
clickhouse中MergeTree引擎 order by的字段是否都走索引,效率怎么样?
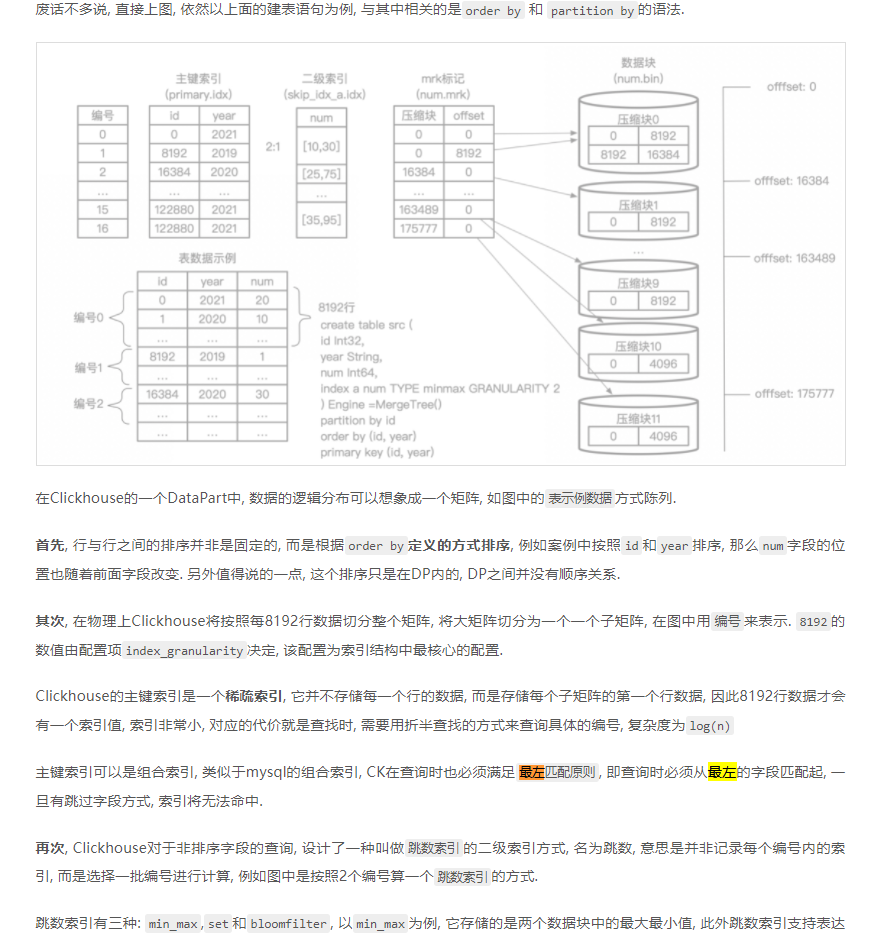
Clickhouse的主键索引是一个稀疏索引, 它并不存储每一个行的数据, 而是存储每个子矩阵的第一个行数据, 因此8192行数据才会有一个索引值, 索引非常小, 对应的代价就是查找时, 需要用折半查找的方式来查询具体的编号, 复杂度为log(n)
主键索引可以是组合索引, 类似于mysql的组合索引, CK在查询时也必须满足最左匹配原则, 即查询时必须从最左的字段匹配起, 一旦有跳过字段方式, 索引将无法命中.
经测试发现与上述结论基本一致,当使用order by的第二个字段查询的时候,效率和不加索引时效率基本一样,甚至会稍微拉低效率;
clickhouse写入磁盘的时候,是按照order by的字段写入的,比如order by (a,b),如果a字段相同,则再按照b字段排序写入磁盘;
第二个字段explain显示走索引,猜测可能是由于,走过索引后,发现也是要扫描全量数据,导致查询变慢;
注意,当a和b两个字段内容完全一样的时,查询的效率也是很快的,因为磁盘索引和写入数据是完全一样的,此时where b字段同样能达到索引的效果;
当where条件使用模糊查询,大于、小于、不等于时,此时可能不会走索引(explain显示走索引,但是效率没上去,本质上是没有走索引的,效率和不加索引没有区别,当使用等号时,有近100倍的差距,没有进行细测),可能和mysql索引类似;
可使用 explain json = 1,indexes=1 xxxsql语句xxx ;看是否走索引
参考:
clickhouse的索引结构和查询优化
深入浅出Clickhouse: 索引结构设计 (可关注下)
https://clickhouse.com/docs/en/sql-reference/statements/explain/
posted on 2022-10-12 16:24 RICH-ATONE 阅读(1483) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号