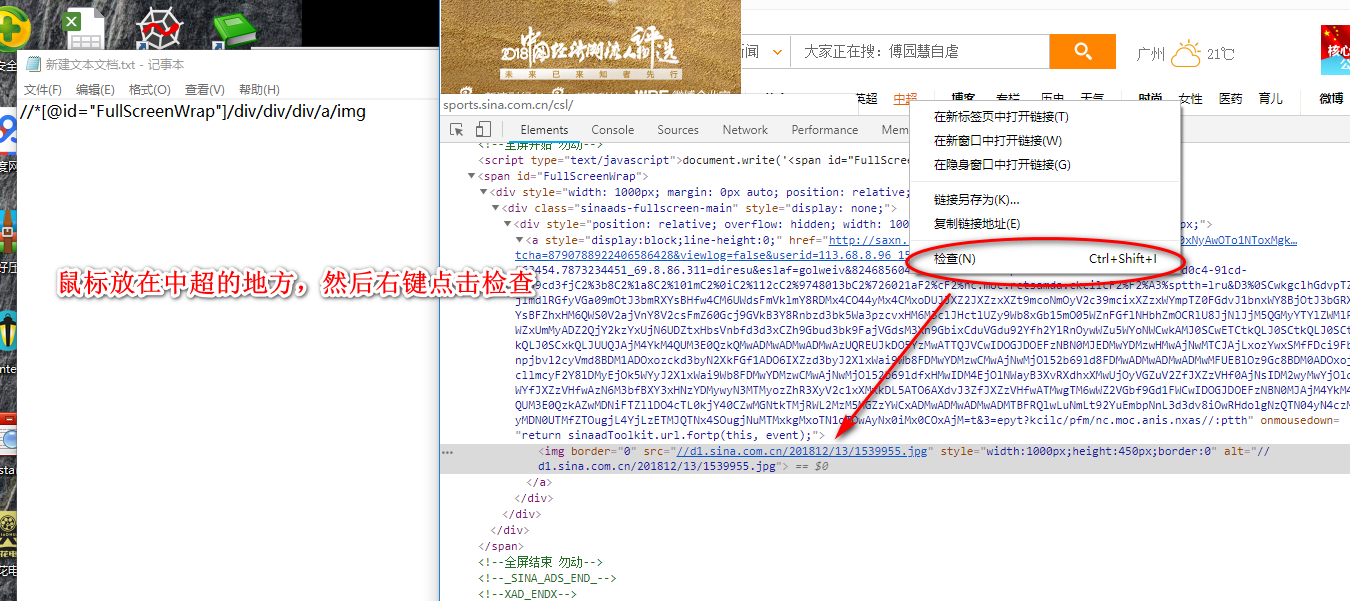
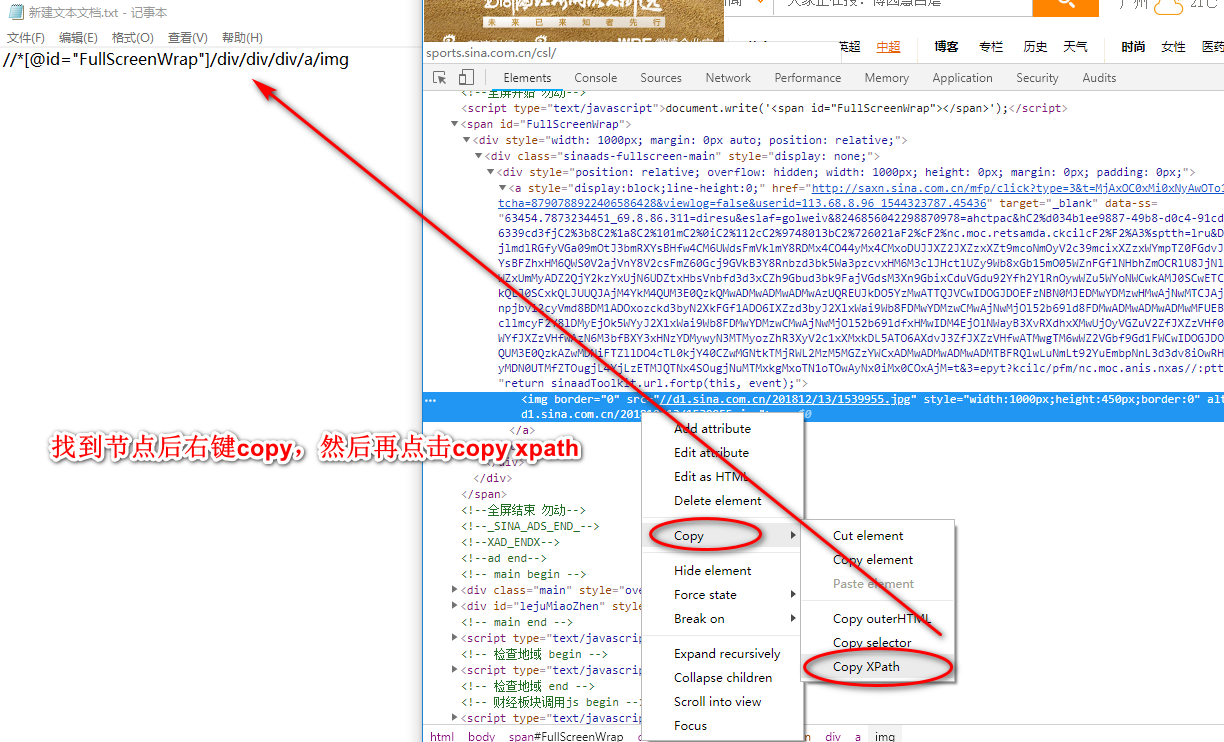
获取页面中某个元素节点的匹配路径xpayh copy
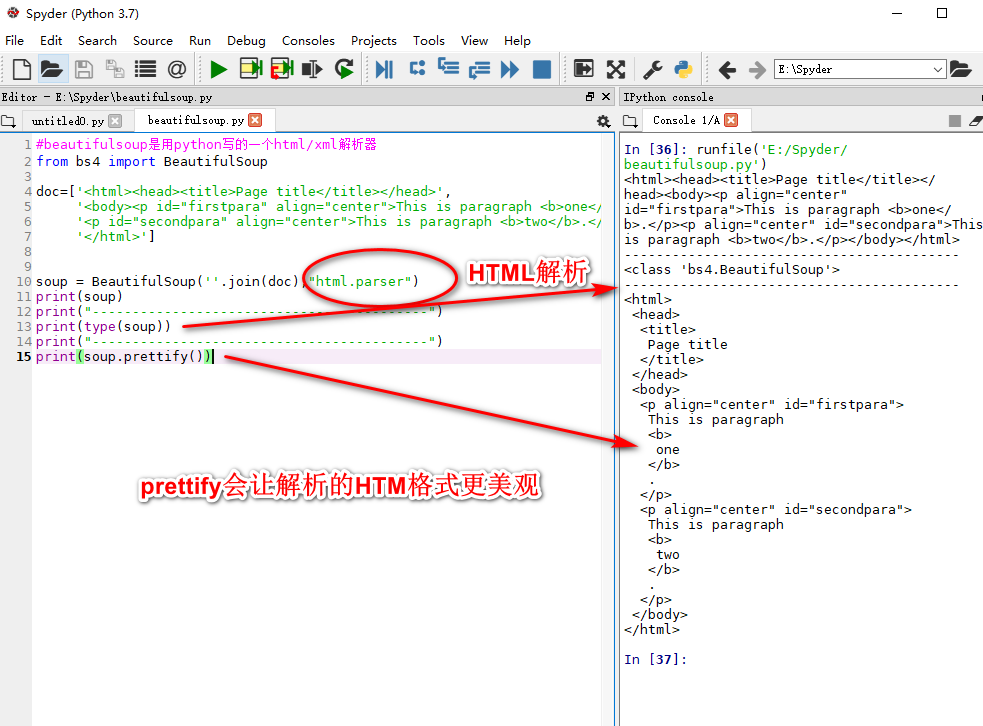
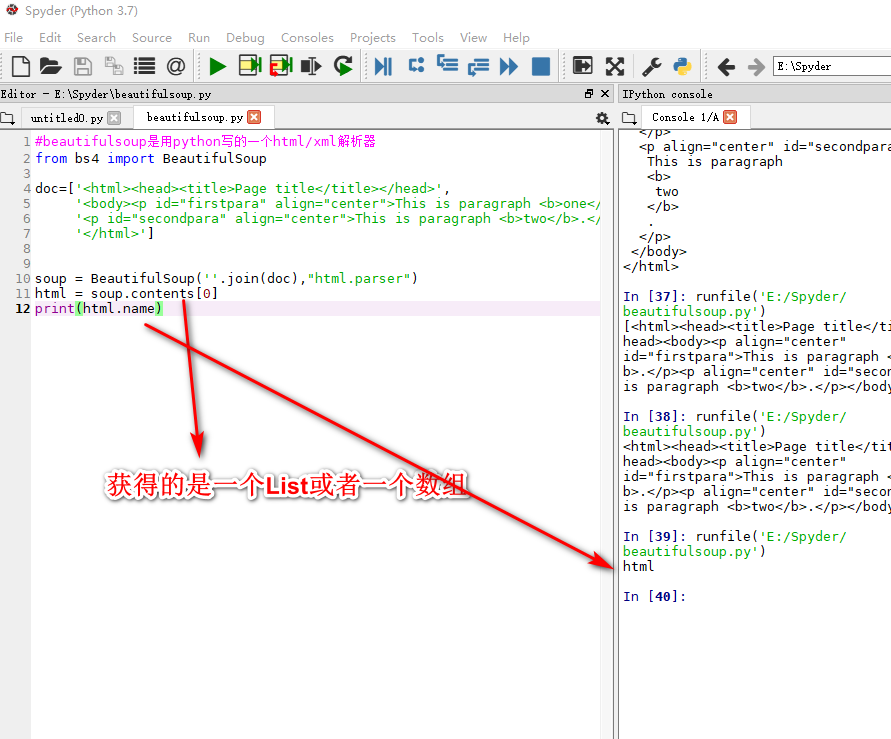
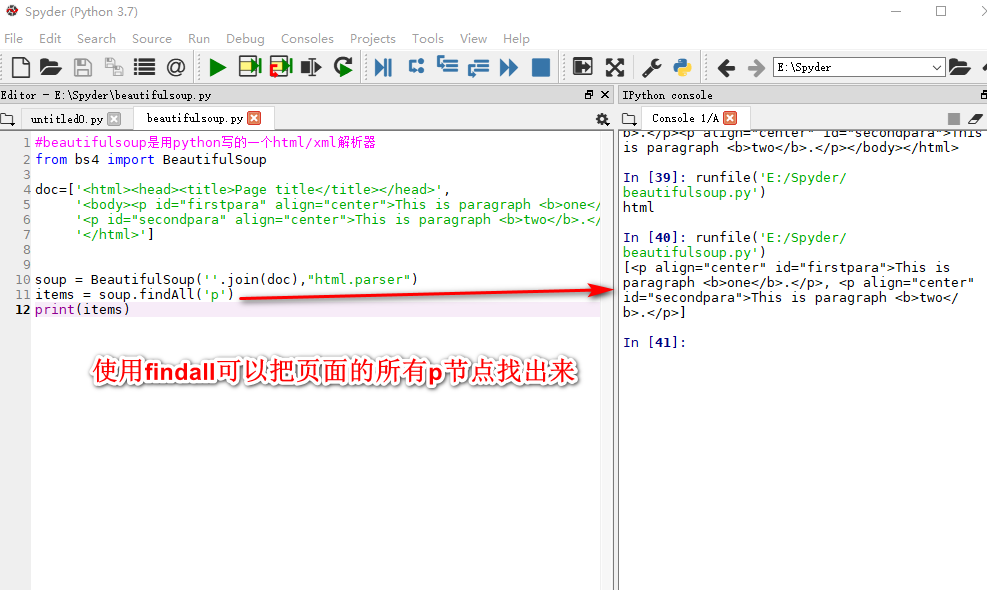
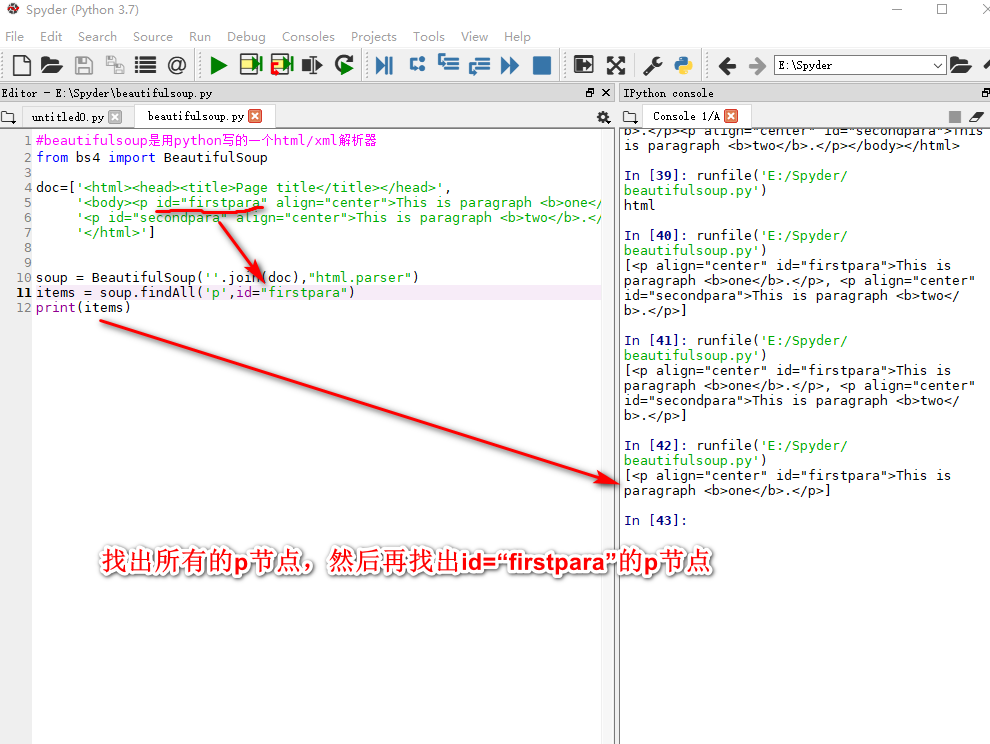
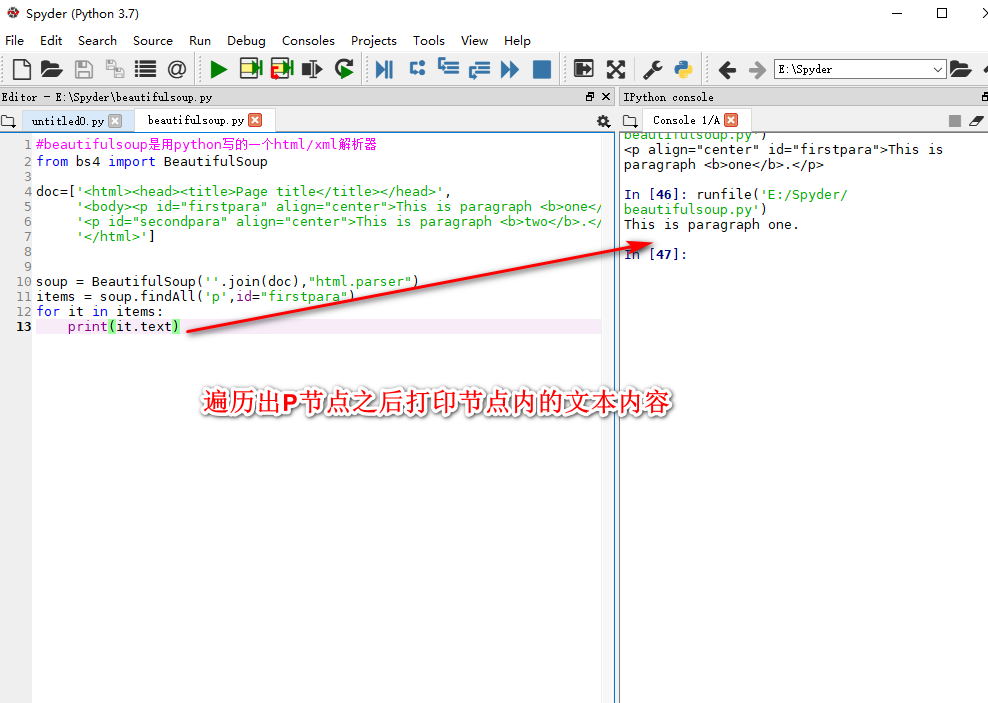
beautifulsoup
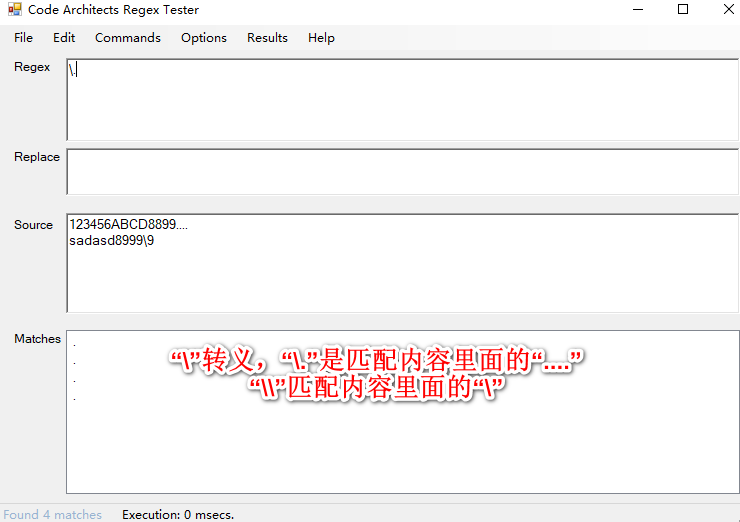
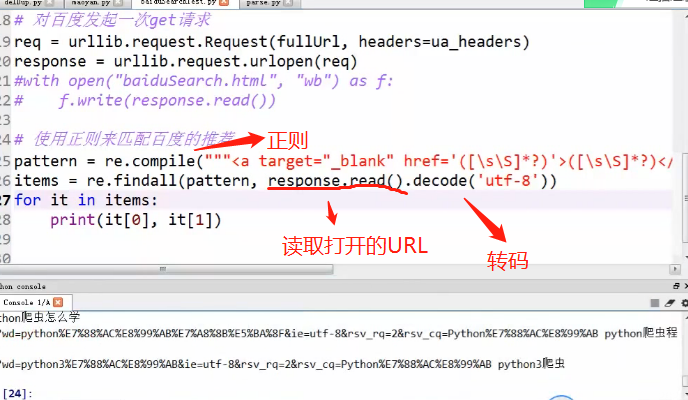
正则表达式(元字符)



