
hive分桶优化
什么是分桶?
和分区一样,分桶也是一种通过改变表的存储模式,从而完成对表优化的一种调优方式。
但和分区不同的是,分区是将表拆分到不同的子目录中进行存储,而分桶是将表拆分到不同文件中进行存储。
那什么是分桶呢?它按分桶键哈希取模的方式,将表中数据随机、均匀地分发到若干桶文件中。
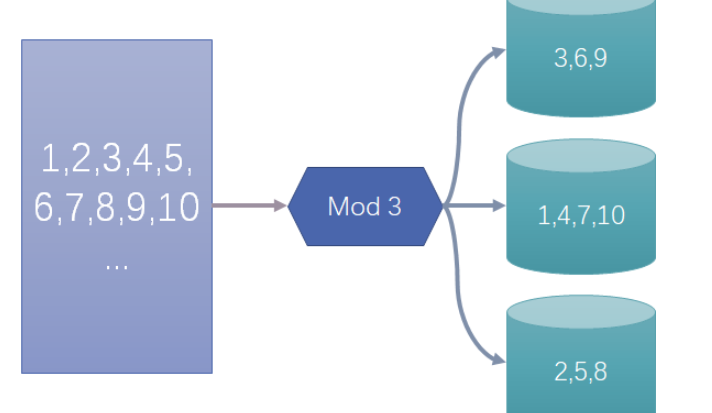
比如,对表的ID字段进行分桶,那ID字段被称为分桶键。ID字段存储的数据假设是1-10,执行分桶操作时,需要确定要分几个桶,这里定为3个;那么便会对分桶键中的值,按照桶的数量进行哈希取模,这里即对桶数3进行取余。
那么,ID为3、6、9的数据会存放到第一个桶中,ID为1、4、7、10的会存放到第二个桶中,ID为2、5、8的则存放到第三个桶中。而每个桶在进行存储的时候,会存储为一个桶文件。
分桶目的
那分桶操作的目的是什么呢?它通过改变数据的存储分布,提升查询、取样、Join等特定任务的执行效率。
因为分桶之后,在数据查询中,根据分桶键的过滤条件,就可以直接通过哈希取模来确定数据存放的桶文件,从而减少需要处理的数据量;在海量数据场景中,能极大提升数据处理效率。而在数据取样过程中,可以直接对某几个桶文件进行取样,缩短取样时间。
其次,如果在Hive中,两张表需要进行join操作,转换为MapReduce或Spark作业之后,必定要经过Shuffle,而Shuffle过程会耗费大量时间,从而拉低了处理效率。但两张表,假设使用ID进行Join,而且都使用ID作为分桶键进行了分桶操作,分桶数也相同,均为3;那么便可以直接对两张表的对应桶文件直接进行join处理,提升处理效率。因为ID相同的数据,按照相同的方式进行哈希取模,必定会存放到相同的桶文件中。
所以当两张表的桶数相同或成倍数时,会带来join效率的提升。
分区和分桶是两种不同的优化手段,当然也可以同时进行,即先分区后分桶;最终的存储效果便是在子目录下的数据,被存储为多个桶文件。
分桶表创建
例如,现创建一张分桶表tb_buckets,包含字段id、name、age,将id作为分桶键,分桶数为3:
1.首先需要开启分桶配置,不开启的话不会生效;
set hive.enforce.bucketing=true; set mapreduce.job.reduces=4;
注:参数默认值为false;设置为true之后,mr运行时会根据bucket桶的个数自动分配reduce task个数。一次作业产生的桶(文件数量)和reduce task个数 一致。这个参数在2.x版本之前,不需要进行设置。
当然用户也可以通过mapred.reduce.tasks自己设置reduce任务个数,但分桶时不推荐使用。(reduce task个数是否要设置,可以测试一下)
2、创建表;
create table tb_buckets( id int, name string, age int ) clustered by (id) into 4 buckets stored as textfile;
3.插入数据;
--开启配置 set hive.enforce.bucketing=true; --插入数据 insert into table tb_buckets_desc values(1, 'zs', 18); insert into table tb_buckets_desc values(2, 'ls', 18); insert into table tb_buckets_desc values(3, 'ls', 18); insert into table tb_buckets_desc values(4, 'ls', 18);
4、查看结果;

#开会往创建的分通表插入数据(插入数据需要是已分桶, 且排序的) #可以使用distribute by(sno) sort by(sno asc) 或是排序和分桶的字段相同的时候使用Cluster by(字段) #注意使用cluster by 就等同于分桶+排序(sort)
示例:
insert into table stu_buck select sno,sname,sex,sage,sdept from student distribute by(sno) sort by(sno asc);
参考:https://blog.csdn.net/qq_33876553/article/details/112216028
posted on 2022-09-06 17:52 RICH-ATONE 阅读(713) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号