总线设备驱动模型
1.1 总线设备驱动模型的引入
原文:https://blog.csdn.net/21cnbao/article/details/73864762
1.1.1 陷入绝境
下面我们设想一个名字叫做ABC的简单网卡,它需要接在一个CPU(假设CPUx)的内存总线上,需要地址、数据和控制总线(以及中断pin脚等)。
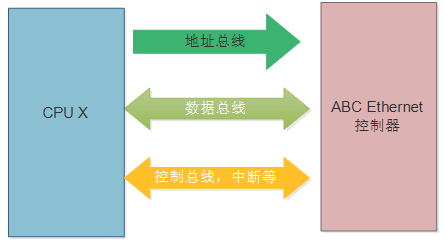
那么在ABC的网卡驱动里面,我们需要定义ABC的基地址、中断号等信息。假设在CPU x电路板上面,ABC的地址为0x100000,中断号为10。假设我们是这样定义的宏:
#define ABC_BASE 0x100000
#define ABC_interrupt 10
并且这样写代码完成发送报文和初始化申请中断:
#define ABC_BASE 0x100000
#define ABC_IRQ 10
int abc_send(...)
{
writel(ABC_BASE + REG_X, 1);
writel(ABC_BASE + REG_Y, 0x3);
...
}
int abc_init(...)
{
request_irq(ABC_IRQ,...);
}
这个代码的问题在于,一旦重新换了板子,ABC_BASE和ABC_IRQ就不再一样了,代码也需要随之变更。有的程序员说我可以这么干:
#ifdef BOARD_A
#define ABC_BASE 0x100000
#define ABC_IRQ 10
#elif defined(BOARD_B)
#define ABC_BASE 0x110000
#define ABC_IRQ 20
#elif defined(BOARD_C)
#define ABC_BASE 0x120000
#define ABC_IRQ 10
...
#endif
这么干固然可以,但是如果你有1万个不同的板子,你就要ifdef一万次,这样写代码,找到了一种明显砌墙的感觉。考虑到linux向全世界各个产品适配,各种硬件适配的特点,究竟有多少个板子用ABC,还真的谁也说不清楚。
那么,是不是真的#ifdef走一万次,就一定能解决问题呢?还真的是不能。假设有一个电路板有2个ABC网卡,就彻底傻眼了。难道这样定义?
#ifdef BOARD_A
#define ABC1_BASE 0x100000
#define ABC1_IRQ 10
#define ABC2_BASE 0x101000
#define ABC2_IRQ 11
#elif defined(BOARD_B)
#define ABC1_BASE 0x110000
#define ABC1_IRQ 20
...
#endif
如果这样做,abc_send()和abc_init()又该如何修改?难道这样:
int abc1_send(...)
{
writel(ABC1_BASE + REG_X, 1);
writel(ABC1_BASE + REG_Y, 0x3);
...
}
int abc1_init(...)
{
request_irq(ABC1_IRQ,...);
}
int abc2_send(...)
{
writel(ABC2_BASE + REG_X, 1);
writel(ABC2_BASE + REG_Y, 0x3);
...
}
int abc2_init(...)
{
request_irq(ABC2_IRQ,...);
}
…
还是这样?
int abc_send(int id, ...)
{
if (id == 0) {
writel(ABC1_BASE + REG_X, 1);
writel(ABC1_BASE + REG_Y, 0x3);
} else if (id == 1) {
writel(ABC2_BASE + REG_X, 1);
writel(ABC2_BASE + REG_Y, 0x3);
}
...
}
} else if (id == 1) {
writel(ABC2_BASE + REG_X, 1);
writel(ABC2_BASE + REG_Y, 0x3);
}
...
}
无论你怎么修改,这个代码实在都已经是惨不忍睹了,连自己都看不下去了。我们为什么会陷入这样的困境,是因为我们犯了未能“把正确的代码,放入正确的位置的错误”,这样引入了极大的耦合。
1.1.2 迷途反思
我们犯的致命错误,在于把板级互连信息,耦合进了驱动的代码,导致驱动无法跨平台。

我们转念想一想,ABC驱动的真正职责是完成ABC网卡的收发流程,试问,这个流程,真的与它接在什么CPU有半毛钱关系吗?又和接在哪个板子上有半毛钱的关系吗?