list中去重元素的两种方法、

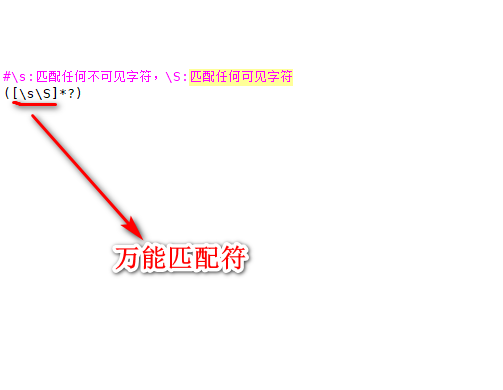
\s\S万能匹配符
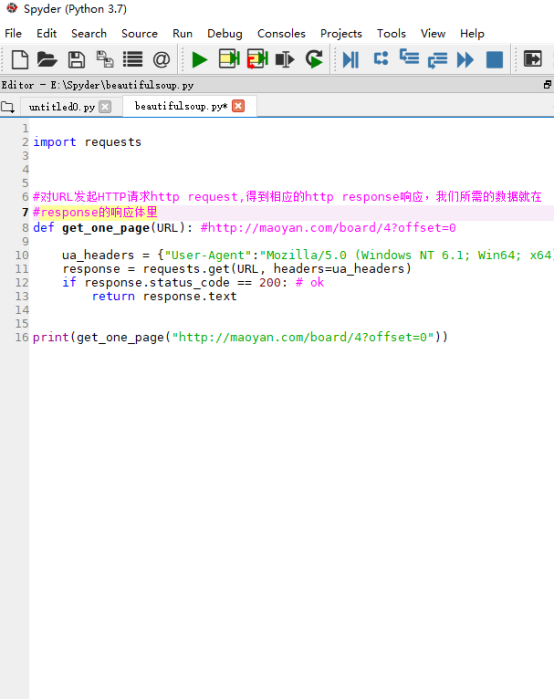
猫眼抓取


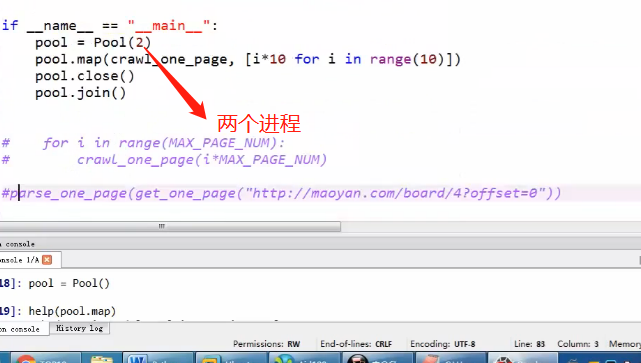
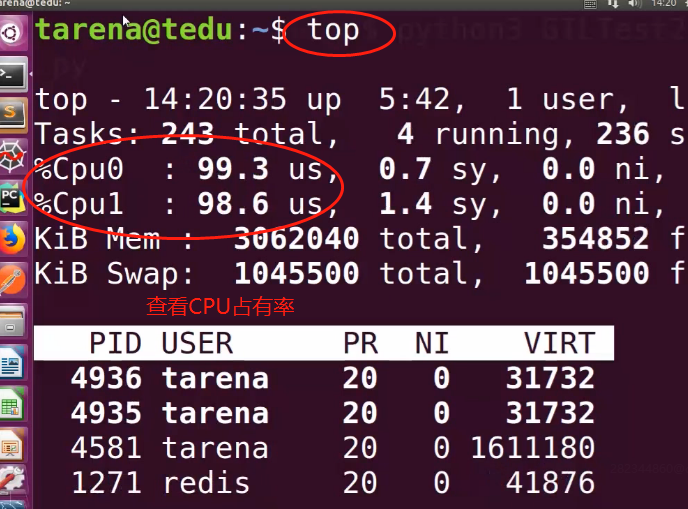
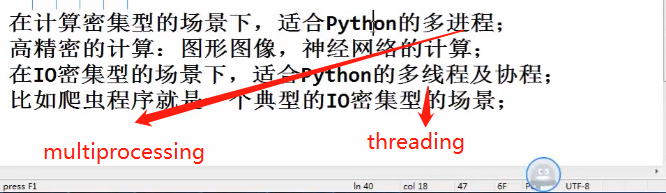
GIL


动态爬虫
有道词典爬虫

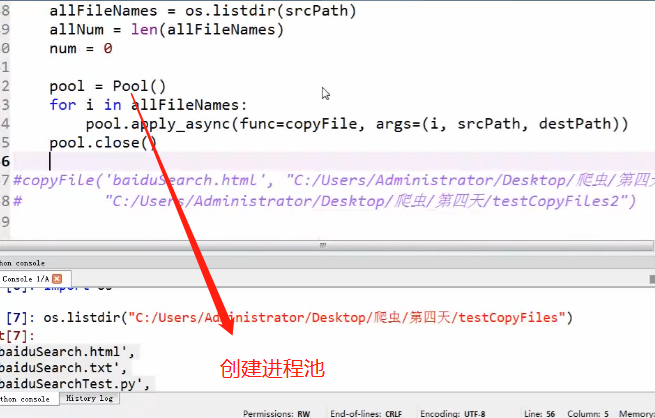
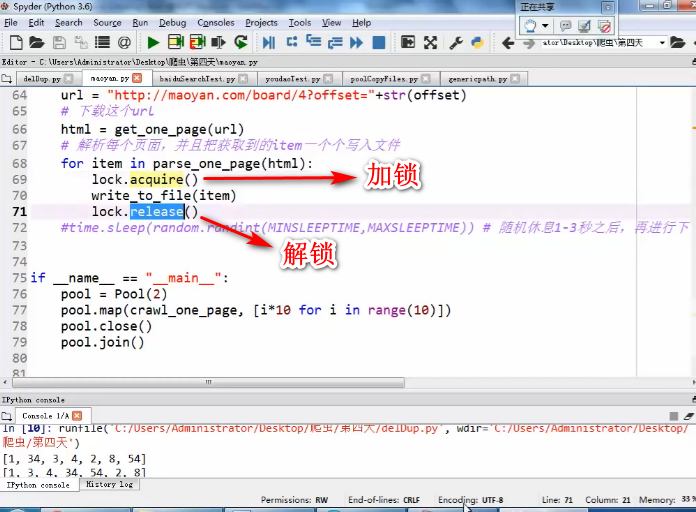
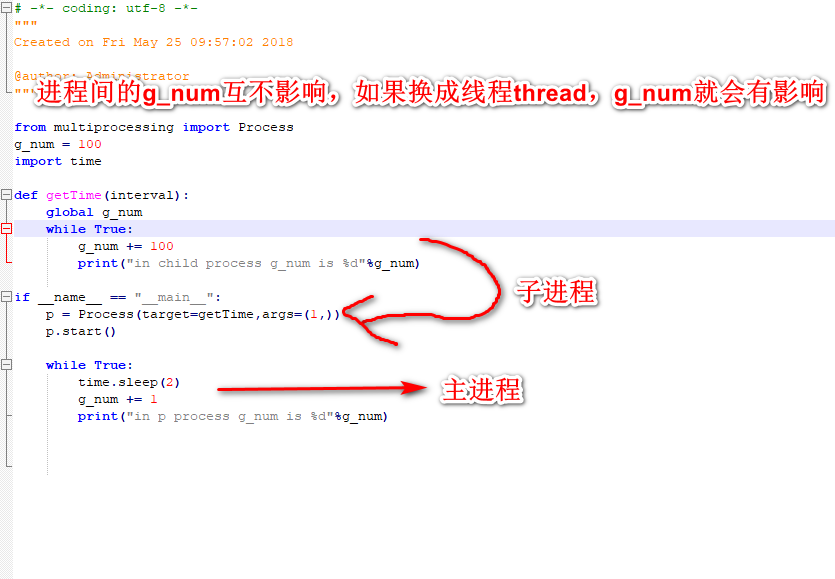
进程,线程(拷贝1000个各种类型的文件)

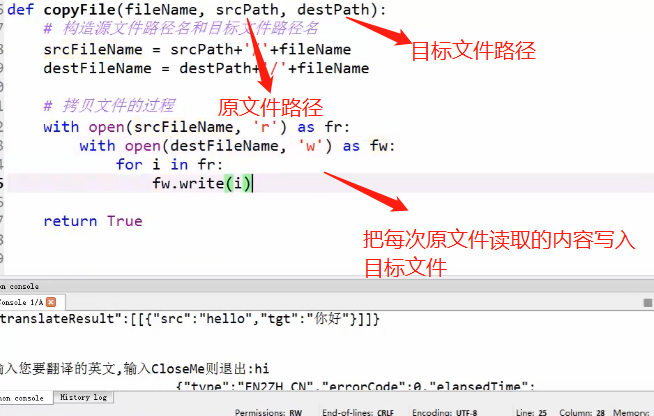
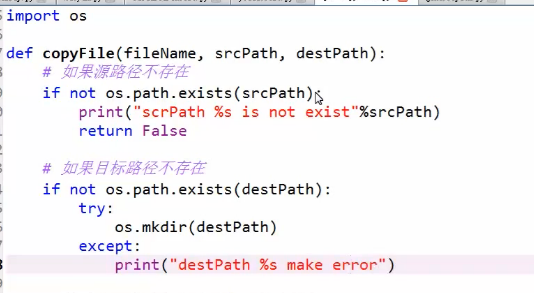


