关于爬取网站的信息遇到的有关问题
问题一:在scrapy框架中,使用的xpath去获取网站信息,没能拿到?
解决方法:xpath在scrapy框架中使用需要注意两件事:第一是使用的user-agent和你去获取的xpath,使用的浏览器需要相匹配;第二就是需要注意使用谷歌浏览器的时候一定要删去tbody标签,这样就基本可以成功爬取到东西了,(第一个事情是网上的其他人讲的,但是我不是很清楚,就当需要注意的事情吧;第二个是我自己曾经经历的过的,可以这样尝试,但是还是请大家详细情况具体分析;推荐本文的问题四,其中的方法应该可以说是比较好的=-=)以下就是我的一些配置:
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}
使用的是谷歌浏览器去复制xpath。
问题二:在scrapy框架中如何使用for循环爬取的数据保存到item中?
解决方法:以下提供两种:
items = response.xpath("/html/body/div[2]/div")
for i in items:
m = item.xpath('.//div[1]/text()').extract_first()
item = Item()
item['code'] = m
yield item
m = response.xpath("/html/body/div[3]/div/div/div[4]/table/tbody/tr/td[6]/text()").extract()
n = response.xpath("/html/body/div[3]/div/div/div[4]/table/tbody/tr/td[6]/text()").extract()
for i in range(0, len(code)):
#设置if语句去除不必要的标题类数据,如“申报要素”等
if i != 0:
item['code'] = m[i]
item['name'] = n[i]
yield item
else:
print("已经删除第一值")
第二个方法是根据下标来操作数据的,所以下标的数据要保证准确无误,其中对于本来就是空值的数据,text()不能保存为None,默认跳过,需要小心注意。
问题三:当自己需要爬取的数据太过庞大的时候,并且其具有反爬虫机制的时候,我们如何最快速爬取出自己想要的数据。
1、使用scrapy-redis,采取windows+服务器的组合爬取数据
2、使用代理ip,代理ip建议购买豌豆的代理ip服务,价格比较便宜
3、使用crontab来增加定时任务,设置scrapy项目下载网页的速度为人为的速度,大致为5s到15s之间(请自己把握)
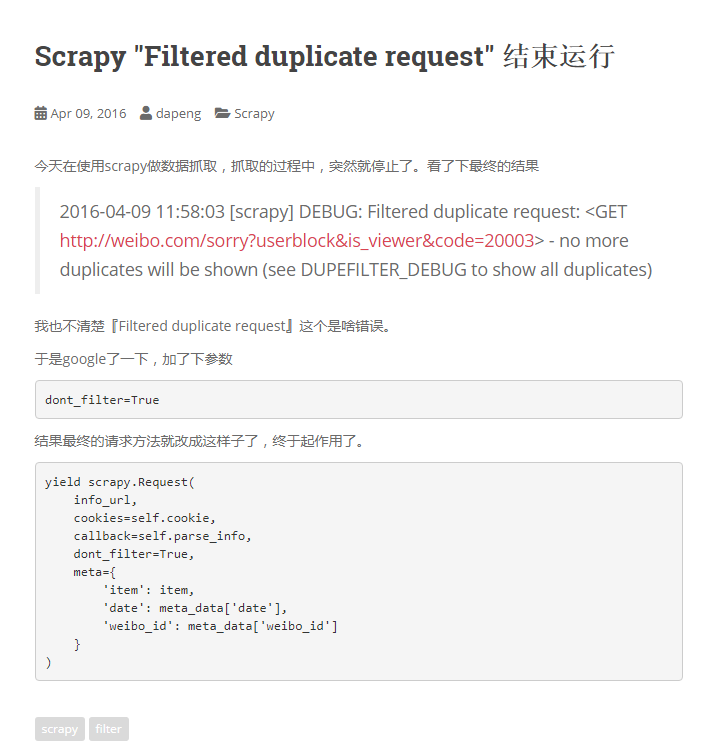
问题四:关于我们在使用xpath来获取相应元素的时候会出现一种情况,就是明明response.text可以返回出我们爬取网页的信息,但是在浏览器中copyXpath的路径却没有帮助我们获取到相应的信息,原因是那个xpath的路径跟我们response获取的页面信息路径不同。
解决方法:首先将response.text获取的页面保存在一个新建html文件中,再使用浏览器打开并使用copyXpath获取我们想要的元素的相应xpath,这个xpath才是不会出错的。(如果还是出错,那么请注意js出现的情况)
着重注意:爬取多级界面的时候一定要认清楚所有情况的url,最好是把所有种类情况的url都放在txt中对比,这样获取的url才不会出错或缺失。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号