答案是真的没有什么关系!ABC网卡,不会因为你是TI的ARM,你是龙芯,还是你是Blackfin有什么不同。任你外面什么板子排山倒海,狗急跳墙,ABC自己都是岿然不动。
既然没有什么关系,那么这些板子级别的互连信息,又为什么要放在驱动的代码里面呢?基本上,我们可以认为,ABC不会因谁而变,所以它的代码应该是天然跨平台的。故此,我们认为"#define ABC_BASE 0x100000,#define ABC_IRQ 10" 这样的代码,出现在驱动里面,属于“在错误的地点,和错误的敌人,打了一场错误的战争”。它没有被放在正确的位置上,而我们写代码,一定“让天堂的归天堂,让尘土的归尘土”。我们真实的期待,恐怕是这个样子:
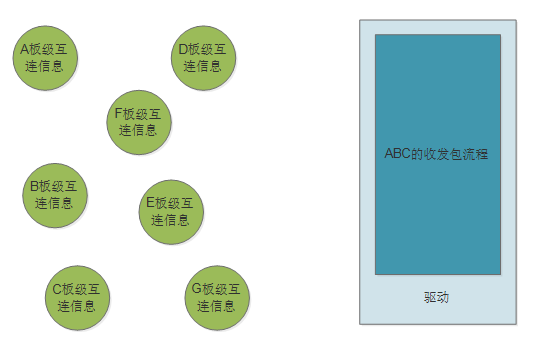
软件工程强调高内聚、低耦合。若一个模块内各元素联系的越紧密,则它的内聚性就越高;模块之间的联系越不紧密,其耦合性就越低。所以高内聚、低耦合强调,内部的要紧紧抱团,外面的给我滚蛋。对于驱动而言,板级互连信息,显然属于应该滚蛋的。
1.1.3 柳暗花明
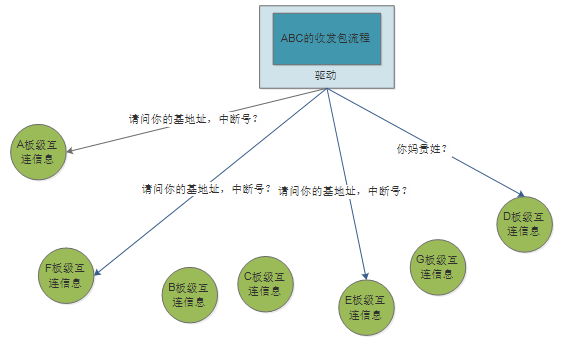
现在板级互连信息已经和驱动分离开来了,让它们彼此出现在不同的软件模块。但是,最终它们仍然有一定的联系,因为,驱动最终还是要取出基地址、中断号等板级信息的。怎么取,这是个大问题。
一种方法是ABC的驱动满世界询问各个板子,“请问你的基地址,中断号是几?”,“你妈贵姓?”这仍然是一个严重的耦合。因为,驱动还是得知道板子上有没有ABC,哪个板子有,怎么个有法。它还是在和板子直接耦合。
可不可以有另外一种方法,我们维护一个共同的类似数据库的东西,板子上有什么网卡,基地址中断号是什么,都统一在一个地方维护。然后,驱动问一个统一的地方,通过一个统一的API来获取即好?
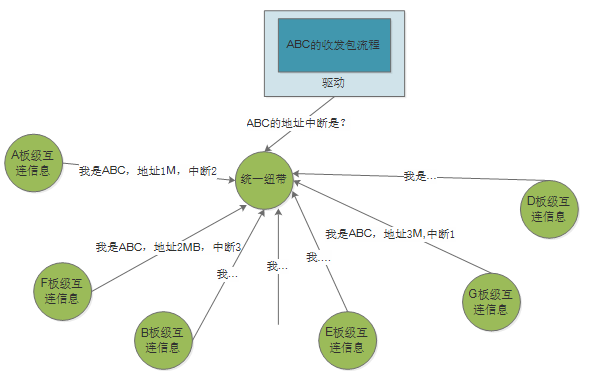
基于这样的想法,Linux把设备驱动分为了总线、设备和驱动三个实体,总线是上图中的统一纽带,设备是上图中的板级互连信息,这三个实体完成的职责分别如下:
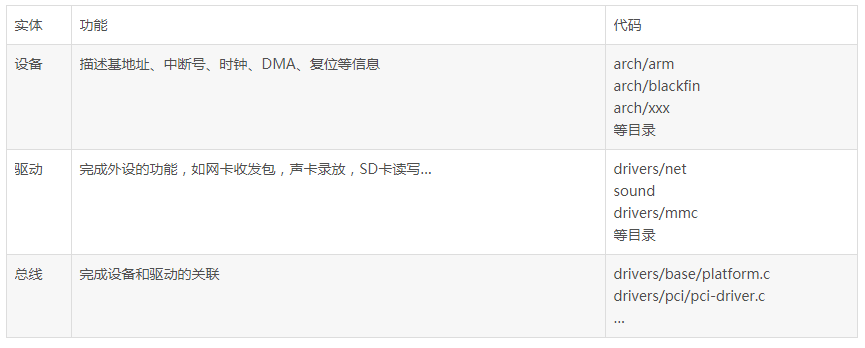
我们把所有的板子互连信息填入设备端,然后让设备端向总线注册告知总线自己的存在,总线上面自然关联了这些设备,并进一步间接关联了设备的板级连接信息。比如arch/blackfin/mach-bf533/boards/ip0x.c这块板子有2个DM9000的网卡,它是这样注册的:
static struct resource dm9000_resource1[] = {
{
.start = 0x20100000,
.end = 0x20100000 + 1,
.flags = IORESOURCE_MEM
},{
.start = 0x20100000 + 2,
.end = 0x20100000 + 3,
.flags = IORESOURCE_MEM
},{
.start = IRQ_PF15,
.end = IRQ_PF15,
.flags = IORESOURCE_IRQ | IORESOURCE_IRQ_HIGHEDGE
}
};
static struct resource dm9000_resource2[] = {
{
.start = 0x20200000,
.end = 0x20200000 + 1,
.flags = IORESOURCE_MEM
}…
};
…
static struct platform_device dm9000_device1 = {
.name = "dm9000",
.id = 0,
.num_resources = ARRAY_SIZE(dm9000_resource1),
.resource = dm9000_resource1,
};
…
static struct platform_device dm9000_device2 = {
.name = "dm9000",
.id = 1,
.num_resources = ARRAY_SIZE(dm9000_resource2),
.resource = dm9000_resource2,
};
static struct platform_device *ip0x_devices[] __initdata = {
&dm9000_device1,
&dm9000_device2,
…
};
static int __init ip0x_init(void)
{