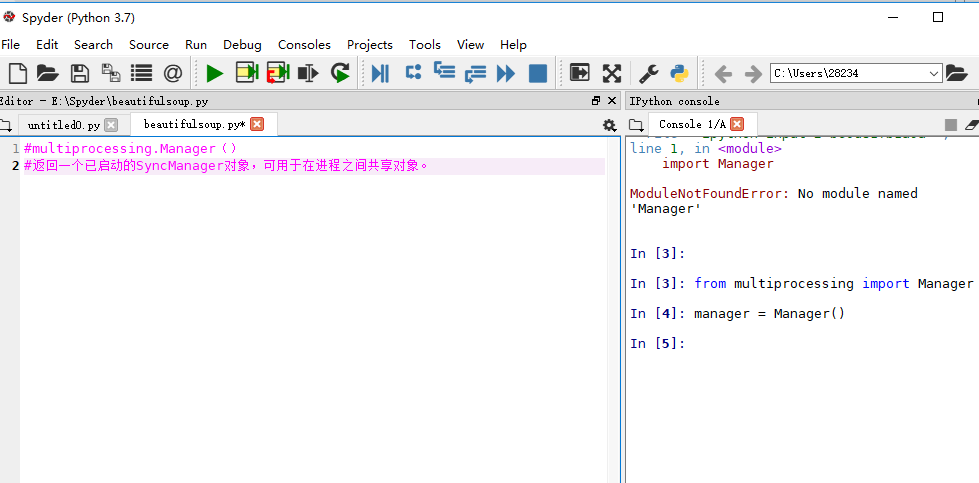
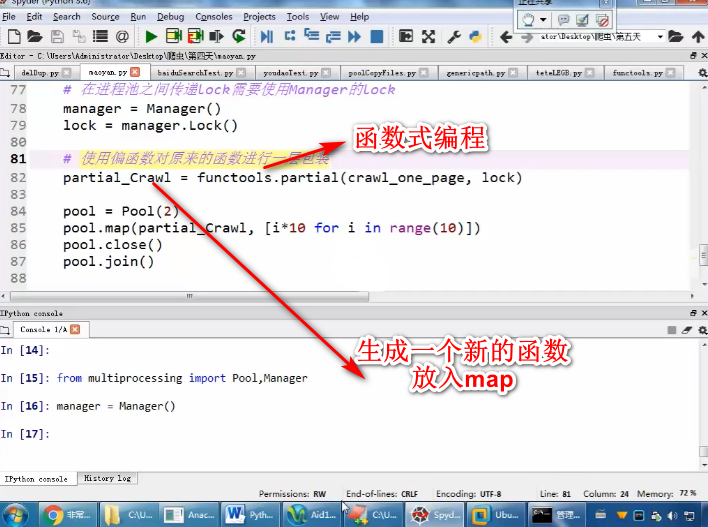
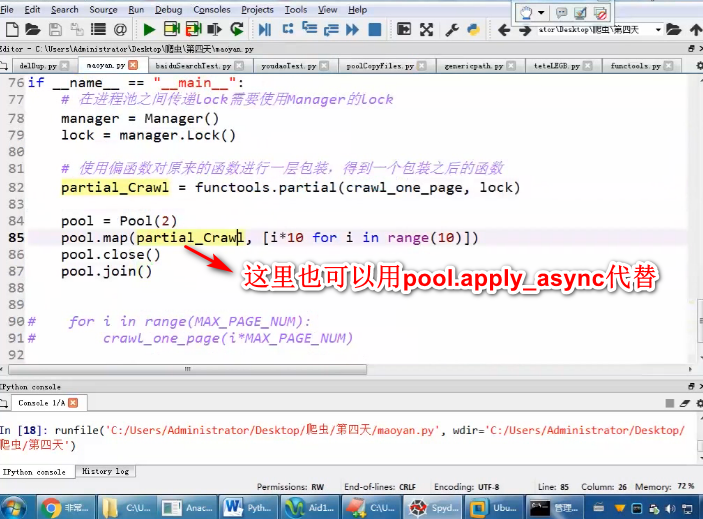
进程Manager
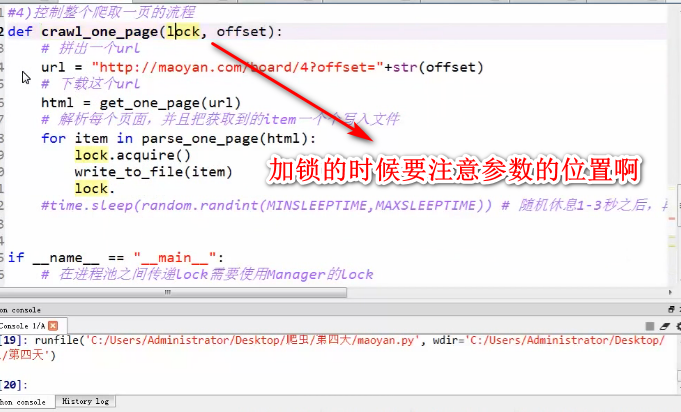
Lock的应用和传递
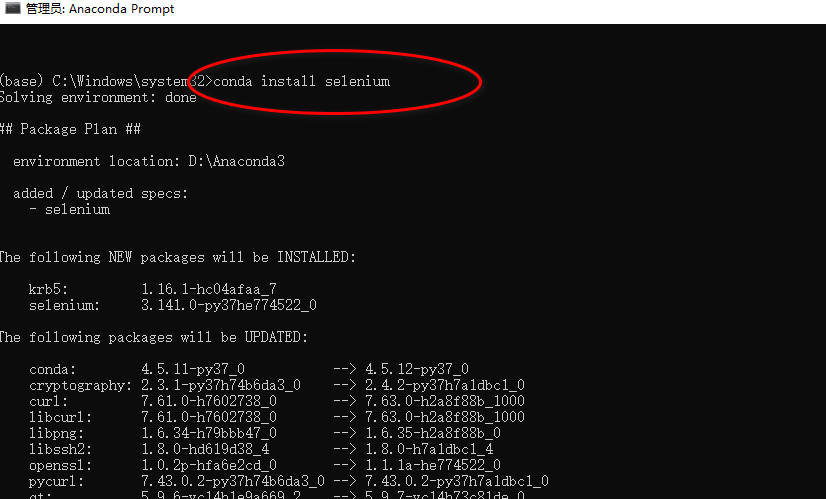
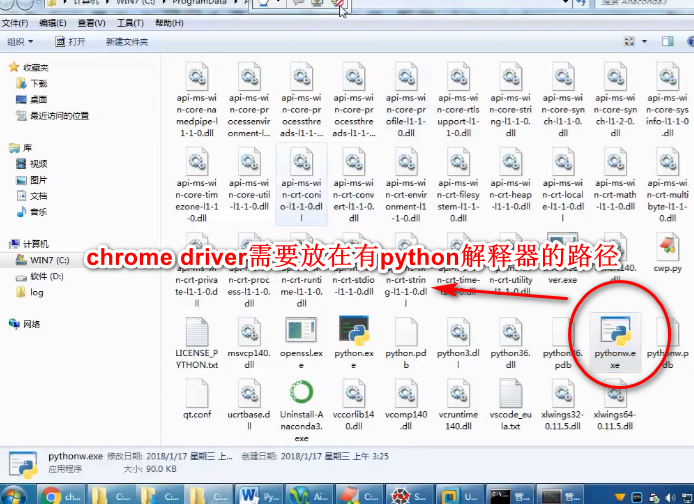
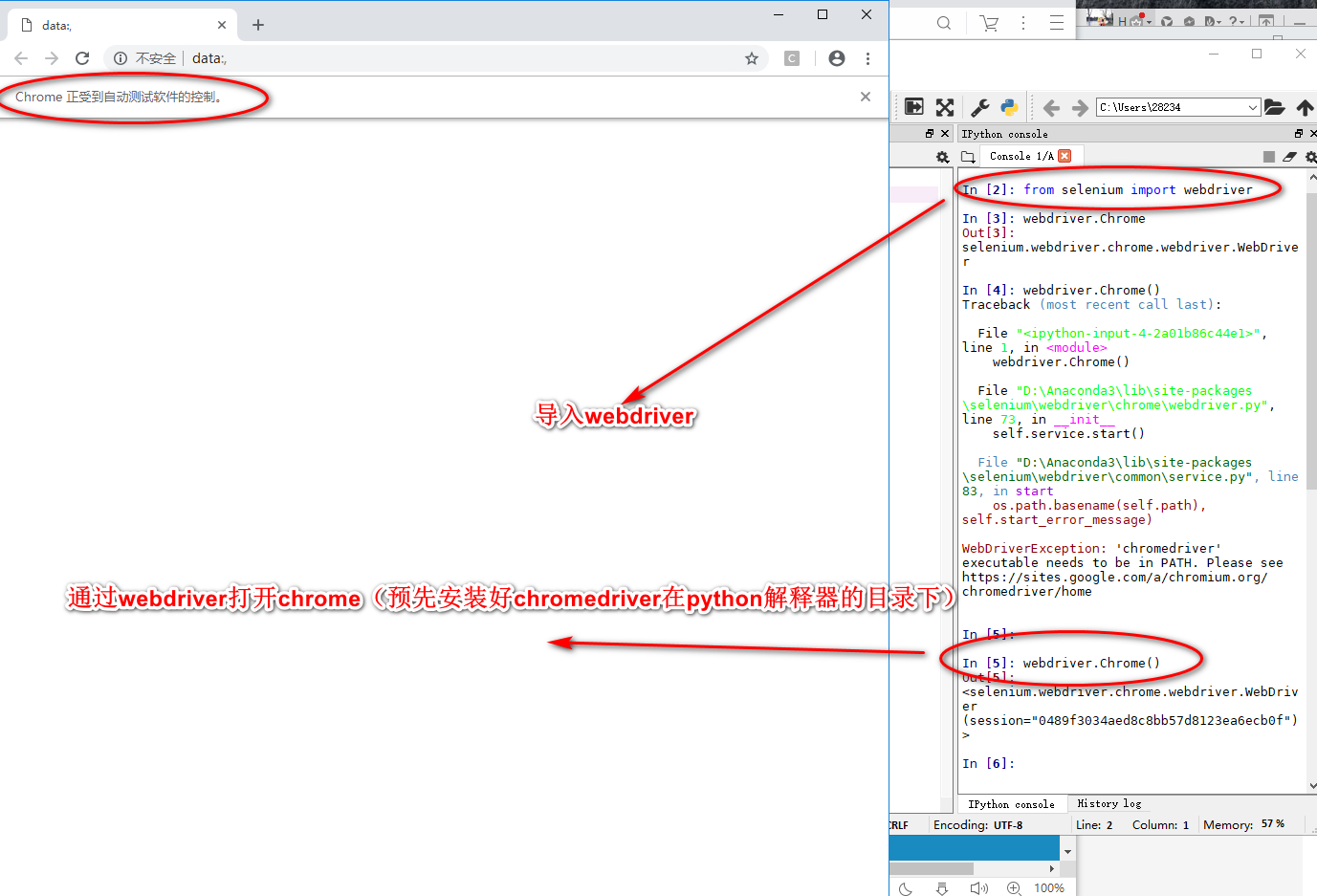
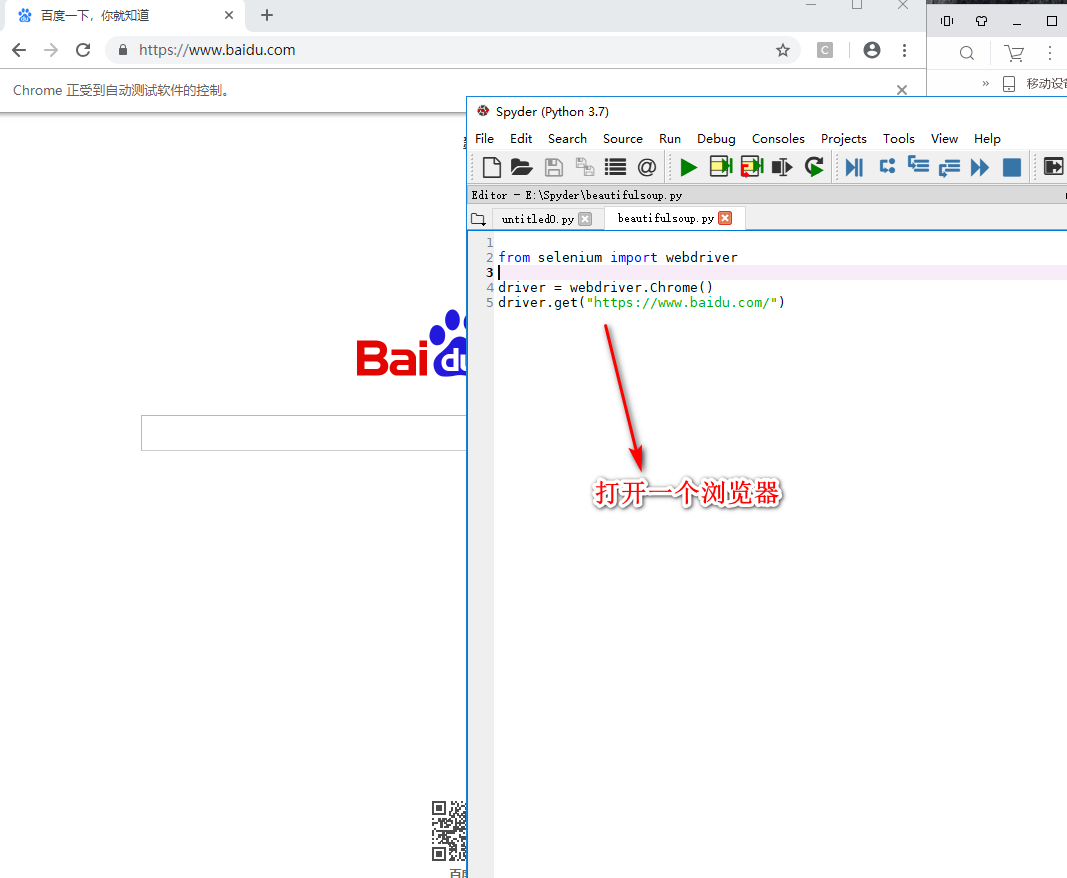
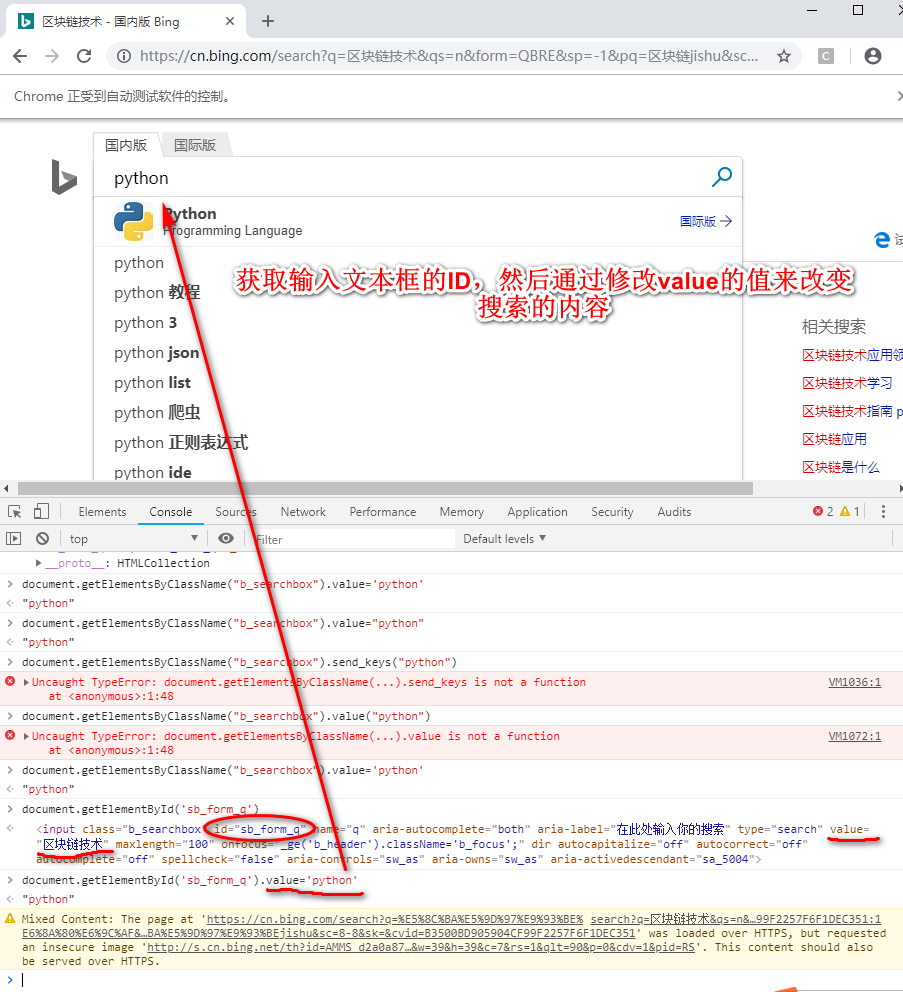
Selenium(自动化测试工具)
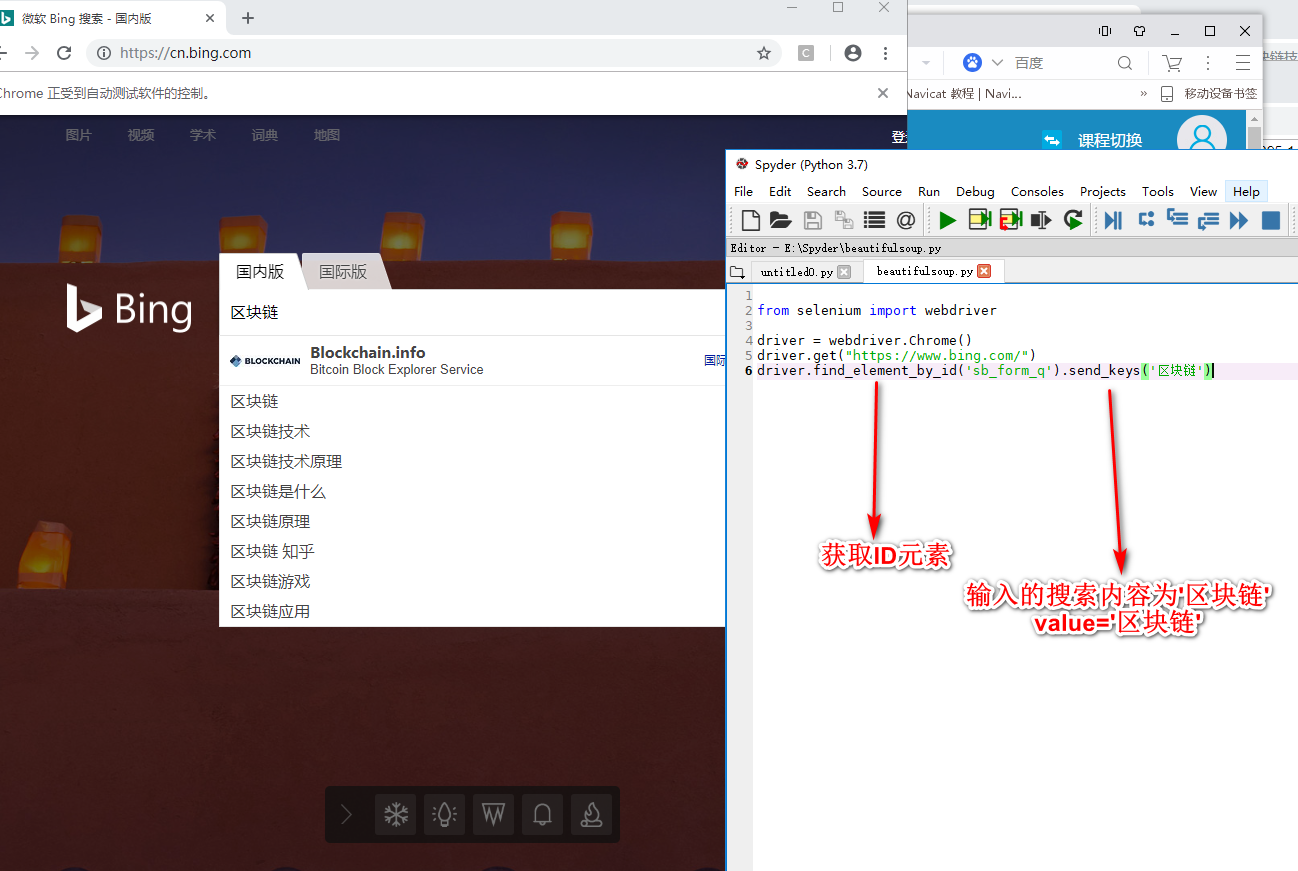
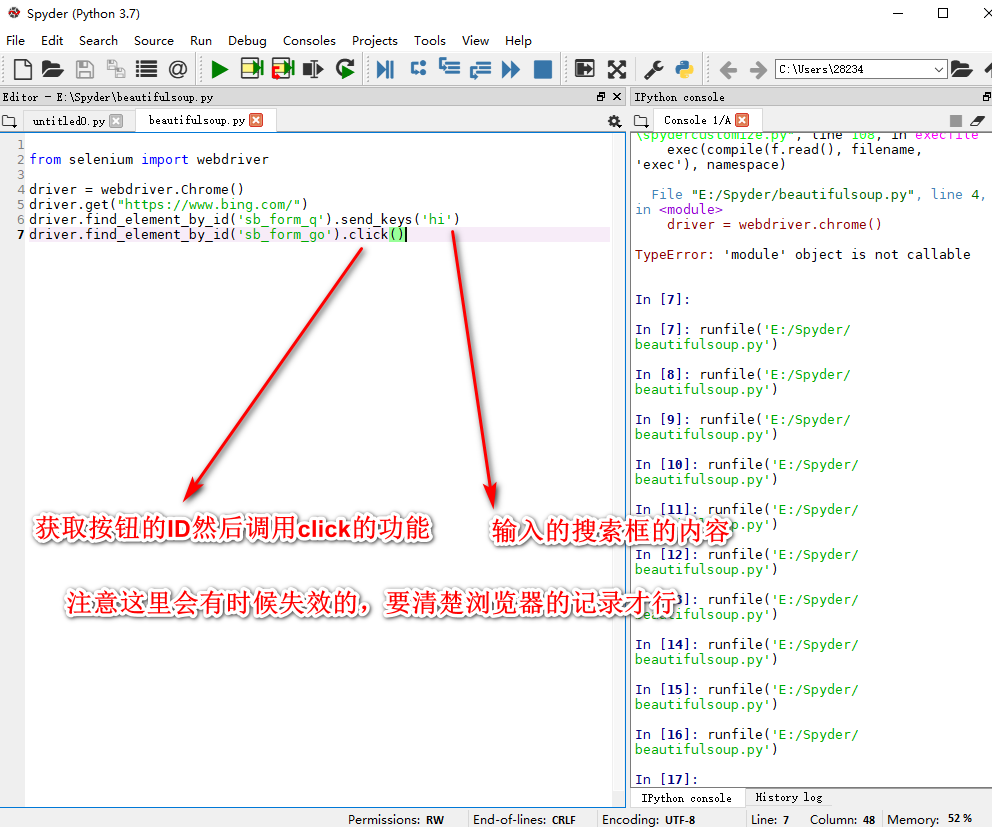
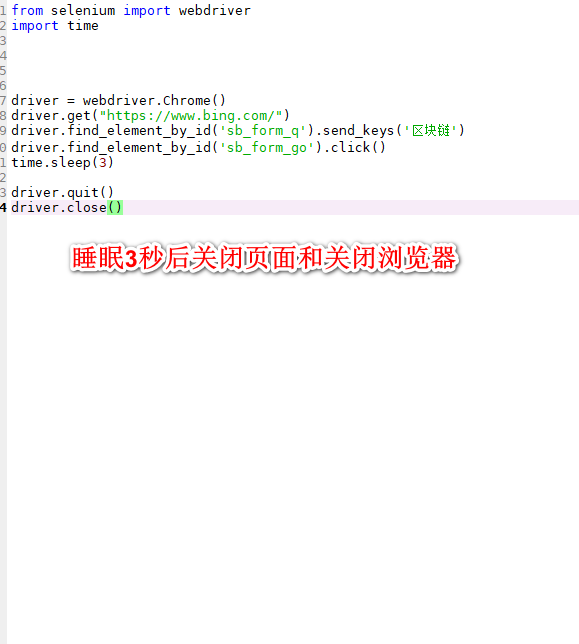

