
Flume基础介绍
概述
Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输系统。Flume基于流式架构,灵活可靠。Flume最主要的作用就是实时读取服务器本地磁盘数据,将数据写到HDFS。Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
1.Java运行时环境-Java 1.7或更高版本
2.内存-足够的内存,用于源,通道或接收器使用的配置
3.磁盘空间-足够的磁盘空间用于通道或接收器使用的配置
4.目录权限-代理使用的目录的读/写权限
Flume主要架构
Flume最核心的角色就是Agent,Agent是一个JVM进程,它以事件的形式将数据从源头送至目的,是Flume数据传输的基本单元。
Agent内部主要具有三个组件:Source、Channel、Sink。
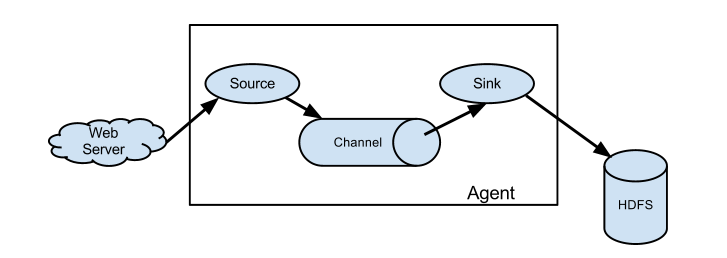
Source
数据采集的源,就是要采集的数据源。
数据输入端的常见类型有:spooling directory(目录)、exec、kafka、avro、netcat等。
Channel
是Agent内部数据的传输通道,位于Source和Sink之间的缓冲区。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是基于内存缓存,在不需要关心数据丢失的情境下使用。
File Channel是Flume的持久化Channel。系统宕机不会丢失数据。
Sink
采集数据要传送的目的地,目的地可以是HDFS、hbase、hive、kafka等众多外部存储系统中 。
Flume的后台启动
nohup /home/pirate/programs/flume/bin/flume-ng agent --conf-file /home/pirate/programs/flume/conf/job2/kafka_flume_hdfs.conf --name a2 -Dflume.monitoring.type=http -Dflume.monitoring.port=34545 -Dflume.root.logger=INFO,LOGFILE >/home/pirate/programs/flume/log.txt 2>&1 &
注:
--conf-file /home/pirate/programs/flume/conf/job2/kafka_flume_hdfs.conf:指定配置文件位置
--name a2 :指定agent的名称
-Dflume.monitoring.type=http -Dflume.monitoring.port=34545:自带http(json)监控agent
-Dflume.root.logger=INFO,LOGFILE >/home/pirate/programs/flume/log.txt 2>&1 &:打印日志到指定的文件中去
posted on 2021-02-25 22:27 RICH-ATONE 阅读(336) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号