platform_add_devices(ip0x_devices, ARRAY_SIZE(ip0x_devices));
…
}
这样platform的总线这个统一纽带上,自然就知道板子上面有2个DM9000的网卡。一旦DM9000的驱动也被注册,由于platform总线已经关联了设备,驱动自然可以根据已经存在的DM9000设备信息,获知如下的内存基地址、中断等信息了:
static struct resource dm9000_resource1[] = {
{
.start = 0x20100000,
.end = 0x20100000 + 1,
.flags = IORESOURCE_MEM
},{
.start = 0x20100000 + 2,
.end = 0x20100000 + 3,
.flags = IORESOURCE_MEM
},{
.start = IRQ_PF15,
.end = IRQ_PF15,
.flags = IORESOURCE_IRQ | IORESOURCE_IRQ_HIGHEDGE
}
}
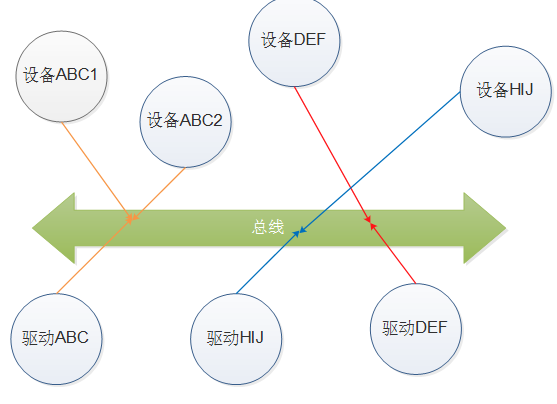
总线存在的目的,则是把这些驱动和这些设备,一一配对的匹配在一起。如下图,某个电路板子上有2个ABC,1个DEF,1个HIJ设备,以及分别1个的ABC、DEF、HIJ驱动,那么总线,就是让2个ABC设备和1个ABC驱动匹配,DEF设备和驱动一对一匹配,HIJ设备和驱动一对一匹配。
驱动本身,则可以用最简单的API取出设备端填入的互连信息,看一下drivers/net/ethernet/davicom/dm9000.c的dm9000_probe()代码:
static int dm9000_probe(struct platform_device *pdev)
{
…
db->addr_res = platform_get_resource(pdev, IORESOURCE_MEM, 0);
db->data_res = platform_get_resource(pdev, IORESOURCE_MEM, 1);
db->irq_res = platform_get_resource(pdev, IORESOURCE_IRQ, 0);
…
}
这样,板级互连信息,再也不会闯入驱动,而驱动,看起来也没有和设备之间直接耦合,因为它调用的都是总线级别的标准API:platform_get_resource()。总线里面有个match()函数,来完成哪个设备由哪个驱动来服务的职责,比如对于挂在内存上的platform总线而言,它的匹配类似(最简单的匹配方法就是设备和驱动的name字段一样):
static int platform_match(struct device *dev, struct device_driver *drv)
{
struct platform_device *pdev = to_platform_device(dev);
struct platform_driver *pdrv = to_platform_driver(drv);
/* When driver_override is set, only bind to the matching driver */
if (pdev->driver_override)
return !strcmp(pdev->driver_override, drv->name);
/* Attempt an OF style match first */
if (of_driver_match_device(dev, drv))
return 1;
/* Then try ACPI style match */
if (acpi_driver_match_device(dev, drv))
return 1;
/* Then try to match against the id table */
if (pdrv->id_table)
return platform_match_id(pdrv->id_table, pdev) != NULL;
/* fall-back to driver name match */
return (strcmp(pdev->name, drv->name) == 0);
}
这就是总线设备驱动模型引入的背景,下一篇将结合代码深入研究总线设备驱动模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号