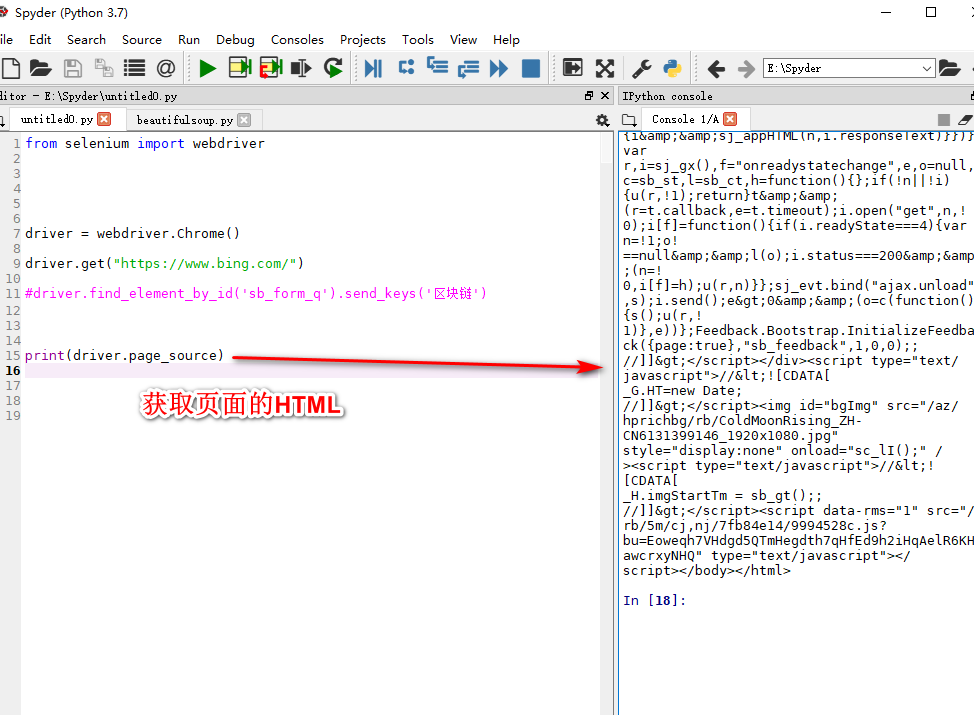

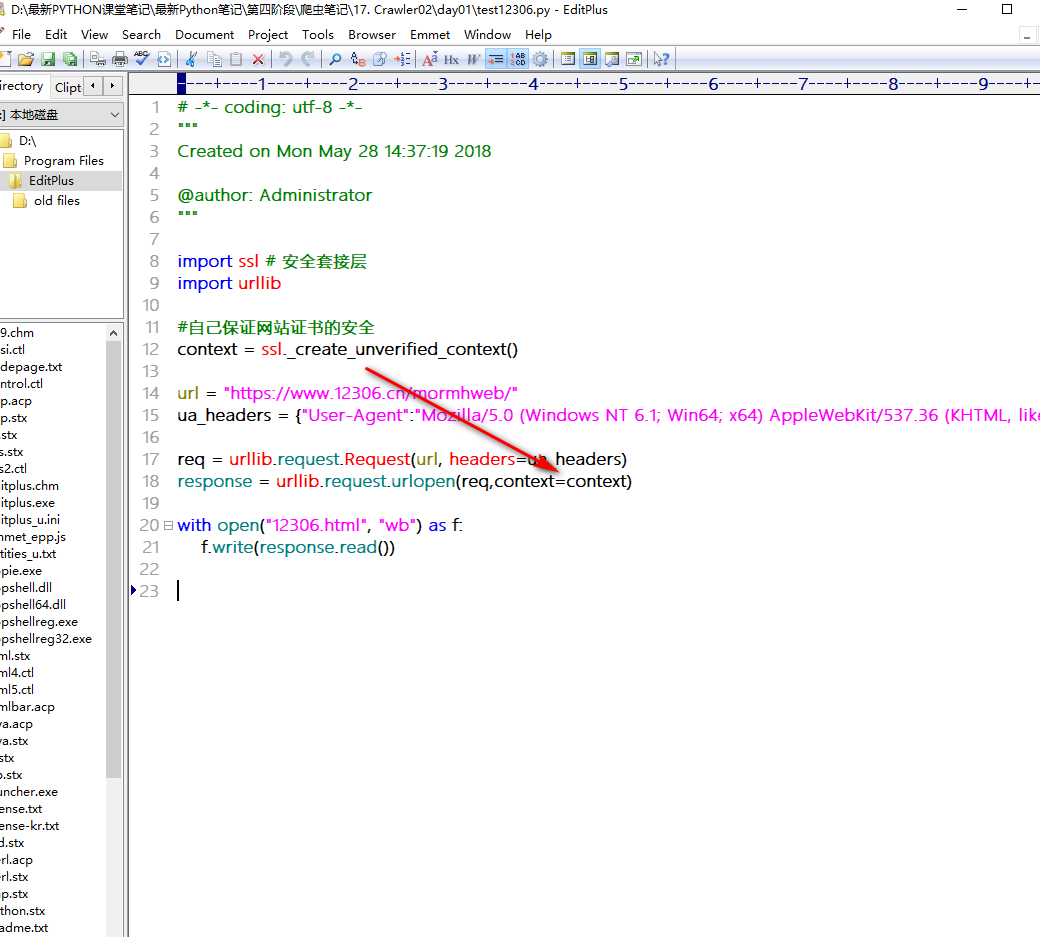
SSL安全套阶层(https=http+ssL)

僵尸进程和孤儿进程

使用cookie模拟登陆
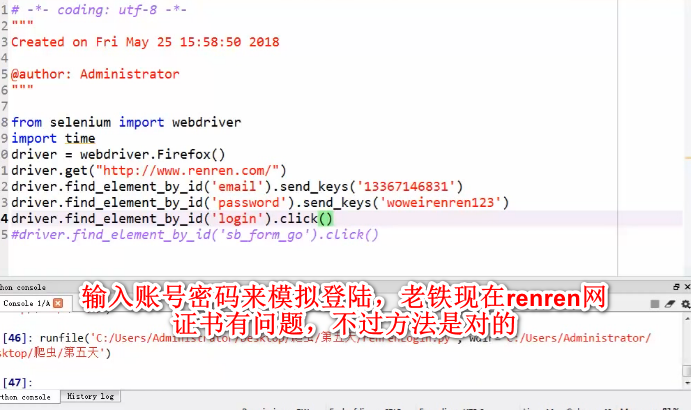
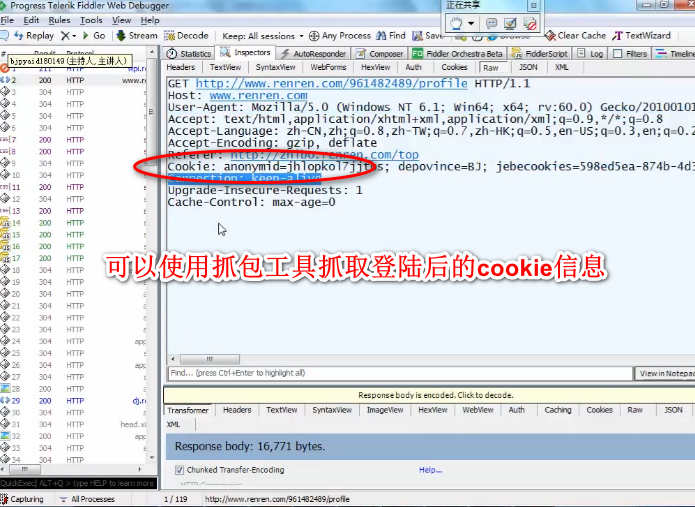
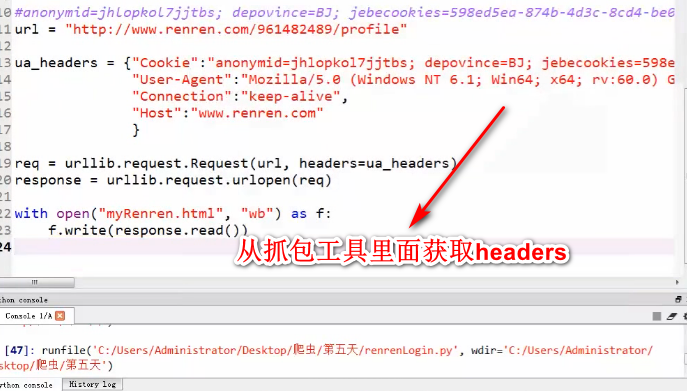
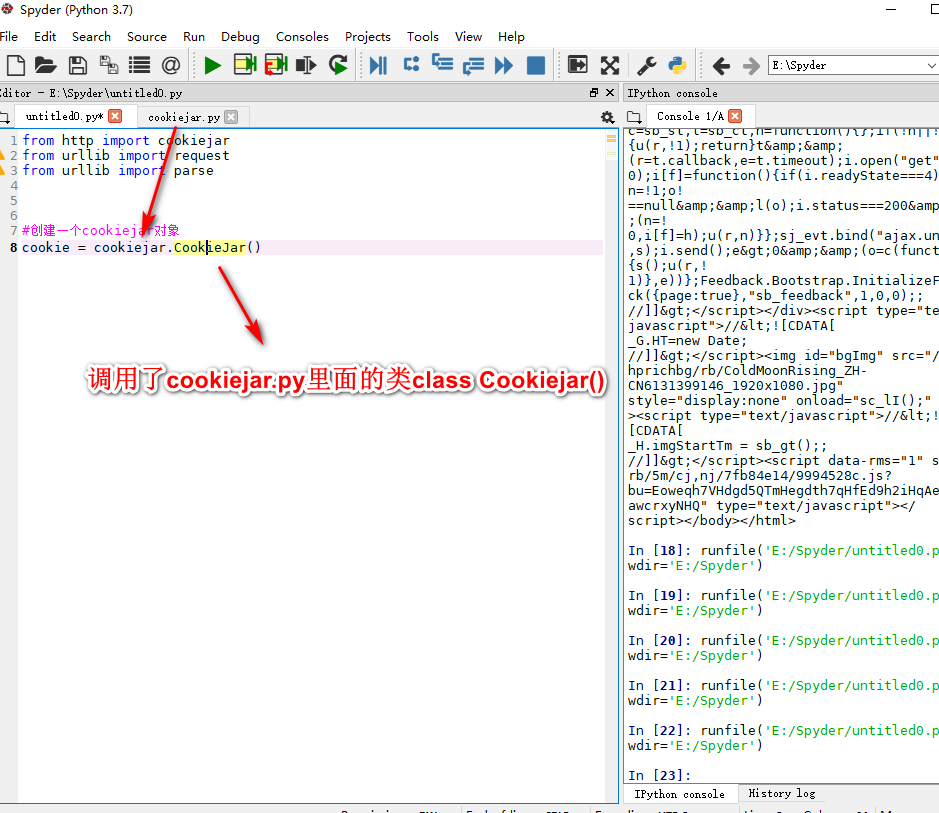
cookiejar和验证码)




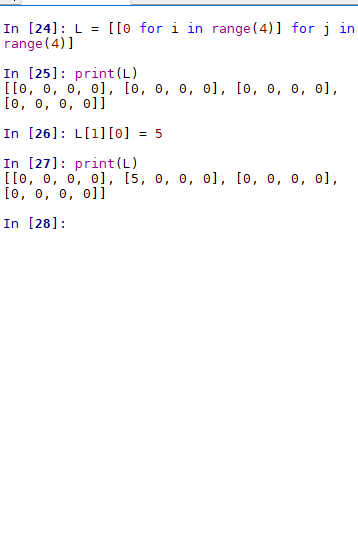
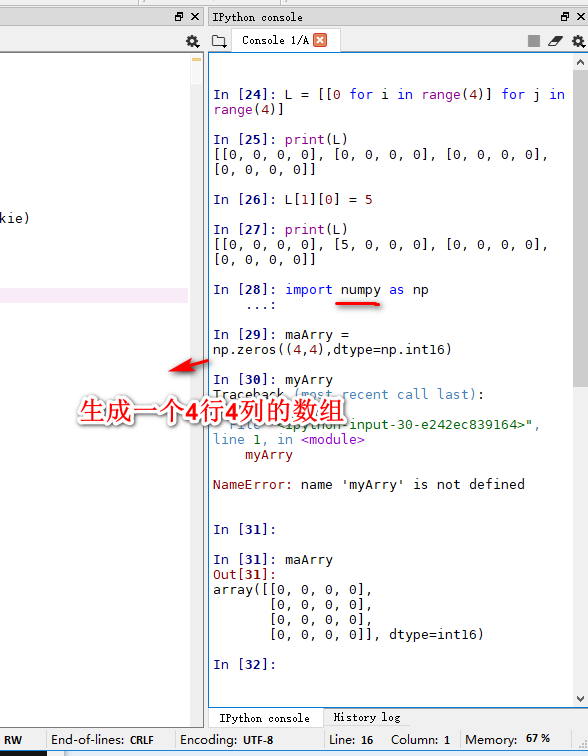
二维列表

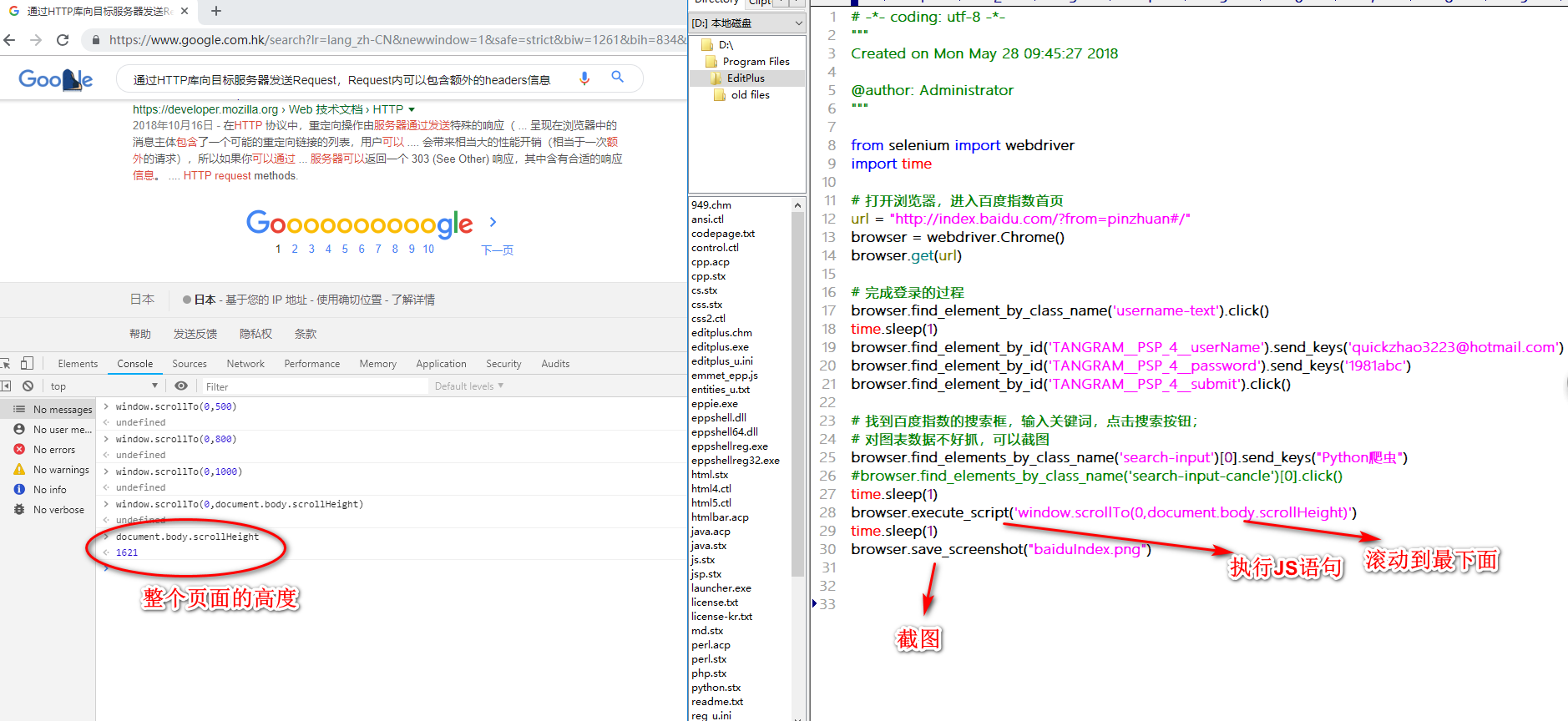
百度指数案例
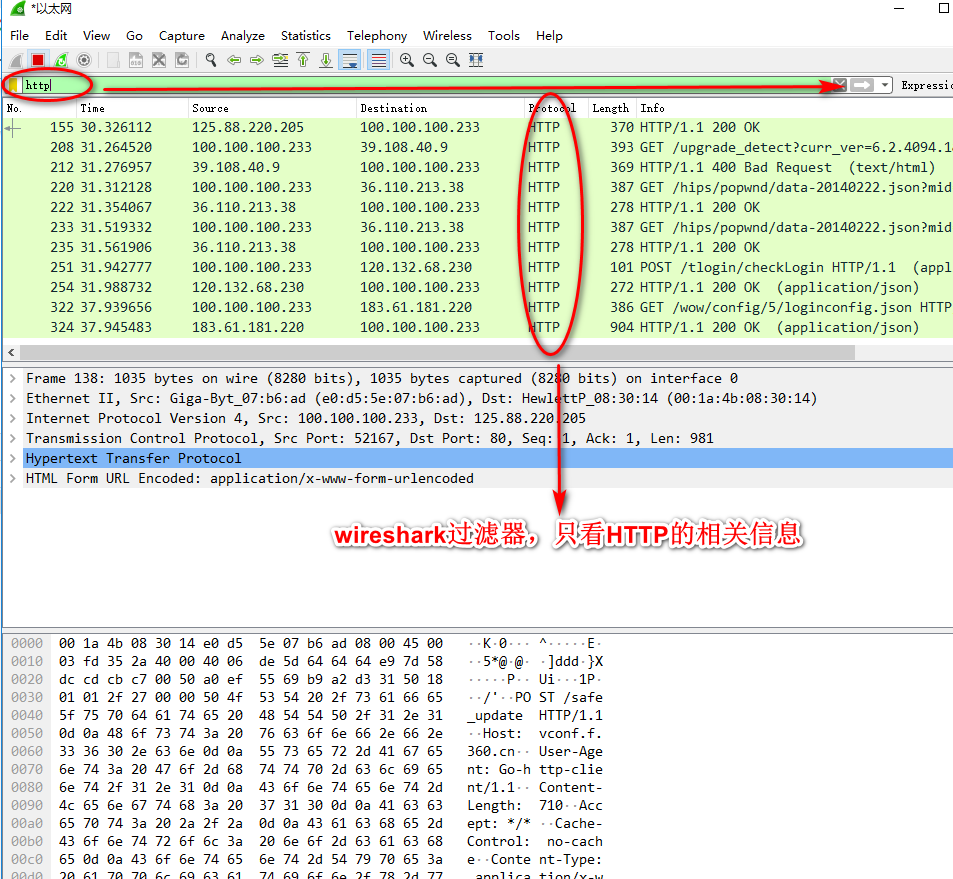
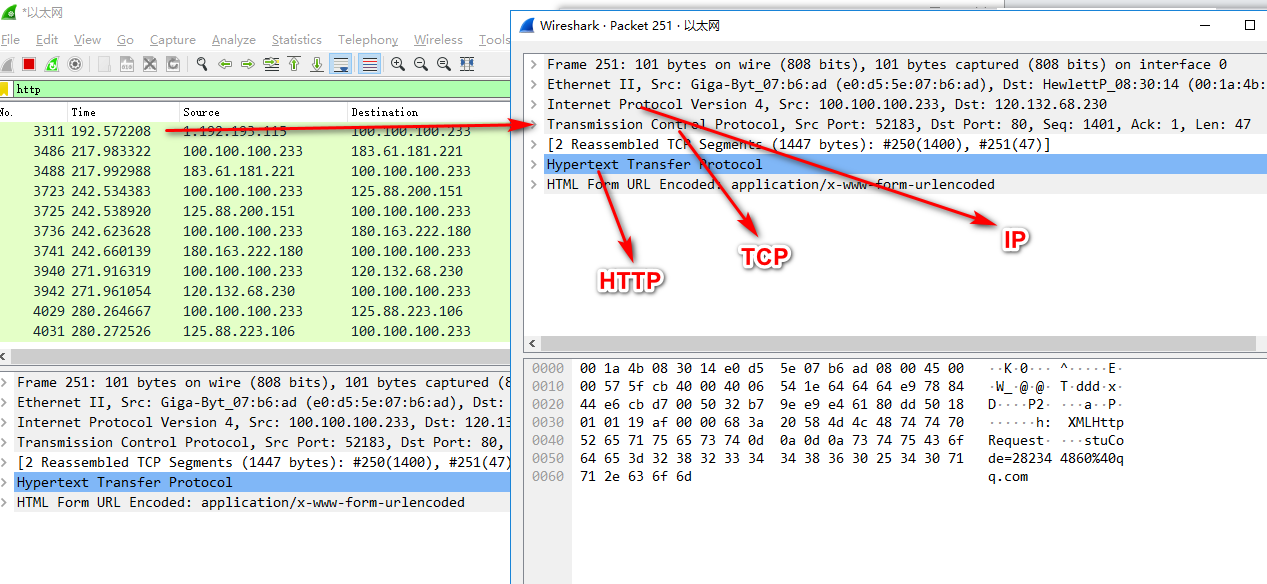
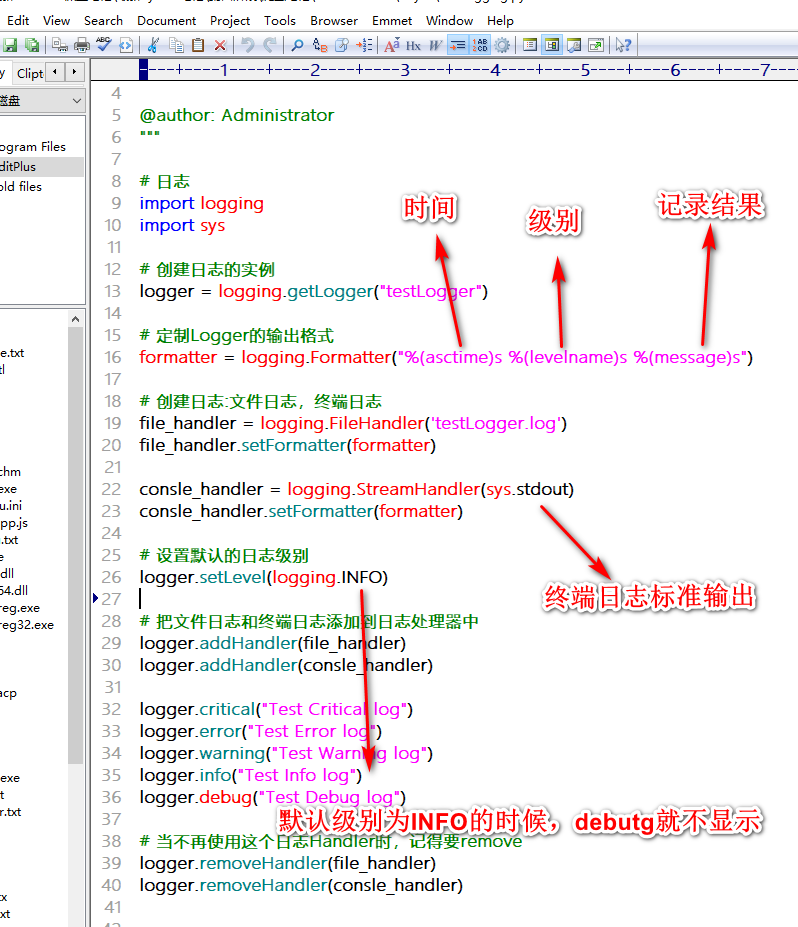
日志
关于SSL网站证书的认真问题
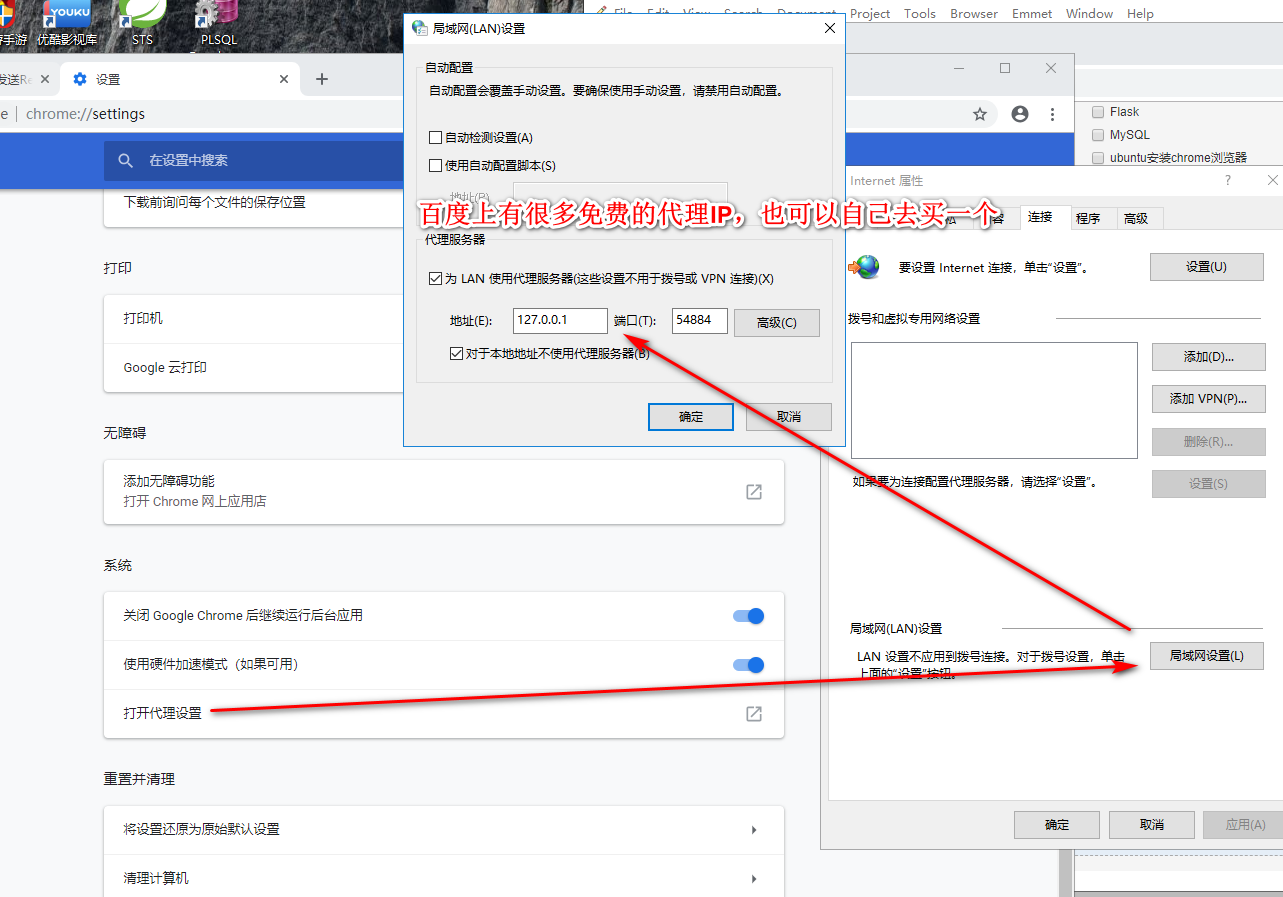
代理服务器


豆瓣案例
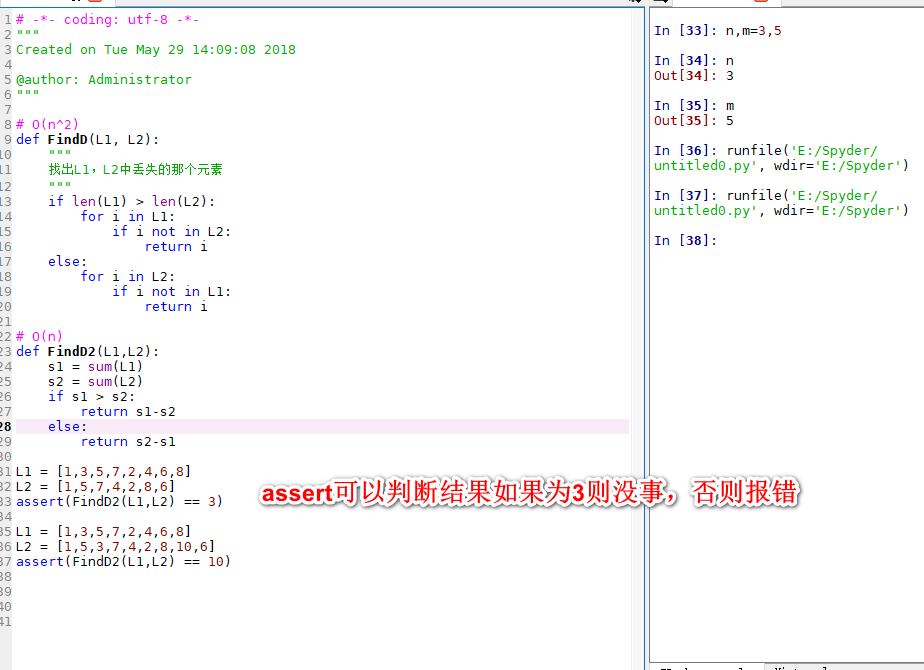
判断两个LIST中丢失的元素
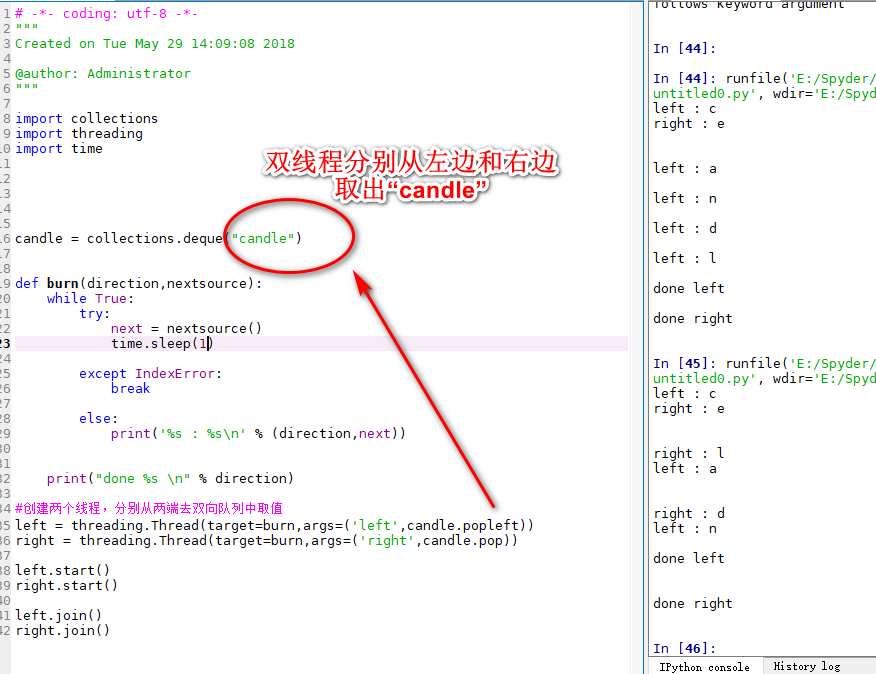
双向队列和进程池
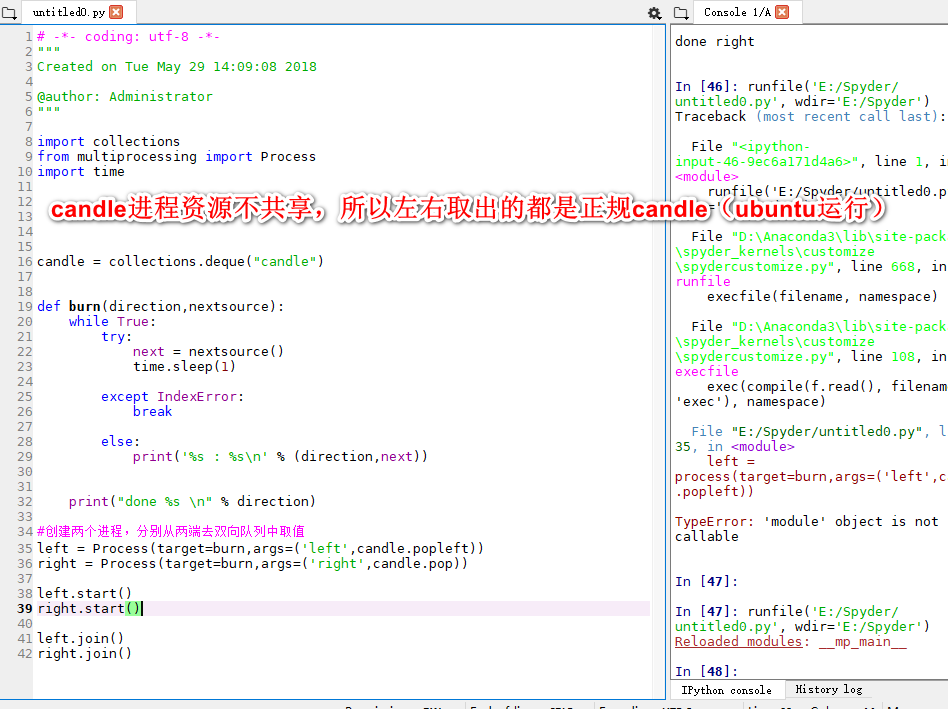
反反爬

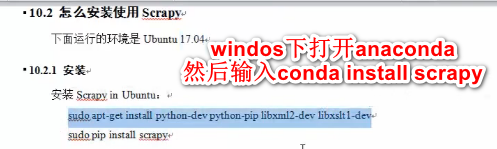
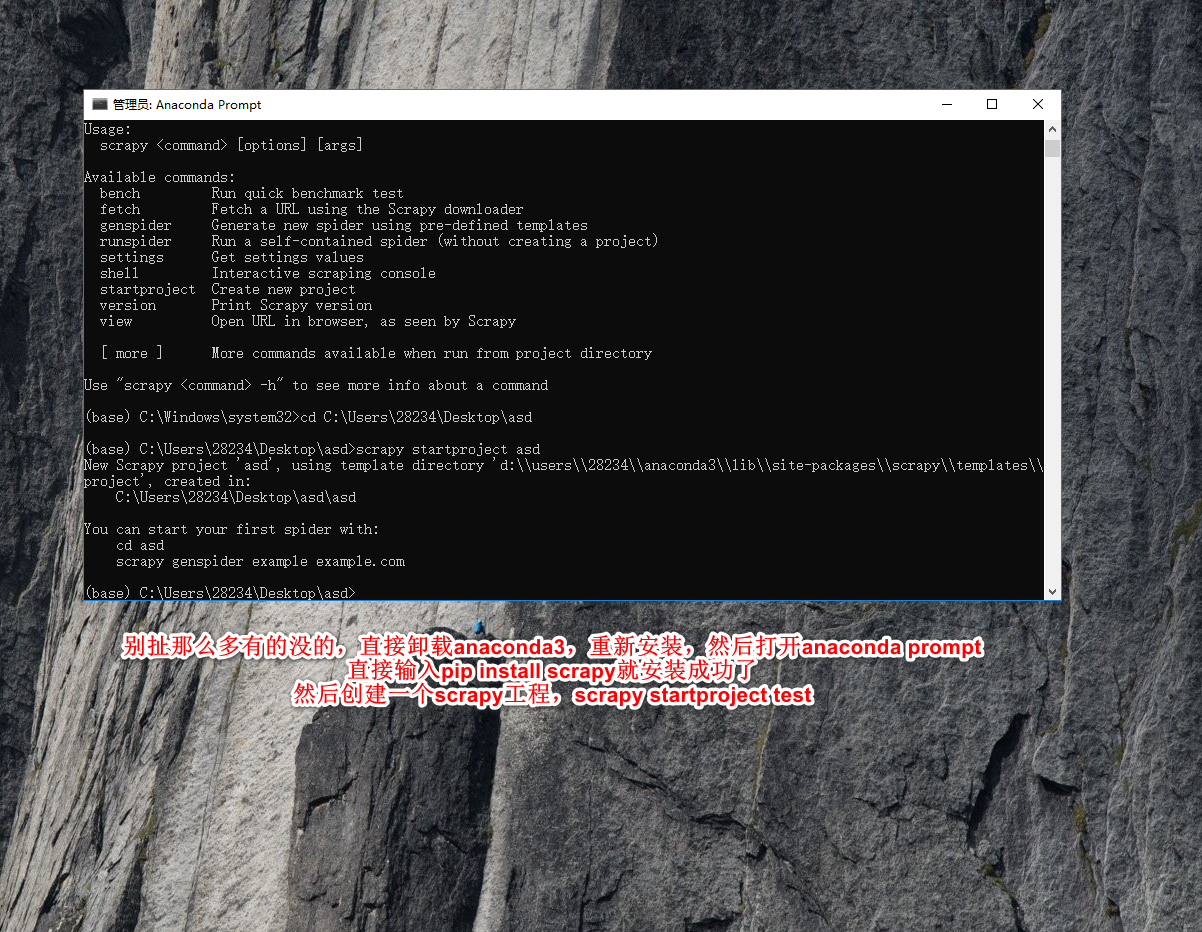
scrapy安装
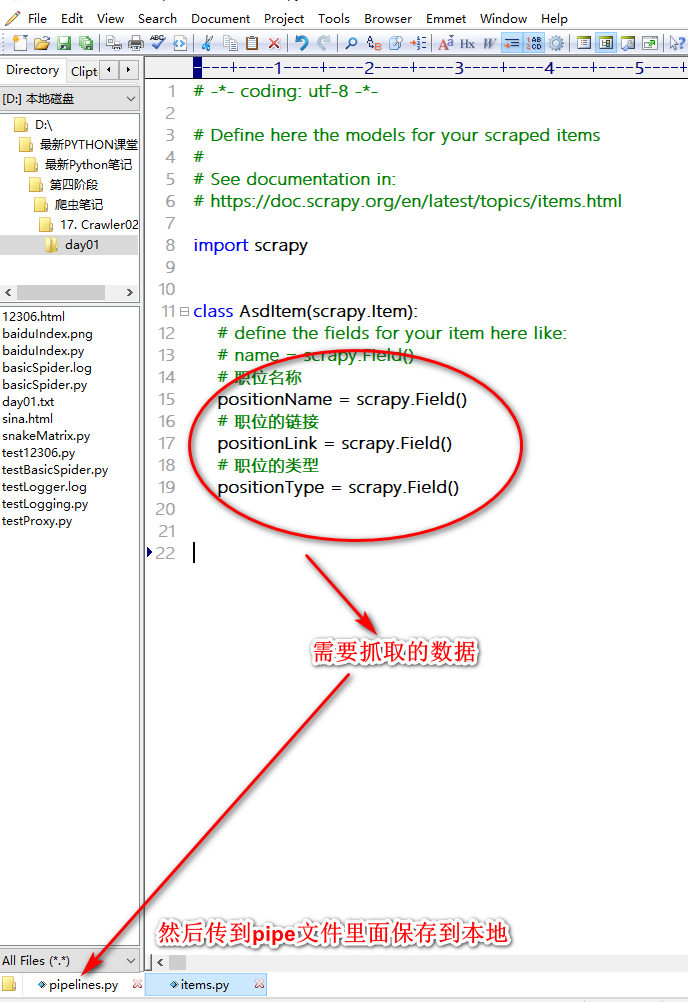
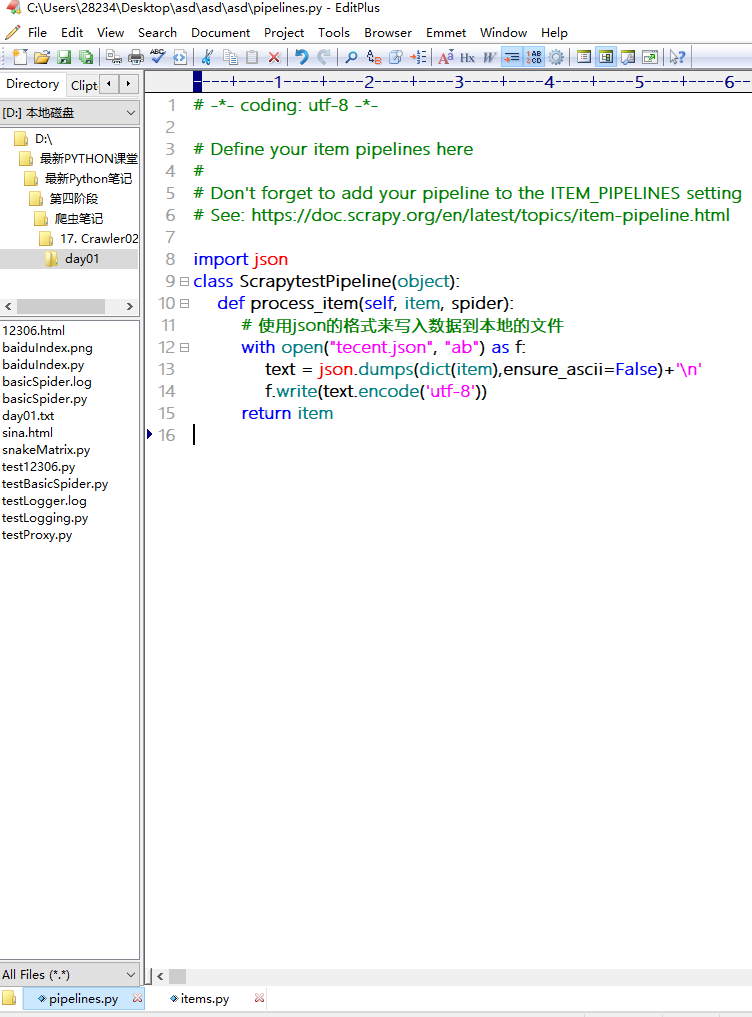
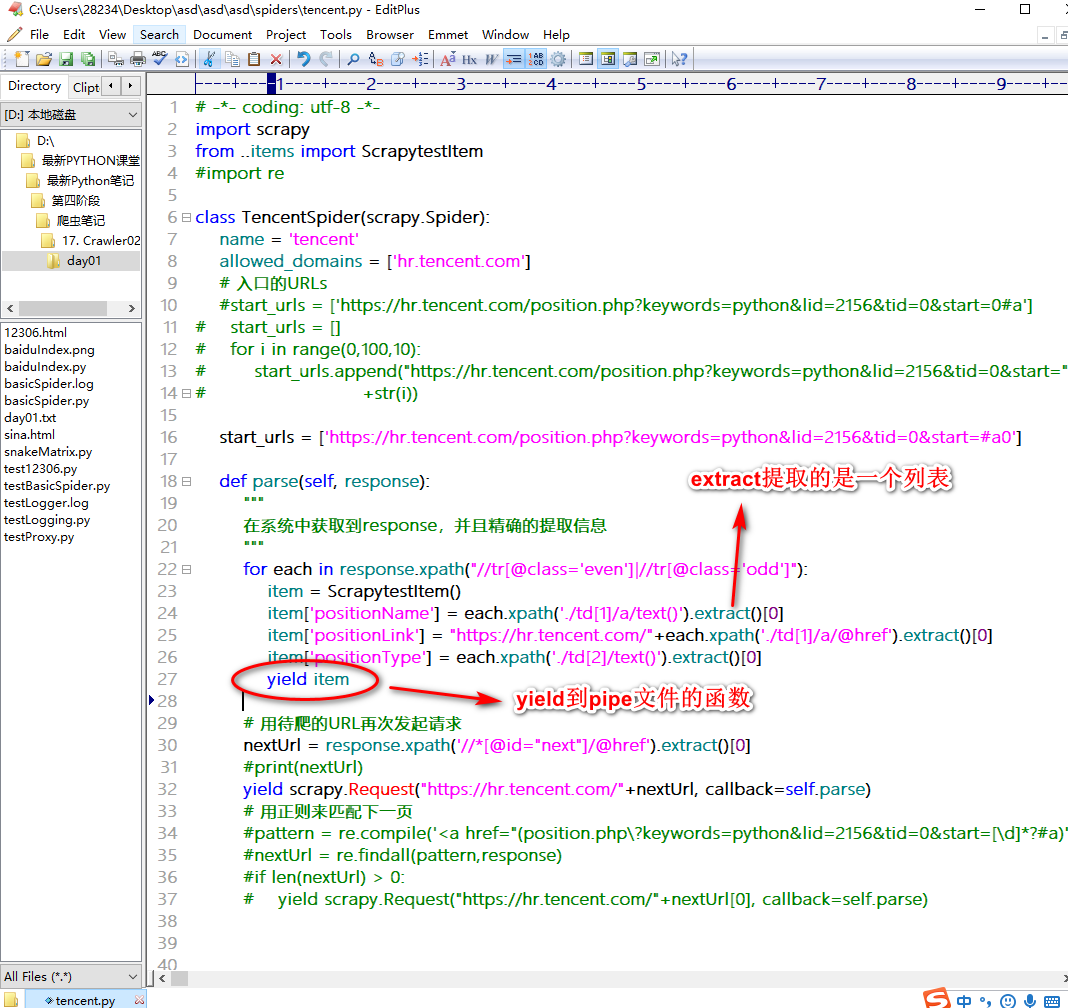
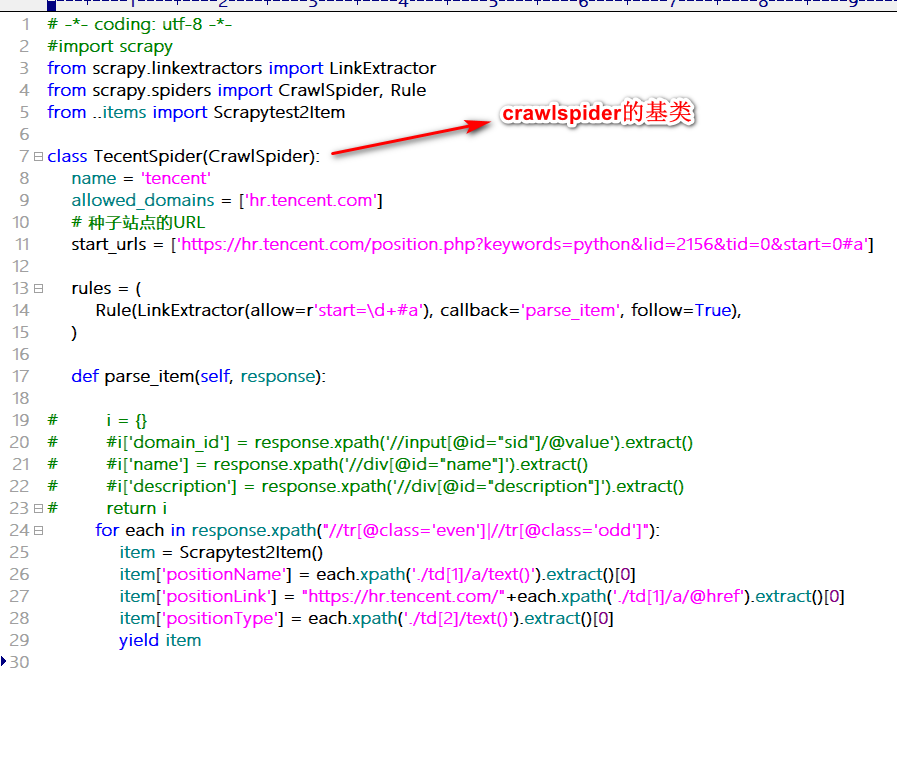
scrapy工程
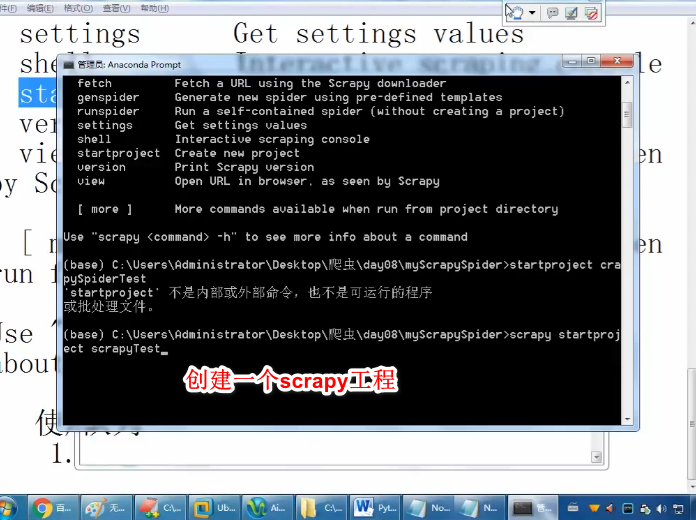
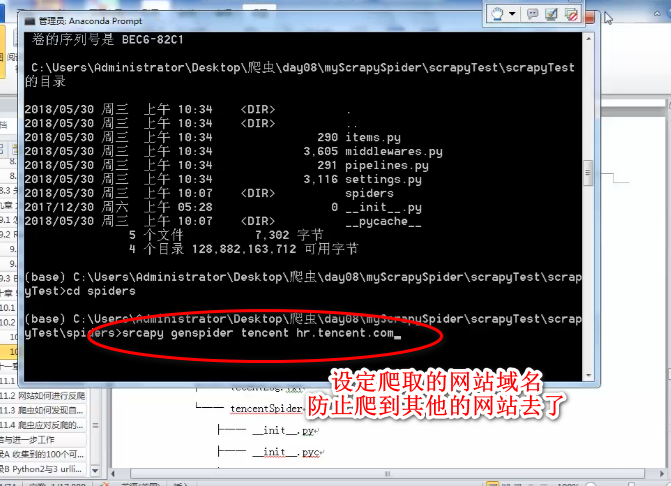
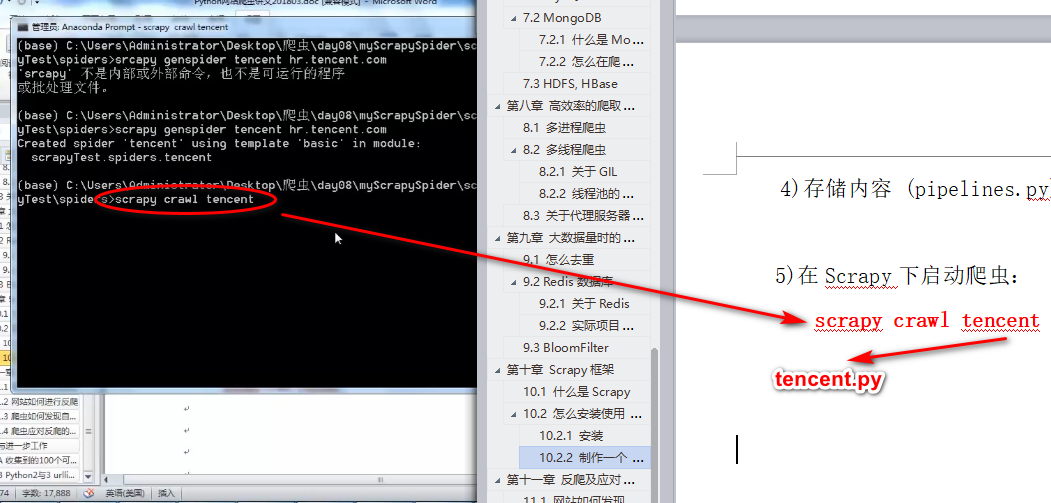
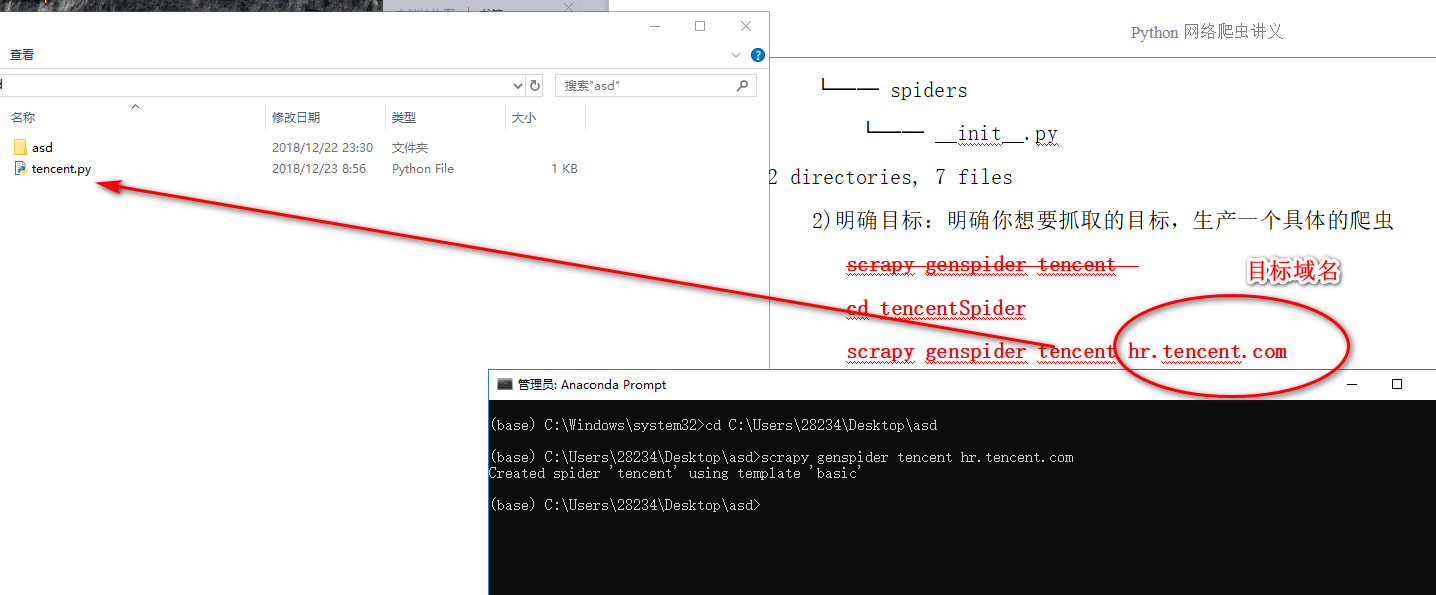
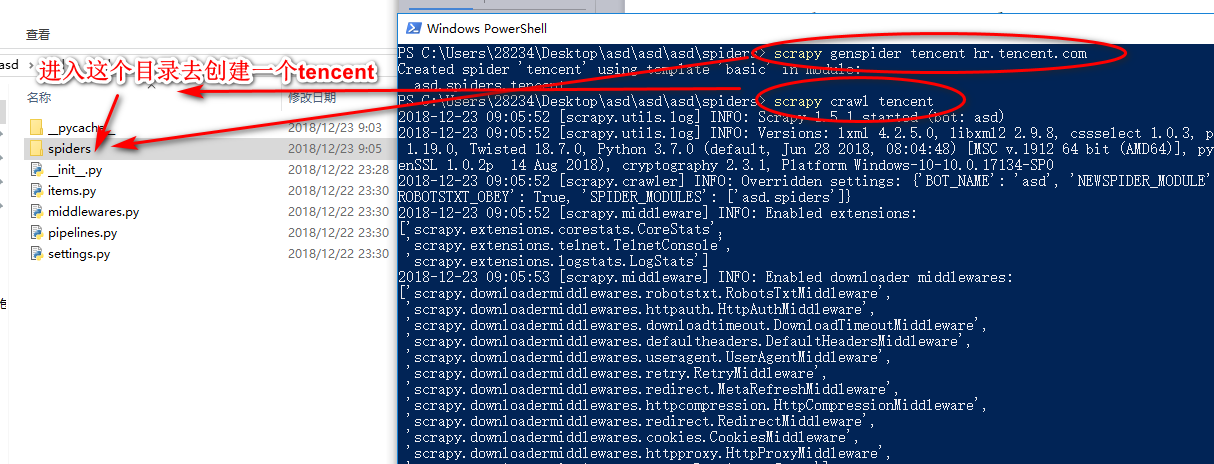
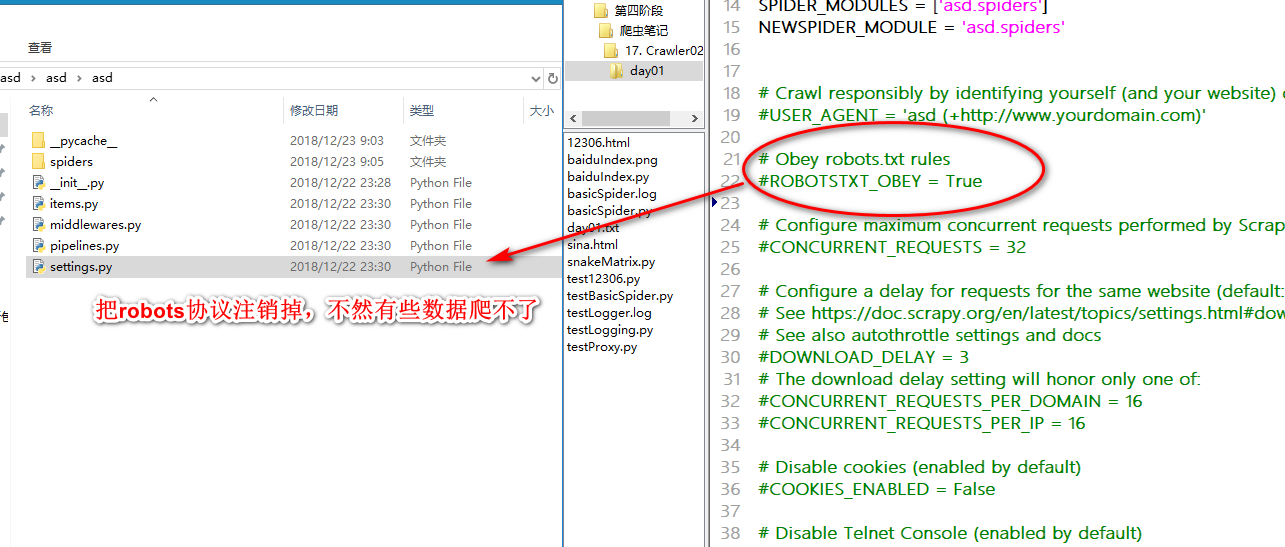

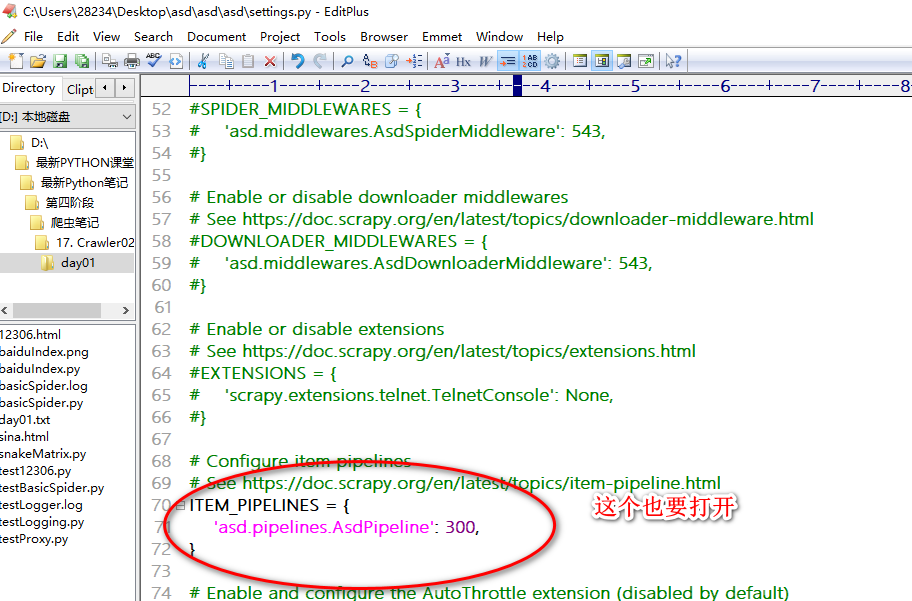


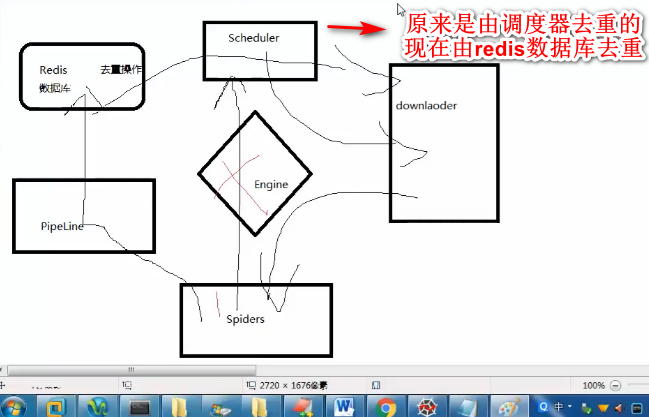
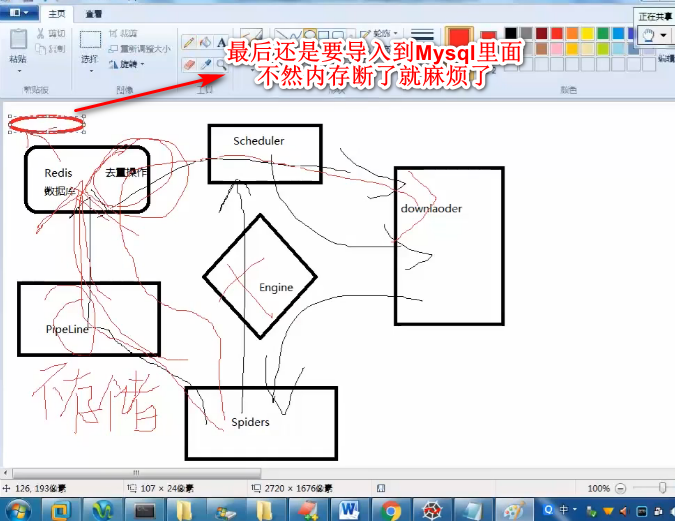
redis数据库的简单原理


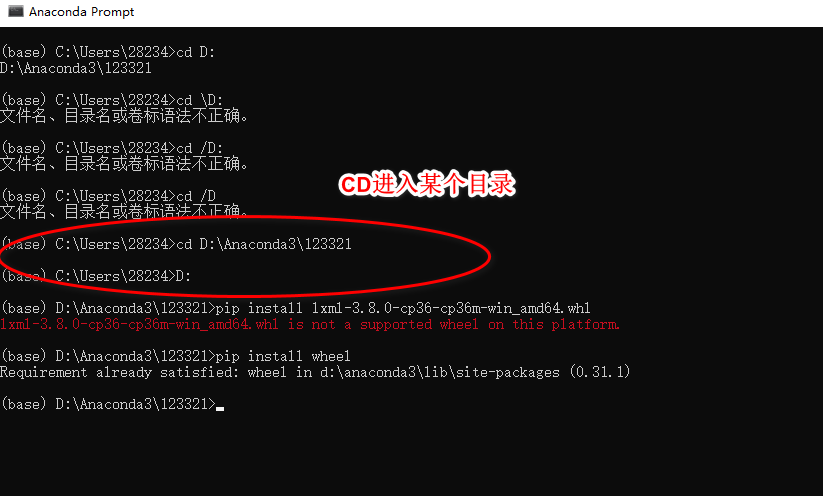
关于安装scrapy失败
把爬取的数据保存到MySQL

 浙公网安备 33010602011771号
浙公网安备 33010602011771号